【C++】C++11的那些新特性
本篇博客,让我们一起来看看C++11的那些新特性!
所使用的编译器:VS2019
本篇博客所有的测试源码都可以在我的GITEE仓库找到
文章目录
- 1.前言
- 2.列表`{}`初始化
- 2.1 new初始化多个数据
- 2.2 initializer_list
- 2.2.1 STL容器初始化
- 2.2.2 initializer_list 容器
- 2.3.1 插入il
- 2.4 模拟实现il构造函数
- 3.变量声明
- 3.1 auto
- 3.2 decltype
- 3.3 typeid
- 4.左/右值引用
- 4.1 左值/右值区别
- 4.1.1 将亡值(概念)
- 4.2 左值引用
- 4.3 右值引用
- 4.4 两个引用的区别
- 4.4.1 move
- 4.5 右值引用使用场景
- 4.5.1 输出型参数
- 4.5.2 右值引用 移动构造
- STL_string
- MY_string
- 移动构造直接移动资源
- STL的更新
- 4.6 编译器优化
- 4.7 优化插入效率
- 5.完美转发
- 5.1 使用场景
- 6.新增的默认成员函数
- 6.1 关键字default
- 7.可变模板参数
- 7.1 递归解参数包
- 错误解法
- 7.2 数组解包
- 7.3 emplace_back
- 8.lambda表达式
- 8.1 情景描述
- 8.2 lambda出场
- 8.3 基本使用
- 8.4 捕捉列表和mutable
- mutable
- 8.5 捕获的几种方式
- 8.5.1 全捕获=
- 8.5.2 引用全捕或
- 8.5.3 全捕获+单独操作
- 8.6 最终呈现
- 8.7 lambda底层:仿函数
- 9.包装器function
- 9.1 基本使用
- 引用类中非static成员
- 9.2 特殊场景的作用
- 9.3 改造逆波兰表达式OJ
- 10.bind绑定
- 10.1 使用
- 10.2 占位符placeholders
- 结语
1.前言
C++11是C++的标准委员会在2011年更新的C++新特性。说白了就是一个升级包。和JAVA\PYTHON这种更新比较频繁的语言相比,C++更新的就没有那么顺风顺水了,而且每一次更新虽然修复了一些问题,但也带来了更多的“没太大必要”的更新
比如没啥用的
array容器,和int arr[10]这种内置方式的区别主要在于越界检查
不过咱们这种小菜鸡,只有学习的权力,哪有啥资格评定C++标准呢?我听大佬说,现在最关注的C++更新便是网络库的上线了,不过那个貌似得等到C++23去了
话不多说,让我们来康康一些C++11的新功能吧!
2.列表{}初始化
C++11更新了初始化方式,不管是什么类型的数据,我们都可以用花括号的方式进行初始化
struct TestA{
int _a;
int _b;
};
void TestInit()
{
int arr1[] = { 1,2,3,4,5 };
TestA t1 = { 1,2 };
}
之前我们已经习惯于用这张方式来初始化数组或者结构体,这在C++98中已经支持
而C++11则在这种玩法之上,又增添了一部分新操作,那就是直接用花括号初始化,你甚至可以把=给省略了
int arr2[]{ 1,2,3,4,5 };
int arr3[5]{ 0 };
TestA t2{ 1,2 };
不过上面这种写法没有什么意义,还增加了代码理解的难度,不如直接用原本的写法。
更多时候,我们是在new初始化多个数据的时候使用这种方式。
2.1 new初始化多个数据
在动态内存管理那一章节,我们学习了new的两种使用方式,也提到了()/[]这两个括号的区别
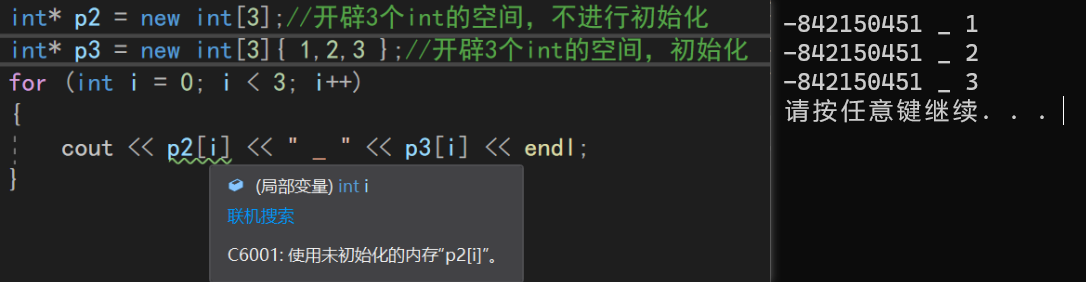
int *p1 = new int(3);//开辟一个int的空间,并初始化为3赋值给p1
int *p2 = new int[3];//开辟3个int的空间,不进行初始化
在C++11中,我们可以直接用花括号,对new开拼出来的数组进行批量初始化。打印的时候,可以看到p2中的数据都是没有进行初始化(vs也报了警告)而p3中的数据都完成了初始化
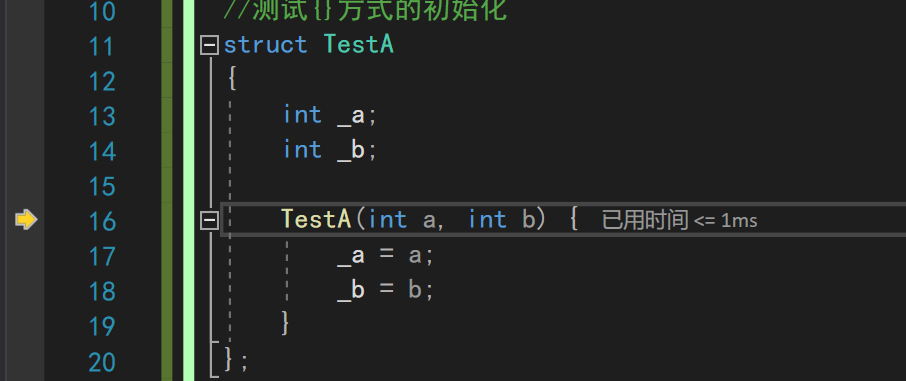
对于结构体数据而言,我们可以用花括号直接调用其构造函数

其中t5是发生了隐式类型转换+调用构造函数进行的初始化
TestA t5 = { 1, 3 };//对类来说,会进行隐式类型转换+调用构造函数
通过调试+打断点可以看到其调用了构造函数进行初始化
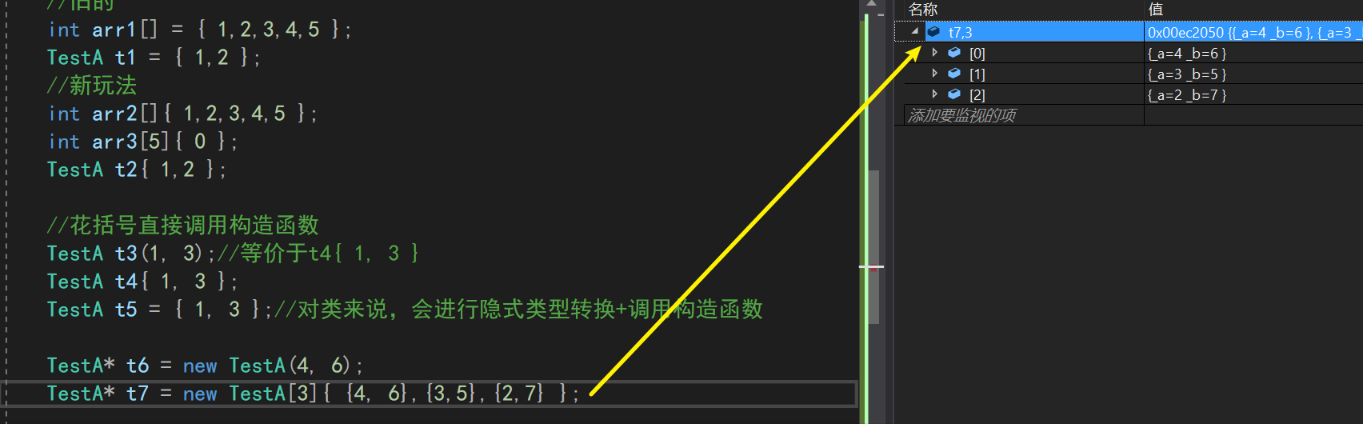
同样的,调用new的时候,我们可以用多个花括号的方式进行批量初始化。这在new一个对象数组的时候非常方便
2.2 initializer_list
2.2.1 STL容器初始化
不光是我们自己写的类、内置类型可以使用这种方式进行初始化,stl库里面的容器也可以使用相同方式进行初始化
vector<int> v1 = { 1,2,3,4 };
vector<int> v2{ 1,2,3,4 };//不建议这么写
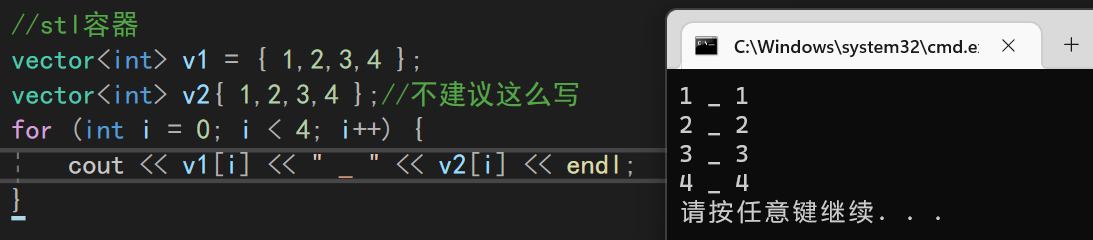
同样的,我们还可以用类似的方式初始化vector内部的对象
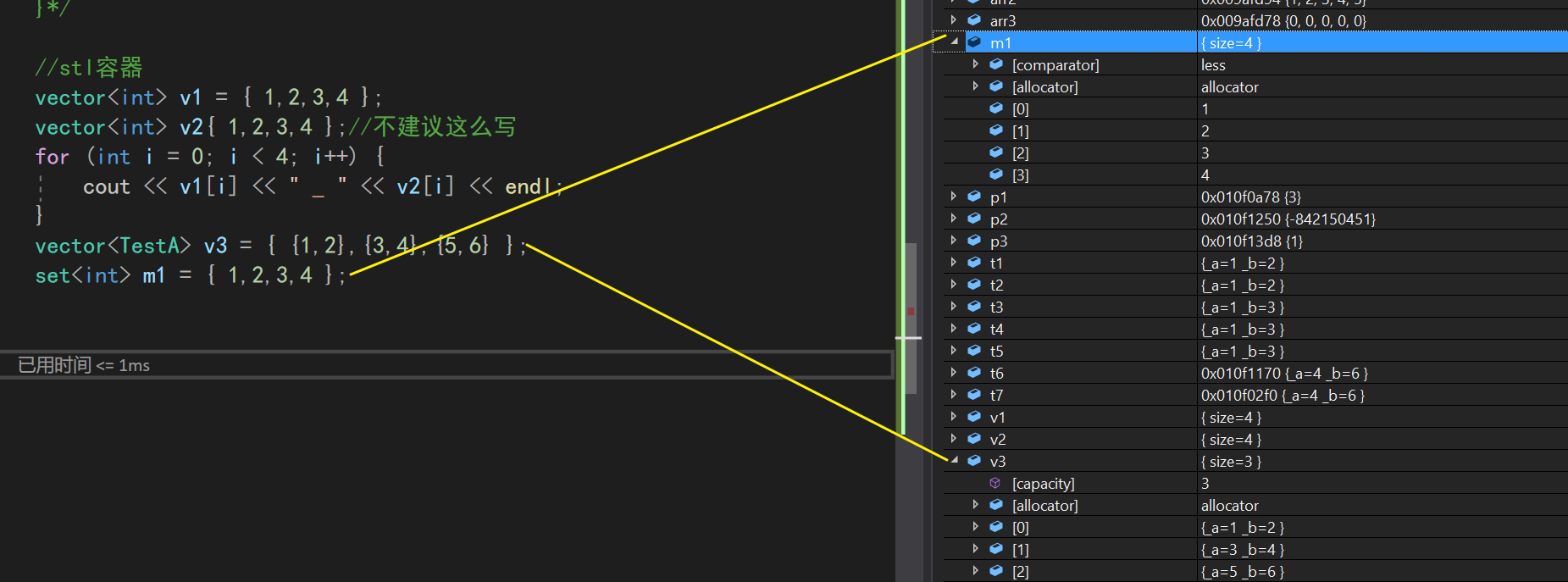
作为容器的一份子,map也有一个利用il进行初始化的构造函数
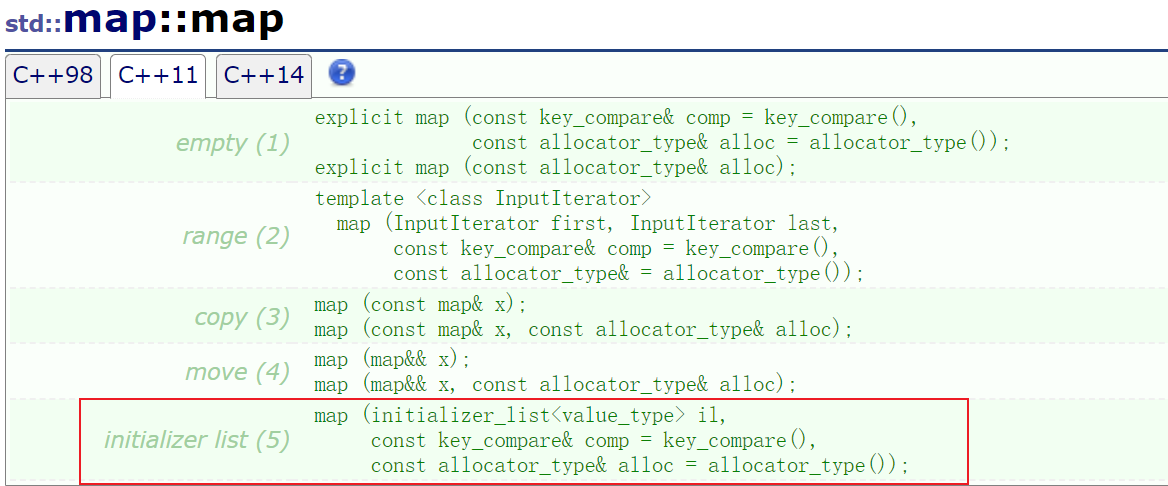
使用方式和之前提到的没啥区别,这里就不多讲啦
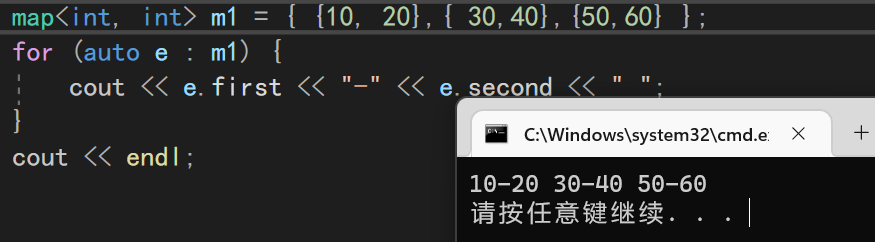
map<int, int> m1 = { {10, 20},{ 30,40},{50,60} };
for (auto e : m1) {
cout << e.first << "-" << e.second << " ";
}
cout << endl;
你可能会好奇,这种初始化的底层是怎么实现的?那么就要提到c++11新增的一个容器了
2.2.2 initializer_list 容器
如果你把vector等容器的版本设定为C++11,看文档的时候便会发现C++11新增了一个用initializer_list进行初始化的操作
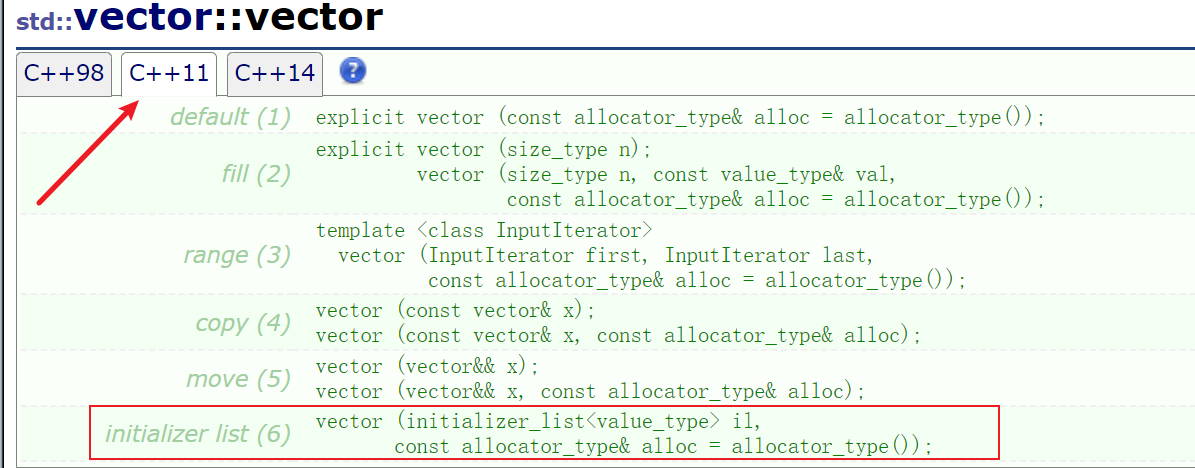

