数据结构————堆
目录
二叉树
满二叉树和完全二叉树
堆
建堆
堆排序
topK问题:
二叉树
在介绍堆之前我们来简单铺垫一下,说一下二叉树。
树的相关概念在之前的博客里面已经介绍过了,详情可以看下我之前写的树的博客。
数据结构——树_SAKURAjinx的博客-CSDN博客
二叉树属于树的一种,在实际应用中占据了相当重的一块分量,无论大厂中厂都喜欢考察这一块知识。二叉树顾名思义,它的每一个根都最多只有两个分支,也可能是一个或没有。

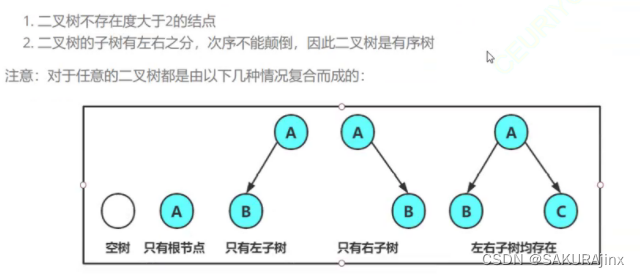
二叉树的基本的基本构成如上所述,二叉树里面又有两种特殊的情况:满二叉树和完全二叉树。
满二叉树和完全二叉树
满二叉树就是二叉树的每个根都有两个分支,每一层都是满的。
假设满二叉树有K层,那么它的节点一共有2^k-1个。
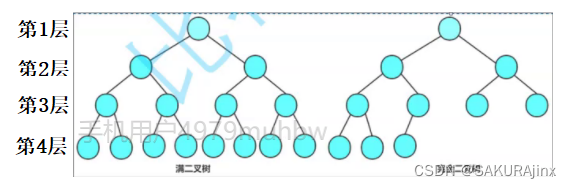
完全二叉树是假设有K层,那么K-1层都是满的,最后的K层可以不满(也可以满),但从左到右一定是连续的,这种就是完全二叉树(满二叉树是完全二叉树的一种)。
完全二叉树是一种效率很高的数据结构,它的节点个数区间为 [ 2^(k-1) , 2^k-1 ] 。
堆
了解了完全二叉树,就可以介绍堆了,堆是完全二叉树。
注意:和栈以及队列一样,这里的堆是数据结构,不要和内存区域划分那边的堆搞混了。

堆存储的逻辑结构是刚刚介绍的完全二叉树,但是它的物理结构是数组,也就是说它逻辑上的二叉树的结构、形式,其实是通过数组来实现的,看上去是数组,其实画图展开就是二叉树。
堆又分小根堆和大根堆,小根堆如上图所示,它的孩子节点>=父亲节点,大根堆正好相反。
从结构上来看,小根堆的堆顶存的是最小的数,大根堆的堆顶存的是最大的数。因此,堆就有两个基本应用:堆排序和topK问题的解决。
堆排序:时间复杂度度O(logN*N),远超冒泡、选择等基础排序。效率很高。
topK问题:从一组数据中选出较大的K个数。
向我们平时使用饿了么、美团消费,推荐店铺的前K名,就是用的类似的方法解决的。
这两个应用我们之后再讲解,先来学习一下如何建堆。
建堆
Heap.h 头文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<errno.h>
#include<stdbool.h>
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;
void HeapInit(HP* php);
void HeapDestory(HP* php);
void HeapPrint(HP* php);
void HeapPush(HP* php, HPDataType x);
void HeapPop(HP* php);
bool HeapEmpty(HP* php);
HPDataType HeapTop(HP* php);
int HeapSize(HP* php);Heap.c 实现接口
#include"Heap.h"
void HeapInit(HP* php)
{
assert(php);
php->a = NULL;
php->size = php->capacity = 0;
}
void HeapDestory(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}
void HeapPrint(HP* php)
{
assert(php);
for (int i = 0; i < php->size; ++i)
{
printf("%d ", php->a[i]);
}
printf("\n");
}
void swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void AdjustDown(HPDataType* a, int n,int parent)
{
int minchild = parent * 2 + 1;
while (minchild < n)
{
if (minchild + 1 < n && a[minchild] > a[minchild + 1])
{
minchild++;
}
if (a[minchild] < a[parent])
{
swap(&a[minchild], &a[parent]);
parent = minchild;
minchild = parent * 2 + 1;
}
else
break;
}
}
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
perror("tmp fail");
exit(-1);
}
php->capacity = newcapacity;
php->a = tmp;
}
php->a[php->size] = x;
