[DAU-FI Net开源 | Dual Attention UNet+特征融合+Sobel和Canny等算子解决语义分割痛点]
文章目录
- 概要
- I Introduction
- 小结
概要

提出的架构,双注意力U-Net与特征融合(DAU-FI Net),解决了语义分割中的挑战,特别是在多类不平衡数据集上,这些数据集具有有限的样本。DAU-FI Net 整合了多尺度空间-通道注意力机制和特征注入,以提高目标定位的准确性。核心采用了一个多尺度深度可分离卷积块,捕获跨尺度的局部模式。这个块由一个空间-通道挤压与激励(scSE)注意力单元补充,该单元模拟特征图中通道和空间区域之间的依赖关系。此外,附加注意力门通过连接编码器-解码器路径来优化分割。
为了增强模型,使用Gabor滤波器进行纹理分析,使用Sobel和Canny滤波器进行边缘检测,并由语义Mask引导,以战略性地扩展特征空间。在具有挑战性的严重 Pipeline 和涵洞缺陷数据集以及基准数据集上的全面实验验证了DAU-FI Net的性能。消融研究突出了注意模块和特征注入的逐步利益。DAU-FI Net在缺陷测试集和基准数据集上的平均Intersection over Union (IoU)分别为95.6%和98.8%,分别比先前的方法提高了8.9%和12.6%。消融研究突出了注意模块和特征注入的逐步利益。所提出的架构提供了一个强大的解决方案,推动了在有限训练数据的多类问题的语义分割。作者的严重 Pipeline 和涵洞缺陷数据集,具有像素级标注,为这一关键领域提供了进一步研究的途径。总的来说,这项工作在架构、注意和特征工程方面实现了关键的创新,以提高语义分割的有效性。
地下基础设施的自动缺陷检测至关重要且具有挑战性,手工检查具有危险性、耗时和易出错。作者提出的DAU-FI Net架构提供了准确的自动化解决方案,克服了先验方法的关键局限性。通过集成注意机制和特征工程的创新,DAU-FI Net在排水 Pipeline 和涵洞缺陷数据集和细胞核基准上分别实现了95.6%和98.8%的Intersection over Union,比最先进的方法提高了8.9%和12.6%。这种在复杂实际数据上的性能水平,使得基础设施检查的可靠自动化成为可能,从而提高了效率和安全。筛选出的像素级标注缺陷数据集也为新研究提供了途径。
随着进一步的发展,这种技术可以部署在实际应用中,自主分析排水 Pipeline 、隧道和 Pipeline ,提供快速异常检测,以确定维护的优先顺序,防止灾难性故障。这项工作建立了完整的基准,推动了架构设计、注意模型和特征注入方面的边界突破,以提高深度学习能力。
提出的架构,双注意力U-Net与特征融合(DAU-FI Net),解决了语义分割中的挑战,特别是在多类不平衡数据集上,这些数据集具有有限的样本。DAU-FI Net 整合了多尺度空间-通道注意力机制和特征注入,以提高目标定位的准确性。核心采用了一个多尺度深度可分离卷积块,捕获跨尺度的局部模式。这个块由一个空间-通道挤压与激励(scSE)注意力单元补充,该单元模拟特征图中通道和空间区域之间的依赖关系。此外,附加注意力门通过连接编码器-解码器路径来优化分割。
为了增强模型,使用Gabor滤波器进行纹理分析,使用Sobel和Canny滤波器进行边缘检测,并由语义Mask引导,以战略性地扩展特征空间。在具有挑战性的严重 Pipeline 和涵洞缺陷数据集以及基准数据集上的全面实验验证了DAU-FI Net的性能。消融研究突出了注意模块和特征注入的逐步利益。DAU-FI Net在缺陷测试集和基准数据集上的平均Intersection over Union (IoU)分别为95.6%和98.8%,分别比先前的方法提高了8.9%和12.6%。消融研究突出了注意模块和特征注入的逐步利益。所提出的架构提供了一个强大的解决方案,推动了在有限训练数据的多类问题的语义分割。作者的严重 Pipeline 和涵洞缺陷数据集,具有像素级标注,为这一关键领域提供了进一步研究的途径。总的来说,这项工作在架构、注意和特征工程方面实现了关键的创新,以提高语义分割的有效性。
