Scala系列从入门到精通(三)
8、集合
8.1、集合简介
- Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable特质。
- 对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包
- 不可变集合:scala.collection.immutable
- 可变集合: scala.collection.mutable
- Scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而不会对原对象进行修改。类似于 java 中的 String 对象
- 可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似于 java 中 StringBuilder 对象
建议:在操作集合的时候,不可变用符号,可变用方法
8.1.1、不可变集合继承图
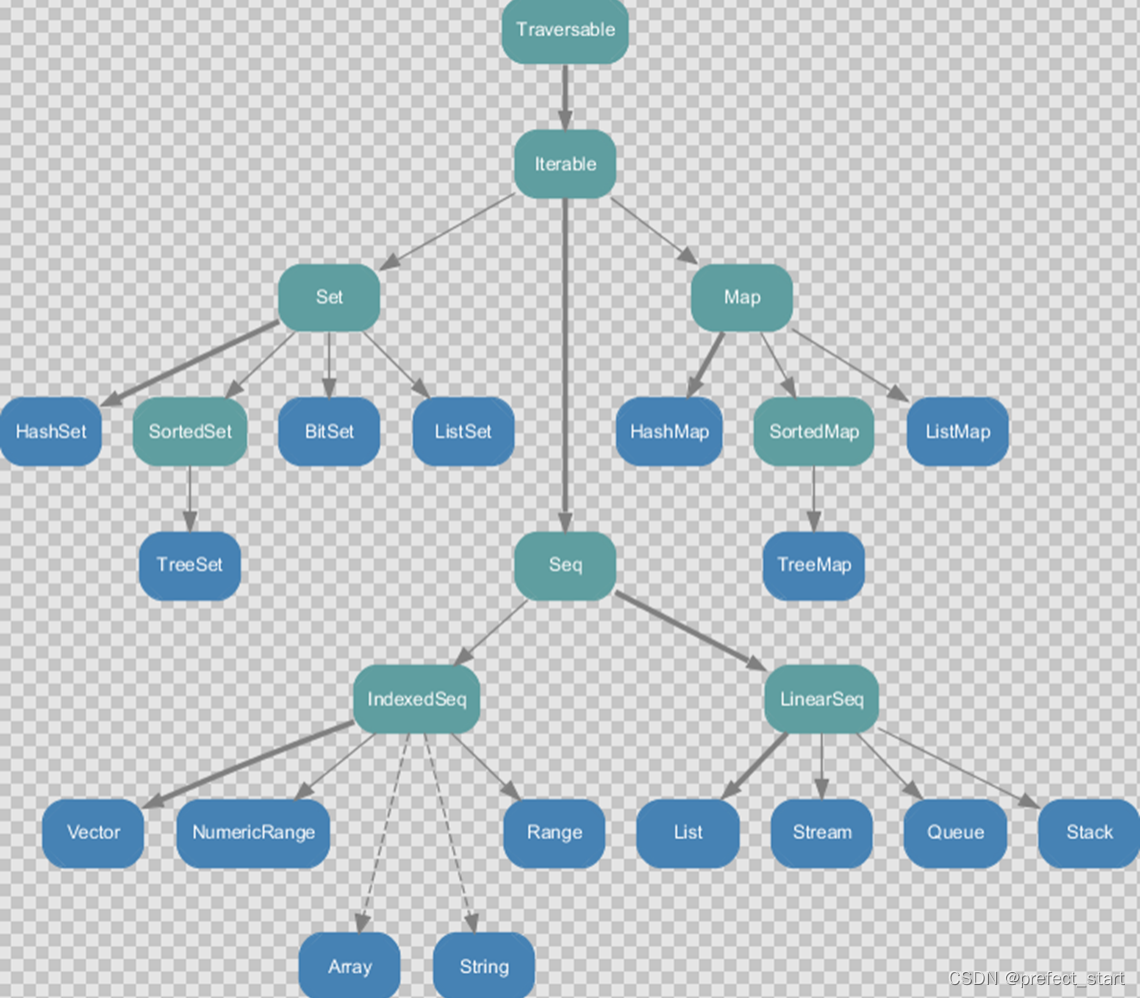
- Set、Map 是 Java 中也有的集合
- Seq 是 Java 没有的,我们发现 List 归属到 Seq 了,因此这里的 List 就和 Java 不是同一个概念了
- 我们前面的 for 循环有一个 1 to 3,就是 IndexedSeq 下的 Range
- String 也是属于 IndexedSeq
- 我们发现经典的数据结构比如 Queue 和 Stack 被归属到 LinearSeq(线性序列) 6)大家注意 Scala 中的 Map 体系有一个 SortedMap,说明 Scala 的 Map 可以支持排序
- IndexedSeq 和 LinearSeq 的区别:
- IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位
- LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找
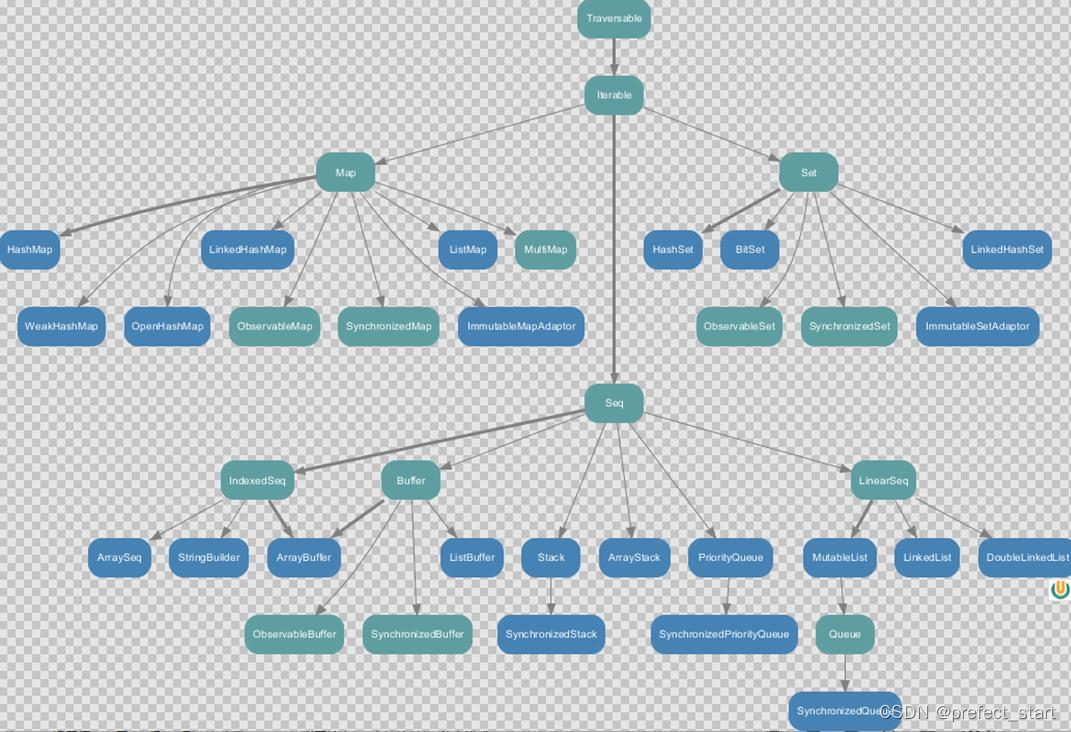
8.1.2、可变集合继承图
8.2、数组
8.2.1、不可变数组
- 第一种方式定义数组
定义:val arr1 = new Array[Int](10)
- new 是关键字
- [Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定 Any
- (10),表示数组的大小,确定后就不可以变化
- 案例实操
object TestArray {
def main(args: Array[String]): Unit = {
//(1)数组定义
val arr01 = new Array[Int](4)
println(arr01.length) // 4
//(2)数组赋值
//(2.1)修改某个元素的值
arr01(3) = 10
//(2.2)采用方法的形式给数组赋值
arr01.update(0, 1)
//(3)遍历数组
//(3.1)查看数组
println(arr01.mkString(","))
//(3.2)普通遍历
for (i <- arr01) {
println(i)
}
//(3.3)简化遍历
def printx(elem: Int): Unit = {
println(elem)
}
arr01.foreach(printx)
// arr01.foreach((x)=>{println(x)})
// arr01.foreach(println(_))
arr01.foreach(println)
//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数组
)
println(arr01)
val ints: Array[Int] = arr01 :+ 5
println(ints)
}
}
- 第二种方式定义数组
val arr1 = Array(1, 2)
- 在定义数组时,直接赋初始值
- 使用 apply 方法创建数组对象
- 案例实操
object TestArray {
def main(args: Array[String]): Unit = {
var arr02 = Array(1, 3, "bobo")
println(arr02.length)
for (i <- arr02) {
println(i)
}
}
}
8.2.2、可变数组
- 定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
- [Any]存放任意数据类型
- (3, 2, 5)初始化好的三个元素
- ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer
- 案例实操
- ArrayBuffer 是有序的集合
- 增加元素使用的是 append 方法(),支持可变参数
import scala.collection.mutable.ArrayBuffer
object TestArrayBuffer {
def main(args: Array[String]): Unit = {
//(1)创建并初始赋值可变数组
val arr01 = ArrayBuffer[Any](1, 2, 3)
//(2)遍历数组
for (i <- arr01) {
println(i)
}
println(arr01.length) // 3
println("arr01.hash=" + arr01.hashCode())
//(3)增加元素
//(3.1)追加数据
arr01.+=(4)
//(3.2)向数组最后追加数据
arr01.append(5, 6)
//(3.3)向指定的位置插入数据
arr01.insert(0, 7, 8)
println("arr01.hash=" + arr01.hashCode())
//(4)修改元素
arr01(1) = 9 //修改第 2 个元素的值
println("--------------------------")
for (i <- arr01) {
println(i)
}
println(arr01.length) // 5
}
}
8.2.3、不可变数组与可变数组的转换
- 说明
arr1.toBuffer //不可变数组转可变数组
arr2.toArray //可变数组转不可变数组
- arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化
- arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化
- 案例实操
object TestArrayBuffer {
def main(args: Array[String]): Unit = {
//(1)创建一个空的可变数组
val arr2 = ArrayBuffer[Int]()
//(2)追加值
arr2.append(1, 2, 3)
println(arr2) // 1,2,3
//(3)ArrayBuffer ==> Array
//(3.1)arr2.toArray 返回的结果是一个新的定长数组集合
//(3.2)arr2 它没有变化
val newArr = arr2.toArray
println(newArr)
//(4)Array ===> ArrayBuffer
//(4.1)newArr.toBuffer 返回一个变长数组 newArr2
//(4.2)newArr 没有任何变化,依然是定长数组
val newArr2 = newArr.toBuffer
newArr2.append(123)
println(newArr2)
}
}
8.2.4、多维数组
- 多维数组定义
val arr = Array.ofDim[Double](3,4)
