SPPNet
文章目录
- 论文信息
- 论文标题:
- 论文作者:
- 收录期刊/会议及年份:
- 论文学习
- 论文阅读
- 问题/背景:
- 主要贡献:
- 摘要:
- 介绍:
- 具有空间金字塔池化的深度网络:
论文信息
论文标题:
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文作者:
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
收录期刊/会议及年份:
ECCV,2014
论文获取地址
论文学习
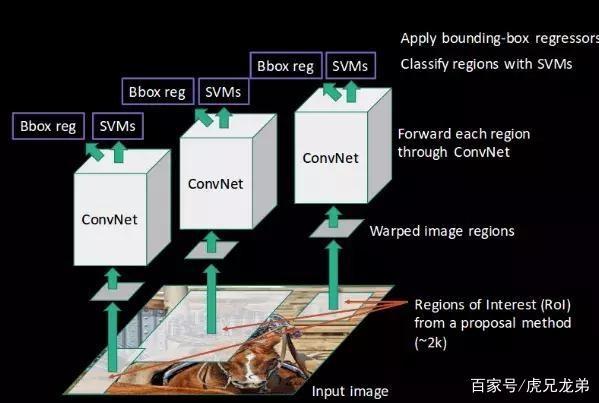
R-CNN 的速度主要慢在哪儿?慢在卷积运算这一步。一张图片生成约 2000 个候选区域,每一个候选区域经过调整大小后都需输入进 CNN 做卷积运算以提取特征向量。
CNN 为什么需要固定的输入呢?CNN 可以分为卷积层部分和全连接层部分,卷积层部分的卷积核可以适用任意大小的输入,也可以产生任意大小的输出。但是全连接层部分不同,其参数是神经元对于所有输入的连接权重,也就是说输入尺寸不固定的话,全连接层参数的个数都不能固定。
何凯明团队提出的 SPPNet 给出的解决方案是,既然只有全连接层需要固定的输入,那么在全连接层前面加上一个网络层,使得任意经过该网络层的输入都能产生固定的输出。

| R-CNN | SPPNet |
|---|---|
| 1. 在输入到 CNN 中之前需要对候选区域做尺寸的修改; 2. 一张图像做 2000 次特征提取(生成 2000 个候选区域)。 | 1. 在输入到 CNN 中之前并不需要对图像做尺寸的修改; 2. 一张图像只需做一次特征提取。 |
SPPNet 算法的具体步骤:
- 使用 SS 算法生成 2000 个候选区域;
- 将整个图像输入到 CNN 中,提取出整个图像的 feature map,然后将候选区域映射到 feature map 上得到一个块,而后对这个块做空间金字塔池化,以提取固定长度的特征向量;
- 使用 SVM 分类器对候选区域(特征向量)进行分类;
- 非极大值抑制;
- 修正候选框。
SPPNet 与 R-CNN 最大的不同就在于第二步的处理上,SPPNet 对一张图像只做一次特征提取,从而显著提高效率,使得速度得到很大提升。
映射: 对原始图像使用 SS 算法得到候选区域,将原始图像输入 CNN 得到 feature map,现在需要将候选区域在原始图像中的位置映射到 feature map 上相对应的位置。

假设原图上的坐标点为 ( x , y ) (x, y) (x,y),特征图上的坐标点为 ( x ′ , y ′ ) (x', y') (x′,y′),S 为 CNN 中所有 stride 的乘积,包括卷积和池化的 stride。那么映射关系可以如下所示:
左上角映射为:

右下角映射为:

spatial pyramid pooling: 通过空间金字塔池化,将候选区域对应的特征块转换成固定大小的特征向量。

SPP 层会将每一个候选区域进行三次划分,分别划分成 1*1、2*2、4*4 三个子图。然后对每个子图的每个划分区域做 max pooling 操作,得到的特征连接在一起就是 (16+4+1)*256=21*256=5376 维特征向量。而后将特征向量输入全连接层做进一步处理。
SPPNet 的优点: SPPNet 在 R-CNN 的基础上提出了改进,通过将整个图像输入 CNN 以提取一次特征,而后将候选区域一一映射到 feature map 上,再配合 SPP 层的使用,从而得到固定长度的特征向量。很大程度上减少了卷积运算,极大地提升了速度。
SPPNet 的缺点: 训练依然过慢、效率低,特征仍需写入磁盘(因为 SVM 的存在);训练阶段仍然多,选取候选框、训练 CNN、训练 SVM、训练 bbox 回归器,反向传播效率低。
论文阅读
问题/背景:
现有的 CNN 需要输入固定大小的图像,这可能会降低对任意大小的图像或子图像的识别精度;
在 R-CNN 中一张图像生成 2000 个候选区域,每一个候选区域都需要输入到 CNN 中进行卷积运算以提取特征。
主要贡献:
提出了 SPPNet 模型,不需要考虑输入网络的图像大小,一样可以生成固定长度的特征向量;
整个图像输入到 CNN 中进行卷积运算,一张图像只需进行一次特征提取,大大减少了卷积运算。
摘要:
SPPNet 避免了卷积特征的重复计算。在处理测试图像时,该方法比 R-CNN 快 24-102 倍。
介绍:
流行的 CNN 需要固定的输入图像大小,这限制了输入图像的长宽比。当应用任意大小的图像时,当前的方法大多会通过裁剪、扭曲等将输入图像适配到固定大小。但裁剪的区域可能并不包含整个对象,扭曲的内容也可能导致不需要的几何扭曲。识别精度可能会因为内容丢失或失真而受到影响。
CNN 主要由卷积层和全连接层两部分组成,卷积层并不需要固定的输入图像大小,且可以生成任何大小的特征图。但全连接层需要根据其定义输入固定的大小。因此,固定大小的限制仅来自于网络更深层的全连接层。
SPP 对于深度 CNN 具有几个显著的性质:(1)SPP 能够生成固定长度的输出而不受输入大小的影响;(2)SPP 使用多级空间盒,而卷积中的滑动窗口仅使用单一的窗口大小,多级池化对于目标变形已被证明是稳健的;(3)由于输入尺度的灵活性,SPP 可以汇集在不同尺度上提取的特征。
具有空间金字塔池化的深度网络:
我们用空间金字塔池化层来代替深度网络中的最后一个池化层(即最后一个卷积层后的
P
o
o
l
5
Pool_5
Pool5)。
空间金字塔池化的输出是 kM 维的特征向量,其中 k 表示最后一个卷积层的卷积核数量,M 表示空间盒(spatial bins)的数量(即16+4+1=21)。kM 维的特征向量就是下一个全连接层的输入。
注:空间盒指的就是需要做池化操作的区域,比如有 16 个空间盒,则在每个空间盒内做最大池化操作。
Single-size training: 如果网络接受的是固定大小的图像输入,对于给定大小的图像,可以预先计算空间金字塔池化所需的空间盒大小。
假设图像经过
C
o
n
v
5
Conv_5
Conv5 后得到的特征图大小为 a*a,金字塔某一级所需空间盒数量为 n*n,用一个滑动窗口来实现池化,则这个滑动窗口的大小应设置为
⌈
a
/
n
⌉
\left \lceil a/n\right \rceil
⌈a/n⌉,滑动步长应设置为
⌊
a
/
n
⌋
\left \lfloor a/n\right \rfloor
⌊a/n⌋。
Multi-size training: 考虑有两种大小的图像,180*180 和 224*224,一个网络固定输入 180*180 大小的图像,一个网络固定输入 224*224 大小的图像,金字塔池化中滑动窗口的大小与步长的计算方法同上。可以知道,不管输入的图像大小是多少,因为金字塔池化中设定的空间盒是一定的(一个空间盒经过池化操作得到一个特征数值),所以特征块经过金字塔池化后得到的特征向量是固定长度的。
换句话说,在训练过程中,我们通过两个共享参数的固定输入大小的网络来实现可变输入大小的 SPPNet 模型。
为了减少从一个网络(224*224)切换到另一个网络(180*180)的开销,我们在一个网络上训练完一个 epoch,然后再切换到另一个网络进行下一个 epoch 的训练。
在实验中发现,这种多尺度训练的收敛速度与上述单一尺度训练的收敛速度相似。
上述单一尺度以及多尺度的方法仅用于训练阶段,在测试阶段,可以直接将 SPPNet 应用于任何大小的图像。
