[DM复习]Apriori算法-国会投票记录关联规则挖掘(上)
Apriori算法|关联规则挖掘
〇.相关基础概念
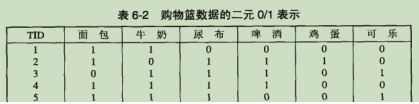
1.购物篮数据的二元表示
- 事务:购物篮数据可以用一个列表来表示,列表中的每一行都对应一个事务
- 项:表格中的每一列则对应一个数据项
- 项的二元表示:如果该项在这个事务中出现了则值为1,否则值为0.
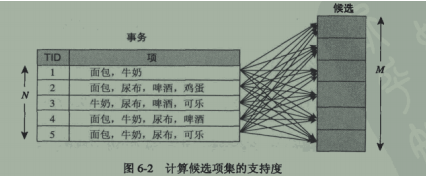
2.项集与支持度计数
- 项的集合:I = {i1,i2,…,id}是购物篮数据中所有项的集合
- 事务集合:T = {t1,t2,…tN}是所有事务的集合。
每个事务ti包含的项集都是I的子集
- (k-)项集:包含0个或多个项的集合被称为项集,项集中含有k个项,则把这个项集称为k-项集。
空集是指不包含任何项的项集。
e.g.{啤酒,尿布,牛奶}是一个3-项集
- 项集的支持度计数
①事务包含项集:若某一个项集是事务的子集,则称这个事务包括项集。
②项集的支持度计数:包含这个项集的事务的个数。
σ(X)=|{ti|X∈ti,ti∈T}|
3.关联规则与支持度和置信度
- 关联规则:形如X→Y的蕴含表达式,且X∩Y=∅。
- 关联规则的支持度:描述该项集在给定数据集的频繁程度
s(X→Y)=σ(X∪Y)/N
- 关联规则的置信度:确定集合Y在包含X得到事务中出现的频繁程度
c(X→Y)=σ(X∪Y)/σ(X)

一.问题定义与分解
1.问题描述
- 关联规则发现
给定事务的集合T,关联规则发现是指找出支持度大于或等于minsup且置信度大于或等于minconf的所有规则,其中minsup和minconf是对应的支持度和置信度阈值。
- 任务分解
①频繁项集的产生——发现满足最小支持度的所有项集。
②规则的产生——对于找到的频繁项集进行二划分产生规则提取出所有高置信度的规则。
2.复杂度分析与完善
- 频繁项集产生所需要的计算开销远大于产生规则所需要的计算开销
原因:在同一个项集中通过二划分产生的规则,则这些项的支持度都是相同的,如果进行划分的项集不是频繁的,那么自然结果不会是好的规则,所以进行关联规则生成之前已经对项集进行了剪枝。

