一道晦涩难懂的Pandas基础题
之前群友分享这样一道Pandas题:
应用pandas模块,导入“python_test.xlsx”的excel中的表格数据(2个sheet)
要求:
将sheet1表数据中Code_A字段按照下列规则替换为sheet2表数据中对应的Code_B字段。
替换规则:
1)、先按City,Year,Month,MonthSort升序排序,然后根据City,Year,Month,MonthSort匹配对应行进行替换
2)、相同City,Year,Month下,Code_A和Code_B的数量可能不同,如果不同,按照下面子规则替换:
(1)Code_A较多时,多出的Code_A暂时不替换(即sheet1的MonthSort大于sheet2的MonthSort的行)
(2)Code_B较多时,多出的Code_B暂时不替换,但相同City,Year后续的月份可能出现Code_A较多的情况,此时将前面月份多出的Code_B按先后顺序替换多出的Code_A。(先多出的Code_B先替换,且多出的Code_B只替换更大月份的Code_A)
(3)最终还剩余多出的Code_A和Code_B不用参与替换。替换只在同City间发生。
3)、最后保留City,Year,Month,MonthSor,Code_A五个字段,将结果导出成excel。将结果excel命名为“result_1.xlsx”
将脚本命名为“python_2.py”
注意:
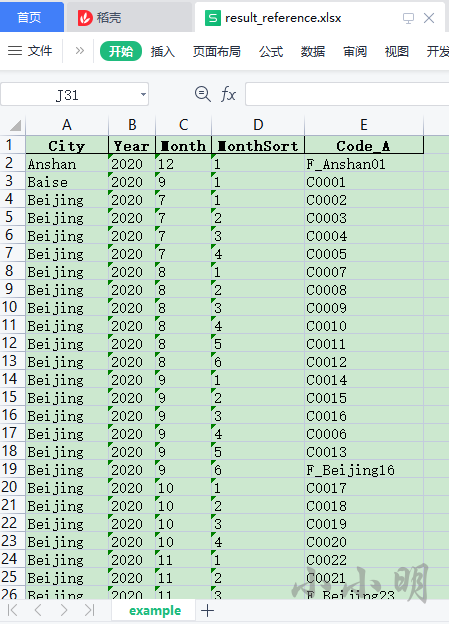
结果可参考result_reference.xlsx文件的example页;
数据集可以到https://gitcode.net/as604049322/blog_data中下载。
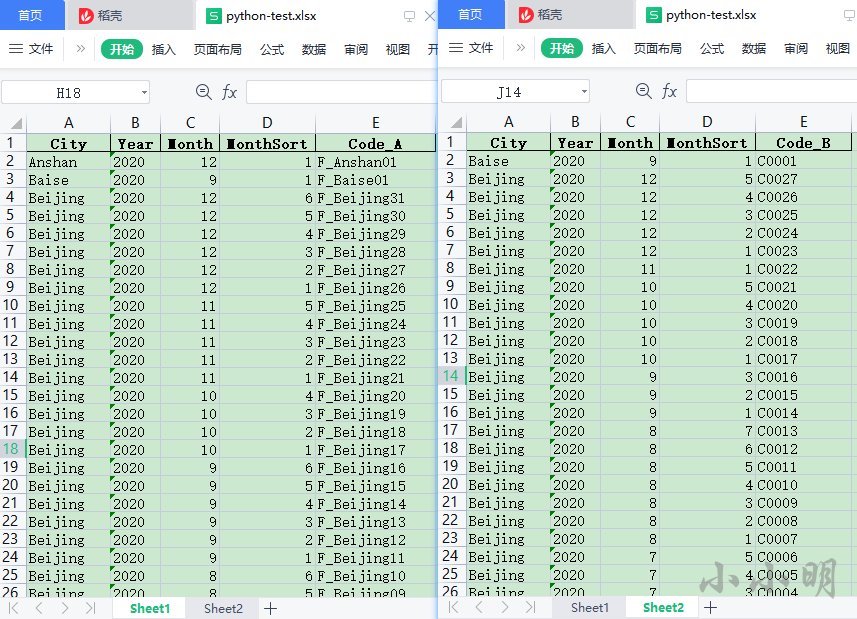
python_test.xlsx中的数据格式如下:
result_reference.xlsx中的结果数据如下:
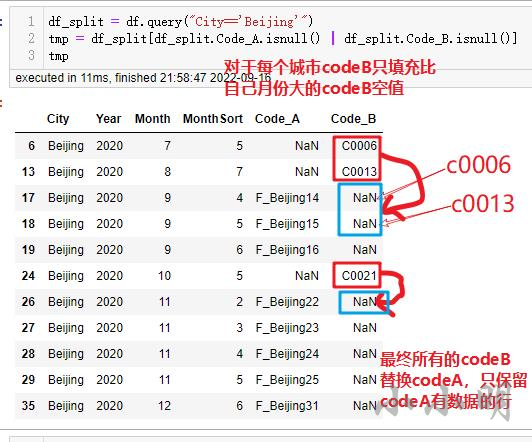
题目题意很难看懂,我在认真对照答案后,核心点翻译如下:
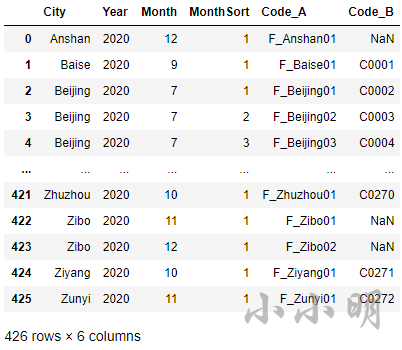
下面我们解决本题,首先读取并合并数据:
import pandas as pd
excel = pd.ExcelFile("python-test.xlsx")
df1 = excel.parse(0)
df2 = excel.parse(1)
df = df1.merge(df2, how="outer", on=['City', 'Year', 'Month', 'MonthSort'])
df.sort_values(['City', 'Year', 'Month', 'MonthSort'],
ignore_index=True, inplace=True)
df
然后一个遍历搞定:
for city, df_split in df.groupby("City"):
idx1 = df_split.index[df_split.Code_A.isnull()].values
idx2 = df_split.index[df_split.Code_B.isnull()].values
