算法与数据结构(第一周)——线性查找法
目录
线性查找法介绍
实现线性查找法
使用泛型
使用自定义类测试算法
循环不变量
简单的复杂度分析
常见的时间复杂度
测试算法性能
线性查找法介绍
线性查找法是一个非常简单的算法,比如说现在有一打试卷在,每个试卷都有自己的一个编号,在这一沓试卷当中找到属于自己的那一张试卷。一个一个去寻找自己的目标元素,就是线性查找法,例如:

实现线性查找法
对于以上算法返回的是一个int,也就是所查找的目标元素所对应的索引值,此时这个算法需要两个参数,第一个是数组,第二个是目标元素 。
public class LinearSearch {
public int search(int[] data,int target){
for (int i = 0;i< data.length;i++)
if (data[i]==target)
return i;
return -1;
}
public static void main(String[] args) {
int[] data = {24,18,12,9,16,66,32};
LinearSearch ls = new LinearSearch();
int res = ls.search(data,16);
System.out.println(res);
int res2 = ls.search(data,666);
System.out.println(res2);
}
}仔细看LinearSearch是一个动词,创建一个动词的类对象看样子有点奇怪,所以将search函数设置为静态,相应的在调用search这个方法的时候。就不需要再次实例化LinearSearch了,可以接调用linear search这个类的名称,从而调用函数,这才是一个更加自然的设计方式。我们没有必要去创建linear search这个类。我们直接调用LinearSearch中的静态方法Search方法来查找。数组中target的索引。
我们这个累并不希望用户去创建linear search这样的一个对象,那怎么做才能阻止呢?可以将linear search的构造函数设置成私有的。
