HadoopSpark
质差聚类优化:
cpu的分支预测,有序数组的的求和比无序数组快很多,就是因为CPU分支预测器的存在。
解决办法:用移位来取代分支,让分支器更好预测等等。
actor:
通常对一个actor的调用会在不同线程上处理,一组线程处理一组actor,很多actor调用同一个线程,也就是说线程与actor之间的关系是多对多的关系。
需要返回结果的时候可以考虑future。
spark_strming=0.5-n秒的准实时计算。
DataFrame,DataSet是以RDD为基础的分布式数据集
hadoop的mapreduce
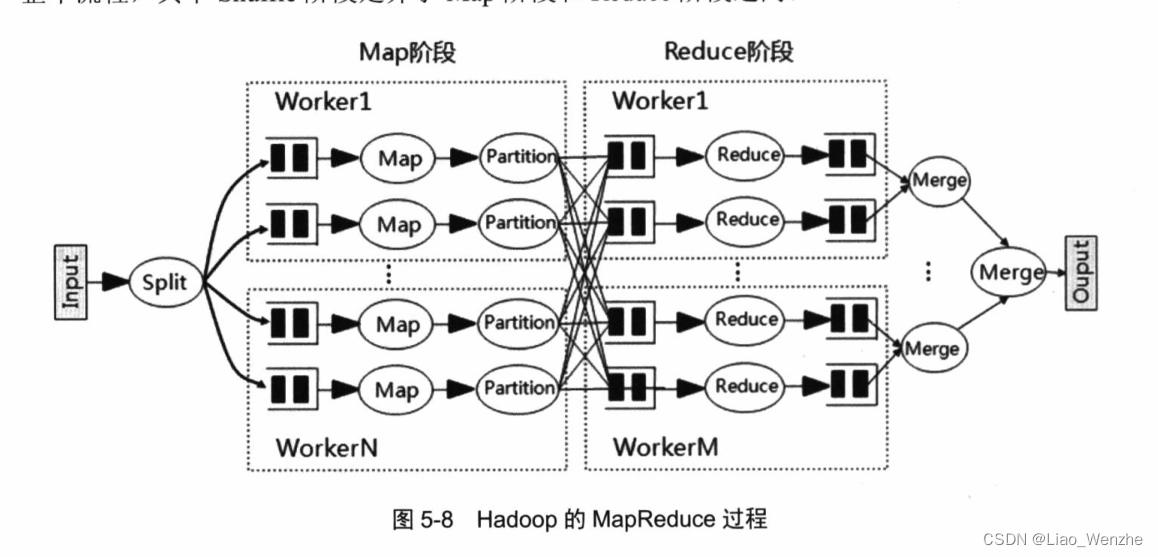
spark的shuffle1
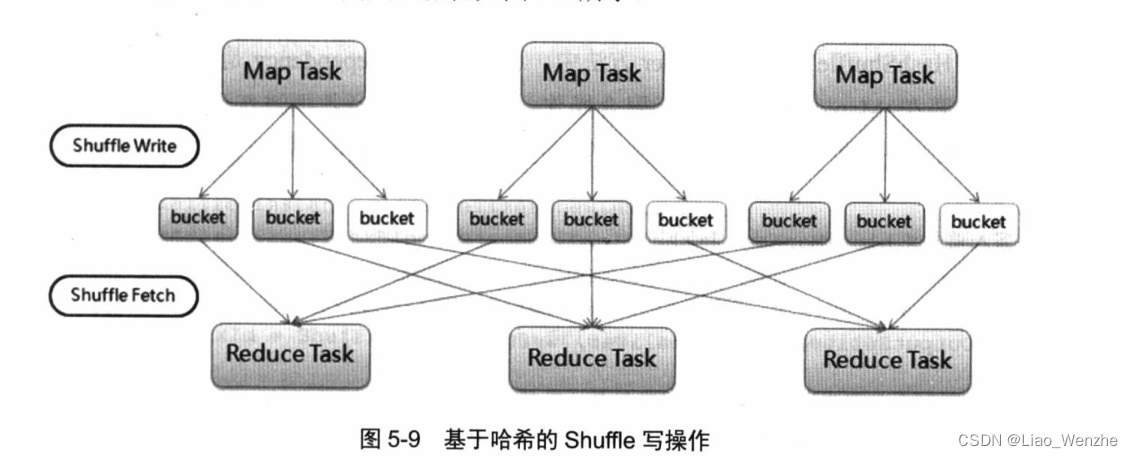
spark的shuffle2(默认)
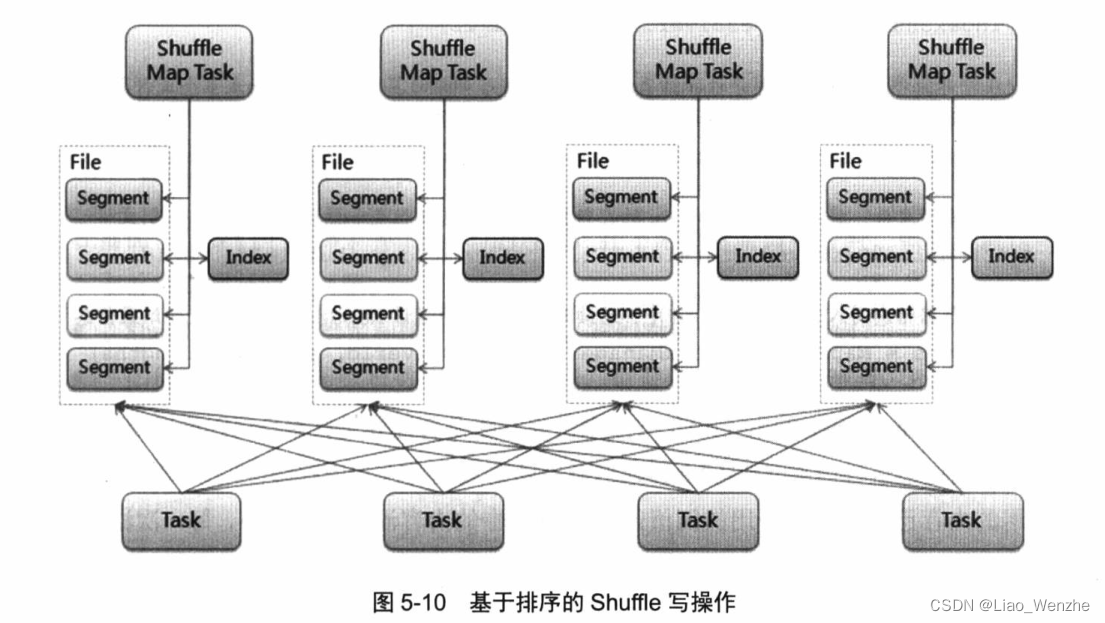
