【AI理论学习】关于Attention机制的全面理解
关于Attention机制的全面理解
- 人类的视觉注意力
- Encoder-Decoder框架
- 什么是Seq2Seq?
- RNN结构的局限
- Attention机制的引入
- Attention机制的直观理解
- Self-Attention详解
- Self-Attention的矩阵计算
- Multi-Head Attention
- Positional Encoding
- Add & Norm模块
- The Decoder Side
- 最终的线性层和Softmax层
- 训练回顾
- 损失函数
- Attention的N种类型
- 计算区域
- 所用信息
- 结构层次
- 模型方面
- 1)CNN+Attention
- 2)LSTM+Attention
- 3) 纯Attention
- 相似度计算方式
- 源码解读
- Attention任务分析
- 参考资料
注意力模型(Attention Model)被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,是深度学习技术中最值得关注与深入了解的核心技术之一。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
本文以机器翻译为例,深入浅出地介绍了深度学习中注意力机制的原理及关键计算机制,同时也抽象出其本质思想,并介绍了注意力模型在图像及语音等领域的典型应用场景。
人类的视觉注意力

从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
视觉注意力机制是人类从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Encoder-Decoder框架
Encoder-Decoder 模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
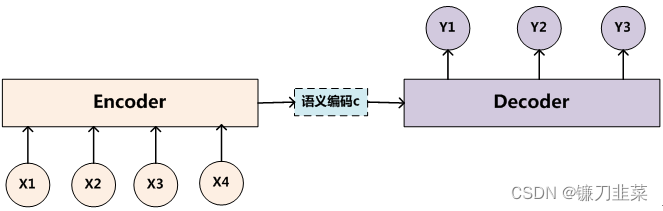
Encoder-Decoder 这个框架很好的诠释了机器学习的核心思路:将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题。
- Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」
- Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
只要是符合上面的框架,都可以统称为 Encoder-Decoder 模型。说到 Encoder-Decoder 模型就经常提到一个名词—— Seq2Seq。
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
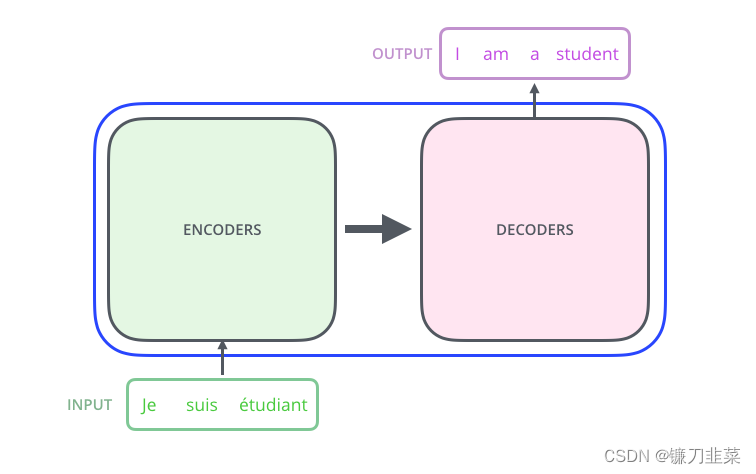
上图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
S
o
u
r
c
e
=
<
x
1
,
x
2
,
.
.
.
,
x
m
>
Source = <x_1, x_2,...,x_m>
Source=<x1,x2,...,xm>
T
a
r
g
e
t
=
<
y
1
,
y
2
,
.
.
.
,
y
n
>
Target = <y_1, y_2,...,y_n>
Target=<y1,y2,...,yn>
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
C
=
F
(
x
1
,
x
2
,
.
.
.
,
x
m
)
C=\mathcal{F}(x_1,x_2,...,x_m)
C=F(x1,x2,...,xm)
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息
y
1
,
y
2
,
.
.
.
,
y
i
−
1
y_1,y_2,...,y_{i-1}
y1,y2,...,yi−1来生成i时刻要生成的单词
y
i
y_i
yi:
y
i
=
G
(
C
,
y
1
,
y
2
,
.
.
.
,
i
−
1
)
y_i=\mathcal{G}(C, y_1,y_2,...,_{i-1})
yi=G(C,y1,y2,...,i−1)
每个
y
i
y_i
yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。
- 如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;
- 如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;
- 如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。
由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
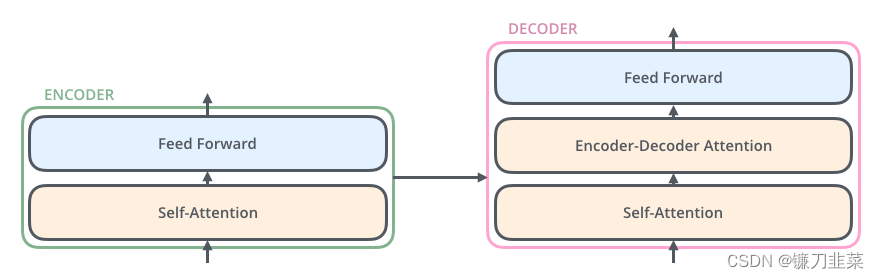
encoding component是一堆编码器(论文中堆叠着六个编码器——数字六没有什么神奇之处,人们肯定可以尝试其他安排)。decoding component是一组相同编号的解码器。
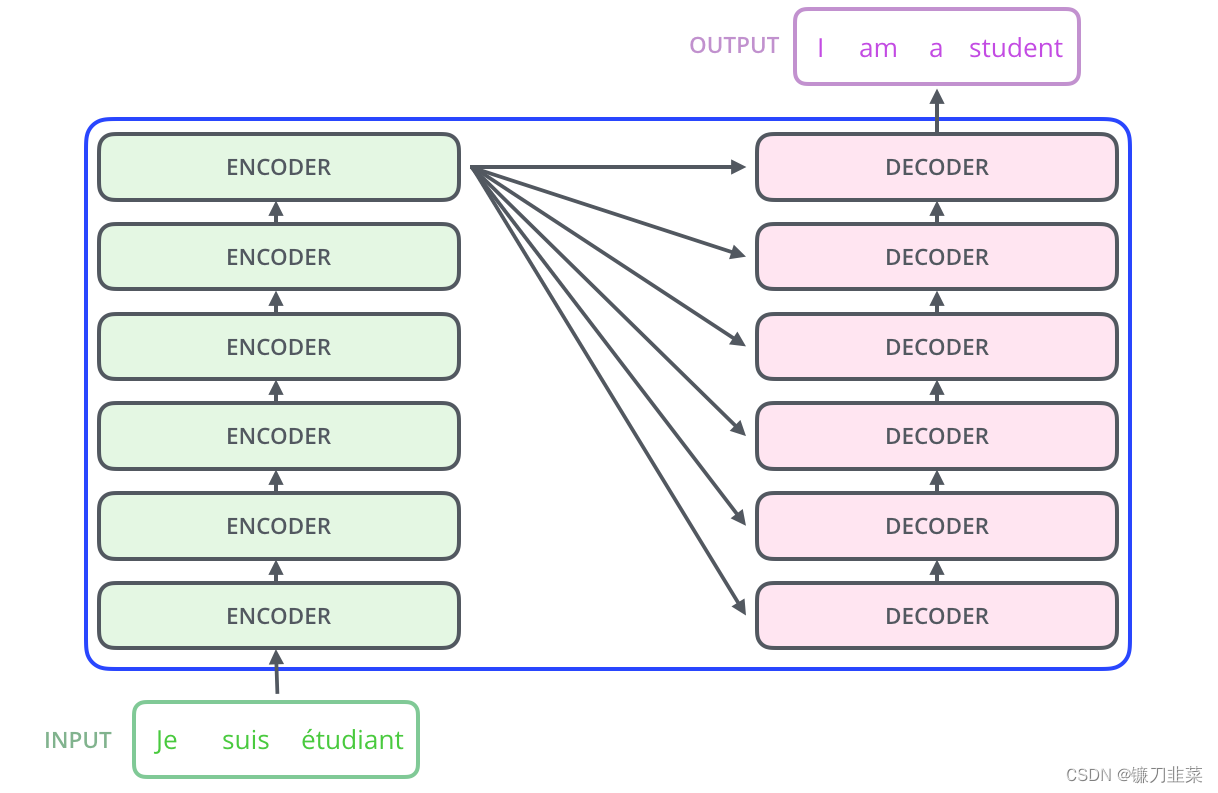
encoders的结构完全相同(但它们不共享权重)。每一层都分为两个子层:
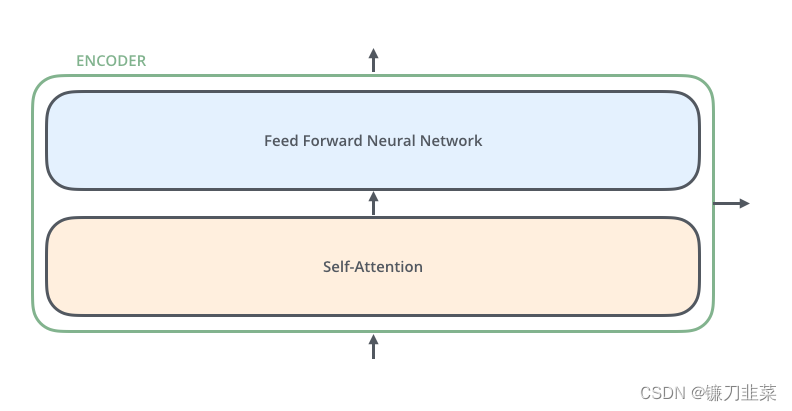
encoder的输入首先通过一个self-attention层——一个帮助编码器在编码特定单词时查看输入句中其他单词的层。我们将在后面的文章中进一步探讨self-attention。
self-attention层的输出反馈给前馈神经网络。完全相同的前馈网络独立应用于每个位置。
decoder有这两个层,但在它们之间有一个attention层,帮助decoder关注输入句子的相关部分(类似于seq2seq模型中的attention )。
现在我们已经了解了模型的主要组成部分,让我们开始看看各种向量/张量,以及它们如何在这些组成部分之间流动,从而将经过训练的模型的输入转化为输出。与NLP应用程序中一样,我们首先使用嵌入算法将每个输入单词转换为向量。

每个单词都embedding到一个大小为512的向量中。我们将用这些简单的框来表示这些向量。
embedding仅发生在bottom-most encoder中。所有encoders 都有一个共同的抽象概念,即它们接收到一个大小为512的vectors列表——在底部编码器中,这是单词嵌入,但在其他编码器中,它是编码器的输出,位于正下方。该列表的大小是我们可以设置的超参数——基本上,这是我们训练数据集中最长句子的长度。
在我们的输入序列中嵌入单词后,每个单词都流经编码器的两层中的每一层。

在这里,我们开始看到Transformer的一个关键属性,即每个位置的单词在编码器中流经自己的路径。在self-attention层中,这些路径之间存在依赖关系。然而,feed-forward层没有这些依赖关系,因此,在流过feed-forward层时,可以并行执行各种路径。
接下来,我们将把示例切换到一个较短的句子,然后看看编码器的每个子层中发生了什么。
正如我们已经提到的,encoder接收vectors列表作为输入。它通过将这些vectors传递到“self-attention”层,然后进入前馈神经网络,然后将输出向上发送到下一个编码器来处理该列表。

每个位置的单词都经过一个self-attention的过程。然后,它们各自通过一个前馈神经网络——完全相同的网络,每个vector分别通过它。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如:
- 对于语音识别来说,上图所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;
- 对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。
一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
什么是Seq2Seq?
