论文解读:Sadeepcry:使用自我注意和自动编码器网络的蛋白质结晶倾向预测的深度学习框架
SADeepcry: a deep learning framework for protein crystallization propensity prediction using self-attention and auto-encoder networks
期刊:BIB
分区:2区
影响因子:13.999
发表时间:2022.7.27
Github:GitHub - zhc940702/SADeepcry
目录
摘要
方法与数据集
1. Benchmark datasets
2.方法框架: SADeepcry
3. 结果
3.1 与多阶段预测器的性能比较
3.2 单级预测结果比较
3.3 膜蛋白预测结果比较
3.4 分析各种特征的贡献
4. 消融实验
5. 自注意力层数对实验的影响
6. 独立测试
7. 预测蛋白质样品
8. 结论
摘要
基于晶体学的X射线衍射(XRD)技术是分析蛋白质三维结构的主要实验方法。 XRD技术所依赖的蛋白质晶体的生产过程已经进行了多个实验步骤,这需要大量的人力和材料资源。此外,研究表明,并非所有蛋白质都可以在实验条件下形成晶体,而蛋白质最终结晶的成功率仅<10%。尽管已经开发了一些蛋白质结晶预测因子,但并没有很多能够预测多阶段蛋白质结晶倾向的工具,并且这些工具的准确性并不令人满意。在本文中,我们提出了一个新颖的深度学习框架,名为Sadeepcry,用于预测蛋白质结晶倾向。该框架可用于估计蛋白质结晶实验中的三个步骤(蛋白质材料的产生,纯化和结晶)以及最终蛋白质结晶的成功率。 Sadeepcry使用优化的自我注意力和自动编码器模块从蛋白质中提取序列,结构和理化特征。与其他最先进的蛋白质结晶预测模型相比,Sadeepcry可以获得更复杂的蛋白质序列信息的全局空间长距离依赖性。我们的计算结果表明,在基准数据集中的DCFCrystal方法上,Sadeepcry的MCC(Matthews相关系数)和AUC(曲线下的面积)分别增加了100.3%和13.4%。
方法与数据集
1. Benchmark datasets
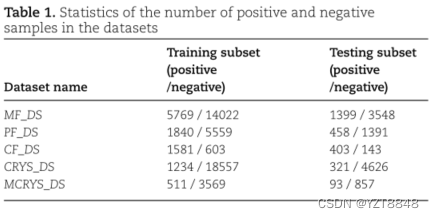
我们所有的实验均在公开可用的数据集上进行。从参考[19]获得了五个名为MF_DS,PF_DS,CF_DS,CRYS_DS和BD_MCRYS的基准数据集。数据集中的蛋白质名称及其相应的标签是从TargetTrack [22]数据库中提取的。具体而言,MF_DS,PF_DS和CF_DS数据集用于检查蛋白质材料生产步骤,纯化步骤和晶体生产步骤中方法的有效性。 CRYS_DS数据集用于检查方法在整个蛋白质结晶过程的倾向预测中的有效性。 BD_MCRYS用于检查方法在膜蛋白结晶倾向预测中的有效性。表1分别显示了五个数据集中的正和负样品的数量。对于每个基准数据集,我们根据基准数据集的训练子集训练Sadeepcry,并基于基准数据集的测试子集测试框架的预测性能。