再来看看initializer_list,这不就是我们刚刚用的花括号嘛?
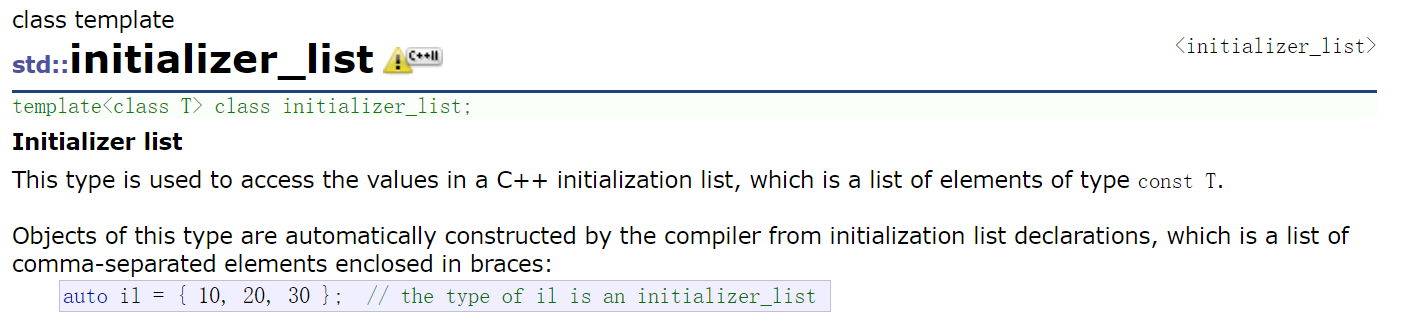
这个容器的成员函数很少,只有两个迭代器以及size()

它最重要的特性,便是当我们使用auto自动推到参数类型的时候,{1,2,3,4}这种类型会被推到成initializer_list
auto il = { 10, 20, 30 };
cout << typeid(il).name() << endl;//initializer_list
因为他有迭代器,所以我们也可以使用范围for进行打印操作
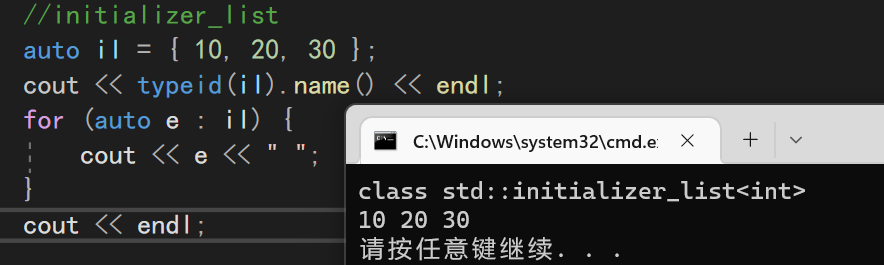
个人理解,当其他容器使用initializer_list进行初始化的时候,本质上调用的接口和利用迭代器进行初始化是一样的
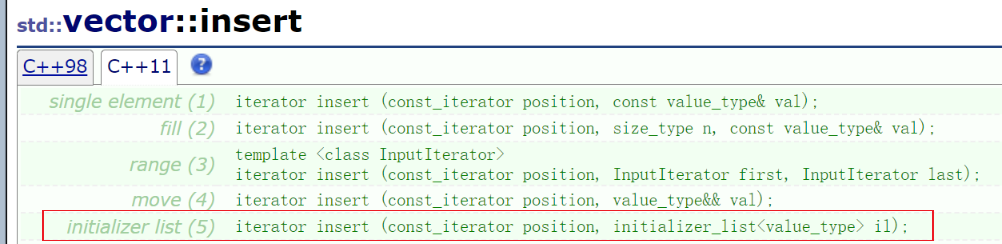
2.3.1 插入il
部分容器的insert函数也添加了使用il进行插入连续数据的操作
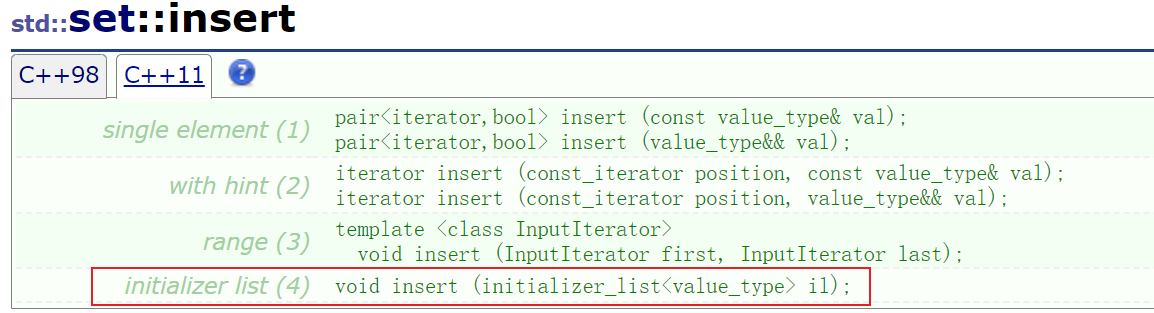
set<int> s2 = { 1,2,3,4 };
s2.insert({ 5,6,7,8 });
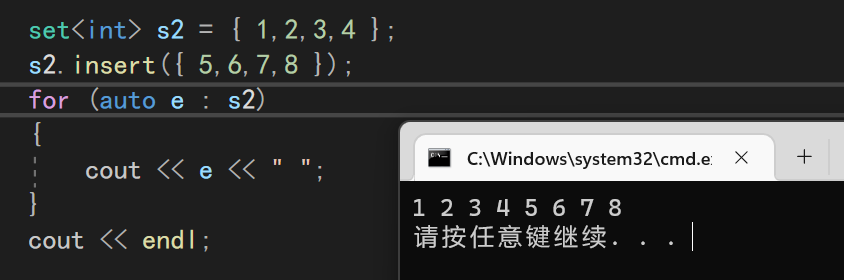
在vector中使用il插入的时候,需要指定pos位置这个和vector的其他几个插入函数是一样的
2.4 模拟实现il构造函数
那么,如何让我们自己模拟实现的vector也能支持这个功能呢?【模拟实现vector源码】
和STL库里面的代码一样,添加上initializer_list的构造函数即可
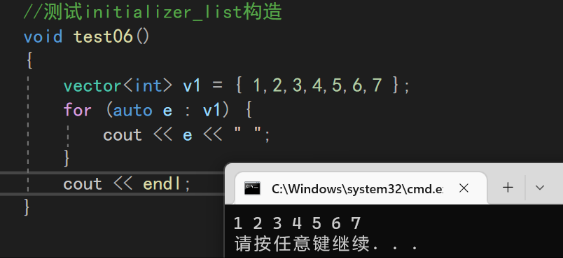
因为il容器已经有了它自己的迭代器,我们完全可以复用迭代器构造的操作,直接进行遍历然后push_back即可!
//initializer_list构造
vector(const initializer_list<T>& il)
:_start(nullptr),
_finish(nullptr),
_endofstorage(nullptr)
{
for (auto e : il) {
push_back(e);
}
}
试试自定义类型,也可以很好的支持!

这里还有一个优化的地方,那便是开始构造的时候,直接给vector开对应il size()的空间大小,避免后续push_back的时候需要多次扩容
//initializer_list构造
vector(const initializer_list<T>& il)
:_start(nullptr),
_finish(nullptr),
_endofstorage(nullptr)
{
reserve(il.size());//扩容
for (auto e : il) {
push_back(e);
}
}
通过调试能发现达成了我们的需求(因为调试步骤太多,截图不方便,这里就不演示了。感兴趣的老哥可以去我的gitee仓库下源码自己试试)
3.变量声明
C++11提供了多种简化的声明/定义方式,比如我们熟悉的auto
3.1 auto
C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局 部的变量默认就是自动存储类型,所以auto就没什么价值了。
C++11给auto上了实现自动类型推断的全新功能,方便我们在定义一个变量的时候直接用auto进行类型推导
auto num = 1;//int
auto p = #//int*
需要注意的是,如果想用auto推到,则必须初始化。只给一个auto i是不行的!
auto还可以用于范围for等其他操作,这些都在之前讲解这个关键字的博客中有提到,这里就不多说了!
3.2 decltype
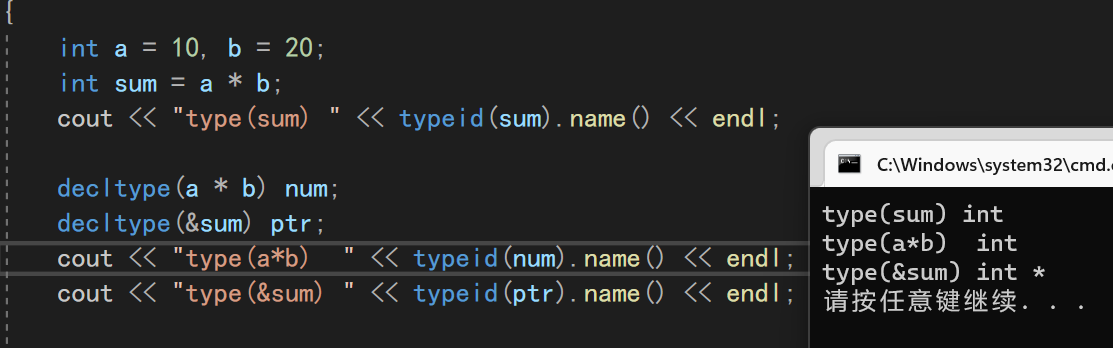
关键字decltype可以把变量声明成我们想要的目标类型
int a = 10, b = 20;
int sum = a * b;
cout << "type(sum) " << typeid(sum).name() << endl;
decltype(a * b) num;
decltype(&sum) ptr;
cout << "type(a*b) " << typeid(num).name() << endl;
cout << "type(&sum) " << typeid(ptr).name() << endl;
怎么样,是不是觉得很神奇?很方便?
那让我们来看看另外一个语言声明变量的方式吧!😂
# Python
a=10
sum = a*20
print(type(a))
print(type(sum))

要是C++也有这么方便就好了😭
3.3 typeid
这个关键字上面已经用过好几次了,就是用来打印变量的类型的
int a = 10;
cout << "type(a) " << typeid(a).name() << endl;
4.左/右值引用
在之前我们学习了引用的基本操作,但那个是左值引用。当时我们尚未引入左指引用和右值引用的区别。本篇博客里面将会详细讲解~
4.1 左值/右值区别
要解答这两种引用的区别,首先我们需要直到左值/右值分别代指什么
左值:
- 可以存在于
=左边或右边 - 可以取地址
- 可以对它赋值(const除外)
右值:
- 右值是一个表示数据的表达式,比如:函数返回值
[不能是左值引用返回的]、表达式返回值A+B、字面常量10 - 右指只能出现在
=的右边,不能出现在左边(俺可没见过A+B=C的代码语法) - 右指不能取地址
左值和右值最大的区别便是:左值可以取地址,右值不能取地址
4.1.1 将亡值(概念)
右值还分为两种情况:
//纯右值
10;
a+b;
Add(a,b);
//将亡值
string s1("1111");//"1111"是将亡值
string s2 = to_string(1234);//to_string的return对象是一个将亡值
string s3 = s1+"hello" //相加重载的return对象是一个将亡值
move(s1);//被move之后的s1也是将亡值
在右值引用的介绍中将用上将亡值的概念
4.2 左值引用
左值引用就是对左值的引用。我们之前学习的就是这一类型
// a、b、c、*a都是左值
// 对象内部的*this也是左值
int* a = new int(0);
int b = 1;
const int c = 2;
// 以下是对上面左值的 左值引用
int*& rp = a;
int& rb = b;
const int& rc = c;
int& p = *a;
// 引用相当于别名,修改引用后的内容相等于修改原本的参数
之前也提到了,其作用主要是在针对出了作用域不会销毁的变量进行引用返回,以节省拷贝的代价。亦或者是引用传参,减少形参拷贝代价
4.3 右值引用
来看看几个比较常见的右值吧,其中Add是一个简单的相加函数
double x = 1.1, y = 2.2;
// 常见的右值
10;
x + y;
Add(x, y);
// 以下都是对右值的右值引用
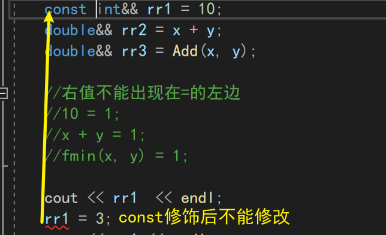
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = Add(x, y);
//右值不能出现在=的左边
//10 = 1;
//x + y = 1;
//fmin(x, y) = 1;
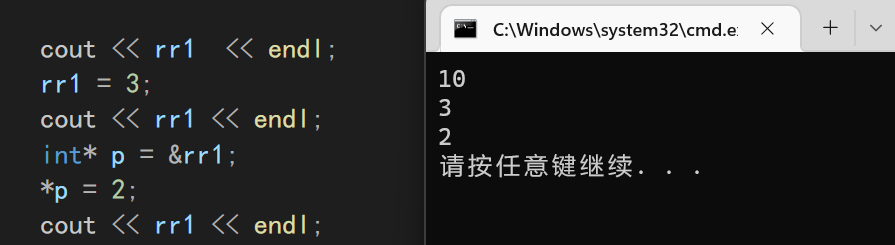
虽然我们不能直接对右值进行取地址/赋值操作,但是在右值引用过后,便可以对引用值进行取地址/赋值操作
这是因为右值引用的时候,会把当前引用的数据放入一个位置存起来。
存放位置:普通变量在
栈,全局变量/静态变量在静态区(没有验证过,可能不对)
int&& rr1 = 10;
cout << rr1 << endl;
rr1 = 3;
cout << rr1 << endl;
int* p = &rr1;
*p = 2;
cout << rr1 << endl;
如果你不喜欢右值引用被修改,则可以使用const进行修饰
4.4 两个引用的区别
用一个表格来总结二者的区别
| 左值引用 | 右值引用 |
|---|---|
| 只能引用左值 | 只能引用右指 |
| const可以引用左值/右值 | 可以引用move后的左值 |
4.4.1 move
move可以把左值换成右值,但不能把右值转左值
谨慎使用
move,如果当前对象在后续还需要使用,则不能move将其改为右值,否则可能资源被掠夺导致该对象失效!

