【翻译】Adaptive Convolutions for Structure-Aware Style Transfer

用于结构感知的风格迁移的自适应卷积
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 3. 使用 AdaConv 进行特征调制( Feature Modulation with AdaConv)
- 3.1. 概述
- 3.2. 用 AdaConv 进行风格转换
- 3.2.1 Style Encoder
- 3.2.2 预测深度可分离卷积
- 3.3. Training
- 4. Results
- 4.1. Style Transfer
- 4.2. 生成模型的扩展
- 5. 结论
Abstract
图像之间的风格转移是CNN的一种艺术应用,即把一个图像的 "风格 "转移到另一个图像上,同时保留了后者的内容。神经风格转移的技术现状是基于自适应实例归一化(AdaIN),该技术将风格特征的统计属性转移到内容图像上,并能实时转移大量的风格。然而,AdaIN是一个全局性的操作,因此在传输过程中,风格图像中的局部几何结构往往被忽略。我们提出了自适应卷积法(AdaConv),这是AdaIN的一个通用扩展,允许实时地同时转移统计和结构风格。除了风格转移,我们的方法还可以随时扩展到基于风格的图像生成,以及其他已经采用AdaIN的任务。
1. Introduction
近年来,卷积神经网络(CNN)已被用于探索和操纵图像的风格。图像风格通常由图像特征定义,如绘画中的整体颜色和笔触的局部结构,或生成性图像应用中的脸部姿势和表情。风格也是在不同的分辨率下定义的,因此既可以包括脸部的整体特征,也可以包括皮肤上雀斑的局部结构。这一领域的研究随着神经风格转移的出现而获得了很大的发展,最初是由Gatys等人提出的[8],其中一个CNN被训练来重现一个输入图像的内容,但以另一个图像的风格来呈现。本着类似的精神,生成对抗网络(GANs)被用来生成具有随机矢量输入定义的风格的真实的同步图像,例如在创建合成脸部图像时[18]。
处理风格的广泛方法是通过自适应实例归一化(AdaIN),这是一种转换图像特征的平均值和方差的方法。例如,AdaIN经常被用来将风格图像的特征统计数据转移到内容图像上。自从Huang等人在2017年提出定义以来[13],这种操作已经在基于CNN的图像处理文献中变得非常普遍。然而,AdaIN的一个主要缺点是,统计学计算是一个全局性的操作;因此,风格中的局部空间结构不能被有效捕捉和转移。一个具体的例子见图1(第1行),风格图像有明显的特征,如黑白的圆和方。AdaIN的结果将该图像的统计数据转移到内容图像上,但结果缺乏任何风格的结构。类似的现象可以在第2行看到,对于不同的风格图像。

图1:我们提出了自适应卷积(AdaConv),这是自适应实例归一化(AdaIN)在图像风格转移方面的一个扩展,它能够转移统计和结构风格元素。AdaConv也可以应用于生成模型,如StyleGAN,用于众多数据集上的逼真图像合成1。
在这项工作中,我们引入了对AdaIN的扩展,称为自适应卷积(AdaConv),它允许同时适应统计和结构风格。在风格转移的背景下,我们的方法不是从每个风格特征中转移一对简单的全局统计数据(平均值和标准差),而是从风格图像中估计完整的卷积核和偏置值,然后将其卷积在内容图像的特征上。由于这些内核能更好地捕捉风格中的局部空间结构,AdaConv能更忠实地将风格图像的结构元素转移到内容图像上,如图1(第4和第7列)所示。
