二道题:分组顺序向下填充 和 标注数据整理
分组顺序向下填充
需求
之前群友分享这样一道Pandas题:
应用pandas模块,导入“python_test.xlsx”的excel中的表格数据(2个sheet)
要求:
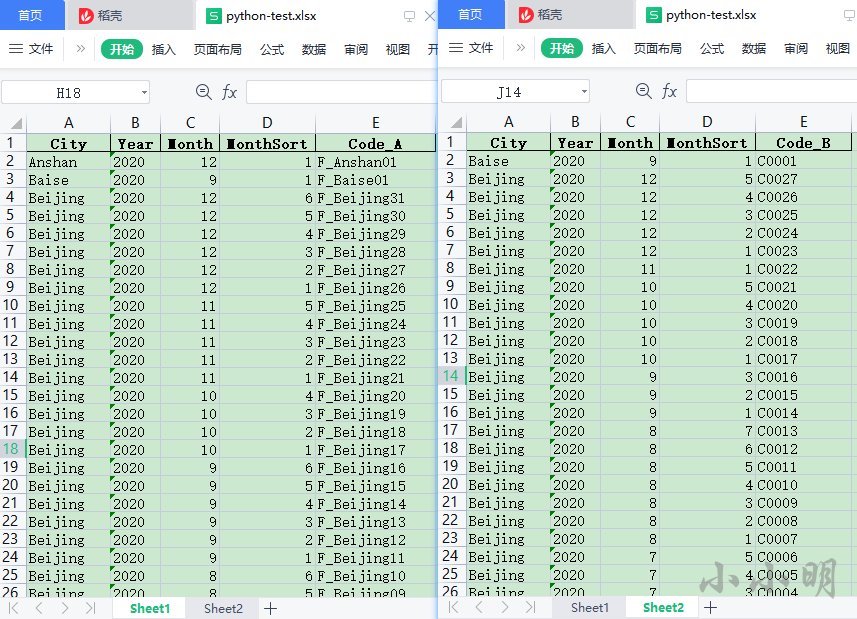
将sheet1表数据中Code_A字段按照下列规则替换为sheet2表数据中对应的Code_B字段。
替换规则:
1)、先按City,Year,Month,MonthSort升序排序,然后根据City,Year,Month,MonthSort匹配对应行进行替换
2)、相同City,Year,Month下,Code_A和Code_B的数量可能不同,如果不同,按照下面子规则替换:
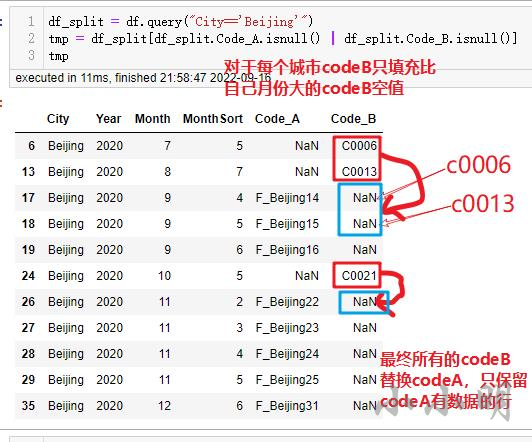
(1)Code_A较多时,多出的Code_A暂时不替换(即sheet1的MonthSort大于sheet2的MonthSort的行)
(2)Code_B较多时,多出的Code_B暂时不替换,但相同City,Year后续的月份可能出现Code_A较多的情况,此时将前面月份多出的Code_B按先后顺序替换多出的Code_A。(先多出的Code_B先替换,且多出的Code_B只替换更大月份的Code_A)
(3)最终还剩余多出的Code_A和Code_B不用参与替换。替换只在同City间发生。
3)、最后保留City,Year,Month,MonthSor,Code_A五个字段,将结果导出成excel。将结果excel命名为“result_1.xlsx”
将脚本命名为“python_2.py”
注意:
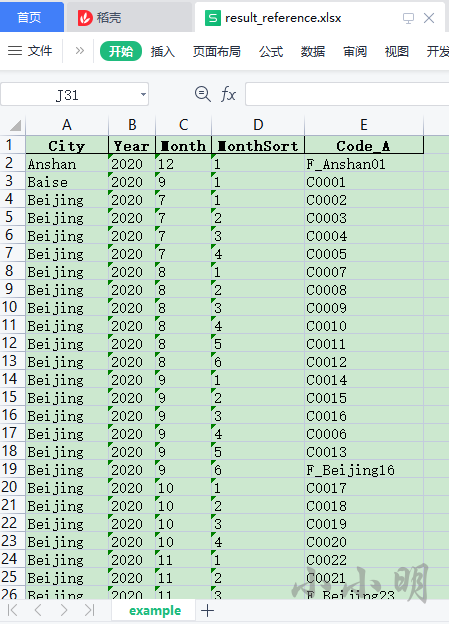
结果可参考result_reference.xlsx文件的example页;
数据集可以到https://gitcode.net/as604049322/blog_data中下载。
python_test.xlsx中的数据格式如下:
result_reference.xlsx中的结果数据如下:
题目题意很难看懂,我在认真对照答案后,题意核心点翻译如下:
解题
下面我们解决本题,首先读取并合并数据:
import pandas as pd
excel = pd.ExcelFile("python-test.xlsx")
df1 = excel.parse(0)
df2 = excel.parse(1)
df = df1.merge(df2, how="outer", on=['City', 'Year', 'Month', 'MonthSort'])
df.sort_values(['City', 'Year', 'Month', 'MonthSort'],
ignore_index=True, inplace=True)
df
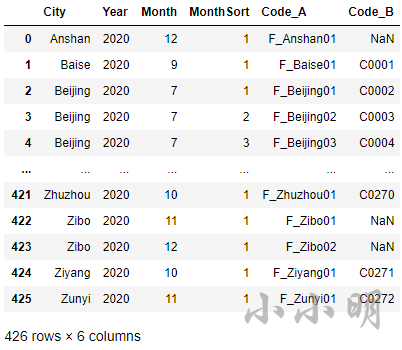
然后一个遍历搞定:
for city, df_split in df.groupby("City"):
idx1 = df_split.index[df_split.Code_A.isnull()].values
idx2 = df_split.index[df_split.Code_B.isnull()].values
i, j = 0, 0
while i < idx1.shape[0] and j < idx2.shape[0]:
if df_split.loc[idx1[i], "Month"] < df_split.loc[idx2[j], "Month"]:
df.loc[idx2[j], "Code_B"] = df_split.loc[idx1[i], "Code_B"]