public class LinearSearch {
public LinearSearch() {
}
public static int search(int[] data,int target){
for (int i = 0;i< data.length;i++)
if (data[i]==target)
return i;
return -1;
}
public static void main(String[] args) {
int[] data = {24,18,12,9,16,66,32};
int res = LinearSearch.search(data,16);
System.out.println(res);
int res2 = LinearSearch.search(data,666);
System.out.println(res2);
}
}使用泛型
现在对于这个算法来讲,它使用的是一个int类型数组,而目标也是int类型,而现实中要查找的类型。可能是千奇百怪的,有可能是字符串,也可能是字符,也有可能是用户自己设置的类,这个时候就需要使用到泛型。
此时最好将search方法设置为泛型方法,此时数组data设置为e,Target的类型也为e,此时参数的类型不再固定为int型,用户可以根据自己的代码来选择合适的类型。(泛型只能接受类对象,而不能接受基本数据类型,当时用泛型的时候,如果我们想传入的类型是基本数据类型的时候,此时就需要把它转化为对应的包装类即可)

public class LinearSearch {
public LinearSearch() {
}
public static <E> int search(E[] data, E target){
for (int i = 0;i< data.length;i++)
if (data[i].equals(target))
return i;
return -1;
}
public static void main(String[] args) {
Integer[] data = {24,18,12,9,16,66,32};