i, j = 0, 0
while i < idx1.shape[0] and j < idx2.shape[0]:
if df_split.loc[idx1[i], "Month"] < df_split.loc[idx2[j], "Month"]:
df.loc[idx2[j], "Code_B"] = df_split.loc[idx1[i], "Code_B"]
i += 1
j += 1
df.dropna(subset=["Code_A"], inplace=True)
df.Code_A = df.Code_B.fillna(df.Code_A)
df = df.drop(columns=["Code_B"]).reset_index(drop=True)
df.to_excel("result_1.xlsx", index=False)
df
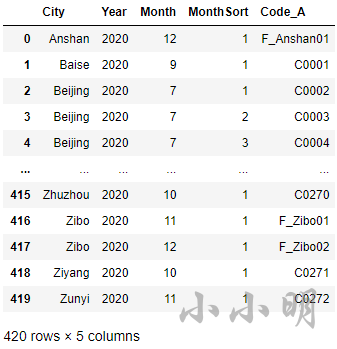
经确认结果无误:
df2 = pd.read_excel("result_reference.xlsx")
print(df.compare(df2))
Empty DataFrame
Columns: []
Index: []
对比差异为空。
然后按要求将以下完整代码保存到python_2.py文件中:
import pandas as pd
excel = pd.ExcelFile("python-test.xlsx")
df1 = excel.parse(0)
df2 = excel.parse(1)
df = df1.merge(df2, how="outer", on=['City', 'Year', 'Month', 'MonthSort'])
df.sort_values(['City', 'Year', 'Month', 'MonthSort'],
ignore_index=True, inplace=True)
for city, df_split in df.groupby("City"):
idx1 = df_split.index[df_split.Code_A.isnull()].values
idx2 = df_split.index[df_split.Code_B.isnull()].values
i, j = 0, 0
while i < idx1.shape[0] and j < idx2.shape[0]:
if df_split.loc[idx1[i], "Month"] < df_split.loc[idx2[j], "Month"]:
df.loc[idx2[j], "Code_B"] = df_split.loc[idx1[i], "Code_B"]
i += 1
j += 1
df.dropna(subset=["Code_A"], inplace=True)
df.Code_A = df.Code_B.fillna(df.Code_A)
df = df.drop(columns=["Code_B"]).reset_index(drop=True)
df.to_excel("result_1.xlsx", index=False)