i += 1
j += 1
df.dropna(subset=["Code_A"], inplace=True)
df.Code_A = df.Code_B.fillna(df.Code_A)
df = df.drop(columns=["Code_B"]).reset_index(drop=True)
df.to_excel("result_1.xlsx", index=False)
df
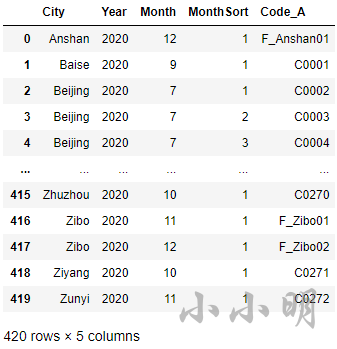
经确认结果无误:
df2 = pd.read_excel("result_reference.xlsx")
print(df.compare(df2))
Empty DataFrame
Columns: []
Index: []
对比差异为空。
然后按要求将以下完整代码保存到python_2.py文件中:
import pandas as pd
excel = pd.ExcelFile("python-test.xlsx")
df1 = excel.parse(0)
df2 = excel.parse(1)
df = df1.merge(df2, how="outer", on=['City', 'Year', 'Month', 'MonthSort'])
df.sort_values(['City', 'Year', 'Month', 'MonthSort'],
ignore_index=True, inplace=True)
for city, df_split in df.groupby("City"):
idx1 = df_split.index[df_split.Code_A.isnull()].values
idx2 = df_split.index[df_split.Code_B.isnull()].values
i, j = 0, 0
while i < idx1.shape[0] and j < idx2.shape[0]:
if df_split.loc[idx1[i], "Month"] < df_split.loc[idx2[j], "Month"]:
df.loc[idx2[j], "Code_B"] = df_split.loc[idx1[i], "Code_B"]
i += 1
j += 1
df.dropna(subset=["Code_A"], inplace=True)
df.Code_A = df.Code_B.fillna(df.Code_A)
df = df.drop(columns=["Code_B"]).reset_index(drop=True)
df.to_excel("result_1.xlsx", index=False)
标注数据整理
需求
背景:
有一张图片, 其上用矩形框标注出数目不定的若干对象. 每个对象有若干属性, 每个属性值为预定的值之一.
要求解析输入数据, 适配成人和程序方便阅读的csv格式, 打印或保存结果.输入:
输入数据有两个, assignment描述的是标注需求, annotations描述的是标注结果.
输入数据示例如下:
assignment_sample = { # assignment 顶层为python字典
'type': 'rectangle', # 标注对象工具类型, 题目中只有矩形框一种, 可忽略
'properties': [{ # 要求标注对象的属性. 数组, 其中每个字典描述一个属性, 数目不定
'id': 1, # 此属性项的唯一id
'name': '对象类型', # 此属性项的名称
'items': ['行人', '车'], # 属性值备选项. 对应annotations中的属性值为其中之一.