4.5 右值引用使用场景
右值引用可以提高移动构造/移动赋值等深拷贝场景的效率
什么场景可以使用左值引用提高效率?
- 操作符重载:前置++
- 操作符重载:
+= - 出了作用域后不会销毁的变量,如输出型参数(即传入函数进行处理的参数)
而有一些场景是左值引用无法处理的:
- 操作符重载:后置++(需要返回一个全新变量)
- 操作符重载:
+(需要返回一个全新变量) - 模拟实现string中的
to_string函数
这些场景大多有一个特性,那就是会生成一个全新的变量(对象)其对象生命周期出了函数作用域便会销毁(将亡值)
如果使用左值引用返回,就会出现访问已经销毁了的对象的错误。
假设我们有一个
vector<vector<int>>,若内部的vector很大的时候,拷贝构造的代价是很大的!
4.5.1 输出型参数
如果在C++98的情况下,我们只能用输出型参数来解决这个问题
vector<vector<int>>& test(vector<vector<int>>&v1,int val)
{
//……
//v1就是一个输出型参数。放入该函数进行操作后原路返回
return v1;
}
4.5.2 右值引用 移动构造
在C++11中,我们可以使用右值引用的拷贝构造来解决这个问题
下方就是一个具体示例
muxue::string to_string(int val)
{
bool flag = true;
if (val < 0){
flag = false;
val = 0 - val;
}
muxue::string str;
while (val > 0){
int x = val % 10;
val /= 10;
str += ('0' + x);
}
if (flag == false){
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
在默认情况下,如果想使用这个to_string函数,就需要进行深拷贝进行传值返回。这是无可避免的代价
如果使用左值引用返回,这里就会有bug。因为出了函数作用域后,临时对象str会被销毁。而如果我们使用左值引用取别名,在进行赋值的时候,便会出现利用str的别名进行拷贝构造,而str是一个已经销毁的对象的问题
而如果我们使用右值引用返回,则不会出现这种问题。前提是我们自己实现了右值引用的构造函数和赋值重载
一般我们把右值引用的构造函数/赋值重载称作
移动构造/移动赋值
为什么叫移动呢?因为右值引用是会直接拿取对象的资源
STL_string
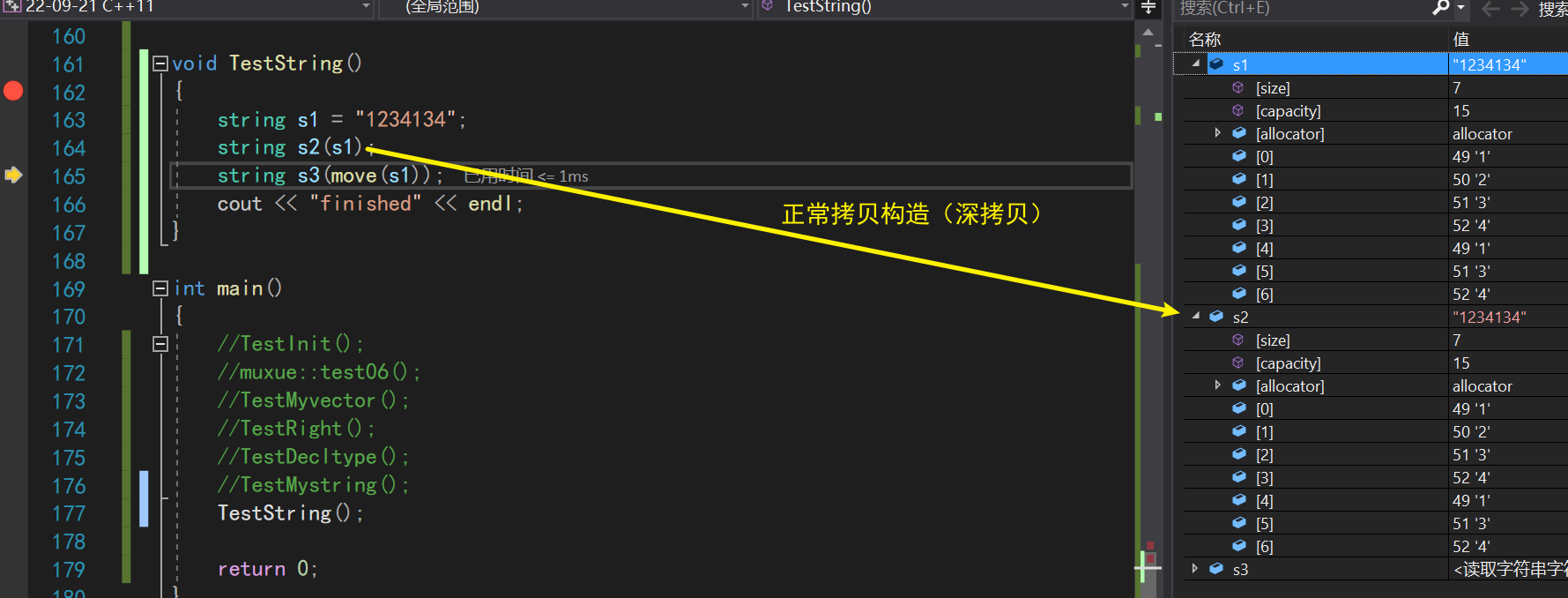
我们可以先用库里面的string观察一下,当我们使用move之后的右值进行构造的时候,会直接拿掉对象的资源!
string s1 = "1234134";
string s2(s1);
string s3(move(s1));
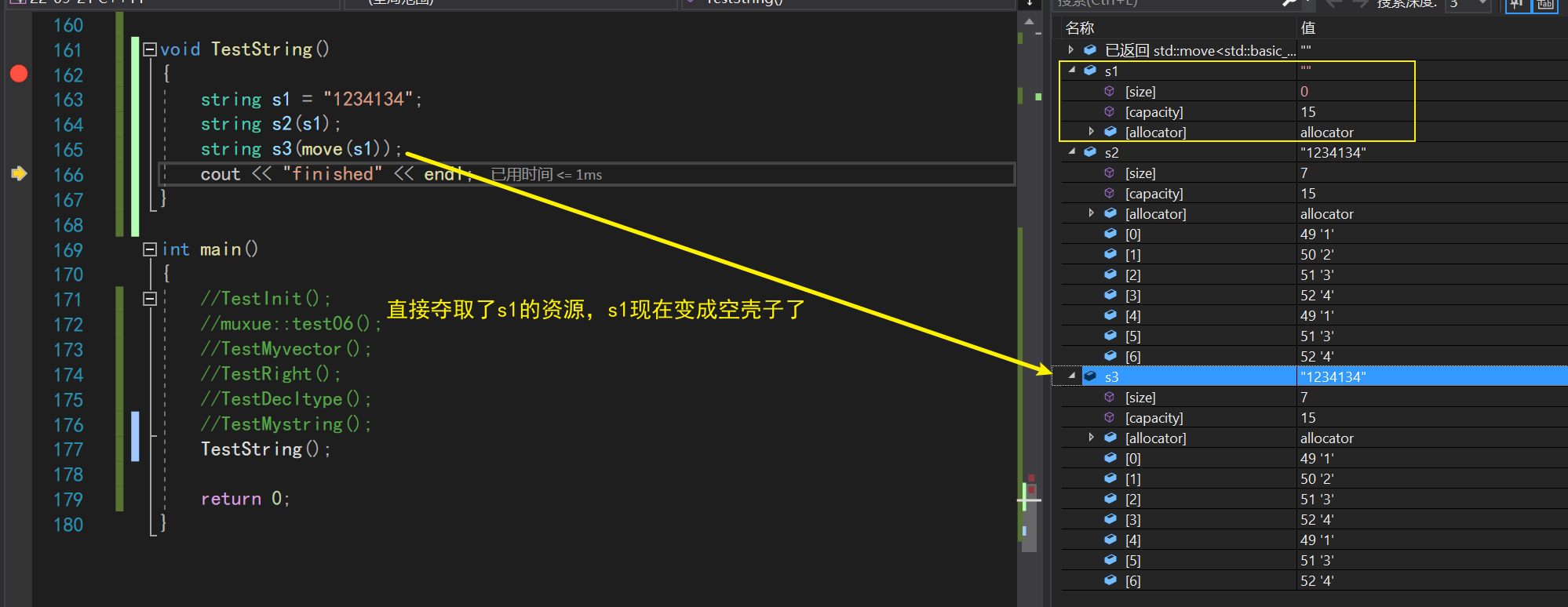
而在使用右值进行返回的时候,编译器会进行一波优化,直接使用移动构造拿取资源,避免多次拷贝构造造成的空间和时间损失
在处理这种问题的时候,就比输出型参数好太多了。
MY_string
不过库里面的string涉及到了buf之类的高级操作,也不适合我们调试查看调用的具体情况。所以这里我们再使用自己写的string来演示一下
这里我还发现了之前模拟实现string的一个bug,在
push_back操作的时候,没有给末尾加上\0,导致析构的时候报错了
- 模拟实现string代码见我的gitee仓库【传送门】
在演示之前,我们先要实现自己的移动构造/移动赋值
//移动赋值
string& operator=(string&& s){
swap(s);
return *this;
}
//移动拷贝
string(string&& s)
:_a(nullptr),
_size(0),
_capa(0)
{
swap(s);
}
这里我直接复用了之前已经写好的一个swap函数,实现了一个“现代写法”的构造,直接交换了二者的资源。避免深拷贝带来的副作用
接下来用下面的几个来测试一下拷贝构造的操作
muxue::string s1 = "1234";
muxue::string s2(s1);//拷贝构造
muxue::string s3 = muxue::to_string(5678);//移动构造
muxue::string s4 = s1 + s3;//拷贝构造+移动构造
通过在构造函数中添加打印,可以看出这几个分别调用了什么构造函数
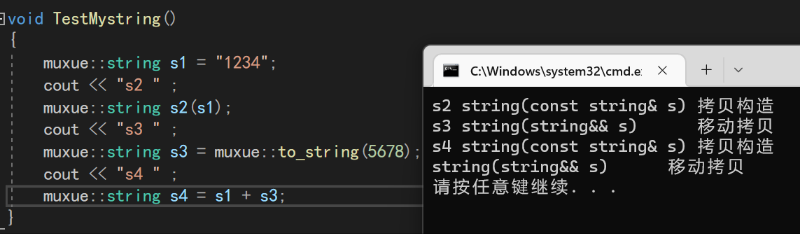
- s2调用了深拷贝构造,因为s1是一个左值
- s3调用了移动构造,因为
to_string函数中return的是一个将亡值 - s4先是在
运算符+重载中调用深拷贝构建了一个string的临时对象,在使用移动构造进行return
运算符+重载的代码如下,和to_string一样,都是return了一个将亡值
//相加重载
string operator+(const string& s)
{
muxue::string tmp(*this);
tmp += s;
return tmp;
}
将一个对象move成为右值之后,便可以使用移动赋值

移动构造直接移动资源
这时候如果调用拷贝构造,就很是浪费:
- 本来tmp的资源就要销毁了,你还得先把他的资源复制一份给自己,再销毁tmp
- 那为何不把tmp的资源直接拿给自己呢?省去了复制的消耗!
这便是移动构造的优势之处!
调试体现出来的,便是深拷贝中两个对象_a的地址完全不同
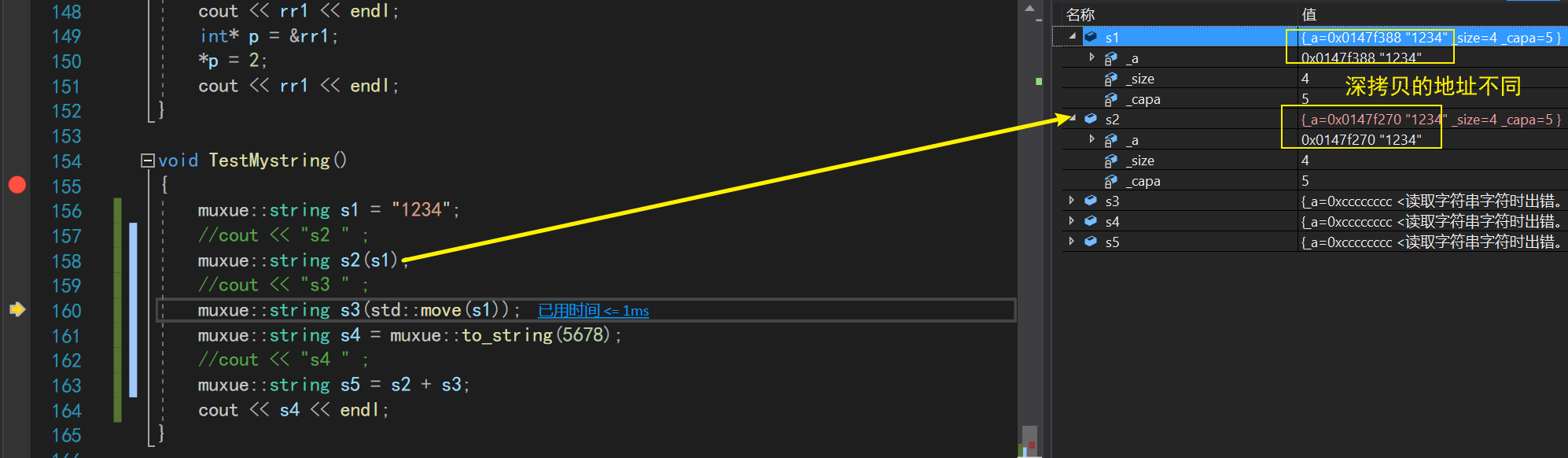
而移动构造是直接把s1的_a资源拿了过来!
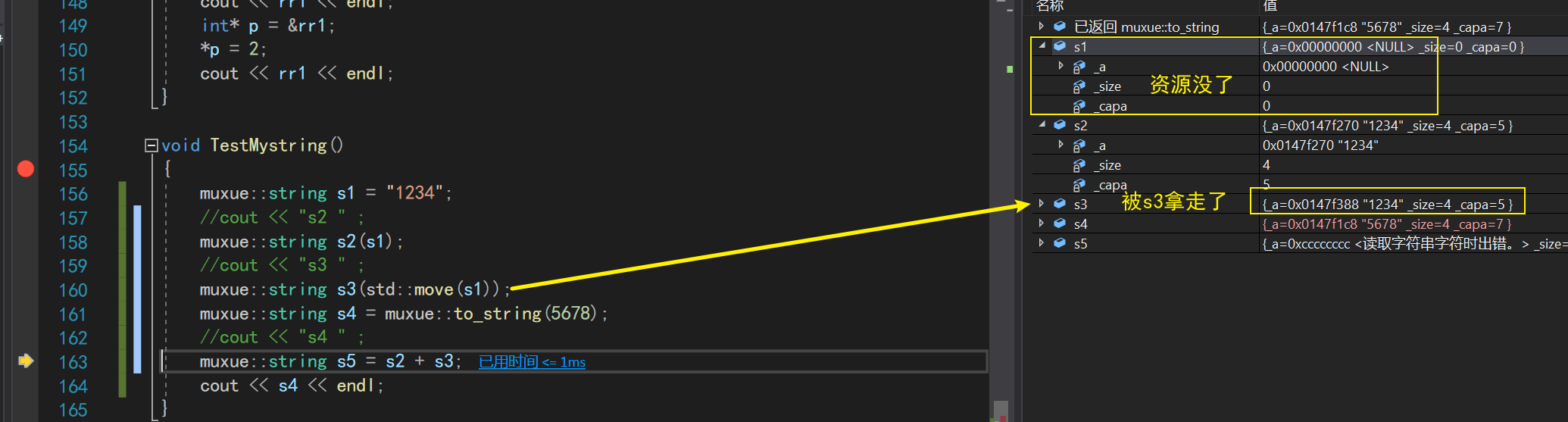
其最明显的特征,便是s3的_a地址就是s1的!

STL的更新
如果我们把自己模拟实现的移动构造删除,那么所有的return都会去调用深拷贝,代价就很大了。对象很大的时候,来一次深拷贝有可能可以把整个系统干废😂
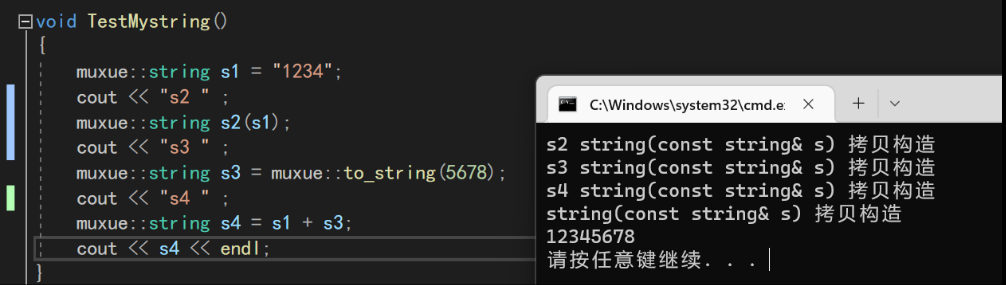
所有STL的容器,在C++11之后,都支持了右值引用的插入、移动构造和移动赋值

C++11的swap也提供了一个直接使用右值进行资源替换的版本,效率更高

4.6 编译器优化
在之前有关构造函数的博客里面有提到过,当我们return一个对象的时候,编译器会把两次拷贝构造优化成一次
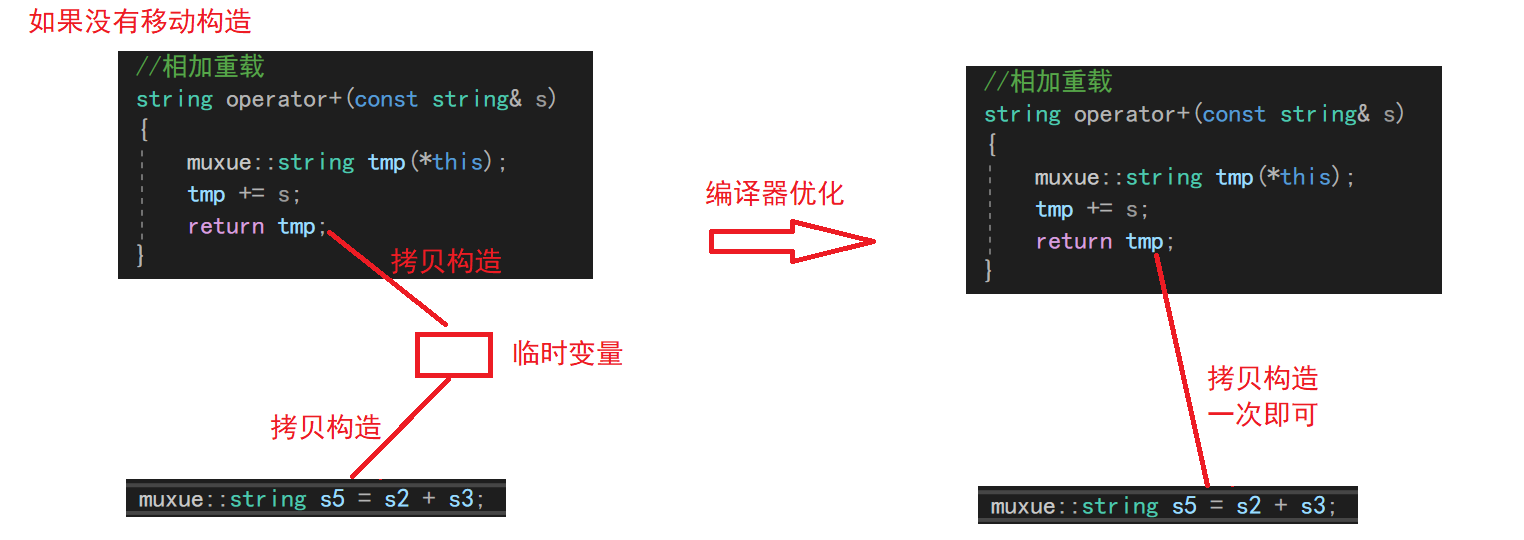
和拷贝构造一样,执行移动构造的时候,编译器也有一定的优化

不过这个优化就取决于编译器的处理了。不排除有些编译器没有做此等处理哦!
4.7 优化插入效率
有了右值引用,只要我们实现一个右值引用方式的插入,也可以优化插入时的效率
muxue::list<muxue::string> t;
muxue::string s1("111");
//调用拷贝构造,左值
t.push_back(s1);
//调用移动构造,右值
t.push_back("222");
t.push_back(std::move(s1));
5.完美转发
c++11提供了一个万能引用,既可以引用左值,也可以引用右值
void Fun(int& x) {
cout << "左值引用" << endl;
}
void Fun(const int& x) {
cout << "const 左值引用" << endl;
}
void Fun(int&& x) {
cout << "右值引用" << endl;
}
void Fun(const int&& x) {
cout << "const 右值引用" << endl;
}
template<typename T>
void test(T&& t){//T&&就是一个万能引用
Fun(t);
}
通过测试我们会发现,不管是传入一个左值还是传入一个右值,其都会调用左值引用
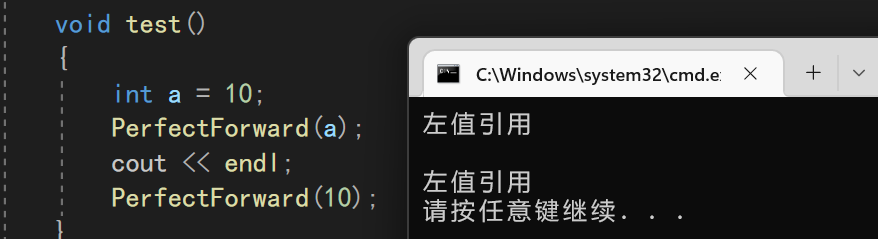
这是因为右值引用之后,形参t就是一个左值,所以调用了左值的函数
我们也不能粗暴的使用
move来解决这里的问题,因为有时候一些左值对象在后续还是需要使用的,move之后变成右值,资源被拿走了咋办!template<typename T> void PerfectForward(T&& t) { Fun(std::move(t)); }

而完美转发的存在就是为了将右值保持其右值属性,依旧调用右值对应的函数,其语法如下,使用forward函数进行完美转发
template<typename T>
void PerfectForward(T&& t){
Fun(std::forward<T>(t));
}
这时候第二种情况就正确掉用了对应的右值引用函数,也没有改变左值的属性
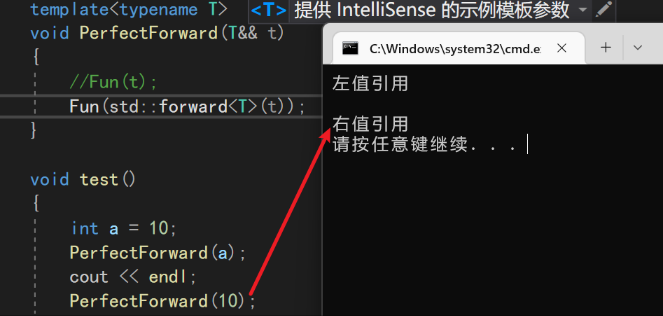
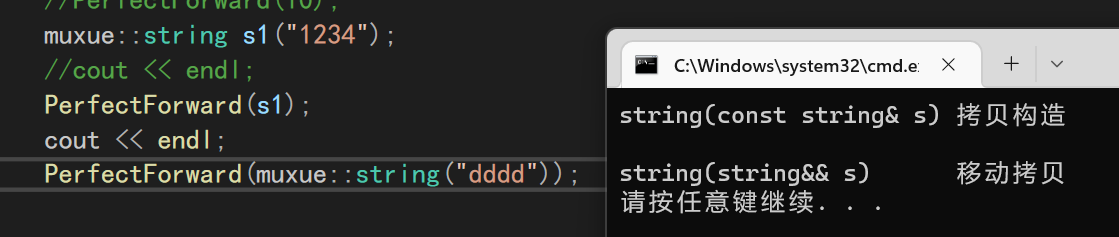
再把函数改成我们自己写的string,也能看出完美转发的作用
template<typename T>
void PerfectForward(T&& t){
muxue::string s = std::forward<T>(t);
}
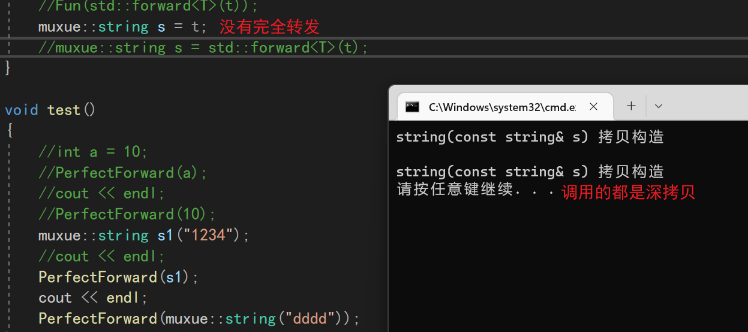
5.1 使用场景
有些场景下,我们需要对一个函数传入不同类型的参数,这时候就需要用万能引用+完美转发来进行不同的处理
比较典型的便是很多STL容器都提供了一个新的尾插函数emplace_back

template <class... Args>
void emplace_back (Args&&... args);
这里便使用了万能引用,以及可变模板参数(后面会写道)
利用我们自己写的string进行打印,即可看出二者的区别
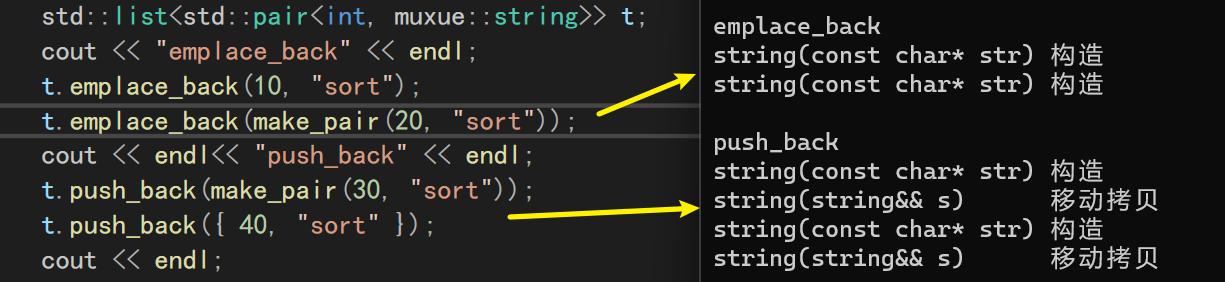
emplace_back直接调用了构造函数push_back构造+移动构造
因为移动构造的效率是很高的,所以这两种方式的差距并不算很大。不过差距肯定是有的,如果为了兼容性,使用push_back肯定更好,因为emplace是C++11新增的操作

6.新增的默认成员函数
在初识类和对象的时候,我便在博客中提到了C++的几个默认成员函数
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
在C++11中也多了两个成员函数,那便是前文所讲述的移动构造/移动赋值
但是想让编译器默认生成移动构造可没那么容易:只有你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,编译器才会帮你整一个移动构造出来
编译器默认生成的移动构造:对于内置类型会执行逐成员按字节拷贝;对自定义类型成员,则需要看这个成员是否实现移动构造, 如果实现了就调用移动构造,没有实现就调用拷贝构造。
同样的,移动赋值也需要满足上面的条件,编译器才会帮你生成。
class TestB{
private:
muxue::string _s;
int _a;
public:
TestB(const muxue::string& s="", int a=0)
:_s(s),
_a(a)
{}
};
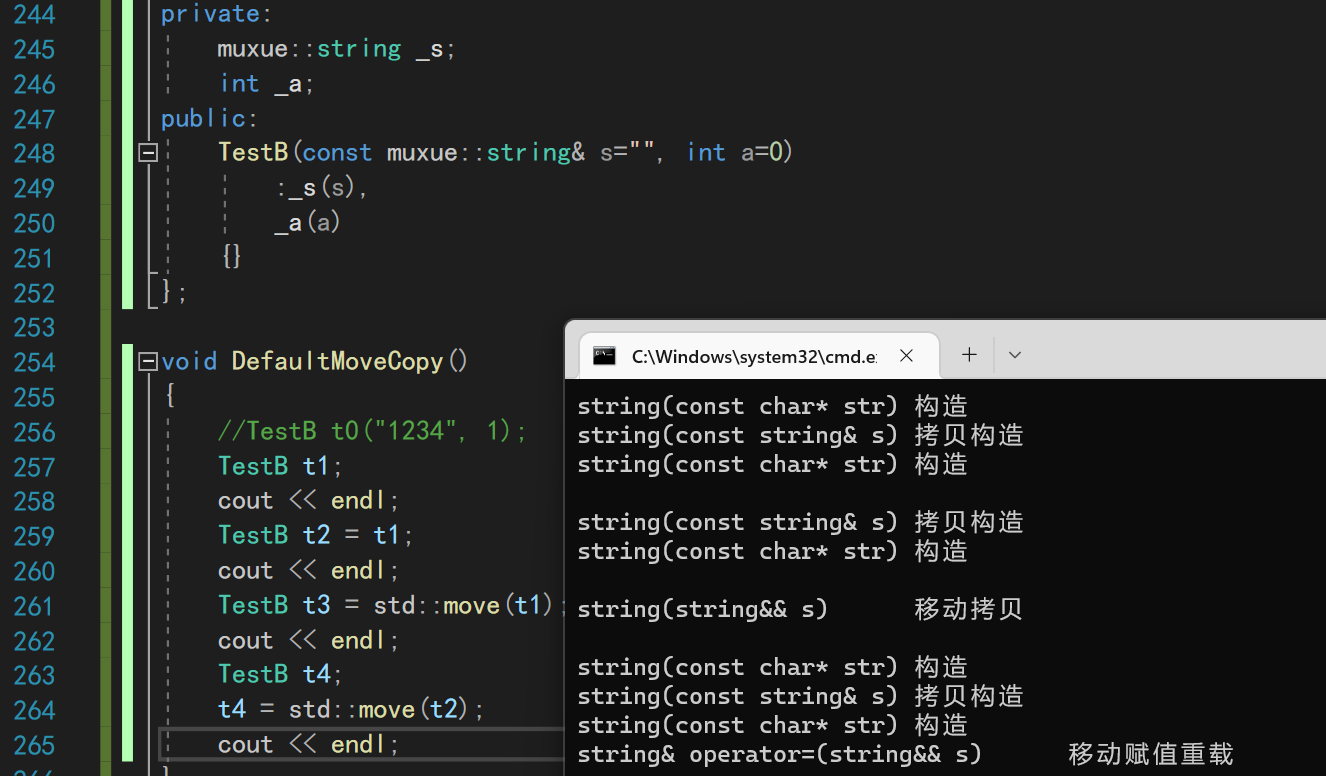
void DefaultMoveCopy(){
TestB t1;
cout << endl;
TestB t2 = t1;
cout << endl;
TestB t3 = std::move(t1);
cout << endl;
TestB t4;
t4 = std::move(t2);
cout << endl;
}
通过测试可以看出来,编译器默认生成了移动拷贝和移动赋值重载。并调用了自定义类型的移动拷贝/移动赋值
6.1 关键字default
这个关键字的作用之前好像记录过? 不记得了
default关键字的作用是让编译器强制生成一个指定的成员函数
还是上面的TestB类的代码,如果我们自己写一个拷贝构造,编译器就不再会生成默认的移动构造/移动赋值,而是会去调用string里面的拷贝构造、拷贝赋值
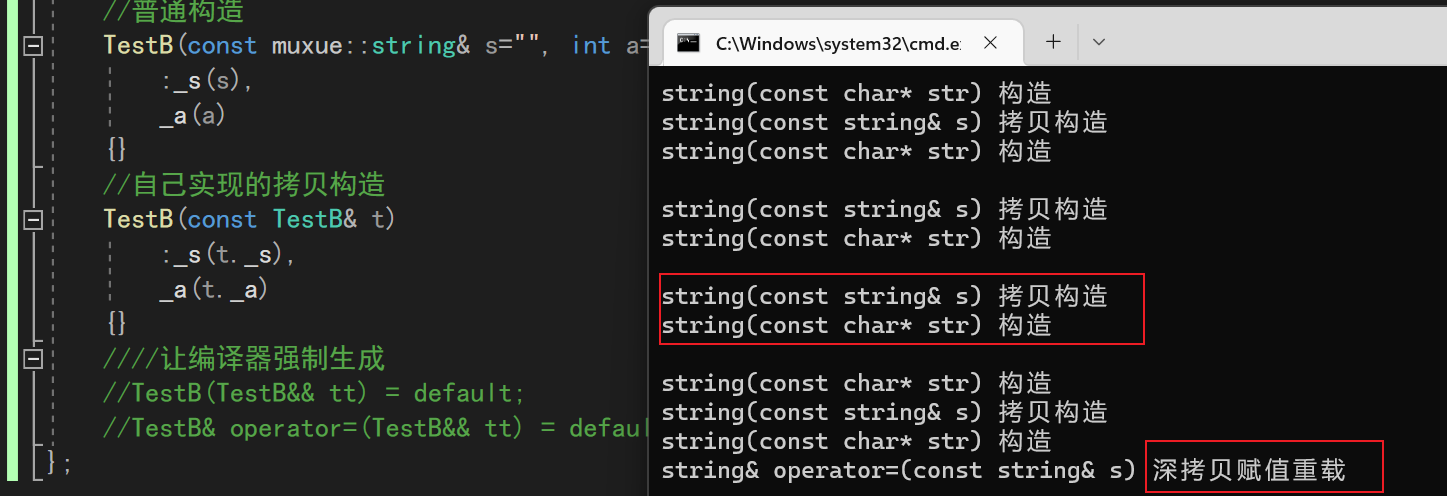
这时候我们太懒了,不想自己写移动版本了,于是就用default强制让编译器干活
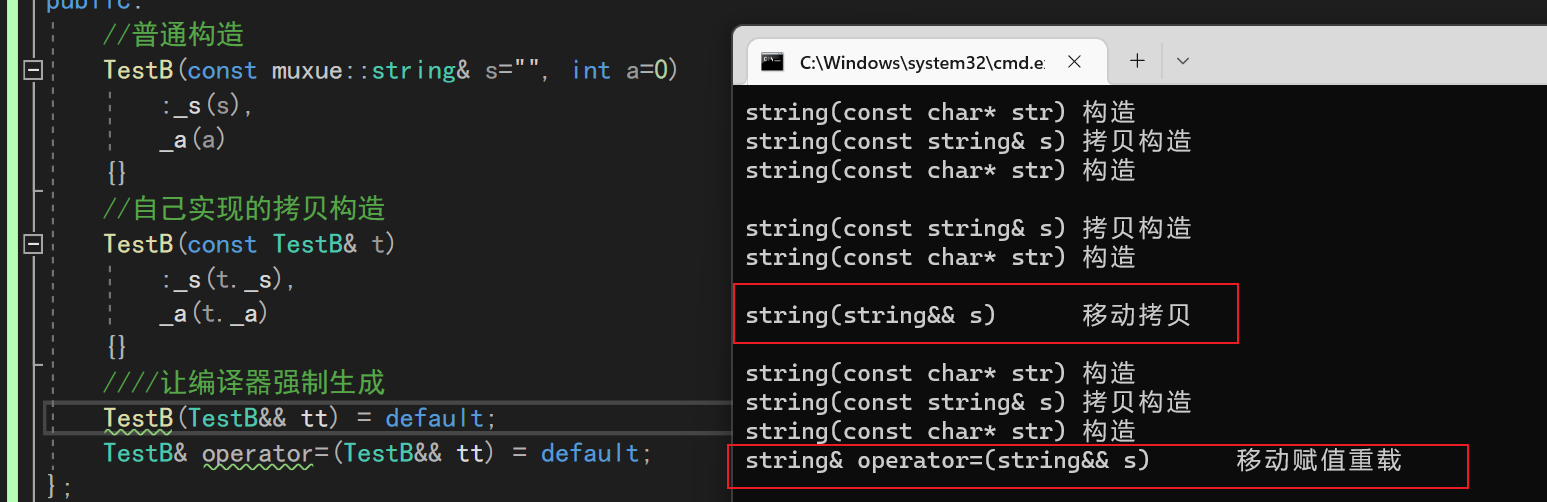
现在就正确调用了对应的移动构造和移动赋值了!
7.可变模板参数
在5.1提到的emplace_back函数中,便出现了下面这种语法
template <class... Args>
void emplace_back (Args&&... args);
这就是一个可变的模板参数,允许一个函数有多个参数,且不要求是相同类型
使用sizeof即可查看参数的个数
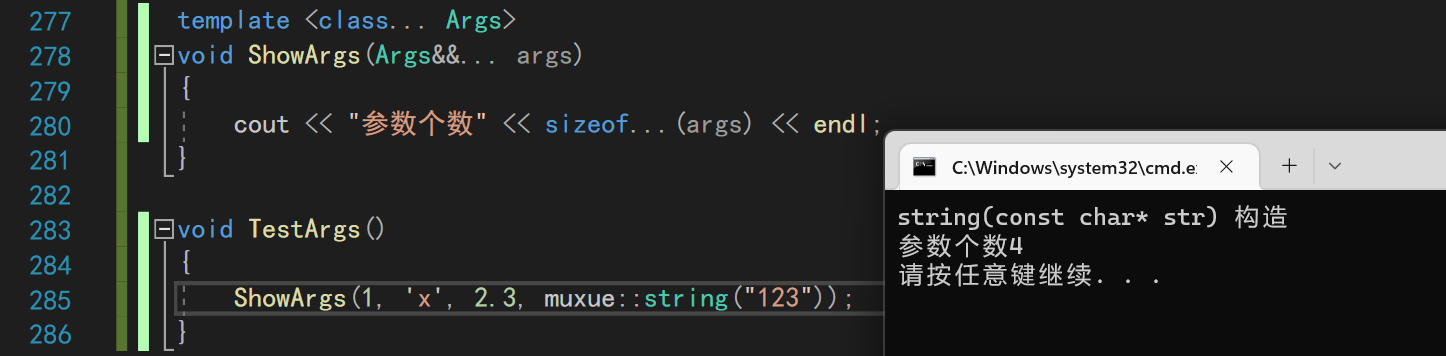
7.1 递归解参数包
而如果你想查看参数的类型并使用它,则需要进行递归取出参数来
template <class T>
void ShowArgs(const T& val)
{
cout << val << " type: " << typeid(val).name() << endl;
}
template <class T,class... Args>
void ShowArgs(const T&val,Args&&... args)
{
//cout << "参数个数" << sizeof...(args) << endl;
cout << val << " type: " << typeid(val).name() << endl;
ShowArgs(args...);
}
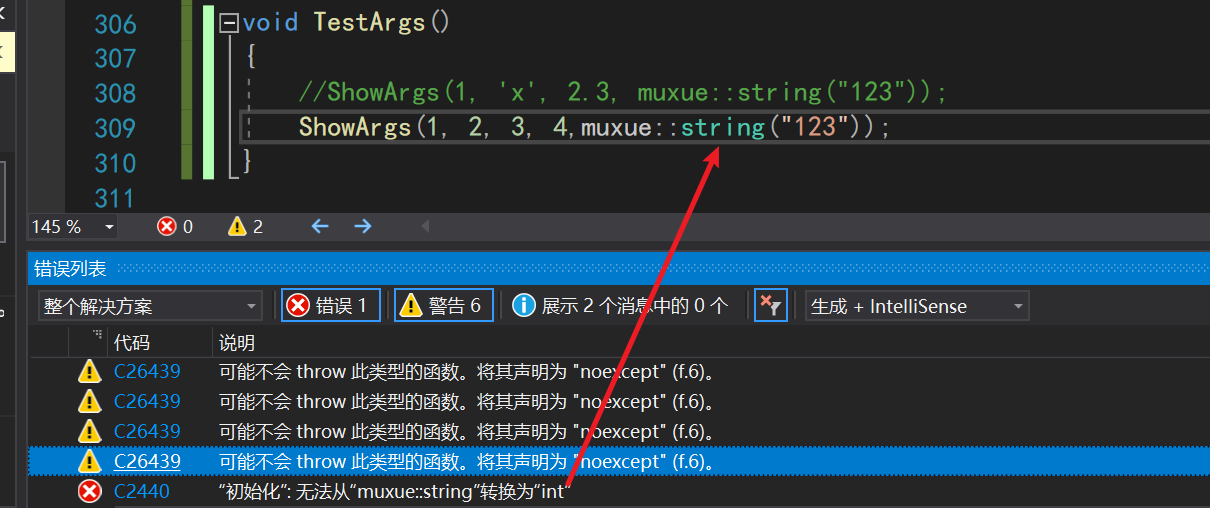
void TestArgs()
{
ShowArgs(1, 'x', 2.3, muxue::string("123"));
}
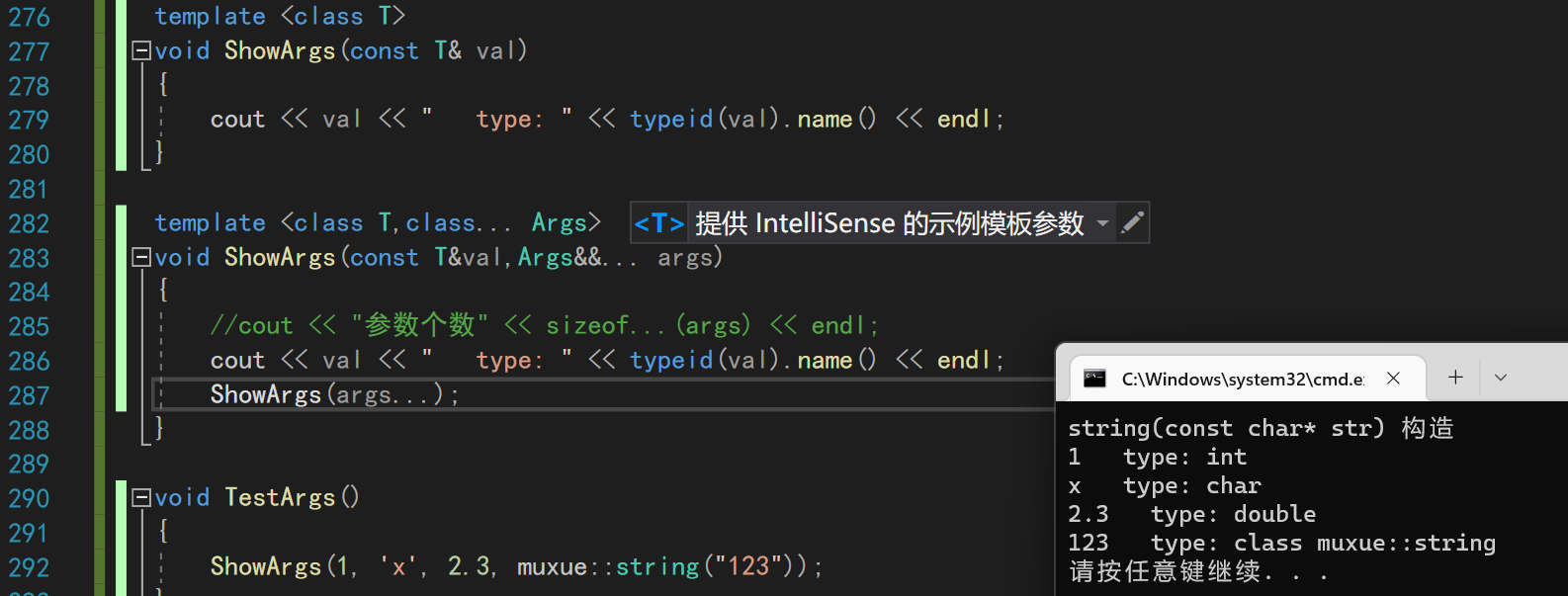
其中void ShowArgs(const T& val)函数的作用,是当参数包中只有一个参数的时候,调用对应的单参函数,而不会报错
另外一种办法便是提供一个无参的同名函数,用作参数包递归的结尾
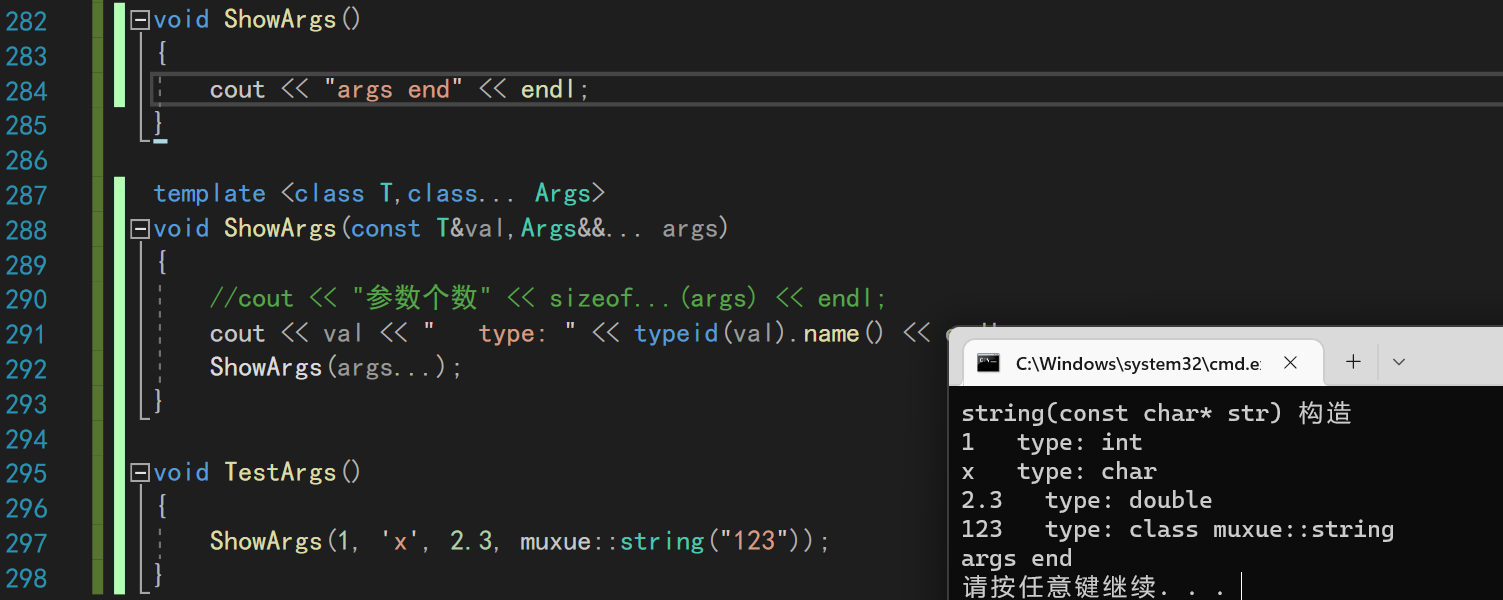
错误解法
可能有人想使用这样的方法来解包,当参数包里的函数只有一个的时候,结束递归
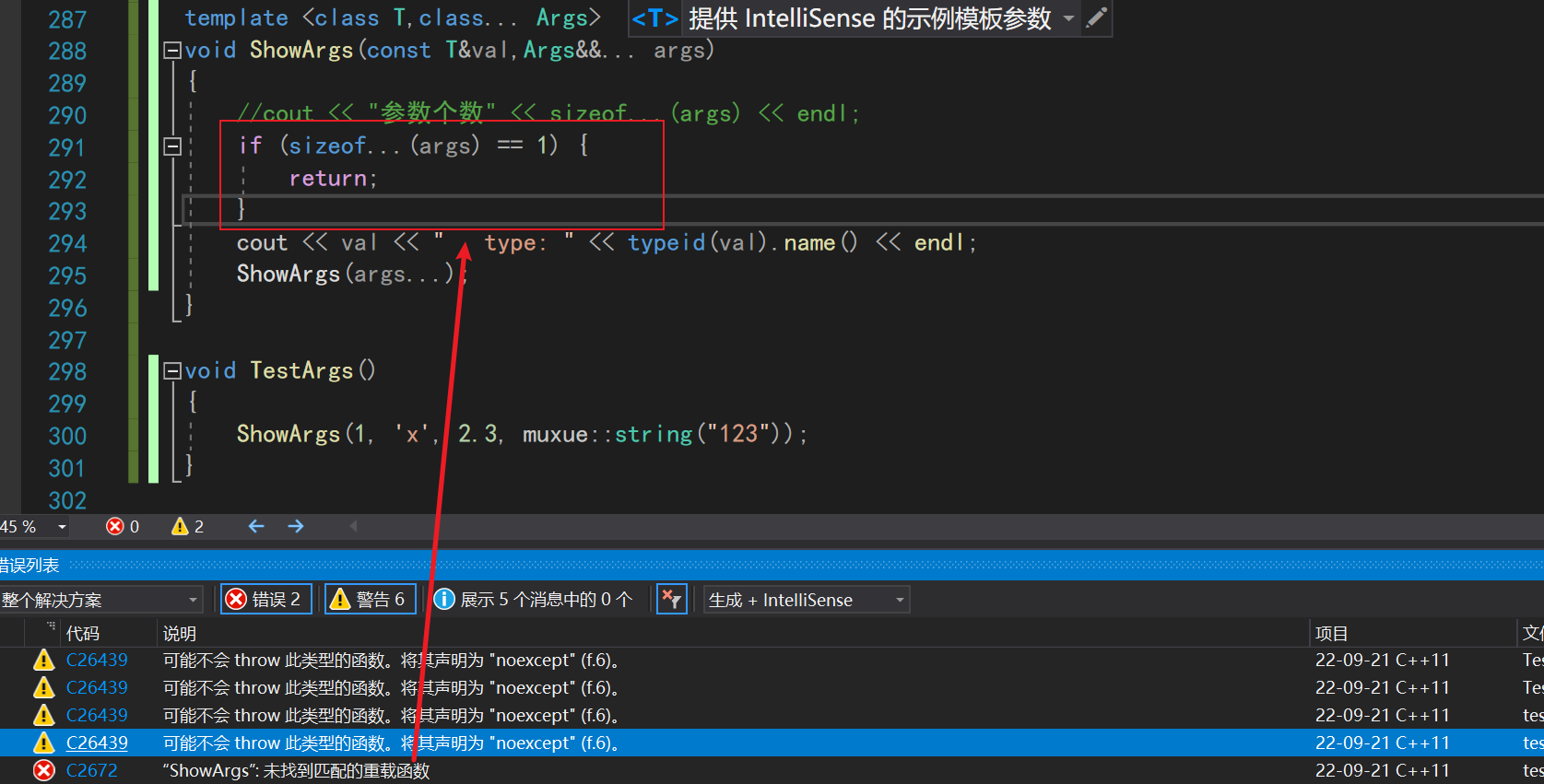
但是这样是不行的!
- 递归推参数包是一个
编译时逻辑 - 通过
sizeof判断是一个运行时逻辑
在编译这个函数的时候,已经开始找对应的函数进行调用了。当参数包里面的参数只有1个或者0个的时候,编译器编译的时候发现找不到对应函数,就直接报错了。
7.2 数组解包
除了上面的递归解包,这里还可以使用数组的方式直接来解包
template <class... Args>
void ShowArgs(Args&&... args)
{
cout << "参数个数" << sizeof...(args) << endl;
int arr[] = { args... };
}
void TestArgs(){
ShowArgs(1, 2, 3, 4);
}
可以看到arr数组里面解包出了传入的参数

但是这种方法不通用,只适用于所有参数都是相同类型的情况,如果是不同类型则会报错
通用办法是使用一个逗号表达式,来获取一共有多少个参数以及解包
template <class T>
void PrintArgs(const T& val)
{
cout << val << " type: " << typeid(val).name() << endl;
}
template <class... Args>
void ShowArgs(Args&&... args)
{
cout << "参数个数" << sizeof...(args) << endl;
//int arr[] = { args... };
int arr[] = { (PrintArgs(args),0)... };
}
一共有多少个参数,那么数组里面就会有多少个0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FOozNw7y-1664336504341)(https://img-7758-typora.oss-cn-shanghai.aliyuncs.com/img1/202209231837656.png)]
7.3 emplace_back
库函数中emplace_back的参数包还使用了万能应用,这就让它的使用更加灵活
template <class... Args>
void emplace_back (Args&&... args);
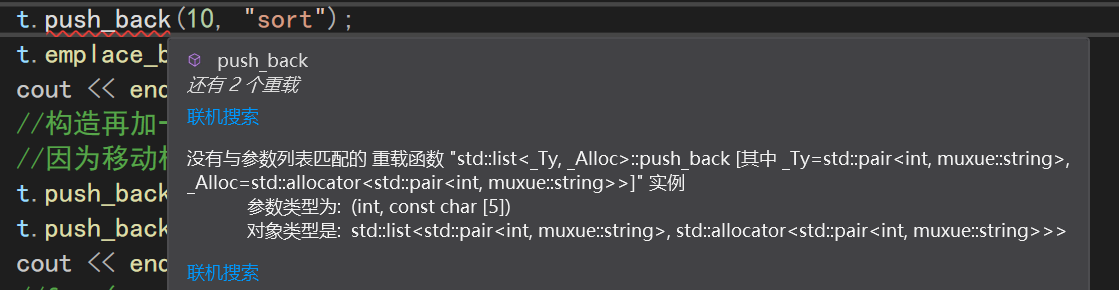
可以直接传入两个参数,他会自动解包参数,创建一个键值对
std::list<std::pair<int, muxue::string>> t;
t.emplace_back(10, "sort");
而push_back则不支持这么干
8.lambda表达式
在之前,我们使用sort的时候,如果是内置类型,默认会返回一个升序序列。如果我们需要返回降序,则需要改变比较规则,传入一个仿函数来使用自定义的比较对比
#include <algorithm>//sort
#include <functional>//greater
int main()
{
int arr[]={1,3,2,5,4};
int sz=sizeof(arr)/sizeof(arr[0]);
//默认升序
std::sort(arr,arr+sz);
//降序传入仿函数greater
std::sort(arr,arr+sz,greater<int>());
}
因为int是内置类型,库中自带的greater/less仿函数即可满足我们的需求。而如果我们排序的是自定义类型,则需要自己实现一个对应的仿函数
//价格降序
struct CompPriceGreater{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
//价格升序
struct CompPriceLess {
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price < g2._price;
}
};
8.1 情景描述
但是如果需要处理的对象有很多不同的成员变量的时候(比如京东淘宝上商品不同的筛选方式)我们就需要实现非常非常多的仿函数
这样一来,程序的代码行数就会变多
在VS编译器下,这种问题还算好解决,我们可以快速跳转道函数定义。但如果我们没有这个功能可用,在处理大文本代码的时候,怎么很快的找到对应的仿函数呢?
特别是在项目合作的时候,万一有个家伙编程命名规范很差劲,我们无法从函数名推断函数功能,再加上不能直接跳转定义,那麻烦事可多了。
8.2 lambda出场
这时候就可以试试用lambda表达式拉,以下是lambda表达式的书写格式
[capture-list](parameters)mutable -> return-type{statement}
说明一下各个位置分别写的是啥玩意
[capture-list]捕捉列表,用于编译器判断为lambda表达式,同时捕捉该表达式所在域的变量以供函数使用(parameters)参数,和函数的参数一致。如果不需要传参则可连带()一起省略mutable默认情况下捕捉列表捕捉的参数是const修饰的,该关键字的作用是取消const使其可修改-> return-type函数返回值类型{statement}函数体,和普通函数一样。除了可以使用传入的参数,还可以使用捕捉列表获取的参数
8.3 基本使用
先来写一个最简单的lambda表达式试试水吧
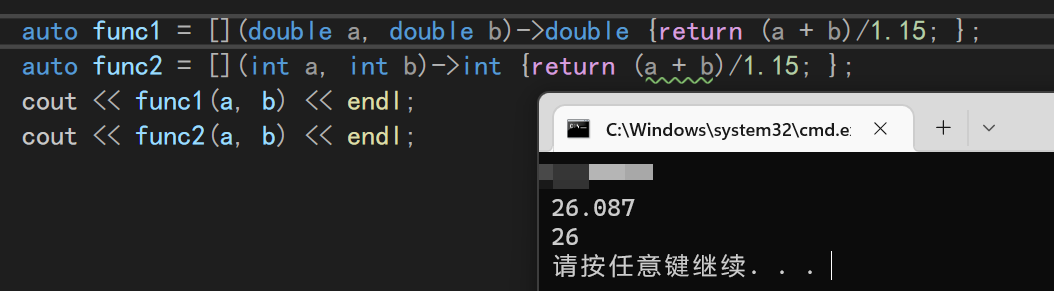
auto Add = [](int a, int b) {return a + b; };

可以看到,这个表达式的使用方法和函数完全一致,也成功提供了结果
因为我们返回值的类型是明确的,所以这里可以省略类型,让编译器自己来推断。当然也可以显示指定类型,这样可以更精确的控制
lambda表达式还支持复制给相同类型的函数指针,但是一般都不要这么用!
void(*PF)(); PF = f2; PF();
8.4 捕捉列表和mutable
学会了基本使用,我们再来看看捕捉列表是怎么玩的
void TestLambda1()
{
int a = 10, b = 20;
auto func3 = [a,b](int x, int y)->int {
return a+b;
};
cout<<func3(a, b)<<endl;
}

这里我们捕捉了函数作用域里面的局部变量a/b,直接在lambda表达式内部使用👍
因为不需要传入参数,所以我们可以直接把参数()和返回值一并省略掉

mutable
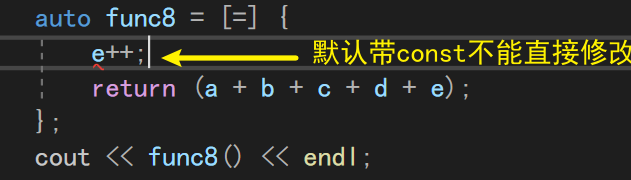
默认情况下,我们捕捉到的参数是带const的,我们并不能对其进行修改。
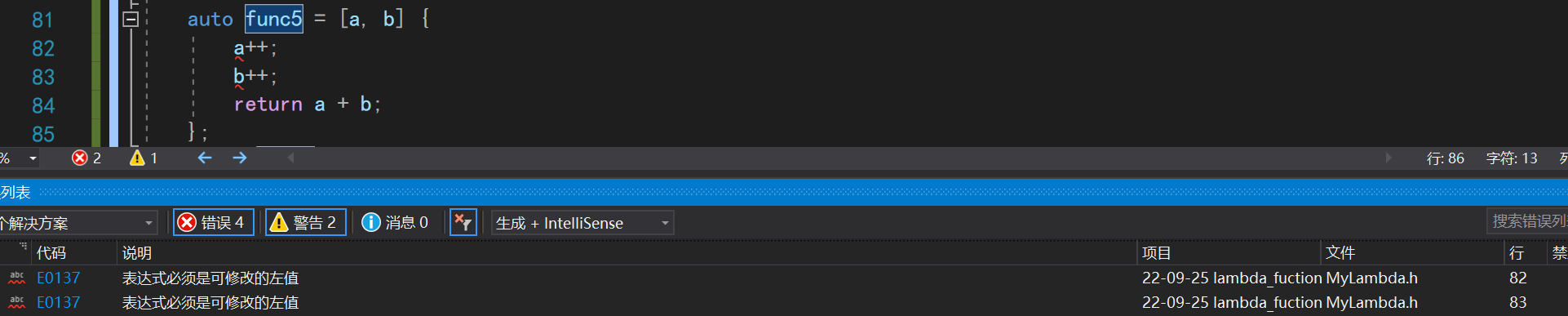
这时候就需要使用前面提到的mutable关键字来修饰
注意:这个关键字使用的时候必须带上函数参数的
()
auto func5 = [a, b]()mutable {
a++;
b++;
return a + b;
};
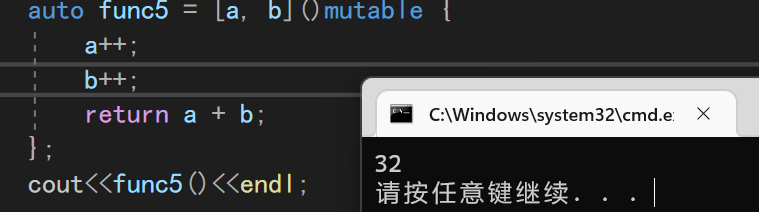
8.5 捕获的几种方式
注意,当我们在对象里面以值传递方式捕获参数的时候,还需要捕获this指针来调用类内部的函数
[val]:表示值传递方式捕捉变量val
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&val]:表示引用传递捕捉变量val
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
其中第一个就是我们上面演式的[a,b]这样最直接的值捕获
而最后一个的this指针主要用用于类内部
8.5.1 全捕获=
当一个作用域里面的变量很多,而我们又不想一个一个写的时候,可以使用=捕捉全部变量
int a = 10, b = 20;
int c = 1, d = 3, e = 5;
auto func6 = [=] {
return (a + b + c + d + e);
};
cout << func6() << endl;
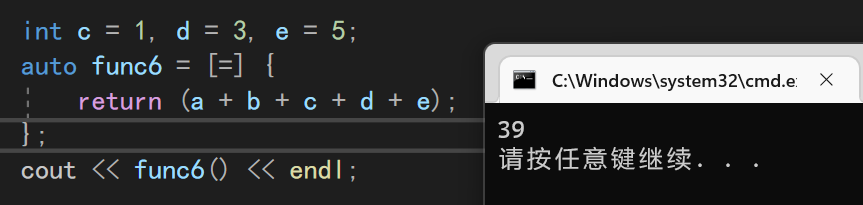
8.5.2 引用全捕或
除了基本的全捕或,我们还可以用一个&以引用的方式捕获全部参数。
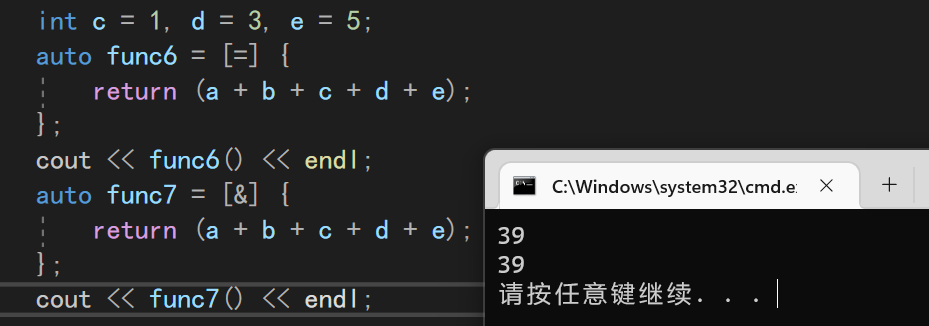
引用了过后,我们也可以修改参数了
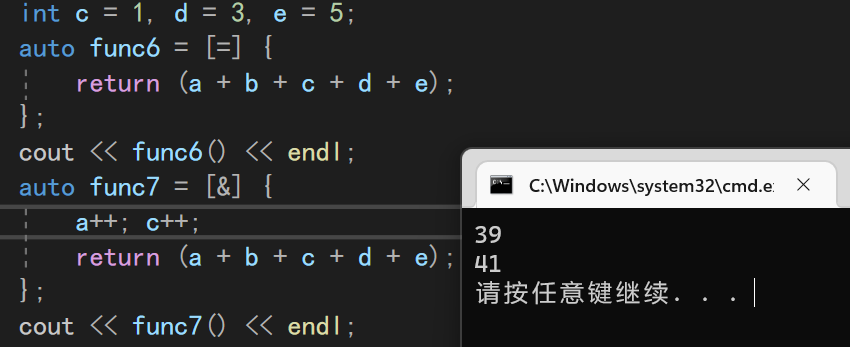
8.5.3 全捕获+单独操作
如果只是仅仅的全捕或还不够,我们还想单独修改某一个参数的时候,可以以不同的方式进行捕获操作
auto func8 = [=,&e] {
e++;
return (a + b + c + d + e);
};
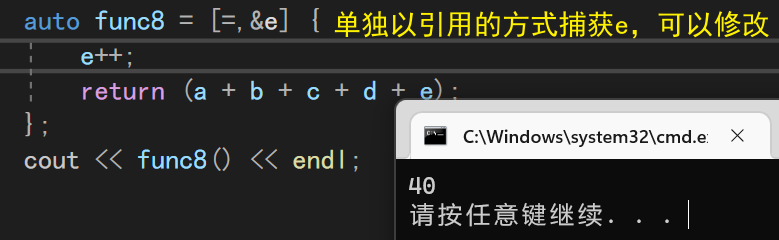
这样一来就方便多了
8.6 最终呈现
这样,当我们sort的时候,就不再需要用仿函数了,而是可以直接用lambda表达式来完成相同的操作,大大增加代码可读性!
这是因为排序所用的方法直接就在sort这里用lambda的形式给出了,看代码的时候,也不需要去找定义,更不用担心函数命名规则的问题了。
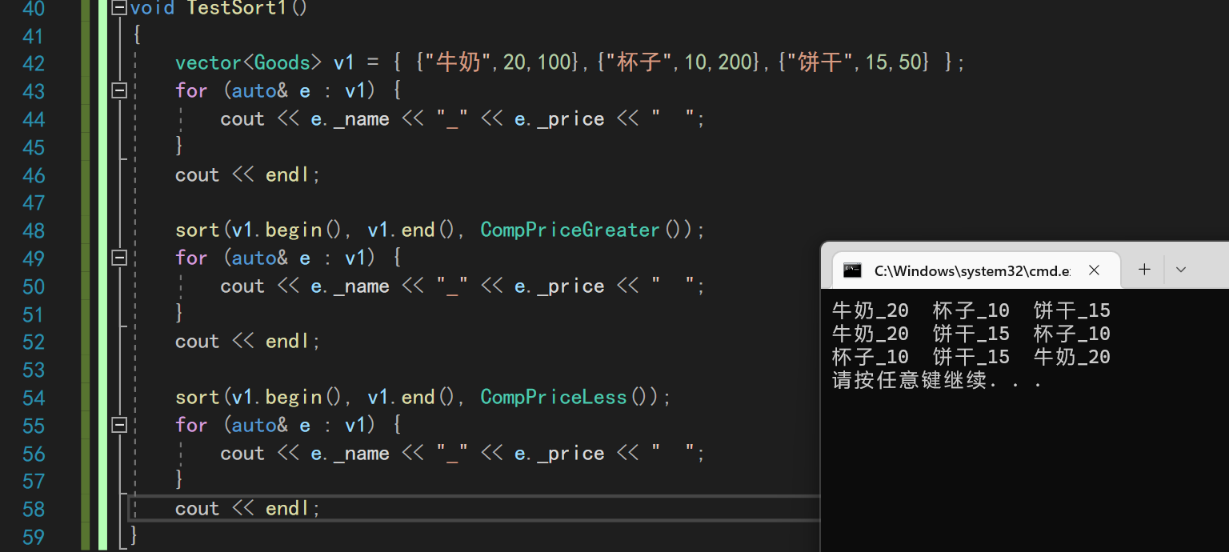
vector<Goods> v1 = { {"牛奶",20,100},{"杯子",10,200},{"饼干",15,50} };
//价格升序
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) {return g1._price < g2._price; });
for (auto& e : v1) {
cout << e._name << "_" << e._price << " ";
}
cout << endl;
v1 = { {"牛奶",20,100},{"杯子",10,200},{"饼干",15,50} };
//价格降序
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) {return g1._price > g2._price; });
for (auto& e : v1) {
cout << e._name << "_" << e._price << " ";
}
cout << endl;
v1 = { {"牛奶",20,100},{"杯子",10,200},{"饼干",15,50} };
//名称字典序
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) {return g1._name < g2._name; });
for (auto& e : v1) {
cout << e._name << "_" << e._price << " ";
}
cout << endl;

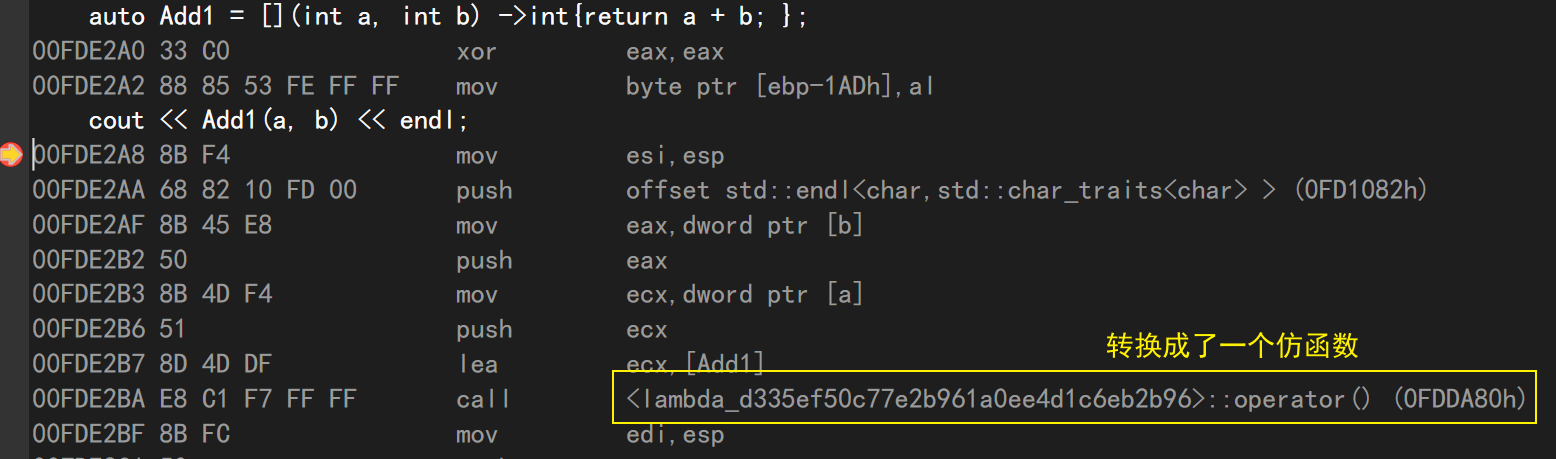
8.7 lambda底层:仿函数
实际上,lambda的底层就是把自己转成了一个仿函数供我们调用。这也是为何sort可以以lambda来作为排序方法的原因——底层都是仿函数嘛!
9.包装器function
function包装器,也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
那么这个东西是用来干啥的呢?
- 把所有的可调用对象封装成统一的格式
什么是可调用对象?
- 函数指针
- 仿函数对象
- lambda表达式
9.1 基本使用
我们可以用function来包装这些不同的可调用对象,说白了就是产生了另外一个相同的可调用对象。类似于“引用”了这个函数
class AddClass{
public:
static int Addi(int a, int b){
return a + b;
}
double Addd(double a, double b){
return a + b;
}
};
int func(int a,int b){
return a + b;
}
struct Functor{
int operator()(int a,int b){
return a+b;
}
};
void TestFunction1()
{
// 函数
function<int(int, int)> func1 = func;
cout << func1(10, 20) << endl;
// 仿函数
function<int(int, int)> func2 = Functor();
cout << func2(10, 20) << endl;
// 类中static成员函数
function<int(int, int)> func3 = AddClass::Addi;
cout << func3(100, 200) << endl;
// 类中非静态成员函数
function<double(AddClass, double, double)> func4 = &AddClass::Addd;
cout << func4(AddClass(), 100.11, 200.11) << endl;
// lambda表达式
function<int(int, int)> func5 = [](int a, int b) {return a + b; };
cout << func5(100, 200) << endl;
}
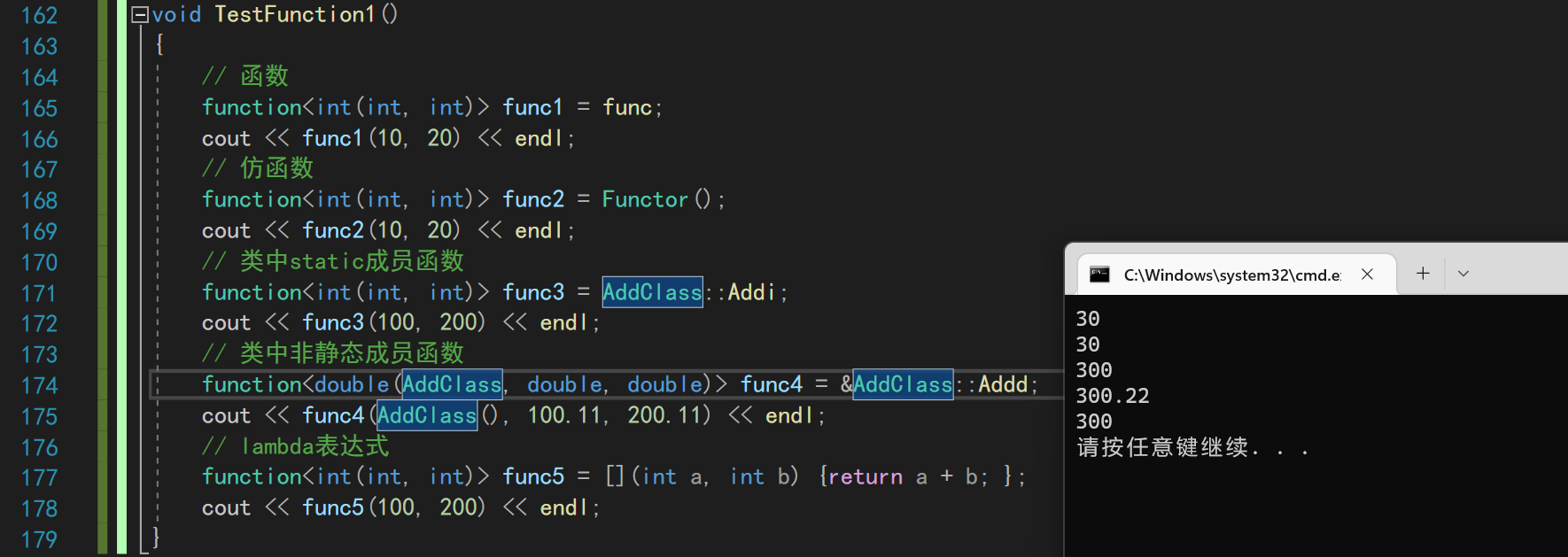
引用类中非static成员
需要注意的是,当我们使用静态成员函数的时候,必须要带上一个this指针才能很好的访问。所以我们需要穿入一个AddClass()的匿名对象来适配包装器
同时,非静态的成员函数还必须要进行&取地址操作。静态的则可以不加
为了统一,可以都加上以防忘记
9.2 特殊场景的作用
这个东西呢,看起来好像没啥用,但是在一些地方可以帮大忙
比如模板函数,假设我们知道在函数B里面需要调用一个模板函数A多次,而且每次调用都是相同类型的(或者说就只有已知的几个特定类型),那么就可以先用fuction对这个模板函数进行指定的实例化,避免每一次调用的时候,后台都需要单独去实例化一个函数,减小模板的性能损耗!
9.3 改造逆波兰表达式OJ
leetcode逆波兰表达式:https://leetcode.cn/problems/evaluate-reverse-polish-notation/
之前写这个OJ的时候,我用的是栈和switch/case语句
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> s;
for(auto& ch : tokens)
{
if(ch=="+"||ch=="-"||ch=="*"||ch=="/")
{
int right=s.top();
s.pop();
int left=s.top();
s.pop();
switch(ch[0])
{
case '+':
s.push(left+right);
break;
case '-':
s.push(left-right);
break;
case '*':
s.push(left*right);
break;
case '/':
s.push(left/right);
break;
default:
break;
}
}
else{
s.push(stoi(ch));
}
}
return s.top();
}
};
现在我们就不需要这么麻烦了,可以使用包装器来改造这个OJ题的答案
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> s;
map<string,function<int(int,int)>> FuncMap = {
{"+",[](int x,int y){return x+y;}},
{"-",[](int x,int y){return x-y;}},
{"*",[](int x,int y){return x*y;}},
{"/",[](int x,int y){return x/y;}}
};
for(auto& ch : tokens)
{
if(ch=="+"||ch=="-"||ch=="*"||ch=="/")
{
int right=s.top();
s.pop();
int left=s.top();
s.pop();
int ret = FuncMap[ch](left,right);
s.push(ret);
}
else{
s.push(stoi(ch));
}
}
return s.top();
}
};
这里我们还用到了前面提到过的{}初始化构造。现在我们只需要从funcmap里面取出封装器封装的lambda表达式进行操作就可以了!
代码一下就简洁了许多,但是这也只有学习过C++11的人才看得懂,属于一个进阶用法
测试的时候发现出现了一些问题,int溢出了
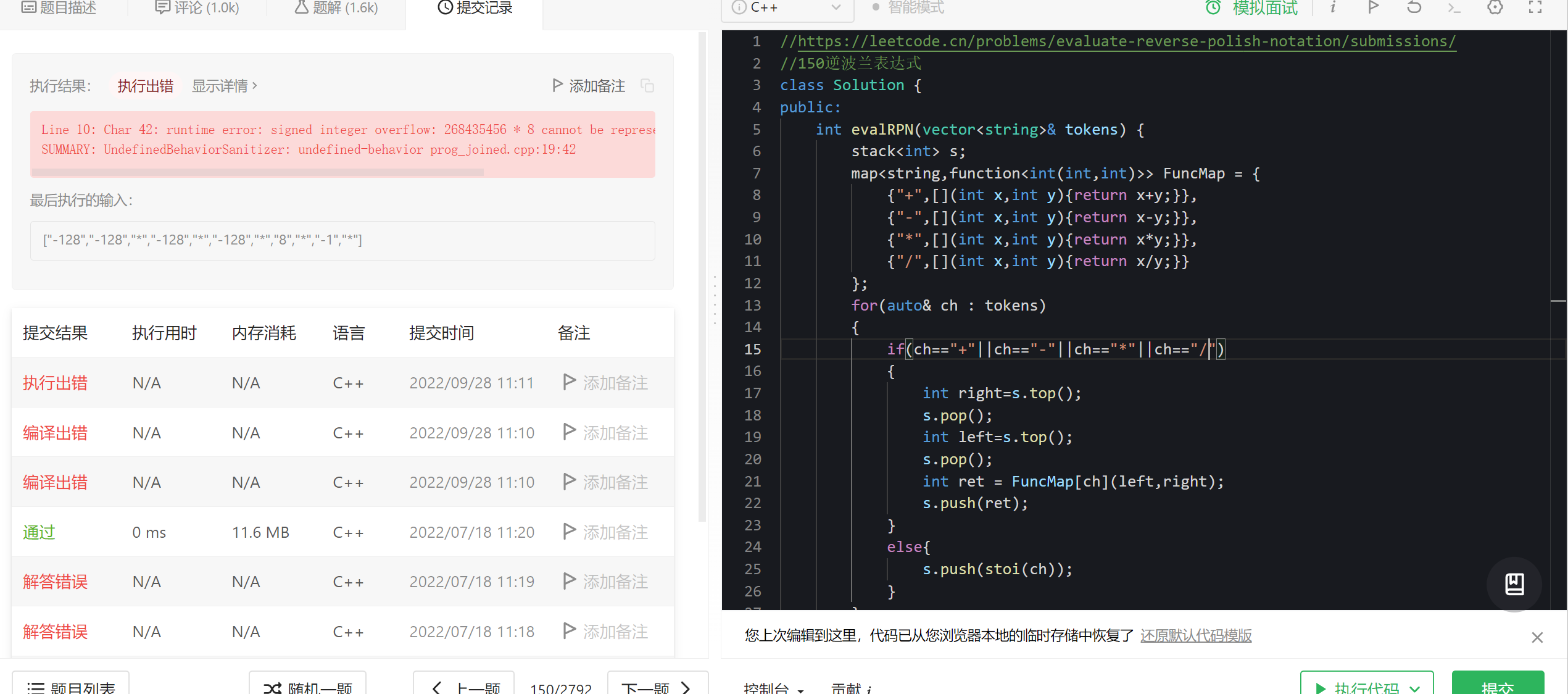
把所有的int都改成long long即可

10.bind绑定
在上面我们用fuction包装一个对象内部的成员函数时,需要利用匿名对象传入一个this指针。这样就很不方便了,明明是两个参数的函数,非要传入第三个参数。
要是我们再用9.3中map的方式来封装一个可调用的表,那带this指针的函数就没办法一起包装了
class AddClass
{
public:
static int Addi(int a, int b)
{
return a + b;
}
int Addii(int a, int b)
{
return a + b;
}
};
int func(int a,int b)
{
return a + b;
}
struct Functor
{
int operator()(int a,int b)
{
return a+b;
}
};
map<string, function<int(int, int)>> FuncMap = {
{"函数",func},
{"仿函数",Functor()},
{"静态成员函数",AddClass::Addi},
{"非静态成员函数",&AddClass::Addii}
};
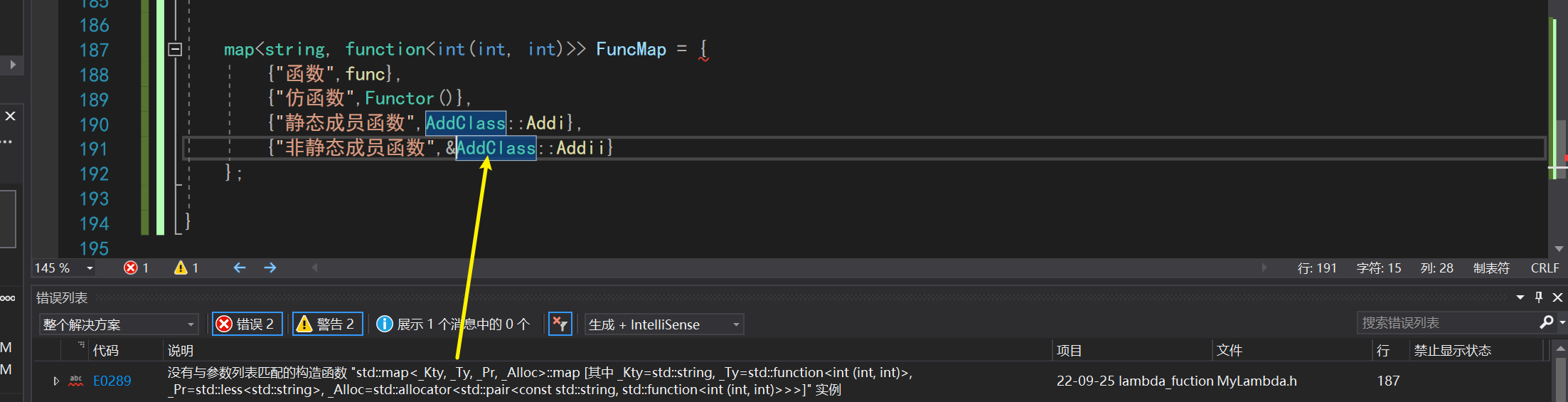
这里不能使用可变参数包,因为是实例化操作
这时候我们就可以使用bind来进行参数绑定
10.1 使用
调整参数的顺序,绑定固有参数,形成一个新的可调用对象
function<int(int, int)> func7 = bind(&AddClass::Addii,AddClass(), placeholders::_1, placeholders::_2);
cout << func7(100, 200) << endl;

这时候我们就不需要传入this指针,因为当我们用bind绑定的时候,已经默认传入了第一个参数了!
10.2 占位符placeholders
placeholders是用来占位的,代表这里的参数需要用户手动传入,而_1代表传入的第一个参数,_2就是传入的第二个参数,以此类推
function<int(int, int)> func7 = bind(&AddClass::Addii,AddClass(), placeholders::_1, placeholders::_2);
因为有不同的后缀,所以我们还可以调整绑定的参数顺序!
//Minii的作用是a-b
function<int(int, int)> func8 = bind(&AddClass::Minii, AddClass(), placeholders::_1, placeholders::_2);
cout << func8(100, 200) << endl;
function<int(int, int)> func9 = bind(&AddClass::Minii, AddClass(), placeholders::_2, placeholders::_1);
cout << func9(100, 200) << endl;
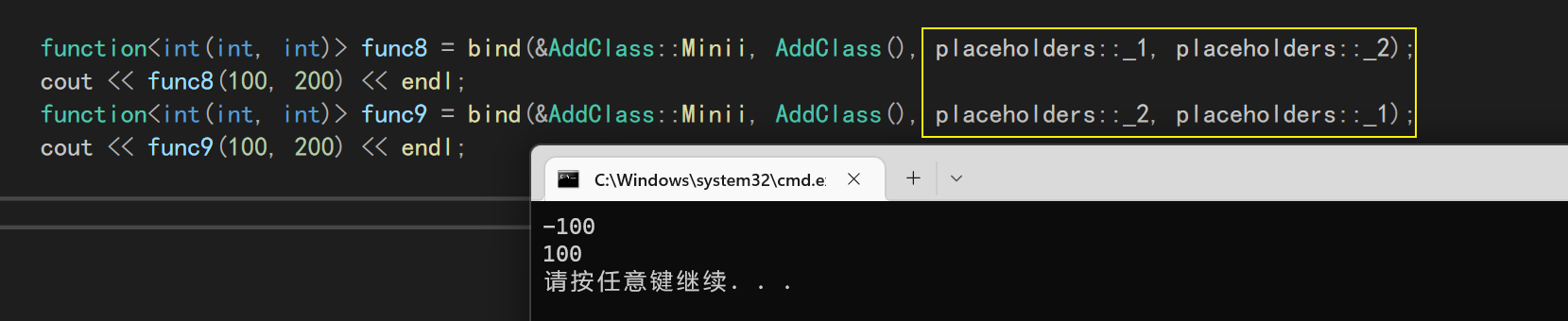
我们调整了顺序之后,也得到了不同的结果!
结语
本篇超长的博客到这里就结束辣!
其实C++11还有其他的新特性,但是那些我会单开一篇文章来写~
