【AI实践案例】基于Encoder-Decoder模型的Word Level英语到Marathi神经机器翻译
基于Encoder-Decoder模型的Word Level英语到Marathi神经机器翻译
- 基于Encoder-Decoder模型的Word层级English到Marathi神经机器翻译
- 1.引言
- 2.先决条件
- 3.编码器-解码器架构
- 4.Encoder LSTM
- 5.Decoder LSTM——训练模式
- 6.Decoder LSTM——推断模式
- 7.代码演练
- 数据集
- 推理设置:
- 8.结果和评估
- 在训练数据集上的结果
- 在测试数据集上的效果
- 测试结论
- 9.未来的工作
- 10.注意事项
- 11.遇到的问题
- 12.参考资料
基于Encoder-Decoder模型的Word层级English到Marathi神经机器翻译
1.引言
Recurrent Neural Network(或更准确地说,LSTM/GRU)已被发现在解决给定大量数据的复杂序列相关问题时非常有效。它们在语音识别、自然语言处理(NLP)问题、时间序列预测等方面有实时应用。这个博客很好地解释了其中的一些应用。
Sequence-to-Sequence(通常缩写为seq2seq)模型是一类特殊的递归神经网络架构,通常用于(但不限于)解决复杂的语言相关问题,如机器翻译、问答、创建聊天机器人、文本摘要等。
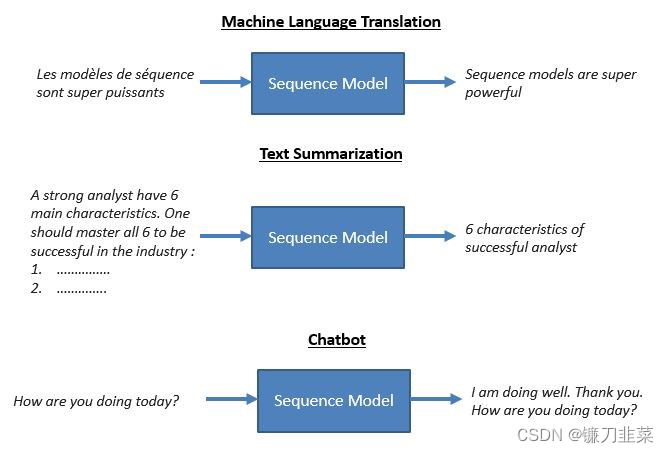
这篇博客文章的目的是详细解释序列到序列模型是如何构建的,并直观地理解它们是如何解决这些复杂任务的。
我们将以机器翻译问题(将文本从一种语言翻译成另一种语言,在我们的例子中是从英语翻译成马拉地语)作为本博客的运行示例。然而,技术细节通常适用于任何顺序到顺序的问题。
因为我们使用神经网络来执行机器翻译,所以通常称之为神经机器翻译(NMT)。
2.先决条件
这篇文章假设你:
- 了解机器学习和神经网络的基本概念
- 了解高中线性代数和概率
- 具备Python和Keras中LSTM网络的工作知识
The Unreasonable Effectiveness of Recurrent Neural Networks(解释了RNN如何用于构建语言模型)和 Understanding LSTM Networks(解释了LSTM的工作)是两个精彩的博客,如果你还没有度过,强烈建议你去看看。这些博客中解释的概念在本文中被广泛使用。
3.编码器-解码器架构
用于构建Seq2Seq模型的最常见架构是Encoder-Decoder架构。这是本文中案例要使用的架构。下面是这个架构的一个非常抽象的视图:
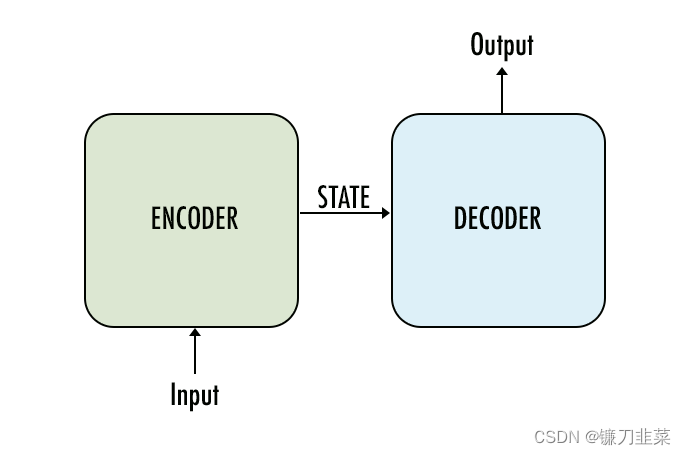
注意:
- encoder和decoder通常都是LSTM模型(或者有时是GRU模型)
- Encoder读取输入序列并将信息汇总为
内部状态向量(internal state vectors)(对于LSTM,这些向量称为隐藏状态(hidden state)和单元状态向量(cell state vectors))。我们丢弃encoder的输出,只保留内部状态。 - Decoder是一种LSTM,其初始状态初始化为Encoder LSTM的最终状态。使用这些初始状态,decoder开始生成输出序列。
- 在训练和推断过程中,decoder的行为稍有不同。在training期间,我们使用了一种叫
