【精通内核】CPU控制并发原理CPU中断控制内核解析

前言
📫作者简介:小明java问道之路,专注于研究计算机底层/Java/Liunx 内核,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计📫
🏆 CSDN专家博主/Java优质创作者/CSDN内容合伙人、InfoQ签约作者、阿里云签约专家博主、华为云专家、51CTO专家/TOP红人 🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
目录
本文导读
一、CPU的中断控制
1、并行和并发
1.1 并发
1.2 并行
2、CPU中断控制原理
二、CPU的结构与缓存一致性
1、现代CPU架构
2、CPU的缓存一致性
3、CPU总线与MESI协议
三、CPU的系统屏障内核原理解析
1、编译器屏障原理解析
2、指令级屏障剖析
总结
本文导读
本文讲解CPU角度的中断控制,CPU层面并行并发和中断控制的原理,现代CPU的缓存结构和架构图、CPU缓存一致性的源码原理,以及CPU如何通过编译器的屏障与指令实现系统屏障,经过内联汇编代码验证之后,证明上述所说的 Linux 内核用 volatile 关键字实现系统屏障(指令重排),加深对系统屏障的内核源码和原理的理解。
一、CPU的中断控制
1、并行和并发
1.1 并发
最初的计算机中是没有并发概念的。一台计算机只能运行一个任务,该任务没有完成,就不能运行下一个任务。
这有什么缺点呢?
想象一下,你的计算机只能运行一个任务,如果你在听歌,那么计算机就无法进行其他事情。是不是很抓狂!让我们来想想如何让计算机同时运行多个任务,让你在听歌时还能写文档、聊天等。这个在计算机中运行多个任务的操作就叫作并发,高并发当然就是同时有非常多的任务在你的计算机中执行。那么问题来了:大家都知道计算机中进行计算的是CPU,然而CPU个数有限,任务个数又远大于CPU个数,这时CPU又该如何运行这么多的任务的呢?
可换个思维来考虑,大家都学过数学,不妨回忆什么是函数,想象一个连续的曲线函数,用离散的多个小块来模拟曲线,当小块足够多时,那么我们就说这些小块就是组成连续函数的块。
同理,计算机也可以这么做。计算机中有很多任务,让这些任务交替在速度够快,人眼就感知不到任务间的切换,只要矩形足够多,就越能模拟出这个函数。下面我们对并发进行定义:在有限的COU中执行超过了CPU数量的任务,任务之间交替执行。
1.2 并行
并发也就是在不同时间执行多个任务,因为时间很短,所以人眼看不出来是在替执行。而并行呢,就是一种特殊的并发。并发是不同时间执行多个任务,并行其实就是同一时间执行多个任务。下面给出计算机中并行的定义:在有限的CPU中执行任务,任务的个数正好等同于CPU的个数,则称之为并行。
计算机什么时候用到并发,又什么时候用到并行呢?
这不仅仅是CPU个数正好等于任务的个数,还需要操作系统提供支持。例如,操作系统如果设定只用一个CPU,那么CPU个数再多也没有意义,所以具体的并发与并行问题需要放在实际情况中来考量。不过现在个人计算机或者服务器CPU个数都足够多,且操作系统如果不是特殊设置,也不会只用一个CPU。由于实际运行的任务多于CPU核心数,因此并行与并发是同时存在的。
2、CPU中断控制原理
本节从CPU来看看并发和并行下,硬件层是如何处理共享资源的。
如果只有一个CPU,我们肯定采用并发任务,因为没有多个CPU,所以无法并行,也就是分时复用CPU资源,即给每个任务分CPU时间片,当时间片到后切换下一个任务执行。想象一下,如我想在这种场景下实现 P-V 原语,那么应怎么做呢?
众所周知,对于变量加 1 的操作分为3步,加载、修改、写回,如果在加载完成的时候,CPU 切换了任务,那么会发生什么?肯定就回到了之前说的共享资源导致并发的问题,肯定又要上锁,那么上锁就必须要有原子性操作。
怎么解决上述问题呢?
让我们先思考,是什么导致CPU下来看看任到没到达时间片呢?因为任务代码里是没有检测时间片的指令的,答案是中断那么什么是中断呢?想象一下,你在写代码,当你老板找你时给你打了个电话,于是你停下手里的工作,接你老板的电话,完毕后继续写代码,那么你放下手头完成后继续写代码的过程就叫作中断恢复。
你写代码时是电话把你中断了,那么CPU执行指令时是谁中断了CPU?
