Hadoop与Spark中的Shuffle过程梳理
文章目录
- 1 Hadoop的shuffle过程
- 2 Spark的Shuffle过程
- 2.1 RDD依赖关系与Stage划分
- 2.2 HashShuffle解析
- 2.3 SortShuffle解析
- 3 Hadoop与Spark的Shuffle对比
1 Hadoop的shuffle过程
Map 方法之后,Reduce 方法之前的数据处理过程称之为Shuffle。
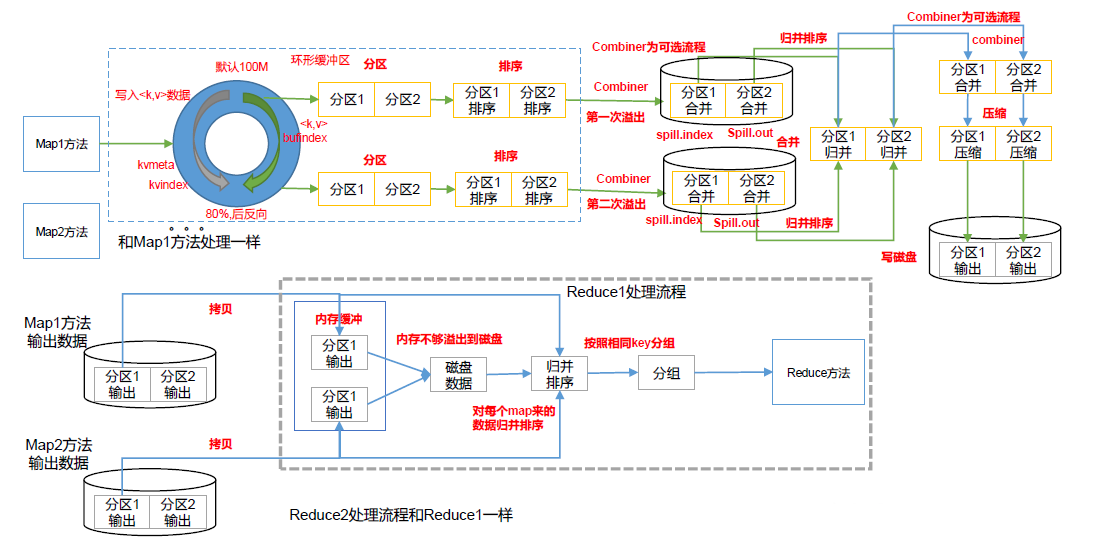
Shuffle的具体过程如下:
(1)MapTask 收集我们的 map()方法输出的 kv对,放到内存缓冲区中;
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件;
(3)多个溢出文件会被合并成大的溢出文件;
(4)在溢出过程及合并的过程中,都要调用 Partitioner进行分区和针对key 进行排序;
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据;
(6)ReduceTask会抓取到同一个分区的来自不同 MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序);
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入 ReduceTask 的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)。
2 Spark的Shuffle过程
2.1 RDD依赖关系与Stage划分
RDD的依赖关系,其实就是两个相邻RDD之间的关系。
RDD的依赖分为窄依赖和宽依赖。
窄依赖表示每一个父(上游)RDD的Partition最多被子(下游)RDD的一个Partition使用。
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency [T](rdd)
宽依赖表示同一个父(上游)RDD的Partition被多个子(下游)RDD的Partition依赖,会引起Shuffle。
class ShuffleDependency [K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K,
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C ]] =
