吴恩达深度学习笔记(四)——深度学习的实践层面
一、数据集的划分



要确保验证集和测试集的数据来自同一分布。


二、偏差和方差
方差:训练集和验证集的数据分布是否均匀,训练集和验证集之间的差别;
偏差:训练集和真实结果的差别。
高偏差:欠拟合
高方差:过拟合

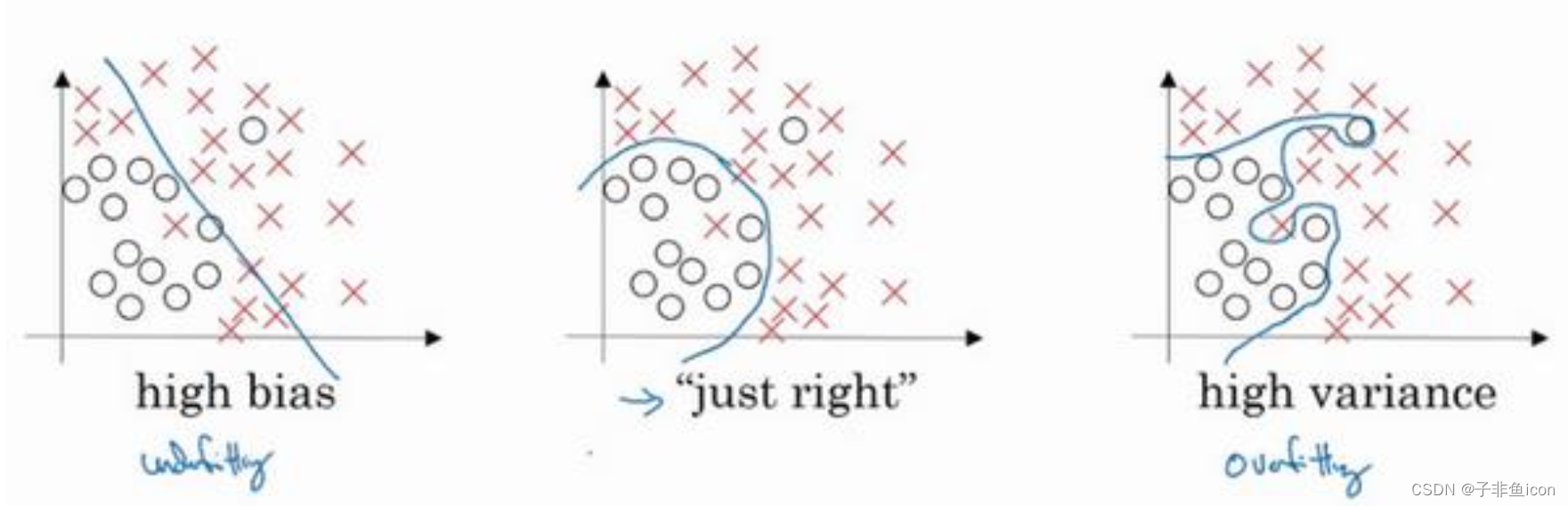
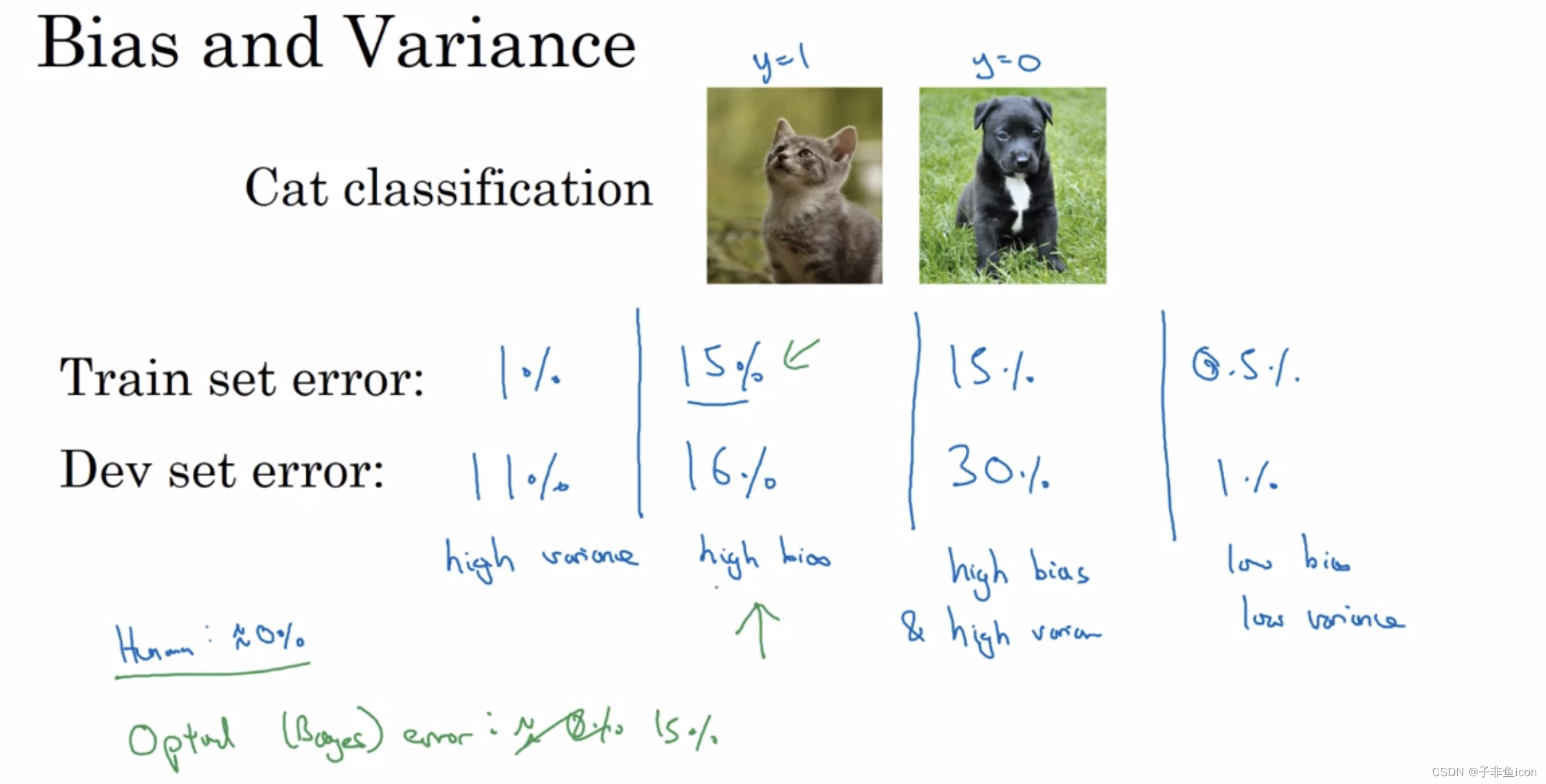
理解偏差和方差的两个关键数据是训练集误差(Train set error)和验证集误差(Dev set error)。
这里沿用的仍然是猫咪图片分类的例子:





三、机器学习基础
解决高方差:扩充数据集、正则化、或者其他模型结构。


四、正则化
4.1 正则化的概念
只正则化参数w,而省略掉参数b,是因为w通常是一个高维参数矢量,已经可以表达高方差的问题。想加上b也没啥问题。
L1正则化,w最终会变得稀疏,也就是w向量中会有很多0。并且这样做,也没有降低太多存储内存。
Frobenius范数:表示一个矩阵中所有元素的平方和。


L2范数正则化也被称之为“权重衰减"。
4.2为什么正则化有利于预防过拟合?
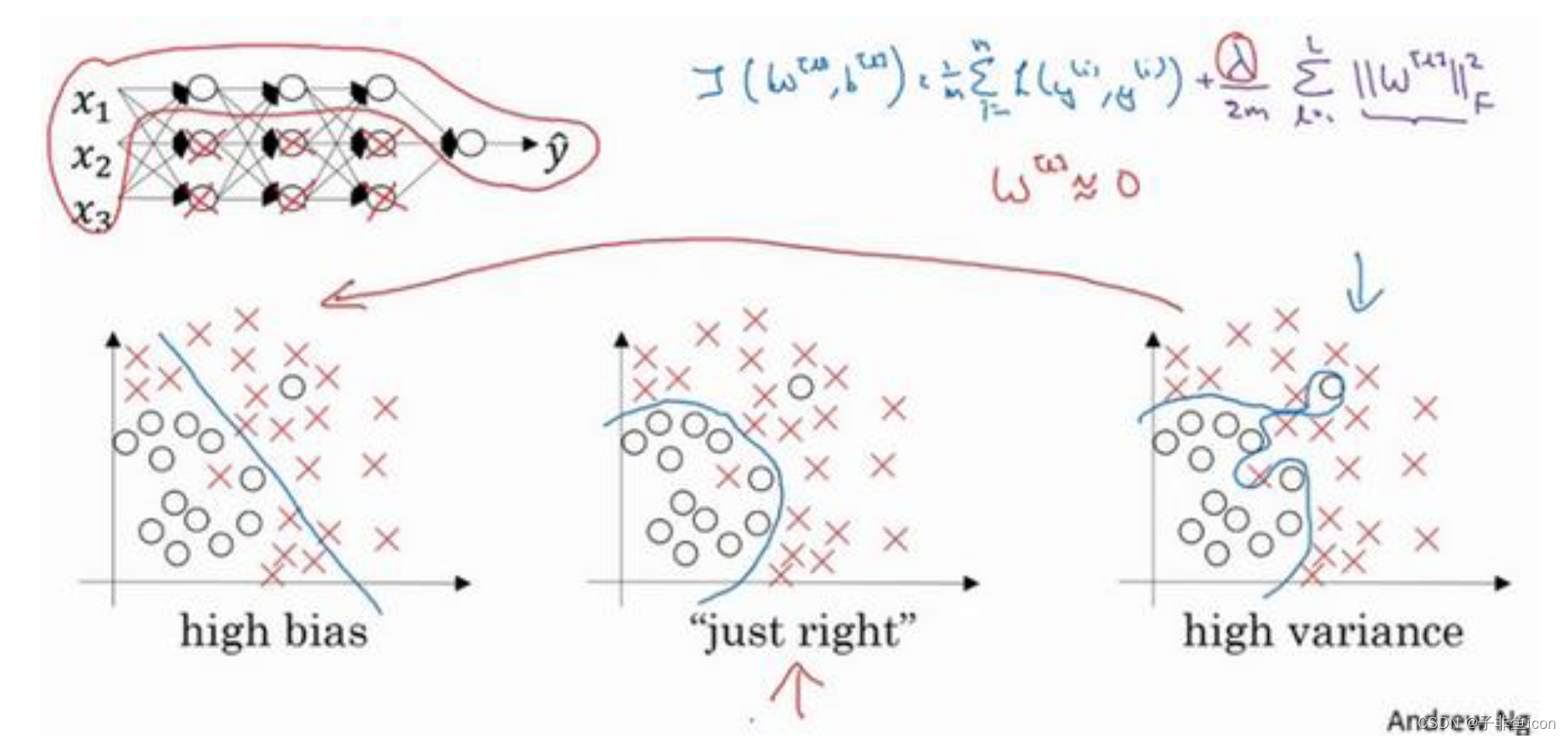
直观上理解就是,如果正则化
λ
\lambda
λ设置的足够大,权重矩阵W就会被设置为接近于0的值,多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。原本一个深度拟合的神经网络,就会变成一个很小的网络,小到如同一个逻辑回归单元。但是深度却依然很大,会使这个网络从过度拟合的状态更接近高偏差状态。

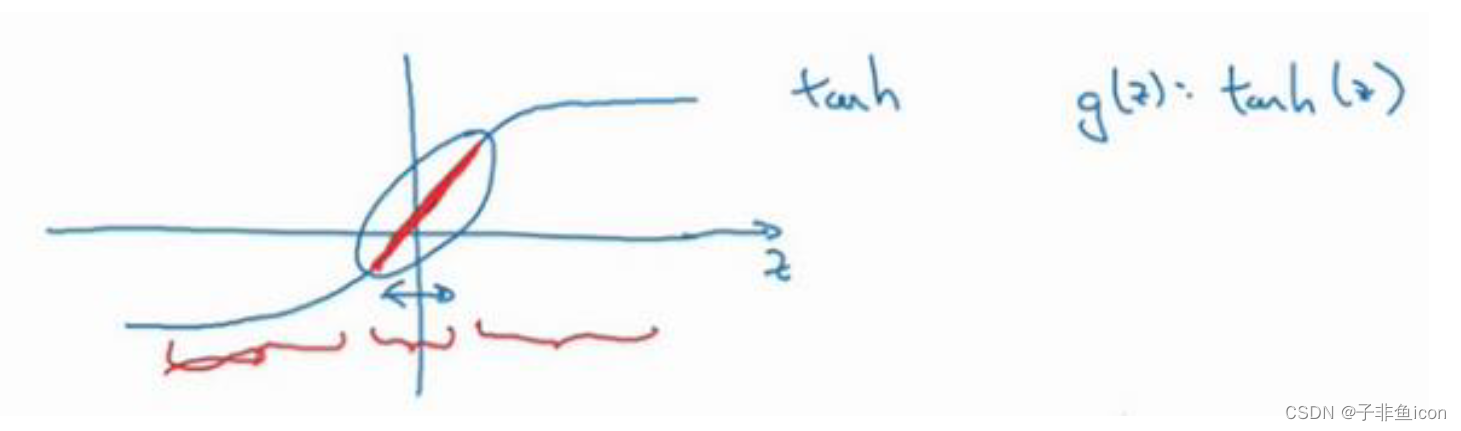
用tanh(z)的激活函数来解释,就是当正则化参数
λ
\lambda
λ设置较大时,激活函数的参数就相对较小,W小,z也会很小,就主要利用了tanh函数的线性部分,每层几乎都是线性的,那就和线性回归函数一样了。因此也就不会发生过拟合。
4.3理解dropout


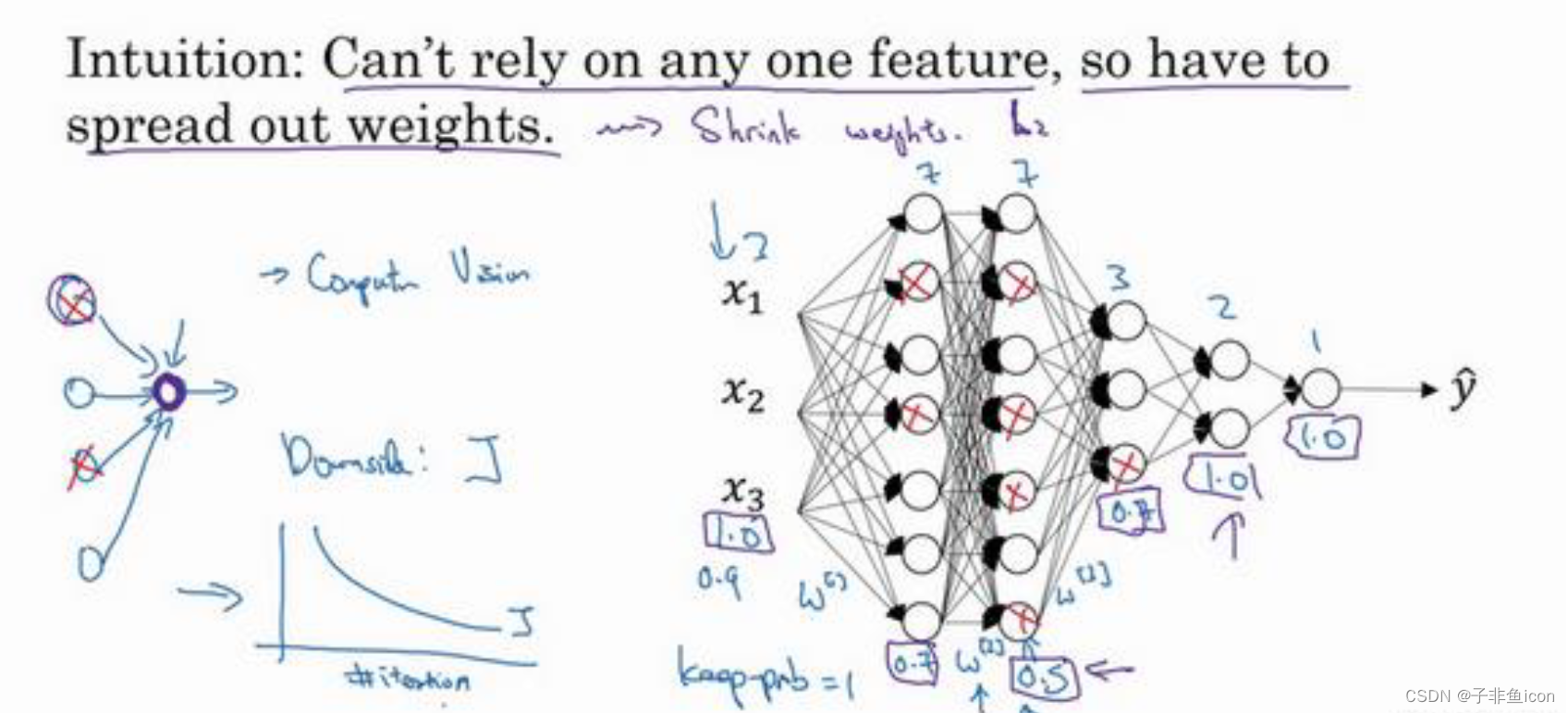

4.4 其他正则化方法
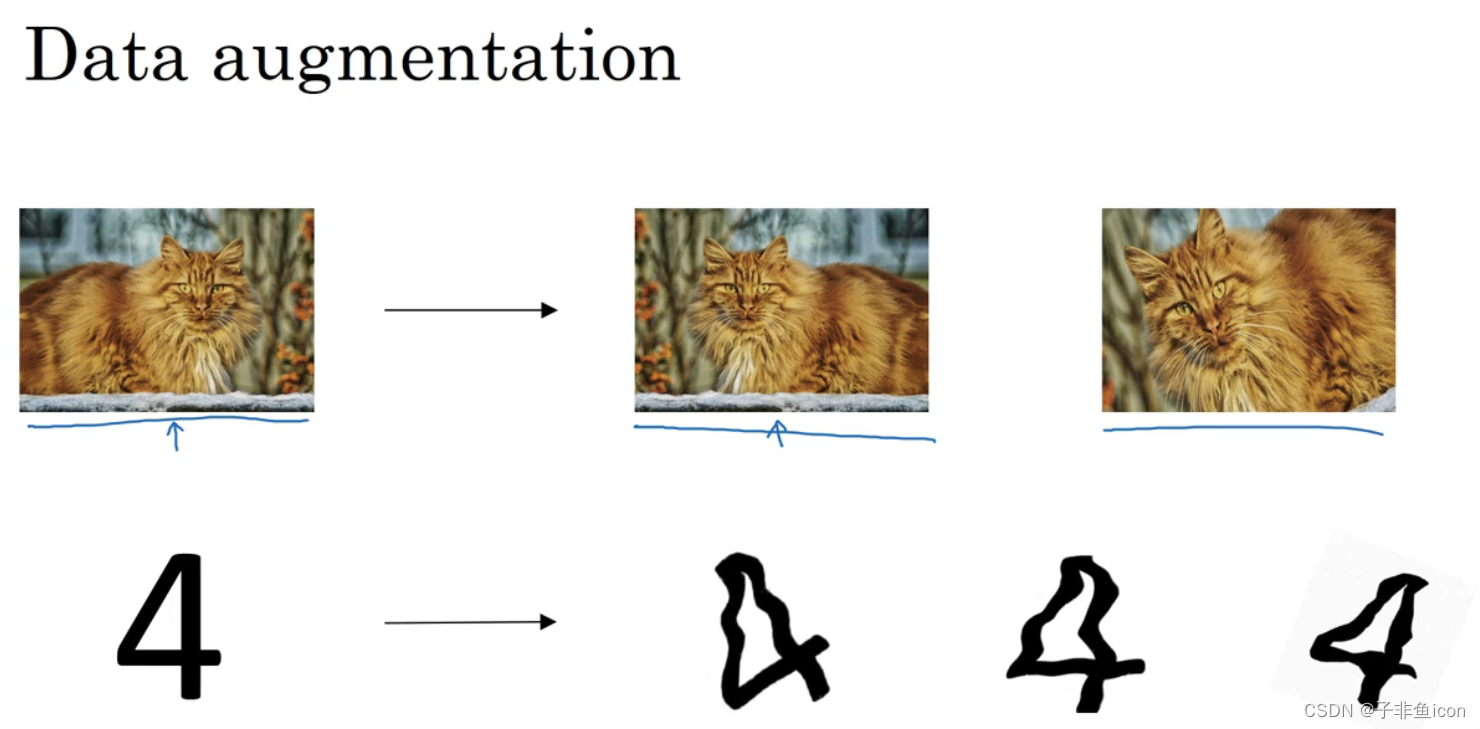
数据扩增
水平翻转图片,训练集增大了一倍。
原图旋转一定角度+裁剪,也能增大数据集,额外生成假训练数据,也可以正则化数据集。
对于光学字符识别,可以通过添加数字、随意旋转或扭曲数字来扩增数据。
early stopping-提早停止训练神经网络

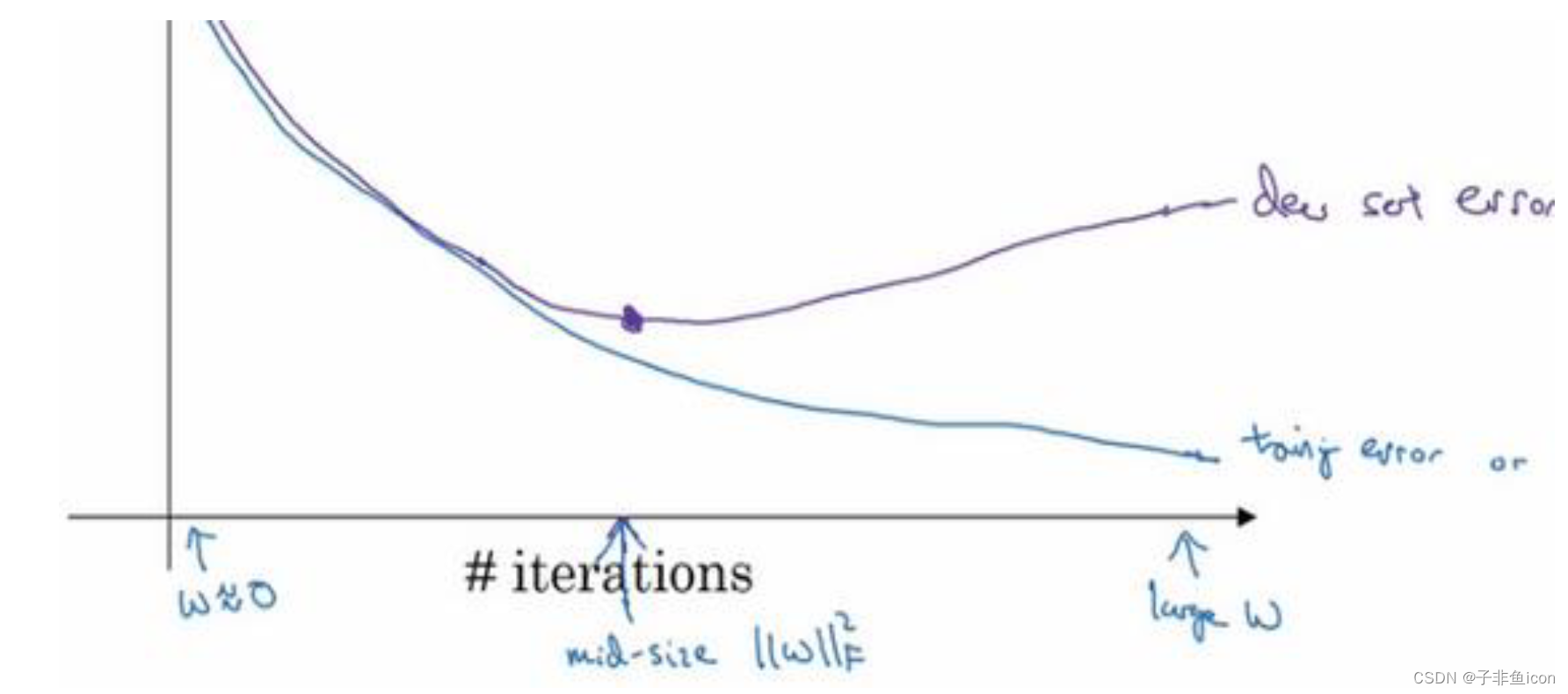
机器学习一般包括几个步骤,如选择一个算法来优化代价函数J,如梯度下降、Adam算法等;然后优化之后,也不想发生过拟合,可以用正则化、扩增数据等来解决。
early stopping 的主要缺点就是不能独立地处理优化代价函数和防止过拟合这两件事。提早停止了梯度下降,也就是停止了优化代价函数J,同时又不希望出现过拟合。也就是说,并没有采取不同的方式来解决这两个问题,而是用同一种方法同时解决两个问题,需要考虑的东西变得更加复杂。
其优点就是:只需要运行一次梯度下降,就可以找到w的较小值,中间值和较大值,而无需L2正则化那样超参数 λ \lambda λ的很多之,计算代价较大。
但是,还是更推荐和倾向于使用L2正则化。
五、归一化输入
两个步骤:
1.零均值
2.归一化方差
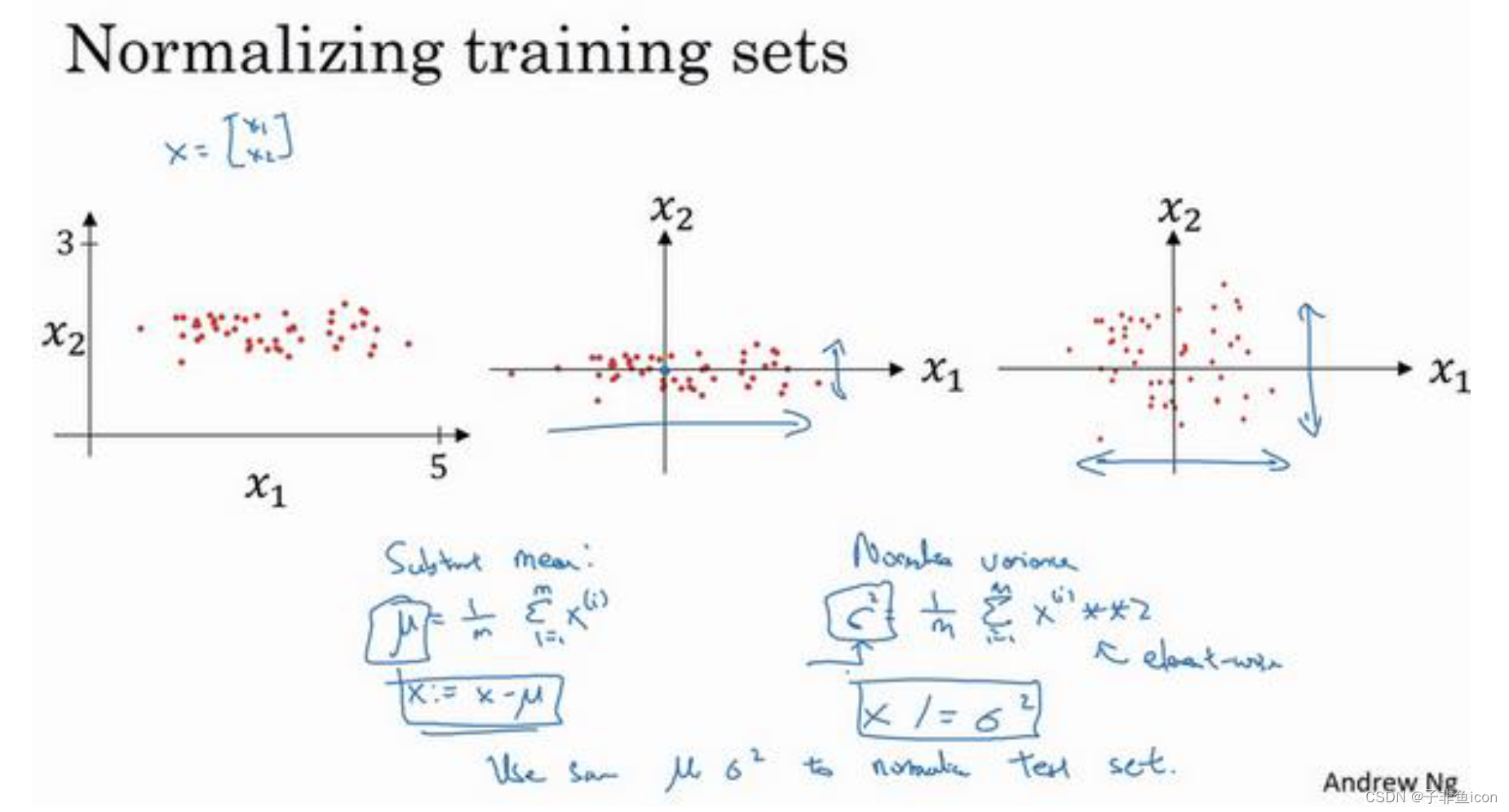
注:训练集和测试集的归一化方式应该相同,其中的
μ
\mu
μ和
σ
2
\sigma^2
σ2是由训练集的数据计算得来的
原因:


六、梯度消失和梯度爆炸
对于一个深度神经网络,激活函数将以与L(层数)相关的指数级增长或下降,也适用于与L相关的导数或梯度函数,也是呈指数级增长或呈指数衰减。
这通常会导致训练难度的上升,尤其是梯度指数小于L时,梯度下降算法的步长将会非常非常小,梯度下降算法会花费很长时间来学习。
七、神经网络的权重初始化
针对梯度消失和梯度爆炸的问题,提出了一个不完整的,但却有用的方案——权重的随机初始化。
即设置某层权重 w [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ∗ n p . s q r t ( 1 n [ l − 1 ] ) w^{[l]}=np.random.randn(shape)*np.sqrt(\frac {1}{n^{[l-1]}}) w[l]=np.random.randn(shape)∗np.sqrt(n[l−1]1), n [ l − 1 ] n^{[l-1]} n[l−1]就是我们喂给第 l l l层神经网络的数量,即第 l − 1 l-1 l−1层神经元数量。
如果用的是Relu函数,方差设置为 2 n [ l − 1 ] \frac{2}{n^{[l-1]}} n[l−1]2,效果更好
