计算机组成原理第二章----数据信息的表示 详解版(写的这么接地气我一下就懂了?)
首先把原码、反码、补码的基本定义解释一下,然后补充为什么计算机采用补码运算,以及补码的优势。原码、反码、补码之间转换的规律。
一、数值数据表示
刚开始接触机器数时,你应该和我一样也很懵,什么原码反码又补码的,计算机底层把程序转换成01代码不就好了,为啥要弄出来这么多奇奇怪怪的麻烦呢?但是你想啊,计算机底层只认0,1代码,他在做01代码的运算时只有加运算,那遇到减运算怎么办?而且还牵扯到符号问题,他不像人类大脑能思考:+为加,-为减。但是补码的模运算特性能解决这一问题,比方说,时钟从2点到4点,你可以顺时针转到4点(+2格),也可以逆时针转到4点(-10格),因为时钟是以12为模的,结果都是相同的到达了4点,补码也有这种特性,但原码、反码没有,刚说过计算机就能做加法运算,那只能把减一个数变成加一个负数,补码刚好能做到,这不就像时钟一样,不论是+2还是-10都能转到正确的结果4点。不仅如此,原码、反码都有两个‘0’(后面具体会说到),在计算时用哪个‘0’?也会乱套的,补码只有唯一的‘0’能完美解决这个问题。
看到这心里有没有稍微有点谱了?学习不是一蹴而就的,唯手熟尔,而且一个知识点你至少要了解它的原理,慢慢才能吃透,要不就像摸瞎走路。一遍复一遍,其义自见,加油![]()

1、数的机器码表示
(1)原码
原码就是符号化的数值。在计算机底层,低电平代表0高电平代表1,这同样能用作数值中区分数值的正负。带“+” “-”的二进制数称真值(+10011),将真值符号用0、1编码表示的成为机器数或机器码(0,10011逗号将符号位和数值为分开)
机器码:原码、补码、反码、移码(机器码是将‘+’、‘-’转换成‘0’、‘1’之后的)
如:x=+0.1101 则[x]原=0.1101(x为小数)
x=+1101 则[x]原=0,1101
x=-1111 则[x]原=1,1111

以上边这个整数的真值→原码转换为例直观解释一下这个公式 ↑ (每次都不喜欢这种公式,不知道咋推导的,也不理解都是啥意思,不喜欢也得啃啊)
(真值就是带±号,还没把±变成0,1的时候)当真值x≥0时,只需要在真值前面把‘+’换成0作为符号位就行了,当x≤0时,举例:x=-1111,则按照上边公式,n=4(真值有4位)2^4 - (-1111)=2^4 + 1111 (因为x为-),2^4=10000 综上2^4 - (-1111)=10000 + 1111=11111
2^n - x 等价于 2^n +|x|

(2)反码
顾名思义就是原码取反。反码又称1的补码,其符号位和原码相同,真值为正数时,反码原码相同,真值为负数时,原码的数值位按位取反就是反码。
x=+0.1101 则[x]反=0.1101(标蓝是符号位)
x=-0.1111 则[x]反=1.0000
x=+1101 则[x]反=01101
x=-1111 则[x]反=10000


(3)补码
原码和反码在运算过程中在遇到减法运算时都会很复杂,如果能把减法运算变换成加法运算就能很好解决这个问题,补码就可以,它相当于时钟中6到3,可以顺时针转9(即+9)也可以逆时针转3(即-3)补码就是应用这个道理。
补码的定义:计算机中的二进制数据都有字长的限制,数据最高位进位的权值就是模数,运算结果超过模数的部分都会被自动舍弃,所以非常适合采用补码进行表示和运算,而且0的补码有唯一的表示方法。
x≥0时,补码等于真值,x≤0时,真值加上模数就是补码。


求补码有三种方法:
1、利用真值加上模数得补码,但这个方法比较麻烦,略过。
2、反码法
当x≤0时,符号位为1,补码数据位等于真值数据位按位取反,末位加一。
x=-1000 ,x[原]=11000 则[x]补 =10111+0001=11000
x=-0001 ,x[原]=10001 则[x]补 =11110+0001=11111
x=-0.0001, x[原]=1.0001 则[x]补 =1.1110+0.0001=1.1111
3、扫描法
当x≤0时,符号位为1,对真值数据位从右到左顺序扫描,右起第一个1及其右边的0保持不变,其余各位求反。
补码变成原码:把补码除符号位外取反再+1
(4)移码
移码只用于定点数的表示,通常用于表示浮点数的阶码(阶码都为整数)。补码很难直接判断真值大小,但移码可以很容易分辨出大小。
两数移码的加减等于两数加减后表示成补码


移码和补码比较:

(4)原码反码补码转换真值:原码第一位为符号位,其他位根据权值相加得出对应十进制数值。
反码、补码如果为正数则和原码同理,如果为负数,要先把反码、补码转换成对应的原码之后在根据权值相加得出对应十进制的结果。
2、定点数表示
(1)定点小数:
符号位Xs用来表示数的正负,小数点的位置是固定的,在计算机中并不用去表示它。X1~Xn 是数值的有效部分,也称为尾数,X1为最高有效位,定点小数主要用于表示浮点数的尾数。

(2)定点整数:

3、浮点数表示
- 浮点数介绍
浮点数中的小数点位置不固定,也就是小数点位置可以浮动,这也是浮点数得名的原因,为
了扩大浮点数的表示范围和提高表示精度,二进制浮点数采用了类似十进制科学计数法的表示方法。比如要表示3 x 10^30 这个数,或者0.000000000001在用二进制表示时会很麻烦,而且可能位数还不够,浮点数表示形式能解决。
图一:

任意一个二进制数N都可以表示成如下形式:
![]()
采用这种方法,二进制浮点数可表示成阶码E和尾数M两部分,其中阶码E是定点整数,尾数M是定点小数。阶码的位数决定数据表示的范围,阶码位数越多表示的数据范围就越大,而阶码的值决定了小数点的位置,尾数的位数决定数据表示的精度。
- 浮点数的规格化
同一个浮点数如果采用上图一的浮点数格式,可能存在多种表示形式,0.01111 x 2^101 还可以表示成0.11110 x 2^100 尾数小数点的位置不同,就会有不同的尾数和阶码组合,因此要将浮点数在数据表示时对尾数进行规格化处理,就是使得尾数真值最高有效位为1,也就是尾数的绝对值应大于或等于(0.1)二进制。也就是十进制下的0.5
比如0.10110 按照规格化移位(尾数最高有效位要为1)需要右移一位 0.10110=1.0110 *2^ -1
每个浮点数都会按照要求规格化,那么就是每个尾数都是1.M的形式,(这样能够避免0浪费存储位置)无须单独表示最高有效位上的1,需要进行数据运算时在恢复最高有效位的表示,被隐藏的一位又称隐藏位。
- IEEE7754浮点数标准
上述的浮点数一般格式中,既没有规定阶码个尾数的位数,也么有规定阶码和尾数采用的机器码形式,IEEE754标准根据精度不同S、E、M位数的标准

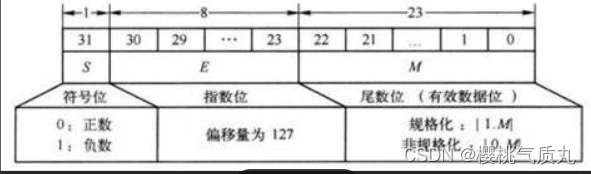
S是数符、E是阶码 M是尾数
其中,E阶码位采用移码表示而且偏移量是127不是128,采用127偏移量的最主要原因是使得任何一个规格化数的倒数能用另一个浮点数表示,而采用128偏移量表示的最小规格化数的倒数会发生溢出。
M尾数是原码表示。
- 例题将十进制数20.59375转换成IEEE754单精度浮点数的十六进制机器码
首先把20.59375转换成机器码,整数部分转换成二进制 除2取余,最后把余数倒序排列,小数转换二进制 乘2取整,剩余小数继续乘2,取出整数正序排列。
20.59375=10100.10011
移动小数点,尾数规格化变成1.M的格式
1.010010011 x 2^4
可得:
S=0(正数) ,E=e+127=4+127=131=10000011 ,M=010010011
最后得到32位浮点数的二进制存储格式为(同样颜色的一一对应)
0100 0001 1010 0100 1100 0000 0000 0000=41A4C000 4位二进制代表一位16进制,所以4个一组对应一个16进制。
如有疑问欢迎交流,并反复阅读。
二、非数值数据表示
书本上有很多关于非数值字符、汉字的讲述。但没说到数位的扩展与压缩,第一章课后题有涉及到,真是如同看天书,在前面翻也翻不到,看这题多少有点为难人......
- 数位的扩展与压缩
(1)符号扩展
扩展一般都是短位扩展成长位,压缩是长变短
直接把符号位(0/1)填充到扩展位
000A→0000000A
从000A可以看出是16进制数,4位二进制代表一位16进制数,000A其实是(4x4)16个01代码
16位扩展成32位,000A要增加到8位(4x8)而000A只有4位,要在其前面填充符号位,也就是填充4个0
800A→FFFF800A
为啥补F呢? 这个8是4个二进制组成的1000,那第一位符号位就是1,所以补的4个1111,在16进制中1111就是F,所以是4个F
(2)0-扩展 高位均全补0(针对无符号数)
002A→ 0000002A
F12C→0000F12C
(3)位数压缩 :弃高位、留低位
F12B800A→800A
02A0F12C→F12C