老师强制(teacher forcing)的技术,这有助于更快地训练解码器。在推断过程中,每个时间步的解码器输入是前一时间步的输出。 - 直观地,encoder将输入序列汇总为
状态向量(有时也称为Thought vectors),然后将状态向量馈送给decoder,decoder开始生成给定Though vectors的输出序列。decoder只是一个以初始状态为条件的语言模型。
现在,我们将通过考虑将英语句子(输入序列)翻译为等效的马拉地句子(输出序列)的示例,详细了解上述所有步骤。
4.Encoder LSTM
本节简要概述了编码器LSTM的主要组件。我将在不进入数学领域的情况下保持这种直觉。所以这就是他们的本质:
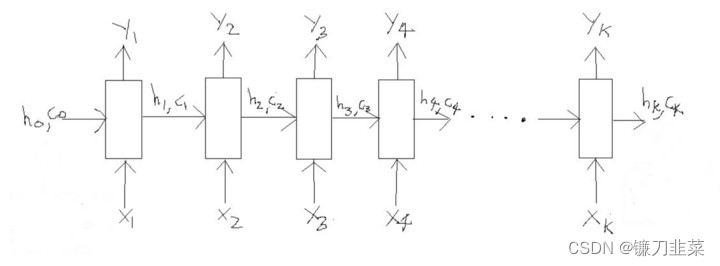
LSTM处理长度为“k”的输入序列
LSTM依次读取数据。因此,如果输入是一个长度为“k”的序列,我们就说LSTM以“k”时间步长读取它(将其视为具有“k”次迭代的for循环)。
参考上图,以下是LSTM的3个主要组成部分:
(1)
X
i
X_i
Xi:在时间步
i
i
i的输入序列
(2)
h
i
h_i
hi和
c
i
c_i
ci:LSTM在每个时间步维持两个状态("h"意思是hidden state,"c"是cell state),综合起来,这些是 LSTM 在时间步
i
i
i的内部状态
(3)
Y
i
Y_i
Yi:在时间步
i
i
i的输出序列
注意:从技术上讲,所有这些组件( X i X_i Xi、 h i h_i hi、 c i c_i ci和 Y i Y_i Yi)实际上都是浮点数的向量(解释如下):
让我们尝试在我们的问题背景下理解所有这些概念。回想一下,我们的问题是把一个英语句子翻译成对应的马拉地语。为了撰写这个博客,我们将考虑以下示例。即我们有以下句子:
Input sentence (English)=> “Rahul is a good boy”
Output sentence (Marathi) => “राहुल चांगला मुलगा आहे”
现在只关注输入,即英语句子
关于 X i X_i Xi的解释
现在,一个句子可以看作是单词或字符的序列。例如,在单词的情况下,上述英语句子可以看作是一个由5个单词组成的序列(“Rahul”、“is”、“a”、“good”、“boy”)。对于字符,可以认为是19个字符的序列(‘R’、‘a’、‘h’、‘u’、‘l’、‘’、……、‘y’)。
我们将用单词打破句子,因为该方法在现实世界应用中更为常见。因此,称为“Word Level NMT”。因此,参考上面的图,有以下输入:
X1 = ‘Rahul’, X2 = ‘is’, X3 = ‘a’, X4 = ‘good, X5 = ‘boy’.
LSTM 将按照如下所示的5个时间步逐字地读这个句子:
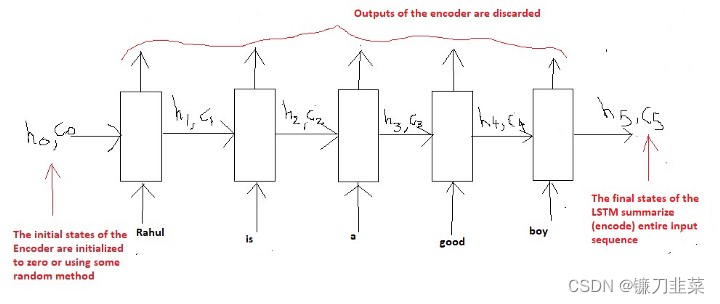
但我们必须回答的一个问题是,如何将每个
X
i
X_i
Xi(每个词)表示为一个向量?
有多种word embedding技术可以将单词映射(embed)到固定长度的向量中。我假设读者熟悉单词嵌入的概念,不会详细讨论这个话题。然而,我们将使用Keras API的内置Embedding Layer将每个单词映射到固定长度向量。
关于 h i h_i hi和 c i c_i ci的解释
下一个问题是,内部状态( h i h_i hi和 c i c_i ci)在每个时间步中的作用是什么?