int res = LinearSearch.search(data,16);
System.out.println(res);
int res2 = LinearSearch.search(data,666);
System.out.println(res2);
}
}注意,对于类之间的判断需要用equals方法。
对于不同的历来讲方法内部实现的逻辑有可能是不同的,对于一般的数据类型,equals方法足以应对,但是如果使用自己定义的类的话,就需要注意在自己定义的类当中将equals方法。的逻辑实现出来,这个任务不是线性查找法该实现的,而是这个类的设计者去实现的。
使用自定义类测试算法
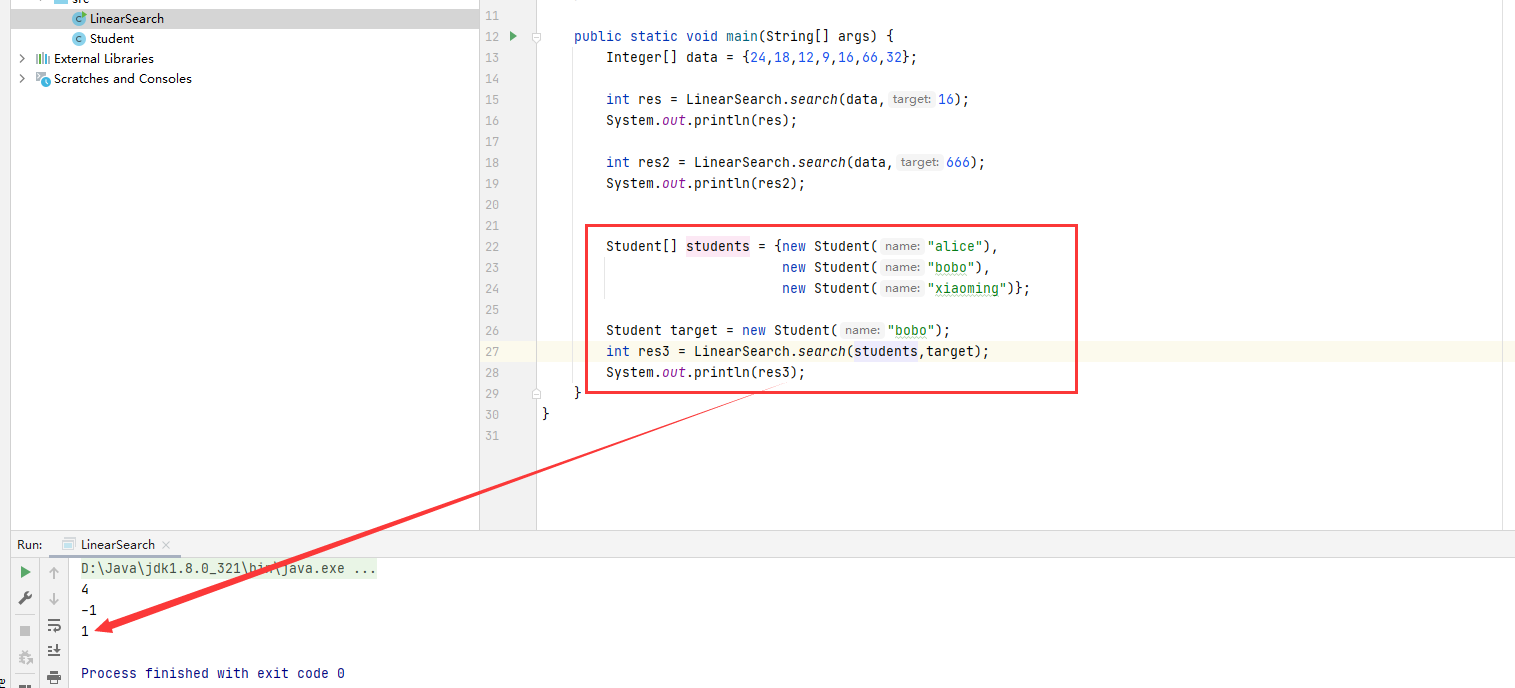
自定义一个student类,并且去完善equals方法。
在主方法当中定义一个student类型的数组,然后再定义一个student类型来确定要查找的元素。
Student[] students = {new Student("alice"),
new Student("bobo"),
new Student("xiaoming")};
Student target = new Student("bobo");
int res3 = LinearSearch.search(students,target);
System.out.println(res3);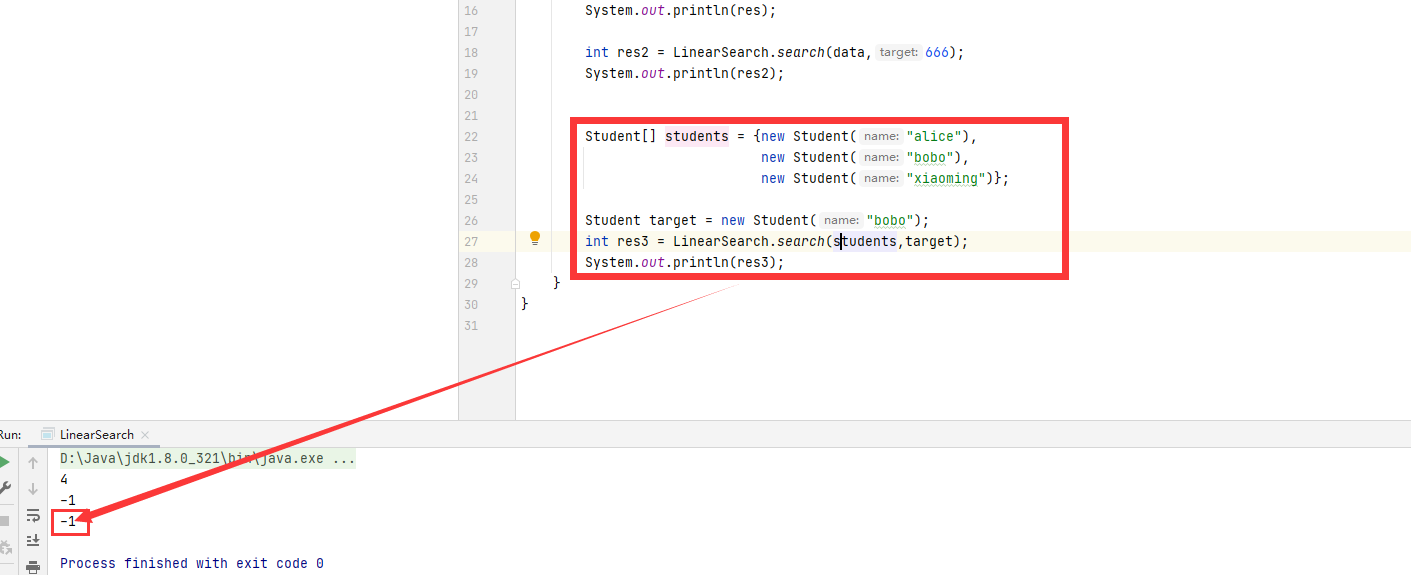
返回结果是-1,这是为什么呢?因为equals方法默认比较的是两个类对象的地址,而在我们的逻辑中,想要比较的是字符串,所以这个逻辑就需要我们自己去自定义equals函数,我们需要重写equals方法,所以equals方法中的参数类型需要与父类Object保持一致。
import java.util.Objects;
public class Student {
private String name;
public Student(String name) {
this.name = name;