spark的shuffle在hadoop的shuffle上做了一些有益的迭代(比如shuffle排序上的一些改进)。
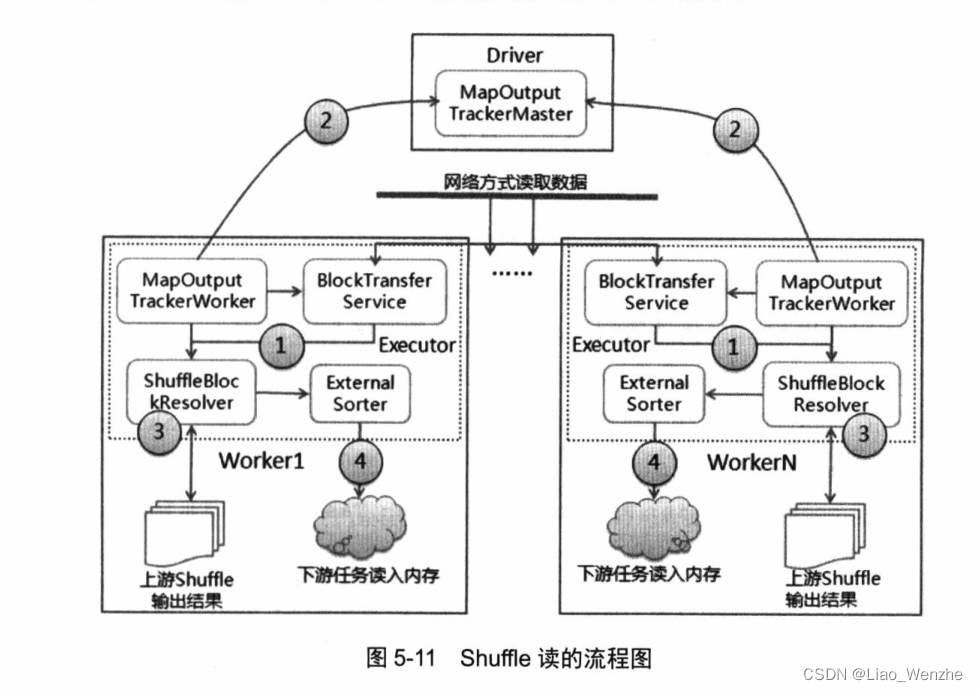
HIVE操作——把SQL编译成mapreduce程序运行。、
SPARKSQL——通过HQL,优化器等等API,转化成RDD计算。
RDD的一些action操作把全部或者部分RDD的集合或者值返回给驱动程序。
像collect就是把全部的值放到驱动器
reducebykey,就是在集群算完后返回一个值给驱动器。
foreach(func)就是在集群算完func函数后,返回结果。
hadoop的mapreduce必然伴随着shuffle。
spark.sql(group by)会触发spark_shuffle,因为底层是rdd
.collect.foreach(
)是在驱动器上运行的然后操作的。
普通数组的action操作会发到驱动器吗?