地下基础设施的自动缺陷检测至关重要且具有挑战性,手工检查具有危险性、耗时和易出错。作者提出的DAU-FI Net架构提供了准确的自动化解决方案,克服了先验方法的关键局限性。通过集成注意机制和特征工程的创新,DAU-FI Net在排水 Pipeline 和涵洞缺陷数据集和细胞核基准上分别实现了95.6%和98.8%的Intersection over Union,比最先进的方法提高了8.9%和12.6%。这种在复杂实际数据上的性能水平,使得基础设施检查的可靠自动化成为可能,从而提高了效率和安全。筛选出的像素级标注缺陷数据集也为新研究提供了途径。
随着进一步的发展,这种技术可以部署在实际应用中,自主分析排水 Pipeline 、隧道和 Pipeline ,提供快速异常检测,以确定维护的优先顺序,防止灾难性故障。这项工作建立了完整的基准,推动了架构设计、注意模型和特征注入方面的边界突破,以提高深度学习能力。
代码:https://tinyurl.com/DAUFNet
I Introduction
语义分割是计算机视觉的一个重要子领域,继续保持研究领域的活跃和动态性。该技术通过为每个像素分配相应的类别和精确的空间位置,使机器更好地理解视觉场景。在这个领域中最有前途的进展是全卷积网络(FCNs)。FCNs通过围绕卷积神经网络(CNNs)的优雅的编码器-解码器架构在语义分割方面表现出色。编码器部分通过卷积和下采样层将输入图像压缩成紧凑的潜在表示。然后,这个表示高级特征的编码器部分被传递到解码器网络,该网络通过上采样生成与原始图像尺寸相匹配的分割图。编码器-解码器结构使得FCNs可以对任意大小的输入进行像素级端到端预测。
FCNs是能够容纳不同尺寸输入的全神经网络架构,能够生成匹配尺寸的输出。这种独特的架构方法使得FCNs能够有效地为图像中的单个像素分配类别标签,并将它们与相应的目标类别对齐。特别值得一提的是,U-Net架构最近在语义分割领域取得了显著的进展,尤其是当在有限数据上训练时,它能够产生精确的分割输出。
U-Net的编码器-解码器结构和跳跃连接允许它在生成分割时利用局部细节和全局上下文[1]。通过结合捕获层次特征表示的卷积层和使精确局部定位的上采样层,U-Net在需要详细界定复杂结构的医学影像和其他分割任务中取得了优秀的性能。该网络从小数据集中产生准确输出的能力对于许多应用具有极大的价值,在这些应用中,获取大规模标注训练数据具有很大的挑战性。
在利用FCNs和U-Net架构进行语义分割的最新进展基础上,作者自己的先前工作旨在进一步提高分割性能。在作者先前的研究中,作者介绍了一种增强的U-Net架构,该架构采用了深度可分隔块,其中包含一系列具有多种核尺寸(3x3和5x5)的分离卷积,以及一个核尺寸为1x1且减小了卷积滤波器的卷积。这种卷积组合捕获了多种局部模式,并提取了跨越多个尺度的特征。尽管模型表现出了有前途的性能,但需要进一步改进以解决多类数据集的局限性和挑战,尤其是在类不平衡实例和受限的样本可用性方面。此外,在数据集中区分类似于彼此的类仍然具有挑战性。
本文通过引入不同的注意力机制来解决上述挑战。具体而言,作者将多尺度深度可分隔块与增强的挤压和激励(SE)机制相结合。这个组合块的主要目标是通过捕获输入数据的时空和通道依赖性来增强模型的表示能力。这种双重注意力方法允许模型将局部模式和全局上下文纳入考虑,从而提高分割性能。
此外,作者引入了一种新颖的方法,将提取的图像特征集成到模型中以提高性能。尽管在深度学习的兴起下,特征工程的重要性逐渐减弱,但将手工制作的特征与深度神经网络相结合仍然具有优势,尤其是在涉及有限训练数据或较少语义类别的场景中。这种混合方法可以有效地扩展特征空间并提供额外的信息来指导模型的学习过程。
为了评估作者模型的性能,作者创建了一个专门的数据集,用于分割排水 Pipeline 和涵洞中的缺陷,该数据集中的图像由领域专家识别并标注。这些缺陷包括裂缝、开裂、 Pipeline 变形、接头问题以及其他在 Pipeline 和涵洞检查过程中常见的复杂损伤模式。通过使用LabelMe标注工具手动勾画每张图像中的缺陷边界,作者获得了精确的像素级标注。
此外,为了评估模型的泛化能力,它被用于2018年数据科学竞赛的细胞核分割数据集的测试,该数据集被认为是公共基准。这个基准包括一系列具有分割真实值的2D光显微镜图像。这种评估的双重性质–专注于分割精细 Pipeline 缺陷的具体任务,以及更广泛的分割挑战,使作者能够全面分析模型的能力。
创建一个定制的 Pipeline 涵洞缺陷分割数据集,其中包括实际情况下观察到的具有挑战性的特征,不仅有助于对作者模型进行深入评估,而且也为这个关键领域的未来研究提供了宝贵的资源。
Main Contributions