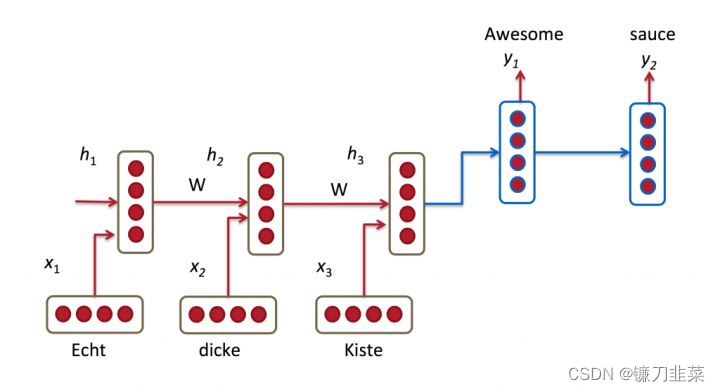
Seq2Seq(是 Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。例如下图:

如上图:输入了 6 个汉字,输出了 3 个英文单词。输入和输出的长度不同。
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。而 Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型(强调方法)的范畴。
总之:
- Seq2Seq 属于 Encoder-Decoder 的大范畴
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
Encoder-Decoder 的缺陷: 当输入信息太长时,会丢失掉一些信息。Attention 机制就是为了解决「信息过长,信息丢失」的问题。Attention 模型的特点是 Eecoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。
下面的动图演示了Attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。

但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。下面的图片则是脱离 Encoder-Decoder 框架后的原理图解:
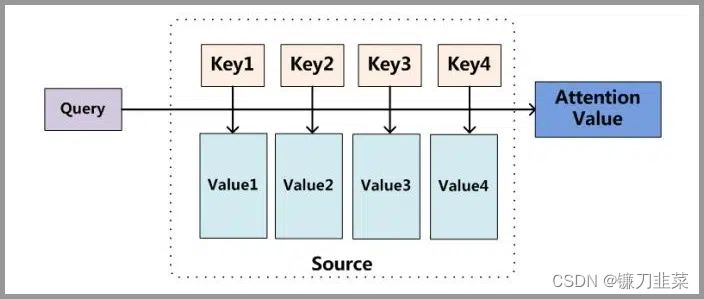
更进一步,我们这里先剧透一下Attention的整体原理图:
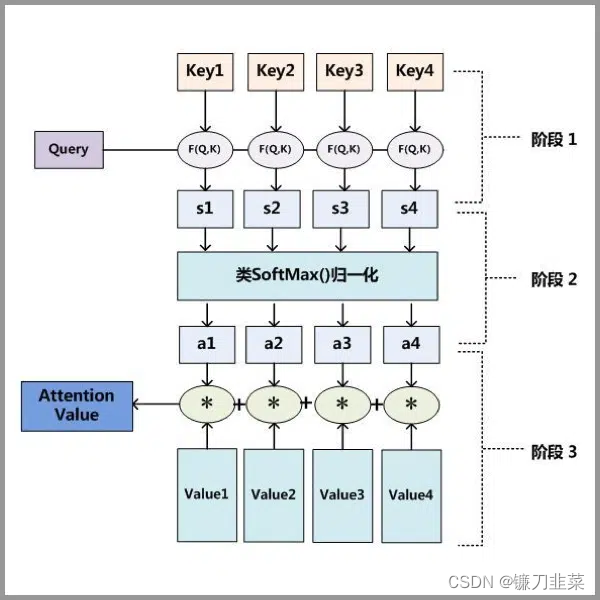
Attention 原理的3步分解:
- 第一步: Query 和 Key 进行相似度计算,得到权值
- 第二步:将权值进行归一化,得到直接可用的权重
- 第三步:将权重和 value 进行加权求和
RNN结构的局限
机器翻译解决的是输入是一串在某种语言中的一句话,输出是目标语言相对应的话的问题,如将德语中的一段话翻译成合适的英语。之前的Neural Machine Translation(简称NMT)模型中,通常的配置是Encoder-Decoder结构,即Encoder读取输入的句子将其转换为定长的一个向量,然后Decoder再将这个向量翻译成对应的目标语言的文字。通常Encoder及Decoder均采用RNN结构,如LSTM或GRU等。
如下图所示,我们利用Encoder RNN将输入语句信息总结到最后一个hidden vector中,并将其作为Decoder初始的hidden vector,利用Decoder解码成对应的其他语言中的文字。
但是这个结构有些问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
Attention机制的引入
为了解决这一由长序列到定长向量转化而造成的信息损失的瓶颈,Attention注意力机制被引入了。Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。
同样的,Attention模型中,当我们翻译当前词语时,我们会寻找源语句中相对应的几个词语,并结合之前的已经翻译的部分作出相应的翻译,如之前的Seq2Seq图所示,当我们翻译“knowledge”时,只需将注意力放在源句中“知识”的部分,当翻译“power”时,只需将注意力集中在"力量“。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。
以上是直观理解,我们来详细的解释一下数学上对应哪些运算。
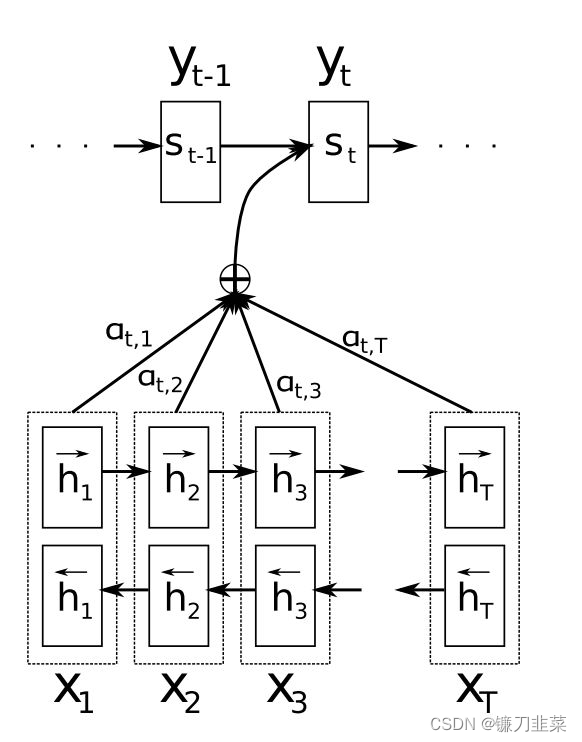
- 首先,我们利用RNN结构得到Encoder中的hidden state( h 1 , h 2 , . . . h T h_1, h_2,...h_T h1,h2,...hT),
- 假设当前Decoder的hidden state是 s t − 1 s_{t-1} st−1,可以计算每一个输入位置 j j j与当前输出位置的关联性 e t j = a ( s t − 1 , h j ) e_{tj}=a(s_{t-1},h_j) etj=a(st−1,hj),写成相应的向量形式即为: e t → = ( a ( s t − 1 , h 1 ) , . . . , a ( s t − 1 , h T ) ) \overrightarrow{e_t}=(a(s_{t-1},h_1),...,a(s_{t-1},h_T)) et=(a(st−1,h1),...,a(st−1,hT)),其中 a a a是一种相关性算法,例如常见的有点乘形式 e t → = s t − 1 → T h → \overrightarrow{e_t}=\overrightarrow{s_{t-1}}^T\overrightarrow{h} et=st−1Th,加权点乘 e t → = s t − 1 → T W h → \overrightarrow{e_t}=\overrightarrow{s_{t-1}}^TW\overrightarrow{h} et=st−1TWh,加和 e t → = v → T t a n h ( W 1 h → + W 2 s t − 1 → ) \overrightarrow{e_t}=\overrightarrow{v}^Ttanh(W_1\overrightarrow{h}+W_2\overrightarrow{s_{t-1}}) et=vTtanh(W1h+W2st−1)等等
- 对于 e t → \overrightarrow{e_t} et进行softmax操作将其normalize得到attention的分布, α t → = s o f t m a x ( e t → ) \overrightarrow{\alpha_t}=softmax(\overrightarrow{e_t}) αt=softmax(et),展开形式为: α t j = e x p ( e t j ) ∑ k = 1 T e x p ( e t k ) \alpha_{tj}=\frac{exp(e_{tj})}{\sum_{k=1}^T exp(e_{tk})} αtj=∑k=1Texp(etk)exp(etj)
- 利用 α t → \overrightarrow{\alpha_t} αt,可以进行加权求和得到相应的context vector c t → = ∑ j = 1 T α t j h j \overrightarrow{c_t}=\sum_{j=1}^T\alpha_{tj}h_j ct=∑j=1Tαtjhj
- 由此,可以计算Decoder的下一个hidden state s t = f ( s t − 1 , y t − 1 , c t ) s_t=f(s_{t-1}, y_{t-1}, c_t) st=f(st−1,yt−1,ct)以及该位置的输出 p ( y t ∣ y 1 , . . . , y t − 1 , x → ) = g ( y i − 1 , s i , c i ) p(y_t|y_1,...,y_{t-1}, \overrightarrow{x})=g(y_{i-1},s_i, c_i) p(yt∣y1,...,yt−1,x)=g(yi−1,si,ci)
这里关键的操作是计算encoder与decoder state之间的关联性的权重,得到Attention分布,从而对于当前输出位置得到比较重要的输入位置的权重,在预测输出时相应的会占较大的比重。
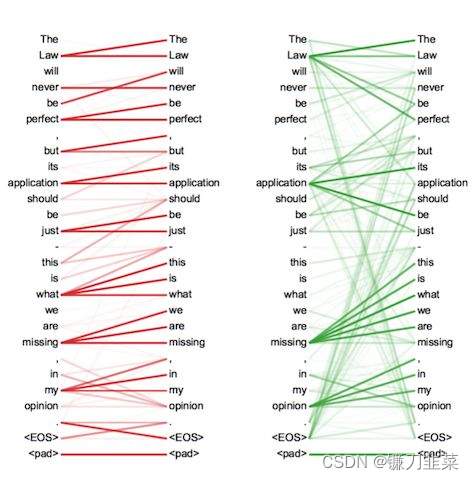
通过Attention机制的引入,我们打破了只能利用Encoder最终单一向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。还有一个优点是,我们通过观察attention 权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,有助于更好的理解模型工作机制,如下图所示:

一个自然的疑问是:Attention机制如此有效,那么可不可以去掉模型中的RNN部分,仅仅利用Attention呢?