为深度学习任务预测卷积核的概念已经在视频帧插值[26, 27, 28]和变性[1, 35]等领域显示了一些前景。在这里,我们利用这个想法来扩展AdaIN,以实现更普遍的图像风格操作。AdaConv可以将AdaIN重新置于几乎所有已经采用AdaIN的应用中,为基于CNN的图像生成和风格操作提供一个新的、通用的构建模块。为了说明AdaConv的通用性,我们展示了它在风格转移和基于风格的生成性面部建模(StyleGAN[18])中的应用。
2. Related Work
本节回顾了与我们的工作更密切相关的神经风格转移、生成模型中的调制层和内核预测等领域的前期工作。
基于CNN的神经风格转移最初是由Gatys等人[8]提出的。虽然他们的方法允许在图像之间转移任意的风格,但它是基于一个缓慢的优化过程。Johnson等人[17]通过引入感知损失来解决这个问题,使优化的速度大大加快,实现了实时结果。同时,Ulyanov等人[33]提出了一种风格转移方法,通过评估特定风格和预训练的前馈神经网络,进一步加快推理速度。在后续的工作中[34],他们还用实例规范化(IN)取代了批量规范化(BN)的铺垫,以产生更高质量的结果而不影响速度。为了改善对风格转移结果的控制,Gatys等人[9]随后通过在基于优化和前馈的方法中重新调整损失函数,引入了明确的颜色、比例和空间控制[9]。在IN的基础上,Dumoulin等人[7]提出了有条件的实例规范化(CIN),并将规范化层以风格为条件,允许一个模型从32种预定义的风格或其插值中的一种进行风格转移。Ghiasi等人[11]进一步扩展了CIN,允许在训练时未见的任意风格的转换;这是用一个大型的风格语料库来训练一个编码器,将风格图像转换为条件潜伏向量。Cheng等人[6]提出了基于补丁的风格互换方法,用于任意风格的转换。同时,Huang等人[13]提出了一种任意风格转换的方法,通过有效地使IN适应风格特征的平均值和标准差,从而导致AdaIN。Li等人[22]通过对给定风格的潜在特征进行白化和着色来扩展这一方法。这个想法被Sheng等人[31]用一个风格装饰模块和多尺度风格适应来进一步扩展。其他的工作也研究了用于风格转换的元网络[30],使用学习的线性变换的快速风格转换[21]和立体图像的风格转换[4]。最近,Jing等人[15]注意到,直接用风格特征的统计数据替换内容特征的统计数据可能是次优的;相反,他们的动态实例归一化(DIN)方法训练风格编码器输出内容特征的新统计数据,同时还调整后续卷积层的大小和采样位置。除了实例归一化,Kotovenko等人[20]还探索了对抗性学习,以更好地将风格与内容区分开来。Jing等人[16]最近发表的评论文章中对其他神经风格转移方法进行了深入描述。我们工作的目的是进一步扩展AdaIN,根据风格图像预测整个卷积核和偏差,以转移风格的统计数据和局部结构。
生成模型中的调制层也对风格转移之外的其他突破做出了贡献。最值得注意的是,StyleGAN[18]使用了AdaIN的原始版本,但输入的风格统计是由一个MLP从高斯噪声向量中预测出来的。为了减轻AdaIN造成的一些可见的假象,StyleGAN2[19]用一个权重解调层取代了它,它只对标准差进行归一化和调制,而不改变平均值。由于AdaIN及其变体只转换全局统计数据,它们对风格中的局部空间语义不敏感。为了解决这一局限性,已经提出了新的方法,从输入的空间布局图像中预测空间变化的标准化参数[29, 39, 15]。SPADE[29]用从输入空间遮罩回归的每像素变换取代了AdaIN的全局仿生变换。SEAN[39]通过考虑输入布局遮罩的额外样式向量进一步扩展了SPADE。SPADE和SEAN都为语义图像生成的目的保留了调节空间布局;它们有效地控制了每个内核在特定图像位置的强调或压制方式。相比之下,我们的Ada-Conv方法在测试时产生了全新的内核。另外,SPADE和SEAN并不直接适用于风格转换的应用,在这种情况下,必须保留内容图像的空间布局。