如果是tanh函数,可以用 1 n [ l − 1 ] \frac{1}{n^{[l-1]}} n[l−1]1
八、梯度检验
就是利用梯度逼近的方式,去检验此前的梯度计算是否正确,然后根据逼近计算的结果与此前的公式法进行比较,如果差别较大,就需要debug.
一些提示和注意事项:
1.不要在训练中使用梯度检验,只用于调试。它太慢了
2.如果算法的梯度检验失败,要检查所有项,并试着找出bug,也就是哪个导致
d
θ
a
p
p
r
o
x
[
i
]
d\theta_{approx}[i]
dθapprox[i]与
d
θ
[
i
]
d\theta[i]
dθ[i]相差这么多。
3.注意正则化。比如有L2正则化,则一定要包括进来
4.梯度检验不能与dropout同时使用。dropout会随机消除隐藏层单元的不同子集,难以计算dropout在梯度下降上的代价函数J。
5.当w和b接近0时,梯度下降的实施是正确的,但是在运行梯度下降时,w和b变得更大,backprop的实施会变得越来越不准确。可以在随机初始化的过程中,运行梯度检验,然后再训练网络,w和b会有一段时间远离0,如果随机初始化值比较小,反复训练网络之后,再重新运行梯度检验。
九、编程作业
参考链接
9.1 np.nansum()
忽略nan值求和
参考链接
9.2 初始化参数
9.2.1 初始化为0
init_utils:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- sigmoid(x)
"""
s = 1/(1+np.exp(-x))
return s
def relu(x):
"""
Compute the relu of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- relu(x)
"""
s = np.maximum(0,x)
return s
def compute_loss(a3, Y):
"""
Implement the loss function
Arguments:
a3 -- post-activation, output of forward propagation
Y -- "true" labels vector, same shape as a3
Returns:
loss - value of the loss function
"""
m = Y.shape[1]
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
loss = 1./m * np.nansum(logprobs)
return loss
def forward_propagation(X, parameters):
"""
Implements the forward propagation (and computes the loss) presented in Figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape ()
b1 -- bias vector of shape ()
W2 -- weight matrix of shape ()
b2 -- bias vector of shape ()
W3 -- weight matrix of shape ()
b3 -- bias vector of shape ()
Returns:
loss -- the loss function (vanilla logistic loss)
"""
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
z1 = np.dot(W1, X) + b1
a1 = relu(z1)
z2 = np.dot(W2, a1) + b2
a2 = relu(z2)
z3 = np.dot(W3, a2) + b3
a3 = sigmoid(z3)
cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)
return a3, cache
def backward_propagation(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
cache -- cache output from forward_propagation()
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache
dz3 = 1./m * (a3 - Y)
dW3 = np.dot(dz3, a2.T)
db3 = np.sum(dz3, axis=1, keepdims = True)
da2 = np.dot(W3.T, dz3)
dz2 = np.multiply(da2, np.int64(a2 > 0))