php->size++;
AdjustUp(php->a, php->size - 1);
}
void HeapPop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
swap(&php->a[0], &php->a[php->size-1]);
php->size--;
AdjustDown(php->a, php->size, 0);
}
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
HPDataType HeapTop(HP* php)
{
assert(php);
return php->a[0];
}
int HeapSize(HP* php)
{
assert(php);
return php->size;
}Test.c 测试接口
#include"Heap.h"
void Test1()
{
int a[] = { 15,18,19,25,28,34,65,49,27,37,10 };
HP hp;
HeapInit(&hp);
for (int i = 0; i < sizeof(a) / sizeof(a[0]); ++i)
{
HeapPush(&hp, a[i]);
}
HeapPrint(&hp);
if (HeapEmpty(&hp))
printf("YES\n");
else
printf("NO\n");
printf("%d\n",HeapSize(&hp));
printf("%d\n",HeapTop(&hp));
HeapDestory(&hp);
}
void Test2()
{
int a[] = { 15,18,19,25,28,34,65,49,27,37,10 };
HP hp;
HeapInit(&hp);
for (int i = 0; i < sizeof(a) / sizeof(a[0]); ++i)
{
HeapPush(&hp, a[i]);
}
HeapPrint(&hp);
HeapPop(&hp);
HeapPop(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapDestory(&hp);
}
int main()
{
//Test1();
Test2();
return 0;
}这里建堆我用了向上调整建堆AdjustUp, 删除堆顶数据用的是向下调整AdjustDown的逻辑,传参时没有直接传定义的结构体php,而是独立出来用数组和整型变量接收,方便后面堆排序单独使用这两个接口。具体请参考上述代码。
堆排序
实现堆排序之前需要先写一个堆出来吗?————没有必要,如果需要先实现一个堆就太过麻烦了,而且这种方式空间复杂度就变成了O(N),原本只需要在数组中选数,现在将数据传入堆里,需要开辟额外空间。所以我们上面将向上调整 AdjustUp 和向下调整 AdjustDown 接口给独立出来,方便现在使用。
在没有堆的情况下,给一个数组,要将里面的数据堆排序,我们需要模拟建堆的情况,先将数组建堆,然后进行排序。
这里有两种思路:
一、向上调整模拟建堆
void HeapSortUp(int* a, int n)
{
for (int i = 1; i < n; ++i)
{
AdjustUp(a, i);
}
}
int main()
{
int a[] = { 6,2,5,4,13,7,9,16,56 };
int n = sizeof(a) / sizeof(a[0]);
HeapSortUp(a, n);
int i = 0;
for (i = 0; i < n; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}这种建堆方式时间复杂度是O(N*logN)
二、向下调整模拟建堆
void HeapSortDown(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
}
int main()
{
int a[] = { 6,2,5,4,13,7,9,16,56 };
int n = sizeof(a) / sizeof(a[0]);
int i = 0;
HeapSortDown(a, n);
for (i = 0; i < n; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}这种方式时间复杂度是O(N)。
所以建堆的时候一般选用向下调整建堆的方法。
证明时间复杂度:
向下调整:

向上调整:

与向下调整一样,这里就不算了,其实很容易想,二叉树越往下节点越多,最后一层就占了一半,向下调整最后一层调整h-1次,比向上调整多了太多,因此时间复杂度大。
完成模拟建堆后,就是进行排序了,这里有个非常关键的点:如果要排成升序,是建大堆还是建小堆?降序又如何呢?
