数据分析-非参数秩方法
文章目录
- 两种处理方法比较的秩检验
- Wilcoxon秩和检验
- Smirnov检验
- 成对分组设计下两种处理方法的比较
- 符号检验
- Wilcoxon符号秩检验
- 多种处理方法比较
- Kruskal-Wallis检验
- 分组设计下多种处理方法的比较
- Friedman检验
非参数秩方法,即不假定总体分布的具体形式,从数据本身获得所需信息,适用范围广,但忽略了分布类型,针对性差。
本文主要参考《数据分析》范金城,梅长林主编. -2版.

两种处理方法比较的秩检验
首先理解「秩」是什么,秩即顺序,是数据排序之后的位置。比如N个数据{3,2,4,1,5},若按从小到大排序可以得到排序结果{1,2,3,4,5},也就是第一个数据3的秩S1为3,以此类推S2=2,S3=4,S4=1,S5=5。
此节即通过秩来比较两种不同处理方法的优劣,也就是将N个数据分为两组,两组分别用两种不同的处理方法,分别为 n n n和 m m m个( m m m=N- n n n),共 C N n C_N^{n} CNn种分法,每种分配方式出现概率为 1 C N n \frac{1}{C_N^{n}} CNn1。
检验零假设 H 0 H_0 H0:两方法处理效果无显著差异。由于分组是随机的,则秩 ( S 1 , S 2 , ⋅ ⋅ ⋅ , S n ) (S_1,S_2,···,S_n) (S1,S2,⋅⋅⋅,Sn)的零分布 P H 0 { S 1 = s 1 , S 2 = s 2 , ⋅ ⋅ ⋅ , S n = s n } = 1 C N n P_{H_0}\{S_1=s_1,S_2=s_2,···,S_n=s_n\}=\frac{1}{C_N^{n}} PH0{S1=s1,S2=s2,⋅⋅⋅,Sn=sn}=CNn1。
Wilcoxon秩和检验
- 单边假设检验
单边假设即在实验前认为新方法比旧方法好,比如是旧方法的改进版。备择假设 H 1 H_1 H1:新方法优于对照方法。
N个数据分为 n n n和 m m m个,排序后得到秩,秩分别记为 ( S 1 , S 2 , ⋅ ⋅ ⋅ , S n ) (S_1,S_2,···,S_n) (S1,S2,⋅⋅⋅,Sn)和 ( R 1 , R 2 , ⋅ ⋅ ⋅ , R m ) (R_1,R_2,···,R_m) (R1,R2,⋅⋅⋅,Rm),记秩和为 W W W,即 W s = S 1 + S 2 + ⋅ ⋅ ⋅ + S n W_s=S_1+S_2+···+S_n Ws=S1+S2+⋅⋅⋅+Sn,同理 W r = R 1 + R 2 + ⋅ ⋅ ⋅ + R m W_r=R_1+R_2+···+R_m Wr=R1+R2+⋅⋅⋅+Rm,得到各种组合情况下的秩和后,即可得到对应零分布。
其实 W s W_s Ws和 W r W_r Wr的零分布是相同的,用来检验 H 0 H_0 H0也是等价的,即可以算 n n n和 m m m中较小一个即可。
根据零分布计算 p p p值, p = P H 0 { W s ≥ w s } p=P_{H_0}\{W_s≥w_s\} p=PH0{Ws≥ws},与题目给的显著水平 α \alpha α比较,若 p < α p<\alpha p<α,则拒绝 H 0 H_0 H0,认为新方法比就方法好,否则接受 H 0 H_0 H0,认为两者不存在显著差异。
- 习题2.1.(1):求
m
m
m=2,
n
n
n=4情况下,Wilcoxon秩和统计量
W
s
W_s
Ws和
W
r
W_r
Wr的零分布。
解: ( S 1 (S_1 (S1, S 2 S_2 S2, S 3 S_3 S3, S 4 ) S_4) S4)取各组值对应 W s W_s Ws如下表所示:
