Hive数据类型、部分函数及关键字整理
文章目录
- 一、数据类型
- 1.基本数据类型
- (1)数值类型
- (2)日期类型
- (3)字符串类型
- (4)杂项类型
- 2.集合数据类型
- 3.类型转换
- 二、DDL
- 1.创建表
- 2.修改表
- (1)重命名表
- (2)增加分区
- (3)重命名分区
- (4)删除分区
- (5)修改表中的列
- (6)替换,新增列
- 三、DML
- 1.数据导入
- (1)通过Load向表中装载数据
- (2)通过values插入数据
- (3)通过查询其他表插入数据
- (4)更新数据
- (5) 删除数据
- (6)清除表中数据
- 2.表查询
- 3.连接表
- 4.侧写表
- 5.合并查询结果
- 6.数据抽样
- 四、窗口和分析函数
- 1.开窗函数
- 2.窗口函数
- 3.聚合函数
- 4.分析函数
- 5.多维分析
一、数据类型
1.基本数据类型
(1)数值类型

(2)日期类型

(3)字符串类型
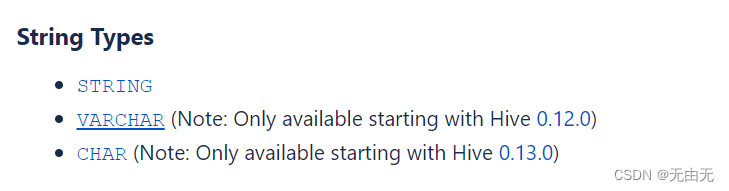
(4)杂项类型

2.集合数据类型

3.类型转换
Hive 的数据类型可以进行隐式转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型,但是 Hive 不会进行反向转化,例如某表达式使用TINYINT类型,INT 不会自动转换为 TINYINT 类型,会返回错误,除非使用 CAST操作。
CAST:进行显示转换。如果强制类型转换失败,会返回空值 NULL。
二、DDL
1.创建表
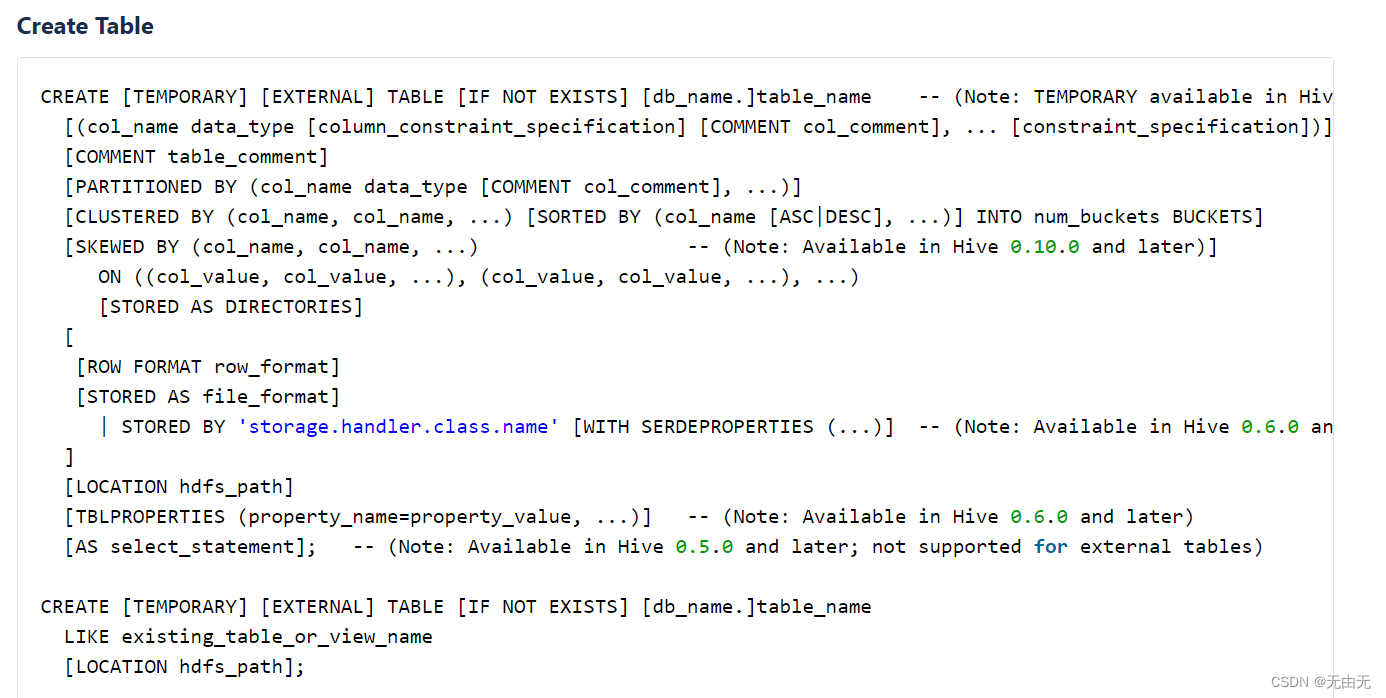
①CREATE TABLE:创建一个指定名字的表。为了防止相同名字的表已经存在,可以通过 IF NOT EXISTS 进行判断。
②EXTERNAL::创建一个外部表。在删除表的时候,外部表只删除元数据,不删除数据。
③COMMENT:为表和列添加注释。
④PARTITIONED BY :创建分区表。
⑤CLUSTERED BY:创建分桶表。
⑥SORTED BY:对分桶表中的一个或多个列另外排序。
⑦ROW FORMAT:指定数据连接格式。
⑧STORED AS: 指定存储文件类型。
⑨LOCATION:指定表在 HDFS 上的存储位置。
⑩AS:后跟查询语句,根据查询结果创建表。
⑪LIKE:复制现有的表结构,但是不复制数据。
2.修改表
(1)重命名表
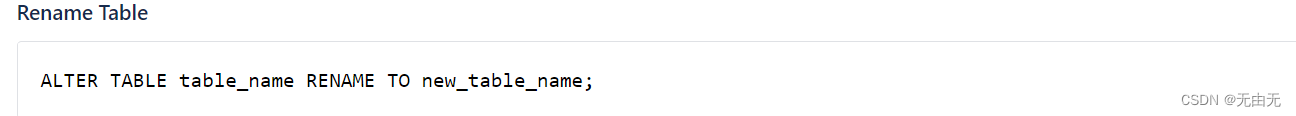
(2)增加分区