说明:二维数组中有三个一维数组,每个一维数组中有四个元素
2. 案例实操
object DimArray {
def main(args: Array[String]): Unit = {
//(1)创建了一个二维数组, 有三个元素,每个元素是,含有 4 个元素一维
数组()
val arr = Array.ofDim[Int](3, 4)
arr(1)(2) = 88
//(2)遍历二维数组
for (i <- arr) { //i 就是一维数组
for (j <- i) {
print(j + " ")
}
println()
}
}
}
8.3、列表 List
8.3.1、列表 List
- 说明
- List 默认为不可变集合
- 创建一个 List(数据有顺序,可重复)
- 遍历 List
- List 增加数据
- 集合间合并:将一个整体拆成一个一个的个体,称为扁平化
- 取指定数据
- 空集合 Nil
- 案例实操
object TestList {
def main(args: Array[String]): Unit = {
//(1)List 默认为不可变集合
//(2)创建一个 List(数据有顺序,可重复)
val list: List[Int] = List(1, 2, 3, 4, 3)
//(7)空集合 Nil
val list5 = 1 :: 2 :: 3 :: 4 :: Nil
//(4)List 增加数据
//(4.1)::的运算规则从右向左
//val list1 = 5::list
val list1 = 7 :: 6 :: 5 :: list
//(4.2)添加到第一个元素位置
val list2 = list.+:(5)
//(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
val list3 = List(8, 9)
//val list4 = list3::list1
val list4 = list3 ::: list1
//(6)取指定数据
println(list(0))
//(3)遍历 List
//list.foreach(println)
//list1.foreach(println)
//list3.foreach(println)
//list4.foreach(println)
list5.foreach(println)
}
}
8.3.2、可变 ListBuffer
- 说明
- 创建一个可变集合 ListBuffer
- 向集合中添加数据
- 打印集合数据
- 案例实操
import scala.collection.mutable.ListBuffer
object TestList {
def main(args: Array[String]): Unit = {
//(1)创建一个可变集合
val buffer = ListBuffer(1, 2, 3, 4)
//(2)向集合中添加数据
buffer.+=(5)
buffer.append(6)
buffer.insert(1, 2)
//(3)打印集合数据
buffer.foreach(println)
//(4)修改数据
buffer(1) = 6
buffer.update(1, 7)
//(5)删除数据
buffer.-(5)
buffer.-=(5)
buffer.remove(5)
}
}
8.4、 Set 集合
默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用scala.collection.mutable.Set 包
8.4.1、 不可变 Set
- 说明
- Set 默认是不可变集合,数据无序
- 数据不可重复
- 遍历集合
- 案例实操
object TestSet {
def main(args: Array[String]): Unit = {
//(1)Set 默认是不可变集合,数据无序
val set = Set(1, 2, 3, 4, 5, 6)
//(2)数据不可重复
val set1 = Set(1, 2, 3, 4, 5, 6, 3)
//(3)遍历集合
for (x <- set1) {
println(x)
}
}
}
8.4.2、可变 mutable.Set
- 说明
- 创建可变集合 mutable.Set
- 打印集合
- 集合添加元素
- 向集合中添加元素,返回一个新的 Set
- 删除数据
- 案例实操
object TestSet {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val set = mutable.Set(1, 2, 3, 4, 5, 6)
//(3)集合添加元素
set += 8
//(4)向集合中添加元素,返回一个新的 Set
val ints = set.+(9)
println(ints)
println("set2=" + set)
//(5)删除数据
set -= (5)
//(2)打印集合
set.foreach(println)
println(set.mkString(","))
}
}
8.5、 Map 集合
Scala 中的 Map 和 Java 类似,也是一个散列表,它存储的内容也是键值对(key-value)映射
8.5.1、不可变 Map
- 说明
- 创建不可变集合 Map
- 循环打印
- 访问数据
- 如果 key 不存在,返回 0
- 案例实操
object TestMap {
def main(args: Array[String]): Unit = {
// Map
//(1)创建不可变集合 Map
val map = Map("a" -> 1, "b" -> 2, "c" -> 3)
//(3)访问数据
for (elem <- map.keys) {
// 使用 get 访问 map 集合的数据,会返回特殊类型 Option(选项):有值( Some) , 无值(None)
println(elem + "=" + map.get(elem).get)
}
//(4)如果 key 不存在,返回 0
println(map.get("d").getOrElse(0))
println(map.getOrElse("d", 0))
//(2)循环打印
map.foreach((kv) => {
println(kv)
})
}
}
8.5.2、可变 Map
- 说明
- 创建可变集合
- 打印集合
- 向集合增加数据
- 删除数据
- 修改数据
- 案例实操
object TestSet {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val map = mutable.Map("a" -> 1, "b" -> 2, "c" -> 3)
//(3)向集合增加数据
map.+=("d" -> 4)
// 将数值 4 添加到集合,并把集合中原值 1 返回
val maybeInt: Option[Int] = map.put("a", 4)
println(maybeInt.getOrElse(0))
//(4)删除数据
map.-=("b", "c")
//(5)修改数据
map.update("d", 5)
map("d") = 5
//(2)打印集合
map.foreach((kv) => {
println(kv)
})
}
}
8.6、元组
-
说明,元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。
注意:元组中最大只能有 22 个元素。 -
案例实操
- 声明元组的方式:(元素 1,元素 2,元素 3)
- 访问元组
- Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为对偶
object TestTuple {
def main(args: Array[String]): Unit = {