}
@Override
public boolean equals(Object student) {
/*
强制转换有可能出现异常,因此需要做出判断
*/
if (this == student)//比较当前类对象与传入的参数是否一致,如果一致,则不需要进行强制类型转换了,直接为true
return true;
if (student == null)//如果传入的对象为空的话,则直接为false即可
return false;
/*
如果当前的类对象与传入参数的类对象不属于同一个类的话,则直接为false,也不需要强制转换了
(之所以重写equals方法需要强制转换,是因为它的参数必须为类型Object,以此来涵盖所有可能传入的参数类型,
而如果具体传来的参数类型与。挣钱类对象不同的话,则这两个对象肯定是不同的)
*/
if (this.getClass() != student.getClass())
return false;
Student another = (Student) student;
return this.name.equals(another.name);//写比较逻辑
}
}
如果我们想要比较的逻辑是比较学号或者比较的逻辑是姓名忽略大小写的,都可以对student类当中的equals方法进行一个修改。
循环不变量
循环是程序设计中一种非常重要的构建逻辑的方式,实际上几乎所有的算法都有循环这个概念,我们总会使用循环来用算法进行求解。
在每一轮循环开始的时候,这个条件本身是不变的,这就是循环不变量。经过这个循环体之后,要么循环结束了,已经return i了,要么循环继续,如果循环继续的话,在下一轮循环中,如果依旧满足循环不变量的话,则继续依靠循环体维持循环不变量。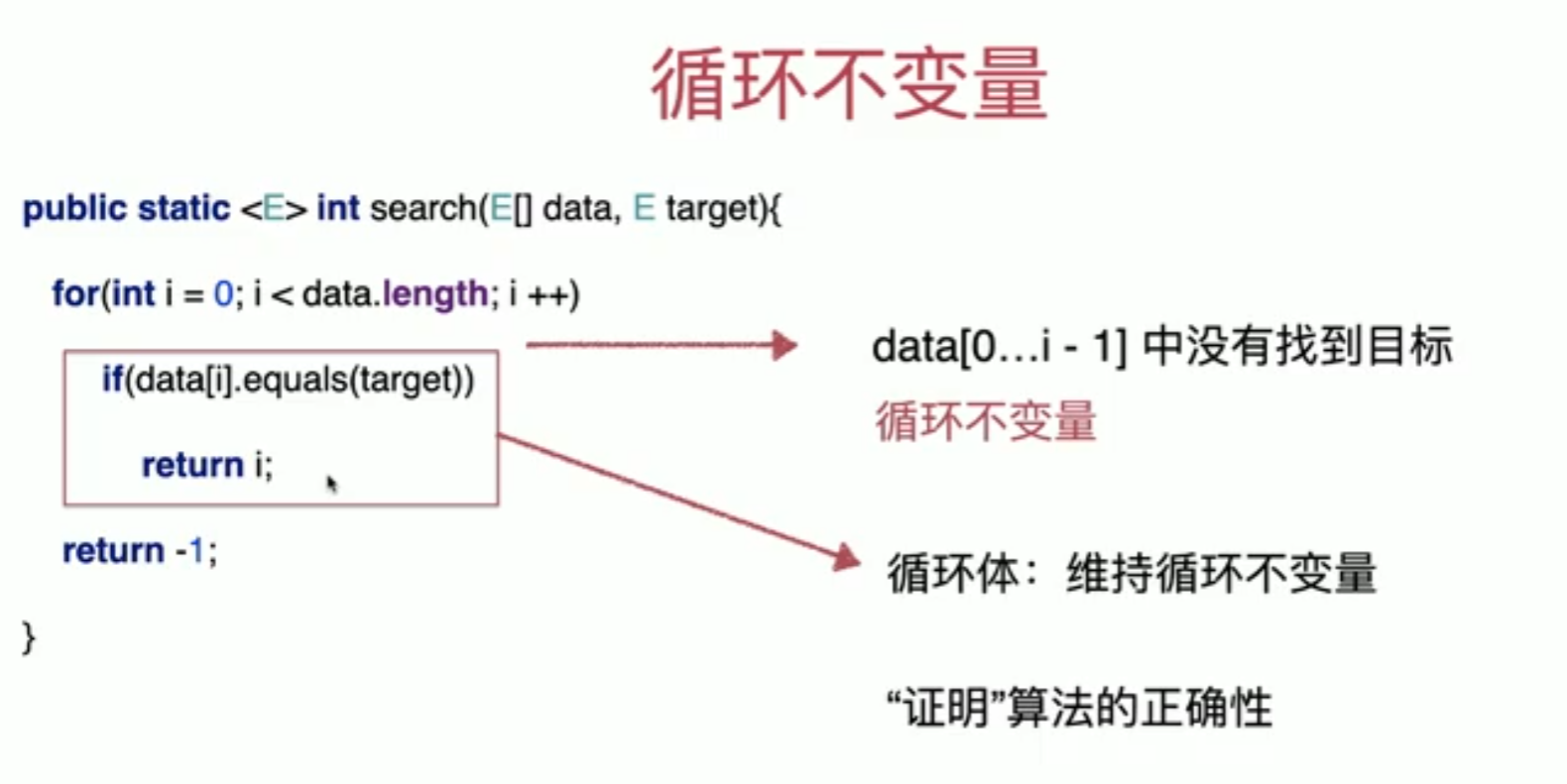

简单的复杂度分析