(3)重命名分区

(4)删除分区

(5)修改表中的列

(6)替换,新增列

三、DML
1.数据导入
(1)通过Load向表中装载数据
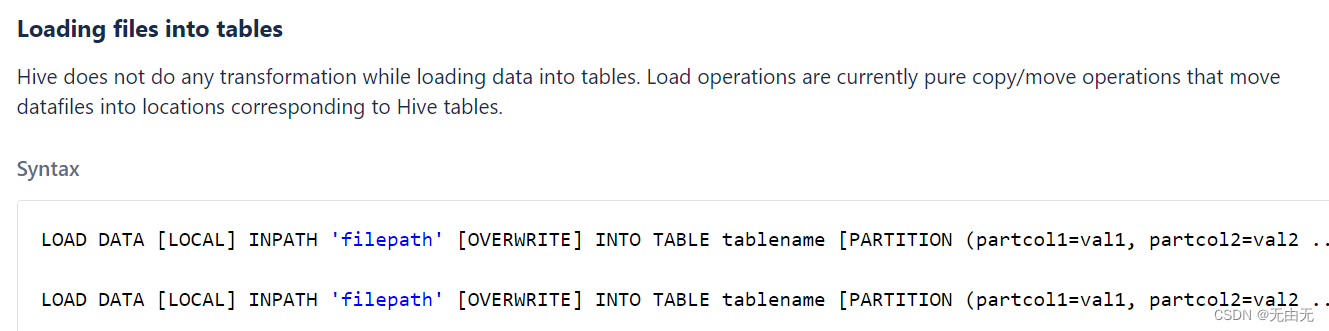
①load data:表示加载数据
②local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
③inpath:表示加载数据的路径
④overwrite:表示覆盖表中已有数据,否则表示追加
⑤partition:表示上传到指定分区
(2)通过values插入数据
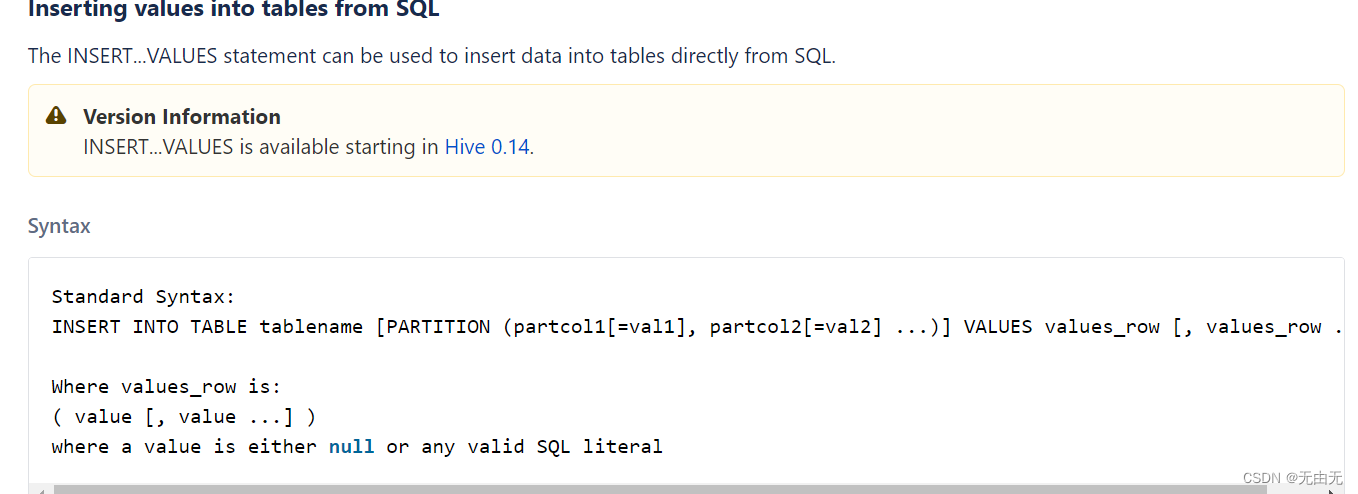
(3)通过查询其他表插入数据