Attention机制的直观理解
先来看一个翻译的例子“I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。
Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。
Transformer模型的整体结构如下图所示:
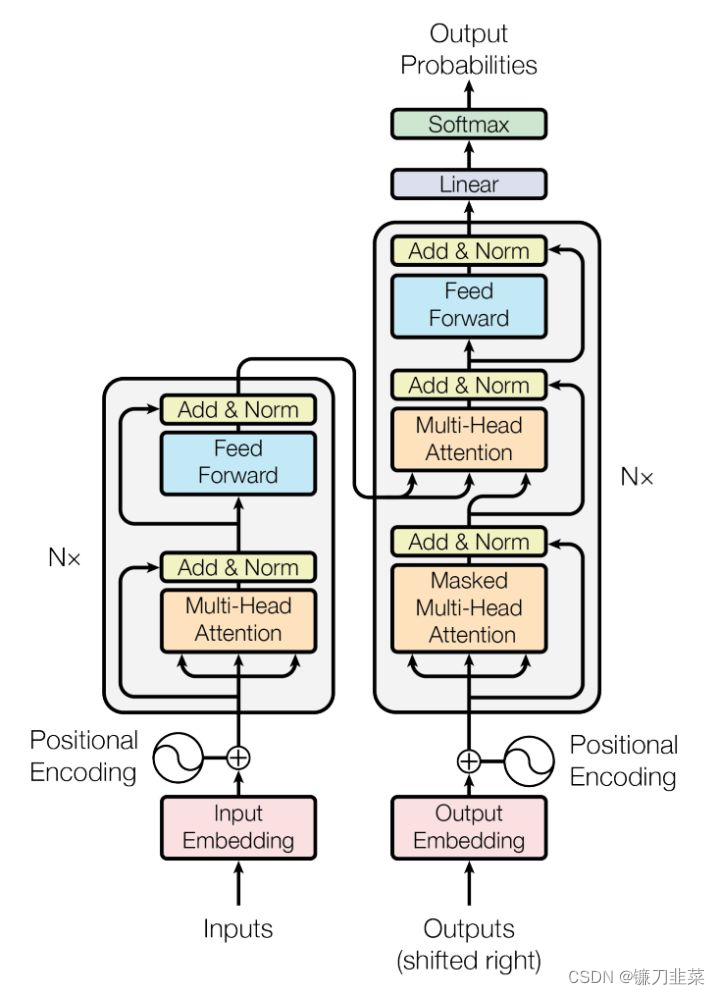
这里面Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,如下图所示,两个head学习到的Attention侧重点可能略有不同,这样给了模型更大的容量。
Self-Attention详解
了解了模型大致原理,就可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
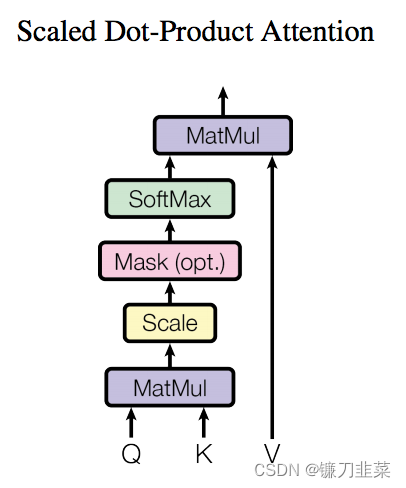
对于Self-Attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入。
首先,我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度
d
k
\sqrt{d_k}
dk,其中
d
k
d_k
dk为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后,再乘以矩阵V,就得到权重求和的表示。该操作可以表示为
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
我们来看一个具体的例子(详见:Jay Alammar的博客)。假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用 x 1 x_1 x1表示,Machines的embedding vector用 x 2 x_2 x2表示。
第一步,从每个encoder的输入向量中创建三个向量(该示例中输入向量是每个单词的嵌入)。因此,对于每个单词,我们创建一个 Query 向量、一个 Key 向量和一个 Value 向量。这些向量是通过将embedding与三个矩阵相乘得到的,这三个矩阵在训练过程中被训练出来。
注意,这些新向量的维数比embedding向量小。它们的维数为64,而embedding和encoder的输入/输出向量的维数为512。它们不一定要更小,这是一个架构选择,以计算多头注意(大部分)常数。

x
1
x_1
x1乘以
W
Q
W^Q
WQ权重矩阵得到
q
1
q_1
q1,query向量和该词相关联,最终为输入句子中的每个单词创建一个query、key、value向量。
What are the “query”, “key”, and “value” vectors?
它们是抽象的,可用于计算和思考注意力。一旦阅读下面的注意力如何计算,您几乎都会知道所有这些向量扮演的角色所需的所有内容。
第二步是计算一个得分。假设我们正在计算此示例中的第一个单词”Thinking“的self-attention,我们需要根据这个单词对输入句子中的每个单词进行评分。分数决定了当我们在某个位置编码一个单词时,对输入句子其他部分的关注程度。也就是说,我们需要计算句子中所有词与它的Attention Score,这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。
我们用
q
1
q_1
q1代表Thinking对应的query vector,
k
1
k_1
k1及
k
2
k_2
k2分别代表Thinking以及Machines对应的key vector,则计算Thinking的Attention score的时候我们需要计算
q
1
q_1
q1与
k
1
,
k
2
k_1,k_2
k1,k2的点乘,同理,我们计算Machines的attention score的时候需要计算
q
2
q_2
q2与
k
1
,
k
2
k_1,k_2
k1,k2的点乘。如下图中所示
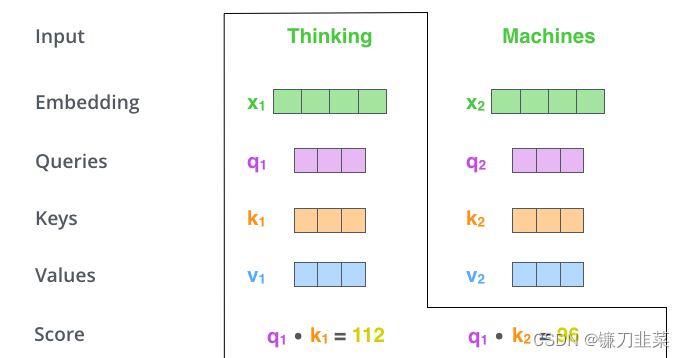
第三步和第四步是将分数除以8(论文中使用的key向量维度的平方根——64)。这导致具有更稳定的梯度。这里可能还有其他可能的值,但这是默认值),然后通过SoftMax操作传递结果。Softmax将分数标准化,使其全部为正值,加起来为1。即我们分别得到了
q
1
q_1
q1与
k
1
,
k
2
k_1,k_2
k1,k2的点乘积,然后我们进行尺度缩放与softmax归一化,如下图所示:
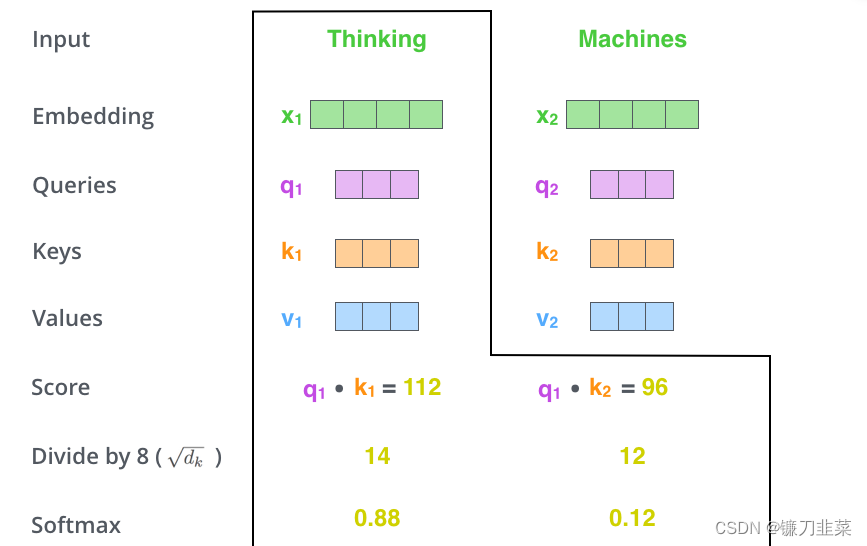
此softmax得分确定每个单词在此位置上会表达多少。显然,该位置的单词将具有最高的SoftMax分数,但是有时候,请注意与当前单词相关的另一个单词。显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。
第五步是将每个value向量乘以SoftMax分数(准备将它们求和)。即用这些Attention score与value vector相乘,得到加权的向量。目的是保持我们要关注的单词的原貌(intact),并掩盖(drown-out)无关的单词(例如,将它们乘以0.001这样的小数字)
第六步是将加权的value向量求和,得到在该位置上的自注意力层的输出(对于第一个单词来说)
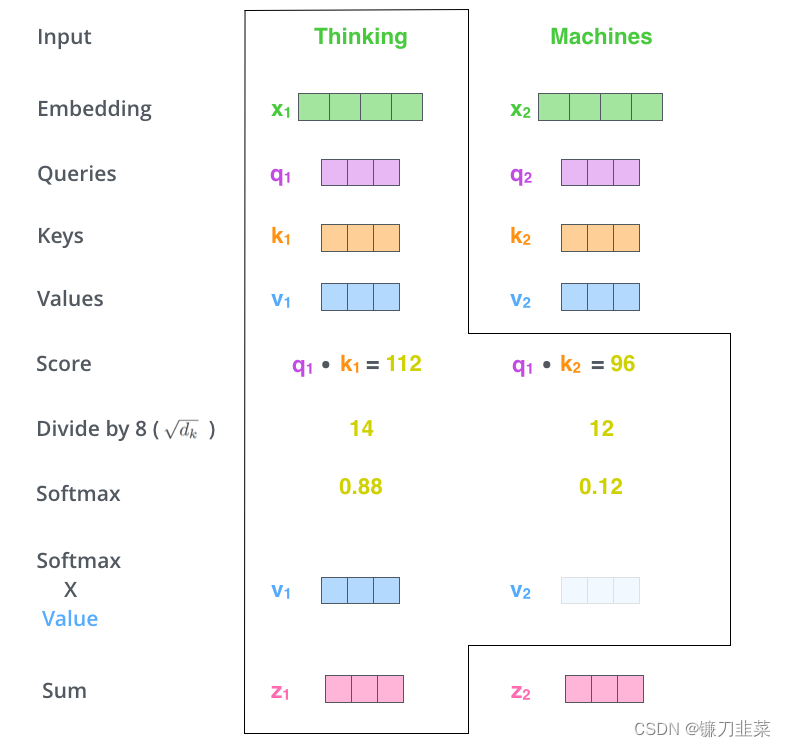
这就是self-attention的计算。最终的向量是我们可以发送到前馈神经网络的矢量。但是,在实际实现中,此计算以矩阵形式完成,以更快地处理。
Self-Attention的矩阵计算
第一步,是计算Query, Key和Value矩阵。如果将输入的所有embedding向量合并为矩阵形式
X
X
X,将其与我们已经训练得到的权重矩阵(
W
Q
,
W
K
,
W
V
W^Q, W^K,W^V
WQ,WK,WV)相乘。
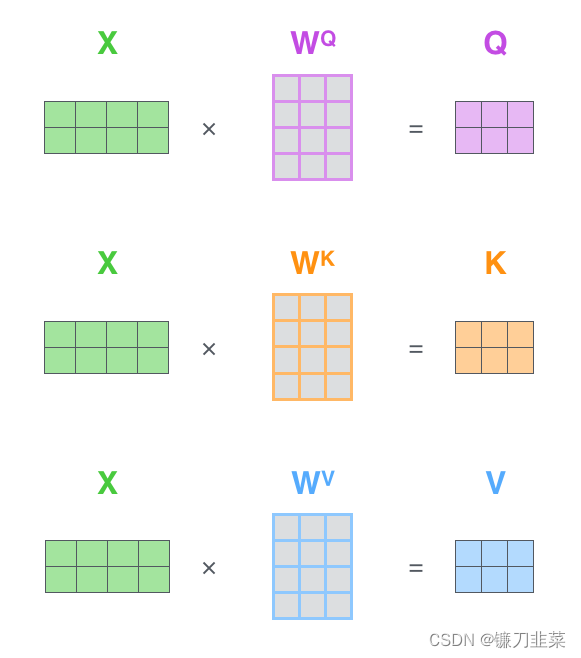
矩阵
X
X
X中的每一行对应输入句子中的一个单词,所有query, key, value向量合并为矩阵形式表示,其中
W
Q
,
W
K
,
W
V
W^Q, W^K,W^V
WQ,WK,WV是我们模型训练过程学习到的合适的参数。我们再次看到embedding向量(512,或者图中的4个框)与q/k/v向量(64,或者图中的3个框)的维度差异。