val mapSideCombine: Boolean = false)
extends Dependency [Product2[K, V]]
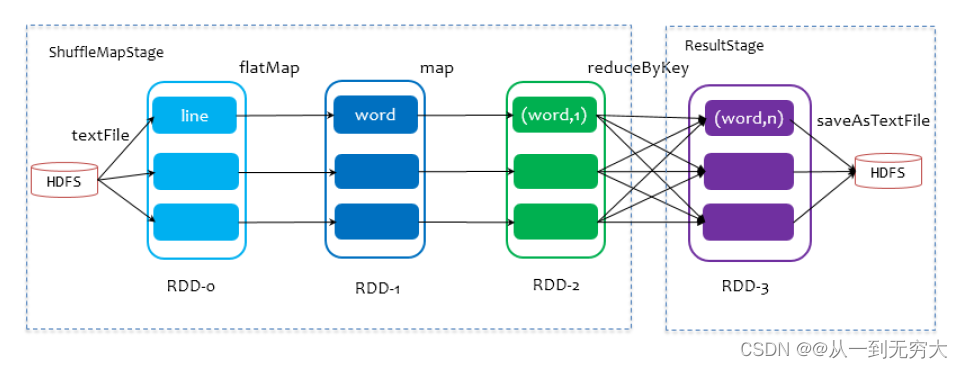
在进行Stage划分时,以 RDD宽依赖 (即 Shuffle)为界,遇到 Shuffle做一次划分。最后一个 Stage称为 finalStage,它本质上是一个 ResultStage对象,前面的所有 Stage被称为 ShuffleMapStage。
ShuffleMapStage的结束伴随着 Shuffle文件的写磁盘。
ResultStage基本上对应代码中的 action算子,即将一个函数应用在 RDD的各个 partition的数据集上,意味着一个 job的运行结束。
2.2 HashShuffle解析
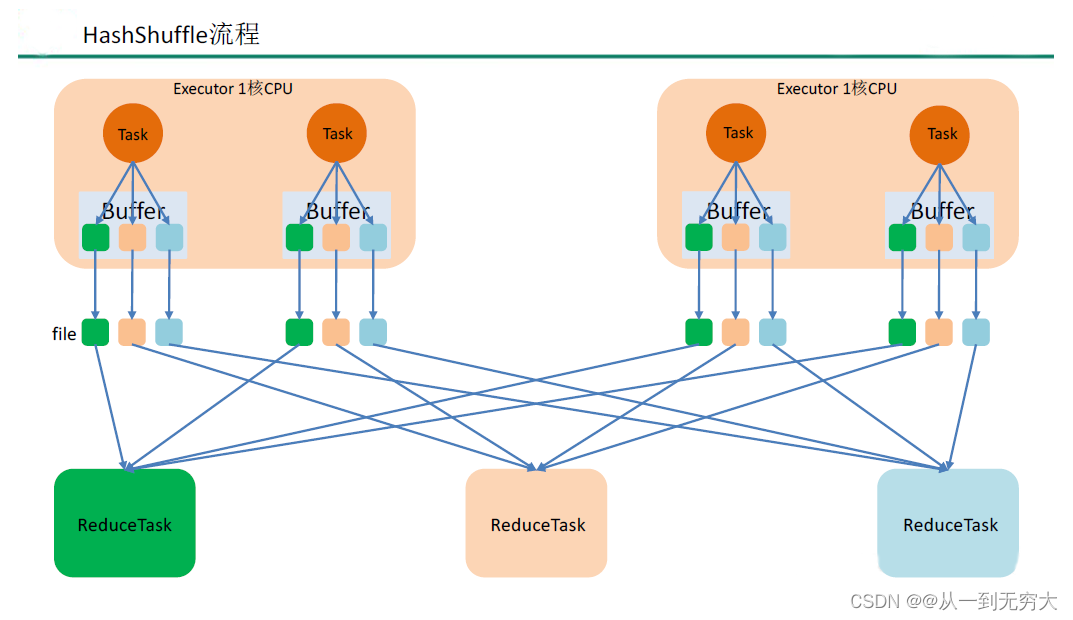
未优化的 HashShuffle
这里我们先明确一个假设前提:每个Executor只有 1个 CPU core,也就是说,无论这个 Executor上分配多少个 task线程,同一时间都只能执行一个 task线程。
如下图中有3个 Reducer,从 Task 开始那边各自把自己进行 Hash 计算 (分区器:hash/numreduce取模 ),分类出 3个不同的类别,每个 Task 都分成 3种类别的数据,想把不同的数据汇聚然后计算出最终的结果,所以 Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,每 1个 Task 输出 3份本地文件,这里有 4个Mapper Tasks,所以总共输出了 4个 Tasks x 3个分类文件 = 12个本地小文件。
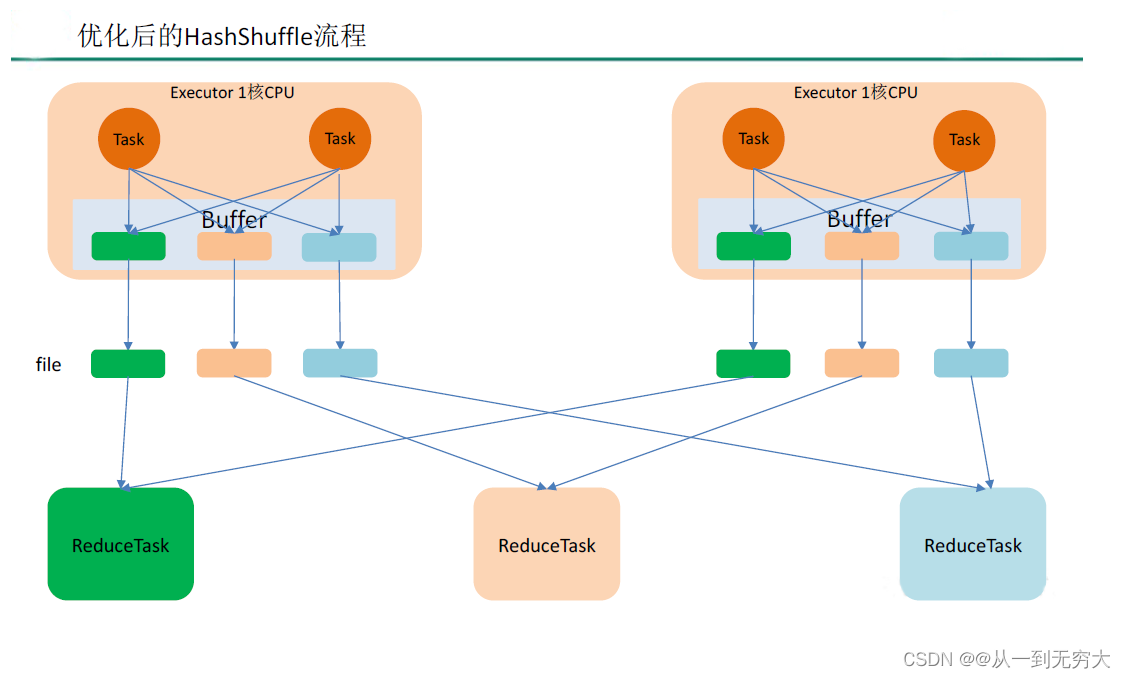
优化后的HashShuffle
优化的HashShuffle 过程就是启用合并机制,合并机制就是复用buffer,开启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true 即可开启优化机制。通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