简单地说,它们记得LSTM到现在为止读过(学到)什么。例如:
h
3
h_3
h3,
c
3
c_3
c3:这两个向量会记住,到目前为止,网络已经阅读了“ Rahul Is A”。基本上是时间步3之前的信息汇总,存储在向量
h
3
h_3
h3和
c
3
c_3
c3中(因此称为时间步3的状态)。
同样地,我们可以说 h 5 h_5 h5, c 5 c_5 c5将包含整个输入句子的摘要,因为这是句子结束的地方(在时间步5)。从最后一个时间步中出来的这些状态也被称为“Thought vectors”,因为它们以向量形式总结了整个顺序。
那
h
0
h_0
h0,
c
0
c_0
c0呢?这些向量通常初始化为零,因为该模型尚未开始读取输入。
注意:这两个向量的大小等于LSTM单元中使用的单元数(神经元)数量。
关于 Y i Y_i Yi的解释
最后, Y i Y_i Yi在每个时间步骤中呢?这些是每个时间步骤中LSTM模型的输出(预测)。
但是 Y i Y_i Yi是什么类型的向量?更具体地说,对于单词级别的语言模型,每个 Y i Y_i Yi实际上是整个词汇量的概率分布,它是通过使用SoftMax激活生成的。因此,每个 Y i Y_i Yi是代表概率分布的大小“ vocab_size”的向量。
根据问题的背景,它们有时可能会被使用,或有时被丢弃。
在我们的案例中,除非我们阅读了整个英语句子,否则我们将无需输出。因为一旦阅读了整个英语句子,我们将开始生成输出序列(等效的马拉地语)。因此,对于我们的问题,我们将放弃编码器的 Y i Y_i Yi。
对encoder的总结
我们将通过单词水平逐步读取输入序列(英语句子)的单词,并保留在最后一次时间步 h k h_k hk之后生成的LSTM网络的内部状态(假设该句子具有“ k”单词)。这些向量(状态 h k h_k hk和 c k c_k ck)被称为输入序列的编码,因为它们以向量形式编码(总结)整个输入。因为一旦读取了整个序列,我们将开始生成输出,因此每个时间步的编码器的输出( Y i Y_i Yi)被丢弃。
此外,您还必须了解 X i X_i Xi, h i h_i hi, c i c_i ci和 Y i Y_i Yi的类型。它们的大小是多少(形状),它们代表了什么。如果您有任何理解这一部分的混乱,那么您需要首先加强对LSTM和语言模型的理解。
5.Decoder LSTM——训练模式
与在训练阶段和推理阶段都具有相同作用的Encoder LSTM不同,Decoder LSTM在这两个阶段中都具有略有不同的作用。
在本节中,我们将尝试了解如何在训练阶段配置Decoder,而在下一节中,我们将了解如何在推理过程中使用它。
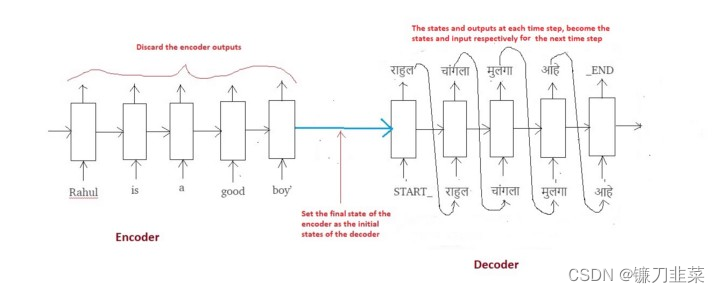
回想一下,如果输入一个句子“ Rahul is a good boy”, 训练过程的目标是训练(教会)解码器输出"राहुल चांगला मुलगा आहे". 就像Encoder 逐词扫描输入序列一样,Decoder也会逐词生成输出序列。
出于一些技术原因(稍后解释),我们将在输出序列中添加两个标记(tokens),如下所示:
Output sequence => “START_ राहुल चांगला मुलगा आहे _END”
现在考虑下图:
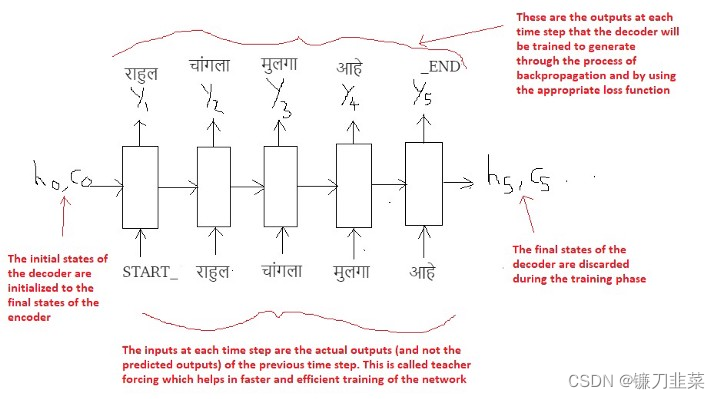
Decoder LSTM — Training Mode
最重要的一点是,解码器的初始状态( h 0 h_0 h0, c 0 c_0 c0)被设置为编码器的最终状态。直观上意味着:根据编码器编码的信息,训练解码器开始生成输出序列。显然,翻译的马拉地语句子必须取决于给定的英语句子。
在第一个时间步中,我们提供START_标记,以便解码器开始生成下一个标记(token)(Marathi句子的实际第一个单词)。在Marathi句子的最后一个单词之后,我们让解码器学习预测_END标记。这将用作推理过程中的停止条件,基本上它将表示翻译句子的结束,我们将停止推理循环(稍后将对此进行详细介绍)。
我们使用一种称为“Teacher Forcing”的技术,其中每个时间点的输入都是前一个时间点的实际输出(而不是预测输出)。这有助于更快,更有效的网络训练。要了解有关teacher forcing的更多信息,请参阅此博客。
最后,损失是根据每个时间步的预测输出计算的,并且错误会随时间反向传播,以更新网络的参数。用足够大的数据量对网络进行较长时间的训练,可以得到非常好的预测(翻译),我们稍后会看到。
下图是整个训练过程(编码器 +解码器)的概览:
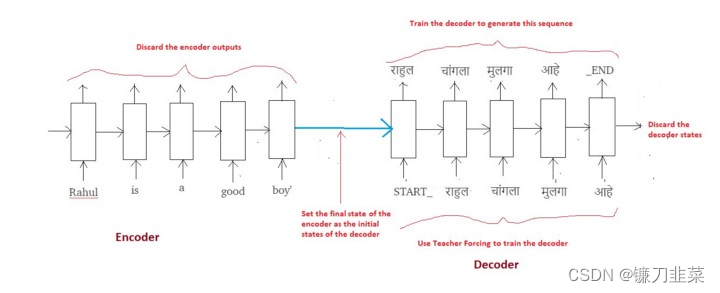
6.Decoder LSTM——推断模式
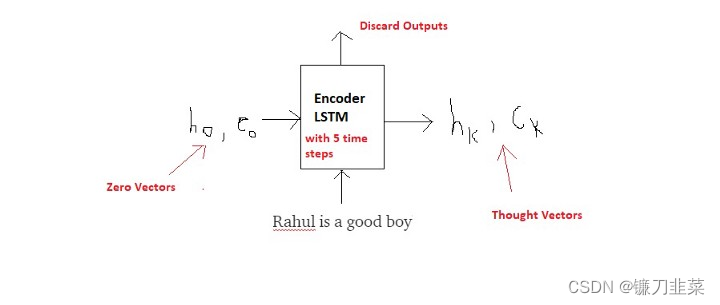
现在,让我们尝试了解推断模式所需的设置。如前所述,Encoder LSTM在读取输入序列(英语句子)和生成thought vectors( h k h_k hk, c k c_k ck)方面起着相同的作用。
然而,解码器现在必须根据这些thought vectors预测整个输出序列(Marathi句子)。
让我们试着通过同样的例子来直观地理解。
Input sequence => “Rahul is a good boy”
(Expected) Output Sequence => “राहुल चांगला मुलगा आहे”