最后,因为我们处理的是矩阵,因此可以将第二步至第六步浓缩在一个公式中,以计算self-attention layer的输出:
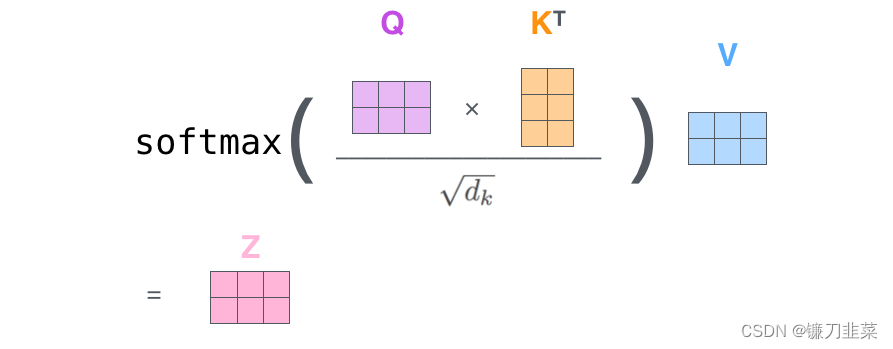
Multi-Head Attention
Multihead就是我们可以有不同的Q,K,V表示,有两个优势:(1)它扩展了模型关注不同位置的能力。(2)它给注意层提供了多个“表示子空间”。最后再将其结果结合起来,如下图所示:
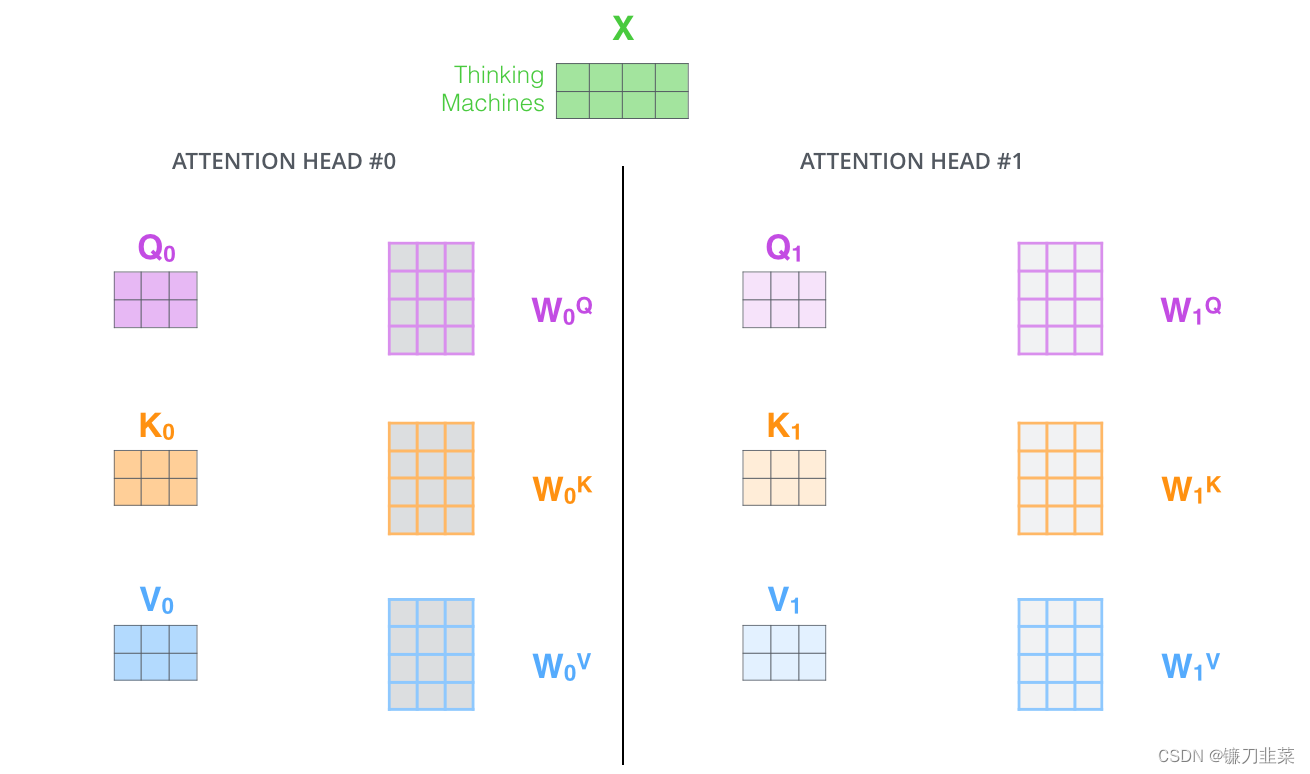
有了multi-headed attention,我们为每个head保持单独的Q/K/V重量矩阵,从而产生不同的Q/K/V矩阵。像以前一样,我们将X乘以WQ/WK/WV矩阵产生Q/K/V矩阵。
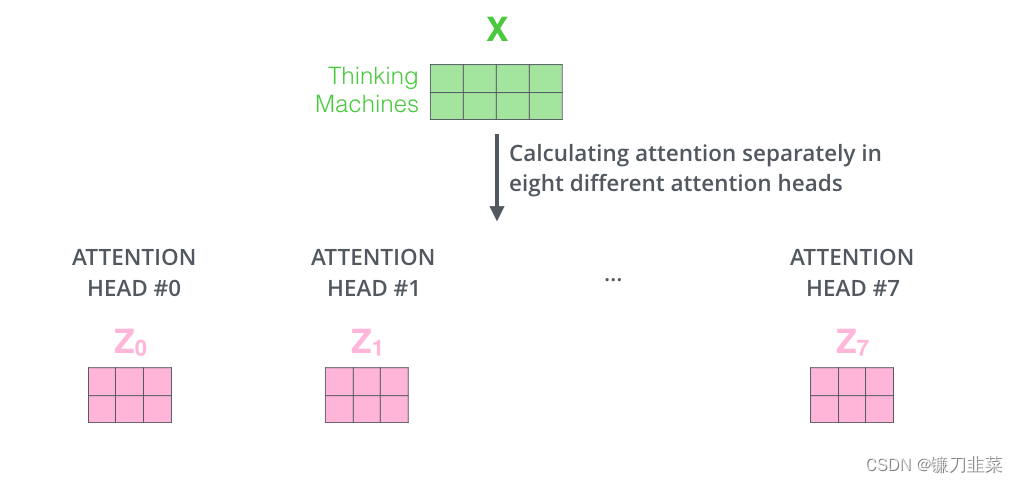
如果我们用上面提到的相同的注意力计算,用不同的权重矩阵只进行八次不同的计算,我们最终得到八个不同的
Z
Z
Z矩阵:
这给我们带来了一些挑战。前馈层没有期望八个矩阵——它期望一个矩阵(每个单词是一个向量)。因此,我们需要一种方法将这八个矩阵整合成一个矩阵。我们连接(concat)这些矩阵,然后将它们乘以额外的一个权重矩阵
W
O
W^O
WO。
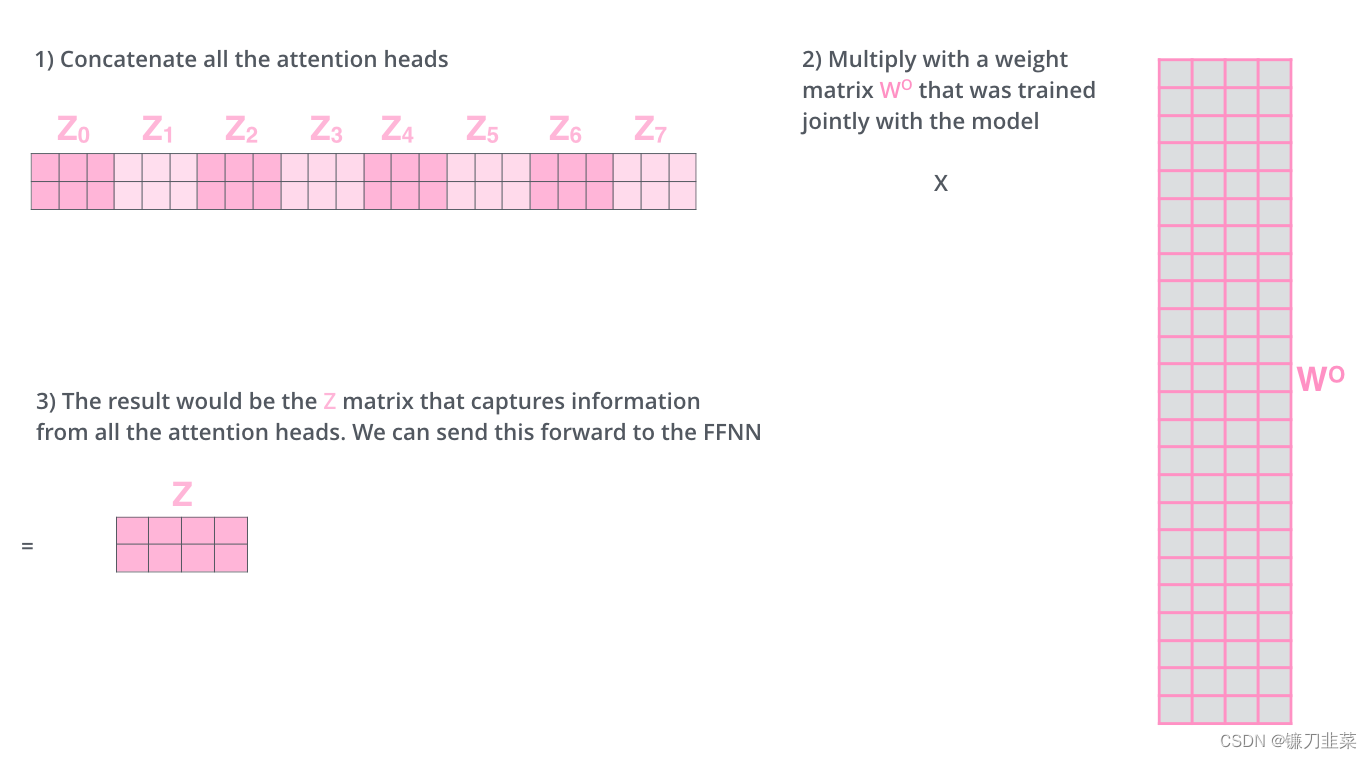
这就是multi-headed self-attention的全部。上面描述了相当多的矩阵。让我们试着把它们放在一个视图中,这样我们可以做一个总览:
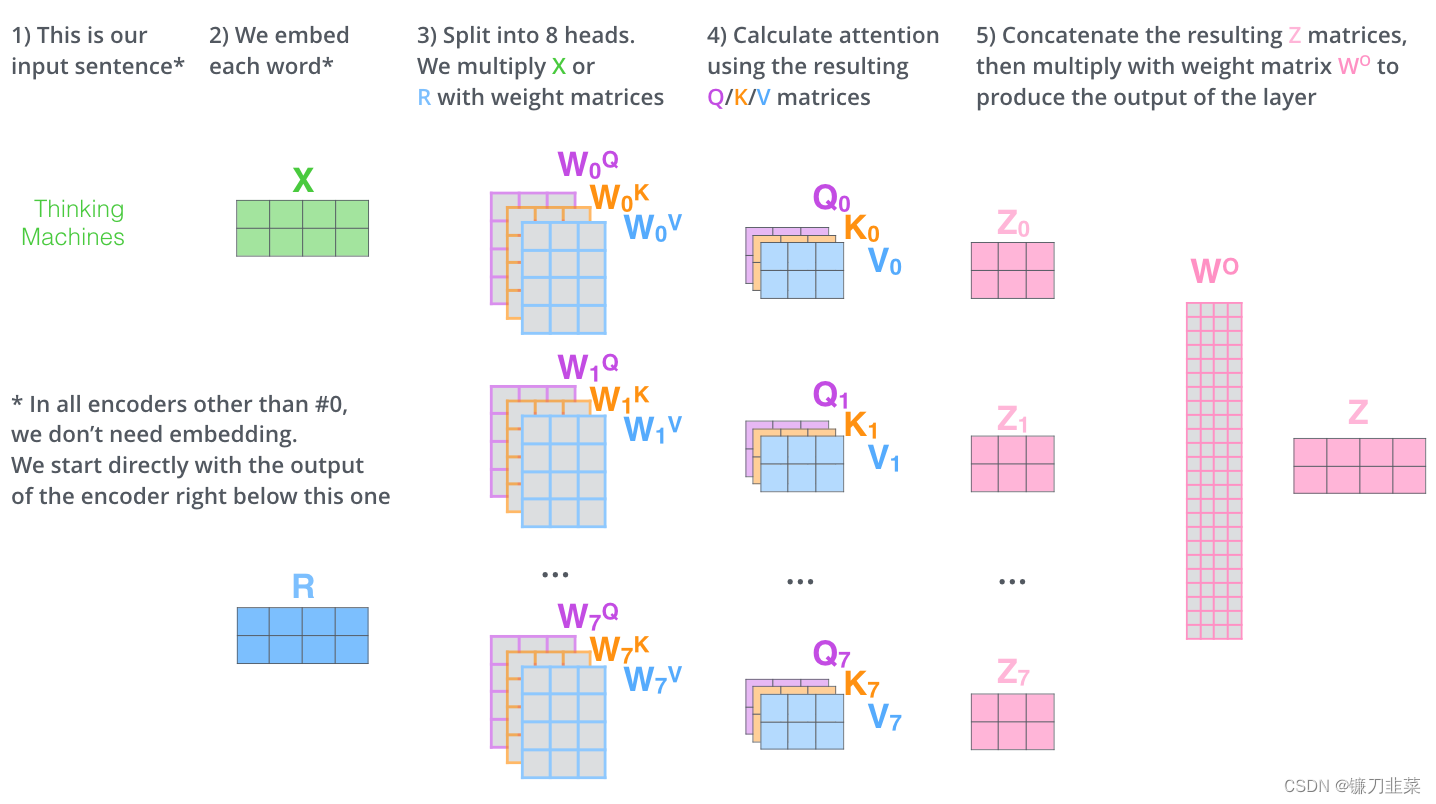
这就是基本的Multihead Attention单元,对于Encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层Encoder的输出,即Encoder的每个位置都可以注意到之前一层Encoder的所有位置。
对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出,下面分别解释一下是什么原理。
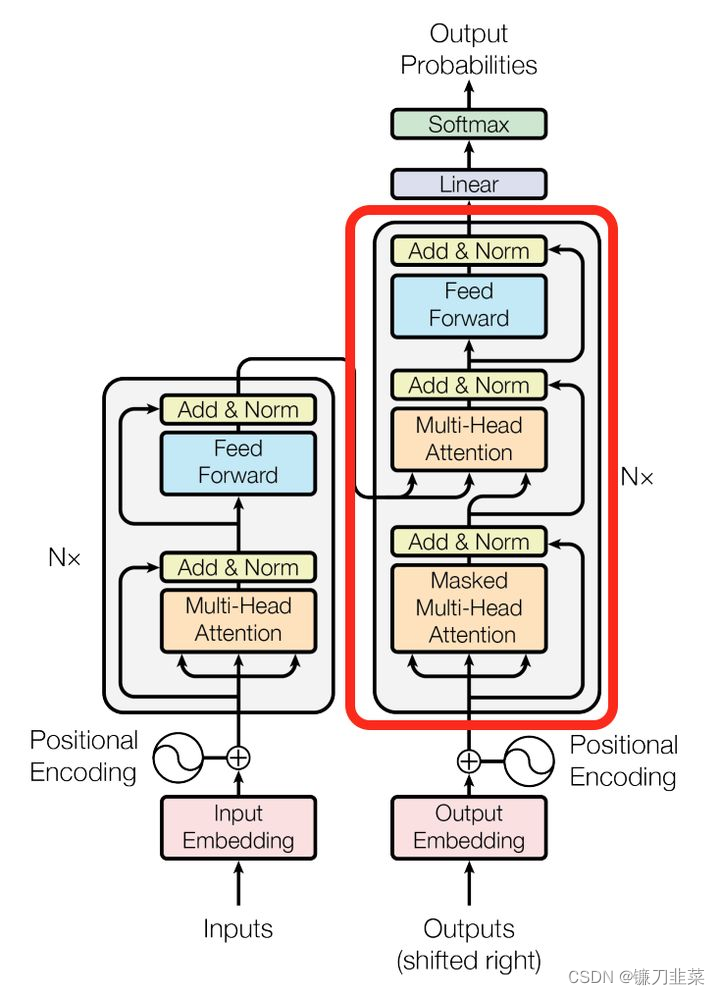
第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
而第二级decoder也被称作encoder-decoder attention layer,即它的query来自于之前一级的decoder层的输出,但其key和value来自于encoder的输出,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。
总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
Positional Encoding
Position Encoding参见另一篇博客:对Transformer中Positional Encoding的理解
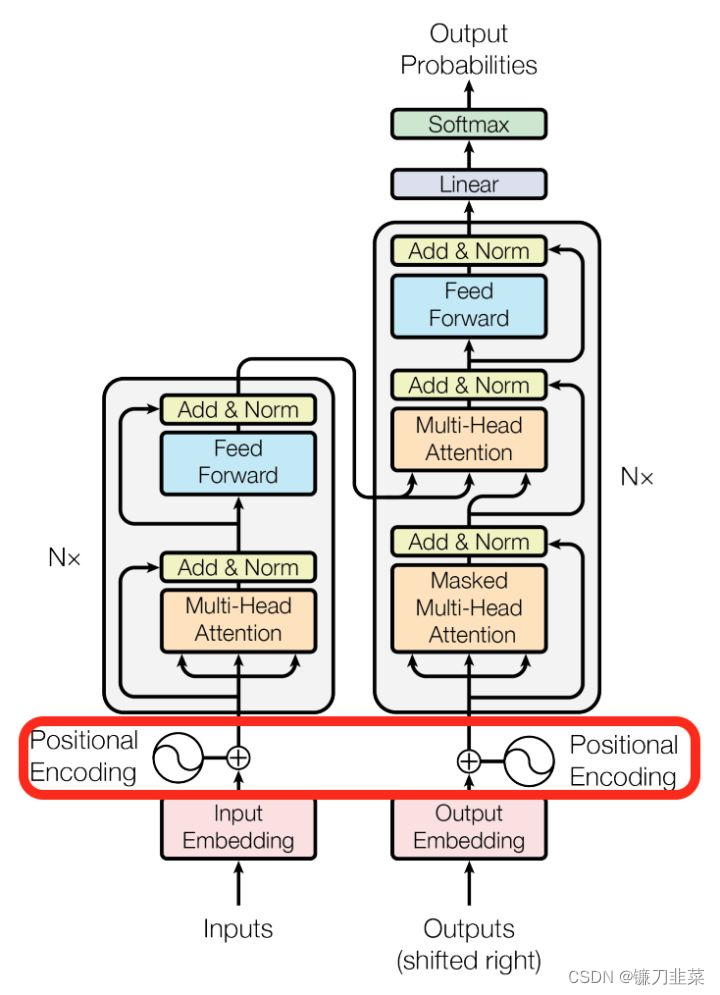
这里做一下补充:使用position encoding的目的是什么?由于该模型没有recurrence或convolution操作,所以没有明确的关于单词在源句子中位置的相对或绝对的信息,为了更好的让模型学习位置信息,所以添加了position encoding并将其叠加在word embedding上。该论文中选取了三角函数的encoding方式,其他方式也可以,该研究组最近还有relation-aware self-attention机制,可参考Self-Attention with Relative Position Representations
Add & Norm模块
在继续之前,我们需要提到encoder架构中的一个细节,即每个encoder中的每个子层(self-attention,ffnn)都有一个围绕它的residual连接,然后是一个layer-normalization步骤。
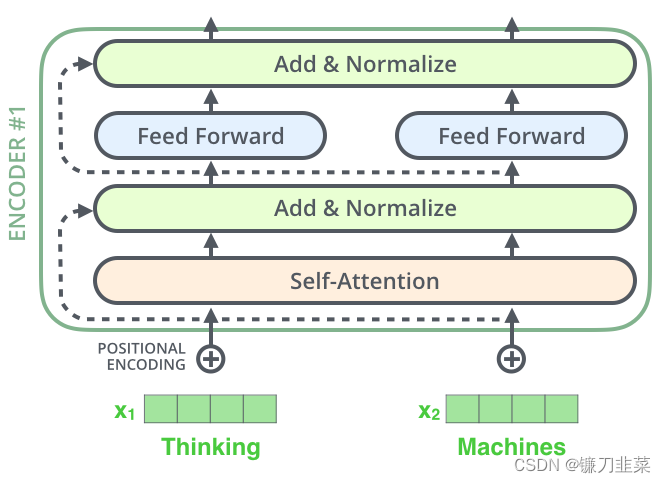
Add代表了Residual Connection,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分,这一方法之前在图像处理结构如ResNet等中常常用到。
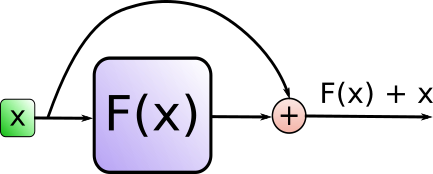
而Norm则代表了Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛,原理可以参考Layer Normalization
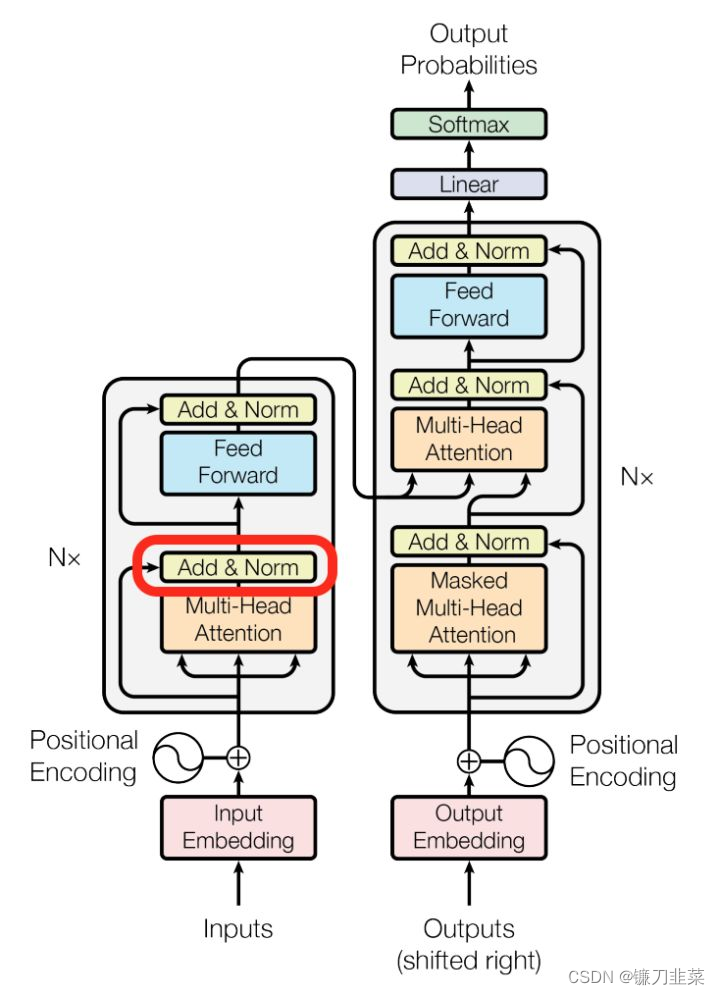
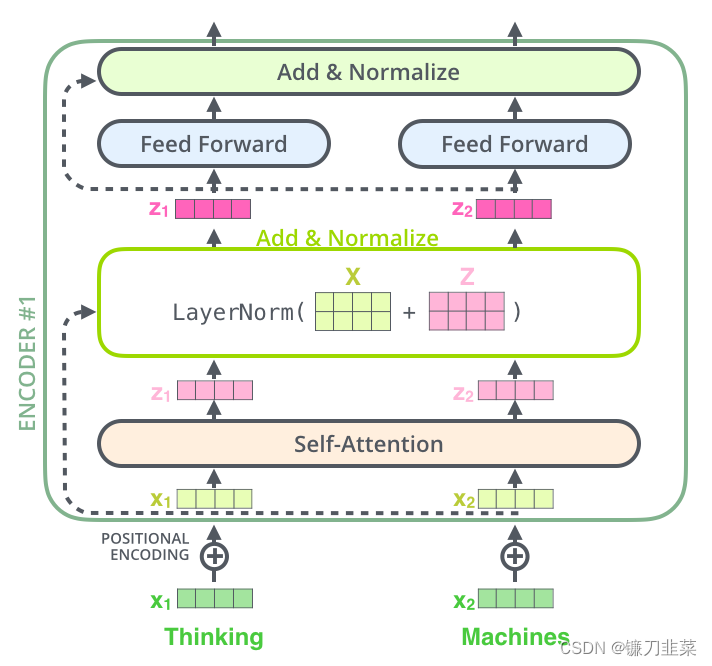
如果我们要可视化与self attention相关的vectors 和layer-norm操作,它应该是这样的:
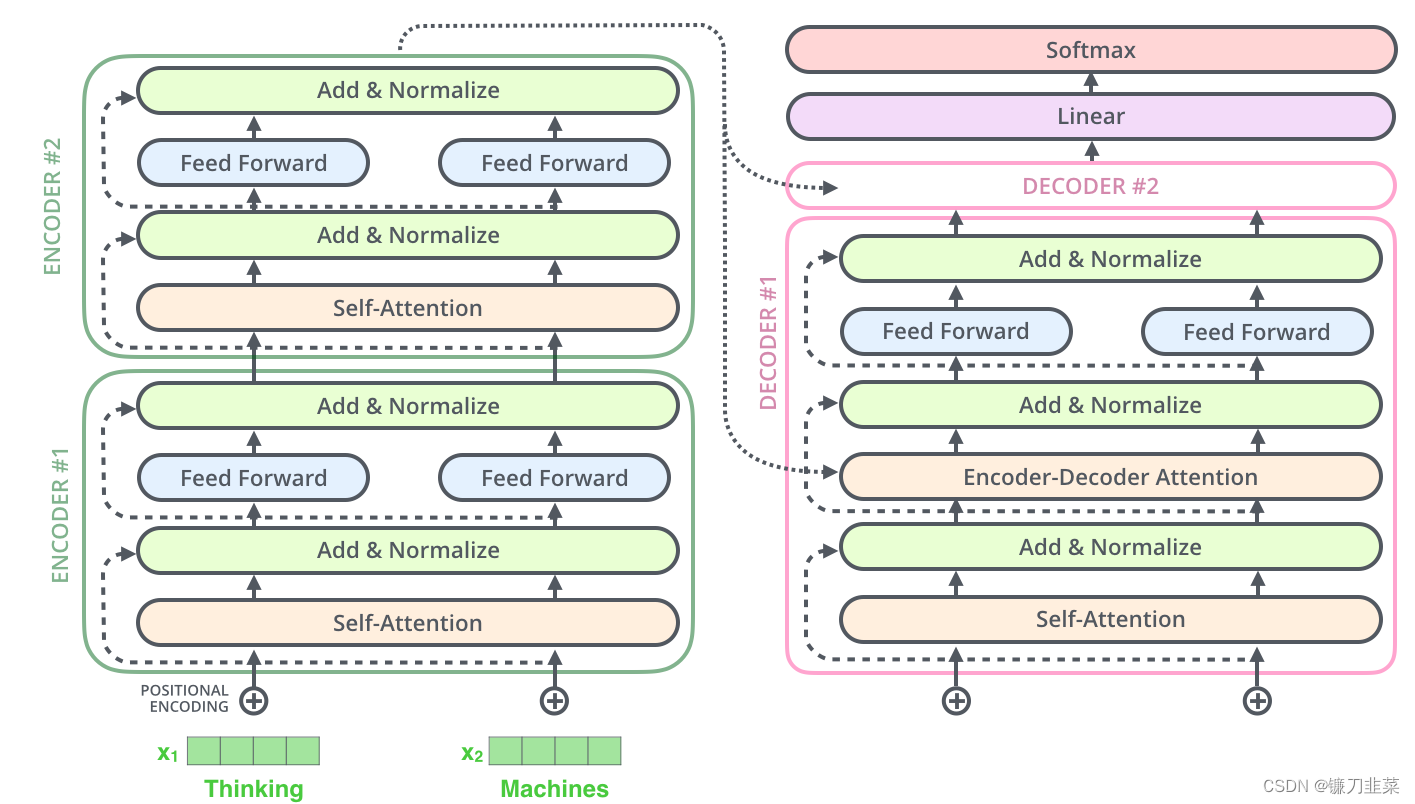
这也适用于decoder的子层。如果我们考虑一个由2个stacked encoders和decoders组成的Transformer,它看起来应该是这样的:
The Decoder Side
既然上文已经涵盖了encoder side的大多数概念,那么我们基本上就知道了decoder的组件的工作方式。这里让我们看一下它们如何一起工作。
encoder从处理输入序列开始。然后,将顶部编码器( top encoder)的输出转换为一组注意力向量(attention vectors)
K
K
K和
V
V
V。每个decoder在其“encoder-decoder attention”层中使用这些信息,这有助于decoder将注意力集中在输入序列中的适当位置:

在完成编码阶段后,我们开始解码阶段。解码阶段的每个步骤都从输出序列中输出一个元素(本例中为英语翻译句子)。
以下步骤重复该过程,直到出现一个特殊符号,表示transformer decoder已完成其输出。在下一个时间步(time step)中,每一步的输出都被馈送到底部解码器(bottom decoder),而decoder像encoder一样冒出了解码结果。就像我们对encoder输入所做的一样,我们在这些decoder输入中嵌入并添加位置编码,以指示每个单词的位置。
 解码器中的self attention layers与编码器中的self attention layers的工作方式略有不同:
解码器中的self attention layers与编码器中的self attention layers的工作方式略有不同:
- 在decoder中,self-attention layer只允许关注输出序列中的earlier positions。这是通过在self-attention计算的softmax步骤之前屏蔽未来位置(将其设置为
-inf)来实现的。 - “Encoder-Decoder Attention”层的工作原理与multiheaded self-attention类似,不同的是,它从下面的层创建Queries matrix,并从encoder stack的输出中获取Keys和Values matrix。
最终的线性层和Softmax层
decoder stack输出浮点向量。我们如何把它变成一个单词?这是最终Linear layer的工作,然后是Softmax层。
The Linear layer是一个简单的全连接神经网络,它将decoder栈产生的向量投影为一个更大的向量,称为logits向量。
假设我们的模型知道10,000个唯一的英语单词(我们的模型的“输出词汇表”) ,这些单词是从它的训练数据集中学到的。这将使logits向量宽10000个单元格,每个单元格对应一个唯一单词的分数。这就是我们如何解释线性层后面的模型输出。
然后,softmax层将这些分数转换为概率(全部为正,总和为1.0)。选择概率最高的单元格,并生成与其关联的单词作为此时间步的输出。
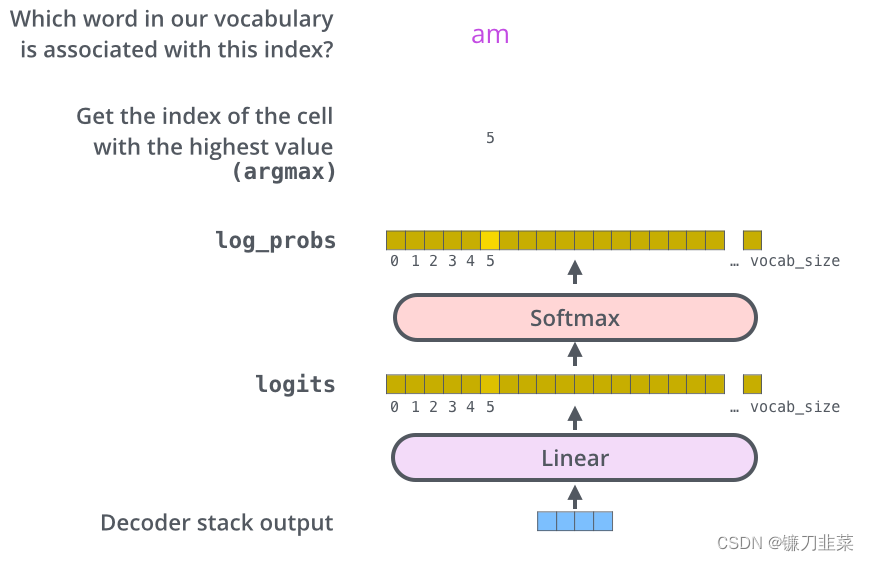
该图从底部开始,将向量作为decoder stack的输出产生。然后将其变成输出单词。
训练回顾
现在,我们已经通过一个训练完备的Transformer涵盖了整个forward-pass process,这对于glance训练模型的intuition将很有用。
在训练期间,未经训练的模型将经历完全相同的前向传递。但由于我们是在一个有标签的训练数据集上训练它,所以我们可以将其输出与实际正确的输出进行比较。
为了看起来方便,我们假设输出词汇表只包含六个单词(“a”、“am”、“i”、“thanks”、“student”和“”(“句末”的缩写))。
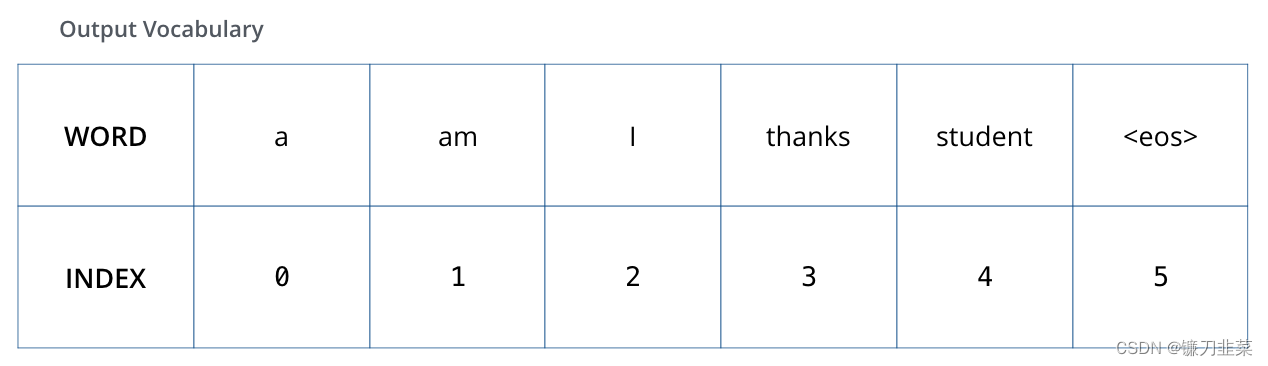
我们的模型的输出词汇是在我们开始训练之前在预处理阶段创建的。
一旦我们定义了输出词汇表,我们就可以使用相同宽度的向量来表示词汇表中的每个单词。这也被称为one-hot编码。例如,我们可以使用下面的向量来表示单词“ am”:

接下来,让我们讨论一下模型的损失函数——我们在训练阶段优化的度量标准,最终得到一个经过训练并且希望非常精确的模型。
损失函数
假设我们正在训练我们的模型。假设这是我们在训练阶段的第一步,我们正在用一个简单的例子进行训练——把“merci”翻译成“thanks”。
这意味着,我们希望输出是表示单词“thanks”的概率分布。但由于该模型尚未经过培训,因此目前还不太可能实现。
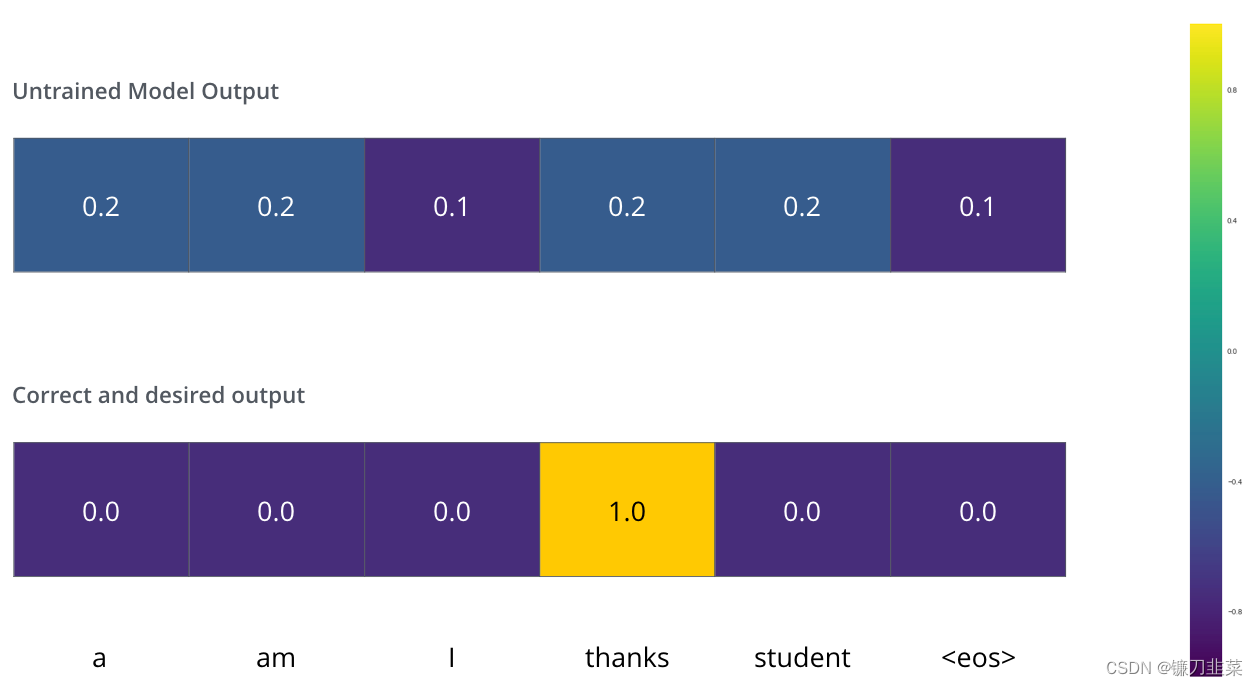
如何比较两种概率分布?我们只需从另一个中减去一个。有关更多详细信息,请查看交叉熵和Kullback-Leibler散度。
但请注意,这是一个过于简单的例子。更现实的是,我们将使用一个比one word长的句子。例如,输入:“je suis étudiant”,预期输出:“i am a student”。这实际上意味着,我们希望我们的模型连续输出概率分布,其中:
- 每个概率分布都由一个宽度为vocab_size的向量表示(在我们的示例中为6,但更实际的是一个类似30000或50000的数字)
- 第一个概率分布在与单词“i”相关的单元格中的概率最高
- 第二个概率分布在与单词“am”相关的单元格中的概率最高
- 依此类推,直到第五个输出分布指示“
<end of sentence>”符号,该符号也有一个与10000个元素词汇表中的单元格关联。
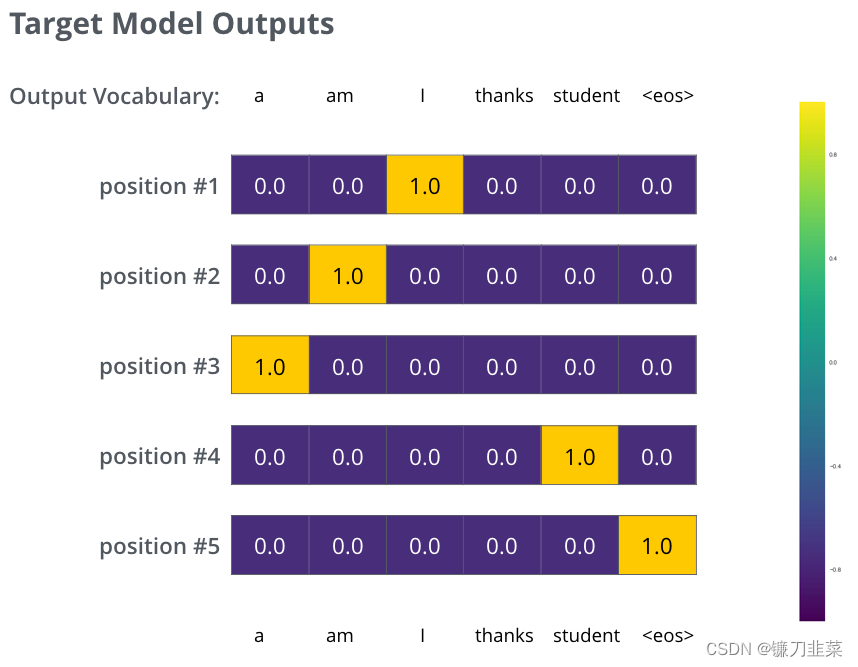
在一个sample句子的训练示例中,我们将针对目标概率分布对模型进行训练。在足够大的数据集上训练模型足够长的时间后,我们希望生成的概率分布如下所示:

现在,因为模型一次产生一个输出,我们可以假设模型从概率分布中选择概率最高的单词,然后丢弃其余的单词。这是一种方法(称为贪婪解码(greedy decoding))。另一种方法是保留前两个单词(比如说,‘ I’和‘ a’) ,然后在下一步中运行模型两次: 一次假设第一个输出位置是单词‘ I’,另一次假设第一个输出位置是单词‘ a’,无论哪个版本保持第一和第二个位置,产生的错误都较少。我们对#2, #3, ……等位置重复此操作。此方法称为“beam search”,在我们的示例中,beam_size为2(意味着在任何时候,内存中都会保存两个部分假设(partial hypotheses)(未完成的翻译),top_beams也为2(表示我们将返回两个翻译)。这些都是可以尝试的超参数。
Attention的N种类型
Attention 有很多种不同的类型:Soft Attention、Hard Attention、静态Attention、动态Attention、Self Attention 等等。下面就跟大家解释一下这些不同的 Attention 都有哪些差别。
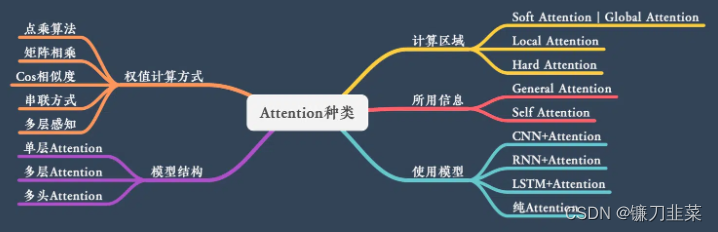
本节从计算区域、所用信息、结构层次和模型等方面对Attention的形式进行归类。
计算区域
根据Attention的计算区域,可以分成以下几种:
1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算attention,这里问题属于原文,文章词向量就属于外部信息。
2)Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
结构层次
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
q
i
,
K
,
V
)
head_i=Attention(q_i, K, V)
headi=Attention(qi,K,V)
最后再把这些结果拼接起来:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MultiHead(Q, K, V)=Concat(head_1,...,head_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
