Pandas 操作数据(三)
一、汇总和计算统计

1、mean()平均值 ,默认skipna=True 是不计算空值NaN;
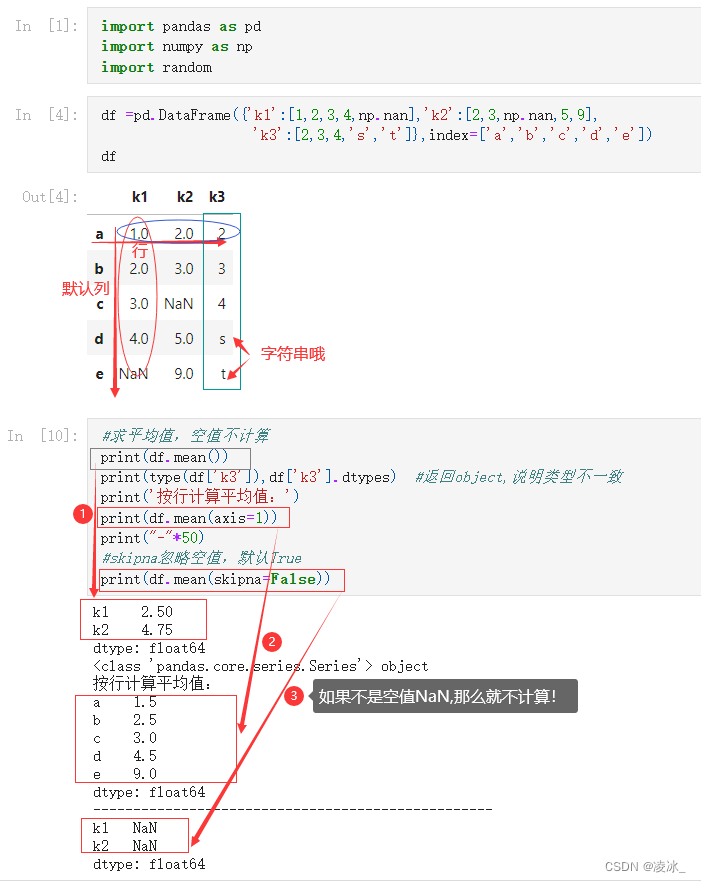 2、sum() 求和,idxmax() 求最大值索引值,依此类推idxmin()类似
2、sum() 求和,idxmax() 求最大值索引值,依此类推idxmin()类似

3、describe() 针对 Series 或 DF 的列计算汇总统计

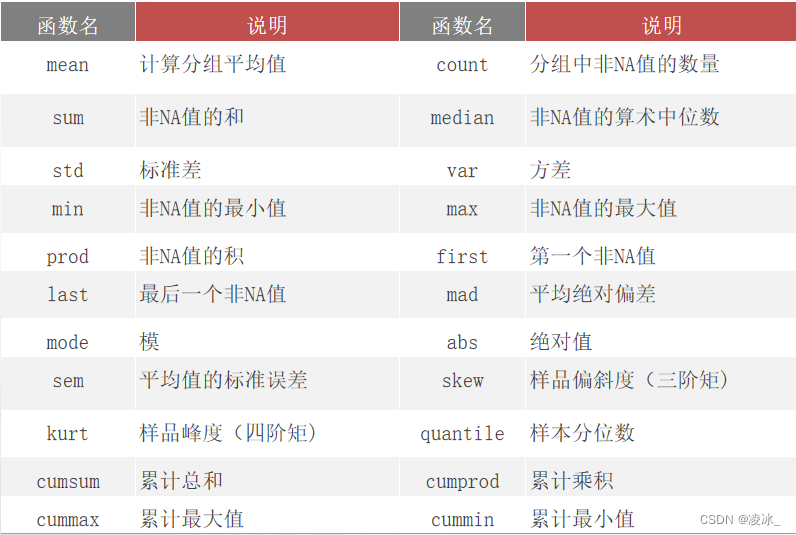
4、其他统计方法,min(),max(),mean(),median(),std(),var(),kurt()等等