- 暴力解法的复杂度估计
①所谓暴力解法就是指将所有候选的规则与支持度阈值逐个比较;将每个规则的置信度与置信度阈值逐个比较,留下满足条件的项。
②从包含d个项的数据集中提取可能的规则总数为:R = 3d -2d+1 +1;且找出来所有的规则之后还要进行筛选,故前面的大部分计算都是无用的
③一个包含k个项的数据集可能产生2k -1个频繁项集(实质上就是项集的所有非空子集都是候选频繁项集)
④设N为事务总数,M为候选项集总数,w是事务的最大宽度,则暴力算法中求解频繁项集的复杂度为O(NMw)
3.降低算法复杂度的思路
①使用剪枝策略减少候选频繁项集的个数
②使用高效的数据结构存储候选项集和事务以减少二者在计算置信度和支持度时的比较次数。
二.频繁项集的产生
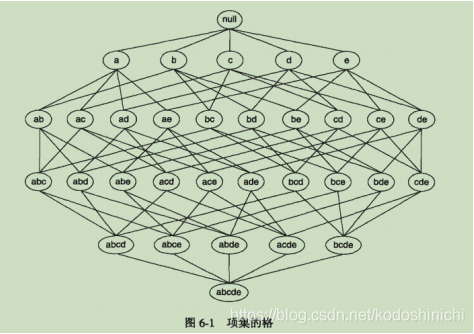
1.项集的格结构
项集的格结构常常用来枚举所有可能的项集,如下图所示,图中显示的就是I={a,b,c,d,e}的项集格
2.先验原理
作用:可以减少候选项集的个数,降低复杂度
本质:基于支持度的剪枝策略
理论基础:支持度度量是一种反单调性的度量
实际操作:一旦发现某个项集是非频繁的,那么包含这个项集及其超集的子图都可以被立即剪枝
定理描述:
①如果一个项集是频繁的,那么该项集的所有子集也一定是频繁的
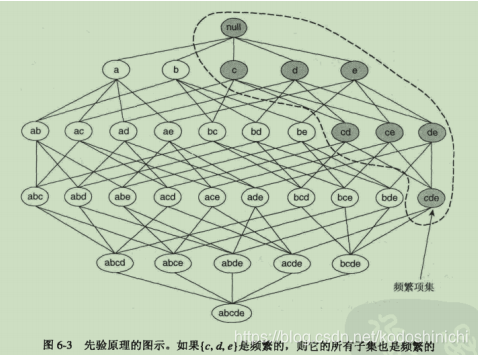
②如果一个项集是非频繁的,那么该项集的所有超集也一定都是非频繁的
理解:如果一个项集是频繁的,那么说明具有一定数目的事务是包含这个项集的,那么至少也有相同数目的事务包含该项集的子集。
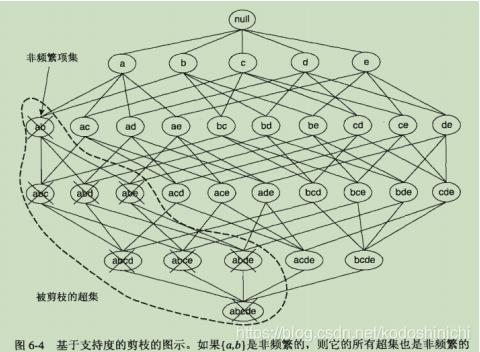
单调性与反单调性

3.候选项集的产生
综述
频繁项集的产生核心分为两个部分,其一是候选项集的产生,其二是候选项集的剪枝。候选项集的策略以下会谈到,候选项集的剪枝就需要选择合适的支持度的计算方法,再按照之前说明的基于支持度的剪枝策略进行剪枝。
3.1蛮力解决:把所有的k-项集都看做是候选频繁项集
3.2 Fk-1*F1方法
①基本描述:使用频繁1-项集来扩展频繁(k-1)-项集。
②问题
③解决方案——规定合并时的顺序要求
频繁(k-1)-项集X只用字典序比X中所有项都大的频繁项进行拓展。
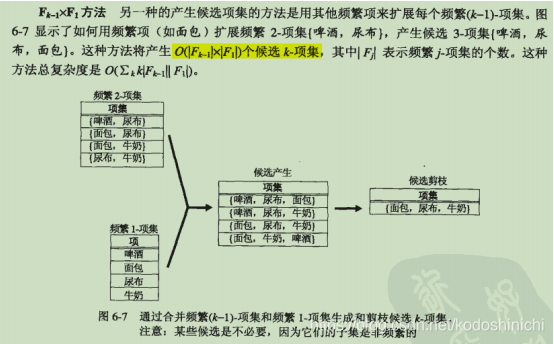

3.3.Fk-1*Fk-1方法
①基本描述:当两个(k-1)-频繁项集的前k-2个项都相同时,A={a1,a2,…,ak-1},B={b1,b2,…,bk-1},则对A和B进行合并,当且仅当
ai = bi (i=1,2,…,k-2) and ak-1≠bk-1②示例