不会,本地操作。或者在集群算子里操作。
var myList = Array(1.9, 2.9, 3.4, 3.5)
对myList的操作没有实名懒惰机制一说,都是在本地运行的scala代码,不是spark。(除非算子里面)
引用外部变量不加collect没关系吗?没关系,因为是本地运行的scala代码,没有上传集群。
var coenblist: ListBuffer[Person] = new ListBuffer[Person]()
//这里的coenblist变量不是在驱动程序中定义的变量。
result.foreach(v =>{
val data = v._2.map(v => Person(v._1,v._2(0),v._2(1),v._2(2)))
data.foreach(line =>{
val cluster = line.cluster
val lng = line.lng
val lat = line.lat
val cell_tac = line.cell_tac
coenblist.append(new Person(cluster,lng,lat,cell_tac))
})
})
spark网页用户界面?
OK
sparksql的Join操作原理?
OK
四种join
hash join 最普通的join
shuffle hash join,broadcast hash join,sort merge join
shuffle hash join有shuffle,根据Key重新打散分区,把 小表分散掉,join.适合大小表关联。
broadcast hash join没有shuffle,把小表整张表放到涉及到的所有executor的内存里,Join,非常吃内存。适合大小表关联。
sort merge join 在shuffle hash join的基础上排序,查找性能有优势,适合大大表关联。
val list1 = ...
rdd1.map(list1...)
每个task都是不同分区的相同操作,都有完整的List1变量。表就不是这样了。
s"""
|select
| cluster
| ,lng
| ,lat
| ,types
| ,cell_tac
| from xxx left join aaa
在阶段1,分成很多个executor中的很多个task。
每个task拉取数据的时候,都是送给他整个表吗?
有好几种,不同情况不一样。广播是这样,其他应该是生成磁盘文件,然后shuffle通信。
那我广播AAA表不是把AAA表整张表放到所有相关的executor上了吗?
更占用内存了吧?
我觉得是,但是能避免数据倾斜。
一个filter算子是一个task吗?
看进行filter的rdd有几个分区。
一个stage会产生很多的task,不同的task是在不同分区上执行相同的操作。
比如阶段1有filter+map,每个task都执行者两个命令。
所以看数据分区。
一个sql是多少个task?
一个stage会产生很多的task,不同的task是在不同分区上执行相同的操作。
所以看数据分区。
输入和输出的分区都可以通过一定的参数调整。
df.createtempview(xxx)
brodecast(df.createtempview(xxx)
s"""
|select
| cluster
| ,lng
| ,lat
| ,types
| ,cell_tac
| from xxx
涉及到xxx的所有task都需要传输临时表吗?
每个task涉及到一部分的数据,所以所有task都传输其所需的部分数据。
表的缓存到哪个内存里?执行这条语句的executor内存里面。其他地方要用,就去这里取。
加了广播后的执行原理是什么?
原本task用到什么就传输给他什么数据,加入2个executor用到这些数据,当2个executor的第一个Task执行的时候,就现在先放到2个executor里面,后续的task直接在executor里面用。
共享变量与累加器
//广播变量和广播表
case class Transaction(id: Long, custId: Int ,itemId: Int )
case class TransactionDetail(id: Long, custName: String ,itemName: String )
val customerMap = Map(1 -> "Tom", 2 -> "Harry")
val itemMap = Map(1 -> "Razor", 2 -> "Blade")
val transactions = spark.sparkContext.parallelize(List(Transaction(1,1,1),Transaction(2,1,2)))
val bcCustomerMap = spark.sparkContext.broadcast(customerMap)
val bcItemMap = spark.sparkContext.broadcast(itemMap)
val TransactionDetails = transactions.map{t => TransactionDetail(t.id, bcCustomerMap.value(t.custId) ,bcItemMap.value(t.itemId))}
val TransactionDetails = transactions.map{t => TransactionDetail(t.id, customerMap(t.custId) ,itemMap(t.itemId))}
TransactionDetails.collect().foreach(println)
val customerMap = Map(1 -> "Tom", 2 -> "Harry")
val itemMap = Map(1 -> "Razor", 2 -> "Blade")
是在驱动端设置的变量,
val TransactionDetails = transactions.map{t => TransactionDetail(t.id, customerMap(t.custId) ,itemMap(t.itemId))}
executor端的的map算子用到了这两个驱动程序的变量,有多少个task就要发送多少遍。