这项工作在多类问题中有限训练数据的情况下推进语义分割的关键贡献包括:
提出了一种新颖的双注意力U-Net架构(DAU-FI Net),该架构集成定制的多尺度空间-通道注意力机制,并战略性地注入工程化的图像特征以增强在有限训练数据的多类分割中的精确度。它引入了一个双注意力块,将多尺度卷积与同时的空间-通道挤压和激励建模相结合,以捕捉局部模式和全局上下文。
在收集并标注的具有挑战性的实际下水道涵洞缺陷分割数据集上达到了最先进的性能。该方法显著优于先前的方法,并验证了在细胞核分割基准测试上的泛化能力。详细的本实验分析关键组成部分的逐步利益。
提供了具有像素级标注的下水道涵洞缺陷数据集,以推进该领域未来研究的安全关键性。深入的本实验分析研究了注意力机制和策略性特征注入如何逐步提高在训练数据稀缺的多类分割。
II Literature Review on the Evolution of Semantic Segmentation
近年来,提出了许多语义分割模型,每个模型都通过不同的策略和技术来超越前人。一个转变的发展是将注意力机制集成到分割模型中。通过关注显著区域并抑制无关细节,注意力模块复制了人类视觉感知的核心方面。当有效地集成时,注意力模块可以增强模型的性能,为该领域的发展做出贡献。本节回顾了语义分割的原始模型,分析了激励作者方法的关键局限性,并介绍了相关的注意力机制。
在其核心部分,语义分割通过像素 Level 的分类对图像中的每个像素进行分类,通常使用全卷积神经网络(FC-NNs)在编码器-解码器架构中实现。编码器通过连续的卷积和下采样层压缩空间维度,将输入压缩成表示突出特征的紧凑潜在表示。然后,解码器将这个编码进行上采样,以生成与原始输入分辨率相匹配的分割图。这种整体设计已经变得众所周知,一直改进着早期方法。例如,FCN-8s模型[5]利用跳跃连接来恢复在编码过程中丢失的精细空间细节,从而在像PASCAL VOC[5]这样的数据集上提高分割精度。
Roy等人提出了空间和通道挤压与激励(scSE)模型,这是对传统挤压与激励(squeeze-and-excitation)块的有针对性的改进,以增强全卷积网络在语义分割方面的性能。这是通过在可学习的权重层中重新校准特征响应来实现的,以捕捉特征图内的相互依赖性。scSE在正向传播过程中动态地重新校准激活,同时提高有用的特征权重并抑制不利的特征。实验表明,将scSE集成到模型中可以提高分割准确性和目标界定,增强表示能力和建模更丰富的通道间关系。然而,可能存在来自增加的模型复杂性和需要在不同的架构和任务上进行全面分析的可变性限制。
为了补充这些进展,Su等人研究了将轻量级卷积块注意力模块(CBAM)集成到U-Net中。通道注意力模块(CAM)沿着通道维度运行,通过平均池化聚合特征,并使用可学习的层选择性地强调有用的通道。同时,空间注意力模块(SAM)生成2D注意力图来突出显著的空间区域和目标。这种同步的通道和空间注意力组合通过捕捉全局语义和定位详细结构来提高分割。评估结果表明,CBAM的有效性,其中双注意力机制提高了像素级目标界定的表示能力和精确度。模块化特性也使得可以灵活地将其集成到像U-Net这样的架构中,而不会增加过度的计算开销。
在基本编码器-解码器架构的基础上,注意力稀疏卷积U-Net(ASCU-Net)提出了一种创新的三角形注意力机制来提高语义分割性能。这是通过有效地集成三种互补的注意力模块实现的 - 注意力门(AG)、空间注意力模块(SAM)和通道注意力模块(CAM)。注意力门动态地将每个编码器层中的重要目标结构聚焦。在传输信息到解码器之前,它会过滤掉无关的区域。轻量级的SAM使用归一化卷积来建模空间关系并定位显著区域。
同时,CAM通过挤压和激励操作适应性地重新校准通道特征以强调有用的通道。这种全面的注意力机制选择性地过滤和强调最重要的信息,从而提高表示质量。他们的实验结果表明,注意力集成方法提高了分割精度,增强了模型的鲁棒性。优雅地集成定制的注意力模块是深度学习技术在场景理解方面取得进步的重要一步。
虽然先前的创新已经为语义分割带来了独特的优势并推动了该领域的边界,但仍然存在处理复杂多类数据集的挑战,这些数据集存在类不平衡的问题。为了克服这些障碍,作者提出了一种新颖的模型,该模型采用了一种集成的方法。