核预测在以前的工作中也有过探索。需要注意的是,上述所有的特征诺玛化和调制方法都遵循一个类似的程序:它们定义了标量仿射变换,独立地应用于每个特征通道。主要的区别在于:
(i) 变换参数是手工制作的,还是在训练中学习的,还是在测试时预测的;
(ii) 每个通道的变换是全局的还是空间变化的。
那些回归全局变换的方法也可以理解为在测试时预测1×1的二维内核。对于风格转换,Chen等人[3, 5]学习了针对风格的滤波器组,这些滤波器组被卷积在内容图像的特征上。他们的方法仅限于在训练时学习的滤波器组;它不能为测试时给出的未见过的风格生成新的内核。Jing等人[15]声称能够使用他们的通用DIN块从输入中回归动态卷积;然而,报告的实验结果仅限于1×1的反演。关于内核预测的相关工作也超越了风格转换。Jia等人[14]提出了用于视频和立体图像预测的动态解决方案,其中测试时间特征被重塑为新的过滤器,这些过滤器被卷积地应用或以特定位置的方式应用。最先进的蒙特卡洛渲染去噪方法[1, 35, 10]使用神经网络来预测用于重建最终去噪帧的动态滤波。也有人提出用神经网络来预测用手持相机以突发模式拍摄的自然图像的去噪内核[24, 36]。Niklaus等人[26]预测视频的帧插值核;他们后来将这项工作扩展到预测分离卷积参数[27, 28]。Xue等人[37]使用一个CNN来预测来自随机高斯变量的运动核,用于合成可信的下一帧。Esquivel等人[38]预测自适应内核,用于减少在有限的计算资源下对图像进行准确分类所需的层数。在本文的其余部分,我们探讨了一个类似的想法,在测试时利用内核预测来改善生成模型中的风格转移和基于风格的调制。
3. 使用 AdaConv 进行特征调制( Feature Modulation with AdaConv)
我们现在描述AdaConv和我们的内核预测器,说明AdaConv是如何概括和扩展基于风格的特征调制中典型的1×1仿射变换的。我们首先在风格转移的背景下与AdaIN相提并论,然后说明AdaConv如何允许对局部特征结构进行更好的调节,以更好地转移空间风格,同时也适用于风格转移之外的高质量生成模型。
3.1. 概述
考虑通常的风格表示{a, b}∈R2,其中a和b分别代表风格的尺度和偏置项(例如,对于风格转换,a和b是风格图像特征的平均值和标准偏差)。给定一个数值为x∈R的输入特征通道和所需的风格,AdaIN对归一化的输入特征进行风格定义的仿射转换,
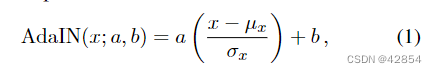
其中μx和σx是特征通道的平均值和标准差。因此,AdaIN只改变了基于调节风格参数{a, b}的每个通道的全局统计数据。请注意,无论每个样本x周围的特征值的空间分布(结构)如何,整个通道都是被平等调制的。
因此,我们扩展AdaIN的第一步是引入一个有条件的二维风格滤波器f∈Rkh×kw,取代尺度项并产生扩展的风格参数{f, b}。这个滤波器可以根据样本x周围的邻域N(x)的局部结构,以空间变化的方式来调节特征通道,
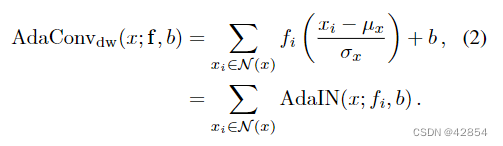