val bcCustomerMap = spark.sparkContext.broadcast(customerMap)
val bcItemMap = spark.sparkContext.broadcast(itemMap)
是在驱动端设置的个广播变量,
val TransactionDetails = transactions.map{t => TransactionDetail(t.id, bcCustomerMap.value(t.custId) ,bcItemMap.value(t.itemId))}
executor端的的map算子用到了这两个驱动程序的广播变量,每个executor中的第一个task需要用到就发送过去,下面这个executor的 task就不用发给talked,直接让这些task调用executor上的广播变量即可。
val df = session
.read
.option("header", true)
.csv(path)
import org.apache.spark.sql.functions.broadcast
broadcast(df).createOrReplaceTempView(name)
当一个executor的第一个task用到这张表的时候,传给executor,这个executor后续的Task就不需要驱动程序传输过去给executor了。
//累加器
case class Customer(id: Long, name: String)
val customers = spark.sparkContext.parallelize(List(Customer(1, "Tom"),Customer(2, "Harry"),Customer(-1, "Paul")))
//var badIds = spark.sparkContext.longAccumulator("a")
var badIds = 0
val validCustomers = customers.filter(c => if (c.id <0) {
badIds += 1
//badIds.add(1)
false}
else true)
val hh=validCustomers.count()
println(badIds)
var badIds = 0是在驱动程序上定义的变量。
val validCustomers = customers.filter(c => if (c.id <0) {
badIds += 1
executor上的fileter算子无法更改其值。
var badIds = spark.sparkContext.longAccumulator("a")是在驱动程序上定义的累加器变量。
val validCustomers = customers.filter(c => if (c.id <0) {
badIds.add(1)
executor上的fileter算子可以更改驱动器的累加器。
mapPartition的高效实用。
有某些特定的转换或者操作方法(.reducebykey,.Groupbykey,sql中的Join)会引发shuffle,和action操作,这两类操作生成stage。
shuffle就是一个洗牌的过程,没有洗牌的过程就没有shuffle,就没有划分stage。(action也会划分stage)
有时候可以让shuffle算子不产生shuffle,有时候可以增加shuffle。
groupbykey的使用。会产生shuffle。
为什么sparksql里的groupby不产生shuffle?在原来的分区里操作。大部分情况下回产生shuffle的
让shuffle算子不产生shuffle什么意思?就像Coacluse不会产生shuffle一样。
工作问题记录Author: 廖文哲 |
spark with tab1 as 有吗?spark_hive_sql可以,普通的Hive不行。
为什么spark_sql不能用取数?加了个local。
spark_sql里的group by 会引起spark_shuffle吗?会。
.write.会涉及到RDD吗?会,dataframe的底层是rdd
Hadoop&&SparkSourceURL: Spark性能优化:资源调优篇_铭霏的博客-CSDN博客 Author: 廖文哲 |
#这里的foreach并不会让rdd.mapPartitions代码运行。变量的foreach,
val pingPangRDD = spark.sql("select * from zqtest_t_ho_list ").rdd.mapPartitions(iter => {
val result = ArrayBuffer[Row]()
val rows = iter.toArray
// findChild("", "", "", "", result, iter.toArray)
rows.foreach(row => {
val imsi = row.getAs[String]("imsi")
val src = row.getAs[String]("dest")
}
RDD和dataframe的foreach也是一个action方法
#RDD和DATAFRAME的spark的转换和操作算子里面调用外部变量只是一个副本,出去就没了。
可以用map返回一个值
或者用collect方法将集群中的数据放到驱动器里面去处理。
hc.read.option("header",true).csv(fileName).
foreach(row => {
var vector = Vector[Double]()
vector ++= Vector(row.getAs("longitude").toString.toDouble)
points.append(vector)
})
区分spark_shuffle和hadpoop_map_shuffle_reduce。hive 的where也会执行hadpoop_map_shuffle_reduce。
对形参的操作会影响实参
stage根据spark_shuffle划分stage。
spark_shuffle类算子和action算子会触发spark_shuffle。
spark_shuffle类算子包括.join,reducebykey等等方法。
action算子导致懒惰机制失效。
shuffle算子引发shuffle.
