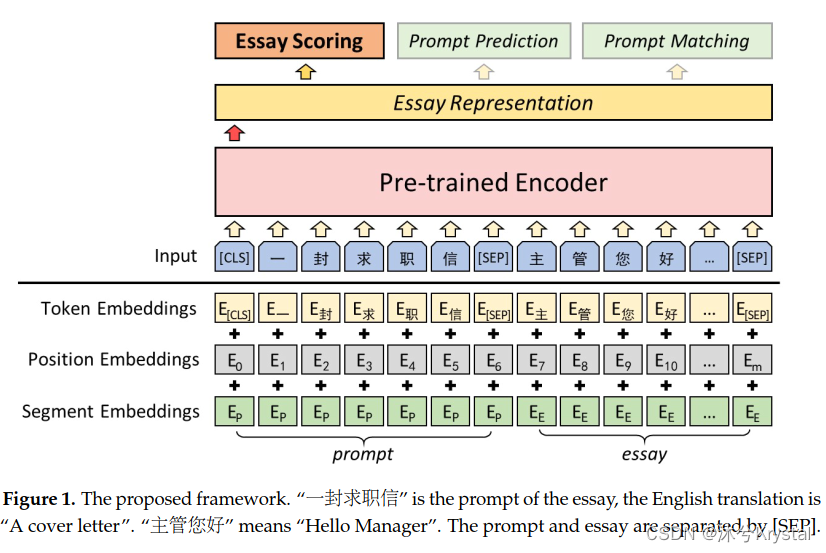
一篇文章的输入表示是加入对应的词嵌入
E
t
o
k
e
n
E_{token}
Etoken,段嵌入(segment)
E
s
e
g
m
e
n
t
E_{segment}
Esegment和位置嵌入
E
p
o
s
i
t
i
o
n
E_{position}
Eposition。为了完全开发prompt的信息,我们把prompt连接在文章的前面。
每个输入的第一个token是特殊的分类token
[
C
L
S
]
[CLS]
[CLS],并且prompt和文章被
[
]
S
E
P
[]SEP
[]SEP分隔开。在第
i
i
i个prompt的第
j
j
j篇文章的token嵌入是:
E
t
o
k
e
n
(
i
)
(
j
)
=
{
E
p
r
o
m
p
t
(
i
)
,
E
e
s
s
a
y
(
i
)
(
j
)
}
E_{token}^{(i)(j)}=\left\{E_{prompt}^{(i)},E_{essay}^{(i)(j)}\right\}
Etoken(i)(j)={Eprompt(i),Eessay(i)(j)}
E
s
e
g
m
e
n
t
E_{segment}
Esegment和
E
p
o
s
i
t
i
o
n
E_{position}
Eposition被从预训练编码器的标注器中获取。
我们使用BERT和NEZHA作为特征提取层。最终的隐藏层对应于
[
C
L
S
]
[CLS]
[CLS]token,也就是文章的表示
r
e
r_e
re,这个文章的表示会被用于文章评分和子任务。
文章评分层
我们将文章评分看作一个回归任务。为了使得数据映射到回归任务,真实的分数被变换范围到区间
[
0
,
1
]
[0,1]
[0,1]来训练,然后重新变换为之前的区间范围在验证的时候。变换的方式:
s
(
i
)
(
j
)
=
s
c
o
r
e
(
i
)
(
j
)
−
m
i
n
(
s
c
o
r
e
(
i
)
)
m
a
x
(
s
c
o
r
e
(
i
)
)
−
m
i
n
(
s
c
o
r
e
(
i
)
)
s^{(i)(j)}=\frac{score^{(i)(j)}-min(score^{(i)})}{max(score^{(i)})-min(score^{(i)})}
s(i)(j)=max(score(i))−min(score(i))score(i)(j)−min(score(i)) 在该公式中,
s
(
i
)
(
j
)
s^{(i)(j)}
s(i)(j)是规约后的第i个prompt和第j篇文章。
来自预训练编码层的文章的表示
r
c
r_c
rc,被馈入一个线性层,采用sigmoid激活函数:
s
^
=
σ
(
W
e
s
⋅
r
e
+
b
e
s
)
\hat{s}=\sigma(W_{es}\cdot{r_e}+b_{es} )
s^=σ(Wes⋅re+bes) 在该公式中,
s
^
\hat{s}
s^是AES系统的预测分数,
σ
\sigma
σ是激活函数。
作文评分系统的训练目标是
l
o
s
s
e
s
(
s
,
s
^
)
=
1
N
∑
k
=
1
N
(
s
k
−
s
k
^
)
2
loss_{es}(s,\hat{s})=\frac{1}{N}\sum_{k=1}^{N}(s^k-\hat{s^k})^2
losses(s,s^)=N1k=1∑N(sk−sk^)2
子任务1:Prompt预测
prompt预测的定义是:给定一篇文章,决定它属于哪个prompt。
我们将prompt预测视为一个分类任务。输入是文章的表示
r
e
r_e
re,它被馈入一个线性层,采用softmax函数。公式是:
u
^
=
s
o
f
t
m
a
x
(
W
p
p
⋅
r
e
+
b
p
p
)