1)CNN+Attention
CNN的卷积操作可以提取重要特征,这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
a. 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
2)LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有:
a. 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
3) 纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
1)点乘:最简单的方法:
s
(
q
,
k
)
=
q
T
k
s(q,k) = q^Tk
s(q,k)=qTk
2)矩阵相乘:
s
(
q
,
k
)
=
q
T
k
s(q,k)=q^Tk
s(q,k)=qTk
3)cos相似度:
s
(
q
,
k
)
=
q
T
k
∣
∣
q
∣
∣
⋅
∣
∣
k
∣
∣
s(q,k)=\frac{q^Tk}{||q||\cdot ||k||}
s(q,k)=∣∣q∣∣⋅∣∣k∣∣qTk
4)串联方式:把q和k拼接起来,
s
(
q
,
k
)
=
W
[
q
;
k
]
s(q,k)=W[q;k]
s(q,k)=W[q;k]
5)用多层感知机也可以:
s
(
q
,
k
)
=
v
a
T
t
a
n
h
(
W
q
+
U
k
)
s(q,k)=v_a^Ttanh(Wq+Uk)
s(q,k)=vaTtanh(Wq+Uk)
源码解读
首先是torch.nn中的MultiheadAttention:
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None, batch_first=False, device=None, dtype=None)
Multi-Head Attention定义为:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MultiHead(Q, K, V)=Concat(head_1, ..., head_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_i=Attention(QW_i^Q, KW_i^K, VW_i^V)
headi=Attention(QWiQ,KWiK,VWiV)
参数列表:
- embed_dim:模型的总维度
- num_heads:并行的attention head数目,注意,每个head的维度是embed_dim//num_heads
- dropout: Dropout概率,默认是0.0
- bias:如果指定,将偏差添加到input/output project层,默认是True
- add_bias_kv: 如果指定,则在dim=0时向key和value序列添加偏移。默认为False
- add_zero_attn: 如果指定,则在dim=1处向key和value序列添加一批新的零。默认为False
- kdim: keys的特征总数,默认为None(使用kdim=embed_dim)
- vdim: values的特征总数,默认为None(使用vdim=embed_dim)
- batch_first: 如果为True, 输入和输出张量作为(batch,seq,feature)提供,默认为False
用法:
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output, attn_output_weights = multihead_attn(query, key, value)
Source:
class MultiheadAttention(Module):
r"""Allows the model to jointly attend to information
from different representation subspaces.
See `Attention Is All You Need <https://arxiv.org/abs/1706.03762>`_.
.. math::
\text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
where :math:`head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)`.
Args:
embed_dim: Total dimension of the model.
num_heads: Number of parallel attention heads. Note that ``embed_dim`` will be split
across ``num_heads`` (i.e. each head will have dimension ``embed_dim // num_heads``).
dropout: Dropout probability on ``attn_output_weights``. Default: ``0.0`` (no dropout).
bias: If specified, adds bias to input / output projection layers. Default: ``True``.
add_bias_kv: If specified, adds bias to the key and value sequences at dim=0. Default: ``False``.
add_zero_attn: If specified, adds a new batch of zeros to the key and value sequences at dim=1.
Default: ``False``.
kdim: Total number of features for keys. Default: ``None`` (uses ``kdim=embed_dim``).
vdim: Total number of features for values. Default: ``None`` (uses ``vdim=embed_dim``).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
