Java架构师技能点面试题汇总消息队列面试题
1、什么是消息队列?
消息队列,是分布式系统中重要的组件。
- 主要解决应用耦合,异步消息,流量削锋等问题。
- 可实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件。
目前主流的消息队列有:
- Kafka
- RabbitMQ
- RocketMQ ,老版本是 MetaQ 。
- ActiveMQ ,目前用的人越来越少了。
另外,消息队列容易和 Java 中的本地 MessageQueue 搞混,所以消息队列更多被称为消息中间件、分布式消息队列等等。
二、消息队列由哪些角色组成?
如下图所示:
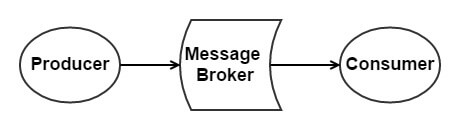
- 生产者(Producer):负责产生消息。
- 消费者(Consumer):负责消费消息
- 消息代理(Message Broker):负责存储消息和转发消息两件事情。其中,转发消息分为推送和拉取两种方式。
1. 拉取(Pull),是指 Consumer 主动从 Message Broker 获取消息
2. 推送(Push),是指 Message Broker 主动将 Consumer 感兴趣的消息推送给 Consumer 。
三、消息队列有哪些使用场景?
一般来说,有下面使用场景:
- 应用解耦
- 异步处理
- 流量削峰
- 消息通讯
- 日志处理
其中,应用解耦、异步处理是比较核心的。
四、Kafka的面试题
1**.Apache Kafka 是什么?**
Kafka 是基于发布与订阅的消息系统。它最初由 LinkedIn 公司开发,之后成为 Apache 项目的一部分。Kafka 是一个分布式的,可分区的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能、低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了同时搞定在线应用
(消息)和离线应用(数据文件、日志),Kafka 就出现了。Kafka 可以起到两个作用:
① 降低系统组网复杂度。
② 降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka 承担高速数据总线的作用。
2.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么?
ISR:In-Sync Replicas 副本同步队列
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持
replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
3.kafka中的broker 是干什么的?
broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
4.kafka中的 zookeeper 起到什么作用,可以不用zookeeper么?
它最初由 LinkedIn 公司开发,之后成为 Apache 项目的一部分。Kafka 是一个分布式的,可分区的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能、低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了同时搞定在线应用
(消息)和离线应用(数据文件、日志),Kafka 就出现了。Kafka 可以起到两个作用:
5.kafka follower如何与leader同步数据?
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。而异步复制方
式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞
吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
6.什么情况下一个 broker 会从 isr中踢出去? leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护 ,如果一个follower比一个leader落后太多,或者超过
一定时间未发起数据复制请求,则leader将其重ISR中移除 。
7.kafka 为什么那么快?
Cache Filesystem Cache PageCache缓存
顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
Zero-copy 零拷技术减少拷贝次数
Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
8.kafka producer如何优化打入速度?
增加线程
提高 batch.size
增加更多 producer 实例
增加 partition 数
设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
跨数据中心的传输:增加 socket 缓冲区设置以及 OS tcp 缓冲区设置。
9.kafka producer 打数据,ack 为 0, 1, -1 的时候代表啥, 设置 -1 的时候,什么情况下,leader 会认为一条消息 commit了
1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
10.Kafka中是怎么体现消息顺序性的?
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
五、RabbitMQ面试题
1、什么是RabbitMQ?为什么使用RabbitMQ?
RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的,消息中间件;
可以用它来:解耦、异步、削峰。
2、RabbitMQ有什么优缺点?
优点:解耦、异步、削峰;
缺点:降低了系统的稳定性:本来系统运行好好的,现在你非要加入个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低;
增加了系统的复杂性:加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大。
3、如何保证RabbitMQ的高可用?
没有哪个项目会只用一搭建一台RabbitMQ服务器提供服务,风险太大;
4、如何保证RabbitMQ不被重复消费?
先说为什么会重复消费:正常情况下,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除;
但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
针对以上问题,一个解决思路是:保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响;保证消息等幂性;
比如:在写入消息队列的数据做唯一标示,消费消息时,根据唯一标识判断是否消费过;
5、如何保证RabbitMQ消息的可靠传输?
