学习笔记:基于GMM的语音转换
基于高斯混合模型的语音转换(Voice conversion based on Gassian mixture model)
任务:
把说话人A的声音转换成说话人B的声音,保持语义信息不变。
实验部分:男女声转换
概述
语音合成任务:
- 语音转换(Voice Conversion, VC)
- 文语转换(Text to Speech, TTS)
- 语音生成(Voice Generation, VG)
今天主要学习语音转换VC任务。
语音转换
将语音经过预处理特征分析提取,然后特征配准,再训练一个转换模型,得到映射关系。
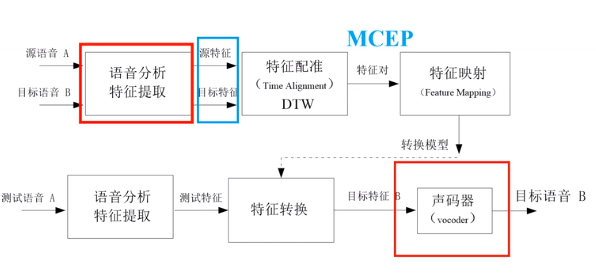
特征提取
红框部分,就是声码器的工作,分解信号,合成信号。
1.常用声码器:World,STRAIGHT, Griffin-Lim(具体原理搜我博客)
2. 如这次用到的STRAIGHT,将信号分解为三部分:
---- F0基频(浊音):反映声音语调,声音的整体调域。
---- 频谱(梅尔倒谱):主要特征,反映声音中的细节,大部分语义信息,说话人信息。
----非周期特征(清音):反映声音中非周期变化。
特征对齐
最常用的就是动态时间规则DWT算法(具体原理搜我博客)。
为了解决原语音与目标语音不等长问题,DWT算法根据相似性,建立了对应关系,形成源+目标特征对。
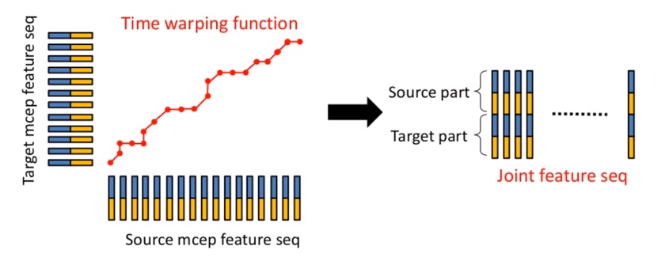
转换模型
基于GMM的特征映射
任务: 已知联合分布,求解条件分布。
原理: 假设原始语音x,目标语音y都是高斯的,所以联合起来也是高斯的。利用若干个高斯如m个,来拟合信号的分布。训练一个GMM模型,就能得到联合分布的均值,方差,就可以求条件分布。
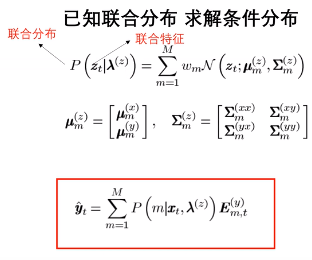
具体来看y是如何求解的?