作者的模型结合了多种注意力机制,包括多尺度过滤,以提高分辨率和细化分割。作者还战略性地注入工程化的特征来扩展表示能力。这种平衡的上下文注意和底层特征设计增强了分割的有效性。这些创新有可能改变复杂真实世界场景的分割,如地下基础设施的检查。作者的方法专注于通过开发更可靠和准确解决方案来推进语义分割研究,这些解决方案可以方便地部署。通过解决当前的限制,作者的工作旨在通过专门设计用于处理多个类别不平衡数据的灵活架构将场景理解提升到一个新的水平。
自动化地检查地下基础设施,如涵洞和排水 Pipeline ,对于识别结构和材料退化至关重要,以确保在整个设计寿命内正常运行。自动化缺陷检测对于改善基础设施所有者做出数据驱动维护决策的能力以及减轻与健康和安全相关的人力风险至关重要。然而,这带来了挑战,因为手工检查速度慢、成本高且易出错。这些环境具有恶劣的照明、遮挡,最重要的是,存在多种缺陷类型,包括裂缝、腐蚀、堵塞、接头问题以及入侵。这种缺陷的异质性极大地复杂化了分析。
此外,Haurum等人和Gao等人也指出了其他困难,例如有限的光照明、纹理变化和水的遮挡和杂物。还存在类不平衡问题,其中某些缺陷的代表性不足。这些问题共同使得精确识别和分类变得非常困难。
然而,最近的研究在利用深度学习和机器学习检测基础设施中的裂缝方面取得了进展。Panta等人提出了一个用于堤防图像像素级裂缝检测的编码器-解码器网络IterLUNet。一个比较研究发现MultiResUnet实现了最高的平均Intersection over Union。强调了持续监测,因为裂缝带来的灾难性风险。以前的研究评估了从图像中检测裂缝的算法,并首创了使用机器学习的沙泡检测。
这些研究展示了在部署复杂算法以检测结构弱点方面取得的进展,有助于灾害预防。然而,关于复杂真实世界环境和航空检查数据限制的挑战仍然存在。
作者的模型旨在通过自定义的注意力机制和扩展的特征表示来解决这些挑战,使即使在数据不平衡、有限的情况下也能实现有效的分割。战略性地注入特征进一步增强了能力,通过集成基础图像处理和学习的表示。作者的方法有助于实现高效、可靠的自动化,使这个传统上需要手动处理的过程更加便捷。

这一节详细介绍了作者提出的模型Dual Attentive U-Net with Feature Infusion(DAU-FI Net),如图1所示。模型包含几个关键组件,通过双重注意力建模和策略性特征工程来增强语义分割能力:
双注意力模块(DAB)注意力机制如图1左边的部分所示。
注意力门如图1右上角所示。
如图1右下角所示,在编码器和解码器路径之间存在注意跳接。
特征增强 Pipeline 如图1右下角所示。
U-Net Encoder-Decoder Backbone with Attentive Skip Connections
DAU-FI Net实现了一个带有注意的编码器-解码器架构,用于精确的语义分割,这是基于作者之前的精炼U-Net架构实现的。这种U形的拓扑结构集成了包括注意力门、跳接、编码器路径和解码器路径之间的协调上/下采样等创新,如DABs和连接节点中的数据流所示。在编码器路径中,使用最大池化降采样,而在解码器路径中,使用转置卷积(上采样)进行上采样。这些组件一起提升了分割建模能力,从而改进了分割效果。
DAU-FI Net的一个关键创新是将在跳接连接编码器和解码器路径的注意门(见图1右上角)集成到跳接中。注意门充当专门的过滤器,在强调编码器特征图中最显著的结构的同时,抑制无关区域。当数据流经注意门时,它们会适当地聚合空间上下文,只允许最有效的信息通过。这种注意门引导的编码器-解码器路径之间的通信,增强了模型的分割能力。
注意门被战略性地放置在连接节点之前,此时编码器和解码器特征被组合。这种机制使注意门可以优先考虑特征图,提高针对目标分割任务的至关重要方面,同时忽略不必要的细节。注意门的选择性,由数据引导,有助于提供更集中的特征表示,支持网络在语义分割方面的能力,并实现更出色的性能。
在DAU-FI Net架构中,战略性地包括注意跳接(见图1右下角)可以增强模型的能力,提高分割准确性和重建保真度。这些跳接以实线表示,可以绕过层来提供给后层的较早的特征图,有助于在降采样过程中保留丢失的空间细节。有效地集成降采样、上采样、注意力建模和跳接极大地提高了分割的准确性和重构特征的能力。
Dual Attentive Block
DAU-FI Net的核心是双注意力模块(DAB),这是一种创新融合方法,它将多个尺度和形状的局部模式和全局依赖性进行融合,以增强分割。具体而言,DAB结合了两个关键组件:多尺度深度可分隔卷积块和修改后的同时空间-通道挤压与激励(scSE)注意力机制。
