VGG16-好莱坞明星识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章地址: 365天深度学习训练营-第6周:好莱坞明星识别
- 🍖 作者:K同学啊
一、前期工作
1. 设置GPU
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
gpus [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2. 导入并查看数据
data_dir = pathlib.Path("./data/")
image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:",image_count)图片总数为: 1800
roses= list(data_dir.glob('train/nike/*.jpg'))
PIL.Image.open(str(roses[0]))
二、数据预处理
1. 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
测试集与验证集的关系:
- 验证集并没有参与训练过程梯度下降过程的,狭义上来讲是没有参与模型的参数训练更新的。
- 但是广义上来讲,验证集存在的意义确实参与了一个“人工调参”的过程,我们根据每一个epoch训练之后模型在valid data上的表现来决定是否需要训练进行early stop,或者根据这个过程模型的性能变化来调整模型的超参数,如学习率,batch_size等等。
- 因此,我们也可以认为,验证集也参与了训练,但是并没有使得模型去overfit验证集
batch_size = 32
img_height = 224
img_width = 224train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="training",
label_mode = "categorical", #### 新增
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes. Using 1620 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="validation",
label_mode = "categorical", #### 新增
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes. Using 180 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
2. 可视化数据
import numpy as np
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")
3. 再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break(32, 224, 224, 3) (32,17)
4. 配置数据集
- shuffle() :打乱数据,关于此函数的详细介绍可以参考:数据集shuffle方法中buffer_size的理解 - 知乎
- prefetch() :预取数据,加速运行
prefetch()功能详细介绍:CPU 正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU 处于空闲状态。因此,训练所用的时间是 CPU 预处理时间和加速器训练时间的总和。prefetch()将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第 N 个训练步时,CPU 正在准备第 N+1 步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态:
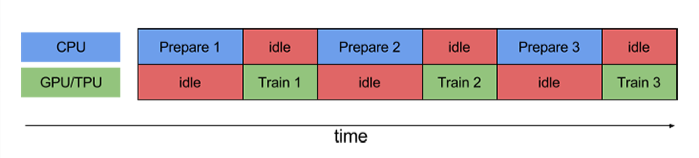
使用prefetch()可显著减少空闲时间:
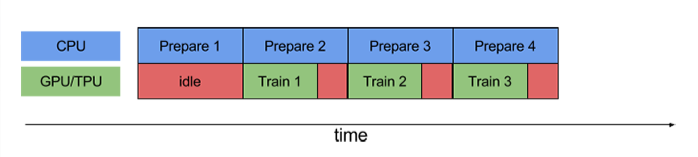
- cache() :将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)三、构建CNN网络
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入的形状是 (224, 224, 3)即彩色图像。我们需要在声明第一层时将形状赋值给参数input_shape。
from tensorflow.keras.regularizers import l2
weight_decay = 0
drop_rate = 0
VGG16_model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3),padding='same',kernel_regularizer=l2(weight_decay), activation='relu', input_shape=(img_height, img_width, 3)),
layers.Dropout(drop_rate),
layers.Conv2D(64, (3, 3), padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Conv2D(128, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(128, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Conv2D(256, (3, 3), padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(256, (3, 3), padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(256, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Dropout(drop_rate),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
])
VGG16_model.summary() # 打印网络结构Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= rescaling (Rescaling) (None, 224, 224, 3) 0 _________________________________________________________________ conv2d (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ dropout (Dropout) (None, 224, 224, 64) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ dropout_1 (Dropout) (None, 224, 224, 64) 0 _________________________________________________________________ average_pooling2d (AveragePo (None, 112, 112, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ dropout_2 (Dropout) (None, 112, 112, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ dropout_3 (Dropout) (None, 112, 112, 128) 0 _________________________________________________________________ average_pooling2d_1 (Average (None, 56, 56, 128) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ dropout_4 (Dropout) (None, 56, 56, 256) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ dropout_5 (Dropout) (None, 56, 56, 256) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ dropout_6 (Dropout) (None, 56, 56, 256) 0 _________________________________________________________________ average_pooling2d_2 (Average (None, 28, 28, 256) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ dropout_7 (Dropout) (None, 28, 28, 512) 0 _________________________________________________________________ conv2d_8 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ dropout_8 (Dropout) (None, 28, 28, 512) 0 _________________________________________________________________ conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ dropout_9 (Dropout) (None, 28, 28, 512) 0 _________________________________________________________________ average_pooling2d_3 (Average (None, 14, 14, 512) 0 _________________________________________________________________ conv2d_10 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ dropout_10 (Dropout) (None, 14, 14, 512) 0 _________________________________________________________________ conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ dropout_11 (Dropout) (None, 14, 14, 512) 0 _________________________________________________________________ conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ dropout_12 (Dropout) (None, 14, 14, 512) 0 _________________________________________________________________ average_pooling2d_4 (Average (None, 7, 7, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________
# 加载VGG16的预训练模型参数
VGG16_model.load_weights('./vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
# 冻结前13层网络参数 保证加载的预训练参数不被改变
for layer in VGG16_model.layers[:13]:
layer.trainable = Falsemodel = models.Sequential([
VGG16_model,
layers.Flatten(),
layers.Dense(1024, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.4),
layers.Dense(128, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.4),
layers.Dense(len(class_names), activation="softmax")
])
model.summary() # 打印网络结构Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= sequential (Sequential) (None, 7, 7, 512) 14714688 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ dense (Dense) (None, 1024) 25691136 _________________________________________________________________ batch_normalization (BatchNo (None, 1024) 4096 _________________________________________________________________ dropout_13 (Dropout) (None, 1024) 0 _________________________________________________________________ dense_1 (Dense) (None, 128) 131200 _________________________________________________________________ batch_normalization_1 (Batch (None, 128) 512 _________________________________________________________________ dropout_14 (Dropout) (None, 128) 0 _________________________________________________________________ dense_2 (Dense) (None, 17) 2193 ================================================================= Total params: 40,543,825 Trainable params: 39,986,193 Non-trainable params: 557,632 _________________________________________________________________
四、训练模型
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
1.设置动态学习率
# 设置初始学习率
initial_learning_rate = 0.0001
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.98, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])损失函数Loss详解:
- binary_crossentropy(对数损失函数)
与 sigmoid 相对应的损失函数,针对于二分类问题。
- categorical_crossentropy(多分类的对数损失函数)
与 softmax 相对应的损失函数,如果是one-hot编码,则使用 categorical_crossentropy
- sparse_categorical_crossentropy(稀疏性多分类的对数损失函数)
与 softmax 相对应的损失函数,如果是整数编码,则使用 sparse_categorical_crossentropy
2.早停与保存最佳模型参数
关于ModelCheckpoint的详细介绍可参考文章 🔗ModelCheckpoint 讲解【TensorFlow2入门手册】
EarlyStopping()参数说明:
monitor: 被监测的数据。
min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。
patience: 没有进步的训练轮数,在这之后训练就会被停止。
verbose: 详细信息模式。
mode: {auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
estore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。
关于EarlyStopping()的详细介绍可参考文章 🔗早停 tf.keras.callbacks.EarlyStopping() 详解【TensorFlow2入门手册】
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
epochs = 100
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1)3. 模型训练
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])Epoch 00064: val_accuracy did not improve from 0.80000
Epoch 00064: early stopping
五、模型评估
1. Loss与Accuracy图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()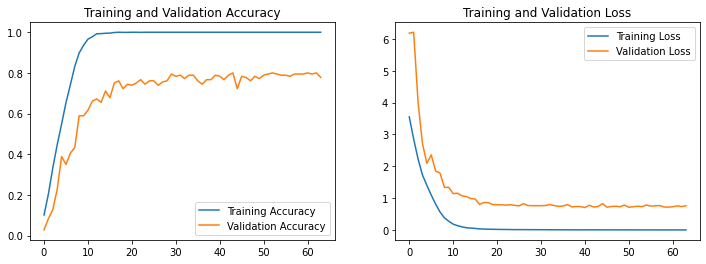
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
from PIL import Image
import numpy as np
img = np.array(Image.open("./hlw/Jennifer Lawrence/001_21a7d5e6.jpg")) #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
预测结果为: Jennifer Lawrence
结论:
以下方法各只简单尝试了1次:
- CNN + AveragePooling2D : 0.37778 (只有简单几层)
- CNN + MaxPooling2D : 0.41111 (只有简单几层)
- VGG16 + MaxPooling2D : 0.46667 (早停)
- VGG16 + AveragePooling2D : 0.48777 (跑完100次)
Loss与Accuracy图上来看,该数据集VGG16 使用 AveragePooling2D效果更好一点。
该模型过于过拟合。后面进行优化,尝试如上文章模型,加入预训练模型参数,效果提升很大,居然有0.8了。
此外在卷积中加入Drop层甚至有反效果,加入BN层后精度提升。
Drop_rate=0,weight_decay = 0 时效果最好。