//(1)声明元组的方式:(元素 1,元素 2,元素 3)
val tuple: (Int, String, Boolean) = (40, "bobo", true)
//(2)访问元组
//(2.1)通过元素的顺序进行访问,调用方式:_顺序号
println(tuple._1)
println(tuple._2)
println(tuple._3)
//(2.2)通过索引访问数据
println(tuple.productElement(0))
//(2.3)通过迭代器访问数据
for (elem <- tuple.productIterator) {
println(elem)
}
//(3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为对偶
val map = Map("a" -> 1, "b" -> 2, "c" -> 3)
val map1 = Map(("a", 1), ("b", 2), ("c", 3))
map.foreach(tuple => {
println(tuple._1 + "=" + tuple._2)
})
}
}
8.7、集合常用函数
8.7.1、基本属性和常用操作
- 说明
- 获取集合长度
- 获取集合大小
- 循环遍历
- 迭代器
- 生成字符串
- 是否包含
- 案例实操
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
//(1)获取集合长度
println(list.length)
//(2)获取集合大小,等同于 length
println(list.size)
//(3)循环遍历
list.foreach(println)
//(4)迭代器
for (elem <- list.iterator) {
println(elem)
}
//(5)生成字符串
println(list.mkString(","))
//(6)是否包含
println(list.contains(3))
}
}
8.7.2、衍生集合
- 说明
- 获取集合的头
- 获取集合的尾(不是头的就是尾)
- 集合最后一个数据
- 集合初始数据(不包含最后一个)
- 反转
- 取前(后)n 个元素
- 去掉前(后)n 个元素
- 并集
- 交集
- 差集
- 拉链
- 滑窗
- 案例实操
object TestList {
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
val list2: List[Int] = List(4, 5, 6, 7, 8, 9, 10)
//(1)获取集合的头
println(list1.head)
//(2)获取集合的尾(不是头的就是尾)
println(list1.tail)
//(3)集合最后一个数据
println(list1.last)
//(4)集合初始数据(不包含最后一个)
println(list1.init)
//(5)反转
println(list1.reverse)
//(6)取前(后)n 个元素
println(list1.take(3))
println(list1.takeRight(3))
//(7)去掉前(后)n 个元素
println(list1.drop(3))
println(list1.dropRight(3))
//(8)并集
println(list1.union(list2))
//(9)交集
println(list1.intersect(list2))
//(10)差集
println(list1.diff(list2))
//(11)拉链 注:如果两个集合的元素个数不相等,那么会将同等数量的数据进行拉链,多余的数据省略不用
println(list1.zip(list2))
//(12)滑窗
list1.sliding(2, 5).foreach(println)
}
}
8.7.3、集合计算简单函数
- 说明
- 求和
- 求乘积
- 最大值
- 最小值
- 排序
- 实操
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 5, -3, 4, 2, -7, 6)
//(1)求和
println(list.sum)
//(2)求乘积
println(list.product)
//(3)最大值
println(list.max)
//(4)最小值
println(list.min)
//(5)排序
// (5.1)按照元素大小排序
println(list.sortBy(x => x))
// (5.2)按照元素的绝对值大小排序
println(list.sortBy(x => x.abs))
// (5.3)按元素大小升序排序
println(list.sortWith((x, y) => x < y))
// (5.4)按元素大小降序排序
println(list.sortWith((x, y) => x > y))
}
}
- sorted
对一个集合进行自然排序,通过传递隐式的 Ordering - sortBy
对一个属性或多个属性进行排序,通过它的类型。 - sortWith
基于函数的排序,通过一个 comparator 函数,实现自定义排序的逻辑。
8.7.4、集合计算高级函数
- 说明
- 过滤:遍历一个集合并从中获取满足指定条件的元素组成一个新的集合
- 转化/映射(map):将集合中的每一个元素映射到某一个函数
- 扁平化
- 扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten 操作集合中的每个元素的子元素映射到某个函数并返回新集合
- 分组(group):按照指定的规则对集合的元素进行分组
- 简化(归约)
- 折叠
- 实操
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
val wordList: List[String] = List("hello world", "hello atguigu", " hello scala")
//(1)过滤
println(list.filter(x => x % 2 == 0))
//(2)转化/映射
println(list.map(x => x + 1))
//(3)扁平化
println(nestedList.flatten)
//(4)扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten操作
println(wordList.flatMap(x => x.split(" ")))
//(5)分组
println(list.groupBy(x => x % 2))
}
}
- Reduce 方法:Reduce 简化(归约) :通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最终获取结果。
object TestReduce {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4)
// 将数据两两结合,实现运算规则
val i: Int = list.reduce((x, y) => x - y)
println("i = " + i)
// 从源码的角度,reduce 底层调用的其实就是 reduceLeft
//val i1 = list.reduceLeft((x,y) => x-y)
// ((4-3)-2-1) = -2
val i2 = list.reduceRight((x, y) => x - y)
println(i2)
}
}
- Fold 方法:化简的一种特殊情况。
- 案例实操:fold 基本使用
object TestFold {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4)