4.候选项集的剪枝
剪枝策略在先验原理部分已经讲解过了,此处主要探讨支持度计算方法
4.1 蛮力方法
将每个事务和候选项集进行比较,如果该事务包含了这个候选项集,则对应的候选项集的支持度计数+1
4.2事务枚举法
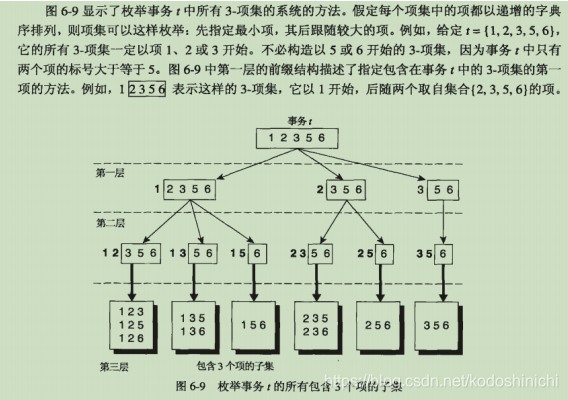
①基本描述:对于每一个事务,若当前需要对k-候选项集进行支持度计数,则考虑该事务选出k个元素的组合方案,如果有和k-候选项集相契合的,则该候选项集的支持度+1
②树形结构
为了避免枚举时的重复,规定枚举的时候元素按照递增的字典序进行排列。
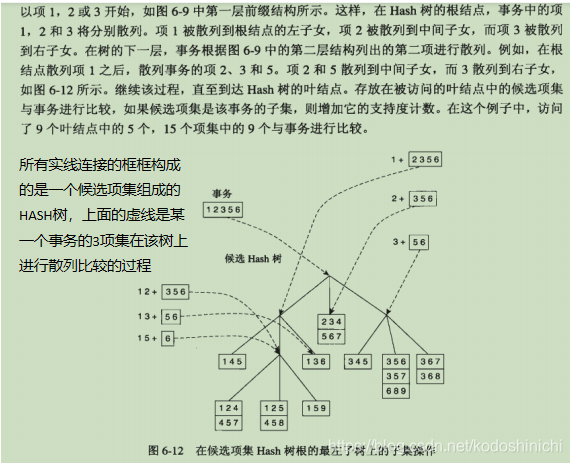
③利用Hash树进行支持度计数
a.首先关于所有的候选项集建立一个hash树,比如按照下图,有三个分叉,则1,4,7往左子树,2,5,8往中间子树,3,6,9往右子树;每一层都按照这个规律,直到最后到叶节点。(下列图是关于3-候选项集建立hash树,所以所有叶节点含有3个元素)
b.在将事务中所有3个元素的子集按照上述hash结构进行同样的散列,直到到达了叶节点,若有匹配的,支持度+1,否然忽略即可。
三.关联规则的产生
关联规则产生的思维图
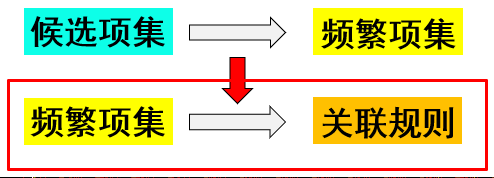
1.使用二分法从频繁项集到候选规则
①候选规则产生:对于给定的频繁项集L,找到所有非空子集f,形如f→L-f的满足最小置信度的规则就为所求

②计算量评估:如果频繁项集L的长度为k(即:该频繁项集中有k个元素),那么会有2k -2个候选规则(所有可能的子集除去空集出现在左右两侧的情况)
2.规则产生方法
①反单调性性质
一般而言,规则的置信度评估并不具有反单调性的性质
但是对于从同一个频繁项集产生的规则具有反单调性——关于规则右边的项的数目呈反单调性