(4)更新数据
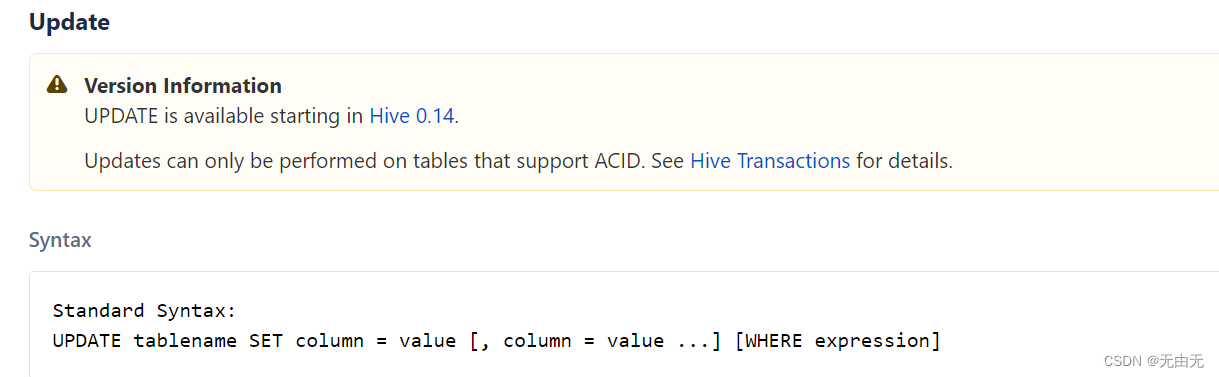
(5) 删除数据
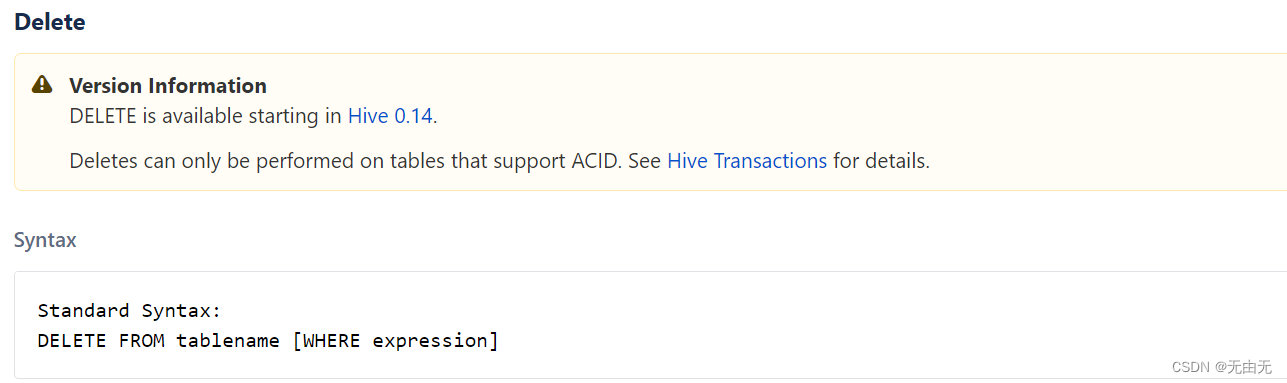
(6)清除表中数据
Truncate 只能删除管理表,不能删除外部表中数据
2.表查询