2.方法框架: SADeepcry
本文以预测蛋白质结晶倾向的每一步和最终结晶倾向分数为目标,将蛋白质结晶倾向预测看作是多个二元分类问题。图1展示了所提出的蛋白质结晶倾向预测框架的构建。SADeepcry可以描述为四个步骤(图1),详细说明如下。
第一步:我们收集并编码蛋白质的原始序列特征和人工特征。对于蛋白质的原始氨基酸序列,在将蛋白质的原始氨基酸序列输入模型之前,需要将蛋白质序列中的每个氨基酸转换为数字向量。首先,我们使用不同的整数来表示蛋白质序列中出现的氨基酸。然后,根据每个蛋白质序列中氨基酸的类型和数量,对蛋白质的原始氨基酸序列进行编码。因为等长的蛋白质向量只能被模型作为输入数据处理。因此,我们通过零填充将每个蛋白质向量的维度大小固定为Lmax,其中Lmax为训练数据集中蛋白质序列的最大长度。得到蛋白质序列向量后,我们用Pytorch包埋层用le维密集向量表示每个氨基酸。本文的嵌入层具有可训练的查找矩阵,存储固定的氨基酸字典和大小的嵌入。矩阵的每一行对应一个氨基酸,每个氨基酸对应一个le维密度向量。
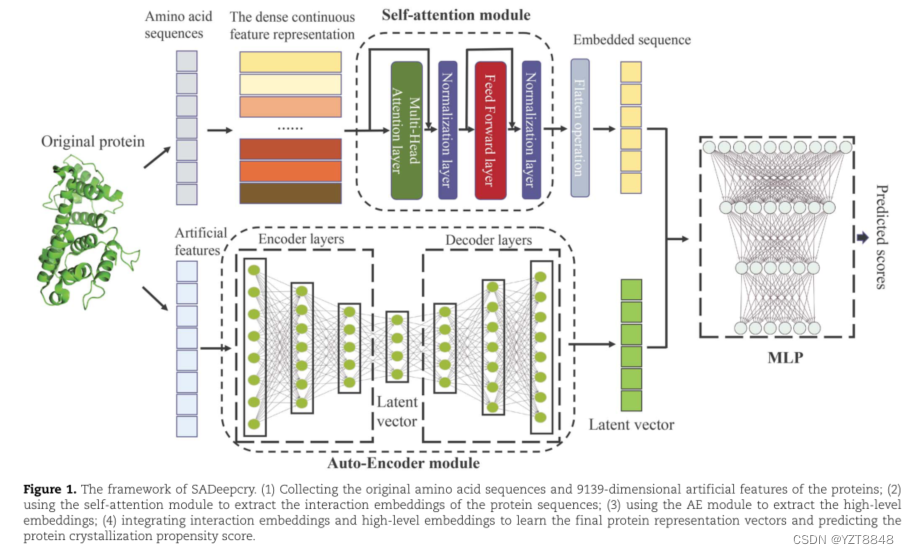
蛋白质序列向量中的值表示不同氨基酸在查找矩阵中的对应索引位置。通过对模型的不断训练,最终可以学习到每个氨基酸的合适表示。Le的搜索网格为[8,32,64,128,256],其搜索网格为[8,32,64,128,256]。在训练子集上进行10倍交叉验证,选择AUC评分最好的Le设置。根据结果,我们将Le设为128。在训练过程中,可以更新嵌入层的权值。最后,我们可以学习一个(Lmax, Le)维密集嵌入矩阵来表示蛋白质的氨基酸序列。蛋白质的9139维人工特征提取自文献[15],其中包括一些著名的物理化学、序列派生特征和一些从SCRATCH套件[23]and DISOPRED中提取的无序特征.
第二步:我们使用一个多头自注意机制来提取蛋白质序列的相互作用嵌入。受其在NLP[25]中取得巨大成功的启发,这里我们将每个蛋白质的序列作为文本中的一个句子,序列中的氨基酸对应于句子中的单词。该自注意模块包含多个相同的单元,每个单元由两个网络层组成,包括一个多头自注意机制层和一个全连接前馈网络层。在两个子层之间增加了残差连接和归一化操作。多头自注意机制层由多个标点注意层组成,用于提取蛋白质序列信息。
第三步:考虑到9139维的人工特征是高维稀疏的,我们将特征降维,并使用AE模块从稀疏的人工特征向量中提取信息。本文将声发射模块分为编码器和解码器两部分。根据经验,AE模块的编码器有三层完全连接,每层分别使用1024、512和256个神经元节点。此外,增加了激活函数[26]和退出策略[27],使模块具有良好的防过拟合能力。AE模块的解码器和编码器采用对称结构,每层分别使用256、512和1024个神经元节点。我们在AE模块中输入9139维人工特征,然后提取中间变量潜在向量作为蛋白质的高级嵌入。