请注意,这个深度AdaConv变体包含AdaIN,它是一个具有1×1过滤器f和N(x)={x}的特殊情况。
我们的第二个也是最后一个步骤是通过扩大输入风格参数来扩展这个深度变体,也包括一个可分离的、点式卷积张量p∈RC,用于具有C特征通道的输入。这使得AdaConv能够根据一种风格进行调制,这种风格不仅能够捕捉到全局统计数据和空间结构,而且能够捕捉到不同输入通道c中的特征xc之间的相关性,
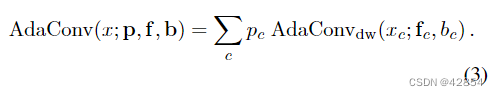
AdaConv的输入样式{p, f, b}有效地包括一个深度可分的三维内核[12],有深度和点卷积成分,以及每通道的偏置。用于调制输入的深度和点卷积核的实际数量是一个设计选择,可以是任意的大。正如我们在后面的第3.2.2节中所描述的,这可以用深度可分离卷积层的组数ng来控制。
在下文中,我们为AdaConv提出了一个内核预测框架,并展示了如何将其作为AdaIN的通用替代物,以便在风格转换和其他高质量生成模型中实现更全面的基于风格的调节。
3.2. 用 AdaConv 进行风格转换
对于风格转移,我们从Huang等人[13]的原始架构开始,并在训练期间应用相同的内容和风格损失。然而,我们并没有使用AdaIN直接将全局风格的统计数字映射到内容特征上,而是使用我们新的内核预测器和AdaConv来更全面地转移风格的不同属性。图2给出了我们的风格转移架构的概述。
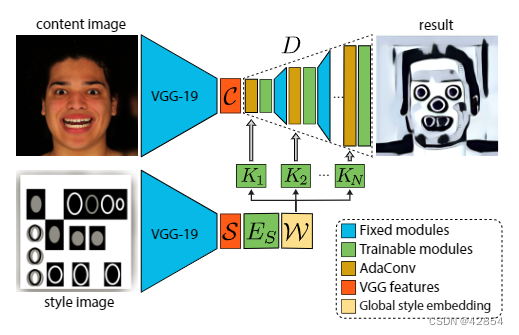
图2:带有我们新的内核预测器和AdaConv的网络架构,用于结构感知的风格转移。
输入的风格和内容图像用预先训练好的VGG-19[32]编码器进行编码,以获得风格S和内容C的潜在特征。对于内核预测,风格特征S由风格编码器ES进一步编码,以获得全局风格描述符W。这些预测被摄入到解码器D的所有层中,并输出风格转换的结果。
我们的风格转换架构采用了4个内核预测器,在解码图像的4个不同的分辨率下运行,其内核的维度不同。每个解码层都有一个自适应卷积块(图3),其中预测的纵深和点状卷积在标准卷积之前。这些标准卷积层负责学习与风格无关的内核,这些内核对重建自然图像很有用,并且在测试时保持固定。编码器ES、内核预测器K和解码器D被联合训练,以最小化VGG-19潜在特征空间内的内容和风格损失的相同加权和[13]。
3.2.1 Style Encoder
我们现在转向从风格特征S预测卷积核的目标,以便在我们的图像解码器的每个尺度上应用于内容特征C。在这里,一个中间步骤是计算一个风格表征W,全面描述不同尺度的风格图像,同时以风格转移损失为指导。这一设计选择也是通过与最先进的生成模型[18, 19]进行类比而产生的,其中术语 "风格 "表示图像的全局和局部属性。
预先训练好的VGG-19网络在VGG-19 relu4 1层将尺寸为(通道、高度、宽度)的原始输入风格图像翻译成尺寸为(512、32、32)的风格张量S。在这里,感受野并没有覆盖整个风格图像。因此,我们通过训练一个额外的编码器组件ES,将S减少到我们的全局嵌入W,如图3所示。
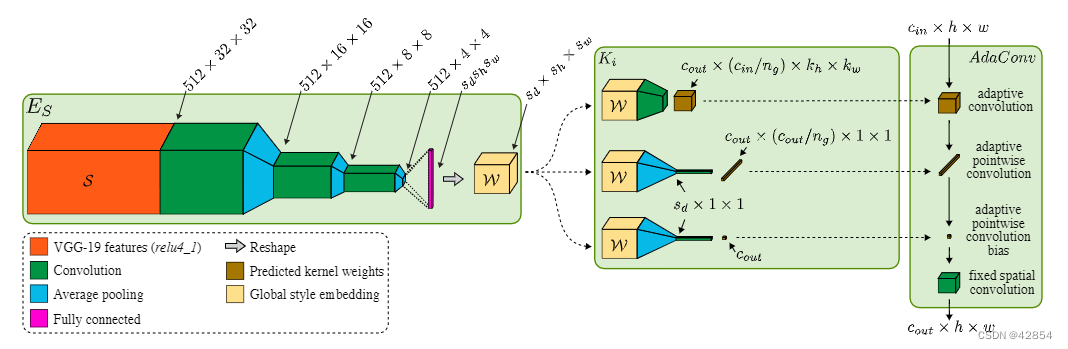
图3:全局风格编码器ES、内核预测器Ki和AdaConv块中的结构调制的架构,所产生的深度可分卷积核应用于输入内容特征(右上)。
我们的风格编码器ES包括3个初始区块,每个区块都有一个3 x 3的卷积,一个平均池操作,以及一个泄漏的ReLU激活。然后,输出被重塑并送入最后的全连接层,该层提供全局风格描述符,反过来又被重塑为一个大小为(SD,SH,SW)的输出张量W。这个嵌入的尺寸是超参数,定义为要预测的内核大小的一个因素。