| ( S 1 (S_1 (S1, S 2 S_2 S2, S 3 S_3 S3, S 4 ) S_4) S4) | W s W_s Ws |
|---|---|
| 1 2 3 4 | 10 |
| 1 2 3 5 | 11 |
| 1 2 3 6 | 12 |
| 1 2 4 5 | 12 |
| 1 2 4 6 | 13 |
| 1 2 5 6 | 14 |
| 1 3 4 5 | 13 |
| 1 3 4 6 | 14 |
| 1 3 5 6 | 15 |
| 1 4 5 6 | 16 |
| 2 3 4 5 | 14 |
| 2 3 4 6 | 15 |
| 2 3 5 6 | 16 |
| 2 4 5 6 | 17 |
| 3 4 5 6 | 18 |
由上表得 W s W_s Ws的零分布,如下表所示:
| W s W_s Ws | P H 0 { W s = w s } P_{H_0}\{W_s=w_s\} PH0{Ws=ws} |
|---|---|
| 10 | 1/15 |
| 11 | 1/15 |
| 12 | 2/15 |
| 13 | 2/15 |
| 14 | 3/15 |
| 15 | 2/15 |
| 16 | 2/15 |
| 17 | 1/15 |
| 18 | 1/15 |
( R 1 (R_1 (R1, R 2 ) R_2) R2)取各组值对应 W r W_r Wr如下表所示:
| ( R 1 (R_1 (R1, R 2 ) R_2) R2) | W r W_r Wr |
|---|---|
| 1 2 | 3 |
| 1 3 | 4 |
| 1 4 | 5 |
| 1 5 | 6 |
| 1 6 | 7 |
| 2 3 | 5 |
| 2 4 | 6 |
| 2 5 | 7 |
| 2 6 | 8 |
| 3 4 | 7 |
| 3 5 | 8 |
| 3 6 | 9 |
| 4 5 | 9 |
| 4 6 | 10 |
| 5 6 | 11 |
由上表得 W r W_r Wr的零分布,如下表所示:
| W r W_r Wr | P H 0 { W r = w r } P_{H_0}\{W_r=w_r\} PH0{Wr=wr} |
|---|---|
| 3 | 1/15 |
| 4 | 1/15 |
| 5 | 2/15 |
| 6 | 2/15 |
| 7 | 3/15 |
| 8 | 2/15 |
| 9 | 2/15 |
| 10 | 1/15 |
| 11 | 1/15 |
- 双边假设检验
双边假设检验即两种方法对我们来说都是新方法,实验前不知道哪个更优。备择假设 H 1 H_1 H1:两方法有显著差异。
同样两组,换了符号为A、B, W A W_A WA为A组秩和,零分布求法一致,概率值 P H 0 { W A ≥ w A } P_{H_0}\{W_A≥w_A\} PH0{WA≥wA}和 P H 0 { W A ≤ w A } P_{H_0}\{W_A≤w_A\} PH0{WA≤wA}, p p p值为这两个概率值中小于1/2的那个的2倍。
同样与显著水平 α \alpha α比较,若 p < α p<\alpha p<α,则拒绝 H 0 H_0 H0,否则接受 H 0 H_0 H0,不再赘述。
- 结点处理
上述方法是不存在结点的情况,所谓结点可理解为排序相同的点,比如对实验结果排序时,是按档次评价的,若干个结果的属于一个档次,秩相同。
设 d d d个个体形成一个结点,对应位置 l , l + 1 , ⋅ ⋅ ⋅ , l + d − 1 l,l+1,···,l+d-1 l,l+1,⋅⋅⋅,l+d−1,比如ABBC对应秩为1224。