步骤1:将输入序列编码为Thought Vectors:
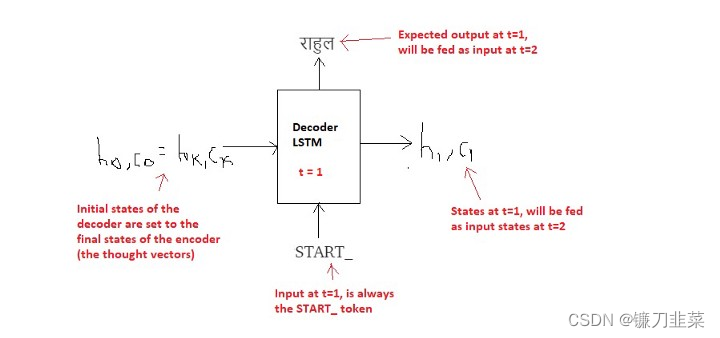
步骤2:开始在循环中生成输出序列,一个词接着一个词:
在
t
=
1
t=1
t=1时刻:
在
t
=
2
t=2
t=2时刻:
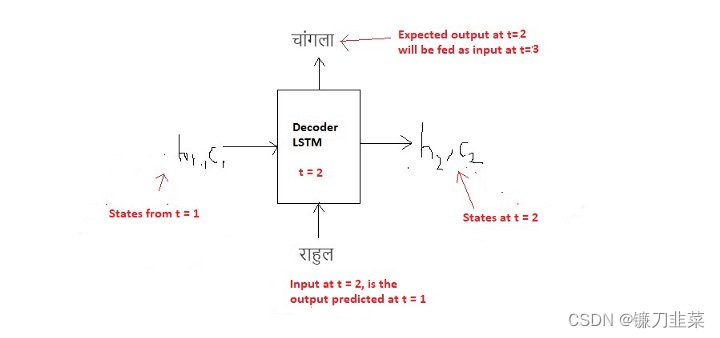
在
t
=
3
t=3
t=3时刻:
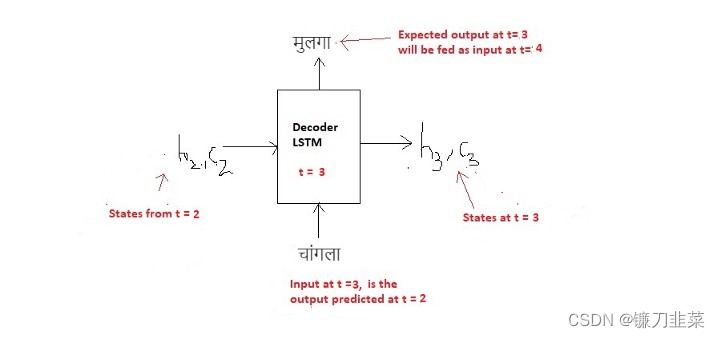
在
t
=
4
t=4
t=4时刻:
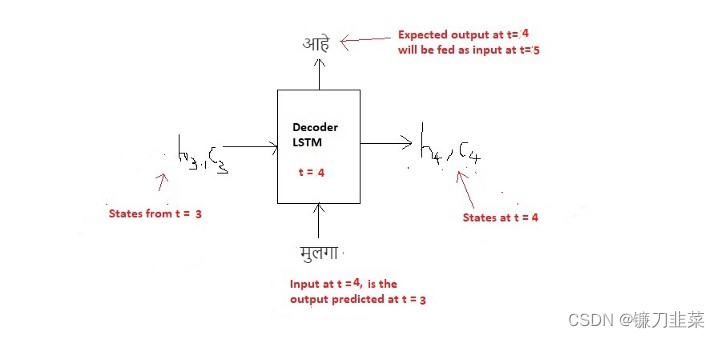
在
t
=
5
t=5
t=5时刻:
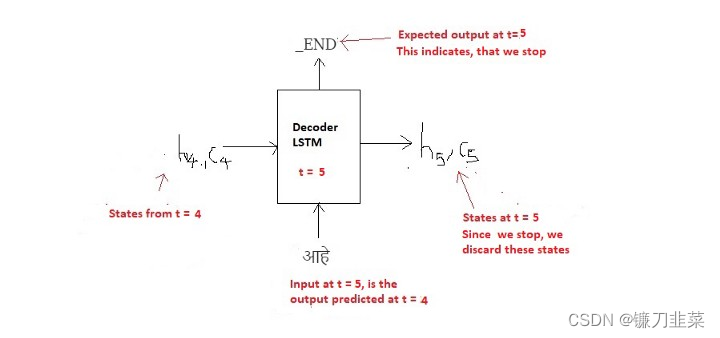
推理算法:
a. 在推理期间,我们一次生成一个单词,因此,每次处理一个时间步时,Decoder LSTM都会在循环中调用。
b. 解码器的初始状态设置为编码器的最终状态。
c. 解码器的初始输入始终是START_ token。
d. 在每个时间步中,我们都保留解码器的状态,并将其设置为下一个步骤的初始状态。
e. 在每个时间步中,预测的输出作为下一个时间步的输入。
f. 当解码器预测END_token时,中断循环。
整个推理过程可以总结在下图中:
7.代码演练
当我们实际实现代码时,没有什么比理解更好的了,无论我们付出了多少努力来理解理论(这并不意味着我们不讨论任何理论,但我的意思是理论必须始终遵循实现)。
数据集
从Tab-delimited Bilingual Sentence Pairs下载和解压mar-eng.zip
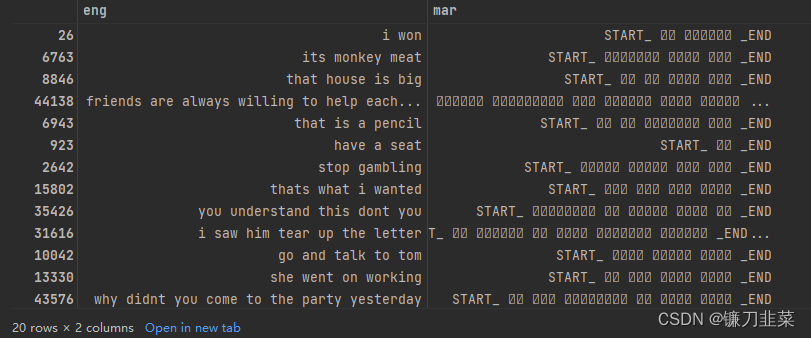
在开始构建模型之前,我们需要执行一些数据清理和准备。在不进行太多细节的情况下,假设读者可以理解以下(自我解释)步骤,这些步骤通常是任何语言处理项目的一部分。
lines = pd.read_table('../DemoData/mar-eng/mar.txt', names=['eng', 'mar'], index_col=False)
print(lines.shape)
#%%
# 小写所有字符
lines.eng = lines.eng.apply(lambda x:x.lower())
lines.mar = lines.mar.apply(lambda x:x.lower())
#%%
# 删除引号
lines.eng = lines.eng.apply(lambda x:re.sub("'", '', x))
lines.mar = lines.mar.apply(lambda x:re.sub("'", '', x))
#%%
exclude = set(string.punctuation) # 所有特殊字符的集合
# 移除所有特殊字符
lines.eng = lines.eng.apply(lambda x: ''.join(ch for ch in x if ch not in exclude))
lines.mar = lines.mar.apply(lambda x: ''.join(ch for ch in x if ch not in exclude))
#%%
# 从文本中删除所有数字
remove_digits = str.maketrans('', '', digits)
lines.eng = lines.eng.apply(lambda x: x.translate(remove_digits))
lines.mar = lines.mar.apply(lambda x: re.sub("[२३०८१५७९४६]", "", x))
#%%
# 删除所有额外的空格
lines.eng=lines.eng.apply(lambda x: x.strip())
lines.mar=lines.mar.apply(lambda x: x.strip())
lines.eng=lines.eng.apply(lambda x: re.sub(" +", " ", x))
lines.mar=lines.mar.apply(lambda x: re.sub(" +", " ", x))
#%%
# 在目标句子中增加开始和结束标记
lines.mar = lines.mar.apply(lambda x : 'START_ '+ x + ' _END')
#%%
下面我们计算英语和马拉地语的词汇。我们还计算了这两种语言的词汇量大小和最大序列长度。最后,我们创建了4个Python词典(每种语言的两个),用以将给定的令牌(token)转换为整数索引,反之亦然。
# 英文单词集
all_eng_words = set()
for eng in lines.eng:
for word in eng.split():
if word not in all_eng_words:
all_eng_words.add(word)
# 所有的马拉地语
all_marathi_words = set()
for mar in lines.mar:
for word in mar.split():
if word not in all_marathi_words:
all_marathi_words.add(word)
#%%
# 翻译中的原始句子的最大长度
length_list = []
for l in lines.eng:
length_list.append(len(l.split(' ')))
max_length_src = np.max(length_list)
max_length_src
#%%
# 目标句子的最大长度
lenght_list=[]
for l in lines.mar:
lenght_list.append(len(l.split(' ')))
max_length_tar = np.max(lenght_list)
max_length_tar
#%%
input_words = sorted(list(all_eng_words))
target_words = sorted(list(all_marathi_words))
# 计算源词汇和目标词汇表的大小
num_encoder_tokens = len(all_eng_words)
num_decoder_tokens = len(all_marathi_words)
num_encoder_tokens, num_decoder_tokens
#%%
num_decoder_tokens += 1 # For zero padding
num_decoder_tokens
#%%
# 分别为源单词和目标单词创建单词与token的对照表
input_token_index = dict([(word, i+1) for i, word in enumerate(input_words)])
target_token_index = dict([(word, i+1) for i, word in enumerate(target_words)])
#%%
# 为源单词和目标单词创建token-to-word的字典
reverse_input_char_index = dict((i, word) for word, i in input_token_index.items())
reverse_target_char_index = dict((i, word) for word, i in target_token_index.items())
#%%
lines = shuffle(lines)
lines.head(10)
#%%
然后,我们按照90%训练,10%测试进行拆分,并编写一个Python生成器函数来批量加载数据,如下所示:
# 训练数据和测试数据拆分
X,y = lines.eng, lines.mar
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
X_train.shape, X_test.shape
#%%
# 训练数据和测试数据拆分
X,y = lines.eng, lines.mar
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
X_train.shape, X_test.shape
#%%
# 保存训练和测试数据框,以便于后边重复本实验
X_train.to_pickle('../DemoData/mar-eng/X_train.pkl')
X_test.to_pickle('../DemoData/mar-eng/X_test.pkl')
#%%
def generate_batch(X=X_train, y=y_train, batch_size=128):
"""Generate a batch of data"""
while True:
for j in range(0, len(X), batch_size):
encoder_input_data = np.zeros((batch_size, max_length_src), dtype='float32')
decoder_input_data = np.zeros((batch_size, max_length_tar), dtype='float32')
decoder_target_data = np.zeros((batch_size, max_length_tar, num_decoder_tokens), dtype='float32')
for i, (input_text, target_text) in enumerate(zip(X[j:j + batch_size], y[j:j + batch_size])):
for t, word in enumerate(input_text.split()):
encoder_input_data[i, t] = input_token_index[word] # 编码器输入序列
for t, word in enumerate(target_text.split()):
if t < len(target_text.split()) - 1:
decoder_input_data[i, t] = target_token_index[word] # 解码器输入序列
if t > 0:
# 解码器 目标序列(one-hot编码)
# 不包含START_ token
# 按一个时间步偏移
decoder_target_data[i, t - 1, target_token_index[word]] = 1.
yield [encoder_input_data, decoder_input_data], decoder_target_data
然后,我们将训练所需的模式定义如下:
latent_dim = 50
#%%