dW2 = np.dot(dz2, a1.T)
db2 = np.sum(dz2, axis=1, keepdims = True)
da1 = np.dot(W2.T, dz2)
dz1 = np.multiply(da1, np.int64(a1 > 0))
dW1 = np.dot(dz1, X.T)
db1 = np.sum(dz1, axis=1, keepdims = True)
gradients = {"dz3": dz3, "dW3": dW3, "db3": db3,
"da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2,
"da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1}
return gradients
def update_parameters(parameters, grads, learning_rate):
"""
Update parameters using gradient descent
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients, output of n_model_backward
Returns:
parameters -- python dictionary containing your updated parameters
parameters['W' + str(i)] = ...
parameters['b' + str(i)] = ...
"""
L = len(parameters) // 2 # number of layers in the neural networks
# Update rule for each parameter
for k in range(L):
parameters["W" + str(k+1)] = parameters["W" + str(k+1)] - learning_rate * grads["dW" + str(k+1)]
parameters["b" + str(k+1)] = parameters["b" + str(k+1)] - learning_rate * grads["db" + str(k+1)]
return parameters
def predict(X, y, parameters):
"""
This function is used to predict the results of a n-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
p = np.zeros((1,m), dtype = np.int)
# Forward propagation
a3, caches = forward_propagation(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, a3.shape[1]):
if a3[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
# print results
print("Accuracy: " + str(np.mean((p[0,:] == y[0,:]))))
return p
def load_dataset(is_plot=True):
np.random.seed(1)
train_X, train_Y = sklearn.datasets.make_circles(n_samples=300, noise=.05)
np.random.seed(2)
test_X, test_Y = sklearn.datasets.make_circles(n_samples=100, noise=.05)
# Visualize the data
if is_plot:
plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y, s=40, cmap=plt.cm.Spectral)
plt.show()
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
test_X = test_X.T
test_Y = test_Y.reshape((1, test_Y.shape[0]))
return train_X, train_Y, test_X, test_Y
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)
plt.show()
def predict_dec(parameters, X):
"""
Used for plotting decision boundary.