如图1左上角所示,深度可分隔卷积块使用大小不同的卷积 Kernel ,如和,以匹配不同物体的尺寸。这种多尺度过滤可以适应尺寸变化,优化不同大小物体上的特征提取。
与此同时,在如图1左下角所示的并行scSE注意力组件中,包括通道挤压与激励(CSE)和空间挤压与激励(SSE)单元,用于针对性地特征重新校准。CSE通过通道维数减化和全局平均来强调有用的通道。SSE通过空间维数减化和全局池化来生成空间注意力图,以突出重要的区域。
作者的关键改进是将CSE和SSE中的缩放比例设置为动态可学习的,而不是固定的。这使得可以进行自适应的输入特定重采样,以优化块内的信息流动。优化后的多尺度过滤和重新校准的注意力可以弥合细粒度像素复杂性和更广泛的通道特征之间的差距。
如图1所示,同时的scSE输出通过添加与初始的多尺度块输出合并。这种两阶段方法将不同尺度的互补空间-通道注意力统一到一个统一的块中。总的来说,DAB代表了整体的创新,通过一个紧密的融合机制有效地将局部模式、上下文关系和缩放动力学整合到一个块中,从而提高分割。
Strategic Feature Augmentation
尽管DAU-FI Net架构展示了有前景的分割能力,但需要进一步的改进来处理具有多类不平衡数据集且训练样本有限的情况。为了解决这些挑战,作者提出了一种基于领域知识的策略,即在模型中战略性地增强工程化的特征。尽管深度神经网络展示了惊人的特征学习能力[18],但将这种特征与手工制作的输入相结合将扩大特征空间,并提供额外的指导,以在数据稀少或倾斜时提高性能。作者的混合方法有效地融合了深度学习和专业特征设计的互补优势。
具体而言,作者采用了一个全面的四角方法,包括:
使用Gabor滤波器进行纹理分析,通过小波变换检测模式、平滑度和不规则性;
使用Canny和Sobel边检测器来识别边界和强度变化,突出物体的轮廓;
使用直方图方向梯度(HOG)来捕捉形态属性,通过量化梯度方向直方图来表示;
使用颜色谱和强度分析来评估图像内的颜色和强度分布。
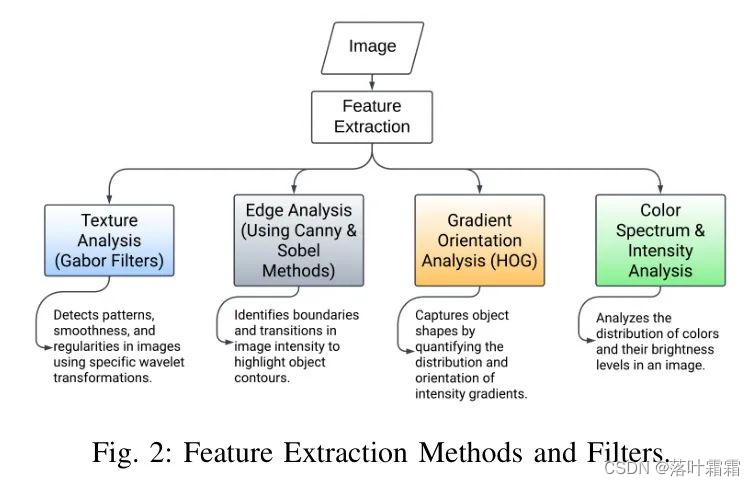
如图2所示,这四种互补技术分别提取了纹理、边缘、形状和颜色/强度特征。将这些工程化输入进行融合显著扩大了特征空间,超过了深度学习从受限 Pipeline 检测数据中提取的范围。这使得模型可以通过使用专门的handcrafted表示来提高分割能力,从而克服样本大小和类不平衡限制。
Gabor滤波器提取多尺度、多方向纹理特征,以稳健地描述腐蚀、开裂和堵塞,而Sobel和Canny操作符捕获有用的边缘模式,以精确地定位缺陷 - 这些技术的适应性为数据集中的复杂下水道 Pipeline 缺陷提供了额外的线索。补充文档包含了基于Gabor滤波器进行纹理分析和基于Sobel和Canny操作符进行边缘分析的信息。
如图2所示,这四种互补技术分别提取了纹理、边缘、形状和颜色/强度特征。将这些工程化输入进行融合显著扩大了特征空间,超过了深度学习从受限 Pipeline 检测数据中提取的范围。这使得模型可以通过使用专门的handcrafted表示来提高分割能力,从而克服样本大小和类不平衡限制。
Gabor滤波器提取多尺度、多方向纹理特征,以稳健地描述腐蚀、开裂和堵塞,而Sobel和Canny操作符捕获有用的边缘模式,以精确地定位缺陷 - 这些技术的适应性为数据集中的复杂下水道 Pipeline 缺陷提供了额外的线索。补充文档包含了基于Gabor滤波器进行纹理分析和基于Sobel和Canny操作符进行边缘分析的信息。

图3显示了提到的滤波器的响应以及应用基于区域特征提取方法对来自作者数据集的样本所得的结果。
Iii-B1 Gradient Orientation Analysis
除了纹理和边缘特征外,作者还探索了直方图方向梯度(HOG)特征来描述局部形状属性和缺陷的空间布局。HOG分析图像局部区域的梯度方向,使其对目标检测具有稳健的特征提取,这对于作者的污水 Pipeline 图像非常有用。对于某些具有定向梯度图案的缺陷(如裂缝、孔洞和脱节),HOG可以帮助捕捉其独特的形状轮廓。这加强了模型在检测基于形状的异常和区分具有定向梯度图案的不同缺陷类型方面的能力。
Iii-A2 Color Spectrum and Intensity Analysis