答案是 CPU 一个针脚会检测中断,而这个中断信号在 intel上是由一个芯片叫作 8259A中断控制芯片 来做的。
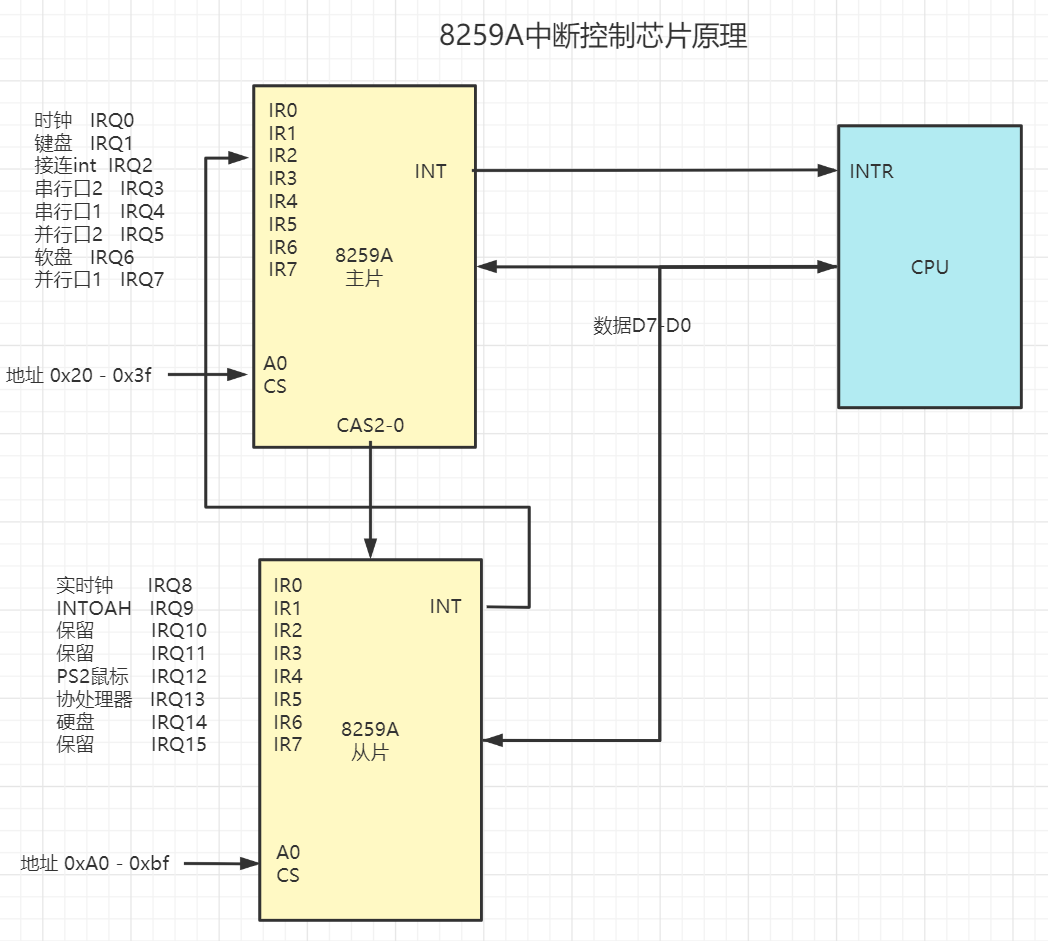
图中有两块 8259A 芯片,每块芯片可以管理8个中断源,通过使用多片级联的方式,那么最多可以管理64个不同的中断号(排列组合,芯片上只有8个中断源针脚,那么8个有8个中断源的8259A芯片是多少 8*8=64),图中采用了两块芯片,可以管理15级中断号(IR2连接了第2块的INT针脚,那么还剩7个,片2有RO-R7总共7个,7+8=15)。
这里将级联的芯片称为从芯片,而将直接跟 CPU 的 INTR 针脚(也就是 CPU Interrupt Request CPU中断请求针脚)相连的芯片称为主芯片。
从芯片的 INT 引脚连接到主芯片的 IR2 引脚上。主芯片的端口基地址为 0x20,从芯片的地址为 0xA0。我们可以在操作系统初始化时通过系统总线控制器,CPU用 IN或者OUT 命令对 8259A 操作。
完成编程后,首先芯片就开始工作,随时响应连接到IR0-IR15针脚的信号,再通过CPUINTR针脚通知给CPU。然后CPU 响应这个信号,通过数据总线 D0-D7 将我们通过编程设定的中断号读出,接着 CPU就可以知道是哪个中断了我,最后根据这个中断号去调用响应的中断服务程序。
其实CPU就是通过检测 INTR 针脚信号来判断是否有中断,问题来了什么时候检测呢?在执行完一条指令,当开始执行下一个指令之前检测中断信号。
回顾CPU如何执行指令? IF(instruction fetch指令提取)、ID(instruction decode指令译码)、EX(execute执行阶段)、MEM(memory访存阶段)、WB(writeback写回阶段)、IE(interrupt execute中断处理阶段)。