使用中间秩= l + d − 1 2 l+\frac{d-1}{2} l+2d−1,记中间秩和为 W s ∗ W_s^* Ws∗和 W r ∗ W_r^* Wr∗,有
期望 E ( W s ∗ ) = 1 2 n ( N + 1 ) E(W_s^*)=\frac{1}{2}n(N+1) E(Ws∗)=21n(N+1)
方差 V a r ( W s ∗ ) = 1 12 m n ( N + 1 ) − m n ∑ i = 1 l d i 3 − d i 12 N ( N − 1 ) Var(W_s^*)=\frac{1}{12}mn(N+1)-\frac{mn\sum_{i=1}^ld_i^3-d_i}{12N(N-1)} Var(Ws∗)=121mn(N+1)−12N(N−1)mn∑i=1ldi3−di
用标准正态分布代替, Φ ( c ) = P H 0 ( W s ∗ − E ( W s ∗ ) V a r ( W s ∗ ) ≤ c ) \Phi(c)=P_{H_0}(\frac{W_s^*-E(W_s^*)}{\sqrt{Var(W_s^*)}}≤c) Φ(c)=PH0(Var(Ws∗)Ws∗−E(Ws∗)≤c)
p = 1 − Φ ( c ) p=1-\Phi(c) p=1−Φ(c),与题目显著水平 α \alpha α比较,若 p < α p<\alpha p<α则拒绝 H 0 H_0 H0,反之接受 H 0 H_0 H0
公式很多很复杂,考前摇一摇。
- 习题2.4:为了比较两种不同的心理咨询方法的效果,将80位接受心理咨询的人随机地分为两组,每组40人,其中一组接受一般的心理咨询,另一组接受特殊的心理咨询,试验结束后,将每个人的心理调整效果做仔细评估,并分为好、较好、较差和差四档,数据如表2.23所示.
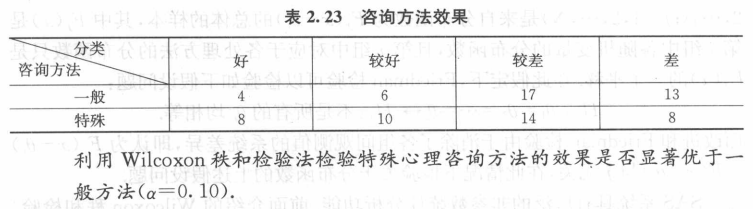
解:N=80, n n n= m m m=40, l l l=4, d 1 d_1 d1=12, d 2 d_2 d2=16, d 3 d_3 d3=31, d 4 d_4 d4=21。
计算中间秩如下所示:
好: 1 + 12 − 1 2 = 6.5 1+\frac{12-1}{2}=6.5 1+212−1=6.5
较好: 13 + 16 − 1 2 = 20.5 13+\frac{16-1}{2}=20.5 13+216−1=20.5
较差: 29 + 31 − 1 2 = 44 29+\frac{31-1}{2}=44 29+231−1=44
差: 60 + 21 − 1 2 = 70 60+\frac{21-1}{2}=70 60+221−1=70
秩和 W s ∗ = 8 × 6.5 + 10 × 20.5 + 14 × 44 + 8 × 70 = 1433 W_s^*=8×6.5+10×20.5+14×44+8×70=1433 Ws∗=8×6.5+10×20.5+14×44+8×70=1433
期望 E ( W s ∗ ) = 1620 E(W_s^*)=1620 E(Ws∗)=1620
方差 V a r ( W s ∗ ) = 9855 Var(W_s^*)=9855 Var(Ws∗)=9855
p = P H 0 { W s ∗ ≥ 1433 } = P H 0 ( W s ∗ − E ( W s ∗ ) V a r ( W s ∗ ) ≥ 1433 − 1620 99.272 ) ≈ 1 − Φ ( − 1.87 ) = 0.03 < 0.10 p=P_{H_0}\{W_s^*≥1433\}=P_{H_0}(\frac{W_s^*-E(W_s^*)}{\sqrt{Var(W_s^*)}}≥\frac{1433-1620}{99.272})≈1-\Phi(-1.87)=0.03<0.10 p=PH0{Ws∗≥1433}=PH0(Var(Ws∗)Ws∗−E(Ws∗)≥99.2721433−1620)≈1−Φ(−1.87)=0.03<0.10