action和shuffle算子会生成stage。
sparkshuffle的改进:涉及到很多参数,可以改进传输效率,中间文件结果等,注意与join之间的区别,join会引起shuffle。
原始的 Hash-Shuffle 所产生的小文件: Mapper 端 Task 的个数 x Reduce 端 Task 的数量
Consolidated Hash-Shuffle 所产生的小文件: CPU Cores 的个数 x Reduce 端 Task 的数量
dataFrame和sparkSql的shuffle算子可以设置spark.sql.shuffle.partitions参数控制shuffle_reduce的并发度,默认为200。reduce才会受影响。
rdd的shuffle算子可以设置spark.default.parallelism控制并发度,默认参数由不同的Cluster Manager控制。map&reduce都会受影响。默认task很低。
| /data/spark-2.1.1/bin/spark-submit --master yarn --deploy-mode client --driver-memory 5g --driver-cores 5 --executor-memory 8g --executor-cores 8 --num-executors 100 --conf spark.default.parallelism=2000 --conf spark.shuffle.memoryFraction=0.8 ./zhongdainapp_2.jar | containers=83, 核心=657 内存=750G | 4分钟1950个task |
| /data/spark-2.1.1/bin/spark-submit --master yarn --deploy-mode client --driver-memory 5g --driver-cores 5 --executor-memory 16g --executor-cores 16 --num-executors 100 --conf spark.default.parallelism=4000 --conf spark.shuffle.memoryFraction=0.8 ./zhongdainapp_2.jar | containers=42, 核心=657 内存=750G | 4分钟1522个task |
| /data/spark-2.1.1/bin/spark-submit --master yarn --deploy-mode client --driver-memory 5g --driver-cores 5 --executor-memory 8g --executor-cores 8 --num-executors 100 --conf spark.default.parallelism=500 --conf spark.shuffle.memoryFraction=0.8 ./zhongdainapp_2.jar | containers=88, 核心=697 内存=800G | 4分钟1800个task |
| /data/spark-2.1.1/bin/spark-submit --master yarn --deploy-mode client --driver-memory 5g --driver-cores 5 --executor-memory 8g --executor-cores 8 --num-executors 100 --conf spark.default.parallelism=10 --conf spark.shuffle.memoryFraction=0.8 ./zhongdainapp_2.jar | containers=88, 核心=697 内存=801G | 4分钟1800个task |
| /data/spark-2.1.1/bin/spark-submit --master yarn --deploy-mode client --driver-memory 5g --driver-cores 5 --executor-memory 8g --executor-cores 8 --num-executors 100 --conf spark.default.parallelism=10 --conf spark.shuffle.memoryFraction=0.1 ./zhongdinapp_2.jar | containers=88, 核心=697 内存=802G | 4分钟1816个task |
RDD,Dataframe与DataSet的区别,以及什么时候用?
RDD一般操作够了,相当于python的numpy。
Daframe在用到数据库操作的时候用到,相当于python的pandas。
daframe是DataSet[Row],每一行的类型是row,不知道每一列的类型,而普通的dataset直接知道每一列的类型,可以类RDD操作的Dataframe.相当于numpy和pandas的结合。
什么情况下会产生shuffle:shuffle算子。
怎么划分stage:shuffle和action算子。
Spark性能调优作者: 廖文哲 |
Spark性能优化:资源调优篇_铭霏的博客-CSDN博客
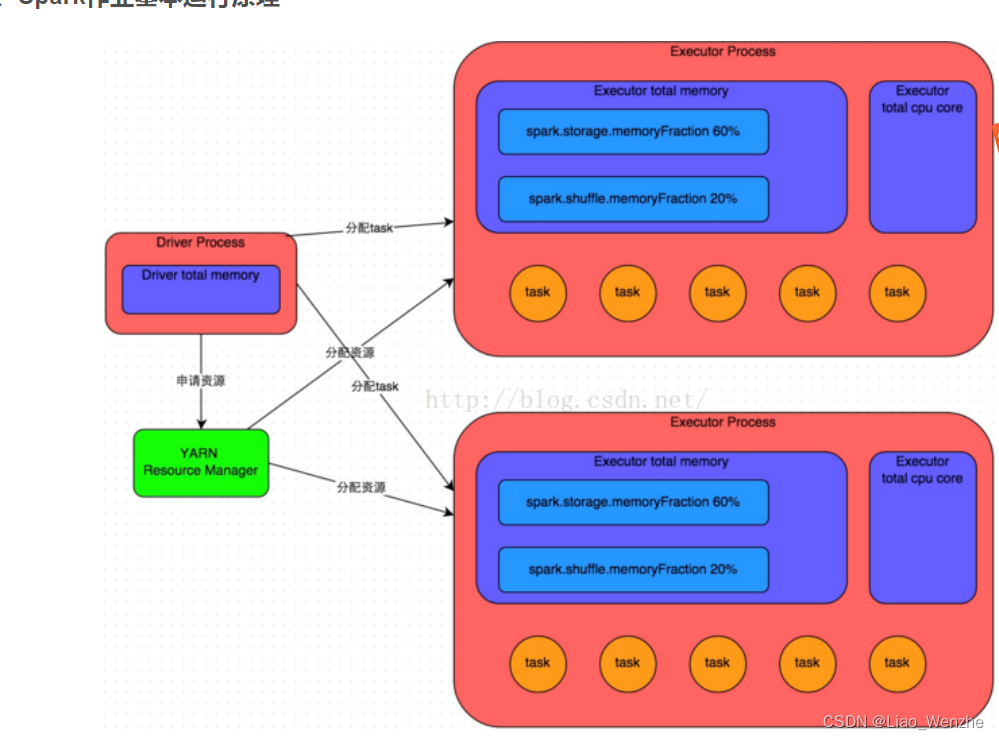
1.性能调优的核心:CPU,FREE,IO,网络,shuffle。
2.