简单的来说,我们之所以要对算法做复杂度分析,是因为我们需要表示算法的性能,我们后续都会看到对于这样的一个任务,我们会有不同的算法能够完成这个任务,那对于不同的算法来说,他们的时间性能是不是有差异呢?当然,我们可以具体的用一个任务或者是具体测试用例对不同的算法都运行一下实际的去比较一下它的性能差异,但是这样的比较结果很多时候是有局限性的,因为严格来讲,你需要保证运行不同的算法的这个计算机他们的性能是完全一致的,甚至他们使用的系统,系统当时的状态都是完全一致的,这个是很难一致的,与此同时测试的结果呢也会和我们具体的测试用例是怎样的相关,更重要的是这样做,我们必须先把这个算法实体的实现出来,才能看到它的性能,但是很多时候呢我们有这个算法思想之后,我们希望可不可能通过这个算法的思想大致评出这个算法的性能是实力是不是能够满足我们真正的需求,然后再来决定是否要去实现它,这些原因都使得我们需要有一套工具能够非常抽象的从数学的层面就去判断一个算法它的性能是怎么样的,那么为了解决这个问题,就产生了复杂度分析这样一个概念。
我们不去仔细的分析,实行这一轮循环,对这n个元素操作,每一次在这个元素的操作上需要多少指令,我们只需要知道我们整个这个算法它的性能和这个data数目n的大小,也就是这个数据规模成立的正比关系就好了,那么这样的一个算法,计算机科学家就把它记作叫做大O(n)级别的算法,在这里这个大O(n)的符号它有一个非常严谨的数学定义。


常见的时间复杂度



我们看一个学算法的复杂度,不能简单的数循环个数,比如这个循环它也是一层循环,但它并不是On级别,因为他不是每次-1-1到0,而是每次除以2到0,所以他直到0的速度非常快,是logN的级别。
以下算法只是循环条件不同,循环具体执行的轮数是不同的




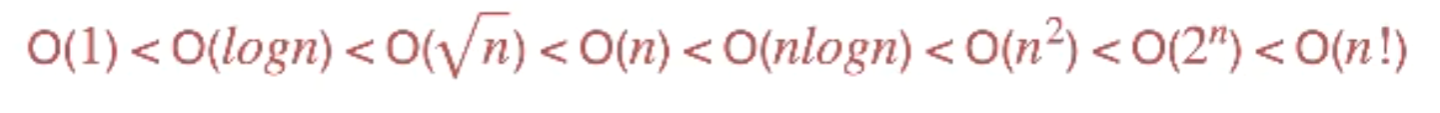
空间复杂度,它的表示符号其实和这个时间复杂度完全是同理的,也就是他对于我们写这一算法来说,我们需要开辟的额外的空间的大小和数据规模n之间的关系是怎样的,那么对于在这一章我们讲的这个非常简单的线性查找法来说,可能可以想象一下,我们为了完成这个计算,其实没有开任何额外的空间,因此这个算法的空间复杂度的就是O(1)这个级别的。