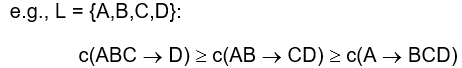
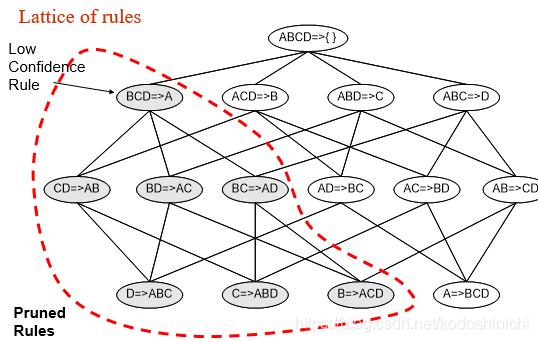
②规则生成方法
核心:合并具有两个相同的前缀的规则
剪枝规则:若生成的规则D=>ABC的子集AD=>BC没有较高的置信度,
那么就要把AD=>BC及其衍生出来的规则全都淘汰
③支持度分布偏斜问题
a.问题描述:比如说一些较贵重的商品,买的人相比一般便宜的商品,自然会买的比较少,所以支持度占比会相对较低,但是这不意味着在贵重的商品之中不存在关联规则
b.支持度阈值分析
最小支持度设置得过高,会错过一些可能包含规则的项;
最小支持度设置得过低,则计算代价会很昂贵,而且得到的数据项的数目会很大
c.解决措施:设置最小支持度MS,对于不同的物体有不同的MS阈值
d.MS计算方法
特点:设置了MS之后,支持度已经不再是反单调性的了