下面来看看Linux内核是如何操作的。Linux 内核中对于中断的宏定义:
#define local irq_disable()_asm__volatile_("cli":::"memory") // 关中断
#define local_irq_enable()__asm__volatile_("sti":::"memory") // 开中断回到我们之前的问题上,如果在 CPU 上执行 P-V 原语呢?也就是如何让 CPU 不会切换任务,很简单,通过一种方式让 CPU 不响应INTR针脚的中断信号就行了,当我们执行完原子性的操作后,再让 CPU 响应INTR 信号即可,那么这两个过程就叫作:中断使能、关中断。对应着两个 CPU 指令,即 STI(set interrupt flag设置中断标志位)和 CLI(clear interrupt flag清除中断标志位)。
二、CPU的结构与缓存一致性
1、现代CPU架构
现代CPU架构除了在片上继承多个核以外,还有为了减少对内存访问增加了多级缓存来提高运行速度。通常是三级缓存,及L1(核内独享)L2(核内独享)L3(核外共享)
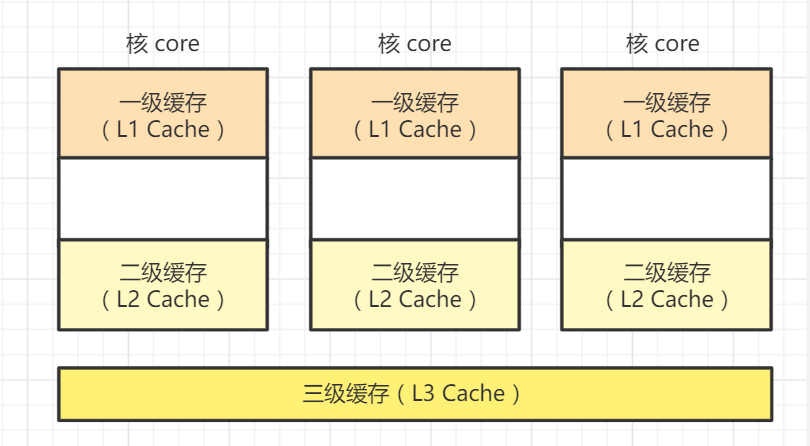
上图描述了现代 CPU 的架构,每个 CPU 独立有 L1和L2 缓存,而共享 L3 缓存。假如我们有两个任务A和B,它们对 counter变量的加1是这样的,任务 A和B 其中一个访存,通过总线总裁只有一个任务能够通过数据总线和地址总线,把counter变量从内存中加载放入 L3缓存 中,然后任务 A和B 分别把 counter 加载到自己的 L1、L2 缓存中,接着进行操作,操作完毕后,只需要把结果放入缓存中即可。
来考虑会出现什么问题?
如果任务A获得了锁,并且在修改了 counter后放到了自己的L1缓存中,同样任务B也如此,那么问题来了,当任务A释放了锁,这时任务B获得了锁,情况又当如何呢?