①DISTINCT:单列和多列的去重
②WHERE:查询的判断条件
③GROUP BY:和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
④ORDER BY:全局排序,只有一个 Reducer。ASC(默认): 升序,DESC: 降序。
⑤CLUSTER BY:当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能,但是排序只能是升序排序,不能指定排序规则为 ASC 或者 DESC。
⑥DISTRIBUTE BY:分区,类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。
⑦SORT BY:Sort by 为每个 reducer 产生一个排序文件。每个 Reducer 内部进行排序。
⑧LIMIT: 用于限制返回的行数。

HAVING:having 只用于 group by 分组统计语句,where 后面不能写分组函数,而 having 后面可以使用分组函数。
3.连接表
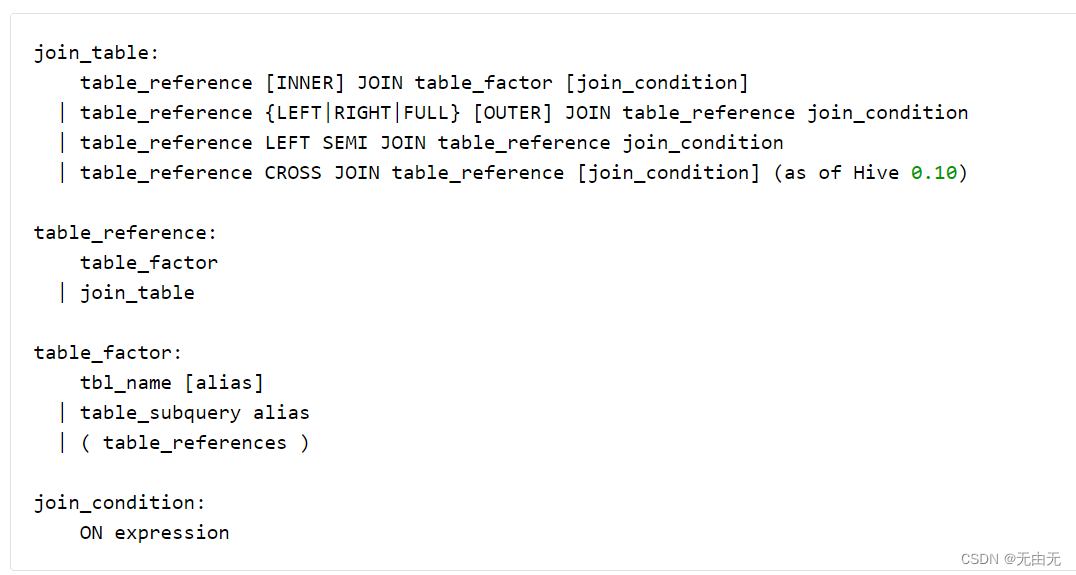
①INNER JOIN:内连接,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
②LEFT JOIN:左外连接,JOIN 操作符左边表中符合 WHERE 子句的所有记录将会被返回。
③RIGHT JOIN:右外连接,JOIN 操作符右边表中符合 WHERE 子句的所有记录将会被返回。
④FULL JOIN:满外连接,将会返回所有表中符合 WHERE 语句条件的所有记录,如果任一表的指定字段没有符合条件的值的话,那么就使用 NULL 值替代。
4.侧写表

Lateral View:写在查询的表后面,和 split, explode 等 UDTF函数 一起使用,能够将UDTF函数的字段与原表做关联,将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。其中udtf为UDTF函数,(expression)为字段内容,tableAlias为侧写表别名,columnAlias为udtf函数字段的别名。
5.合并查询结果