这里还是有4 个Tasks,数据类别还是分成3 种类型,因为Hash 算法会根据你的 Key进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key 放在同一个Buffer里,然后把Buffer 中的数据写入以Core 数量为单位的本地文件中,(一个Core 只有一种类型的Key 的数据),每1 个Task 所在的进程中,分别写入共同进程中的3 份本地文件,这里有4 个Mapper Tasks,所以总共输出是 2 个Cores x 3 个分类文件 = 6 个本地小文件。
2.3 SortShuffle解析
普通 SortShuffle
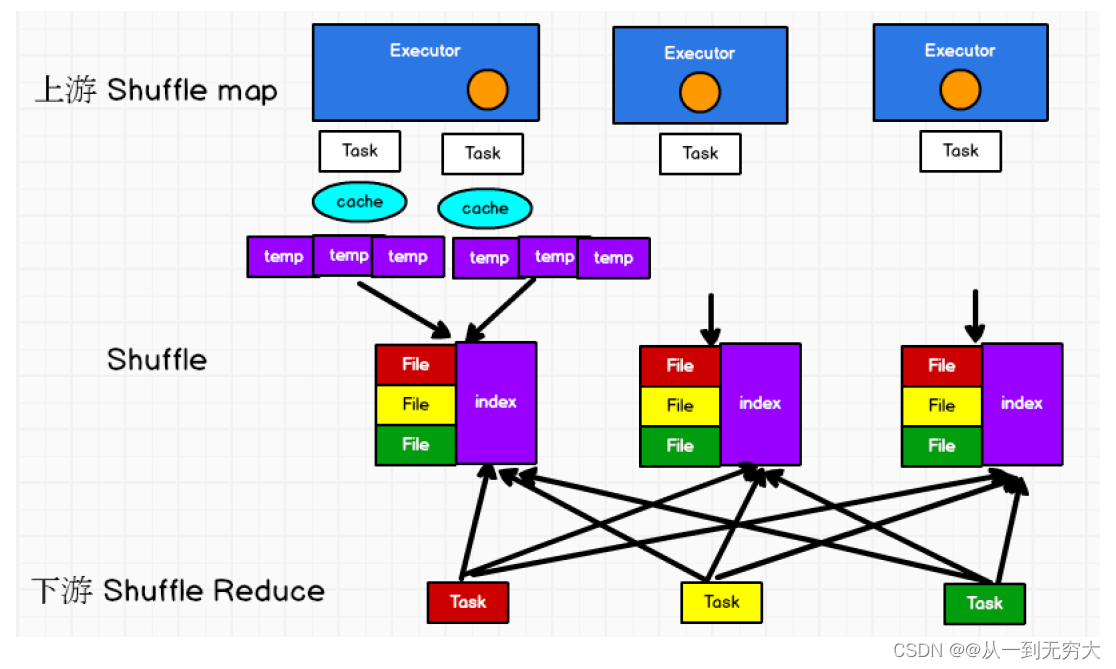
在该模式下,数据会先写入一个数据结构,reduceByKey 写入 Map ,一边通过 Map 局部聚合,一遍写入内存。 Join算子写入 ArrayList直接写入内存中。然后需要判断是否达到阈值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
在溢写磁盘前,先根据key进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为 10000条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件, 也就是说一个 Task过程会产生多个临时文件。
最后在每个Task中,将所有的临时文件合并,这就是 merge过程,此过程将所有临时文件读取出来,一次写入到最终文件。 意味着一个 Task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个 Task的数据在文件中的索引, start offset和 end offset。
bypass Sort Shuffle
bypass运行机制的触发条件如下:
(1)Shuffle reduce task 数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值 ,默认为 200 。
(2)不是聚合类的 shuffle 算子 比如 reduceByKey 。此时task 会为每个 reduce 端的 task 都创建一个临时磁盘文件,并将数据按 key 进行hash,然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager来说, Shuffle read 的性能会更好。