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (m, K)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3>0.5)
return predictions
代码:
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import init_utils #第一部分,初始化
import reg_utils #第二部分,正则化
import gc_utils #第三部分,梯度校验
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 初始化参数
# 读取并绘制数据
train_X, train_Y, test_X, test_Y = init_utils.load_dataset(is_plot=True)
# 模型
def model(X, Y, learning_rate=0.01, num_iterations=15000, print_cost=True, initialization="he", is_polt=True):
grads = {}
costs = []
m = X.shape[1]
layers_dims = [X.shape[0], 10, 5, 1]
# 选择初始化参数的类型
if initialization == "zeros":
parameters = initialize_parameters_zeros(layers_dims)
elif initialization == "random":
parameters = initialize_parameters_random(layers_dims)
elif initialization == "he":
parameters = initialize_parameters_he(layers_dims)
else:
print("错误的初始化参数!程序退出")
exit
# 开始学习
for i in range(0, num_iterations):
# 前向传播
a3, cache = init_utils.forward_propagation(X, parameters)
# 计算成本
cost = init_utils.compute_loss(a3, Y)
# 反向传播
grads = init_utils.backward_propagation(X, Y, cache)
# 更新参数
parameters = init_utils.update_parameters(parameters, grads, learning_rate)
# 记录成本
if i % 1000 == 0:
costs.append(cost)
# 打印成本
if print_cost:
print("第" + str(i) + "次迭代,成本值为:" + str(cost))
# 学习完毕,绘制成本曲线
if is_polt:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# 返回学习完毕后的参数
return parameters
# 三种初始化方法:1.初始化为0;2.初始化为随机数;3.抑梯度异常初始化
# 初始化为0
def initialize_parameters_zeros(layers_dims):
parameters = {}
L = len(layers_dims)
for l in range(1, L):
parameters["W" + str(l)] = np.zeros((layers_dims[l], layers_dims[l-1]))
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1))
assert(parameters["W" + str(l)].shape == (layers_dims[l], layers_dims[l-1]))
assert(parameters["b" + str(l)].shape == (layers_dims[l], 1))
return parameters
def initialize_parameters_random(layers_dims):
pass
def initialize_parameters_he(layers_dims):
pass
# 测试初始化的效果
parameters = model(train_X, train_Y, initialization = "zeros",is_polt=True)
print ("训练集:")
predictions_train = init_utils.predict(train_X, train_Y, parameters)
print ("测试集:")
predictions_test = init_utils.predict(test_X, test_Y, parameters)
输出:
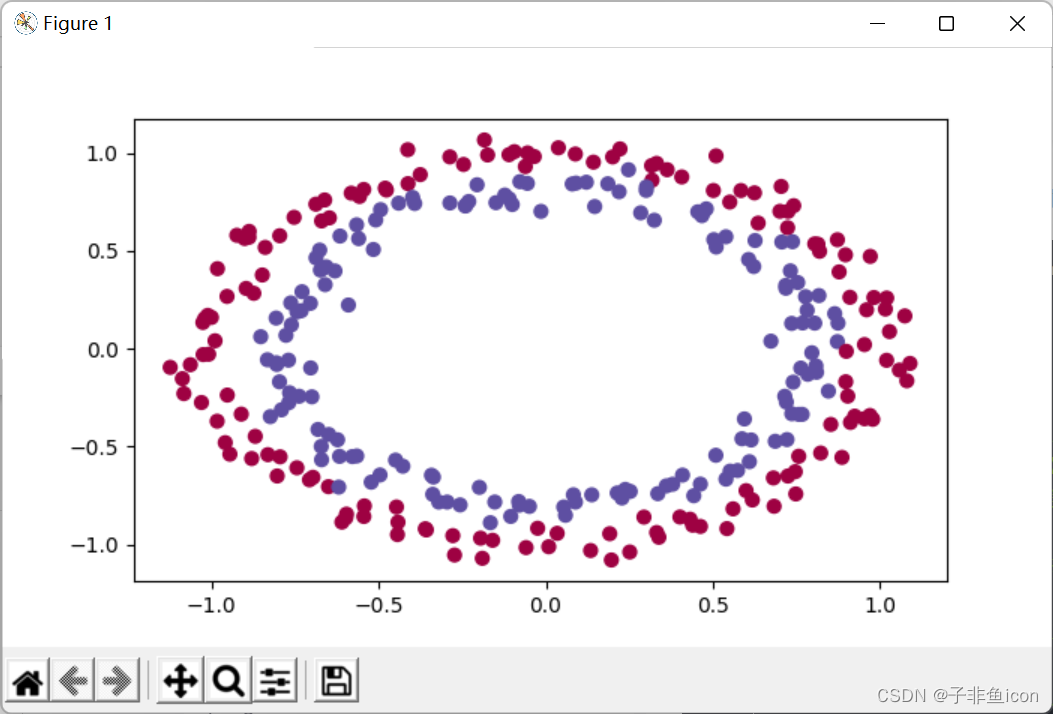
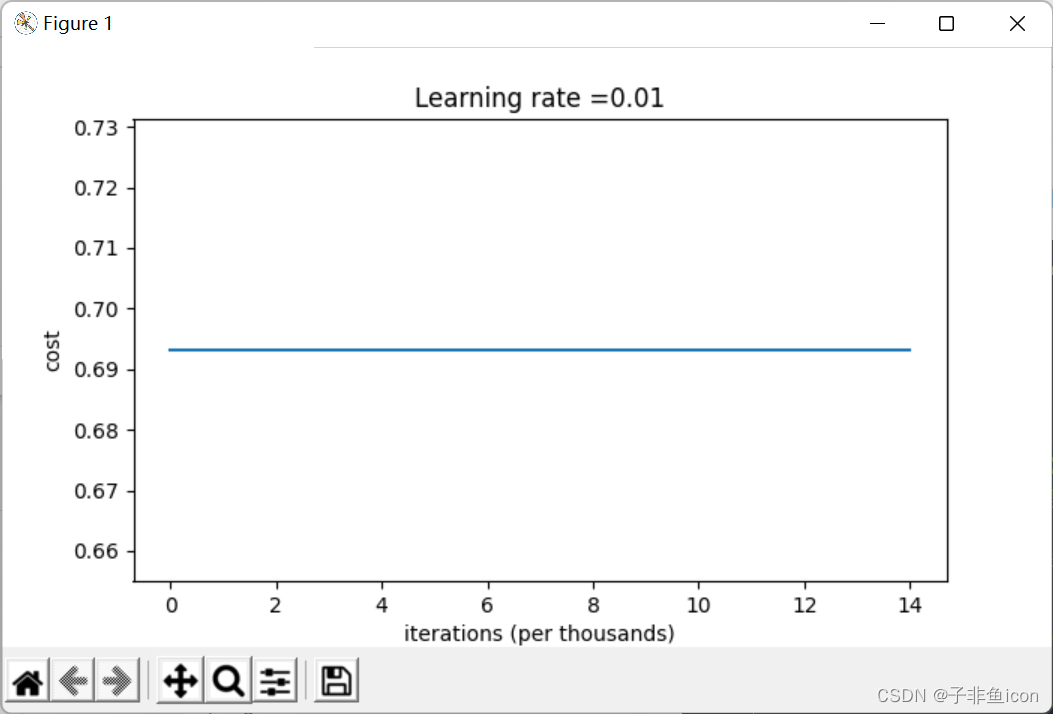
第0次迭代,成本值为:0.6931471805599453
第1000次迭代,成本值为:0.6931471805599453
第2000次迭代,成本值为:0.6931471805599453
第3000次迭代,成本值为:0.6931471805599453
第4000次迭代,成本值为:0.6931471805599453
第5000次迭代,成本值为:0.6931471805599453
第6000次迭代,成本值为:0.6931471805599453
第7000次迭代,成本值为:0.6931471805599453
第8000次迭代,成本值为:0.6931471805599453
第9000次迭代,成本值为:0.6931471805599453
第10000次迭代,成本值为:0.6931471805599455
第11000次迭代,成本值为:0.6931471805599453
第12000次迭代,成本值为:0.6931471805599453
第13000次迭代,成本值为:0.6931471805599453
第14000次迭代,成本值为:0.6931471805599453
训练集:
Accuracy: 0.5
测试集:
Accuracy: 0.5
学习率,无变化,模型没有学习,成本没有下降,预测结果差。
看看预测和决策边界:
# 查看细节
print("predictions_train = " + str(predictions_train))
print("predictions_test = " + str(predictions_test))
plt.title("Model with Zeros initialization")
axes = plt.gca()
axes.set_xlim([-1.5, 1.5])
axes.set_ylim([-1.5, 1.5])
init_utils.plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
输出:
predictions_train = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0]]
predictions_test = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
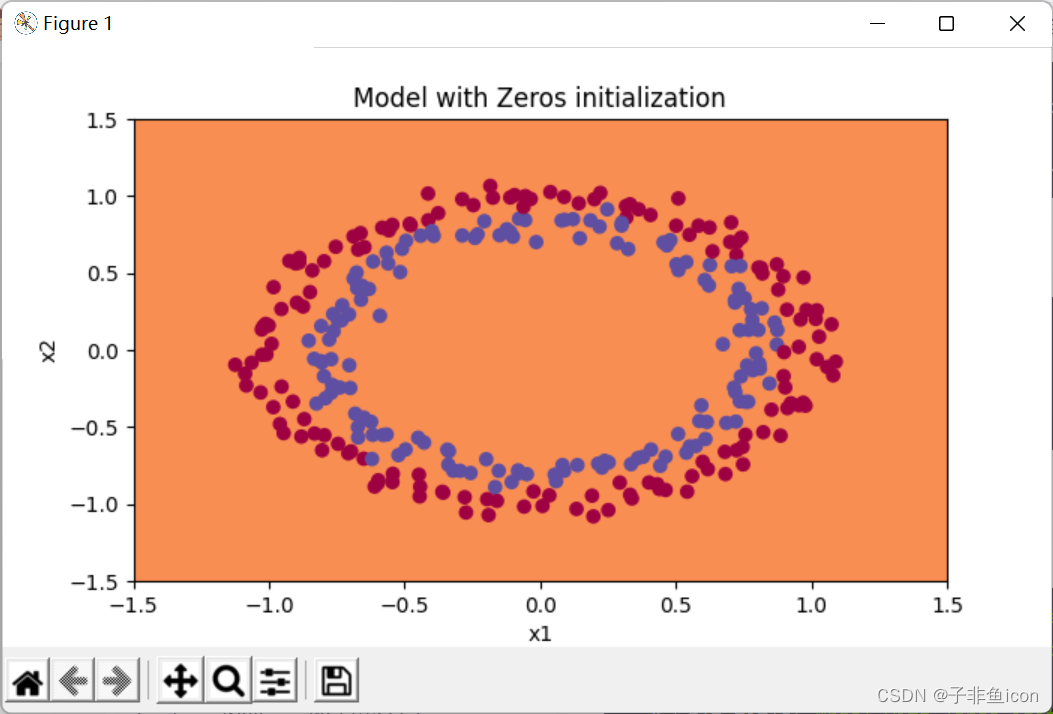
分类失败,该模型预测每个都为0。通常来说,零初始化都会导致神经网络无法打破对称性,最终导致的结果就是无论网络有多少层,最终只能得到和Logistic函数相同的效果。
9.2.2 随机初始化
# 随机初始化
def initialize_parameters_random(layers_dims):
np.random.seed(3)
parameters = {}
L = len(layers_dims)
for l in range(1, L):
parameters["W" + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * 10
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1))
assert(parameters["W" + str(l)].shape == (layers_dims[l], layers_dims[l-1]))
assert(parameters["b" + str(l)].shape == (layers_dims[l], 1))
return parameters
结果:
第0次迭代,成本值为:inf
D:\PyCharm files\deep learning\吴恩达\L2W1\init_utils.py:50: RuntimeWarning: divide by zero encountered in log
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
D:\PyCharm files\deep learning\吴恩达\L2W1\init_utils.py:50: RuntimeWarning: invalid value encountered in multiply
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
第1000次迭代,成本值为:0.6232304162390595
第2000次迭代,成本值为:0.5979027246562124
第3000次迭代,成本值为:0.563641114770631
第4000次迭代,成本值为:0.5500921501952366
第5000次迭代,成本值为:0.5443409879101093
第6000次迭代,成本值为:0.5373540362017244
第7000次迭代,成本值为:0.46969949173370784
