深入理解计算机系统——第五章 Optimizing Program Performance
深入理解计算机系统——第五章 Optimizing Program Performance
- 5.2 Expressing Program Performance
- 5.3 Program Example
- 5.4 Eliminating Loop Inefficiencies
- 5.5 Reducing Procedure Calls
- 5.6 Eliminating Unneeded Memory References
- 5.7 Understanding Modern Processors
- 5.7.1 Overall Operation
- 5.7.2 Functional Unit Performance
- 5.8 Loop Unrolling
- 5.10 Summary of Results for Optimizing Combining Code
- 5.11 Some Limiting Factors
- 5.11.1 Register Spilling
- 5.11.2 Branch Prediction and Misprediction Penalties
- 5.12 Understanding Memory Performance
- 5.14 Identifying and Eliminating Performance Bottlenecks
资源:
视频课程
深入理解计算机系统_第5章 优化程序性能
5.2 Expressing Program Performance
We introduce the metric cycles per element, abbreviated CPE, to express program performance in a way that can guide us in improving the code.
5.3 Program Example
后面的程序示例都是基于下面的优化,程序的一些定义如下:

typedef long data_t;



5.4 Eliminating Loop Inefficiencies
示例:

可以看到 lower2 比 lower1 效率更高,因为 lower1 的循环中每次都要计算 s 的长度。
5.5 Reducing Procedure Calls
示例:


combine3 不用每次循环时都调用 get_vec_start 函数。
5.6 Eliminating Unneeded Memory References
前面 combine3 的循环内的汇编代码如下:

可以看见每次循环都有读写内存的步骤,但实际没有必要的,只用在循环结束后将数据写到内存中即可,因此做如下修改:

其循环内的汇编代码如下:

combine3 编译器在每次循环都要读写数据数据因为考虑到可能会有 memory aliasing 的情况。
Aliasing: two different memory references specify single location.
Easy to have happen in C:
1. since allowed to do address arithmetic
2. Direct access to storage structures
解决方案:
1. Get in habit of introducing local variables;
2. Your way of telling compiler not to check for aliasing
5.7 Understanding Modern Processors
The latency bound : a series of operations must be performed in strict sequence, because the result of one operation is required before the next one can begin.
延迟界限:一系列的指令有依赖关系,必须按照严格的顺序执行。
The throughput bound: characterizes the raw computing capacity of the processor’s functional units. This bound becomes the ultimate limit on program performance.
吞吐量限制:基于硬件的数量和性能,功能单元的原始计算能力。该限制是程序能优化的极限,
5.7.1 Overall Operation
Figure 5.11 shows a very simplified view of a modern microprocessor.

These processors are described in the industry as being superscalar, which means they can perform multiple operations on every clock cycle and out of order, meaning that the order in which instructions execute need not correspond to their ordering in the machine-level program. (需要指令之间独立)
图 5.11 处理器两个部分:
- Instruction control unit (ICU): Reading a sequence of instructions from memory and generating from these a set of primitive operations to perform on program data.
- Execution unit (EU): Executes these operations.
优点:They are better at achieving higher degrees of instruction-level parallelism.
The ICU reads the instructions from an instruction cache—a special high-speed memory containing the most recently accessed instructions.
In general, the ICU fetches well ahead of the currently executing instructions, so that it has enough time to decode these and send operations down to the EU.
存在的问题:
遇到分支时进行分支预测(前面讲过),在执行前已经对预测的分支进行取指和译码的操作,如果预测错误,则需要重新取指令和译码。
如果有分支预测,那最后的在确定分支是否正确前不会存到程序寄存器或内存中。
load 单元:从内存中读数据到处理器。
store 单元:将处理器中的数据写入到内存,并且能计算地址。
从图 5.11 可以看出,load 和 store 两个单元通过 data catch 来读写内存,该单元是包含最近使用的数据的高速内存。
Figure 5.11 indicates that the different functional units are designed to perform different operations.
arithmetic operations: 执行整型和浮点数不同组合的操作。
The arithmetic units are intentionally designed to be able to perform a variety of different operations, since the required operations vary widely across different programs.
For example, our Intel Core i7 Haswell reference machine has eight functional units, numbered 0–7. Here is a partial list of each one’s capabilities:

In the above list, “integer arithmetic” refers to basic operations, such as addition, bitwise operations, and shifting.
Multiplication and division require more specialized resources.
store 操作需要两个function units,一个计算存储地址,另一个存储数据。
We can see that this combination of functional units has the potential to perform multiple operations of the same type simultaneously.
Within the ICU, the retirement unit keeps track of the ongoing processing and makes sure that it obeys the sequential semantics of the machine-level program.
Our figure shows a register file containing the integer, floating-point, and, more recently, SSE and AVX registers as part of the retirement unit, because this unit controls the updating of these registers.
指令被译码时,信息存在队列中(先入先出)。
这些在分支预测结果出现前一直存在队列中。
如果分支预测成功,那么已经执行的预测的指令就可以退役(retired),并更新程序寄存器。
如果分支预测错误,执行的错误的指令将被清空(flushed),并丢弃已经计算的结果,因此不会修改程序状态。
程序寄存器(program registers)只会在指令退役后更新。
执行单元的不同部分能直接传输结果(Operation results)。
The most common mechanism for controlling the communication of operands among the execution units is called register renaming.
对于每个寄存器,通常有几百个寄存器的副本,用于存储需要更新到实际寄存器的值。
当一个更新寄存器 r 的指令被译码后,用标签 t 表示该操作的结果。
An entry (r, t) is added to a table maintaining the association between program register r and tag t for an operation that will update this register.
When a subsequent instruction using register r as an operand is decoded, the operation sent to the execution unit will contain t as the source for the operand value.
When some execution unit completes the first operation, it generates a result (v, t), indicating that the operation with tag t produced value v.
Any operation waiting for t as a source will then use v as the source value, a form of data forwarding.
By this mechanism, values can be forwarded directly from one operation to another, rather than being written to and read from the register file, enabling the second operation to begin as soon as the first has completed.
The renaming table only contains entries for registers having pending write operations.
With register renaming, an entire sequence of operations can be performed speculatively, even though the registers are updated only after the processor is certain of the branch outcomes.
5.7.2 Functional Unit Performance
latency : The total time required to perform the operation.
延迟:一个指令执行需要的时间。
issue time : The minimum number of clock cycles between two independent operations of the same type.
(Cycle/Issue:由于流水线(pipelining)操作,两条指令之间的时间。)
capacity : The number of functional units capable of performing that operation.
5.8 Loop Unrolling
Loop unrolling is a program transformation that reduces the number of iterations for a loop by increasing the number of elements computed on each iteration.
在循环中一次计算多个值而非一个值。
示例:

采用 Loop Unrolling 后改进的 combine5:

改进后的代码每次循环中计算两个数,这里还需要第二的循环处理剩下的数,例如元素的个数为5个时,第一个循环只处理4个数,因此第二个循环处理第5个数。
改进后效果如下:
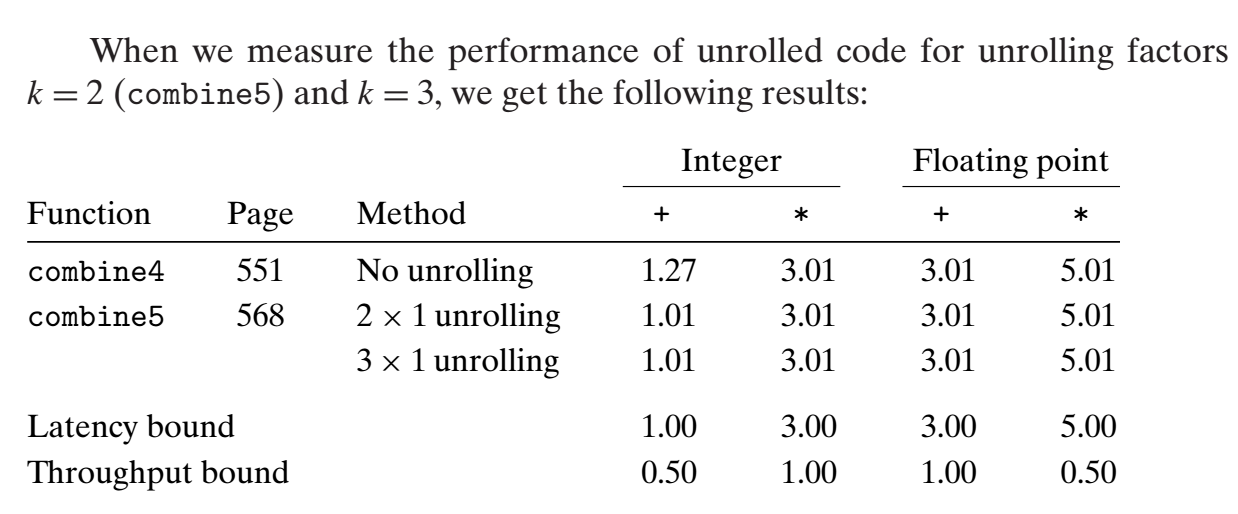
当循环内做2次展开时,对于整数的加法操作有改进(OP 为 +,IDENT 为 0),其他无改进,因为该代码还是需要顺序执行,即一条指令执行完成后才执行下一条,指令之间不是独立的(先计算 acc OP data[i],得到结果后再将结果 OP data[i+1])。
继续优化:
将 acc = (acc OP data[i]) OP data[i+1]; 改为 acc = acc OP (data[i] OP data[i+1]); ,即改变括号的位置,其性能如下(优化后代码为 combine7):
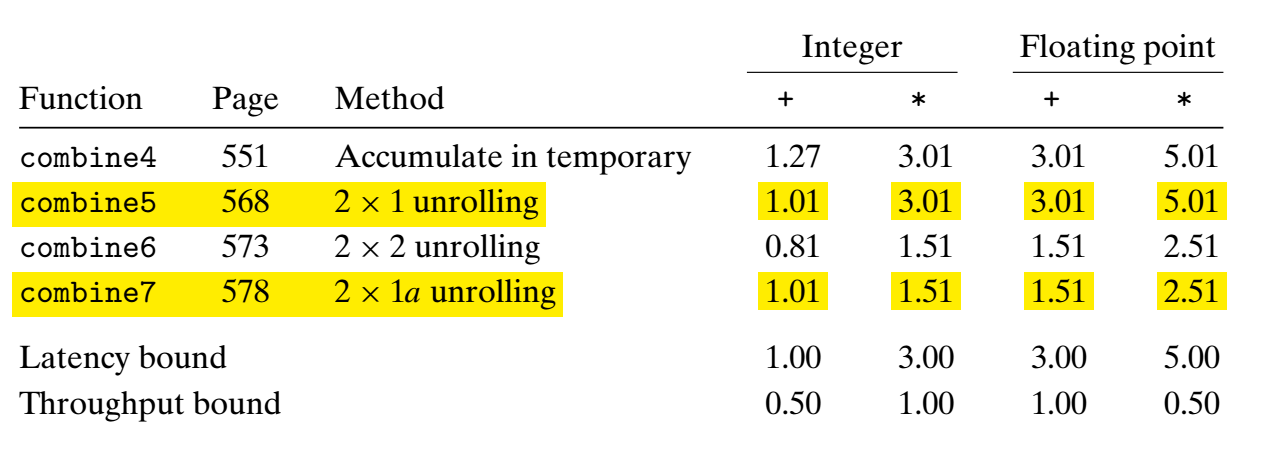
和 combine5 对比可以看见换了括号的位置后整数的乘法和浮点数的操作时间减少几乎一半。
原因:指令之间变得独立了,当一条指令执行 data[0] OP data[1] 时,下一条指令可以提前计算 data[2] OP data[3] 。
存在的问题:对于整数的加法和乘法满足结合率和交换率,这样改变括号的位置对计算结果无影响;但对于浮点数,并不满足结合率,改变括号的位置后可能会出现舍入,甚至溢出的情况,其结果可能和改变括号前不同。
浮点数乘法操作吞吐量为 0.5,因为有两个浮点乘法器。
进一步优化:分别计算两组元素的加法或者积:

combine6 将计算分成两组,索引为偶数的组合在一起计算,索引为奇数的组合为一组计算,其性能如下:
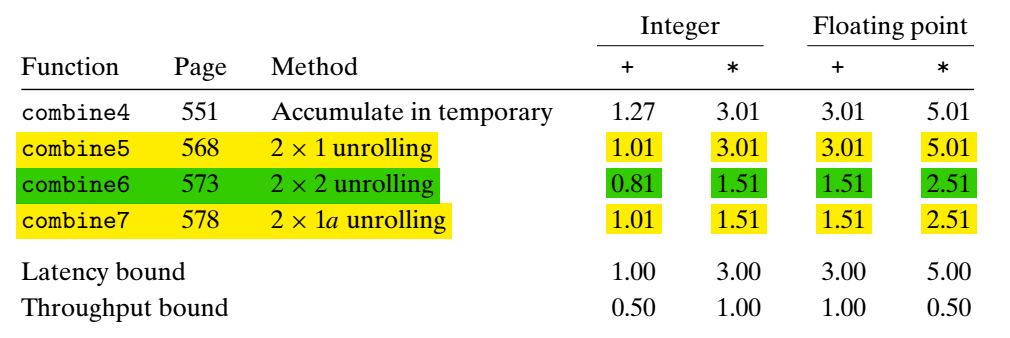
与 combine 7 相比,整数的加法时间减少了。
5.10 Summary of Results for Optimizing Combining Code
继续优化,增大展开的数目(combine6 为 2*2,即一个循环中计算两个数,分成两组计算),让延迟界限尽量接近吞吐量界限:
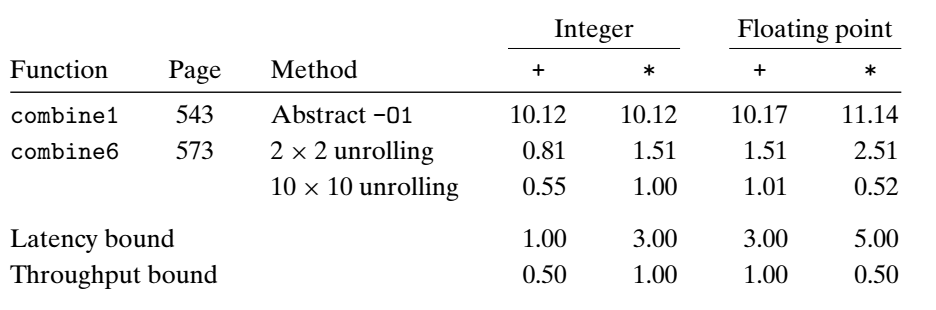
可以看见 10 * 10时,比 2*2 进一步优化了。
5.11 Some Limiting Factors
5.11.1 Register Spilling
可以通过增加循环内计算的数量来优化性能,且级数越大执行时间越短,但这也存在上限,受寄存器的数目的限制,如果寄存器的数目不够用,则编译器会将部分数据存在内存中,通常在栈中,因而导致时间反而更长(内存访问速度低于寄存器),见下图:

可以看见 20 * 20 展开时时间反而比 10 * 10 长。
Fortunately, x86-64 has enough registers that most loops will become throughput limited before this occurs.
5.11.2 Branch Prediction and Misprediction Penalties
对于需要进行分支预测的情况,指令控制单元必须在指令执行单元之前完成,执行指令执行单元时,必须保证该指令是正确的分支(前面讲过)以保证不会影响程序,如果预测错误,则需要回到分支预测的地方,执行正确的分支,重新取指和译码,最后才能进入执行阶段。
分支预测错误也不会对程序有影响,因为分支预测时对无效指令的操作只修改寄存器的值,而每个寄存器都有很多副本,每一次计算的结果都依次保留在寄存器副本中,因此预测错误时,只需要取消寄存器中那些错误的更新并将正确的值返回寄存器中(前面说过的寄存器重命名,即 register renaming)。
5.12 Understanding Memory Performance
All modern processors contain one or more cache memories to provide fast access to such small amounts of memory.
第六章会详细介绍
5.14 Identifying and Eliminating Performance Bottlenecks
本章主要介绍通过工具进行程序剖析(code profilers) 来分析程序的性能,可以查看不同部分花费的时间等来分析代码从而优化程序。