而该机制与普通SortShuffleManager 运行机制的不同在于:不会进行排序。也就是说,启用该机制的最大好处在于, Shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
| 处理器 | 写对象 | 判断条件 |
|---|---|---|
| SerializedShuffleHandle | UnsafeShuffleWriter | 1. 序列化规则支持重定位操作(java序列化不支持,Kryo支持)2. 不能使用预聚合 3. 如果下游的分区数量小于或等于16777216 |
| BypassMergeSortShuffleHandle | BypassMergeSortShuffleWriter | 1. 不能使用预聚合 2. 如果下游的分区数量小于等于200(可配) |
| BaseShuffleHandle | SortShuffleWriter | 其他情况 |
3 Hadoop与Spark的Shuffle对比
Shuffle会带来性能消耗,主要涉及磁盘IO,网络IO,对象的序列化和反序列化等,因此Shuffle操作能避免尽量避免。
(1)Spark的Shuffle和Hadoop的Shuffle目的都是为了在不同的task交换数据。
(2)Spark的Shuffle借鉴了Hadoop的Shuffle,但是在细节上略有不同。Hadoop的Shuffle在到达reduceTask时,会按分区进行归并排序。而在Spark中,数据在reduceTask端一定不排序。在mapTask端,可以根据设置进行排序或不排。
(3)Spark只有特定的算子才会触发Shuffle,例如重新分区的算子coalesce, repartition;byKey类型的算子reduceByKey,groupByKey,aggregateByKey,foldByKey, combineByKey,sortByKey;join类型的算子join,leftOuterJoin,cogroup 等。
参考:
https://www.bilibili.com/video/BV1Qp4y1n7ENspm_id_from=333.337.searchcard.all.click&vd_source=ff364c22743db2666f3a26c417a3f759
https://www.bilibili.com/video/BV11A411L7CKp=149&vd_source=ff364c22743db2666f3a26c417a3f759
http://t.zoukankan.com/itboys-p-14168903.html