第8000次迭代,成本值为:0.3976544824269067
第9000次迭代,成本值为:0.3934446152358788
第10000次迭代,成本值为:0.3920117708228937
第11000次迭代,成本值为:0.3890994673522727
第12000次迭代,成本值为:0.38612917101580696
第13000次迭代,成本值为:0.38497312801494443
第14000次迭代,成本值为:0.3827582473209904
训练集:
Accuracy: 0.83
测试集:
Accuracy: 0.86
predictions_train = [[1 0 1 1 0 0 1 1 1 1 1 0 1 0 0 1 0 1 1 0 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 1
1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 1 1 0 0 1 1 1 1 0 1 1 0 1 0 1 1 1 1 0
0 0 0 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 0 0 1 1 1 0 1 1 0 1 0 1 1 0 1 1 0
1 0 1 1 0 0 1 0 0 1 1 0 1 1 1 0 1 0 0 1 0 1 1 1 1 1 1 1 0 1 1 0 0 1 1 0
0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 0 1 1 0 1 0 1 1 0 1 0 1 1 1 1 0 1 1 1
1 0 1 0 1 0 1 1 1 1 0 1 1 0 1 1 0 1 1 0 1 0 1 1 1 0 1 1 1 0 1 0 1 0 0 1
0 1 1 0 1 1 0 1 1 0 1 1 1 0 1 1 1 1 0 1 0 0 1 1 0 1 1 1 0 0 0 1 1 0 1 1
1 1 0 1 1 0 1 1 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 1 1 1
1 1 1 1 0 0 0 1 1 1 1 0]]
predictions_test = [[1 1 1 1 0 1 0 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 1 0 1 0 1 1 1 1 1 0 0 0 0 1
0 1 1 0 0 1 1 1 1 1 0 1 1 1 0 1 0 1 1 0 1 0 1 0 1 1 1 1 1 1 1 1 1 0 1 0
1 1 1 1 1 0 1 0 0 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 0]]
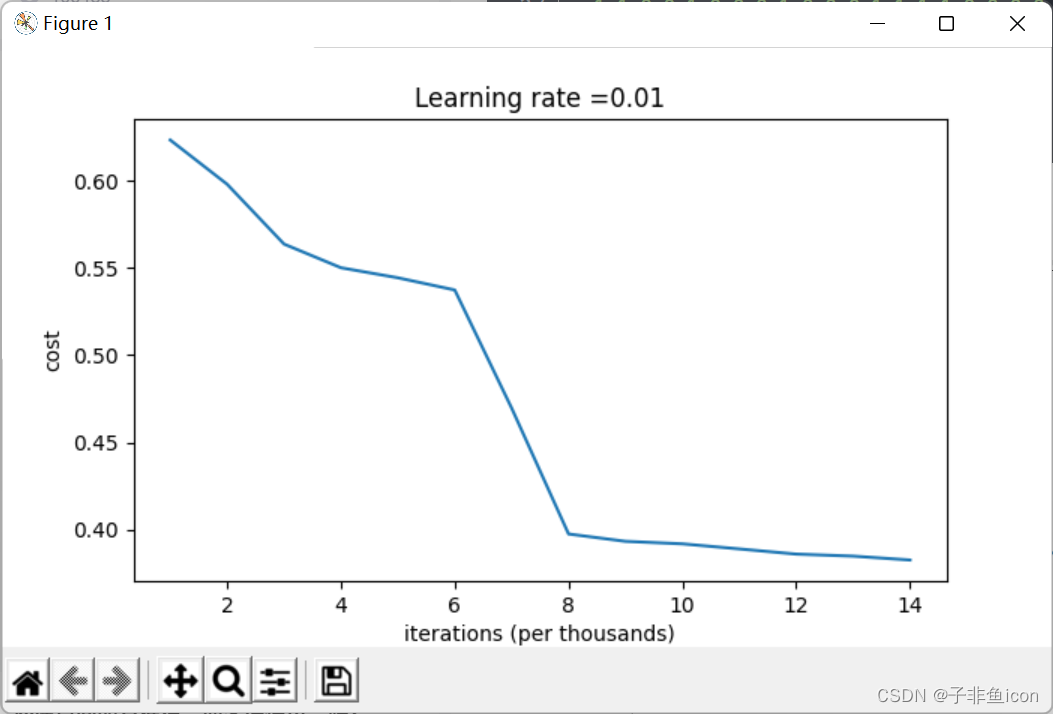
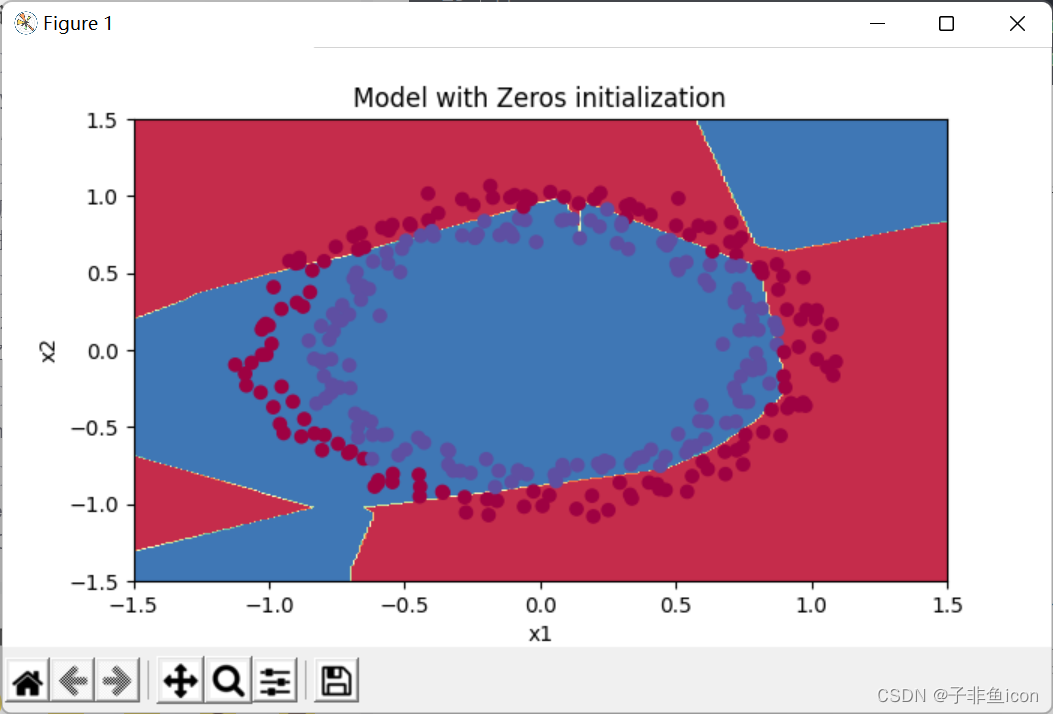
我们可以看到误差开始很高。这是因为由于具有较大的随机权重,最后一个激活(sigmoid)输出的结果非常接近于0或1,而当它出现错误时,它会导致非常高的损失。初始化参数如果没有很好地话会导致梯度消失、爆炸,这也会减慢优化算法。如果我们对这个网络进行更长时间的训练,我们将看到更好的结果,但是使用过大的随机数初始化会减慢优化的速度。
9.2.3 抑梯度异常初始化
def initialize_parameters_he(layers_dims):
np.random.seed(3)
parameters = {}
L = len(layers_dims)
for l in range(1, L):
parameters["W" + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * np.sqrt(2 / layers_dims[l-1])
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1))
assert(parameters["W" + str(l)].shape == (layers_dims[l], layers_dims[l-1]))
assert(parameters["b" + str(l)].shape == (layers_dims[l], 1))
return parameters
输出:
第0次迭代,成本值为:0.8830537463419761
第1000次迭代,成本值为:0.6879825919728063
第2000次迭代,成本值为:0.6751286264523371
第3000次迭代,成本值为:0.6526117768893807
第4000次迭代,成本值为:0.6082958970572938
第5000次迭代,成本值为:0.5304944491717495
第6000次迭代,成本值为:0.4138645817071794
第7000次迭代,成本值为:0.3117803464844441
第8000次迭代,成本值为:0.23696215330322556
第9000次迭代,成本值为:0.1859728720920683
第10000次迭代,成本值为:0.1501555628037181
第11000次迭代,成本值为:0.12325079292273544
第12000次迭代,成本值为:0.0991774654652593
第13000次迭代,成本值为:0.08457055954024273
第14000次迭代,成本值为:0.07357895962677359
训练集:
Accuracy: 0.9933333333333333
测试集:
Accuracy: 0.96
predictions_train = [[1 0 1 1 0 0 1 0 1 1 1 0 1 0 0 0 0 1 1 0 1 0 1 0 0 0 1 0 1 1 0 1 1 0 0 0
0 1 0 1 1 1 1 0 0 1 1 1 0 1 0 1 1 1 1 0 0 1 1 1 1 1 0 1 0 1 0 1 0 1 1 0
0 0 0 0 1 0 0 0 1 0 1 0 0 1 1 1 1 1 1 0 0 0 1 1 0 1 1 0 1 0 0 1 0 1 1 0
0 0 1 1 0 0 1 0 0 1 0 0 1 1 1 0 0 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 0 0 0 0
0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 0 1 0 1 1 0 1 0 1 1 0 1 1 1 1 0 1 0 0 1 0
1 0 0 0 1 0 1 1 1 0 0 1 1 0 0 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 0 1 0 0 1
0 1 0 0 0 1 1 1 1 0 1 0 0 1 1 0 0 1 0 1 0 0 1 0 0 1 1 0 0 0 0 1 1 0 1 0
1 1 0 1 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 1 1 1 1 0 0 0 0 0 1 1 0 0 1 1 1 1
1 1 1 0 0 0 0 1 1 0 1 0]]
predictions_test = [[1 0 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 0 0 1 0 0 0 0 1 1 1 1 0 1 0 0 1
0 1 1 0 0 1 1 1 1 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 0
1 1 1 1 0 1 1 0 0 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 0 0 0 0]]
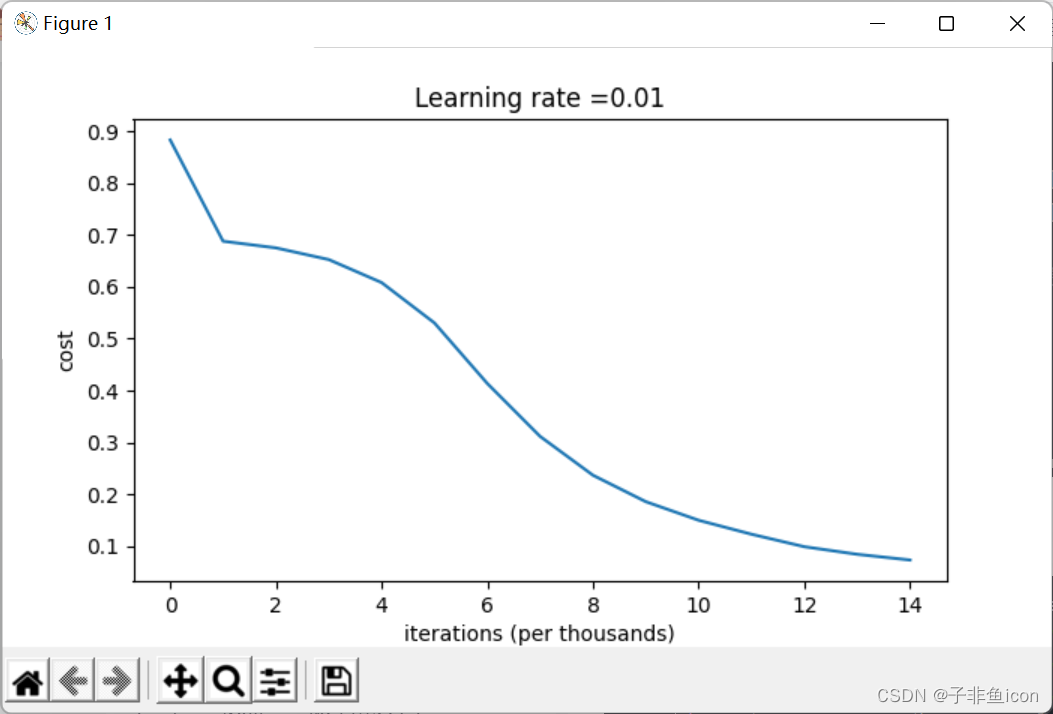
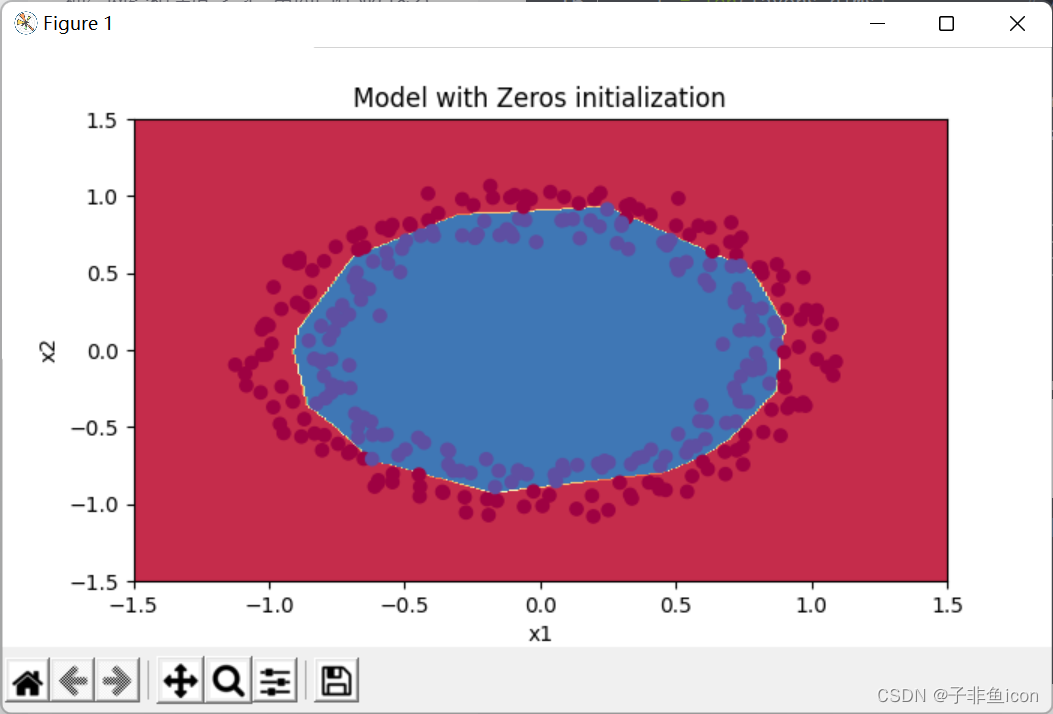
1.不同的初始化方法可能导致性能最终不同
2.随机初始化有助于打破对称,使得不同隐藏层的单元可以学习到不同的参数。
3.初始化时,初始值不宜过大。
4.He初始化搭配ReLU激活函数常常可以得到不错的效果。
9.3 正则化
9.3.1 不使用正则化
reg_utils:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- sigmoid(x)
"""
s = 1/(1+np.exp(-x))
return s
def relu(x):
"""
Compute the relu of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- relu(x)
"""
s = np.maximum(0,x)
return s
def initialize_parameters(layer_dims):
"""
Arguments:
layer_dims -- python array (list) containing the dimensions of each layer in our network
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layer_dims[l], layer_dims[l-1])
b1 -- bias vector of shape (layer_dims[l], 1)
Wl -- weight matrix of shape (layer_dims[l-1], layer_dims[l])
bl -- bias vector of shape (1, layer_dims[l])
Tips:
- For example: the layer_dims for the "Planar Data classification model" would have been [2,2,1].