由于使用了这个全连接层,我们的网络被限制在与固定尺寸(3,256,256)的输入风格图像的工作。然而,内容图像的尺寸不受限制,因为它流经网络的一个完全卷积部分。
3.2.2 预测深度可分离卷积
图2中的每一个核预测器K都是一个简单的卷积网络,其输入是风格描述器W,而输出是一个可深度分离的核。选择预测深度可分的核[12]的动机是希望保持核预测器的简单和计算效率,同时也使随后的卷积更快。
一个标准的卷积层需要一个尺寸为(1, cin, h, w)的输入图像张量,并用一个尺寸为(cout, cin, kh, kw)的内核张量进行卷积,其中cin和cout是输入和输出通道的数量。每个通道的偏置也被添加到输出中。因此,该层所需的权重数量为cout × cin × kh × kw + cout。深度可分离卷积通过将输入通道收集成n个独立的组,并应用单独的空间和点式核,分别学习结构和跨通道的相关性,从而减少了这个数字。所需的权重数量减少为cout × cin /ng × kh × kw + cout。对于ng=cin的深度卷积层,输入的每个通道都与它自己的cout/cin滤波器组进行卷积。然后用1×1的核进行点卷积,以扩大输出中的通道数量,在最终输出中加入每个通道的偏置。
在这里,需要注意的是,我们的解码器中的四个AdaConv 层的cin分别等于512、256、128和64,随着空间分辨率的提高而减少。因此,最低空间分辨率的内核预测器通常具有最高的参数数量。为了将我们的网络能力均匀地分布在连续的复述层上,我们在较低的分辨率上设置了较大的ng∈{cin, cin/ 2 , cin/ 4 , cin/ 8 },并在连续的层上逐渐减少,从而导致更好的结果(在补充中给出了与常数ng=cin的比较)。对于深度卷积核和点卷积核,ng的设置是相同的。
因此,每个内核预测器K都会为解码器的那个规模的深度卷积AdaConv层输出必要的权重。这些权重包括:
(i) 大小为(cout, cin /ng , kh, kw)的空间核,
(ii) 大小为(cout, cout/ ng , 1, 1)的点式核,
(iii) 偏置项b∈Rcout。
每个核预测器K的输入是大小为(SD, SH, SW)的全局风格描述符W,它通过卷积层和汇集层来输出目标尺寸的空间核,图3。这些层可以由标准卷积或转置卷积组成,其参数在设计时确定,并取决于要预测的核的大小。为了预测点状的1×1核,我们将W汇集成一个大小(SD,1,1),然后进行1D卷积来预测cout点状核。我们使用一个单独的预测器来预测每个通道的偏差,与点式内核的预测器类似。一旦内核和偏置被预测出来,它们就被用来调制一个输入,如图3的右半部分所示。
3.3. Training
为了与现有的风格转换技术进行比较(见图4),我们使用COCO数据集[23]作为内容图像,使用WikiArt数据集[25]作为风格图像来训练我们的方法。在其余与AdaIN的比较中,我们使用了一个由大约4000张人脸组成的自定义内容数据集作为内容图像,并继续使用WikiArt数据集作为风格图像。在使用人脸作为内容的实验中,我们从头开始重新训练AdaIN和AdaConv,以进行公平的比较。为了训练我们的方法,我们使用Adam优化器,学习率为1e-4,批次大小为8。对于 AdaIN,我们使用与 [13] 中相同的设置。关于我们训练的其他细节在补充材料中介绍。