由于 p < α p<\alpha p<α,故拒绝 H 0 H_0 H0,认为特殊心理咨询方法优于一般方法。
Smirnov检验
当一组数据分散性小,一组数据分散性大时, Wilcoxon秩和检验不能区分这种差异。使用Smirnov检验能很好反映两种方法处理效果的各种差异。
定义经验分布函数 F k ( x ) = # { x i ≤ x } k F_k(x)=\frac{\#\{x_i≤x\}}{k} Fk(x)=k#{xi≤x},其中 # { x i ≤ x } \#\{x_i≤x\} #{xi≤x}表示 x 1 , x 2 , ⋅ ⋅ ⋅ , x k x_1,x_2,···,x_k x1,x2,⋅⋅⋅,xk中小于等于 x x x的个数。比如1、2、3的经验函数分别为 1 3 \frac{1}{3} 31、 2 3 \frac{2}{3} 32、 1 1 1。
定义统计量 D m , n = m a x ∣ G m ( x ) − F n ( x ) ∣ D_{m,n}=max| G_m(x)-F_n(x)| Dm,n=max∣Gm(x)−Fn(x)∣,即取两组经验分布函数差值的最大值。
p = P H 0 { D m , n ≥ c } p=P_{H_0}\{D_{m,n}≥c\} p=PH0{Dm,n≥c}, p < α p<\alpha p<α时拒绝 H 0 H_0 H0,反之接受 H 0 H_0 H0。
- 习题2.5:下面是1996年华北五省市区和华东七省市的国民生产总值(GDP)的指数(前一年为100);
华北五省市区GDP指数: 109. 2,114.3,113.5,111.0,112.7
华东七省市的GDP指数: 113.0,112.2,112.7,114 4,115.4,113.4,112.2
利用Smirnov检验法检验这两个地区的GDP指数是否有显著差异( α \alpha α=0.10).
解:
将数据排序后得到秩,A:1 2 5 9 10;B:3 3 5 7 8 11 12
| 有序观测值 | G m ( x ) G_m(x) Gm(x) | F n ( x ) F_n(x) Fn(x) | ∣ G m ( x ) − F n ( x ) ∣ | G_m(x)-F_n(x)| ∣Gm(x)−Fn(x)∣ |
|---|---|---|---|
| z 1 z_1 z1 | 0 | 1/5 | 1/5 |
| z 2 z_2 z2 | 0 | 2/5 | 1/5 |
| z 3 z_3 z3 | 2/7 | 2/5 | 4/35 |
| z 4 z_4 z4 | 2/7 | 2/5 | 4/35 |
| z 5 z_5 z5 | 3/7 | 3/5 | 6/35 |
| z 6 z_6 z6 | 3/7 | 3/5 | 6/35 |
| z 7 z_7 z7 | 4/7 | 3/5 | 1/35 |
| z 8 z_8 z8 | 5/7 | 3/5 | 4/35 |
| z 9 z_9 z9 | 5/7 | 4/5 | 3/35 |
| z 10 z_{10} z10 | 5/7 | 1 | 2/7 |
| z 11 z_{11} z11 | 6/7 | 1 | 1/7 |
| z 12 z_{12} z12 | 1 | 1 | 0 |
由上表的
D
7
,
5
D_{7,5}
D7,5的观测值
d
=
2
5