This means W1's shape was (2,2), b1 was (1,2), W2 was (2,1) and b2 was (1,1). Now you have to generalize it!
- In the for loop, use parameters['W' + str(l)] to access Wl, where l is the iterative integer.
"""
np.random.seed(3)
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) / np.sqrt(layer_dims[l-1])
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == layer_dims[l], layer_dims[l-1])
assert(parameters['W' + str(l)].shape == layer_dims[l], 1)
return parameters
def forward_propagation(X, parameters):
"""
Implements the forward propagation (and computes the loss) presented in Figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape ()
b1 -- bias vector of shape ()
W2 -- weight matrix of shape ()
b2 -- bias vector of shape ()
W3 -- weight matrix of shape ()
b3 -- bias vector of shape ()
Returns:
loss -- the loss function (vanilla logistic loss)
"""
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
z1 = np.dot(W1, X) + b1
a1 = relu(z1)
z2 = np.dot(W2, a1) + b2
a2 = relu(z2)
z3 = np.dot(W3, a2) + b3
a3 = sigmoid(z3)
cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)
return a3, cache
def compute_cost(a3, Y):
"""
Implement the cost function
Arguments:
a3 -- post-activation, output of forward propagation
Y -- "true" labels vector, same shape as a3
Returns:
cost - value of the cost function
"""
m = Y.shape[1]
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
cost = 1./m * np.nansum(logprobs)
return cost
def backward_propagation(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
cache -- cache output from forward_propagation()
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache
dz3 = 1./m * (a3 - Y)
dW3 = np.dot(dz3, a2.T)
db3 = np.sum(dz3, axis=1, keepdims = True)
da2 = np.dot(W3.T, dz3)
dz2 = np.multiply(da2, np.int64(a2 > 0))
dW2 = np.dot(dz2, a1.T)
db2 = np.sum(dz2, axis=1, keepdims = True)
da1 = np.dot(W2.T, dz2)
dz1 = np.multiply(da1, np.int64(a1 > 0))
dW1 = np.dot(dz1, X.T)
db1 = np.sum(dz1, axis=1, keepdims = True)
gradients = {"dz3": dz3, "dW3": dW3, "db3": db3,
"da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2,
"da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1}
return gradients
def update_parameters(parameters, grads, learning_rate):
"""
Update parameters using gradient descent
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients, output of n_model_backward
Returns:
parameters -- python dictionary containing your updated parameters
parameters['W' + str(i)] = ...
parameters['b' + str(i)] = ...
"""
L = len(parameters) // 2 # number of layers in the neural networks
# Update rule for each parameter
for k in range(L):
parameters["W" + str(k+1)] = parameters["W" + str(k+1)] - learning_rate * grads["dW" + str(k+1)]
parameters["b" + str(k+1)] = parameters["b" + str(k+1)] - learning_rate * grads["db" + str(k+1)]
return parameters
def load_2D_dataset(is_plot=True):
data = sio.loadmat('datasets/data.mat')
train_X = data['X'].T
train_Y = data['y'].T
test_X = data['Xval'].T
test_Y = data['yval'].T
if is_plot:
plt.scatter(train_X[0, :], train_X[1, :], c=train_Y, s=40, cmap=plt.cm.Spectral)
plt.show()
return train_X, train_Y, test_X, test_Y
def predict(X, y, parameters):
"""
This function is used to predict the results of a n-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
p = np.zeros((1,m), dtype = np.int)
# Forward propagation
a3, caches = forward_propagation(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, a3.shape[1]):
if a3[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
# print results
print("Accuracy: " + str(np.mean((p[0,:] == y[0,:]))))
return p
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)
plt.show()
def predict_dec(parameters, X):
"""
Used for plotting decision boundary.
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (m, K)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3>0.5)
return predictions
代码:
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import init_utils #第一部分,初始化
import reg_utils #第二部分,正则化
import gc_utils #第三部分,梯度校验
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 查看数据集
train_X, train_Y, test_X, test_Y = reg_utils.load_2D_dataset(is_plot=True)
# 模型
def model(X, Y, learning_rate=0.3, num_iterations=30000, print_cost=True, is_plot=True, lambd=0, keep_prob=1):
grads = {}
costs = []
m = X.shape[1]
layers_dims = [X.shape[0], 20, 3, 1]
# 初始化参数
parameters = reg_utils.initialize_parameters(layers_dims)
# 开始学习
for i in range(0, num_iterations):
# 前向传播
# 是否随机删除节点
if keep_prob == 1:
# 不随机删除节点
a3, cache = reg_utils.forward_propagation(X, parameters)
elif keep_prob < 1:
###随机删除节点
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
else:
print("keep_prob参数错误!程序退出。")
exit
# 计算成本
# 是否使用二范数
if lambd == 0:
# 不使用L2正则化
cost = reg_utils.compute_cost(a3, Y)
else:
# 使用L2正则化
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
# 反向传播
# 可以同时使用L2正则化和随机删除节点,但是本次实验不同时使用。
assert (lambd == 0 or keep_prob == 1)
# 两个参数的使用情况
if (lambd == 0 and keep_prob == 1):
# 不使用L2正则化和不使用随机删除节点
grads = reg_utils.backward_propagation(X, Y, cache)
elif lambd != 0:
# 使用L2正则化,不使用随机删除节点
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
# 使用随机删除节点,不使用L2正则化
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
# 更新参数
parameters = reg_utils.update_parameters(parameters, grads, learning_rate)
# 记录并打印成本
if i % 1000 == 0:
## 记录成本
costs.append(cost)
if (print_cost and i % 10000 == 0):
# 打印成本
print("第" + str(i) + "次迭代,成本值为:" + str(cost))
# 是否绘制成本曲线图
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# 返回学习后的参数
return parameters
def forward_propagation_with_dropout(X, parameters, keep_prob):
pass
def compute_cost_with_regularization(a3, Y, parameters, lambd):
pass
def backward_propagation_with_regularization(X, Y, cache, lambd):