// fold 方法使用了函数柯里化,存在两个参数列表
// 第一个参数列表为 : 零值(初始值)
// 第二个参数列表为: 简化规则
// fold 底层其实为 foldLeft
val i = list.foldLeft(1)((x, y) => x - y)
val i1 = list.foldRight(10)((x, y) => x - y)
println(i)
println(i1)
}
}
- 案例实操:两个集合合并
object TestFold {
def main(args: Array[String]): Unit = {
// 两个 Map 的数据合并
val map1 = mutable.Map("a" -> 1, "b" -> 2, "c" -> 3)
val map2 = mutable.Map("a" -> 4, "b" -> 5, "d" -> 6)
val map3: mutable.Map[String, Int] = map2.foldLeft(map1) {
(map, kv) => {
val k = kv._1
val v = kv._2
map(k) = map.getOrElse(k, 0) + v
map
}
}
println(map3)
}
}
8.7.5、普通 WordCount 案例
- 需求:单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结果
- 需求分析
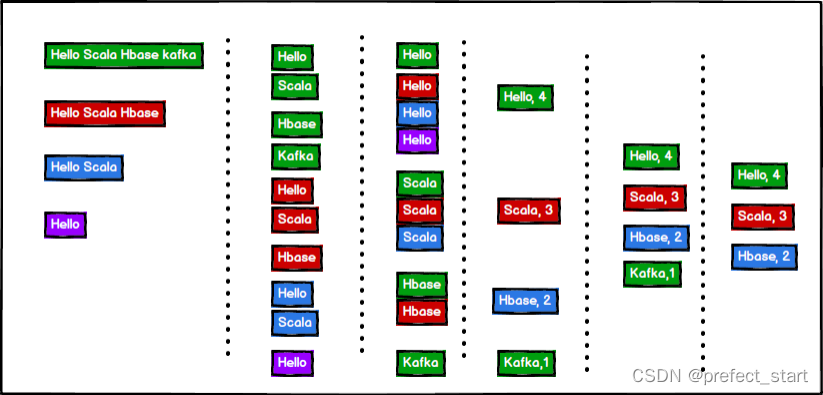
- 案例实操
object TestWordCount {
def main(args: Array[String]): Unit = {
// 单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结
果
val stringList = List("Hello Scala Hbase kafka", "Hello Scala Hbase", " Hello Scala", "Hello")
// 1) 将每一个字符串转换成一个一个单词
val wordList: List[String] =
stringList.flatMap(str => str.split(" "))
//println(wordList)
// 2) 将相同的单词放置在一起
val wordToWordsMap: Map[String, List[String]] =
wordList.groupBy(word => word)
//println(wordToWordsMap)
// 3) 对相同的单词进行计数
// (word, list) => (word, count)
val wordToCountMap: Map[String, Int] = wordToWordsMap.map(tuple => (tuple._1, tuple._2.size))
// 4) 对计数完成后的结果进行排序(降序)
val sortList: List[(String, Int)] =
wordToCountMap.toList.sortWith {
(left, right) => {
left._2 > right._2
}
}
// 5) 对排序后的结果取前 3 名
val resultList: List[(String, Int)] = sortList.take(3)
println(resultList)
}
}
8.7.6、复杂 WordCount 案例
- 方式一
object TestWordCount {
def main(args: Array[String]): Unit = {
// 第一种方式(不通用)
val tupleList = List(("Hello Scala Spark World ", 4), ("Hello Scala Spark", 3), (" Hello Scala", 2), ("Hello", 1))
val stringList: List[String] = tupleList.map(t => (t._1 + " ") * t._2)
//val words: List[String] =
stringList.flatMap(s => s.split(" "))
val words: List[String] = stringList.flatMap(_.split(" "))
//在 map 中,如果传进来什么就返回什么,不要用_省略
val groupMap: Map[String, List[String]] =
words.groupBy(word => word)
//val groupMap: Map[String, List[String]] =
words.groupBy(_)
// (word, list) => (word, count)
val wordToCount: Map[String, Int] = groupMap.map(t => (t._1,
t._2.size))
val wordCountList: List[(String, Int)] =
wordToCount.toList.sortWith {
(left, right) => {
left._2 > right._2
}
}.take(3)
//tupleList.map(t=>(t._1 + " ") * t._2).flatMap(_.split(" ")).groupBy(word=>word).map(t=>(t._1, t._2.size))
println(wordCountList)
}
}
- 方式二
object TestWordCount {
def main(args: Array[String]): Unit = {
val tuples = List(("Hello Scala Spark World", 4), ("Hello Scala Spark", 3), (" Hello Scala", 2), ("Hello", 1))
// (Hello,4),(Scala,4),(Spark,4),(World,4)
// (Hello,3),(Scala,3),(Spark,3)
// (Hello,2),(Scala,2)
// (Hello,1)
val wordToCountList: List[(String, Int)] = tuples.flatMap {
t => {
val strings: Array[String] = t._1.split(" ")
strings.map(word => (word, t._2))
}
}
// Hello, List((Hello,4), (Hello,3), (Hello,2), (Hello,1))
// Scala, List((Scala,4), (Scala,3), (Scala,2)
// Spark, List((Spark,4), (Spark,3)
// Word, List((Word,4))
val wordToTupleMap: Map[String, List[(String, Int)]] =
wordToCountList.groupBy(t => t._1)
val stringToInts: Map[String, List[Int]] =
wordToTupleMap.mapValues {
datas => datas.map(t => t._2)
}
stringToInts
/*
val wordToCountMap: Map[String, List[Int]] =
wordToTupleMap.map {
t => {
(t._1, t._2.map(t1 => t1._2))
}
}
val wordToTotalCountMap: Map[String, Int] =