d=\frac{2}{5}
d=52
p
=
P
H
0
{
D
7
,
5
≥
2
5
}
=
1
12
<
α
p=P_{H_0}\{D_{7,5}≥\frac{2}{5}\}=\frac{1}{12}<\alpha
p=PH0{D7,5≥52}=121<α
故拒绝
H
0
H_0
H0,认为这两个地区GDP有显著差异。
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/

成对分组设计下两种处理方法的比较
成对分组把数据分为若干组,每个组中的差异都很小,称为齐性组。再把齐性组分为两部分,分别接受两种方法的实验,检验两种方法效果差异。
符号检验
令
I
i
=
{
1
,第
i
对个体中
,
新方法效果优于对照方法
0
,否则
I_i=\begin{cases}1,第i对个体中,新方法效果优于对照方法\\0,否则\end{cases}
Ii={1,第i对个体中,新方法效果优于对照方法0,否则
记统计量
S
N
=
∑
i
=
1
N
I
i
S_N=\sum_{i=1}^NI_i
SN=∑i=1NIi
可以理解为每一对做差,取正号的总数,即符号检验。
由于每一对中两个数据随机分给两种实验方法,概率为
1
2
\frac{1}{2}
21,有
P
H
0
{
S
N
=
k
}
=
1
2
N
C
N
k
P_{H_0}\{S_N=k\}=\frac{1}{2^N}C_N^k
PH0{SN=k}=2N1CNk,
k
=
0
,
1
,
⋅
⋅
⋅
,
N
k=0,1,···,N
k=0,1,⋅⋅⋅,N
p
=
P
H
0
{
S
N
≥
c
}
p=P_{H_0}\{S_N≥c\}
p=PH0{SN≥c}
同样的,
p
<
α
p<\alpha
p<α时拒绝
H
0
H_0
H0,反之接受
H
0
H_0
H0。
- 习题2.7.(1):对
N
N
N=4时求符号检验统计量
S
N
S_N
SN的零分布。
解:
P H 0 { S N = 0 } = 1 2 0 C 4 0 = 1 16 P_{H_0}\{S_N=0\}=\frac{1}{2^0}C_4^0=\frac{1}{16} PH0{SN=0}=201C40=161
P H 0 { S N = 1 } = 1 2 1 C 4 1 = 4 16 P_{H_0}\{S_N=1\}=\frac{1}{2^1}C_4^1=\frac{4}{16} PH0{SN=1}=211C41=164
P H 0 { S N = 2 } = 1 2 2 C 4 2 = 6 16 P_{H_0}\{S_N=2\}=\frac{1}{2^2}C_4^2=\frac{6}{16} PH0{SN=2}=221C42=166
P H 0 { S N = 3 } = 1 2 3 C 4 3 = 4 16 P_{H_0}\{S_N=3\}=\frac{1}{2^3}C_4^3=\frac{4}{16} PH0{SN=3}=231C43=164
P H 0 { S N = 4 } = 1 2 4 C 4 4 = 1 16 P_{H_0}\{S_N=4\}=\frac{1}{2^4}C_4^4=\frac{1}{16} PH0{SN=4}=241C44=161
Wilcoxon符号秩检验
符号检验中并未考虑差值的大小,Wilcoxon符号秩检验进一步考虑了差异值。
令
N
+
N_+
N+=新方法与对照方法效果度量值之差为正的配对数
对每个差值的绝对值赋予秩,并根据原差值赋予正负号,得到符号秩。
记
S
1
<
S
2
<
⋅
⋅
⋅
S
N
+
S_1<S_2<···S_{N+}
S1<S2<⋅⋅⋅SN+表示为正的秩,为负用
R