由于counter的最新值在任务A的L1缓存中,这可怎么办?任务B所在的 CPU 的缓存上是旧值,应如何保证程序的正确性?这就是缓存一致性协议。
2、CPU的缓存一致性
来看看intel的MESI缓存一致性协议的状态描述

上述状态的描述非常容易理解,L1、L2、L3 的缓存是一行一行排列的,我们称之为缓存行,那么4 种状态,即modified、exclusive、shared、invalid 就是在缓存行中保留了两个状态位分别可以表示4种状态。
那么分别代表什么意思呢?从上述描述中应该就能够大致猜出这是什么状态了。例如 CPU 1加载了 counter 值,那么 counter 在缓存行中的状态为E状态,当CPU2加载 counter 值时,CPU1窥探到总线上再到内存中加载 counter 值,那么就会把自己缓存行中的数据放入 CPU2 的缓存行中,且把自己状态修改为S状态,表明 CPU1 和 CPU2 共享 counter 变量。而当CPU1获得了锁并且修收了 counter 值时,CPU 1中的 counter 缓存行状态就变为 M 状态,并且 CPU 2 窥探到 counter 值已经改变,可将缓存行状态变为1状态,此时当CPU 2在操作 counter 值时,由于CPU2的缓存行无效,因此就会重新从CPU 1中将counter的最新值加载至其中。这就保证了不同 CPU 中缓存一致性。
总结下CPU缓存一致性
(1)一个处于 M 状态的缓存行,必须时刻监听所有试图读取该缓存行对应的主存地址的操作,如果监听到,则必须在此操作执行前把其缓存行中的数据写回内存中,或者将该值转发给需要这个值的 CPU,然后将状态修改为 S。
(2)一个处于S状态的缓存行,必须时刻监听使该缓存行无效或者独享该缓存行的请求,如果监听到,则必须把其缓存行状态设置为I。
(3)一个处于E状态的缓存行,必须时刻监听其他试图读取该缓存行对应的主存地址的操作,如果监听到,则必须将其缓存行状态设置为S,并且转发值给需需要的 CPU缓存行。
(4)当CPU需要读取数据时,如果其缓存行的状态是 I,则需要重新发起读取请求,并把自己状态变成 S;如果不是 I,则可以直接读取缓存中的值,但在此之前,必须要等待其他 CPU 的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存或者转发后,再次读取。
(5)当CPU需要写数据时,只有在其缓存行是 M或者 E 时才能执行,否则需要发出特殊的 RFO指令(read for ownership,这是一种总线事务),通知其他CPU置缓存无效(I),这种情况下性能开销是相对较大的。在写入完成后,修改其缓存状态为 M。
3、CPU总线与MESI协议
总线/缓存锁非常容易理解,我们回顾上图中描述的 CPU 架构图。
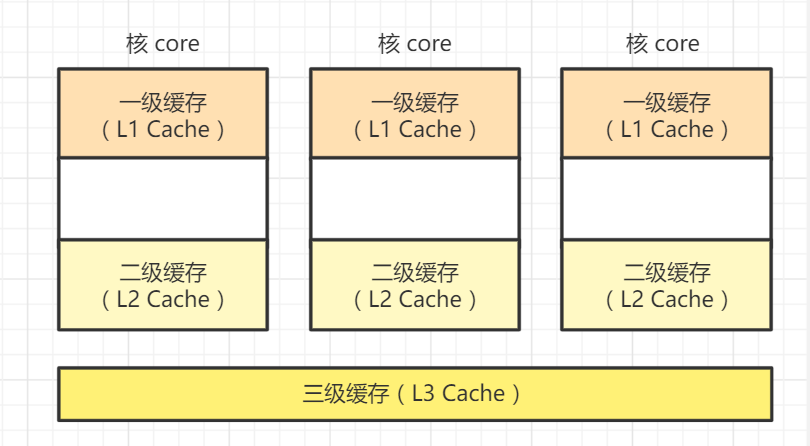
多个 core 也就是CPU核共享一个L3,然后L3后面就是内存,也就是使用同一个总线,我们来想想是不是可以对这根总线上锁,然后当CPU执行完一条指令后再解锁呢?当这个 CPU 在访存时不允许其他 CPU 再申请访问内存,如 CMPXCHG 指令,它是将寄存器的值和内存中的值比较并替换,那么如果我们直接写 CMPXCHGmemory,r,也就是将eax和memery地址的值比较,如果相同,则将r寄存器的内容放入 memory 地址中,将交换的值放入eax 中。想想这几个步骤,这将不会保证正在执行操作的CPU不会被其他CPU锁干扰,也就是这几个步骤不保证原子性。
那么如何做呢?如果写 LOCK CMPXCHG memory,r, 那么仅仅加一个 LOCK 前缀,但是这就够了,我们对这个操作上锁了,等我们这条指令操作完成后锁才释放,那么就能保证CPU这条操作满足原子性了。
我们知道 LOCK 前缀就是用来上锁的,那么想想我们对什么上锁,读者可能会说上述不是说了共享总线么,对总线上锁不就可以了
但是例如我通过一根控制总线拉高电平,这时其他 CPU 将不能够访存这就可以了,可是就像我们上述操作一样,仅仅对一个变量的地址上锁