我的质差距类算法代码的执行顺序:
在本地驱动器运行代码,根据shuffle和action算子 将任务分成不同的stage,每个stage有很多task。
根据spark-submit分配资源,每个集群节点上上运行一些executor,每个executor分配到一些task.一个task一个线程。每个job重复使用这些executor>
驱动器与executor沟通,分配task给executor。
驱动器与控制器沟通,调配资源。
驱动器,控制器与executor之间一起通信。
3.巧用cache。某个RDD和表经常用的时候cache,cache会在某些executor上缓存。
4.shuffle算子少用。很慢。
5.使用到很大的外部变量的时候使用广播变量,或者使用广播取代小表大表的Join。(从每一个涉及到的task都会接受变量到每一个涉及到的executor都接受变量,表的话每个executor都放一张表的确占内存,但是比通信传输各种要快很多,比如join操作,会引发shuffle,如果用到表a,并不是在每个Task都放表A,而是shuffle通信,分区数据洗牌)
6. 使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子,有一些本地运算,减少了远程传输计算成本。
7. mapPartitions替代普通map,foreachPartitions代替foreach.
8.使用filter之后进行coalesce操作以减少partition,降低task。因为数据量变少了。每个task数据量多的话,减少分区。
9.使用repartitionAndSortWithinPartitions替代repartition与sort类操作。
10.使用更好的序列化(集群间的数据传输,自定义类型比如student,序列化cacheRDD等等会用到)
11.优化数据结构,比如用Long取代字符串。
12.数据倾斜的处理方法:
a.想尽一切办法处理数据中的有问题的key。
b.通过设置 spark.sql.shuffle.partitions来增加DataFrame_shuffle_reduce的task。从而使那些大的task被分摊掉。reduce的task默认是200。spark.default.parallelism也可以调优。
13.shuffle调优,更改有关shuffle的参数。
14.代码层面的优化。
15.spark_submit层面的优化。
spark企业级实战作者: 廖文哲 |
1.scala运行于JVM之上,能跟java完美兼容,是spark框架的开发语言,面向对象,spark上还可以用python,java这些,但是scala支持的最好,支持函数式和面向对象编程。
2.面向过程,函数式,面向对象编程的区别。
流量预测就是面向过程。
质差距类就是面向过程+函数式。
之前开发的桶装水系统就是面向对象。
3.SPARK是一个大数据分布式处理框架。
4.hadoop衰落,spark崛起。
5. 合适的Task对于SparkSQL,是一个比较重要的参数,就是shuffle时候的Task数量,通过spark.sql.shuffle.partitions来调节。(没有shuffle的就调不了,只能调输出的,输入的应该在配置文件里弄了)调节的基础是spark集群的处理能力和要处理的数据量,一个partition一个task。Task过多,会产生很多的任务启动开销,如果数据量不大,每个分区数据量不大,浪费。Task太少,每个Task的处理时间过长。
6.spark-submit --master yarn --deploy-mode client --driver-memory 10g --driver-cores 5 --executor-memory 8g --executor-cores 8 --num-executors 100 zcjl.jar
--master yarn-cluster 表示是yarn集群
--deploy-mode client 驱动器在本地和运行,master 表示在集群的一台服务器上运行,质差聚类要是这样可能会快。
--driver-memory 10g 驱动程序占用多大内存。像collect就会用到这个,比如本地计算,变量声明。
--driver-cores 5 驱动器占用多大核心。
--num-executors 50 一般设80到100.