Examples::
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
"""
__constants__ = ['batch_first']
bias_k: Optional[torch.Tensor]
bias_v: Optional[torch.Tensor]
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False,
kdim=None, vdim=None, batch_first=False, device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
if self._qkv_same_embed_dim is False:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim), **factory_kwargs))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim), **factory_kwargs))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim), **factory_kwargs))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim), **factory_kwargs))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim, **factory_kwargs))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = NonDynamicallyQuantizableLinear(embed_dim, embed_dim, bias=bias, **factory_kwargs)
if add_bias_kv:
self.bias_k = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
self.bias_v = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
else:
self.bias_k = self.bias_v = None
self.add_zero_attn = add_zero_attn
self._reset_parameters()
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:
xavier_normal_(self.bias_k)
if self.bias_v is not None:
xavier_normal_(self.bias_v)
def __setstate__(self, state):
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
if '_qkv_same_embed_dim' not in state:
state['_qkv_same_embed_dim'] = True
super(MultiheadAttention, self).__setstate__(state)
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None) -> Tuple[Tensor, Optional[Tensor]]:
r"""
Args:
query: Query embeddings of shape :math:`(L, N, E_q)` when ``batch_first=False`` or :math:`(N, L, E_q)`
when ``batch_first=True``, where :math:`L` is the target sequence length, :math:`N` is the batch size,
and :math:`E_q` is the query embedding dimension ``embed_dim``. Queries are compared against
key-value pairs to produce the output. See "Attention Is All You Need" for more details.
key: Key embeddings of shape :math:`(S, N, E_k)` when ``batch_first=False`` or :math:`(N, S, E_k)` when
``batch_first=True``, where :math:`S` is the source sequence length, :math:`N` is the batch size, and
:math:`E_k` is the key embedding dimension ``kdim``. See "Attention Is All You Need" for more details.
value: Value embeddings of shape :math:`(S, N, E_v)` when ``batch_first=False`` or :math:`(N, S, E_v)` when
``batch_first=True``, where :math:`S` is the source sequence length, :math:`N` is the batch size, and
:math:`E_v` is the value embedding dimension ``vdim``. See "Attention Is All You Need" for more details.
key_padding_mask: If specified, a mask of shape :math:`(N, S)` indicating which elements within ``key``
to ignore for the purpose of attention (i.e. treat as "padding"). Binary and byte masks are supported.