pass
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
pass
# 不使用正则化
parameters = model(train_X, train_Y,is_plot=True)
print("训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
# 画出分割曲线
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
输出:
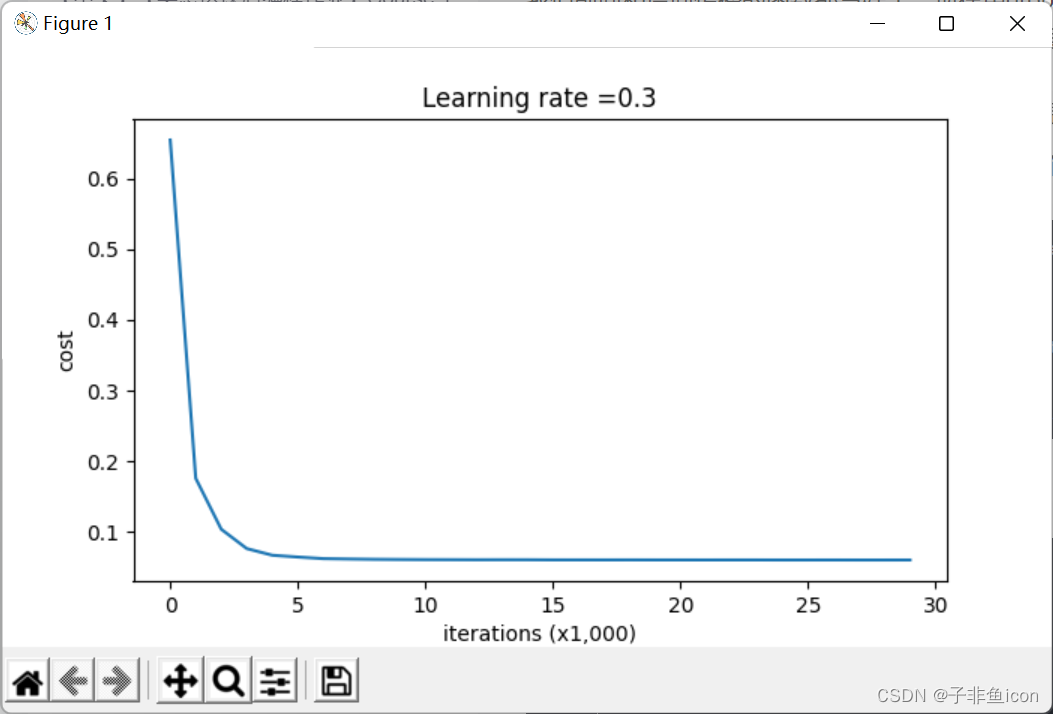
第0次迭代,成本值为:0.6557412523481002
第10000次迭代,成本值为:0.16329987525724213
第20000次迭代,成本值为:0.1385164242325263
训练集:
Accuracy: 0.9478672985781991
测试集:
Accuracy: 0.915
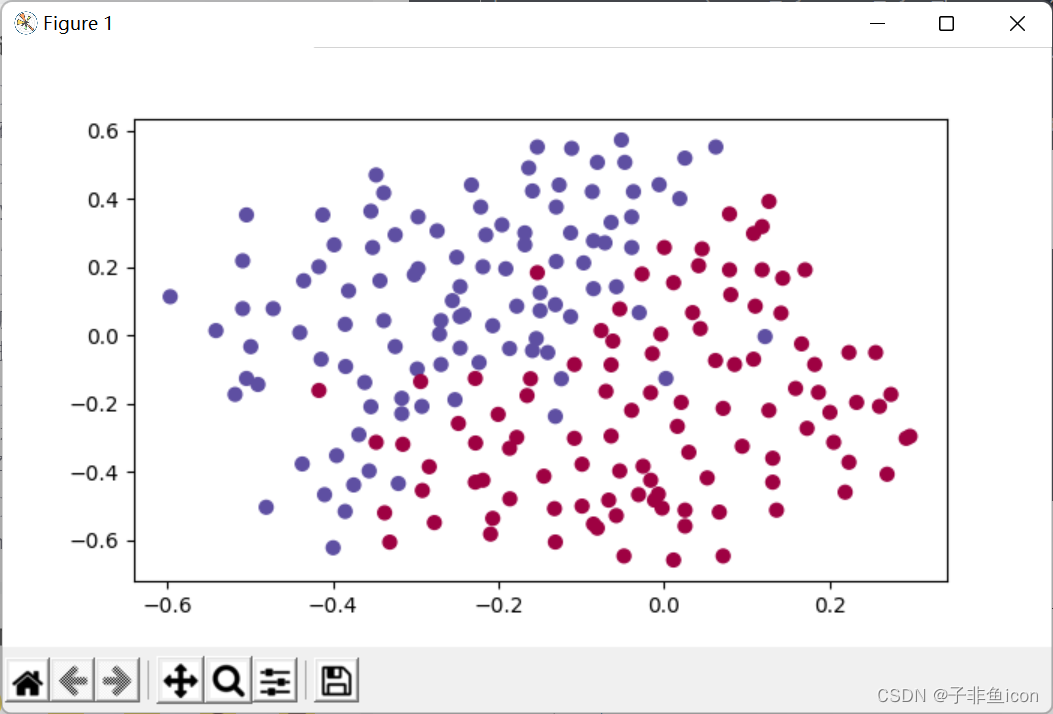
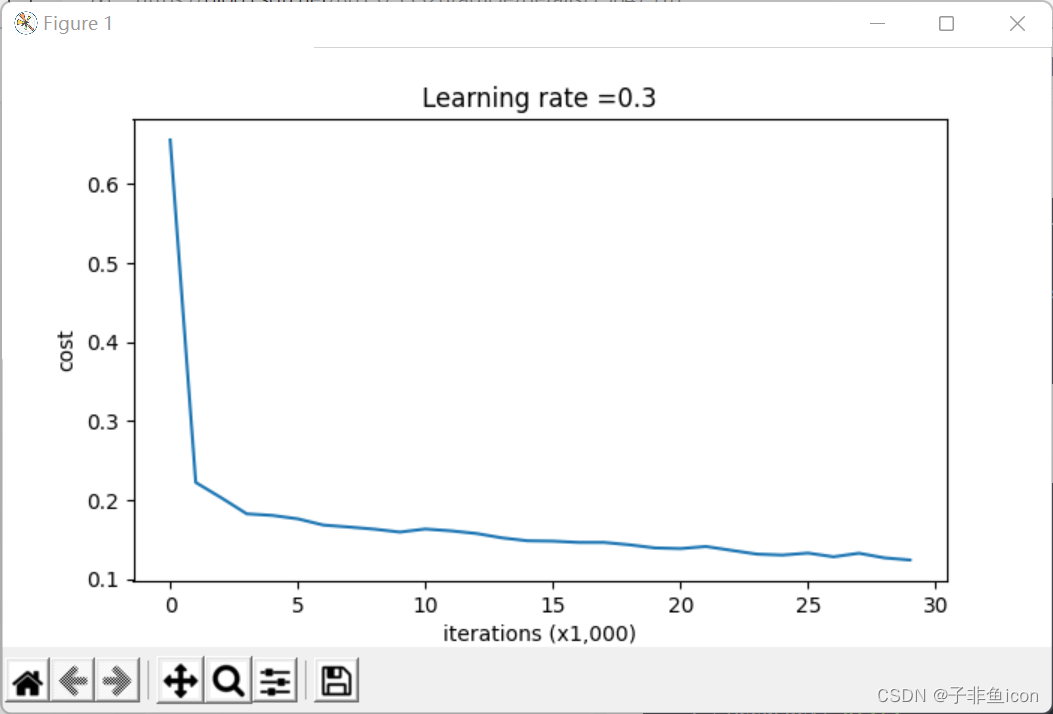
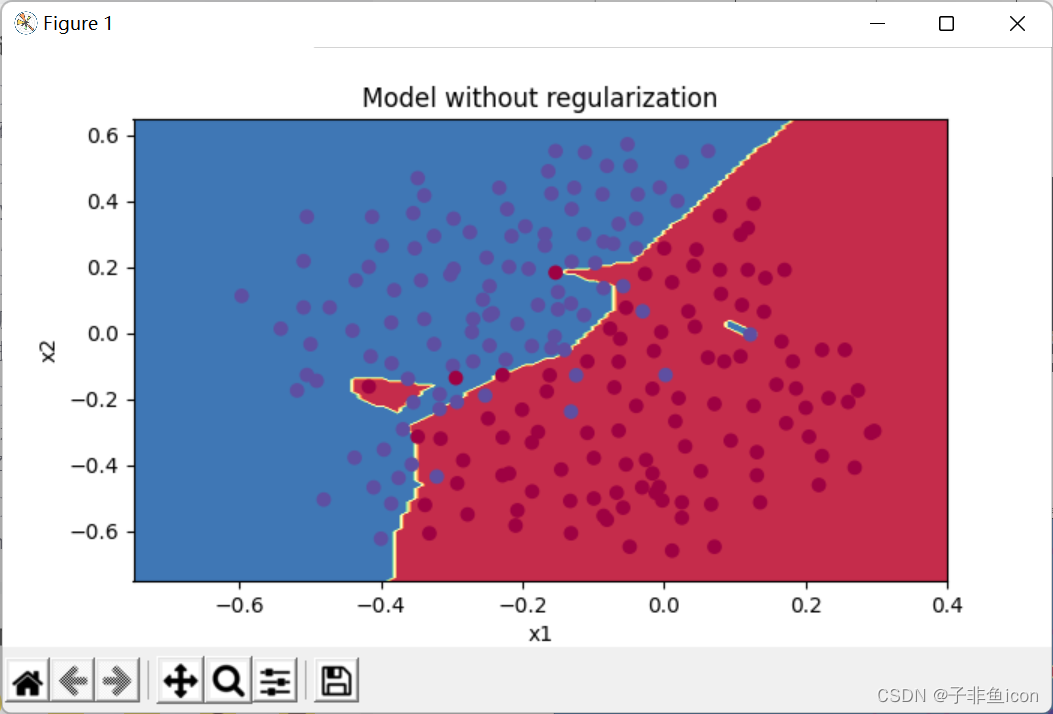
分割曲线有过拟合现象。
9.3.2 使用L2正则化
代码:
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import init_utils #第一部分,初始化
import reg_utils #第二部分,正则化
import gc_utils #第三部分,梯度校验
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 查看数据集
train_X, train_Y, test_X, test_Y = reg_utils.load_2D_dataset(is_plot=True)
# 模型
def model(X, Y, learning_rate=0.3, num_iterations=30000, print_cost=True, is_plot=True, lambd=0, keep_prob=1):
grads = {}
costs = []
m = X.shape[1]
layers_dims = [X.shape[0], 20, 3, 1]
# 初始化参数
parameters = reg_utils.initialize_parameters(layers_dims)
# 开始学习
for i in range(0, num_iterations):
# 前向传播
# 是否随机删除节点
if keep_prob == 1:
# 不随机删除节点
a3, cache = reg_utils.forward_propagation(X, parameters)
elif keep_prob < 1:
###随机删除节点
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
else:
print("keep_prob参数错误!程序退出。")
exit
# 计算成本
# 是否使用二范数
if lambd == 0:
# 不使用L2正则化
cost = reg_utils.compute_cost(a3, Y)
else:
# 使用L2正则化
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
# 反向传播
# 可以同时使用L2正则化和随机删除节点,但是本次实验不同时使用。
assert (lambd == 0 or keep_prob == 1)
# 两个参数的使用情况
if (lambd == 0 and keep_prob == 1):
# 不使用L2正则化和不使用随机删除节点
grads = reg_utils.backward_propagation(X, Y, cache)
elif lambd != 0:
# 使用L2正则化,不使用随机删除节点
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
# 使用随机删除节点,不使用L2正则化
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
# 更新参数
parameters = reg_utils.update_parameters(parameters, grads, learning_rate)
# 记录并打印成本
if i % 1000 == 0:
## 记录成本
costs.append(cost)
if (print_cost and i % 10000 == 0):
# 打印成本
print("第" + str(i) + "次迭代,成本值为:" + str(cost))
# 是否绘制成本曲线图
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# 返回学习后的参数
return parameters
# L2正则化计算损失
def compute_cost_with_regularization(A3, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = reg_utils.compute_cost(A3, Y)
L2_regularization_cost = lambd * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3))) / (2 * m)
cost = cross_entropy_cost + L2_regularization_cost
return cost
# 带L2正则化的反向传播
def backward_propagation_with_regularization(X, Y, cache, lambd):
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = (1 / m) * np.dot(dZ3, A2.T) + ((lambd * W3) / m)
db3 = (1 / m) * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = (1 / m) * np.dot(dZ2, A1.T) + ((lambd * W2) / m)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = (1 / m) * np.dot(dZ1, X.T) + ((lambd * W1) / m)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradient = {"dZ3":dZ3, "dW3":dW3, "db3":db3, "dA2":dA2,
"dZ2":dZ2, "dW2":dW2, "db2":db2, "dA1":dA1,
"dZ1":dZ1, "dW1":dW1, "db1":db1}
return gradient
def forward_propagation_with_dropout(X, parameters, keep_prob):
pass
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
pass
# 使用L2正则化
parameters = model(train_X, train_Y, lambd = 0.7, is_plot=True)
print("使用正则化,训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("使用正则化,测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
# 画出分割曲线
plt.title("Model with regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
输出:
第0次迭代,成本值为:0.6974484493131264
第10000次迭代,成本值为:0.2684918873282238
第20000次迭代,成本值为:0.2680916337127301
使用正则化,训练集:
Accuracy: 0.9383886255924171
使用正则化,测试集:
Accuracy: 0.93
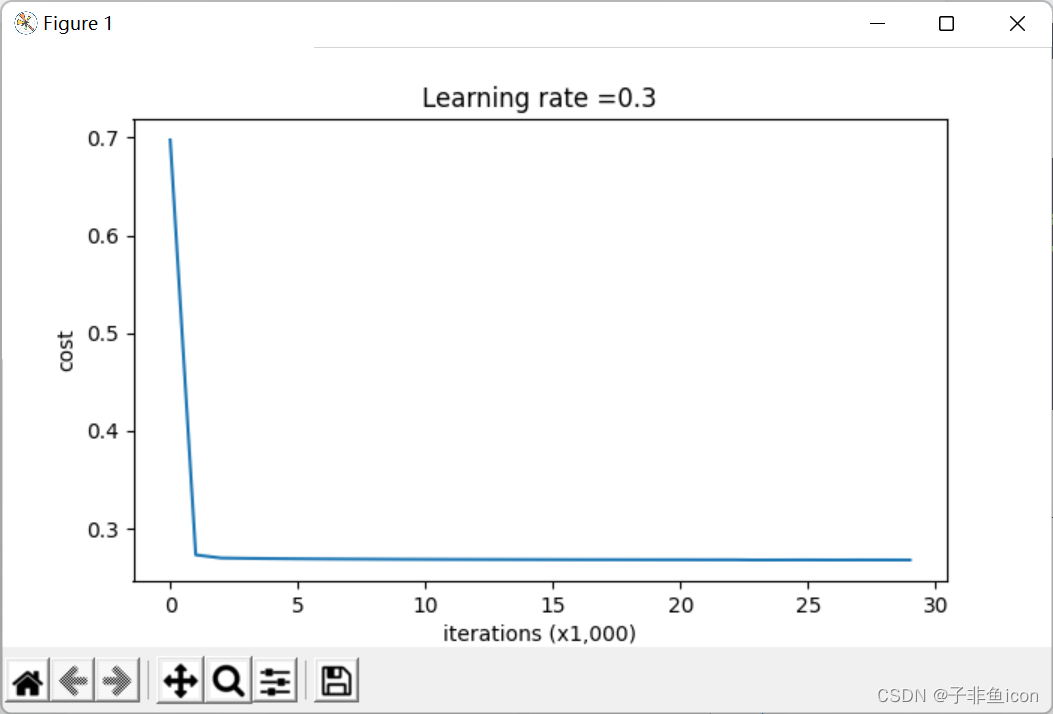
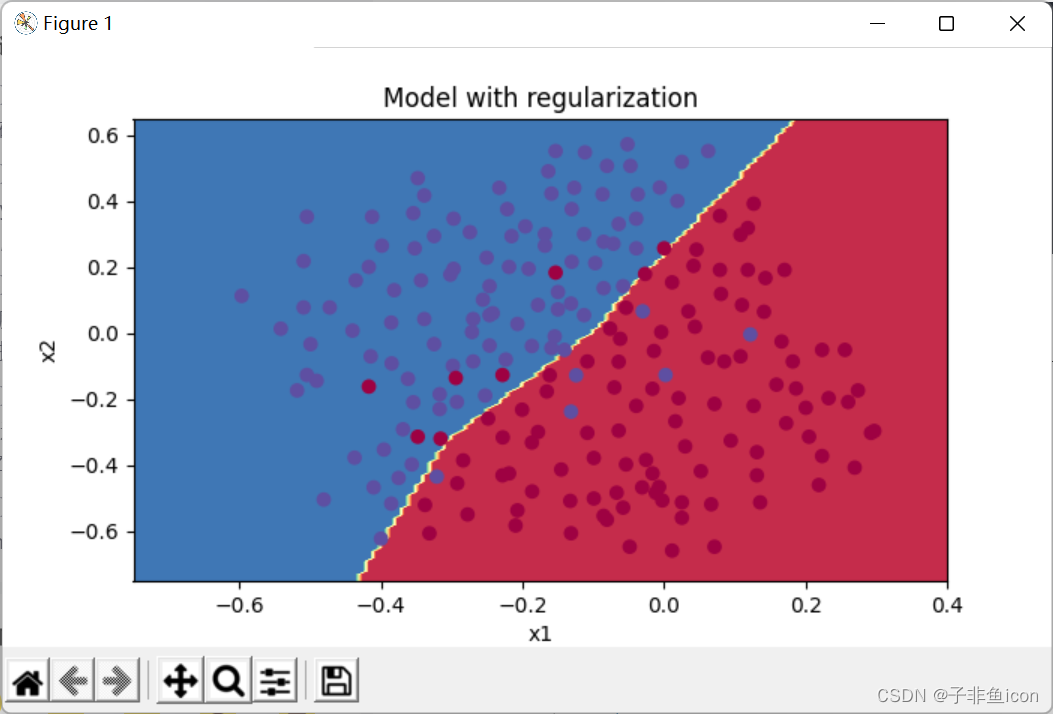
λ的值是可以使用开发集调整时的超参数。L2正则化会使决策边界更加平滑。如果λ太大,也可能会“过度平滑”,从而导致模型高偏差。
9.3.3 随机消除节点
代码:
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import init_utils #第一部分,初始化
import reg_utils #第二部分,正则化
import gc_utils #第三部分,梯度校验
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 查看数据集
train_X, train_Y, test_X, test_Y = reg_utils.load_2D_dataset(is_plot=True)
# 模型
def model(X, Y, learning_rate=0.3, num_iterations=30000, print_cost=True, is_plot=True, lambd=0, keep_prob=1):
grads = {}
costs = []
m = X.shape[1]
layers_dims = [X.shape[0], 20, 3, 1]
# 初始化参数
parameters = reg_utils.initialize_parameters(layers_dims)
# 开始学习
for i in range(0, num_iterations):
# 前向传播
# 是否随机删除节点
if keep_prob == 1:
# 不随机删除节点
a3, cache = reg_utils.forward_propagation(X, parameters)
elif keep_prob < 1:
###随机删除节点
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
else:
print("keep_prob参数错误!程序退出。")
exit
# 计算成本
# 是否使用二范数
if lambd == 0:
# 不使用L2正则化
cost = reg_utils.compute_cost(a3, Y)
else:
# 使用L2正则化
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
# 反向传播
# 可以同时使用L2正则化和随机删除节点,但是本次实验不同时使用。
assert (lambd == 0 or keep_prob == 1)
# 两个参数的使用情况
if (lambd == 0 and keep_prob == 1):
# 不使用L2正则化和不使用随机删除节点
grads = reg_utils.backward_propagation(X, Y, cache)
elif lambd != 0:
# 使用L2正则化,不使用随机删除节点
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
# 使用随机删除节点,不使用L2正则化
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
# 更新参数
parameters = reg_utils.update_parameters(parameters, grads, learning_rate)
# 记录并打印成本
if i % 1000 == 0:
## 记录成本
costs.append(cost)
if (print_cost and i % 10000 == 0):
# 打印成本
print("第" + str(i) + "次迭代,成本值为:" + str(cost))
# 是否绘制成本曲线图
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# 返回学习后的参数
return parameters
# L2正则化计算损失
def compute_cost_with_regularization(A3, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = reg_utils.compute_cost(A3, Y)