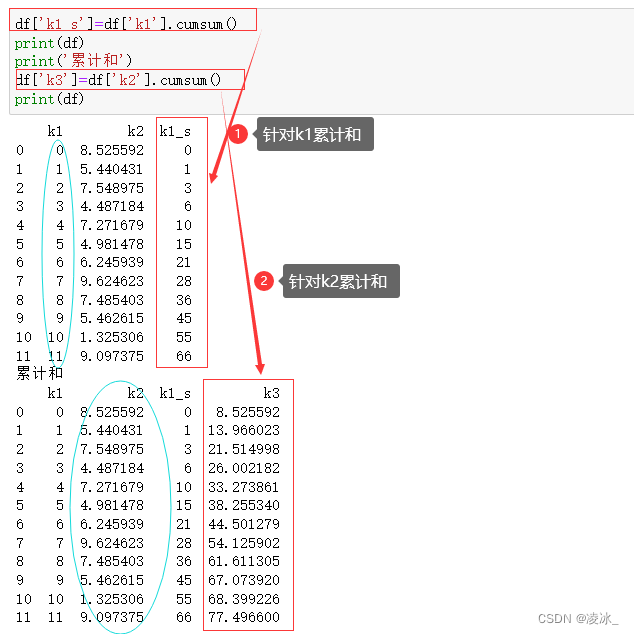
5、cumsum()累计和
二、数据处理

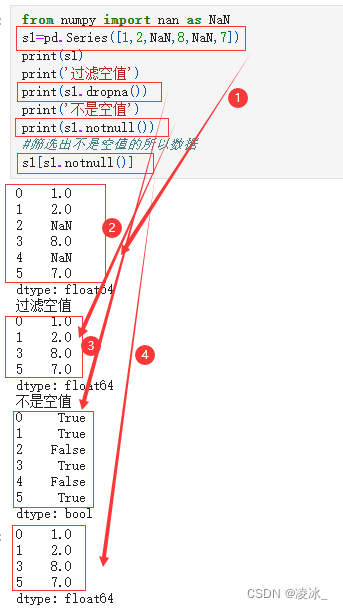
1.1、使用s1=pd.Series(), 过滤空值s1.dropna();不是空值s1.notnull();获取不是空值的值;
1.2、使用df=pd.DataFrame()。在默认情况下,按照 axis=0 来按行处理过滤空值df.dropna();

2、fillna() 常数填充空值

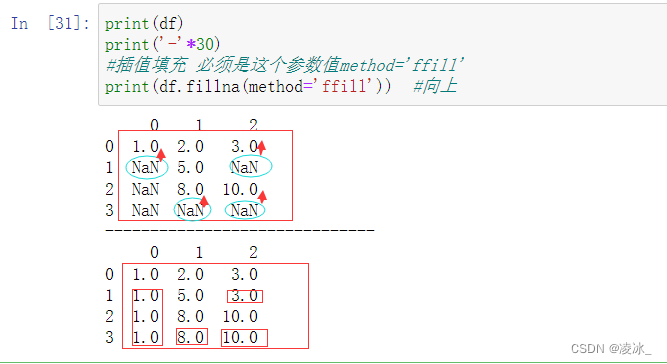
fillna() 插值填充空值

fillna() 均值填充空值

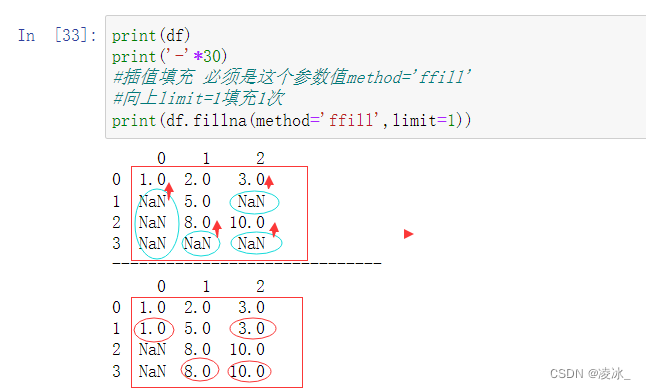
向上->参数值method='ffill'
向下->参数值method='bfill'

向上->参数值method='ffill' ,限制次数limit=1
3、去重复duplicated()

删除重复的drop_duplicated()