R
R表示。
零分布
P
H
0
=
{
V
s
=
v
}
=
#
{
v
;
N
}
2
N
P_{H_0}=\{V_s=v\}=\frac{\#\{v;N\}}{2^N}
PH0={Vs=v}=2N#{v;N},其中n=0,1,···,
N
(
N
+
1
)
2
\frac{N(N+1)}{2}
2N(N+1)
其中,
#
{
v
;
N
}
\#\{v;N\}
#{v;N}表示所有可能出现的
2
N
2^N
2N种符号秩情形中,正号秩之和为
v
v
v的个数。
定义秩和统计量
V
s
=
S
1
+
S
2
+
⋅
⋅
⋅
+
S
N
+
V_s=S_1+S_2+···+S_{N_+}
Vs=S1+S2+⋅⋅⋅+SN+
p
=
P
H
0
{
V
s
≥
c
}
p=P_{H_0}\{V_s≥c\}
p=PH0{Vs≥c}
- 习题2.9:对
N
N
N=4,求Wilcoxon符号秩统计量
V
s
V_s
Vs的零分布。
解:符号秩各种取值情况如下表所示:
| 符号秩 | V s = v s V_s=v_s Vs=vs |
|---|---|
| -1 -2 -3 -4 | 0 |
| -1 -2 -3 4 | 4 |
| -1 -2 3 -4 | 3 |
| -1 2 -3 -4 | 2 |
| 1 -2 -3 -4 | 1 |
| -1 -2 3 4 | 7 |
| -1 2 -3 4 | 6 |
| 1 -2 -3 4 | 5 |
| -1 2 3 -4 | 5 |
| 1 -2 3 -4 | 4 |
| 1 2 -3 -4 | 3 |
| -1 2 3 4 | 9 |
| 1 -2 3 4 | 8 |
| 1 2 -3 4 | 7 |
| 1 2 3 -4 | 6 |
| 1 2 3 4 | 10 |
得 V s V_s Vs零分布:
| V s V_s Vs | P H 0 { V s = v s } P_{H_0}\{V_s=v_s\} PH0{Vs=vs} |
|---|---|
| 0 | 1/16 |
| 1 | 1/16 |
| 2 | 1/16 |
| 3 | 2/16 |
| 4 | 2/16 |
| 5 | 2/16 |
| 6 | 2/16 |
| 7 | 2/16 |
| 8 | 1/16 |
| 9 | 1/16 |
| 10 | 1/16 |

多种处理方法比较
前面都是两种处理方法的比较,现介绍三种及以上处理方法的比较。
Kruskal-Wallis检验
假设
H
0
H_0
H0:各处理方法的效果无显著差异。
令
R
i
+
R_i^+
Ri+表示各组秩和
统计量 K = 12 N ( N + 1 ) ∑ i = 1 s R i + 2 n i − 3 ( N + 1 ) K=\frac{12}{N(N+1)}\sum_{i=1}^s\frac{R_{i+}^2}{n_i}-3(N+1) K=N(N+1)12∑i=1sniRi+2−3(N+1)
p p p由 P H 0 { K ≥ c } P_{H_0}\{K≥c\} PH0{K≥c}确定。
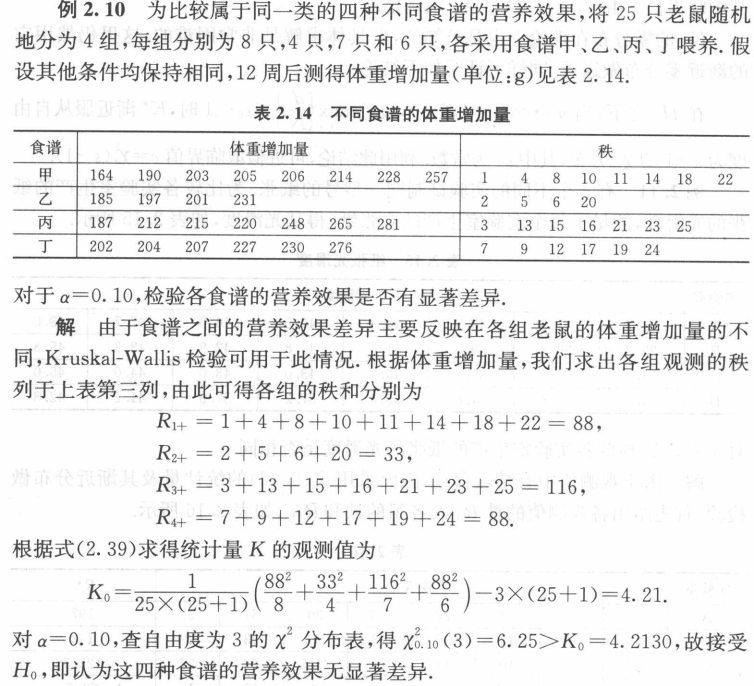
援引书上例子:
分组设计下多种处理方法的比较
即将成对分组应用到多种处理方法中。
令
R
i
j
R_{ij}
Rij表示第
j
j
j组中接受第
i
i
i种方法检验的个体的秩。
各组中
s
s
s个个体随机指定给
s
s
s个方法,即
s
!
s!
s!种分配法。
P
H
0
{
R
11
=
r
11
,
R
s
1
=
r
s
1
,
⋅
⋅
⋅
,
R
1
N
=
r
1
N
,
R
s
N
=
r
s
N
}
=
(
1
s
!