For a binary mask, a ``True`` value indicates that the corresponding ``key`` value will be ignored for
the purpose of attention. For a byte mask, a non-zero value indicates that the corresponding ``key``
value will be ignored.
need_weights: If specified, returns ``attn_output_weights`` in addition to ``attn_outputs``.
Default: ``True``.
attn_mask: If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape
:math:`(L, S)` or :math:`(N\cdot\text{num\_heads}, L, S)`, where :math:`N` is the batch size,
:math:`L` is the target sequence length, and :math:`S` is the source sequence length. A 2D mask will be
broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch.
Binary, byte, and float masks are supported. For a binary mask, a ``True`` value indicates that the
corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the
corresponding position is not allowed to attend. For a float mask, the mask values will be added to
the attention weight.
Outputs:
- **attn_output** - Attention outputs of shape :math:`(L, N, E)` when ``batch_first=False`` or
:math:`(N, L, E)` when ``batch_first=True``, where :math:`L` is the target sequence length, :math:`N` is
the batch size, and :math:`E` is the embedding dimension ``embed_dim``.
- **attn_output_weights** - Attention output weights of shape :math:`(N, L, S)`, where :math:`N` is the batch
size, :math:`L` is the target sequence length, and :math:`S` is the source sequence length. Only returned
when ``need_weights=True``.
"""
if self.batch_first:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
if not self._qkv_same_embed_dim:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
if self.batch_first:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
重点关注multi_head_attention_forward()函数,该函数用来计算q,k,v矩阵,其定义为:
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
embed_dim_to_check: int,
num_heads: int,
in_proj_weight: Tensor,
in_proj_bias: Optional[Tensor],
bias_k: Optional[Tensor],
bias_v: Optional[Tensor],
add_zero_attn: bool,
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_separate_proj_weight: bool = False,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
static_k: Optional[Tensor] = None,
static_v: Optional[Tensor] = None,
) -> Tuple[Tensor, Optional[Tensor]]:
r"""
Args:
query, key, value: map a query and a set of key-value pairs to an output.
See "Attention Is All You Need" for more details.
embed_dim_to_check: total dimension of the model.
num_heads: parallel attention heads.
in_proj_weight, in_proj_bias: input projection weight and bias.
bias_k, bias_v: bias of the key and value sequences to be added at dim=0.
add_zero_attn: add a new batch of zeros to the key and
value sequences at dim=1.
dropout_p: probability of an element to be zeroed.
out_proj_weight, out_proj_bias: the output projection weight and bias.
training: apply dropout if is ``True``.
key_padding_mask: if provided, specified padding elements in the key will
be ignored by the attention. This is an binary mask. When the value is True,
the corresponding value on the attention layer will be filled with -inf.
need_weights: output attn_output_weights.
attn_mask: 2D or 3D mask that prevents attention to certain positions. A 2D mask will be broadcasted for all
the batches while a 3D mask allows to specify a different mask for the entries of each batch.
use_separate_proj_weight: the function accept the proj. weights for query, key,
and value in different forms. If false, in_proj_weight will be used, which is
a combination of q_proj_weight, k_proj_weight, v_proj_weight.
q_proj_weight, k_proj_weight, v_proj_weight, in_proj_bias: input projection weight and bias.
static_k, static_v: static key and value used for attention operators.
Shape:
Inputs:
- query: :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
the embedding dimension.
- key: :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- value: :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- key_padding_mask: :math:`(N, S)` where N is the batch size, S is the source sequence length.
If a ByteTensor is provided, the non-zero positions will be ignored while the zero positions
will be unchanged. If a BoolTensor is provided, the positions with the
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
- attn_mask: 2D mask :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
3D mask :math:`(N*num_heads, L, S)` where N is the batch size, L is the target sequence length,
S is the source sequence length. attn_mask ensures that position i is allowed to attend the unmasked
positions. If a ByteTensor is provided, the non-zero positions are not allowed to attend
while the zero positions will be unchanged. If a BoolTensor is provided, positions with ``True``
are not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
is provided, it will be added to the attention weight.
- static_k: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
- static_v: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
Outputs:
- attn_output: :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
E is the embedding dimension.
- attn_output_weights: :math:`(N, L, S)` where N is the batch size,
L is the target sequence length, S is the source sequence length.
"""
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v, out_proj_weight, out_proj_bias)
if has_torch_function(tens_ops):
return handle_torch_function(
multi_head_attention_forward,
tens_ops,
query,
key,
value,
embed_dim_to_check,
num_heads,
in_proj_weight,
in_proj_bias,
bias_k,
bias_v,
add_zero_attn,
dropout_p,
out_proj_weight,
out_proj_bias,
training=training,
key_padding_mask=key_padding_mask,
need_weights=need_weights,
attn_mask=attn_mask,
use_separate_proj_weight=use_separate_proj_weight,
q_proj_weight=q_proj_weight,
k_proj_weight=k_proj_weight,
v_proj_weight=v_proj_weight,
static_k=static_k,
static_v=static_v,
)
# set up shape vars
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
assert embed_dim == embed_dim_to_check, \
f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
if isinstance(embed_dim, torch.Tensor):
# embed_dim can be a tensor when JIT tracing
head_dim = embed_dim.div(num_heads, rounding_mode='trunc')
else:
head_dim = embed_dim // num_heads
assert head_dim * num_heads == embed_dim, f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
if use_separate_proj_weight:
# allow MHA to have different embedding dimensions when separate projection weights are used
assert key.shape[:2] == value.shape[:2], \
f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
else:
assert key.shape == value.shape, f"key shape {key.shape} does not match value shape {value.shape}"
#
# compute in-projection
#
if not use_separate_proj_weight:
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
else:
assert q_proj_weight is not None, "use_separate_proj_weight is True but q_proj_weight is None"
assert k_proj_weight is not None, "use_separate_proj_weight is True but k_proj_weight is None"
assert v_proj_weight is not None, "use_separate_proj_weight is True but v_proj_weight is None"
if in_proj_bias is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = in_proj_bias.chunk(3)
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)
# prep attention mask
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
# ensure attn_mask's dim is 3
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
# prep key padding mask
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
# add bias along batch dimension (currently second)
if bias_k is not None and bias_v is not None:
assert static_k is None, "bias cannot be added to static key."
assert static_v is None, "bias cannot be added to static value."
k = torch.cat([k, bias_k.repeat(1, bsz, 1)])
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
if attn_mask is not None:
attn_mask = pad(attn_mask, (0, 1))
if key_padding_mask is not None:
key_padding_mask = pad(key_padding_mask, (0, 1))
else:
assert bias_k is None
assert bias_v is None
#
# reshape q, k, v for multihead attention and make em batch first
#
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
if static_k is None:
k = k.contiguous().view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
else:
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
assert static_k.size(0) == bsz * num_heads, \
f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
assert static_k.size(2) == head_dim, \
f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
k = static_k
if static_v is None:
v = v.contiguous().view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
else:
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
assert static_v.size(0) == bsz * num_heads, \
f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
assert static_v.size(2) == head_dim, \
f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
v = static_v
# add zero attention along batch dimension (now first)
if add_zero_attn:
zero_attn_shape = (bsz * num_heads, 1, head_dim)
k = torch.cat([k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1)
v = torch.cat([v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1)
if attn_mask is not None:
attn_mask = pad(attn_mask, (0, 1))
if key_padding_mask is not None:
key_padding_mask = pad(key_padding_mask, (0, 1))
# update source sequence length after adjustments
src_len = k.size(1)
# merge key padding and attention masks
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# convert mask to float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
# adjust dropout probability
if not training:
dropout_p = 0.0
#
# (deep breath) calculate attention and out projection
#
attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
if need_weights:
# average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
return attn_output, attn_output_weights.sum(dim=1) / num_heads
else:
return attn_output, None
其中的_scaled_dot_product_attention定义为:
def _scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
r"""
Computes scaled dot product attention on query, key and value tensors, using
an optional attention mask if passed, and applying dropout if a probability
greater than 0.0 is specified.
Returns a tensor pair containing attended values and attention weights.
Args:
q, k, v: query, key and value tensors. See Shape section for shape details.
attn_mask: optional tensor containing mask values to be added to calculated
attention. May be 2D or 3D; see Shape section for details.
dropout_p: dropout probability. If greater than 0.0, dropout is applied.
Shape:
- q: :math:`(B, Nt, E)` where B is batch size, Nt is the target sequence length,
and E is embedding dimension.
- key: :math:`(B, Ns, E)` where B is batch size, Ns is the source sequence length,
and E is embedding dimension.
- value: :math:`(B, Ns, E)` where B is batch size, Ns is the source sequence length,
and E is embedding dimension.
- attn_mask: either a 3D tensor of shape :math:`(B, Nt, Ns)` or a 2D tensor of
shape :math:`(Nt, Ns)`.
- Output: attention values have shape :math:`(B, Nt, E)`; attention weights
have shape :math:`(B, Nt, Ns)`
"""
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2, -1))
if attn_mask is not None:
attn += attn_mask
attn = softmax(attn, dim=-1)
if dropout_p > 0.0:
attn = dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output, attn
Attention任务分析
Attention机制只是一种思想,可以用到很多任务上,比较适合Attention机制的是有以下特点的任务:
长文本任务,document级别,因为长文本本身所携带的信息量比较大,可能会带来信息过载问题,很多任务可能只需要用到其中一些关键信息(比如文本分类),所以Attention机制用在这里正适合capture这些关键信息。- 涉及到两段的相关文本,可能会需要对两段
内容进行对齐,找到这两段文本之间的一些相关关系。比如机器翻译,将英文翻译成中文,英文和中文明显是有对齐关系的,Attention机制可以找出,在翻译到某个中文字的时候,需要对齐到哪个英文单词。又比如阅读理解,给出问题和文章,其实问题中也可以对齐到文章相关的描述,比如“什么时候”可以对齐到文章中相关的时间部分。 - 任务很大部分取决于某些特征。举个例子,比如在AI+法律领域,根据初步判决文书来预测所触犯的法律条款,在文书中可能会有一些罪名判定,而这种特征对任务是非常重要的,所以用Attention来capture到这种特征就比较有用。(CNN也可以)
下面列举一些常见的Task,其中机器翻译、摘要生成、图文互搜属于seq2seq任务,需要对两段内容进行对齐,文本蕴含用到前提和假设两段文本,阅读理解也用到了文章和问题两段文本,文本分类、序列标注和关系抽取属于单文本Attention的做法。
- 机器翻译:encoder用于对原文建模,decoder用于生成译文,attention用于连接原文和译文,在每一步翻译的时候关注不同的原文信息。
- 摘要生成:encoder用于对原文建模,decoder用于生成新文本,从形式上和机器翻译都是seq2seq任务,但是从任务特点上看,机器翻译可以具体对齐到某几个词,但这里是由长文本生成短文本,decoder可能需要capture到encoder更多的内容,进行总结。
- 图文互搜:encoder对图片建模,decoder生成相关文本,在decoder生成每个词的时候,用attention机制来关注图片的不同部分。
- 文本蕴含:判断前提和假设是否相关,attention机制用来对前提和假设进行对齐。
- 阅读理解:可以对文本进行self attention,也可以对文章和问题进行对齐。
- 文本分类:一般是对一段句子进行attention,得到一个句向量去做分类。
- 序列标注:Deep Semantic Role Labeling with Self-Attention,这篇论文在softmax前用到了self attention,学习句子结构信息,和利用到标签依赖关系的CRF进行pk。
- 关系抽取:也可以用到self attention
参考资料
[1] https://blog.csdn.net/tg229dvt5i93mxaq5a6u/article/details/78422216
[2] https://zhuanlan.zhihu.com/p/47063917
[3] https://easyai.tech/ai-definition/attention/
[4] https://theaisummer.com/attention/
[5] https://jalammar.github.io/illustrated-transformer/
[6] Attention Is All You Need
[7] Attention用于NLP的一些小结