UNION [ALL | DISTINCT]:用来合并多个select的查询结果,需要保证select中字段须一致,每个select语句返回的列的数量和名字必须一样。UNION ALL,其中重复的行不会被删除,UNION的默认行为是从结果中删除重复的行(DISTINCT可以省略)。
6.数据抽样

TABLESAMPLE:将数据分成y个桶,从第x个桶开始抽样,其中x<=y。
四、窗口和分析函数
1.开窗函数
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变话
CURRENT ROW:当前行
n PRECEDING:往前 n 行数据
n FOLLOWING:往后 n 行数据
UNBOUNDED:起点,
UNBOUNDED PRECEDING :表示从前面的起点, UNBOUNDED FOLLOWING: 表示到后面的终点
2.窗口函数

①LAG:往前第 n 行数据
②LEAD:往后第 n 行数据
③FIRST_VALUE:返回第一行数据
④LAST_VALUE:返回最后一行数据
3.聚合函数
4.分析函数

①RANK: 会产生序号相同的记录,同时产生序号间隙。
②ROW_NUMBER:会根据顺序计算排列,不会出现相同的序号。
③DENSE_RANK:也会产生序号相同的记录,但不会产生序号间隙。
④CUME_DIST:当升序排列时,则统计小于等于当前值的行数/总行数的比值 ;当降序排列时,则统计大于等于当前值的行数/总行数的比值。
⑤PERCENT_RANK:计算当前行-1/当前组-1的比值
⑥NTILE:将有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对于每一行,NTILE 返回此行所属的组的编号。
5.多维分析
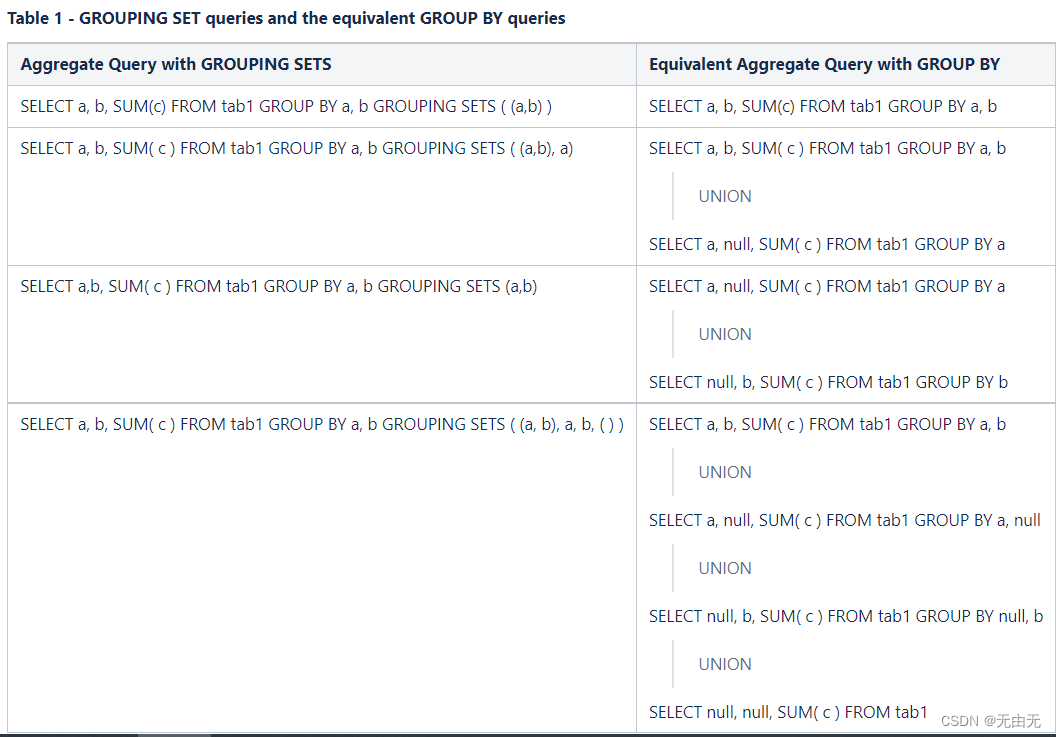
GROUPING SETS:进行不同维度的分析,相当于多个GROUP BY 的UNION。