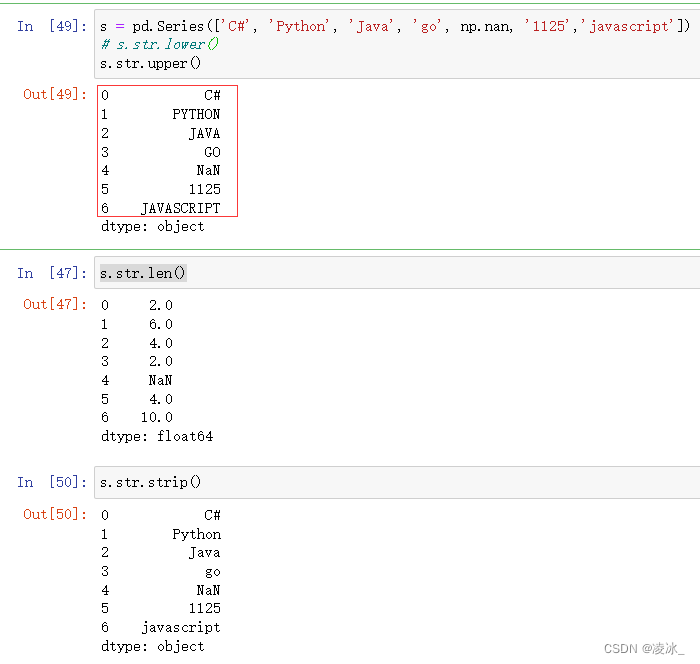
三、字符串 str




四、分组聚合
对分组数据进行聚合、转换,或者过滤
- 拆分(Spliting):表示对数据进行分组;
- 应用(Applying):对分组数据应用聚合函数,进行相应计算;
- 合并(Combining):最后汇总计算结果。
groupby语法:
参数说明:

group by 与聚合函数一起使用
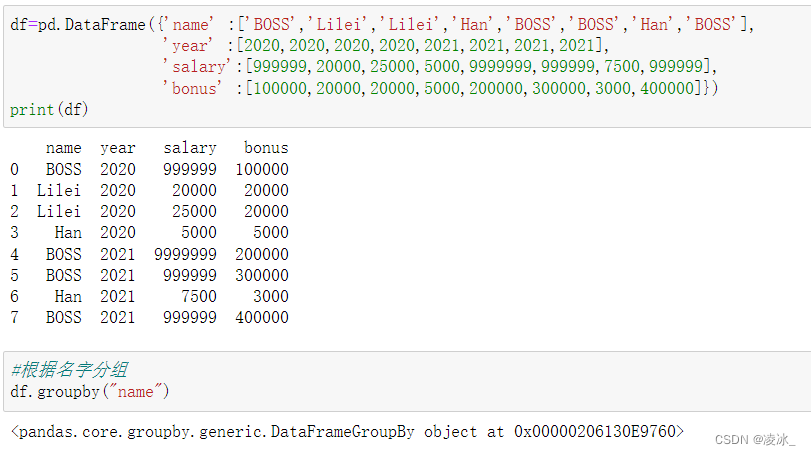
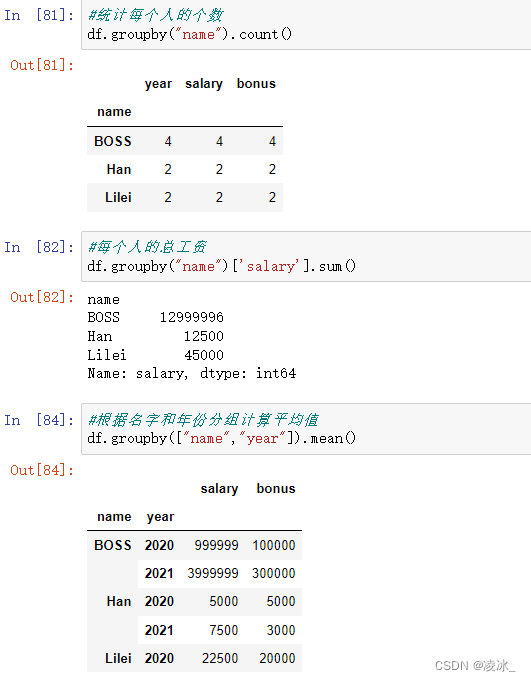
1、2、 创建groupby分组对象
使用 groupby() 可以沿着任意轴分组。您可以把分组时指定的键(key)作为每组的组名,
方法如下所示:
- df.groupby("key")
- df.groupby("key",axis=1)
- df.groupby(["key1","key2"])
2、 查看分组结果
应用聚合函数
通过 agg() 函数可以对分组对象应用多个聚合函数:

组的数据过滤操作
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集。
 五、透视表
五、透视表
1、透视表是一种可以对数据动态排布并且分类汇总的表格格式
2、为何使用pivot_table
- 灵活性高,可以随意定制你的分析计算要求
- 清晰易于理解数据
- 操作性强,报表神器
3、使用透视图:




