在Adult数据集上使用pandas进行独热编码,之后部署Logistic Reggresion模型
Adult数据集
adult 数据集的任务是预测一名工人的收入是高于 50 000 美元还是低于 50 000 美元。这个数据集的特征包括工人的年龄、雇用方式(独立经营、私营企业员工、政府职员等)、教育水平、性别、每周工作时长、职业,等等。

这个数据集需要自己在网上下载,在百度里搜即可,其他博主已经整理好了下载的链接。
使用独热向量编码来对分类变量进行数据表示
由上一个title中的表得知,类似于性别gender、教育程度education等特征,它们都是以字符串的形式呈现的,显然无法作为机器学习模型的输入(输入应该是numPy或scipy格式的数组),因此需要进行数据预处理。数据预处理的方法是使用独热向量编码(one-hot)。独热向量很好理解,看下表即可,相当于用一位表示一个状态。
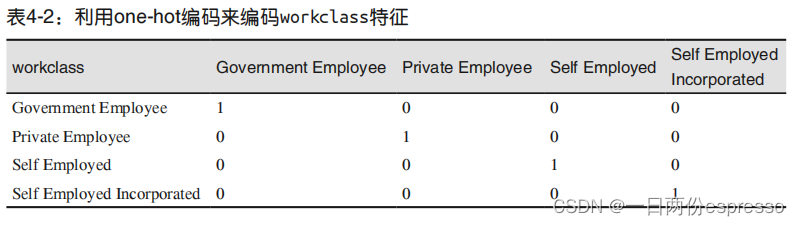
用到的工具:pandas.DataFrame的get_dummies方法
import pandas as pd
from IPython.display import display
# 文件中没有包含列名称的表头,因此我们传入header=None
# 然后在"names"中显式地提供列名称
data = pd.read_csv(
"data/adult.data", header=None, index_col=False,
names=['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race', 'gender',
'capital-gain', 'capital-loss', 'hours-per-week', 'native-country',
'income'])
# 为了便于说明,我们只选了其中几列
data = data[['age', 'workclass', 'education', 'gender', 'hours-per-week',
'occupation', 'income']]
# IPython.display可以在Jupyter notebook中输出漂亮的格式
display(data.head())
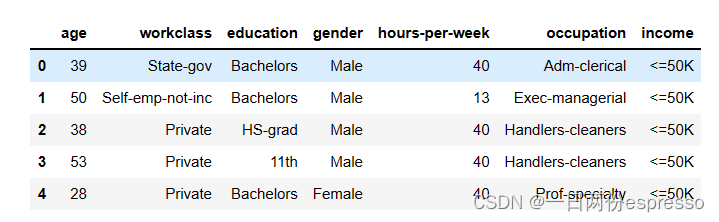
👆首先读取数据集,输出其中几列特征。
print(data.gender.value_counts())
#使用pandas Series的value_counts函数可以显示某列的唯一值及其出现次数
👆之后我们需要检查分类变量的表示是否唯一,如male也可以表示为man,二者都代表性别为男性,需要统一。使用的是pandas.Series的values_counts方法(Series表示pandas数组的一列)。

接下来,使用get_dummies方法对pandas数组中的分类变量进行编码👇
print("Original features:\n", list(data.columns), "\n")
data_dummies = pd.get_dummies(data)
#使用pandas自带的get_dummies方法,对分类特征进行one-hot编码👆
print("Features after get_dummies:\n", list(data_dummies.columns))
data_dummies.head()

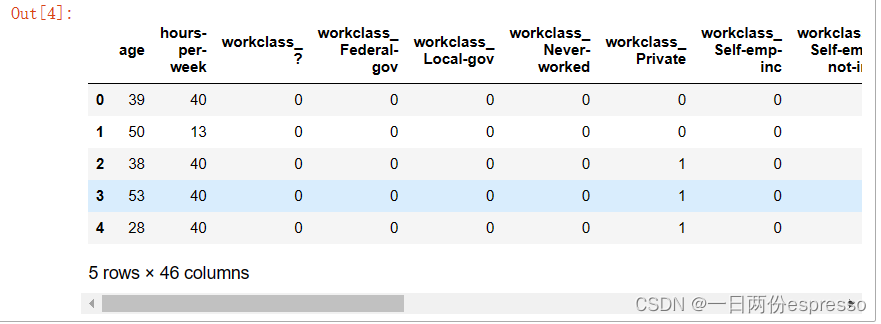
接下来就可以将DataFrame转化为numPy了,即准备机器学习模型的输入数据。
features = data_dummies.loc[:, 'age':'occupation_ Transport-moving']
#👆仅提取带有特征的列; ix索引已过时,可以使用loc或iloc替代,其中iloc通过数值索引
# 提取NumPy数组
X = features.values #通过Dataframe的value方法将Dataframe数组转化为numPy数组,
#以输入到机器学习模型当中
y = data_dummies['income_ >50K'].values
#👆取标签
print("X.shape: {} y.shape: {}".format(X.shape, y.shape))

书中仅使用了Logistic Regression,此处再外加一个RandomForestClassifier,对比两个模型的性能。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
logreg = LogisticRegression(max_iter=10000)
logreg.fit(X_train, y_train)
print("Train score: {:.2f}".format(logreg.score(X_train, y_train)))
print("Test score: {:.2f}".format(logreg.score(X_test, y_test)))

from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=100, max_depth=5, n_jobs=-1)
rfc.fit(X_train, y_train)
print("Train score: {:.2f}".format(rfc.score(X_train, y_train)))
print("Test score: {:.2f}".format(rfc.score(X_test, y_test)))

可以看到,Logistic Regression的性能要优于RandomForestClassifier,但二者在训练集和测试集上的分数都非常接近,可能两个模型都存在一定程度的欠拟合。然而,对于当前数据集,我试了下调节Logistc Regression的C参数,发现无论是调的很大,分数会保持在0.81不变,但将它调的很小,精度会下降。