wordToCountMap.map(t=>(t._1, t._2.sum))
println(wordToTotalCountMap)
*/
}
}
8.8、队列
- 说明
Scala 也提供了队列(Queue)的数据结构,队列的特点就是先进先出。进队和出队的方法分别为 enqueue 和 dequeue。 - 案例实操
object TestQueue {
def main(args: Array[String]): Unit = {
val que = new mutable.Queue[String]()
que.enqueue("a", "b", "c")
println(que.dequeue())
println(que.dequeue())
println(que.dequeue())
}
}
8.9、并行集合
- 说明
Scala 为了充分使用多核 CPU,提供了并行集合(有别于前面的串行集合),用于多核环境的并行计算。 - 案例实操
object TestPar {
def main(args: Array[String]): Unit = {
val result1 = (0 to 100).map { case _ =>
Thread.currentThread.getName
}
val result2 = (0 to 100).par.map { case _ =>
Thread.currentThread.getName
}
println(result1)
println(result2)
}
}
9、模式匹配
Scala 中的模式匹配类似于 Java 中的 switch 语法
int i = 10
switch (i) {
case 10 :
System.out.println("10");
break;
case 20 :
System.out.println("20");
break;
default :
System.out.println("other number");
break;
}
9.1、基本语法
模式匹配语法中,采用 match 关键字声明,每个分支采用 case 关键字进行声明,当需要匹配时,会从第一个 case 分支开始,如果匹配成功,那么执行对应的逻辑代码,如果匹配不成功,继续执行下一个分支进行判断。如果所有 case 都不匹配,那么会执行 case _分支,类似于 Java 中 default 语句。
object TestMatchCase {
def main(args: Array[String]): Unit = {
var a: Int = 10
var b: Int = 20
var operator: Char = 'd'
var result = operator match {
case '+' => a + b
case '-' => a - b
case '*' => a * b
case '/' => a / b
case _ => "illegal"
}
println(result)
}
}
- 说明
- 如果所有 case 都不匹配,那么会执行 case _ 分支,类似于 Java 中 default 语句,若此时没有 case _ 分支,那么会抛出 atchError。
- 每个 case 中,不需要使用 break 语句,自动中断 case。
- match case 语句可以匹配任何类型,而不只是字面量。
- => 后面的代码块,直到下一个 case 语句之前的代码是作为一个整体执行,可以使用{}括起来,也可以不括。
9.2、模式守卫
- 说明:如果想要表达匹配某个范围的数据,就需要在模式匹配中增加条件守卫。
- 案例实操
object TestMatchGuard {
def main(args: Array[String]): Unit = {
def abs(x: Int) = x match {
case i: Int if i >= 0 => i
case j: Int if j < 0 => -j
case _ => "type illegal"
}
println(abs(-5))
}
}
9.3、模式匹配类型
9.3.1、匹配常量
- 说明Scala 中,模式匹配可以匹配所有的字面量,包括字符串,字符,数字,布尔值等等。
- 实操
object TestMatchVal {
def main(args: Array[String]): Unit = {
println(describe(6))
}
def describe(x: Any) = x match {
case 5 => "Int five"
case "hello" => "String hello"
case true => "Boolean true"
case '+' => "Char +"
}
}
9.3.2、匹配类型
- 说明:需要进行类型判断时,可以使用前文所学的 isInstanceOf[T]和 asInstanceOf[T],也可使用模式匹配实现同样的功能。
- 案例实操
object TestMatchClass {
def describe(x: Any) = x match {
case i: Int => "Int"
case s: String => "String hello"
case m: List[_] => "List"
case c: Array[Int] => "Array[Int]"
case someThing => "something else " + someThing
}
def main(args: Array[String]): Unit = {
//泛型擦除
println(describe(List(1, 2, 3, 4, 5)))
//数组例外,可保留泛型
println(describe(Array(1, 2, 3, 4, 5, 6)))
println(describe(Array("abc")))
}
}
9.3.3、 匹配数组
- 说明:scala 模式匹配可以对集合进行精确的匹配,例如匹配只有两个元素的、且第一个元素为 0 的数组。
- 案例实操
object TestMatchArray {
def main(args: Array[String]): Unit = {
for (arr <- Array(Array(0), Array(1, 0), Array(0, 1, 0),
Array(1, 1, 0), Array(1, 1, 0, 1), Array("hello", 90))) { // 对一个数组集合进行遍历
val result = arr match {
case Array(0) => "0" //匹配 Array(0) 这个数组
case Array(x, y) => x + "," + y //匹配有两个元素的数组 , 然后将将元素值赋给对应的 x, y
case Array(0, _*) => "以 0 开头的数组" //匹配以 0 开头和数组
case _ => "something else"
}
println("result = " + result)
}
}
}
9.3.4、匹配列表
- 方式一
object TestMatchList {
def main(args: Array[String]): Unit = {
//list 是一个存放 List 集合的数组
//请思考,如果要匹配 List(88) 这样的只含有一个元素的列表,并原值返回.应该怎么写
for (list <- Array(List(0), List(1, 0), List(0, 0, 0), List(1,
0, 0), List(88))) {
val result = list match {
case List(0) => "0" //匹配 List(0)
case List(x, y) => x + "," + y //匹配有两个元素的 List
case List(0, _*) => "0 ..."