--executor-memory 2g 与num-executors相乘在不影响其他程序的情况下占用集群内存资源的1/3到1/2,一般4-8G
--executor-cores 4与num-executors相乘在不影响其他程序的情况下占用集群CPU核心资源的1/3到1/2 ,一般2-4核
--name liaowenzhe 在spark网址上显示程序的名字。
--conf spark.default. parallelism=500 num-executors * executor-cores的2~3倍较为合适
-conf spark.storage.memoryFraction=0.5 rdd持久化task占用executor的最大内存百分比
--conf spark.shuffle.memoryFraction=0.3 shufflede task占用executor的最大内存百分比
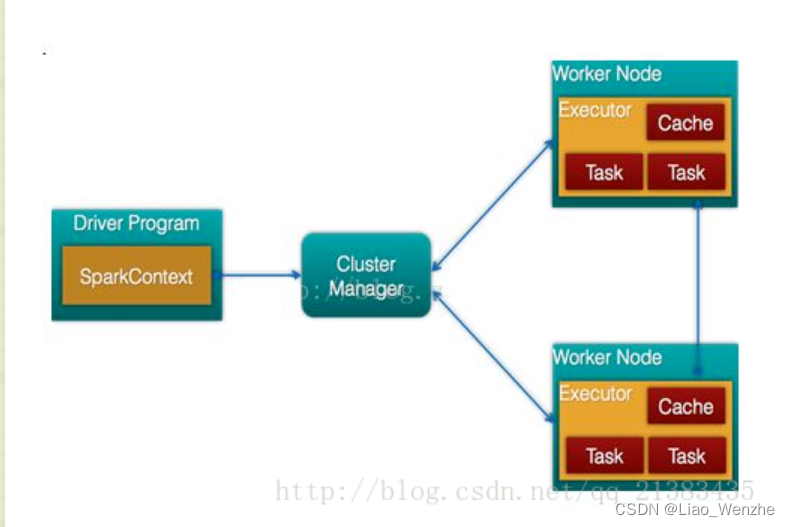
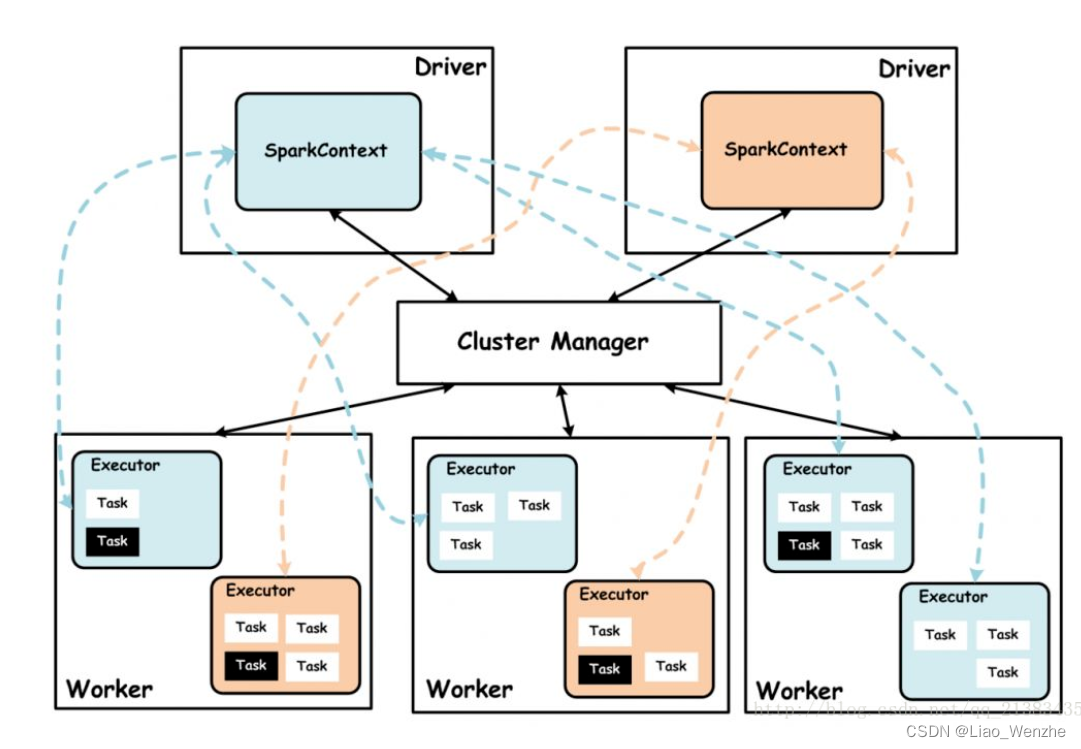
Hadoop命令行安装手册.docx作者: 廖文哲 |
Spark快速大数据分析作者: 13253595285@163.com |
1.Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。这三大优点也使得 Spark 可以作为学习大数据的一个很好的起点。
spark-submit 参数设置说明_u013063153的博客-CSDN博客
1.对于驱动器,管理器和执行器的理解。

1.驱动器:与clusterManager和worker进行通信,发配和结束任务:spark_submit,spark_stop和Main函数的结束。对应宁波项目的115,以及进行本地计算。
2.clusterManager:在yarn中是yarnManage,可以是单独的服务器,也可以与worker运行在一起,负责资源调度。对应宁波项目的一台saprk集群服务器上的一个程序。
3.workNode:具体任务的执行。对应宁波项目的spark集群的一台服务器。
Spark大数据处理:技术、应用与性能优化(1).pdf作者: 廖文哲 |
scala编程作者: 廖文哲 |
1.scala> def max2(x: Int, y: Int) = if (x > y) x else y
2.scala> def max(x: Int, y: Int): Int = {
if (x > y) x
else y
}
3、val 类似于 Java 里的 final 变量。一旦初始化了, val 就不能再赋值了。与之对应的, var 如同 Java 里面的非 final 变量。 var 可以在它生命周期中被多次赋值。
4、
5.
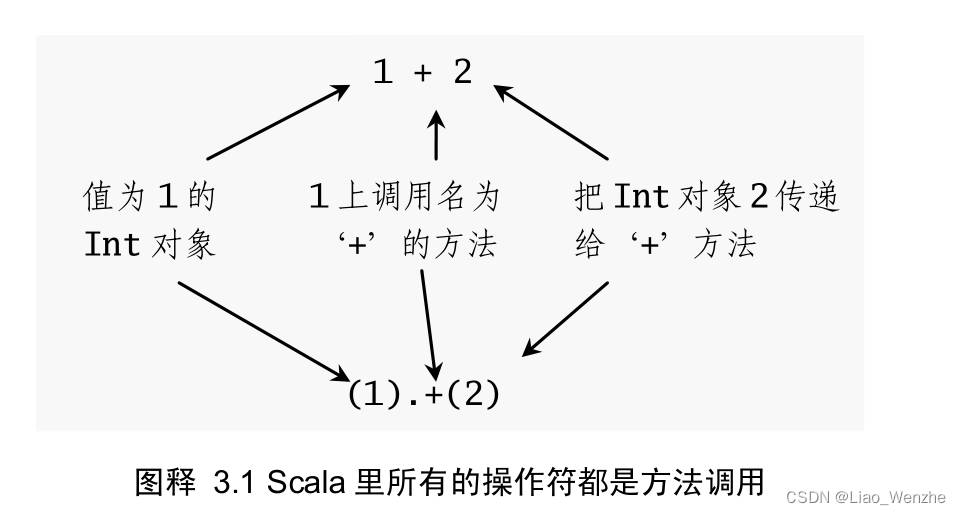
6.因此向函数式风格推进的一个方式,就是尝试不用任何 var 编程。
7.然而在 Scala 看来, val 和 var 只不过是你工具箱里两种不同的工具。
8.Scala 鼓励函数式风格的原因,实际上也就是因为函数式风格可以帮助你写出更易读懂,更不容易犯错的代码。
9.类和单例对象间的一个差别是,单例对象不带参数,而类可以。因为你不能用 new 关键字实例化一个单例对象,
OBJECT中集合了很多静态方法,比如MAIN。而class就没有,所以用object。
总结:
1.相比C,java的指令风格,更加简单,不易错的函数式风格。这种编程风格可以了解一下。
2.val与var。
3.其他的与java类似。
4.面向过程,面向函数,面向对象编程。
hadoop作者: 13253595285@163.com |
1.apache hadoop是一个框架。用于对大数据集进行分布式处理。包括一整个生态系统。hadoop解决了大数据的可靠存储和处理。
2.apache spark是专为大规模数据处理而设计的计算引擎。对hadoop的map_reduce的某些方面做了改进。
3.hadoop生态圈中yarn负责资源的调度。
mapReduce负责计算,比如hive_sql转化为mapreduce计算
hive,一个组件,提供类SQL语句操作HDFS 数据。
hdfs:hadoop的数据都存储在这里。
MAPREDUCE:找到气象数据中1949年和1950年中气温最大值。
分区hdfs数据一行一行输入-map(根据键值对列出1949,1950年的所有气象温度吗,中间结果写入本地磁盘)-shuffle-reduce(找出每年最大气象温度,写入hdfs上)。
比普通的用awk多线程实现要快很多。
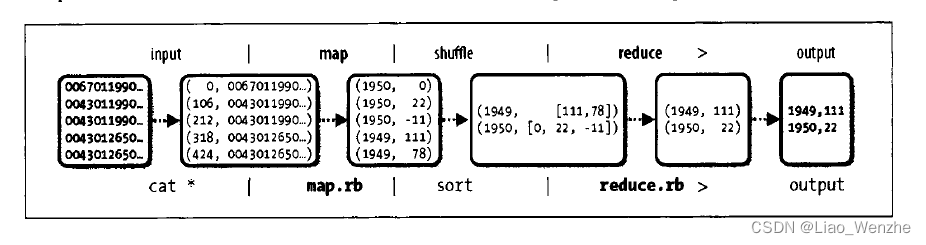

HBASE:低时间延迟,HDFS:应对高数据吞吐量而优化的,就算小数据,时间延迟可能会很大。
HDFS以64MB为一个基本的存储单位,所有的分区之类的,都是其整数倍。
HDFS 分布式存储:机架,就近传输,3重备份等等等等。