那么有没有办法来缩小锁的力度,查看上图,我们的变量可是被加载到了CPU的高速缓存中,而且我们有 MESI协议呢?这就够了,我们可以看看如果变量在高速缓存中,那么我们通过 MESI协议 将其他CPU缓存的值变为 I 状态,这时其他 CPU 就无法再读取这个变量,于是它们就需要去访存,但是由于 MESI 规定了当有 CPU 在对这个变量操作的时候,其他 CPU 不能操作,直到 CPU 将值修改完成后置为 M 状态,因此可以通过 Forward 机制将修改的值转发给其他 CPU,这时状态变为 S,这也避免了其他 CPU 再去访问地址,因而极大地提高了效率。而且我们也将锁细粒度到了变量级别,就不用再去对总线上锁了。
三、CPU的系统屏障内核原理解析
由于我们的汇编代码是由编译器产生的,而我们的编译器是知道流水线的,因此编译器当然能够重排序汇编代码来更进一步的优化指令流水线,不仅是CPU可以乱序执行,而且我们的编译器也可以重排序代码,据此,这里的屏障就被分为了两种,即编译器屏障和指令级屏障。
1、编译器屏障原理解析
上述讨论到,CPU为了高效执行代码 引用了多级流水线,而我们的编译器也会面向CPU编译代码,所以也会导致指令重排序,我们先来看看以下代码和它的汇编代码。
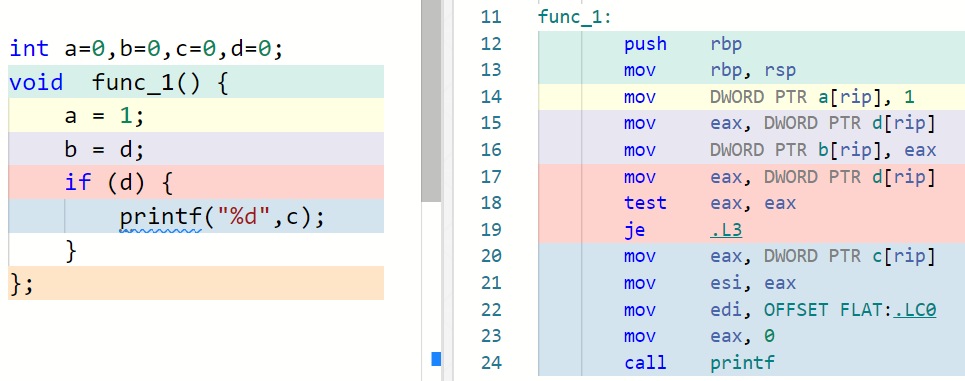
代码声明了4个变量,即 a、b、c、d并初始化为 0, 然后在func_1函数体内修改a为1,并将d的值赋值给a,随后判断d是否为真(C语言非零即真), 如果为真,则输出c的值,同样 func_2
int a = 0, b = 0, c = 0, d = 0;
void func_1() {
a = 1;
b = d;
if (d) {
printf("%d", c);
}
};
void func_2() {
c = 1;
d = a;
if (a) {
printf("%d", b);
}
} ;也是如此。我们来看看func 1未经优化的汇编代码。
func_1: // func_1 函数
push rbp // 保存 rbp
mov rbp, rsp // 将 rsp 的值 赋值给 rbp
mov DWORD PTR a[rip], 1 // 将 1 赋值给变量 a
mov eax, DWORD PTR d[rip] // 将 eax 中 d 赋值给 b
mov DWORD PTR b[rip], eax // 将 eax 中的 d 赋值 b
mov eax, DWORD PTR d[rip] // 将 d 放入 eax
test eax, eax // eax 值取and 看是否为0
je .L3
mov eax, DWORD PTR c[rip] // 将 c 放入 eax 通过 rip来做相对偏移寻址,等于 %rip+c
mov esi, eax
mov edi, OFFSET FLAT:.LC0 // 将 %d 的地址放入 edi
mov eax, 0 // 把调用好 0 方法 eax 中
call printf // 调用 printf 输出c可以看到,未经优化编译器所生成的汇编代码是按照我们的代码书写顺序来执行的,那么如果发生重排序也是CPU的指令重排序,而不是编译器的,因为这里编译器编译的代码和我们的C代码的语义是一样的,同理func2的代码和func 1一样,这里就不粘贴出来了,只不过不同的是变量变为了c和d。那么我们来看看编译器优化过后的汇编代码(基于x86-64 gcc 12.2编译器)。
优化后编译出来的代码和我们写的代码有所不同。这就是编译器面向 CPU 编译,更合理地贴近于 CPU 的流水线架构了,不难发现当把 d 读取放入eax寄存器中时,由于赋值给a=1的指令和 b=d 的指令没有数据依赖,因此不如先把 d 读入,然后指令流水线就会在读入 d 时执行赋值操作
func_1: // func_1 函数
mov eax, DWORD PTR d[rip] // 将 eax 中放入 d
mov DWORD PTR a[rip], 1 // 将 1 赋值给变量 a
test eax, eax // eax 值取and 看是否为0
mov DWORD PTR b[rip], eax // 将 eax 中的 d 赋值 b
jne .L4
rep ret // 优化 CPU 分支预测器有些人可能会认为这没什么关系,反正没有数据依赖,再排序就是为了快,最终结果没问题,但是你想想,如果有两个任务同时进入两个 CPU 中,任务A执行了 func_1方法,任务B执行了 func_2 方法会发生什么?