}],
}
annotations_sample = [{ # 标注结果, 数组, 其中每个元素描述一个标注对象. 图里画了多少框, 就有多少个
'object_id': 1, # 一张图中标注对象的唯一id
'rectangle': { # 题目只有矩形框
'x1': 100, # 框的坐标, 整数. (x1, y1)是框的左上角点, (x2, y2)是框的右下角点. (图片左上角坐标为(0, 0))
'y1': 10,
'x2': 201,
'y2': 250,
},
'properties': [{ # 每项表示一个属性. 每个属性一定有值, 所以其长度等于assignment中properties的长度
'property_id': 1, # 对应assignment['properties']中的'id', 表示此项是哪个属性项.
'value': '行人', # 标注的属性值
}]
}]
输出:
csv格式, 每行代表一个对象, 要求输出每个对象的object_id和属性值.
第一行为列头, 第一个字段是object_id, 余下每个字段是每个属性的name (如示例中的"对象类型")
下面每个对象顺序无要求, object_id对应正确即可.
直接print出结果或保存为文件均可.上面简单示例的输出结果应为:
object_id,对象类型
1,行人提示: 用python自带的csv.DictWriter.
可参考官方文档: https://docs.python.org/3/library/csv.html
(用手动拼接字符串的方式生成结构化数据是巨大的减分项)进阶需求, 可任选:
1. 输出结果中添加一个字段, 表示框的面积 例如: object_id,对象类型,面积 1,行人,3000 2. 额外打印出每个"对象类型"的框的个数统计, 格式任意 例如: object_id,对象类型,面积,个数 1,行人,3000,1
数据工程师测试题.py中待完整的代码:
def convert_to_csv(assignment, annotations):
# 请补全此函数
raise NotImplementedError
# 程序从这里开始执行
if __name__ == '__main__':
# 输入数据不要改
assignment = {
'type': 'rectangle',
'properties': [{
'id': 1,
'name': '对象类型',
'items': ['小汽车', '大汽车', '人', '自行车'],
}, {
'id': 2,
'name': '是否清晰',
'items': ['是', '否'],
}, {
'id': 3,
'name': '是否完整',
'items': ['完整', '不完整'],
}],
}
annotations = [{
'object_id': 100,
'rectangle': {
'x1': 100,
'y1': 100,
'x2': 150,
'y2': 150,
},
'properties': [{
'property_id': 1,
'value': '自行车',
}, {
'property_id': 2,
'value': '是',
}, {
'property_id': 3,
'value': '完整',
}]
}, {
'object_id': 101,
'rectangle': {
'x1': 200,
'y1': 100,
'x2': 450,
'y2': 150,
},
'properties': [{
'property_id': 1,
'value': '大汽车',
}, {
'property_id': 2,
'value': '是',
}, {
'property_id': 3,
'value': '不完整',
}]
}, {
'object_id': 102,
'rectangle': {
'x1': 100,
'y1': 150,
'x2': 120,
'y2': 150,
},
'properties': [{
'property_id': 3,
'value': '完整',
}, {
'property_id': 1,
'value': '大汽车',
}, {
'property_id': 2,
'value': '否',
}]
}, {
'object_id': 103,
'rectangle': {
'x1': 300,
'y1': 100,
'x2': 400,
'y2': 200,
},
'properties': [{
'property_id': 3,
'value': '完整',
}, {
'property_id': 1,
'value': '人',
}, {
'property_id': 2,
'value': '是',
}]
}]
convert_to_csv(assignment, annotations)
解题
实现函数为:
from collections import Counter
import csv
from io import StringIO
def convert_to_csv(assignment, annotations):
# 请补全此函数
properties = {row["id"]: row["name"] for row in assignment["properties"]}
data = []
c = Counter()
for annotation in annotations:
row = {"object_id": annotation["object_id"]}
for propertie in annotation["properties"]:
row[properties[propertie["property_id"]]] = propertie["value"]
p = annotation["rectangle"]
row["面积"] = (p["x2"]-p["x1"])*(p["y2"]-p["y1"])
c[row["对象类型"]] += 1
data.append(row)
for row in data:
row["个数"] = c[row["对象类型"]]
csvfile = StringIO()
writer = csv.DictWriter(csvfile, fieldnames=data[0].keys())
writer.writeheader()
for row in data:
writer.writerow(row)
csvfile.seek(0)
print(csvfile.read())
结果:
object_id,对象类型,是否清晰,是否完整,面积,个数
100,自行车,是,完整,2500,1
101,大汽车,是,不完整,12500,2
102,大汽车,否,完整,0,2
103,人,是,完整,10000,1