case _ => "something else"
}
println(result)
}
}
}
- 方式二
object TestMatchList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 5, 6, 7)
list match {
case first :: second :: rest => println(first + "-" + second + "-" + rest)
case _ => println("something else")
}
}
}
9.3.5、匹配元组
object TestMatchTuple {
def main(args: Array[String]): Unit = {
//对一个元组集合进行遍历
for (tuple <- Array((0, 1), (1, 0), (1, 1), (1, 0, 2))) {
val result = tuple match {
case (0, _) => "0 ..." //是第一个元素是 0 的元组
case (y, 0) => "" + y + "0" // 匹配后一个元素是 0 的对偶元组
case (a, b) => "" + a + " " + b
case _ => "something else" //默认
}
println(result)
}
}
}
拓展案例
def main(args: Array[String]): Unit = {
//特殊的模式匹配 1 打印元组第一个元素
for (elem <- Array(("a", 1), ("b", 2), ("c", 3))) {
println(elem._1)
}
for ((word, count) <- Array(("a", 1), ("b", 2), ("c", 3))) {
println(word)
}
for ((word, _) <- Array(("a", 1), ("b", 2), ("c", 3))) {
println(word)
}
for (("a", count) <- Array(("a", 1), ("b", 2), ("c", 3))) {
println(count)
}
println("--------------")
//特殊的模式匹配 2 给元组元素命名
var (id, name, age): (Int, String, Int) = (100, "zs", 20)
println((id, name, age))
println("--------------")
//特殊的模式匹配 3 遍历集合中的元组,给 count * 2
var list: List[(String, Int)] = List(("a", 1), ("b", 2), ("c", 3))
//println(list.map(t => (t._1, t._2 * 2)))
println(
list.map {
case (word, count) => (word, count * 2)
}
)
var list1 = List(("a", ("a", 1)), ("b", ("b", 2)), ("c", ("c", 3)))
println(
list1.map {
case (groupkey, (word, count)) => (word, count * 2)
}
)
}}
9.3.6、匹配对象及样例类
- 基本语法:
class User(val name: String, val age: Int)
object User {
def apply(name: String, age: Int): User = new User(name, age)
def unapply(user: User): Option[(String, Int)] = {
if (user == null)
None
else
Some(user.name, user.age)
}
}
object TestMatchUnapply {
def main(args: Array[String]): Unit = {
val user: User = User("zhangsan", 11)
val result = user match {
case User("zhangsan", 11) => "yes"
case _ => "no"
}
println(result)
}
}
小结:
- val user = User(“zhangsan”,11),该语句在执行时,实际调用的是 User 伴生对象中的apply 方法,因此不用 new 关键字就能构造出相应的对象。
- 当将 User(“zhangsan”, 11)写在 case 后时[case User(“zhangsan”, 11) => “yes”],会默认调用 unapply 方法(对象提取器),user 作为 unapply 方法的参数,unapply 方法将 user 对象的 name 和 age 属性提取出来,与 User(“zhangsan”, 11)中的属性值进行匹配
- case 中对象的 unapply 方法(提取器)返回 Some,且所有属性均一致,才算匹配成功,属性不一致,或返回 None,则匹配失败。
- 若只提取对象的一个属性,则提取器为
unapply(obj:Obj):Option[T], - 若提取对象的多个属性,则提取器为
unapply(obj:Obj):Option[(T1,T2,T3…)] - 若提取对象的可变个属性,则提取器为
unapplySeq(obj:Obj):Option[Seq[T]]
- 样例类
- 语法:
case class Person (name: String, age: Int) - 说明:
- 样例类仍然是类,和普通类相比,只是其自动生成了伴生对象,并且伴生对象中自动提供了一些常用的方法,如 apply、unapply、toString、equals、hashCode 和 copy。
- 样例类是为模式匹配而优化的类,因为其默认提供了 unapply 方法,因此,样例类可以直接使用模式匹配,而无需自己实现 unapply 方法。
- 构造器中的每一个参数都成为 val,除非它被显式地声明为 var(不建议这样做)
- 实操
case class User(name: String, age: Int)
object TestMatchUnapply {
def main(args: Array[String]): Unit = {
val user: User = User("zhangsan", 11)
val result = user match {
case User("zhangsan", 11) => "yes"
case _ => "no"
}
println(result)
}
}
9.4、变量声明中的模式匹配
case class Person(name: String, age: Int)
object TestMatchVariable {
def main(args: Array[String]): Unit = {
val (x, y) = (1, 2)
println(s"x=$x,y=$y")
val Array(first, second, _*) = Array(1, 7, 2, 9)
println(s"first=$first,second=$second")
val Person(name, age) = Person("zhangsan", 16)
println(s"name=$name,age=$age")
}
}
9.5、for 表达式中的模式匹配
object TestMatchFor {