)
N
P_{H_0}\{R_{11}=r_{11},R_{s1}=r_{s1},···,R_{1N}=r_{1N},R_{sN}=r_{sN}\}={(\frac{1}{s!})}^N
PH0{R11=r11,Rs1=rs1,⋅⋅⋅,R1N=r1N,RsN=rsN}=(s!1)N
Friedman检验
设接受第
i
i
i个方法实验的
N
N
N个个体的秩的平均值为
R
i
⋅
R_{i·}
Ri⋅(i=1,2,···,s)
R
i
⋅
=
1
N
(
R
i
1
+
R
i
2
+
⋅
⋅
⋅
+
R
i
N
)
R_{i·}=\frac{1}{N}(R_{i1}+R_{i2}+···+R_{iN})
Ri⋅=N1(Ri1+Ri2+⋅⋅⋅+RiN)
统计量
Q
=
12
N
s
(
s
+
1
)
∑
i
=
1
s
R
i
+
2
−
3
N
(
s
+
1
)
Q=\frac{12}{Ns(s+1)}\sum_{i=1}^sR^2_{i+}-3N(s+1)
Q=Ns(s+1)12∑i=1sRi+2−3N(s+1)
其中
R
i
+
R_i^+
Ri+仍是表示各组秩和
p p p由 P H 0 { Q ≥ c } P_{H_0}\{Q≥c\} PH0{Q≥c}确定。
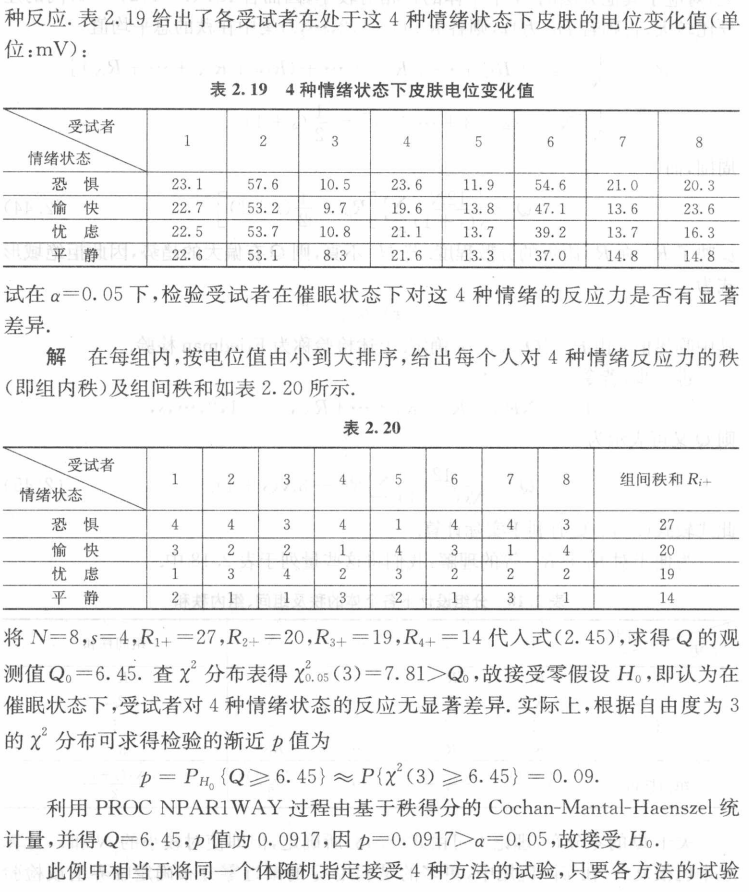
仍援引书上例子(计算量太大了,都是计算机算)
本文主要介绍了非参数秩方法中各种检测方法的原理,其实都有相应的封装可以调用的,比如Python中的Scipy库,下次介绍Scipy中具体编程应用(挖个坑)。
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