L2_regularization_cost = lambd * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3))) / (2 * m)
cost = cross_entropy_cost + L2_regularization_cost
return cost
# 带L2正则化的反向传播
def backward_propagation_with_regularization(X, Y, cache, lambd):
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = (1 / m) * np.dot(dZ3, A2.T) + ((lambd * W3) / m)
db3 = (1 / m) * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = (1 / m) * np.dot(dZ2, A1.T) + ((lambd * W2) / m)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = (1 / m) * np.dot(dZ1, X.T) + ((lambd * W1) / m)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradient = {"dZ3":dZ3, "dW3":dW3, "db3":db3, "dA2":dA2,
"dZ2":dZ2, "dW2":dW2, "db2":db2, "dA1":dA1,
"dZ1":dZ1, "dW1":dW1, "db1":db1}
return gradients
# dropout前向传播
def forward_propagation_with_dropout(X, parameters, keep_prob=0.5):
np.random.seed(1)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
Z1 = np.dot(W1, X) + b1
A1 = reg_utils.relu(Z1)
D1 = np.random.rand(A1.shape[0], A1.shape[1])
D1 = D1 < keep_prob
A1 = A1 * D1
A1 = A1 / keep_prob
Z2 = np.dot(W2, A1) + b2
A2 = reg_utils.relu(Z2)
D2 = np.random.rand(A2.shape[0], A2.shape[1])
D2 = D2 < keep_prob
A2 = A2 * D2
A2 = A2 / keep_prob
Z3 = np.dot(W3, A2) + b3
A3 = reg_utils.sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
# dropout后向传播
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = (1 / m) * np.dot(dZ3, A2.T)
db3 = (1 / m) * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dA2 = dA2 * D2
dA2 = dA2 / keep_prob
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dA1 = dA1 * D1
dA1 = dA1 / keep_prob
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradients = {"dZ3":dZ3, "dW3":dW3, "db3":db3, "dA2":dA2,
"dZ2":dZ2, "dW2":dW2, "db2":db2, "dA1":dA1,
"dZ1":dZ1, "dW1":dW1, "db1":db1}
return gradients
# 使用随机删除节点
parameters = model(train_X, train_Y, keep_prob = 0.86, learning_rate=0.3, is_plot=True)
print("使用随机删除节点,训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("使用随机删除节点,测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
# 画出分割曲线
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
输出:
第0次迭代,成本值为:0.6543912405149825
D:\PyCharm files\deep learning\吴恩达\L2W1\reg_utils.py:121: RuntimeWarning: divide by zero encountered in log
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
D:\PyCharm files\deep learning\吴恩达\L2W1\reg_utils.py:121: RuntimeWarning: invalid value encountered in multiply
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
第10000次迭代,成本值为:0.0610169865749056
第20000次迭代,成本值为:0.060582435798513114
使用随机删除节点,训练集:
Accuracy: 0.9289099526066351
使用随机删除节点,测试集:
Accuracy: 0.95

正则化会把训练集的准确度降低,但是测试集的准确度提高了。
9.4 梯度校验
代码:
import numpy as np
import matplotlib.pyplot as plt
import gc_utils
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 前向传播
def forward_propagation_n(X, Y, parameters):
m = X.shape[1]
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
Z1 = np.dot(W1, X) + b1
A1 = gc_utils.relu(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = gc_utils.relu(Z2)
Z3 = np.dot(W3, A2) + b3
A3 = gc_utils.sigmoid(Z3) # 这里一定记得输出是sigmoid
logprobs = np.multiply(-np.log(A3), Y) + np.multiply(-np.log(1 - A3), 1 - Y)
cost = (1 / m) * np.sum(logprobs)
cache = (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3)
return cost, cache
# 反向传播
def backward_propagation_n(X, Y, cache):
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = (1 / m) * np.dot(dZ3, A2.T)
db3 = (1 / m) * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
gradients = {"dZ3":dZ3, "dW3":dW3, "db3":db3, "dA2":dA2,
"dZ2":dZ2, "dW2":dW2, "db2":db2, "dA1":dA1,
"dZ1":dZ1, "dW1":dW1, "db1":db1}
return gradients
# 梯度检验
def gradient_check_n(parameters, gradients, X, Y, epsilon=1e-7):
# 初始化参数
parameters_values, _ = gc_utils.dictionary_to_vector(parameters)
grad = gc_utils.gradients_to_vector(gradients)
num_parameters = parameters_values.shape[0]
J_plus = np.zeros((num_parameters, 1))
J_minus = np.zeros((num_parameters, 1))
gradapprox = np.zeros((num_parameters, 1))
# 计算逼近梯度
for i in range(num_parameters):
thetaplus = np.copy(parameters_values)
thetaplus[i][0] = thetaplus[i][0] + epsilon
J_plus[i], _ = forward_propagation_n(X, Y, gc_utils.vector_to_dictionary(thetaplus))
thetaminus = np.copy(parameters_values)
thetaminus[i][0] = thetaminus[i][0] - epsilon
J_minus[i], _ = forward_propagation_n(X, Y, gc_utils.vector_to_dictionary(thetaminus))
gradapprox[i] = (J_plus[i] - J_minus[i]) / (2 * epsilon)
numerator = np.linalg.norm(grad - gradapprox)
print(grad, gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator
if difference < 1e-7:
print("梯度检查:梯度正常!")
else:
print("梯度检查:梯度超过阈值!")
return difference
# 测试用例
def gradient_check_n_test_case():
np.random.seed(1)
x = np.random.randn(4, 3)
y = np.array([1, 1, 0])
W1 = np.random.randn(5, 4)
b1 = np.random.randn(5, 1)
W2 = np.random.randn(3, 5)
b2 = np.random.randn(3, 1)
W3 = np.random.randn(1, 3)
b3 = np.random.randn(1, 1)
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return x, y, parameters
X, Y, parameters = gradient_check_n_test_case()
cost, cache = forward_propagation_n(X, Y, parameters)
gradients = backward_propagation_n(X, Y, cache)
difference = gradient_check_n(parameters, gradients, X, Y)
print("difference = " + str(difference))
输出:
梯度检查:梯度超过阈值!
difference = 1.1890417877532152e-07
可见,未能满足要求。把种子改为2,np.random.seed(2)
输出:
梯度检查:梯度正常!
difference = 1.3969938247882733e-08
或者,修改参数b的初始化方式(全零):
np.random.seed(1)
x = np.random.randn(4, 3)
y = np.array([1, 1, 0])
W1 = np.random.randn(5, 4)
b1 = np.zeros((5, 1))
W2 = np.random.randn(3, 5)
b2 = np.zeros((3, 1))
W3 = np.random.randn(1, 3)
b3 = np.zeros((1, 1))
输出:
梯度检查:梯度正常!
difference = 2.7912248836331754e-09
注:这里前期把最后一层输出的激活函数写错成了relu,所以找了很久,梯度都不太正常。