def main(args: Array[String]): Unit = {
val map = Map("A" -> 1, "B" -> 0, "C" -> 3)
for ((k, v) <- map) { //直接将 map 中的 k-v 遍历出来
println(k + " -> " + v) //3 个
}
println("----------------------")
//遍历 value=0 的 k-v ,如果 v 不是 0,过滤
for ((k, 0) <- map) {
println(k + " --> " + 0) // B->0
}
println("----------------------")
//if v == 0 是一个过滤的条件
for ((k, v) <- map if v >= 1) {
println(k + " ---> " + v) // A->1 和 c->33
}
}
}
9.6、偏函数中的模式匹配
偏函数也是函数的一种,通过偏函数我们可以方便的对输入参数做更精确的检查。例如该偏函数的输入类型为 List[Int],而我们需要的是第一个元素是 0 的集合,这就是通过模式匹配实现的。
- 偏函数定义
val second: PartialFunction[List[Int], Option[Int]] = {
case x :: y :: _ => Some(y)
}
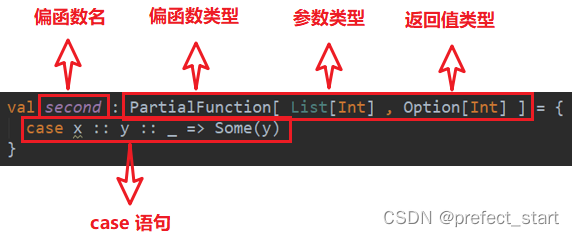
注:该偏函数的功能是返回输入的 List 集合的第二个元素
- 偏函数原理
上述代码会被 scala 编译器翻译成以下代码,与普通函数相比,只是多了一个用于参数检查的函数——isDefinedAt,其返回值类型为 Boolean。
val second = new PartialFunction[List[Int], Option[Int]] {
//检查输入参数是否合格
override def isDefinedAt(list: List[Int]): Boolean = list match {
case x :: y :: _ => true
case _ => false
}
//执行函数逻辑
override def apply(list: List[Int]): Option[Int] = list match {
case x :: y :: _ => Some(y)
}
}
- 偏函数使用
偏函数不能像 second(List(1,2,3))这样直接使用,因为这样会直接调用 apply 方法,而应该调用 applyOrElse 方法,如下
second.applyOrElse(List(1,2,3), (_: List[Int]) => None) applyOrElse 方法的逻辑为 if (ifDefinedAt(list)) apply(list) else default。如果输入参数满足条件,即 isDefinedAt 返回 true,则执行 apply 方法,否则执行 defalut 方法,default 方法为参数不满足要求的处理逻辑。
- 案例实操
- 需求:将该 List(1,2,3,4,5,6,“test”)中的 Int 类型的元素加一,并去掉字符串。
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4, 5, 6, "test")
val list1 = list.map {
a =>
a match {
case i: Int => i + 1
case s: String => s + 1
}
}
println(list1.filter(a => a.isInstanceOf[Int]))
}
- 实操
方法一:List(1,2,3,4,5,6,"test").filter(_.isInstanceOf[Int]).map(_.asInstanceOf[Int] + 1).foreach(println)
方法二:List(1, 2, 3, 4, 5, 6, "test").collect { case x: Int => x + 1 }.foreach(println)
10、异常
10.1、Java 异常处理
public class ExceptionDemo {
public static void main(String[] args) {
try {
int a = 10;
int b = 0;
int c = a / b;
} catch (ArithmeticException e) {
// catch 时,需要将范围小的写到前面
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("finally");
}
}
}
注意事项
- Java 语言按照 try—catch—finally 的方式来处理异常
- 不管有没有异常捕获,都会执行 finally,因此通常可以在 finally 代码块中释放资源
- 可以有多个 catch,分别捕获对应的异常,这时需要把范围小的异常类写在前面,把范围大的异常类写在后面,否则编译错误。
10.2、Scala 异常处理
def main(args: Array[String]): Unit = {
try {
var n = 10 / 0
} catch {
case ex: ArithmeticException => {
// 发生算术异常
println("发生算术异常")
}
case ex: Exception => {
// 对异常处理
println("发生了异常 1")
println("发生了异常 2")
}
} finally {
println("finally")
}
}
- 我们将可疑代码封装在 try 块中。在 try 块之后使用了一个 catch 处理程序来捕获异常。如果发生任何异常,catch 处理程序将处理它,程序将不会异常终止。
- Scala 的异常的工作机制和 Java 一样,但是 Scala 没有“checked(编译期)”异常, 即 Scala 没有编译异常这个概念,异常都是在运行的时候捕获处理。
- 异常捕捉的机制与其他语言中一样,如果有异常发生,catch 子句是按次序捕捉的。因此,在 catch 子句中,越具体的异常越要靠前,越普遍的异常越靠后,如果把越普遍的异常写在前,把具体的异常写在后,在 Scala 中也不会报错,但这样是非常不好的编程风格。
- finally 子句用于执行不管是正常处理还是有异常发生时都需要执行的步骤,一般用于对象的清理工作,这点和 Java 一样。
- 用 throw 关键字,抛出一个异常对象。所有异常都是 Throwable 的子类型。throw 表达式是有类型的,就是 Nothing,因为 Nothing 是所有类型的子类型,所以 throw 表达式可以用在需要类型的地方
def test(): Nothing = {
throw new Exception("不对")
}
- java 提供了 throws 关键字来声明异常。可以使用方法定义声明异常。它向调用者函数提供了此方法可能引发此异常的信息。它有助于调用函数处理并将该代码包含在 try-catch块中,以避免程序异常终止。在 Scala 中,可以使用 throws 注解来声明异常
def main(args: Array[String]): Unit = {
f11()
}
@throws(classOf[NumberFormatException])
def f11() = {
"abc".toInt
}
11、隐式转换
当编译器第一次编译失败的时候,会在当前的环境中查找能让代码编译通过的方法,用于将类型进行转换,实现二次编译.