第四步:我们采用MLP网络进行预测任务。我们将自注意模块输出的矢量和声发射的潜在矢量连接起来,然后输入到MLP模块中。
3. 结果
3.1 与多阶段预测器的性能比较
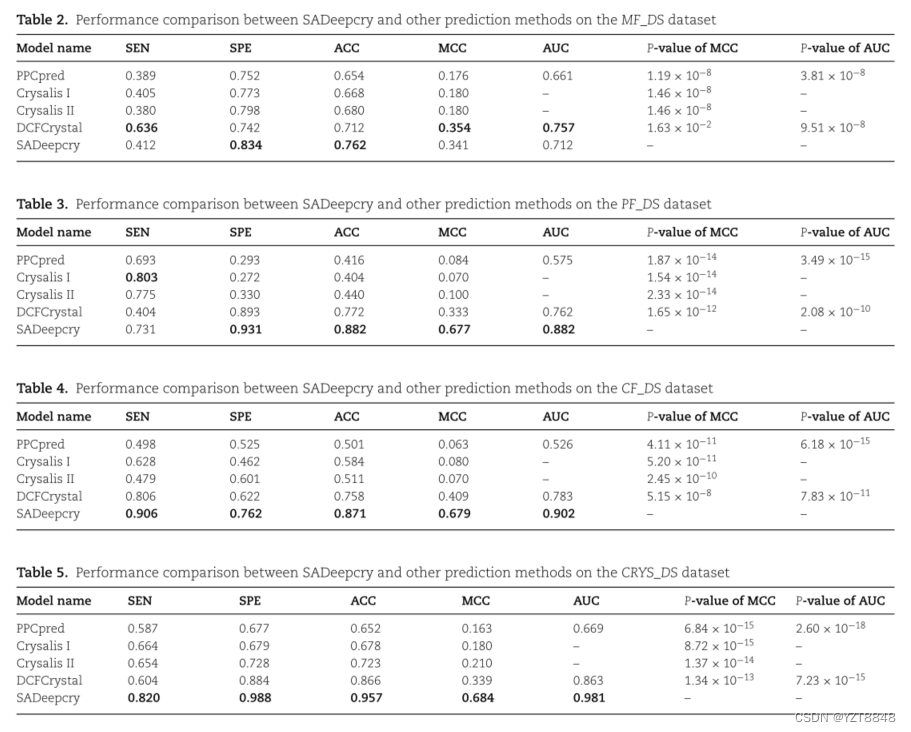
据我们所知,目前只有4个多阶段预测器可用:PPCpred, PredPPCrys, Crysalis和DCFCrystal。由于PPCpred不提供源代码,也不能访问它的web服务器,我们只将我们的模型与其他三个预测器进行比较。SEN、SPE、ACC和MCC的取值由阈值t决定。本文采用网格搜索法确定t的取值,t的搜索网格为[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1]。我们根据训练集选择MCC得分最好的t值。此外,如果有竞争方法的web服务器或源代码,我们将我们的方法和竞争方法运行10次,每次计算对应的MCC和AUC的值,然后使用双尾检验计算我们的方法和竞争方法之间的MCC和AUC的p值。如果竞争方法的web服务器或源不可用,我们只运行我们的方法10次,每次计算对应的MCC和AUC的值,然后用单尾检验计算我们的方法与竞争方法之间的MCC和AUC的p值。SADeepcry与其他方法在MF_DS, PF_DS, CF_DS测试子集中的对比结果见表2-5。利用[19]软件对四种多级分类模型进行了分析。总体而言,SADeepcry框架的预测性能优于其他预测器。以CRYS_DS数据集为例,与第二优方法DCFCrystal相比,SADeepcry对SEN、SPE、ACC、MCC和AUC值的平均增强分别为14.9%、10.3%、10.1%、100.3%和13.4%。
3.2 单级预测结果比较
在这里,我们还将SADeepcry与一些单阶段预测器进行了比较,这些单阶段预测器只预测最终蛋白结晶的成功率。我们将SADeepcry的预测结果与DeepCrystal[32]、BCrystal[15]、XRRpred[33]、ATTCry[34]和DCFCrystal[19]五种最先进的方法进行了比较。由于BCrystal的输入序列长度要求小于800,我们在CRYS_DS数据集中删除原始序列长度超过800的样本,并重新训练和测试SADeepcry。XRRpred可以同时预测给定蛋白质序列的分辨率和R-free。在这里,我们使用Resolution_XRRpred和R-Free_XRRpred分别表示XRRpred的两个任务。特别是,与DeepCrystal和ATTCry两种深度学习方法相比,SADeepcry提取了蛋白质原始氨基酸序列的全局相互作用信息,并引入了几个众所周知的特征,提供了蛋白质的理化、序列和结构特性的信息。如Table 6所示,我们可以发现SADeepcry的性能最好,这表明我们的框架可以作为预测蛋白质结晶预测的有用工具。