消息不可靠的情况可能是消息丢失,劫持等原因;
丢失又分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息;
生产者丢失消息:从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息;
transaction机制就是说:发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit())。然而,这种方式有个缺点:吞吐量下降;
confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;
rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;
如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
消息队列丢数据:消息持久化。
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。
这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢?
这里顺便说一下吧,其实也很容易,就下面两步
- 将queue的持久化标识durable设置为true,则代表是一个持久的队列
- 发送消息的时候将deliveryMode=2
这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据
消费者丢失消息:消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可!
消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消息;
如果这时处理消息失败,就会丢失该消息;
解决方案:处理消息成功后,手动回复确认消息。
6、如何保证RabbitMQ消息的顺序性?
单线程消费保证消息的顺序性;对消息进行编号,消费者处理消息是根据编号处理消息;
六、ActiveMQ
1.什么是activemq?
activeMQ是一种开源的,实现了JMS1.1规范的,面向消息(MOM)的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。
2.activemq的作用以及原理?
Activemq 的作用就是系统之间进行通信。 当然可以使用其他方式进行系统间通信, 如果使用 Activemq 的话可以对系统之间的调用进行解耦, 实现系统间的异步通信。 原理就是生产者生产消息, 把消息发送给activemq。 Activemq 接收到消息, 然后查看有多少个消费者, 然后把消息转发给消费者, 此过程中生产者无需参与。 消费者接收到消息后做相应的处理和生产者没有任何关系
3.activemq的几种通信方式?
3.1publish(发布)-subscribe(订阅)(发布-订阅方式)
发布/订阅方式用于多接收客户端的方式.作为发布订阅的方式,可能存在多个接收客户端,并且接收端客户端与发送客户端存在时间上的依赖。一个接收端只能接收他创建以后发送客户端发送的信息。作为subscriber ,在接收消息时有两种方法,destination的receive方法,和实现message listener 接口的onMessage 方法
3.2 p2p(point-to-point)(点对点)
p2p的过程则理解起来比较简单。它好比是两个人打电话,这两个人是独享这一条通信链路的。一方发送消息,另外一方接收,就这么简单。在实际应用中因为有多个用户对使用p2p的链路。
相互通信的双方是通过一个类似于队列的方式来进行交流。和前面pub-sub的区别在于一个topic有一个发送者和多个接收者,而在p2p里一个queue只有一个发送者和一个接收者。
- ****publish(发布)-subscribe(订阅)****方式的处理
发布订阅模式的通信方式, 默认情况下只通知一次, 如果接收不到此消息就没有了。 这种场景只适用于对消息送达率要求不高的情况。 如果要求消息必须送达不可以丢失的话, 需要配置持久订阅。 每个订阅端定义一个 id, ****<****property name=“clientId” 在订阅是向 activemq 注册。 发布消息 <****property name=“subscriptionDurable” value=“true”/>****和接收消息时需要配置发送模式为持久化template.setDeliveryMode(DeliveryMode.PERSISTENT);。 此时如果客户端接收不到消息, 消息会持久化到服务端(就是硬盘上), 直到客户端正常接收后为止。
- ****4.2p - p(点对点)****方式的处理
点对点模式的话, 如果消息发送不成功此消息默认会保存到 activemq 服务端直到有消费者将其消费, 所以此时消息是不会丢失的。
4.如何解决消息重复问题
所谓消息重复,就是消费者接收到了重复的消息,一般来说我们对于这个问题的处理要把握下面几点,
①.消息不丢失(上面已经处理了)
②.消息不重复执行
一般来说我们可以在业务段加一张表,用来存放消息是否执行成功,每次业务事物commit之后,告知服务端,已经处理过该消息,
这样即使你消息重发了,也不会导致重复处理
大致流程如下:
业务端的表记录已经处理消息的id,每次一个消息进来之前先判断该消息是否执行过,如果执行过就放弃,如果没有执行就开始执行消息,消息执行完成之后存入这个消息的id