条件概率的求解

第一部分:已知输入信号x,该x属于每一个高斯成分m=1~M的概率。
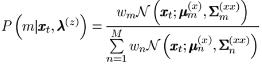
第二部分:在这个第m个高斯下,已知x,能产生出y的概率。
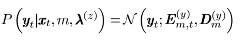
其中,E和D都有闭式解:
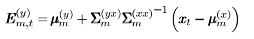
这样,就能求解y:
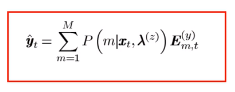
可以看到,一个xt算一个yt,就是最小均方误差求解。这种转换算法效果差点,是因为没有考虑帧间信息。
转换模型改进
针对GMM转换存在问题,2007年Toda等人提出了改进方法。

主要改进了三部分:
1.引入动态成分
2.将最小均方误差估计,改为最大似然估计。评估一组数据,而不是单一一帧,充分考虑序列整体性。
3.引入全局方差(GV,Global Variance)。使最终转换结果与目标分布更加接近。
具体算法:
1.此时,x不再是一帧一帧,而是一组帧,T帧,y也是。
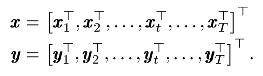
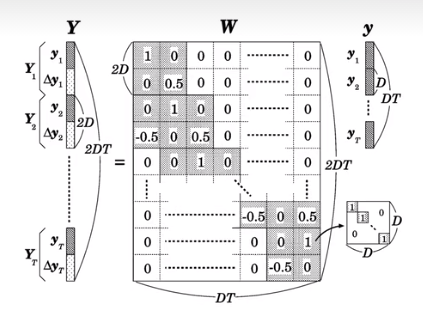
2.引入相邻帧之间的差值(动态成分):
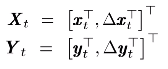
Y和y之间关系为:Y=W*y
3.从而得到序列X和Y,还有联合特征的数据:
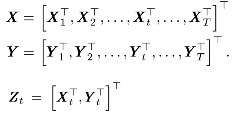
4.用最大似然估计求解:
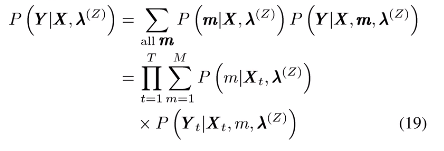
要让上面式子值最大。
每部分含义和上面的类似。