3.3 膜蛋白预测结果比较
膜蛋白在各种生物过程中发挥着重要作用。然而,预测膜蛋白的结晶倾向要比预测非膜蛋白复杂得多。为了比较膜蛋白特异性结晶预测模型的性能,我们在MCRYS_DS数据集上比较了SADeepcry与最近开发的6种蛋白结晶倾向预测模型:XRRPred[33]、BCrystal[15]、ATTCry[34]、DeepCrystal[32]、TMCrys[22]和MDCFCrystal[19]。具体来说,TMCrys和MDCFCrystal用于膜蛋白的结晶倾向。如Table7所示,SADeepcry在SEN、ACC、MCC和AUC指标上取得了最佳性能。
3.4 分析各种特征的贡献
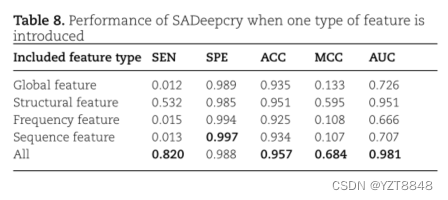
为了构建SADeepcry,我们引入了优化的自注意和声发射模块,从蛋白质中提取原始的氨基酸序列、结构和理化特征。在这里,我们将9139维人工特征分为全局特征、结构特征和频率特征三种类型,并将原始氨基酸序列定义为序列特征。确定每种类型的特性对SADeepcry的贡献是一个有趣的问题。因此,我们重构SADeepcry,将四个考虑的特征分别作为输入,以评估每个特征的相对贡献。从而得到4个SADeepcrys。这些分类器也通过CRYS_DS数据集进行训练和评估,产生5个度量值(Table 8)。具有少数特征的SADeepcry的性能低于具有所有特征的原始SADeepcry,这表明所有特征提供的贡献更少或更多。经过仔细检查,结构特征提供了最大的贡献。其余特性的性能几乎处于同一水平。
4. 消融实验
为了提高模型在蛋白质结晶倾向方面的性能,我们提出的框架引入了两种流行的深度学习架构,自我注意模块和AE模块,分别提取蛋白质的两种类型的特征。为了验证这两种架构的有效性,我们基于CRYS_DS数据集进行了消融实验。Table9对比了SADeepcry及其两种变体在SEN、SPE、ACC、MCC和AUC方面的性能,发现SADeepcry优于其他方法。

5. 自注意力层数对实验的影响
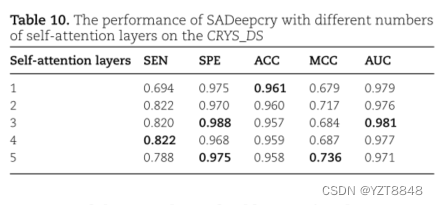
蛋白质的自注意层数是预测蛋白质结晶倾向的一个关键参数。在这里,我们在10倍交叉验证下比较了几个投影维度对SADeepcry性能的影响。Table10 显示了当自我注意层数设置为1、2、3、4和5时,我们的模型所取得的性能。可以发现,随着网络层数的增加,模型的预测性能并没有显著提高。考虑到每个自我注意层需要训练许多可学习参数,但训练集中的样本数量相对较少。堆叠的自注意层可能导致过拟合和梯度消失问题。因此,在SADeepcry中,自我注意层数为3。