图4:AdaConv的表现与目前最先进的方法1,2相当。我们的方法特别善于将风格图像的局部结构转换为内容图像。
4. Results
我们现在展示了使用AdaConv作为AdaIN的扩展来进行风格转换和生成式建模的结果。
4.1. Style Transfer
我们的工作主要是以图像风格转移的应用为动机,与最初的AdaIN[13]很相似。在本节中,我们所有的结果都是在风格描述符大小sd=512和内核大小3×3的情况下创建的。
定性比较。我们首先将AdaConv与几种风格转换方法进行比较,包括Huang和Belongie的AdaIN[13]、Chen和Schmidt[6]、Ulyanov等人[34]、Gatys等人[8]、Jing等人[15]、Li等人[22]、Sheng等人[31],以及Johnson等人[17]。图4显示,我们的方法与目前的技术水平相当,并且在保留风格图像的结构方面有明显的优势。例如,帆船图像(第一行)中的水的结构与风格图像中的头发丝相似;艺术画中的笔触结构被自然地转移到内容图像上。
由于AdaConv扩展了AdaIN,我们在图5中进行了更彻底的比较。在所有情况下,AdaConv渲染的内容图像更忠实于风格图像的结构(局部空间分布),同时也传递了风格的全局统计数据。AdaIN不能转移风格结构,只能转移风格的全局统计数据。
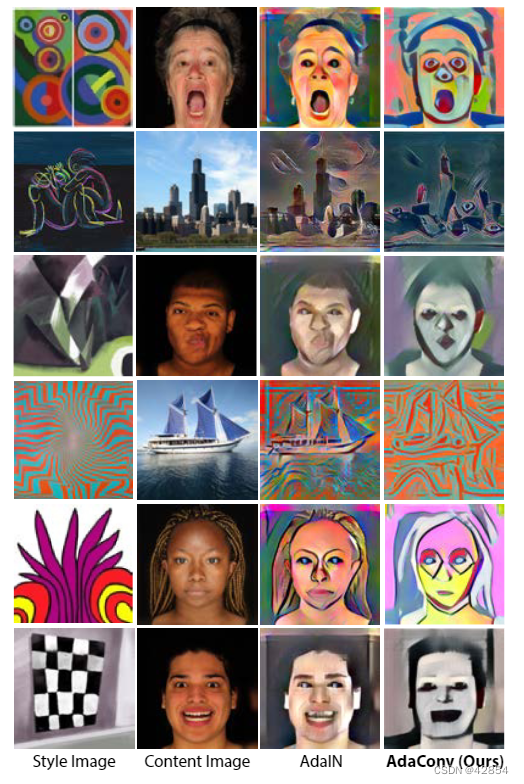
图5:与AdaIN[13]相比,由于我们的内核预测方法,我们的AdaConv扩展在保持风格图像的结构方面做得更好。
风格旋转。我们进一步强调了Ada-Conv在保留风格图像结构方面的好处,即在不同程度的旋转下应用同一风格图像。当然,旋转的风格图像实际上是一种不同的风格。然而,当使用AdaIN转移风格时,这一概念在很大程度上消失了,因为全局特征统计在旋转下基本保持不变。我们在图6中说明了这一效果,我们将四种不同旋转的风格图像转移到同一内容图像上(取自图5的最后一行)。我们可以看到,AdaConv成功地保留了转移结果中风格图像的空间方向,而AdaIN的结果看起来基本与旋转无关。我们鼓励读者在补充视频中查看更多旋转结果。

图6:当旋转风格图像时,使用AdaConv将风格定向很好地转移到内容图像上,而AdaIN的结果大多是旋转不变的,因为全局统计数据在旋转下变化不大。
风格插值。与AdaIN一样,我们也可以在风格空间中插值,以产生混合多种输入风格的结果。在AdaConv的情况下,我们在内核预测器之前对风格特征编码器的输出进行插值。插值后的风格描述器产生内核,改变解码结果的结构。因此,风格图像的结构元素被平滑地插值到空间。这可以在图7中观察到,我们在两个结构非常不同的风格图像之间进行插值,并将结果应用于一个面部的内容图像。与AdaIN相比,AdaConv生成的插值结果的结构也介于两个风格图像的结构之间。例如,人们可以很容易地看到像粗线这样的结构元素在使用AdaConv时从一个结果到另一个结果的实际变形和扭曲。
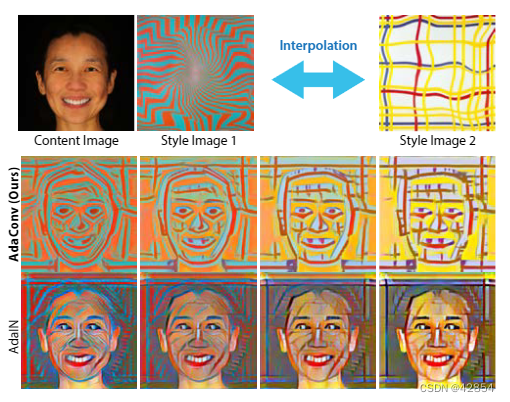
图7:当我们在两个风格的图像之间插值时,AdaConv的结果比AdaIN更平滑,我们可以通过AdaConv的方法在空间上变形时对个别结构进行跟踪。