这是个非常容易出错的点,可能大家会觉得要排升序,小的数在前面,那就建小堆,降序大的数在前面,那就建大堆,其实恰恰相反,升序是建大堆,降序是建小堆。
我来证明一下:以升序为例,假设数组是这样的:2,4,5,6,13,7,9,16,56
模拟建成小堆: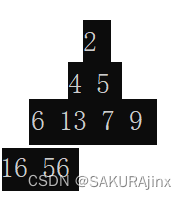
这时选出次小的数4,堆的形态就发生了变化: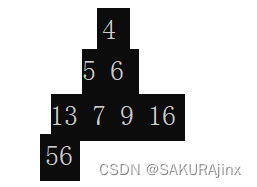
本来4和5是兄弟,现在成了父子,关系全乱了,此时只能重新建堆选数,那么堆排序就没有任何意义了。因此得反过来建大堆。
模拟建成大堆:
这时将堆顶的数56 和最后一个数2 交换,然后不算最后一个数56,向下调整选出次大的(在堆顶),再重复上面操作,就能排出升序了,实际上就是倒着将数组排出来,降序也一样。
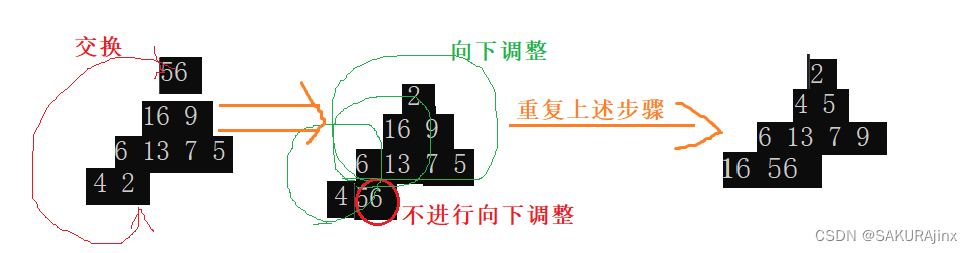
代码如下:
typedef int HPDataType;
void AdjustDown(HPDataType* a, int n, int parent)
{
int minchild = parent * 2 + 1;
while (minchild < n)
{
if (minchild + 1 < n && a[minchild] < a[minchild + 1])
{
minchild++;
}
if (a[minchild] > a[parent])
{
swap(&a[minchild], &a[parent]);
parent = minchild;
minchild = parent * 2 + 1;
}
else
break;
}
}
void HeapSortDown(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
int i = 1;
while (i < n)
{
swap(&a[0], &a[n - i]);
AdjustDown(a, n-i, 0);
i++;
}
}
int main()
{
int a[] = { 6,2,5,4,13,7,9,16,56 };
int n = sizeof(a) / sizeof(a[0]);
int i = 0;
HeapSortDown(a, n);
for (i = 0; i < n; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
降序也一样,改下建小堆就可以了。
topK问题:
在个数为N的数组中选出前K大的数,这里用堆排或者快排时间复杂度是O(N*logN),有点浪费。
这里有两种思路:
一、如果有堆的话,直接popK次选出前K大的数。如果没有,先对这N个数建大堆,和上面堆排方式一样,将堆顶的数和最后一个交换,排除最后一个数向下调整,K次就能选出前K大的数。时间复杂度是O(N+logN*K)。(建堆是O(N))
这种方法有一个问题,就是N很大,远比K的时候就不行。如果N是100亿,建堆的时候占用的内存就过大了,而且不能分别存进内存,这样就不能选出前K大的数了。
二、为了避免上述方法的问题,我们可以建小堆。先对前K个数建小堆,再遍历后N-K个数,如果比堆顶的数大,就将堆顶的数替换出来,最后堆里面就是前K大的数。
时间复杂度O(K+logK*(N-K)),差不多是O(N)这个量级的,空间复杂度是O(K)