6. 独立测试
我们进行了一个独立的测试来评估我们模型的性能。在独立测试中,模型的训练集为CRYS_DS数据集,蛋白质结晶预测性能的测试基于参考文献中的SP最终数据集。在SwissProt (SP)最终数据集中,有148个可结晶蛋白序列和89个非结晶蛋白序列。Table11显示了SADeepcry与其他7个模型的比较结果。我们的模型在ACC、MCC和AUC指标方面优于几个最先进的结晶预测器。

7. 预测蛋白质样品
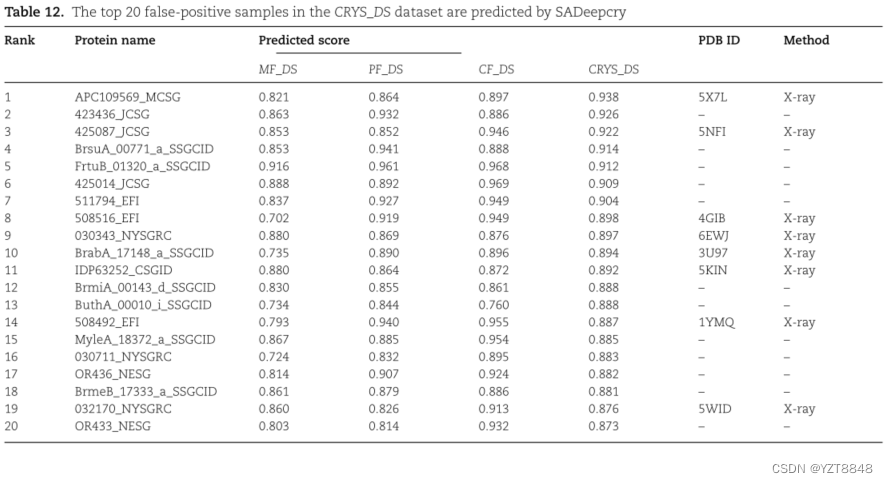
随着技术的进步和时间的推移,越来越多的基于蛋白质晶体的XRD技术发现了蛋白质的三维结构。由于基准数据集中蛋白质数量有限和标签的及时性,一些样本使用我们的框架预测了假阳性。然而,我们发现最新文献和数据库报道的一些假阳性预测是活跃的。为了评估SADeepcry的可靠性,我们对假阳性样本进行了案例分析。我们使用预先训练的SADeepcry来预测CRYS_DS数据集中的测试样本,并根据预测分数对它们进行排名。从分析排名前20位的样品中,我们在最新的PDB数据库中找到了7个蛋白质样品的三维结构(表12),这些蛋白质的三维结构是通过XRD的结晶学分析得到的。此外,我们对前20个假阳性样本的中间过程预测进行了跟踪。具体来说,我们专注于前20个假阳性样本,并分别从MF_DS、PF_DS和CF_DS训练集中删除这些样本。然后,我们使用三个经过处理的训练集对SADeepcry进行训练,并分别输出这20个样本的预测值。由表12可知,该模型在各个中间阶段对同一样本的预测标签是一致的。这一现象表明我们的框架可能是一个识别和发现潜在可结晶蛋白的有效工具。
8. 结论
在本文中,我们提出了一个基于自我注意和AE模块的端到端学习框架SADeepcry。该框架可用于估计蛋白质结晶过程的三个步骤(蛋白质材料生产、纯化和晶体生产)和最终的蛋白质结晶成功率。通过与现有的结晶倾向预测器的比较,证明了SADeepcry的有效性。所提出的预测器性能优越的主要原因是利用设计的高级深度学习模型提取蛋白质的原始序列信息和人工特征,可以有效地学习隐藏在基准数据集中的晶体知识。此外,对CRYS_DS数据集中假阳性预测样本的案例研究也说明了SADeepcry的有效性。虽然SADeepcry取得了良好的预测性能,但仍有改进的空间。首先,一些以前被认为是不可结晶蛋白的蛋白质将被鉴定为可结晶蛋白。数据的缺失和噪声会给蛋白质结晶倾向预测带来负面影响。其次,由于基准数据集中膜蛋白数量较少,SADeepcry无法预测膜蛋白的中间过程。未来,我们将在现有公共数据库的基础上更新和扩展我们的基准数据集,收集更多的膜蛋白数据来完善我们的模型。