第一部分:已知输入X的第t帧,该Xt属于每一个高斯成分m=1~M的概率。
第二部分:在这个第m个高斯下,已知X,能产生出Y的概率。
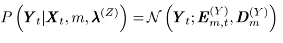
推导可得,当E和D等于如下值时,似然值最大:
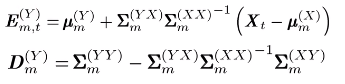
为了计算简便,对似然函数进行了化简:
定了哪个m,只取概率最大的那个m。
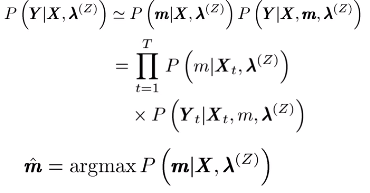
最终解:
将Y=W*y代入,得:
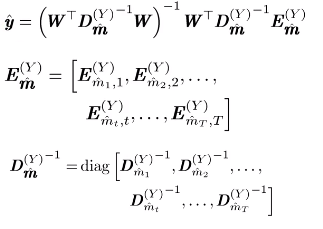
这样就实现了序列级别的转换。
代码实现
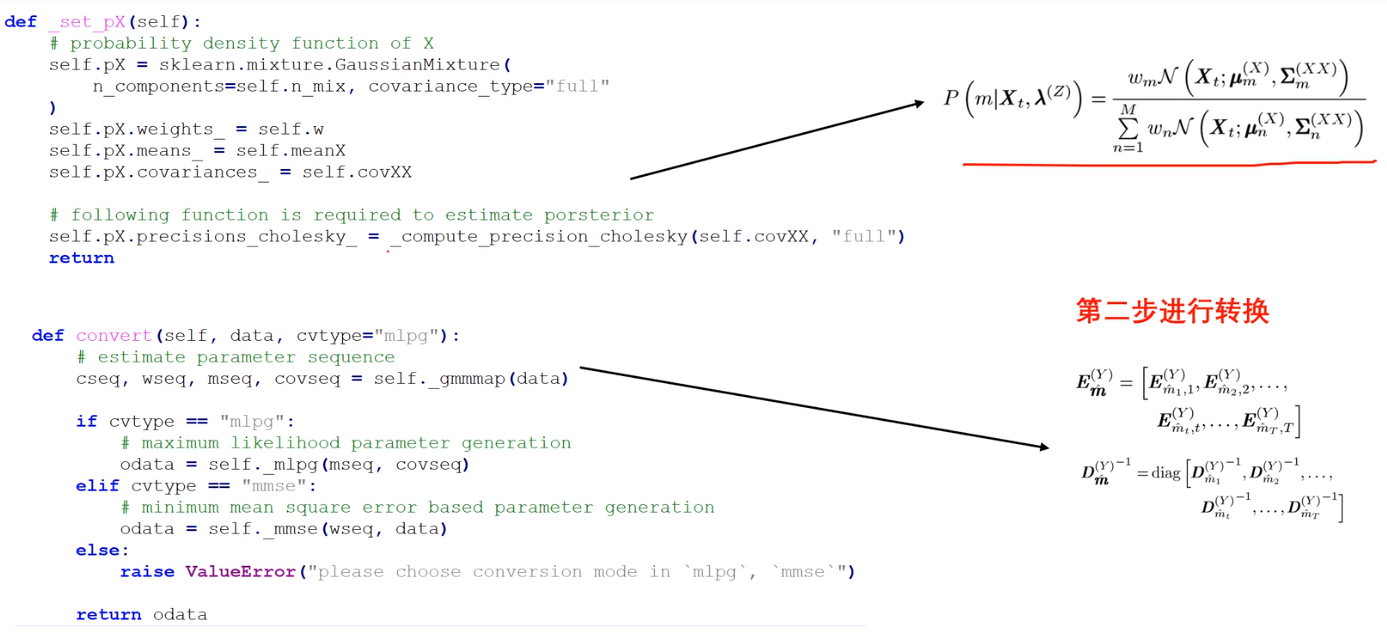
用机器学习中常用的库函数sklearn。
import sklearn.mixture
from sklearn.mixture.gaussian.mixuture import _compute_precious_cholesky

E的具体函数如下:

D的函数,还有转换函数:
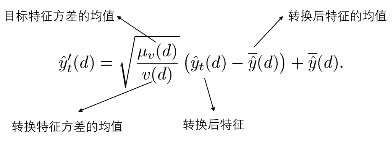
全局方差的实现:
对转换后的特征方差分布,进行调整,使其符合目标特征的方差分布。
算法实现
下面介绍具体的GMM语音转换。
1.数据准备:如男女声声音文件各70条。
2.特征提取:F0,mcep,AP, npow(反映每帧能量,为了去静音帧)
3. 统计信息:F0均值方差(单高斯转换),主要转mcep
4. 特征配对:DWT
5. 训GMM:训mcep特征对
6. 特征修正:计算训练数据转换后的特征的方差的均值
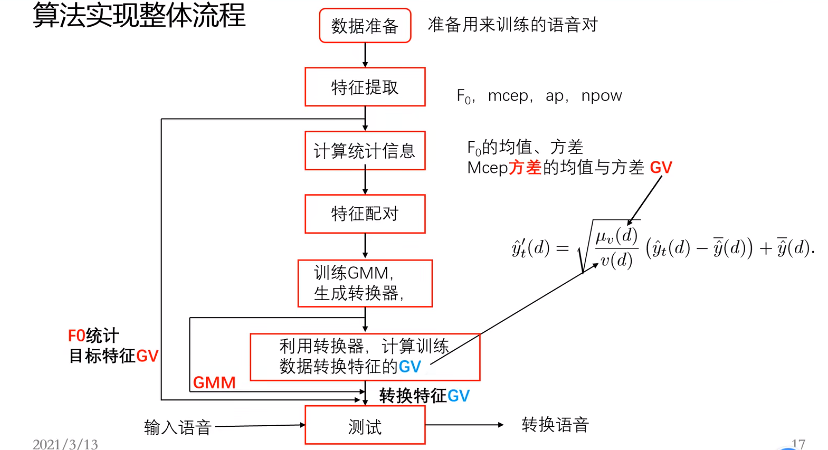
代码:GMM语音转换