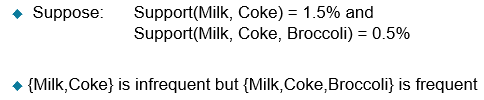
四.Apriori算法
1.产生频繁项集

注:Apriori算法使用Fk-1*Fk-1的策略

2.规则产生



设置MS后对Apriori算法的改进

五.代码实现
-
实验内容
使用Apriori算法,对美国国会投票数据进行高置信度规则的挖掘;其中支持度设为30%,置信度设为90%。
数据来源:http://archive.ics.uci.edu/ml/datasets/Congressional+Voting+Records -
实验分析与设计
-
源代码
#coding:gbk
def loadData(path=''):
'''
加载原始数据
'''
f = open(path + 'house-votes-84.data')
txt = f.read()
f.close()
lst_txt = txt.split('\n')
data = []
for txt_line in lst_txt:
tmp = txt_line.split(',')
data.append(tmp)
return data
def preProcessing(data, vote_y_n):
'''
数据预处理
以按 y 或 n 寻找关联规则
'''
data_pre = []
for data_line in data:
tmp_data = []
for i in range(1, len(data_line)):
#从第二列开始,将数据文件中的记录与当前的选择vote_y_n进行比较,若找到了相关记录,把下标存进去
if (data_line[i] == vote_y_n):
tmp_data.append(i)
if (tmp_data == []):
continue#如果当前这一条记录中没有任何一个项是vote_y_n对应的选项,那么不存储空列表,直接进行下一个记录的查找
data_pre.append(tmp_data)
return data_pre
def ppreProcessing(data, vote_y_n, party):
'''
数据预处理
以按 y 或 n 和议员所属党派来寻找关联规则
'''
data_pre = []
for data_line in data:
tmp_data = []
if data_line[0] == party:
for i in range(1, len(data_line)):
# 从第二列开始,将数据文件中的记录与当前的选择vote_y_n进行比较,若找到了相关记录,把下标存进去
if (data_line[i] == vote_y_n):
tmp_data.append(i)
if (tmp_data == []):
continue#如果当前这一条记录中没有任何一个项是vote_y_n或者这条记录不是对应party的议员对应的选项,那么不存储空列表,直接进行下一个记录的查找
data_pre.append(tmp_data)
return data_pre
def rule_mining(data, support, confidence):
'''
挖掘关联规则
'''
dic_1 = mining_first(data, support, confidence)
# print(dic_1)
dic_2 = mining_second(data, dic_1, support, confidence)
# print(dic_2)
dic_before = dic_2
dic_r = []
#频繁项集产生的终止条件就是不再有新的频繁项集产生为止
while (dic_before != {}):
#dict_r里面存储的是频繁2-项集及之后的所有频繁项集
dic_r.append(dic_before)
dic_3 = mining_third(data, dic_before, support, confidence)
dic_before = dic_3
return dic_r
pass
def mining_first(data, support, confidence):
'''
进行第一次挖掘
挖掘候选1-项集
'''
dic = {}
count = len(data)
for data_line in data:
#对于数据集中的每一行投票数据
for data_item in data_line:
#对于每一行数据中的下标(对应某个议题)
if (data_item in dic):
#以键值对的形式进行存储和计数
dic[data_item] += 1
else:
dic[data_item] = 1
assert (support >= 0) and (support <= 1), 'suport must be in 0-1'
#依靠给定的支持度阈值和投票数据的总数的得到满足条件的最小支持度值
val_suport = int(count * support)
assert (confidence >= 0) and (confidence <= 1), 'coincidence must be in 0-1'
#如果键值对中的值大于或等于当前支持度阈值,则可以将该键值对作为频繁1-项集保留
dic_1 = {}
for item in dic:#如果对每一个议题的所选定的(y|n)进行计数,若计数总值超过了支持度所需要的计数,就把它放到下一个字典中
if (dic[item] >= val_suport):
dic_1[item] = dic[item]
return dic_1
def mining_second(data, dic_before, support, confidence):
'''
进行关联规则的二次挖掘
挖掘出候选2-项集
注:所有挖掘出来的频繁项集都是以字典的形式存储的,字典的键是频繁项集,
1频繁项集用1-16个整数,表示这些议题在原数据集中的下标;多频繁集就是这些下标的一个元组
隐藏含义是这些议题共同被投票为vote_y_n,字典的值就是这样的组合出现的次数
'''
#每一次扩展频繁项集的时候产生一个临时dict用于保存那些通过频繁项集生成算法可以留下的项集
#但是还要对其中的结果进行支持度判断,才能确定最终留下的算法
dic = {}
count = len(data)
count2 = 0
for data_line in data:
# 获取元素数量
count_item = len(data_line)
# 每两个组合计数
for i in range(0, count_item - 1):
#外层循环,控制频繁2-项集中的第一个元素的取值
for j in range(i + 1, count_item):
#内层循环,控制频繁2-项集中的第二个元素的取值
if (data_line[i] in dic_before and data_line[j] in dic_before):
count2 += 1
tmp = (data_line[i], data_line[j])
if (tmp in dic):
#上同,使用键值对集合计数,只不过此时元素是二元的元组
dic[tmp] += 1
else:
dic[tmp] = 1
else:
continue
#当两个项中有一个不是频繁1-项集,根据剪枝策略,这样组成的项不是频繁2-项集
# print(dic)
assert (support >= 0) and (support <= 1), 'suport must be in 0-1'
assert (confidence >= 0) and (confidence <= 1), 'confidence must be in 0-1'
dic_2 = {}
for item in dic:
count_item0 = dic_before[item[0]]
count_item1 = dic_before[item[1]]
# 判断 支持度 和 置信度
#判断置信度的时候对于一个无序的元组,任何一种方向的规则都有可能,都要进行比较
if ((dic[item] >= support * count) and (
(dic[item] >= confidence * count_item0) or (dic[item] >= confidence * count_item1))):
dic_2[item] = dic[item]
return dic_2
def mining_third(data, dic_before, support,confidence):