用户研究。我们还进行了一项用户研究来比较AdaConv和AdaIN的结果。参与者评估了由AdaIN和AdaConv获得的总共10个并排的风格转换结果,两个结果以随机的顺序显示。参与者被要求根据以下3个问题选择一个结果:(1)哪一个风格转换结果更好地保留了内容图像?(2) 哪一个风格转换结果更好地保留了风格图像中的风格结构?(3)哪种风格转移的结果在将风格转移到内容图像方面总体上做得更好?共有185名来自多个国家、年龄段和背景的参与者参加了我们的在线调查。不出所料,93.9%的参与者认为AdaIN在内容保存方面做得更好,而92%的参与者认为AdaConv在风格结构方面抓得更好。总的来说,绝大多数的参与者(71.8%)表示AdaConv在风格转移方面做得更好。
视频风格转换。最后,从补充视频中可以看出,AdaConv对视频序列进行风格转换时具有良好的时间稳定性,即使在对每一帧独立应用转换时也是如此。通过将AdaConv与视频风格转换的光学流技术相结合,可以提高时间稳定性[2]。
4.2. 生成模型的扩展
虽然AdaIN最初是为风格转移而提出的,但它已被发现应用于许多领域,包括像StyleGAN[18]和StyleGAN2[19]这样的生成模型,它被用来将 "风格 "注入以对抗性方式训练的生成网络中。由于AdaConv是AdaIN的扩展,我们通过将其与我们的内核预测器一起纳入一个类似StyleGAN2的网络来证明其对生成网络的适用性。
在StyleGAN2发生器的每个刻度上,由MLP预测的每个通道的平均值和标准差(A)被用来用AdaIN调制卷积层的权重(图8,左)。然而,请注意,内核权重是在训练中学习的,只有在测试时才会调整其比例。相比之下,我们的AdaConv块在测试时从输入的风格参数中预测全深度卷积核。因此,我们将StyleGAN2中的每个权重解调块替换为AdaConv块,对上一层的上采样输入进行 "基于风格 "的深度分离卷积(图8,右)。噪声向量也通过MLP转换为每个Ada-Conv块中的内核预测器的输入 "样式 "W。由于深度卷积比标准卷积的直径小,我们在同一块中用标准的二维卷积进行适应性卷积。然后加入每个通道的偏置和高斯噪声,输出被送入下一个AdaConv块。
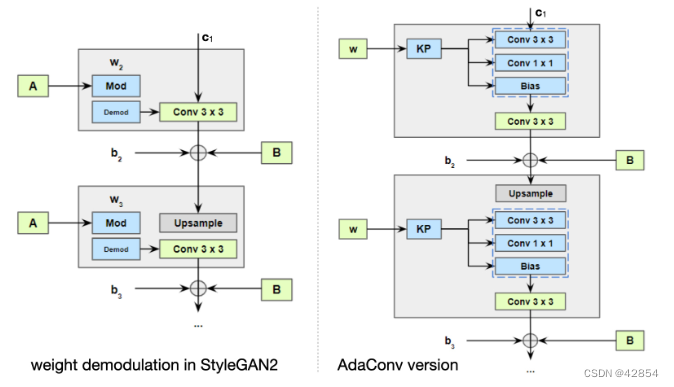
图8:StyleGAN2[19]中的解调块和我们带有AdaConv块的替代网络。
我们在FFHQ、CelebHQ、AFHQ-wild和AFHQ-dog数据集上以(256×256)的分辨率训练了这个改良的StyleGAN2生成器。我们修改后的生成器和StyleGAN2的判别器是用与[19]相同的超参数和损失函数训练的。我们在单个Nvidia2080Ti GPU上训练了我们的生成网络,进行了 300K 迭代(~1.2m 真实图像),批次大小为4。我们在图 9 中展示了一些合成面孔和野生动物的示例。这些结果是在风格描述符大小sd=128和内核大小3×3的情况下产生的。在生成环境中使用AdaConv的其他结果见我们的补充材料。

图9:AdaConv也可以应用于生成性架构,如StyleGAN2[19],用于现实的图像合成。
5. 结论
在这项工作中,我们提出了自适应卷积(Ada-Conv)用于结构感知的风格操作。作为自适应实例归一化(AdaIN)的延伸,AdaConv预测卷积核和来自给定风格嵌入的偏差,这可以被编织到图像解码器的层中,以便在测试时更好地调整其行为。在神经风格转移的文本中,AdaConv不仅可以将全局统计数据,而且可以将风格图像的空间结构转移到内容图像上。此外,AdaConv还可以应用于基于风格的图像生成(如StyleGAN),我们已经证明了这一点,而且几乎所有AdaIN都被采用。它提供了一个新的、通用的构建模块,用于将条件输入数据纳入基于CNN的图像生成和风格操作。