# Encoder
encoder_inputs = Input(shape=(None, ))
enc_emb = Embedding(num_encoder_tokens, latent_dim, mask_zero=True)(encoder_inputs)
encoder_lstm = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(enc_emb)
#%%
# 我们抛弃`encoder_outputs`,只保留状态
encoder_states = [state_h, state_c]
# 设置解码器, 使用'encoder_states'作为初始状态
decoder_inputs = Input(shape=(None, ))
dec_emb_layer = Embedding(num_decoder_tokens, latent_dim, mask_zero=True)
dec_emb = dec_emb_layer(decoder_inputs)
#%%
# 我们将解码器设置为返回完整的输出序列,并返回内部状态。
# 我们不在训练模型中使用返回状态,但我们将在推理中使用它们。
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(dec_emb, initial_state=encoder_states)
# 使用softmax为每个时间步生成目标词汇表的概率分布
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# 定义将 `encoder_input_data` 和 `decoder_input_data` 转换为 `decoder_target_data` 的模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
#%%
# 编译模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
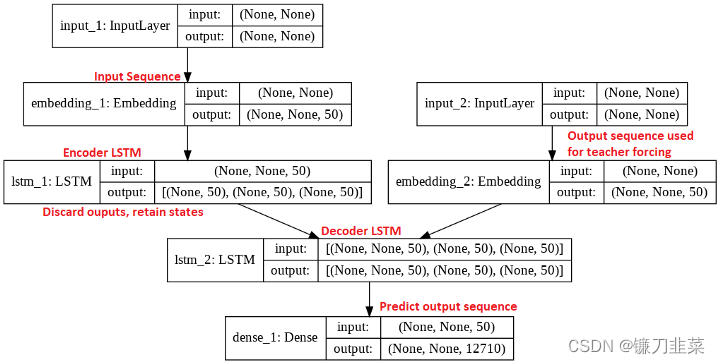
这里应该能够从概念上将每一行与上文第4和第5节中的解释联系起来。让我们看一下Keras的plot_model程序生成的模型架构图:
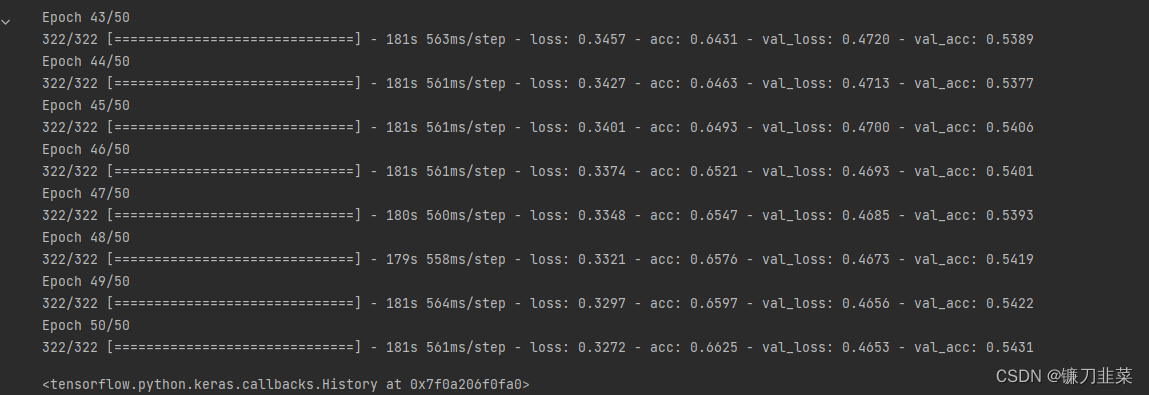
我们对网络进行了50个epochs的训练,batch大小为128。在P4000 GPU上,训练时间略多于2个小时。训练过程如下:
推理设置:
# 编码输入序列,以获得”thought vectors“
encoder_model = Model(encoder_inputs, encoder_states)
#%%
# 解码器设置
# 下列tensors将会保存上一个时间步的状态
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# 获得解码器序列的embeddings
dec_emb2 = dec_emb_layer(decoder_inputs)
#%%
# 为了预测序列中的下一个词,将来自前一个时间步的状态设置初始状态
decoder_outputs2, state_h2, state_c2 = decoder_lstm(dec_emb2, initial_state=decoder_states_inputs)
decoder_states2 = [state_h2,state_c2]
# 一个dense software layer用以生成概率列表,基于目标词汇表
decoder_outputs2 = decoder_dense(decoder_outputs2)
#%%
# 最终的解码器模型
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs2]+decoder_states2)
#%%
编码器模型:
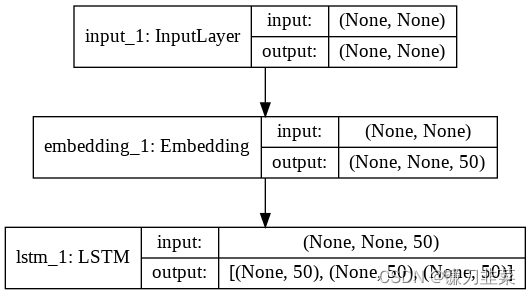
解码器模型:
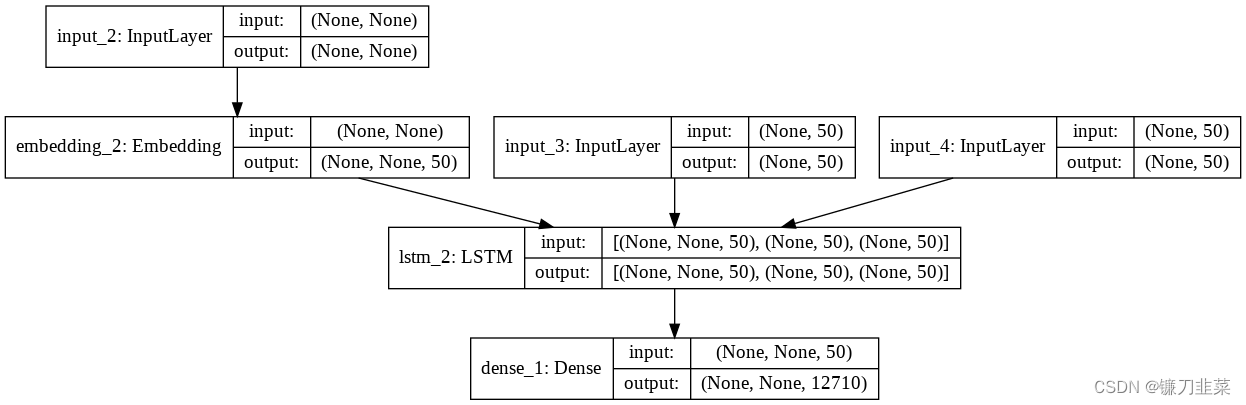
最后,我们通过在循环中调用上述设置来生成输出序列:如下:
def decode_sequence(input_seq):
# 编码输入作为状态向量
state_value = encoder_model.predict(input_seq)
# 生成长度为1的空的目标序列
target_seq = np.zeros((1,1))
# 用起始字符填充目标序列的第一个字符
target_seq[0,0] = target_token_index['START_']
# 一个批次序列的抽象循环,为了简单起见,我们假设一个batch的大小为1
stop_condition=False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq]+state_value)
# 采样一个token
sampled_token_index = np.argmax(output_tokens[0,-1,:])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += ''+sampled_char
# 退出条件:要么达到最大长度,要么遇到停止字符
if sampled_char == '_END' or len(decoded_sentence) > 50:
stop_condition = True
# 更新目标序列(长度为1)
target_seq = np.zeros((1,1))
target_seq[0,0] = sampled_token_index
# 更新状态
state_value = [h, c]
return decoded_sentence
此时,您必须能够从概念上将上述两个代码块中的每一行代码与第6节中提供的解释连接起来。
8.结果和评估
这篇博文的目的是对如何使用 LSTM 构建序列模型的基本层次序列给出一个直观的解释,而不是开发一个高质量的语言翻译器。因此,请记住,由于许多原因,这些结果并不是世界级的(而且你不会开始与谷歌翻译进行比较)。最重要的原因是,数据集的大小非常小,只有33000对句子(是的,这些是太少)。如果你想提高翻译质量,我将在本博客结尾处列出一些建议。然而,现在,让我们看看从上述模型生成的一些结果(它们也不是太糟糕)。
在训练数据集上的结果
train_gen = generate_batch(X_train, y_train, batch_size=1)
k=-1
#%%
k+=1
(input_seq, actual_output), _ = next(train_gen)
decoded_sentence = decode_sequence(input_seq)
print('Input English sentence:', X_train[k:k+1].values[0])
print('Actual Marathi Translation:', y_train[k:k+1].values[0][6:-4])
print('Predicted Marathi Translation:', decoded_sentence[:-4])
结果如下:
Input English sentence: it is a holiday tomorrow
Actual Marathi Translation: उद्या सुट्टी आहे
Predicted Marathi Translation: उद्या नाताळ आहे
Input English sentence: i will give you this book
Actual Marathi Translation: मी तुम्हाला हे पुस्तक देईन
Predicted Marathi Translation: मी तुला हे पुस्तक तुला दिलं
Input English sentence: this sentence has five words
Actual Marathi Translation: या वाक्यात पाच शब्द आहेत
Predicted Marathi Translation: या पाच शब्द आहेत
Input English sentence: did you clean your room
Actual Marathi Translation: तुझी खोली साफ केलीस का
Predicted Marathi Translation: तुझी खोली साफ केली का
Input English sentence: she wrapped herself in a blanket
Actual Marathi Translation: त्यांनी स्वतःला एका चादरीत गुंडाळून घेतलं
Predicted Marathi Translation: तिने एका छोट्या चादर घातली
Input English sentence: he is still alive
Actual Marathi Translation: तो अजूनही जिवंत आहे
Predicted Marathi Translation: ते अजूनही जिवंत आहेत
Input English sentence: you cant speak french can you
Actual Marathi Translation: तुला फ्रेंच बोलता येत नाही ना
Predicted Marathi Translation: तुला फ्रेंच बोलता येत नाही का नाही माहीत
在测试数据集上的效果
val_gen = generate_batch(X_test, y_test, batch_size=1)
k=-1
#%%
k+=1
(input_seq, actual_output), _ = next(val_gen)
decoded_sentence = decode_sequence(input_seq)
print('Input English sentence:', X_test[k:k+1].values[0])
print('Actual Marathi Translation:', y_test[k:k+1].values[0][6:-4])
print('Predicted Marathi Translation:', decoded_sentence[:-4])
结果如下:
Input English sentence: my wife isnt beautiful yours is
