PostgreSQL数据库统计信息——acquire_sample_rows采样函数
我们知道src/backend/commands/analyze.c文件中do_analyze_rel函数的采样工作是由如下工作完成:
/* Acquire the sample rows */
rows = (HeapTuple *) palloc(targrows * sizeof(HeapTuple));
if (inh) numrows = acquire_inherited_sample_rows(onerel, elevel, rows, targrows, &totalrows, &totaldeadrows);
else numrows = (*acquirefunc) (onerel, elevel, rows, targrows, &totalrows, &totaldeadrows);
这里分析以下acquire_sample_rows的主要流程,先看一下注释,该函数用于从表中获取一份随机采样的样本,采样的元组存放于形参rows中,采样的真实行数通过返回值返回,同样估计的live和dead行数通过totalrows和totaldeadrows返回。自2004年5月起,我们使用了一种新的两阶段方法:第一阶段选择最多targrows个随机块random blocks(或所有块,如果没有那么多)。第二阶段扫描这些块并使用Vitter算法创建一个targrows 行的随机样本 (或更少,如果块样本中的行较少)。这两个阶段同时执行:每个块在第一阶段返回其编号时立即处理,并且在读取行时,第二阶段控制哪些行要插入到样本中。尽管每一行进入最终样本的机会均等,但这种抽样方法并不完美:并非每个可能的样本都有均等的机会被选中。对于大表,样本所代表的不同块的数量往往太少。
总结一下分为两个阶段进行采集:阶段一随机选择包含目标采样行数的数据块;阶段二对每一个数据块使用 Vitter 算法按行随机采样数据。
Knuth’s Algorithm S算法采样数据块
随机数算法使用的是Knuth’s Algorithm S,具体流程如下: 设k为样本大小, K为抽样对象大小, i为当前对象,V生成的0-1之间的随机数
while i < k
p = k/(K - i);
if V < p
pick it
k--;
i++
postgresql源码使用BlockSamplerData存储如上算法需要的变量,void BlockSampler_Init(BlockSampler bs, BlockNumber nblocks, int samplesize, long randseed)函数将bs->N设置为nblocks作为抽样对象大小(表总的数据块)、将bs->n设置为samplesize作为样本大小(采样目标行数)、bs->t设置为0、bs->m设置为0。random()函数返回的随机数设置到bs->randstate中。
typedef struct{
BlockNumber N; /* number of blocks, known in advance */ // 抽样对象大小
int n; /* desired sample size */
BlockNumber t; /* current block number */
int m; /* blocks selected so far */
SamplerRandomState randstate; /* random generator state */
} BlockSamplerData;
typedef unsigned short SamplerRandomState[3];
算法主要流程如下所示,BlockSampler_HasMore函数只包含一行代码return (bs->t < bs->N) && (bs->m < bs->n),其中(bs->m < bs->n)就是代表Knuth’s Algorithm S算法中的i < k,而(bs->t < bs->N)确保采样的块号不超过表总数据块数。
BlockSampler_Init(&bs, totalblocks, targrows, random());
while (BlockSampler_HasMore(&bs)){
BlockNumber targblock = BlockSampler_Next(&bs);
}
BlockSampler_Next这段代码与Knuth的算法并不相同。s.Knuth说以概率1-k/k跳过当前块。如果要跳过,我们应该提前t(因此减少K),并对下一个块重复相同的概率测试。因此,朴素的实现需要对每个块号调用sampler_random_fract函数。但我们可以将其减少为每个选定块的一个sampler_random_fract调用,注意每次while测试成功时,我们可以将V重新解释为0到p范围内的统一随机数。因此,我们不选择新的V,只需将p调整为其前一个值的适当分数,然后我们的下一个循环进行适当的概率测试。我们最初的K>k>0。如果循环将K减少到等于k,则下一个while测试必须失败,因为p将完全变为零(我们假设除法中没有舍入误差)。(注意:Knuth建议使用“<=”循环条件,但我们使用“<”只是为了双倍确定舍入误差。)因此,K不能小于k,这意味着我们不能选择足够的块。
BlockNumber BlockSampler_Next(BlockSampler bs) {
BlockNumber K = bs->N - bs->t; /* remaining blocks */ // 剩余带抽样数据块
int k = bs->n - bs->m; /* blocks still to sample */ // 还需要抽样的数据块数目
double p; /* probability to skip block */
double V; /* random */
if ((BlockNumber) k >= K) { /* need all the rest */ // 剩余带抽样数据库不够,剩下的都需要
bs->m++; // 当前已抽样数据块数量++
return bs->t++; // 使用该数据库
}
V = sampler_random_fract(bs->randstate); // 产生V 0-1之间的随机数
p = 1.0 - (double) k / (double) K;
while (V < p){
bs->t++; /* skip */ // 跳过该数据块
K--; /* keep K == N - t */
p *= 1.0 - (double) k / (double) K; /* adjust p to be new cutoff point in reduced range */
}
bs->m++; /* select */ // 当前已抽样数据块数量++
return bs->t++; // 使用该数据块
}
Algorithm Z算法采样数据行
reservoir_init_selection_state和reservoir_get_next_S这两个例程实现了杰弗里·S·维特(Jeffrey S.Vitter)在ACM Trans发表的“Random sampling with a reservoir”算法Z。Vitter根据处理另一记录之前要跳过的记录的计数S描述了他的算法。它主要是基于t计算的,t是已经读取的记录数。调用之间唯一需要的额外状态是W,一个随机状态变量。reservoir_init_selection_state计算初始W值。假设我们已经读取了t条记录(t>=n),则reservoir_get_next_S确定在处理下一条记录之前要跳过的记录数。These two routines embody Algorithm Z from “Random sampling with a reservoir” by Jeffrey S. Vitter, in ACM Trans. Math. Softw. 11, 1 (Mar. 1985), Pages 37-57. Vitter describes his algorithm in terms of the count S of records to skip before processing another record. It is computed primarily based on t, the number of records already read. The only extra state needed between calls is W, a random state variable. reservoir_init_selection_state computes the initial W value. Given that we’ve already read t records (t >= n), reservoir_get_next_S determines the number of records to skip before the next record is processed.
水库抽样算法为空间亚线性算法,可以在减少计算内存使用量的同时保证抽样数据的均匀性和准确性。输入为一组数据,其大小未知。
输出为这组数据的k个均匀抽样。要求为扫描一次数据、空间复杂性位O(k)、扫描到数据的前n个数字时(n>k),保存当前已扫描数据的k个均匀抽样。水库抽抽样算法的实现如下:
- 申请长度为k的数组A保存抽样;
- 首先保存最先接收的k个数据;
- 当收到第i个数据t时,生成[1,i]间的随机数j,如若j<=k,则以t替换A[j]。第三步的随机替换保证了数据的均匀性和完整数据的概率特征。
水库抽样算法的原理:对于每个新到来的数据i,收入样本的概率为k/i。当第i+1个数据到来时,第i+1个数据被替换到抽样中的概率Pi=k/(i + 1)。而此时,前一个元素i被从中替换出的概率为Pc=1/k。则第i+1个数据替换出第i个数据的概率为PiPc,第i个数据没有被第i+1个数据替换出的概率为P=1-PiPc=1 - (k/(i + 1) * (1/k))=1 - 1/(i + 1)。由此可知,当第i+2,i+3…个数据到来时,第i个数据没有被替换出来的概率为1 - 1/(i + 2),1 - 1/(i + 3)… 根据古典概型,当元素i被选入且保留至最后扫描完成时的概率为:
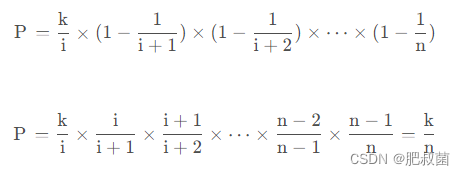
由公式可以推导出对于这组数据的所有元素,选入样本的概率都为k/n,这样便可以得到从A中均匀抽样的数据。
算法主要流程如下所示,reservoir_init_selection_state函数使用随机数初始化ReservoirState->randstate,初始化ReservoirState->W。
typedef struct
{
double W;
SamplerRandomState randstate; /* random generator state */
} ReservoirStateData;
typedef unsigned short SamplerRandomState[3];
void reservoir_init_selection_state(ReservoirState rs, int n){
sampler_random_init_state(random(), rs->randstate); /* Reservoir sampling is not used anywhere where it would need to return repeatable results so we can initialize it randomly. */ // 水库采样不用于需要返回可重复结果的任何地方,因此我们可以随机初始化
rs->W = exp(-log(sampler_random_fract(rs->randstate)) / n); /* Initial value of W (for use when Algorithm Z is first applied) */
}
reservoir_get_next_S函数的详细代码如下,这里不做详细介绍。
double reservoir_get_next_S(ReservoirState rs, double t, int n) {
double S;
if (t <= (22.0 * n)) { /* The magic constant here is T from Vitter's paper */
/* Process records using Algorithm X until t is large enough */
double V, quot;
V = sampler_random_fract(rs->randstate); /* Generate V */
S = 0;
t += 1;
/* Note: "num" in Vitter's code is always equal to t - n */
quot = (t - (double) n) / t;
while (quot > V){ /* Find min S satisfying (4.1) */
S += 1;
t += 1;
quot *= (t - (double) n) / t;
}
}else{
/* Now apply Algorithm Z */
double W = rs->W;
double term = t - (double) n + 1;
for (;;){
double numer,numer_lim,denom;
double U,X,lhs,rhs,y,tmp;
/* Generate U and X */
U = sampler_random_fract(rs->randstate);
X = t * (W - 1.0);
S = floor(X); /* S is tentatively set to floor(X) */
/* Test if U <= h(S)/cg(X) in the manner of (6.3) */
tmp = (t + 1) / term;
lhs = exp(log(((U * tmp * tmp) * (term + S)) / (t + X)) / n);
rhs = (((t + X) / (term + S)) * term) / t;
if (lhs <= rhs){
W = rhs / lhs;
break;
}
/* Test if U <= f(S)/cg(X) */
y = (((U * (t + 1)) / term) * (t + S + 1)) / (t + X);
if ((double) n < S){
denom = t;
numer_lim = term + S;
}else{
denom = t - (double) n + S;
numer_lim = t + 1;
}
for (numer = t + S; numer >= numer_lim; numer -= 1){
y *= numer / denom;
denom -= 1;
}
W = exp(-log(sampler_random_fract(rs->randstate)) / n); /* Generate W in advance */
if (exp(log(y) / n) <= (t + X) / t)
break;
}
rs->W = W;
}
return S;
}
acquire_sample_rows采样函数
acquire_sample_rows采样函数利用Knuth’s Algorithm S算法采样数据块、Algorithm Z算法采样数据行。采样数据库和采样数据行的算法已经在上面描述过了,这里从获取了目标数据块开始描述acquire_sample_rows采样函数的具体逻辑。两阶段同时进行,并且可以看到采样过程也会受到vacuum_cost_delay的影响。while (table_scan_analyze_next_tuple(scan, OldestXmin, &liverows, &deadrows, slot))函数体就是在处理水库采样的过程。在采样完成后,被采样到的元组应该已经被放置在元组数组中了。对这个元组数组按照元组的位置进行快速排序,并使用这些采样到的数据估算整个表中的存活元组live行数/采样样本行数*总数据块 + 0.5与死元组dead行数/采样样本行数*总数据块 + 0.5的个数。
static int acquire_sample_rows(Relation onerel, int elevel, HeapTuple *rows, int targrows, double *totalrows, double *totaldeadrows) {
int numrows = 0; /* # rows now in reservoir */
double samplerows = 0/* total # rows collected */, liverows = 0/* # live rows seen */, deadrows = 0/* # dead rows seen */, rowstoskip = -1 /* -1 means not set yet */;
BlockNumber totalblocks;
TransactionId OldestXmin;
BlockSamplerData bs;
ReservoirStateData rstate;
TupleTableSlot *slot;
TableScanDesc scan;
totalblocks = RelationGetNumberOfBlocks(onerel); // 首先获取该表有多少数据块
OldestXmin = GetOldestXmin(onerel, PROCARRAY_FLAGS_VACUUM); /* Need a cutoff xmin for HeapTupleSatisfiesVacuum */
BlockSampler_Init(&bs, totalblocks, targrows, random()); /* Prepare for sampling block numbers */ //Algorithm Z算法采样数据行准备工作
reservoir_init_selection_state(&rstate, targrows); /* Prepare for sampling rows */ //Algorithm Z算法采样数据行准备工作
scan = table_beginscan_analyze(onerel);
slot = table_slot_create(onerel, NULL);
while (BlockSampler_HasMore(&bs)) { /* Outer loop over blocks to sample */
BlockNumber targblock = BlockSampler_Next(&bs); // 获取目标数据块
vacuum_delay_point();
if (!table_scan_analyze_next_block(scan, targblock, vac_strategy)) continue; // 目标数据块不适合采样
while (table_scan_analyze_next_tuple(scan, OldestXmin, &liverows, &deadrows, slot)) {
/* The first targrows sample rows are simply copied into the reservoir. Then we start replacing tuples in the sample until we reach the end of the relation. This algorithm is from Jeff Vitter's paper (see full citation in utils/misc/sampling.c). It works by repeatedly computing the number of tuples to skip before selecting a tuple, which replaces a randomly chosen element of the reservoir (current set of tuples). At all times the reservoir is a true random sample of the tuples we've passed over so far, so when we fall off the end of the relation we're done. */ // 第一个目标行样本行简单地复制到水库中。然后我们开始替换样本中的元组,直到到达表的末尾。该算法来自Jeff Vitter的论文(参见utils/misc/sampling.c中的完整引用)。它的工作原理是在选择元组之前重复计算要跳过的元组数,这将替换随机选择的库元素(当前元组集)。在任何时候,水库中都是到目前为止传递的元组的真正随机样本,所以当我们扫描到表的结尾时,我们就完成了
if (numrows < targrows) rows[numrows++] = ExecCopySlotHeapTuple(slot); // tuple拷贝到rows中
else { /* t in Vitter's paper is the number of records already processed. If we need to compute a new S value, we must use the not-yet-incremented value of samplerows as t. */
if (rowstoskip < 0) rowstoskip = reservoir_get_next_S(&rstate, samplerows, targrows);
if (rowstoskip <= 0) { /* Found a suitable tuple, so save it, replacing one old tuple at random */ // 替换水库中的采样元素
int k = (int) (targrows * sampler_random_fract(rstate.randstate));
heap_freetuple(rows[k]);
rows[k] = ExecCopySlotHeapTuple(slot);
}
rowstoskip -= 1;
}
samplerows += 1;
}
}
ExecDropSingleTupleTableSlot(slot);
table_endscan(scan);
/* If we didn't find as many tuples as we wanted then we're done. No sort is needed, since they're already in order. Otherwise we need to sort the collected tuples by position (itempointer). It's not worth worrying about corner cases where the tuples are already sorted. */ // 如果我们找不到我们想要的那么多元组,那么我们就完了。不需要排序,因为它们已经排序好了。否则,我们需要按位置(itempointer)对收集的元组进行排序。不必担心元组已经排序的corner cases 。
if (numrows == targrows) qsort((void *) rows, numrows, sizeof(HeapTuple), compare_rows);
/* Estimate total numbers of live and dead rows in relation, extrapolating on the assumption that the average tuple density in pages we didn't scan is the same as in the pages we did scan. Since what we scanned is a random sample of the pages in the relation, this should be a good assumption. */ // 估计相关的活行和死行总数,假设我们未扫描的页面中的平均元组密度与我们扫描的页面相同。由于我们扫描的是关系中页面的随机样本,这应该是一个很好的假设
if (bs.m > 0){
*totalrows = floor((liverows / bs.m) * totalblocks + 0.5); // live行数/采样样本行数*总数据块 + 0.5
*totaldeadrows = floor((deadrows / bs.m) * totalblocks + 0.5); // dead行数/采样样本行数*总数据块 + 0.5
}else{
*totalrows = 0.0;
*totaldeadrows = 0.0;
}
return numrows;
}