11.1、隐式函数
- 说明
隐式转换可以在不需改任何代码的情况下,扩展某个类的功能。 - 案例实操
需求:通过隐式转化为 Int 类型增加方法。
class MyRichInt(val self: Int) {
def myMax(i: Int): Int = {
if (self < i) i else self
}
def myMin(i: Int): Int = {
if (self < i) self else i
}
}
object TestImplicitFunction {
// 使用 implicit 关键字声明的函数称之为隐式函数
implicit def convert(arg: Int): MyRichInt = {
new MyRichInt(arg)
}
def main(args: Array[String]): Unit = {
// 当想调用对象功能时,如果编译错误,那么编译器会尝试在当前作用域范围内查找能调用对应功能的转换规则,这个调用过程是由编译器完成的,所以称之为隐 式转换。也称之为自动转换
println(2.myMax(6))
}
}
11.2、隐式参数
普通方法或者函数中的参数可以通过 implicit 关键字声明为隐式参数,调用该方法时,就可以传入该参数,编译器会在相应的作用域寻找符合条件的隐式值。
- 说明
- 同一个作用域中,相同类型的隐式值只能有一个
- 编译器按照隐式参数的类型去寻找对应类型的隐式值,与隐式值的名称无关。
- 隐式参数优先于默认参数
- 案例实操
object TestImplicitParameter {
implicit val str: String = "hello world!"
def hello(implicit arg: String = "good bey world!"): Unit = {
println(arg)
}
def main(args: Array[String]): Unit = {
hello
}
}
11.3、隐式类
在 Scala2.10 后提供了隐式类,可以使用 implicit 声明类,隐式类的非常强大,同样可以扩展类的功能,在集合中隐式类会发挥重要的作用。
- 隐式类说明
- 其所带的构造参数有且只能有一个
- 隐式类必须被定义在“类”或“伴生对象”或“包对象”里,即隐式类不能是顶级的。
- 案例实操
object TestImplicitClass {
implicit class MyRichInt(arg: Int) {
def myMax(i: Int): Int = {
if (arg < i) i else arg
}
def myMin(i: Int) = {
if (arg < i) arg else i
}
}
def main(args: Array[String]): Unit = {
println(1.myMax(3))
}
}
11.4、隐式解析机制
- 说明
- 首先会在当前代码作用域下查找隐式实体(隐式方法、隐式类、隐式对象)。(一般是这种情况)
- 如果第一条规则查找隐式实体失败,会继续在隐式参数的类型的作用域里查找。类型的作用域是指与该类型相关联的全部伴生对象以及该类型所在包的包对象。
- 案例实操
package com.atguigu.chapter10
import com.atguigu.chapter10.Scala05_Transform4.Teacher
//(2)如果第一条规则查找隐式实体失败,会继续在隐式参数的类型的作用域里查找。
类型的作用域是指与该类型相关联的全部伴生模块 ,
object TestTransform extends PersonTrait {
def main(args: Array[String]): Unit = {
//(1)首先会在当前代码作用域下查找隐式实体
val teacher = new Teacher()
teacher.eat()
teacher.say()
}
class Teacher {
def eat(): Unit = {
println("eat...")
}
}
}
trait PersonTrait {
}
object PersonTrait {
// 隐式类 : 类型 1 => 类型 2
implicit class Person5(user: Teacher) {
def say(): Unit = {
println("say...")
}
}
}
12、泛型
12.1、协变和逆变
- 语法
class MyList[+T]{ //协变
}
class MyList[-T]{ //逆变
}
class MyList[T] //不变
- 说明
- 协变:Son 是 Father 的子类,则 MyList[Son] 也作为 MyList[Father]的“子类”。
- 逆变:Son 是 Father 的子类,则 MyList[Son]作为 MyList[Father]的“父类”。
- 不变:Son 是 Father 的子类,则 MyList[Father]与 MyList[Son]“无父子关系”。
- 实操
//泛型模板
//class MyList<T>{}
//不变
//class MyList[T]{}
//协变
//class MyList[+T]{}
//逆变
//class MyList[-T]{}
class Parent {}
class Child extends Parent {}
class SubChild extends Child {}
object Scala_TestGeneric {
def main(args: Array[String]): Unit = {
//var s:MyList[Child] = new MyList[SubChild]
}
}
12.2、 泛型上下限
- 语法
Class PersonList[T <: Person]{ //泛型上限
}
Class PersonList[T >: Person]{ //泛型下限
}
- 说明:泛型的上下限的作用是对传入的泛型进行限定。
- 实操
class Parent {}
class Child extends Parent {}
class SubChild extends Child {}
object Scala_TestGeneric {
def main(args: Array[String]): Unit = {
//test(classOf[SubChild])
//test[Child](new SubChild)
}
//泛型通配符之上限
//def test[A <: Child](a:Class[A]): Unit ={
// println(a)
//}
//泛型通配符之下限
//def test[A >: Child](a:Class[A]): Unit ={
// println(a)
//}
//泛型通配符之下限 形式扩展
def test[A >: Child](a: A): Unit = {
println(a.getClass.getName)
}
}
12.3、 上下文限定
- 语法
def f[A : B](a: A) = println(a) //等同于 def f[A](a:A)(implicit arg:B[A])=println(a)
- 说明
上下文限定是将泛型和隐式转换的结合产物,以下两者功能相同,使用上下文限定[A : Ordering]之后,方法内无法使用隐式参数名调用隐式参数,需要通过implicitly[Ordering[A]]获取隐式变量,如果此时无法查找到对应类型的隐式变量,会发生出错误。
implicit val x = 1
val y = implicitly[Int]
val z = implicitly[Double]
- 实操
def f[A: Ordering](a: A, b: A) = implicitly[Ordering[A]].compare(a, b)
def f[A](a: A, b: A)(implicit ord: Ordering[A]) = ord.compare(a, b)