\hat{u}=softmax(W_{pp} \cdot r_e+b_{pp})
u^=softmax(Wpp⋅re+bpp) 在该公式中,
u
^
\hat{u}
u^是分类结果的概率分布,
W
p
p
W_{pp}
Wpp是参数矩阵。
损失函数是:
l
o
s
s
p
p
(
u
,
u
^
)
=
−
1
N
∑
k
=
1
N
∑
c
=
1
C
f
(
u
(
k
)
,
c
)
l
o
g
(
p
p
p
(
k
)
(
c
)
)
loss_{pp}(u,\hat{u})=-\frac{1}{N}\sum_{k=1}^{N}\sum_{c=1}^{C}f(u^{(k)},c)log(p_{pp}^{(k)(c)})
losspp(u,u^)=−N1k=1∑Nc=1∑Cf(u(k),c)log(ppp(k)(c))
f
(
x
,
y
)
=
{
1
,
i
f
x
=
y
0
,
e
l
s
e
x
≠
y
f(x,y)= \begin{cases} 1,&if&x=y\\ 0,&else&x\neq y \end{cases}
f(x,y)={1,0,ifelsex=yx=y 在该公式中,
u
(
k
)
u^{(k)}
u(k)是第k个样本的真实的prompt标签,
p
p
p
(
k
)
(
c
)
p_{pp}^{(k)(c)}
ppp(k)(c)是第k个样本属于类别
c
c
c的概率。
子任务2:Prompt匹配
prompt匹配的定义是给出一个prompt和一篇文章,判断这篇文章和这个prompt是否兼容。我们将prompt匹配问题看作是一个分类任务。
v
^
=
s
o
f
t
m
a
x
(
W
p
m
⋅
r
e
+
b
p
m
)
\hat{v}=softmax(W_{pm} \cdot r_e+b_{pm})
v^=softmax(Wpm⋅re+bpm)
目标函数是:
l
o
s
s
p
m
(
v
,
v
^
)
=
−
1
N
∑
k
=
1
N
∑
m
=
0
M
f
(
v
(
k
)
,
c
)
l
o
g
(
p
p
m
(
k
)
(
m
)
)
loss_{pm}(v,\hat{v}) = -\frac{1}{N}\sum_{k = 1}^{N}\sum_{m = 0}^{M}f(v^{(k)},c)log(p_{pm}^{(k)(m)})
losspm(v,v^)=−N1k=1∑Nm=0∑Mf(v(k),c)log(ppm(k)(m))
v
(
k
)
v^{(k)}
v(k)表明了输入的prompt和文章是否匹配。
m
m
m指明了匹配的程度,0表示匹配,1表示不匹配。
多任务的损失函数
最终对每个输入的损失函数是文章评分和两个子任务的加权和:
l
o
s
s
M
T
L
=
α
⋅
l
o
s
s
e
s
+
β
⋅
l
o
s
s
p
p
+
γ
⋅
l
o
s
s
p
m
loss_{MTL}=\alpha \cdot loss_{es}+\beta \cdot loss_{pp} + \gamma \cdot loss_{pm}
lossMTL=α⋅losses+β⋅losspp+γ⋅losspm
对于主任务,我们使用QWK,来分析预测分数于真实之间的同意度。
W
i
,
j
=
(
i
−
j
)
2
(
N
−
1
)
2
W_{i,j}=\frac{(i-j)^2}{(N-1)^2}
Wi,j=(N−1)2(i−j)2
i
i
i和
j
j
j是人评估的黄金分数和AES系统分数,并且每篇文章由
N
N
N个可能的等级。
Q
W
K
=
1
−
W
i
,
j
O
i
,
j
W
i
,
j
Z
i
,
j
QWK=1-\frac{W_{i,j}O_{i,j}}{W_{i,j}Z_{i,j}}
QWK=1−Wi,jZi,jWi,jOi,j 在该公式中,
O
i
,
j
O_{i,j}
Oi,j表明人类评估等级为
i
i
i,并且AES系统评估等级为
j
j
j的文章个数。