此外,颜色和强度特征在图像分析中起着至关重要的作用。作者实现颜色光谱强度分析,以检查 Pipeline 图像内的颜色分布和变化[25]。根据腐蚀和矿物质沉积等因素,缺陷与完好区域相比具有独特的颜色特征。捕捉颜色和强度特征可以帮助识别这些异常模式。将这些手工制作的特征融合在一起,可以扩展深度学习从作者的受限 Pipeline 检测数据中提取的表示能力。
Iii-A3 Injection of Augmented Features
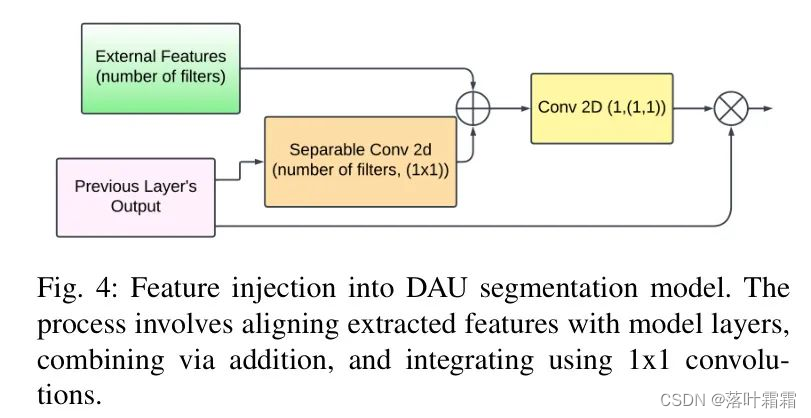
在特征提取后,接下来的关键步骤是将这些特征集成到作者的分割模型DAU中。作者对模型中的多个层进行了深入的检查,尝试了各种操作,如加法和乘法。经过一系列实验后,作者确定了特征注入的最优方法,该方法涉及将特征引入模型的前两层,如下所示:
首先,作者将提取的特征与模型的相应层对齐。这需要创建具有相同通道数(即滤波器或特征提取器数量)的卷积层。然后,作者通过加法将这些层组合在一起,并应用1x1卷积层,该层具有单个过滤器。这一最后步骤使作者能够对模型的输入数据进行逐元素乘法,从而有效地将提取的特征集成到分割过程中。该方法如图4所示。
Iii-A4 Annotation-Guided Extraction
为了进一步优化特征提取,作者利用自定义的数据集从像素级标注的Mask作为区域过滤的指南。作者首先将选定的滤波器应用于图像以生成响应图。然后,作者对响应图和标注Mask进行逐元素乘法,以保留与缺陷相关的模式,这些模式是由领域知识确定的。
通过仔细地结合领域知识、特征设计和数据标注,作者增强了模型在识别和分类 Pipeline 缺陷方面的效率。领域知识指导适当的滤波器选择,标注则定位关键区域,共同实现更集中的特征提取。
作者通过在多个模型层中注入工程化特征来确定最优的注入策略。作者的目标是有效地结合深度表示学习的互补优势和定制特征工程,以提高性能。专门的特征增强旨在克服数据约束,为实际下水道检查部署定制模型。
IV Dataset Description
本节详细介绍了作者创建下水道和涵洞缺陷分割数据集的方法。作者首先概述了数据收集过程,描述了如何获取并预处理包含标记缺陷实例的源视频,以提取关键帧。接下来,作者讨论了用于生成细粒度 GT Mask的像素级标注策略,以实现语义分割。技术行人仔细地 traced 每个缺陷在提取帧中的精确边界,以产生像素级标签。最后,作者通过评估在核分割公共基准数据集上的性能,来评估模型的可靠性和泛化能力。
Data Collection Methodology
作者从两个行业来源收集了580个带有标注的地下基础设施检查视频,以构建一个强大的数据集,覆盖各种实际条件。这些视频涵盖了污水 Pipeline 和涵洞,引入了材料、形状、尺寸和成像环境的变化。技术行人仔细地标注了每个视频,根据行业标准,确定了九种常见的结构缺陷类别的边界框和时间戳。
为了指导模型训练,一位专业的土木工程师根据美国行业标准,为每种缺陷类别分配了0到1之间的权重,以反映经济和安全影响。通过将单个得分除以最高值进行归一化,确定了在学习过程中的优先级。
构建的数据集包括污水 Pipeline 和涵洞中发现的各种材料、形状和尺寸。这种数据集的多样性准确地反映了在实际现场检查污水 Pipeline 和涵洞时遇到的内在变化。由于从各种来源和不同结构的 Pipeline 和涵洞中集成数据,它还带来了额外的挑战。
Pixel-Level Annotation
为了构建作者的数据集,作者首先将每个视频分割成单独的帧,每类别的标注点捕捉一个帧,每个类别标注点的时间间隔为4到10秒。每个标注对应于特定类别的缺陷标签,并具有特定秒数的时间戳。此外,作者还记录了每个标注在 Pipeline 中的位置。目前,数据集包括大约5000帧,包括表I中列出的九种缺陷。
作者的数据集准备的一个关键方面涉及手动像素级标注以促进语义分割。这涉及在视频帧中准确地勾勒出每个缺陷的出现。高度熟练的标注员仔细地勾勒出每个缺陷在每帧中的边界,以创建像素级Mask。这些Mask作为训练和评估作者的语义分割模型的 GT 数据。像素级标注过程确保作者的数据集提供必要的详细信息,以在像素 Level 准确地识别和分类缺陷,从而开发和评估强大的语义分割算法。根据美国国家船舶和海洋管理局(NASSCO) Pipeline 评估认证程序(PACP)[26]中规定的结构色彩编码指南,每个被标注的类别都被分配了特定的颜色。
Benchmark Evaluation