不过通常来讲在我们算法设计的过程中不太强调空间复杂度,更强调时间复杂度,这是因为对于现代计算机来说,空间其实是越来越不值钱的,我们的计算机内存越来越大,硬盘容量越来越多,但相较而言时间是更值钱的,所以我们实际在学习算法的过程中会更加看重时间复杂度,也正是因为如此的多算法设计的核心思想,其实它的本质呢是用空间换时间,也就是我们能不能先存点儿什么东西来加快我们整个算法的运行,那么实际上很多数据结构的原理呢也是如此。
测试算法性能
生成指定长度数组
public class ArrayGenerator {
public ArrayGenerator() {
}
/*
根据用户传来n的大小来创建长度为n的数组
*/
public static Integer[] generateOrderedArray(int n){
Integer[] arr = new Integer[n];
for (int i = 0;i<n;i++){
arr[i] = i;
}
return arr;
}
}
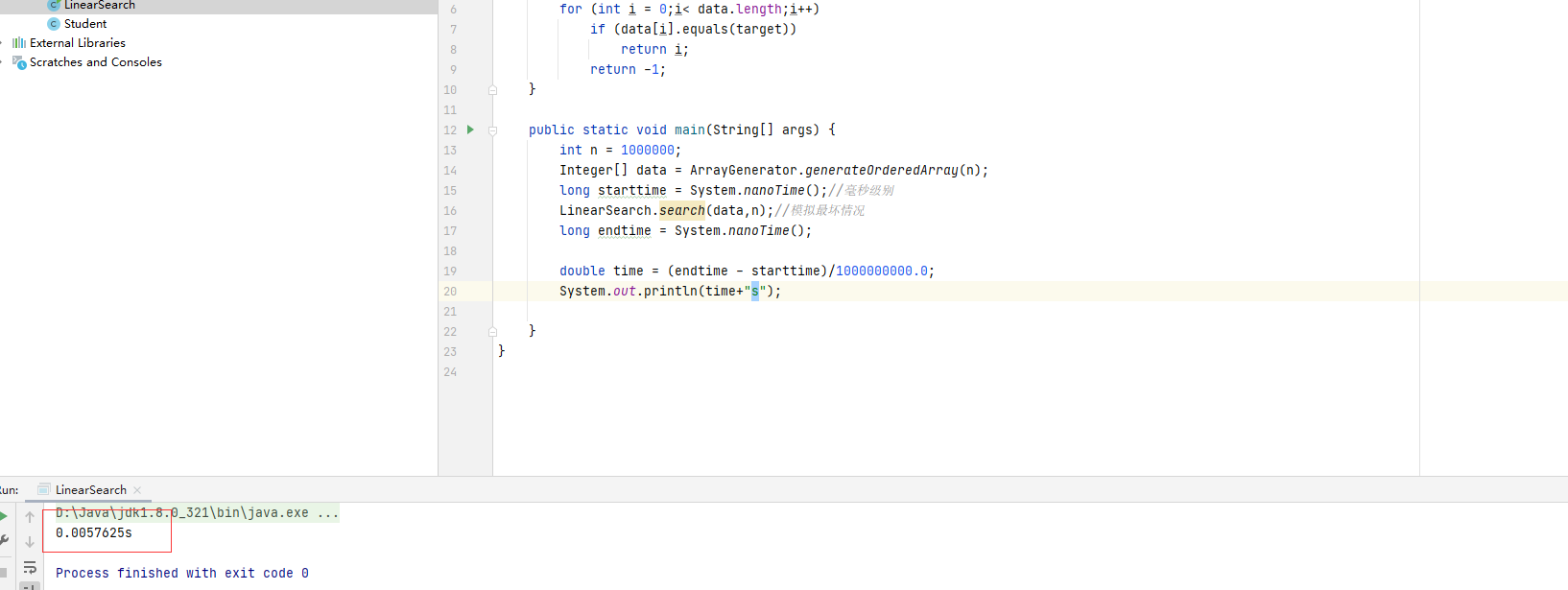
性能测试:
public class LinearSearch {
public LinearSearch() {
}
public static <E> int search(E[] data, E target){
for (int i = 0;i< data.length;i++)
if (data[i].equals(target))
return i;
return -1;
}
public static void main(String[] args) {
int n = 1000000;
Integer[] data = ArrayGenerator.generateOrderedArray(n);
long starttime = System.nanoTime();//毫秒级别
LinearSearch.search(data,n);//模拟最坏情况
long endtime = System.nanoTime();
double time = (endtime - starttime)/1000000000.0;
System.out.println(time+"s");
}
}