从我们的代码中可以看到我们的本意是,当d=1时,c 应该为1。但是想想如果发生了重排序,那么 d 的值会优先被加载而 a 的赋值操作却是在 d 之后,任务B同时执行 func_2 方法,同理也发生了重排序,即d的值先被赋值为a的值,然后c才等于1,这就造成了与我们预期结果不符的现象。。如何让编译器禁止这种优化呢?答案是采用编译器屏障
volatile int a = 0, b = 0, c = 0, d = 0;
void func_1() {
a = 1;
b = d;
if (d) {
printf("%d", c);
}
};重新编译后,与我们的预期是一样的,先赋值 1,然后读入 d 赋值给 b ,确实起到了阻止编译器优化的作用。
接下来,我们来看看在 Linux 内核中是否可以用 volatile 关键字来实现阻止编译器优化呢?查看下列源码。
#define barrier()_asm__volatile_("":::"memory" )可以看到就是通过内联汇编来做这个事的,核心代码是 "":::"memory" ,无汇编但是有 clobber 的指令,确切来说,它不包含汇编指令,所以不能叫作指令,只是起到提示编译器的作用。简而言之,这里的操作会影响内存,不可任意优化。下面来看看加 "":::"memory" 将是什么样的效果,先查看下列修改的代码。
volatile int a = 0, b = 0, c = 0, d = 0;
void func_1() {
a = 1;
_asm__volatile_("":::"memory" )
b = d;
if (d) {
printf("%d", c);
}
};可以看到,加了 _asm__volatile_("":::"memory") 是相同的效果。 我们可以通过 volatile 关键字和内联汇编 _asm__volatile_("":::"memory") 提示编器,不可任意排序。
2、指令级屏障剖析
在上述内容已详细介绍了发生指令集排序是由于 CPU 指令流水线造成的,那么有没有办法在处理器中禁止发生重排序呢?我们来看看 Linux 内核源码。
#define mb() alternative("lock; addl $0,0(%%esp)","mfence", X86_FEATURE_XMM2)
#define rmb() alternative("lock; addl $0,0(%%esp)","lfence", X86_FEATURE_XMM2)很简单,这里先解释 alternative 宏定义,这是一个选择宏,通过让 CPU 在运行时,根据自己支持的指令集选择并调用相应的指令,所以起到指令重排序作用的指令为 "lock; addl $0, 0(%%esp)", "mfence"。其中 "mfence" 为新的指令,因为在 intel 之前的 CPU 可以通过 lock 前缀对栈上指令加0操作来作为指令屏障,但后面新出了 mfence和lfence,其中sfence保证了全屏障、读屏障和写屏障的功能;而 "lock; addl S0,0(%%esp)" 指令对于任何 x86 平台都支持,所以这里通过 alternative 宏定义让 CPU 来选择执行哪个。
至于这里的 mfence、lfence、sfence 这里就不进行详述,因为屏障阻止的就是 loadload、storeload、storestore、loadstore 等重排序,这3个指令也是针对这些不同的场景来选择使用的。读者现在只需要记住能通过这几个指令提供 CPU指令集屏障即可,不用深究,否则容易陷入泥潭。
总结
本文讲解CPU角度的中断控制,CPU层面并行并发和中断控制的原理,现代CPU的缓存结构和架构图、CPU缓存一致性的源码原理,以及CPU如何通过编译器的屏障与指令实现系统屏障,经过内联汇编代码验证之后,证明上述所说的 Linux 内核用 volatile 关键字实现系统屏障(指令重排),加深对系统屏障的内核源码和原理的理解。