除了作者构建的下水道和涵洞缺陷数据集,作者还评估了在2018年数据科学竞赛细胞核分割数据集[4]上的性能。这个数据集最初包含了约700个分割的细胞图像,每个图像都是在各种条件下获得的,包括不同的细胞类型、不同的放大倍数和多种成像模式。虽然这个生物医学应用领域与基础设施检查有显著差异,但在具有独特成像特性的公认基准上评估性能仍然可以提供有用的洞察。作者旨在验证的关键方面是模型在以下方面的能力:
扩展到用于开发的数据之外的各种数据集
从包含独特artifacts、噪声和其他复杂性的图像中分割细粒度结构
处理具有不同输出类别的多类分割任务
对细胞核数据集的结果进行分析,使作者能够在具有不同挑战和成像模态的标准数据集上严格评估作者方法的可扩展性和局限性。
这有助于确定跨领域适用于哪些方面以及可能需要定制的方面。目标是全面评估模型,为未来的发展和应用提供信息。
V Model Training and Evaluation
本文节概述了用于训练和严格评估语义分割模型的优化、正则化、损失函数和评估指标。
Training Optimization and Regularization
V-A1 Loss Function
在模型训练中,作者使用分类交叉熵损失函数以实现优化的多类像素分类。这是一种常用的函数,非常适合在语义分割任务中优化多类预测。该损失函数有效地最小化了预测的类概率和实际标签之间的误差。
V-A2 Dropout Regularization
为了在最大程度上提高模型性能并防止过拟合,作者在输出层之前引入了一个dropout层,通过超参数调优确定其比例为0.2。这是一种正则化技术,在训练过程中暂时禁用随机神经元,以防止共同适应。这有助于提高模型的泛化能力。
V-A3 Optimization Algorithm
作者使用了Adam算法,该算法可以自适应地调整每个参数的学习率。使用初始学习率为0.001,并在10个周期后使用指数衰减。这种学习率调整策略可以逐步优化模型权重。
Evaluation Metrics
对下水道和涵洞缺陷进行语义分割的模型性能评估使用四个关键指标:
交并比(IoU)及其标准(Standard)和加权频率(Frequency-Weighted)变体,用于衡量预测与实际数据的覆盖程度;
F1分数,结合精确率和召回率以获得对数据不平衡敏感的平衡指标;
平衡精度,对所有类别平均召回率以实现公平表示;
马氏相关系数(MCC),衡量二类分类的质量,得分越高表示性能越好,特别适用于分布不平衡的数据集。
VI Results
本文节呈现了作者在具有挑战性的下水道和涵洞缺陷数据集上对所提出的DAU-FI Net模型进行的全面实验结果。作者通过与已建立的架构进行基准测试来评估整体性能,并通过详细的消融研究分析作者核心创新的影响。
Comparative Evaluation
为了验证作者提出的模型,作者与一些著名的 Baseline 和最先进的架构进行了全面的比较,例如:
U-Net:分割领域的开创性全卷积网络;
注意U-Net:具有附加注意模块的U-Net;
CBAM U-Net:具有同时空间和通道注意块的U-Net;
ASCU-Net:具有三部分注意力机制的U-Net;
深度可分隔U-Net(DWS MF U-Net):具有多尺度过滤的U-Net。
作者评估了多种指标 - IoU,FWIoU,F1-Score,平衡精度,和MCC。
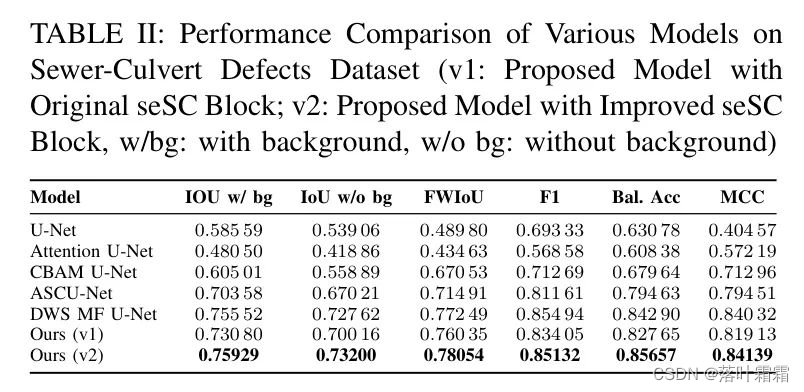
表2总结了关键结果。

在作者的研究中,升级后的增强DAU-FI Net模型,尤其是升级后的seSC块,在所有评估指标方面都超过了其先进的竞争对手。这一成就值得注意,因为该模型的参数数量减少了,如表3所示。

为了实际说明,图5提供了来自作者下水道和涵洞缺陷数据集的样本图像分割结果的对比。该图包括原始图像、 GT Mask和来自各种模型的预测:U-Net,注意U-Net,CBAM U-Net,ASCU-Net,Depthwise Separable U-Net和作者自己的DAU-FI Net。从视觉效果上看,DAU-FI Net在缺陷识别和与 GT Mask的对齐方面都比其竞争对手更准确。
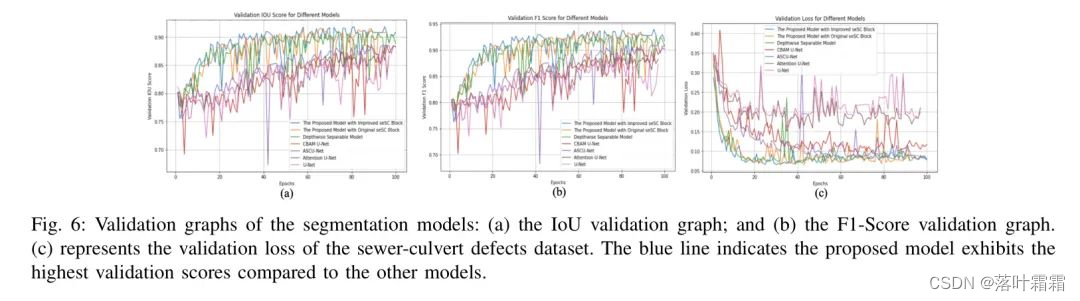