Actual Marathi Translation: माझी बायको सुंदर नाहीये तुझी आहे
Predicted Marathi Translation: माझी तुझी गर्लफ्रेंड सुंदर आहे भेटलो
Input English sentence: who lives in this house
Actual Marathi Translation: या घरात कोण राहतं
Predicted Marathi Translation: या घरात कोणी असतो
Input English sentence: somethings happened to tom
Actual Marathi Translation: टॉमला काहीतरी झालंय
Predicted Marathi Translation: टॉमला काहीतरी झालं आहे
Input English sentence: the dog jumped over a chair
Actual Marathi Translation: कुत्र्याने खुर्चीवरून उडी मारली
Predicted Marathi Translation: एक कुत्र्याला दरवाजा बंद केला
Input English sentence: i can prove who the murderer is
Actual Marathi Translation: खुनी कोण आहे हे मी सिद्ध करू शकतो
Predicted Marathi Translation: मी जिंकू शकतो हे मला माहीत आहे
Input English sentence: everyone could hear what tom said
Actual Marathi Translation: टॉम जे म्हणाला ते सर्वांना ऐकू येत होतं
Predicted Marathi Translation: टॉमने काय म्हटलं म्हटलं तर खरं
Input English sentence: those are my books
Actual Marathi Translation: ती माझी पुस्तकं आहेत
Predicted Marathi Translation: ती माझी पुस्तकं आहेत
测试结论
尽管结果不是最好的,但也没有那么糟糕。当然比随机生成的序列要好得多。在一些句子中,我们甚至可以注意到预测的单词并不正确,但是它们在语义上非常接近正确的单词。
另外,需要注意的是,训练集上的结果比测试集上的结果要好一些,这表明模型可能有点过拟合。
9.未来的工作
如果你有兴趣提高翻译的质量,可以尝试以下措施:
- 获得更多的数据。高质量的翻译是在数以百万计的句子对上的训练。
- 构建更复杂的模型,如Attention。
- 使用dropout和其他形式的正则化技术,来缓解过拟合。
- 执行超参数调优。即关于学习率,batch size,dropout rate等调优。尝试使用双向Encoder LSTM。尝试使用多层 LSTM。
- 尝试使用beam search代替greedy approach。
- 尝试使用BLEU评分来评估你的模型。
- 这个可优化的措施列表永远不会结束,而且还在继续…
10.注意事项
如果你喜欢我的解释,你可以follow我,因为我计划发布一些更有趣的博客有关深度学习和人工智能。
11.遇到的问题
-
cannot import name 'wrappers' from 'tensorflow.python.keras.layers'

由于Tensorflow2.9.1对keras封装的混乱,导致plot_model无法使用 -
Node: 'model_1/embedding_2/embedding_lookup'
indices[7,2] = 5823 is not in [0, 5823)
[[{{node model_1/embedding_2/embedding_lookup}}]] [Op:__inference_train_function_16827]
Answer found: increase the vocabulary size. It is 5000 by default. This error is like an out of bound index error.
num_encoder_tokens += 1
num_encoder_tokens
12.参考资料
[1] What is Teacher Forcing for Recurrent Neural Networks?
[2] https://github.com/hlamba28/Word-Level-Eng-Mar-NMT/blob/master/WordLevelEngMarNMT.ipynb
[3] https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
[4] Sequence to Sequence Learning with Neural Networks
[5] Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation