浅析Relaxed Ordering对PCIe系统稳定性的影响
一、关于PCIe TLP排序机制的介绍
与其他协议一样,当同一个通信等级(Traffic Class, TC)的多个事务(Transactions)同时通过同一个通道时,PCIe对这些事务设置了一些排序(Transaction Ordering)规则。
这样做的好处有以下几点:
- 保持与传统总线的兼容性。比如PCI,PCI-X等;
- 保证事务的完成具有准确性,并且按照设计人员的意愿完成;
- 避免死锁的状况发生;
- 最大限度的优化PCIe总线的传输效率。
注释:死锁是指两个以上的设备在访问临界资源时,相互等待对方释放这些资源,而无法访问这些资源的情况。
在PCI总线上,只支持Strong Ordering传送规则,而在PCIe总线中新增了Relaxed Ordering(RO) 和 ID-based Ordering(IDO)传递方式。
Strong Ordering:
何为Strong Ordering? 顾名思义,Strong,就是很强壮,很彪悍的意思。Strong Ordering强制总线上的TLP按照先来后到的方式进行传递,一视同仁,不管是否有特殊情况,均不允许插队和绿色通道。但是事情总有轻重缓急,对于一些紧急的状况,这个强制规则难免会影响到总线的传递效率和用户体验。
我们看下面一个例子,

- 所有的TLPs类型统一编号;
- 发送端VC buffer有8个待传输的TLPs,依次编号为#1~8,这8个TLPs分为三类:Posted:2, 4, 7;Non-Posted: 1, 5;Completions: 3, 6, 8;
- 接收端对应的VC buffer如上图,其中,Non-Posted buffer已满,而Posted、Completions buffer则仍有可用空间;
此时,接收端Non-Posted buffer已满,TLP 1,5则需要暂停发送。由于这8个TLPs属于同一VC,需要按照Strong-Ordering规则排序。所以TLP 2,3,4对应接收端VC buffer即使有可用空间,也必须等TLP 1传输完成之后才能发送。
这不就是浪费时间嘛,浪费别人的时间,就等于谋杀呀~Strong-Ordering太不厚道咯~~~
Relaxed Ordering(RO):
相比PCI, PCIe则深得中庸之道,更加善解人意。PCIe支持的Relaxed Ordering的传递规则不会要求TLPs严格遵守先来后到,也意味着根据轻重缓急找到最佳的方案,提高数据的传输效率。
不过,Relaxed Ordering是有条件的。因为每个TLP只能对应一个TC(通信等级), 而这个TC有只能对应唯一一个VC(虚拟通道)。所以说:
- VC相同的TLPs遵循Relaxed Ordering规则,
- VC不同的TLPs则没有事务排序的要求,不必遵循Relaxed Ordering规则。
VC相同的TLPs需要遵循的排序规则具体如下表:

先解释一下表格中的Yes, Y/N, No对应的含义:
Yes: 代表第二个事务必须在第一个事务之前通过,也就是强制性"超车";
Y/N: 没有排序要求;
No: 代表第二个事务绝对不允许在第一个事务之前通过,也就是"超车"违法.
我们解析一下表格中的A2b, B2, C2b, D2b的内容来阐述一下Relaxed-Ordering的效果:
A2b: 当RO=1, 也即Enable Relaxed-Ordering规则。此时,Memory Writes or Messages被允许超车之前的Memory Writes or Messages而抢先通过;
B2: 无论RO bit是否被置起来, Read Requests均不被允许超车之前的Memory Writes or Messages而抢先通过;
C2b: 当RO=1, IO writes和Configuration writes被允许超车之前的Memory Writes or Messages而抢先通过;
D2b: 当RO=1, Competitions被允许超车之前的Memory Writes or Messages而抢先通过;
ID-based Ordering(IDO):
IDO的模型是在PCIe V2.1版本之后新增的功能。该模型引入了"数据流"(Stream)的概念,即:
- 相同数据源发送的TLPs属于同一数据流;
- 不同数据源发送的TLPs属于不同的数据流;
IDO模型允许不同数据流的TLPs之间不必遵循事务排序的约定。
我们来看个例子:
- 设备1发送了Posted Write Request, 但是,此时Write Buffer已处于满的状态,所以Posted-Write被锁定在Switch。
- 随后,设备3发送了Non-Posted Read Request, 通过Switch时,正好撞到了上面表格B2所指规则(B2: 无论RO bit是否被置起来, Read Requests均不被允许超车之前的Memory Writes or Messages而抢先通过;), 所以,Read request同样被锁定在Switch。
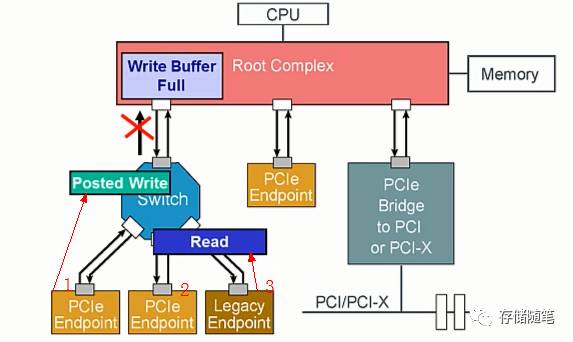
此时,就要靠IDO这位大神出手咯~
依照IDO模型的思想,Posted Write request和Read request的数据源不一样,可以不遵循事务排序规则。
所以,当PCIe总线enable IDO功能时,Read request可以很开心的通过Switch,这个时候,Posted Write只有羡慕嫉妒恨的份儿咯~~~
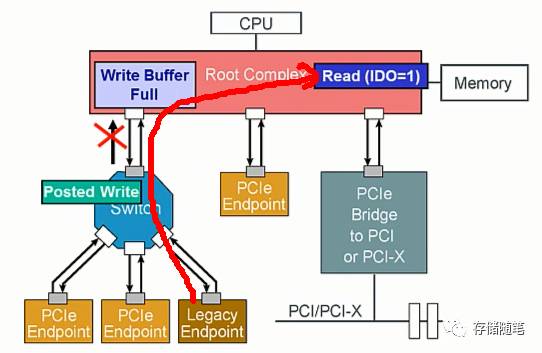
二、Relaxed Ordering对系统的影响
在第一部分的内容,我们介绍了PCIe TLP的排序机制原理,也可以看到Relaxed Ordering也是PCIe一个优化性能的利器。在很多PCIe系统中,PCIe设备也基本是默认打开的Relaxed Ordering这个机制的特性,以保持达到最高的性能。
但是,小编想说下,对Relaxed Ordering的意见是,酌情看是否适合自己的系统,Relaxed Ordering并不是通用的优势。在不适合自己情况,使用Relaxed Ordering将是一场灾难。
在使用Relaxed Ordering的功能之前,据小编的了解,需要先判断两件事情:
1.是否存在PCI-to-PCI的情况,这种情况由于存在strong ordering强排序的要求,可能会出现Write写入还没完成的情况下,Read读取同一个地方的数据,最终导致数据报错。

2.是否存在共享内存的架构,是否可能会存在多个行程访问同一个内存地址的情况。如果是,Relaxed Ordering机制机会给系统带来系统错误。比如在intel的CPU规范中,有一段话,大家可以参考:
- 访问MMIO内存映射区域时,可以打开Relaxed Ordering(RO)功能,这样可以得到最大的性能。
If the access is toward MMIO region, then software can command HW to set the RO bit in the TLP header, as this would allow hardware to achieve maximum throughput for these types of accesses.
MMIO,即Memory Mapped IO,是把IO设备的内部存储和寄存器都映射到统一的存储地址空间(Memory Address Space)。
- 访问共享一致性内存时,可以关闭Relaxed Ordering(RO)功能,这样可以得到最大的性能
For accesses toward coherent memory, software can command HW to clear the RO bit in the TLP header (no RO), as this would allow hardware to achieve maximum throughput for these types of accesses.

如果使用Relaxed Ordering不当,将会出现什么后果的。小编这里列举几种故障现象:
(1)类似网卡出现降速的问题

(2)PCIe FPGA设备出现TLP报错,引发系统报错

(3)NVME盘性能降速,驱动报错completion polled
[ 126.031565] nvme nvme0: I/O 5 QID 0 timeout, completion polled [ 187.471563] nvme nvme0: I/O 6 QID 0 timeout, completion polled [ 248.911566] nvme nvme0: I/O 7 QID 0 timeout, completion polled [ 310.351565] nvme nvme0: I/O 4 QID 0 timeout, completion polled [ 371.791569] nvme nvme0: I/O 5 QID 0 timeout, completion polled
在nvme驱动中出现timeout且completion polled的场景,对应的代码如下:看到主要的原因是初始化过程中,NVMe控制器就出现了超时,说明Relaxed Ordering在初始化阶段就产生了异常,导致TLP处理失败,出现性能降速。解决方案也是要把Relaxed Ordering功能关闭掉,性能就恢复了正常。
if (blk_mq_request_completed(req)) {
dev_warn(dev->ctrl.device,
"I/O %d QID %d timeout, completion polled\n",
req->tag, nvmeq->qid);
return BLK_EH_DONE;
}
/*
* Shutdown immediately if controller times out while starting. The
* reset work will see the pci device disabled when it gets the forced
* cancellation error. All outstanding requests are completed on
* shutdown, so we return BLK_EH_DONE.
*/
所以,Relaxed Ordering的机制并不是使用所有的场景,大家是否还有遇到其他的Relaxed Ordering导致的异常呢?欢迎评论区留言交流。