进一步的定量证据表明DAU-FI Net的有效性,如图6所示。在这里,作者使用下水道和涵洞数据集来展示模型在训练周期内的性能。具体而言,图6(a)揭示了交并比(IoU)分数,其中作者的DAU-FI Net(用蓝色线表示)在验证集上获得了最高的IoU。类似地,图6(b)图表了F1-Score趋势,再次强调了DAU-FI Net在领先性能。最后,图6©展示了验证损失趋势,其中作者的模型显示出比其竞争对手更快的收敛和较低的验证损失。这些图形共同强调了DAU-FI Net的增强分割精度。
作者进行了消融研究,以分析作者核心创新 - 双注意力模块和战略特征注入的影响。将工程化特征集成到模型中,在下水道和涵洞数据集以及细胞核数据集上都取得了显著的IoU改进,突显了作者方法的有效性。表4总结了结果。
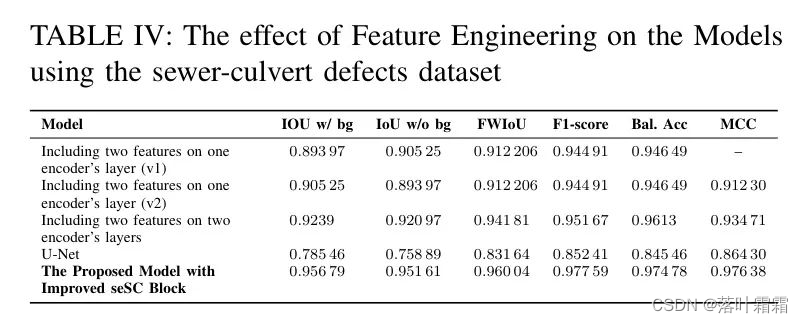
此外,作者进行了一系列实验,以确定最佳的模块放置配置(P1-P6),如表VI所示。最佳架构是P6,其中在编码器和解码器路径上都使用了双注意力,并在跳接连接上使用注意力门。这种配置在表VII中展示了最高的分割精度。
VII Discussion
本文节提供深入分析和对结果的上下文化,以突出所提出的DAU-FI Net模型的卓越性和创新贡献。
比较基准实验验证了DAU-FI Net在像Attention U-Net和CBAM U-Net这样的复杂最新架构上的优越性能。如表2所示,作者的模型在具有挑战性的下水道和涵洞缺陷数据集上,在所有关键指标上取得了最高分。
关键的是,这种卓越性是在与竞争对手相比显著更少的参数下实现的,如表3所示。DAU-FI Net只有1.46百万参数,显著减少了计算量,同时提高了准确性。这种优化使得在实际应用中能够高效部署。
此外,在第六节B中进行的消融研究证实了作者的核心创新的价值。将工程化特征集成到模型中,在下水道和涵洞数据集以及细胞核数据集上都取得了显著的IoU提升,如表5所示。这证明了作者的特征增强方法的跨领域 versatility。
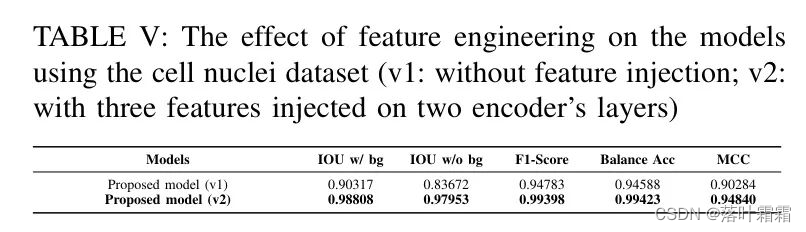
此外,消融实验确定了最优架构配置P6,该配置在编码器-解码器路径上战略性地结合了双注意力模块和跳接连接上的注意力门。如表V所示,这种设计通过增强信息流动和特征融合取得了最佳结果。

为了提供更深的视角,图7以视觉方式比较了分割输出。DAU-FI Net在具有挑战性的情况下生成了精确和准确的Mask,优于其他方法。作者的模型在省略了 GT 值的情况下也能检测到缺陷,证明了其强大的学习能力。
总的来说,作者对DAU-FI Net的系统评估证实了它在处理复杂的类别分割任务时的能力,即使数据受到限制。该框架有效地将互补的模态集成在一起 - 双注意力用于表示增强和特征注入用于扩展嵌入。这种平衡方法推动了边界,交付了一个新的最先进解决方案。
通过率先提出一种优化的架构、战略特征增强以及创建一个新颖的缺陷数据集,这项工作为推进实际世界中的语义分割奠定了坚实的基础。作者的可配置方法提供了一个蓝图,可以解决跨领域的数据稀缺分割问题。
小结
这项研究在多类语义分割方面取得了重大进展,尤其是在有限训练数据的约束下。DAU-FI Net架构是这项研究的基石,创新性地将多尺度深度可分隔卷积与先进的并行空间-通道挤压与激励(scSE)注意力单元相结合。这种集成是实现细微分割的关键,通过促进局部特征学习并捕捉全局依赖关系。
作者在包括具有挑战性的下水道和涵洞缺陷数据集和基准数据集的严格测试中,证明了DAU-FI Net的鲁棒性。消融研究进一步强调了作者的方法的价值,特别是使用Gabor、Sobel和Canny滤波器根据语义Mask进行战略特征注入的注意力机制的集成。这些技术在两个数据集上的Intersection over Union(IoU)得分上都取得了可衡量的改进。
这里提出的方法不仅提高了性能,而且没有显著增加计算开销。它展示了如何将特定领域的工程化特征有效地集成到深度学习框架中。
这项研究不仅推动了多类语义分割的边界,而且强调了深度学习和特征工程之间的协同潜力,这对于数据稀缺的场景尤其有价值。作者创新的适应性特征注入和并发空间-通道注意力方法为解决复杂的分割任务提供了新的视角。
在本研究中使用污水 Pipeline 和涵洞缺陷数据集为未来的研究提供了有价值的维度。尽管DAU-FI Net已在两个数据集上进行了测试,但它在各种分割任务上显示出前景。本文为改进多类语义分割架构奠定了基础。作者将不同技术进行集成标志着重大进步,为这个领域的进一步研究打开了大门。