'''
进行关联规则的三次挖掘
挖掘出候选3-项集或者4-项集乃至n-项集
'''
#频繁项集的产生使用Fk-1*Fk-1的策略
dic_3 = {}
for item0 in dic_before:
#外层循环控制频繁k-1项集中的某一项
for item1 in dic_before:
#内层循环控制频繁k-1项集中的另一项
if (item0 != item1):
# print(item0,item1)
item_len = len(item0)
equal = True
tmp_item3 = []
# 判断前n-1项是否一致
for i in range(item_len - 1):
tmp_item3.append(item0[i])
if (item0[i] != item1[i]):
equal = False
break
if (equal == True):
#如果两个Fk-1项具有k-2个公共前缀,那么就按照顺序,将其组合起来
minitem = min(item0[-1], item1[-1])
maxitem = max(item0[-1], item1[-1])
tmp_item3.append(minitem)
tmp_item3.append(maxitem)
tmp_item3 = tuple(tmp_item3)
dic_3[tmp_item3] = 0
else:
continue
# print('dic_3:',dic_3)
#暴力统计支持度的方法,对于每一个数据项,看每个新找到的k项集是否包含在数据项中
#比较的方法,是对项的每一位进行判断,看这一位是否在数据项中
for data_line in data:
for item in dic_3:
is_in = True
for i in range(len(item)):
if (item[i] not in data_line):
is_in = False
#该候选k项集中的所有项都在数据项中,则可以将该项保留
if (is_in == True):
dic_3[item] += 1
assert (support >= 0) and (support <= 1), 'suport must be in 0-1'
assert (confidence >= 0) and (confidence <= 1), 'coincidence must be in 0-1'
count = len(data)
dic_3n = {}
for item in dic_3:
#前一项的支持度计数,就是现在的项除去末尾的数字,通过键值对在原来的字典中查询的值
count_item0 = dic_before[item[:-1]]
# 判断 支持度 和 置信度
if ((dic_3[item] >= support * count) and (dic_3[item] >= confidence * count_item0)):
dic_3n[item] = dic_3[item]
return dic_3n
def association_rules(freq_sets, min_conf):
'''
根据产生的频繁项集生成满足置信度要求的规则
:param dict: 频繁项集的字典
:param dict: 频繁项集字典中的频繁项集列表
:param min_conf: 最小置信度
:return: 规则列表
'''
rules = []
max_len = len(freq_sets)
for k in range(max_len - 1):
for freq_set in freq_sets[k]:
for sub_set in freq_sets[k + 1]:
if set(freq_set).issubset(set(sub_set)):
conf = freq_sets[k+1][sub_set] / freq_sets[k][freq_set]
rule = (set(freq_set), set(sub_set) - set(freq_set), conf)
if conf >= min_conf:
rules.append(rule)
return rules
if (__name__ == '__main__'):
data_row = loadData()
data_y = preProcessing(data_row, 'y')
data_n = preProcessing(data_row, 'n')
data_y_republican = ppreProcessing(data_row, 'y', 'republican')
data_y_democrat = ppreProcessing(data_row, 'y', 'democrat')
data_n_republican = ppreProcessing(data_row, 'n', 'republican')
data_n_democrat = ppreProcessing(data_row, 'n', 'democrat')
# 支持度
support = 0.3
# 置信度
confidence = 0.9
#总的y规则与两个党派的y规则
r_y = rule_mining(data_y, support, confidence)
print('vote `y`:\n', r_y)
rule_y = association_rules(r_y, confidence)
print('rule `y`:\n', rule_y)
r_y_republican = rule_mining(data_y_republican, support, confidence)
print('vote_republican `y`:\n', r_y_republican)
rule_y_republican = association_rules(r_y_republican, confidence)
print('rule_republican `y`:\n', rule_y_republican)
r_y_democrat = rule_mining(data_y_democrat, support, confidence)
print('vote_democrat `y`:\n', r_y_democrat)
rule_y_democrat = association_rules(r_y_democrat, confidence)
print('rule_democrat `y`:\n', rule_y_democrat)
#总的n规则与两个党派的n规则
r_n = rule_mining(data_n, support, confidence)
print('vote `n`:\n', r_n)
rule_n = association_rules(r_n, confidence)
print('rule `n`:\n', rule_n)
r_n_republican = rule_mining(data_n_republican, support, confidence)
print('vote_republican `n`:\n', r_n_republican)
rule_n_republican = association_rules(r_n_republican, confidence)
print('rule `n`:\n', rule_n_republican)
r_n_democrat = rule_mining(data_n_democrat, support, confidence)
print('vote_democrat `n`:\n', r_n_democrat)
rule_n_democrat = association_rules(r_n_democrat, confidence)
print('rule_democrat `n`:\n', rule_n_democrat)
f = open('result_mining.txt', 'w')
f.write('vote `y`:\n')
f.write(str(r_y))
f.write('rule `y`:\n')
f.write(str(rule_y))
f.write('\n\nvote `n`:\n')
f.write(str(r_n))
f.write('rule `n`:\n')
f.write(str(rule_y))
f.close()
实验报告+源码