基于机器学习的搜索推荐系统
目录
一. 引言 1
二. 准备 2
一. 软件工程语言选择 2
二. 服务器的选取 2
三. 搜索服务 5
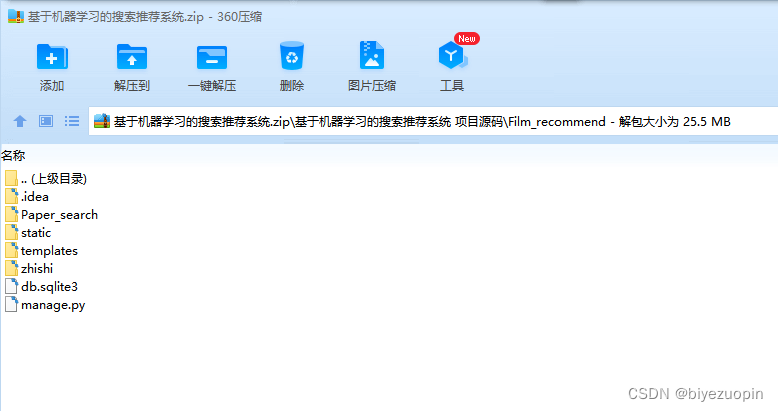
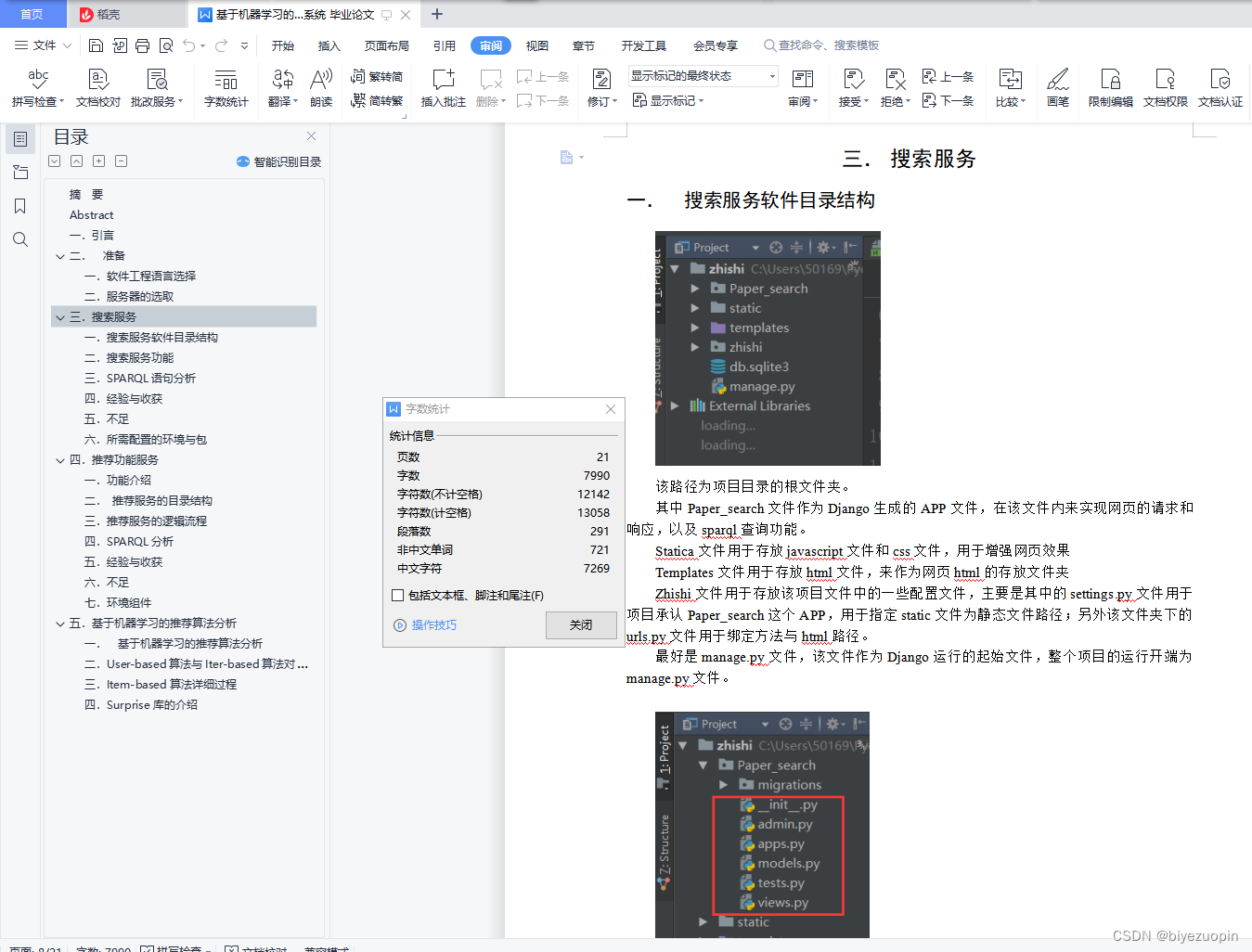
一. 搜索服务软件目录结构 5
二. 搜索服务功能 6
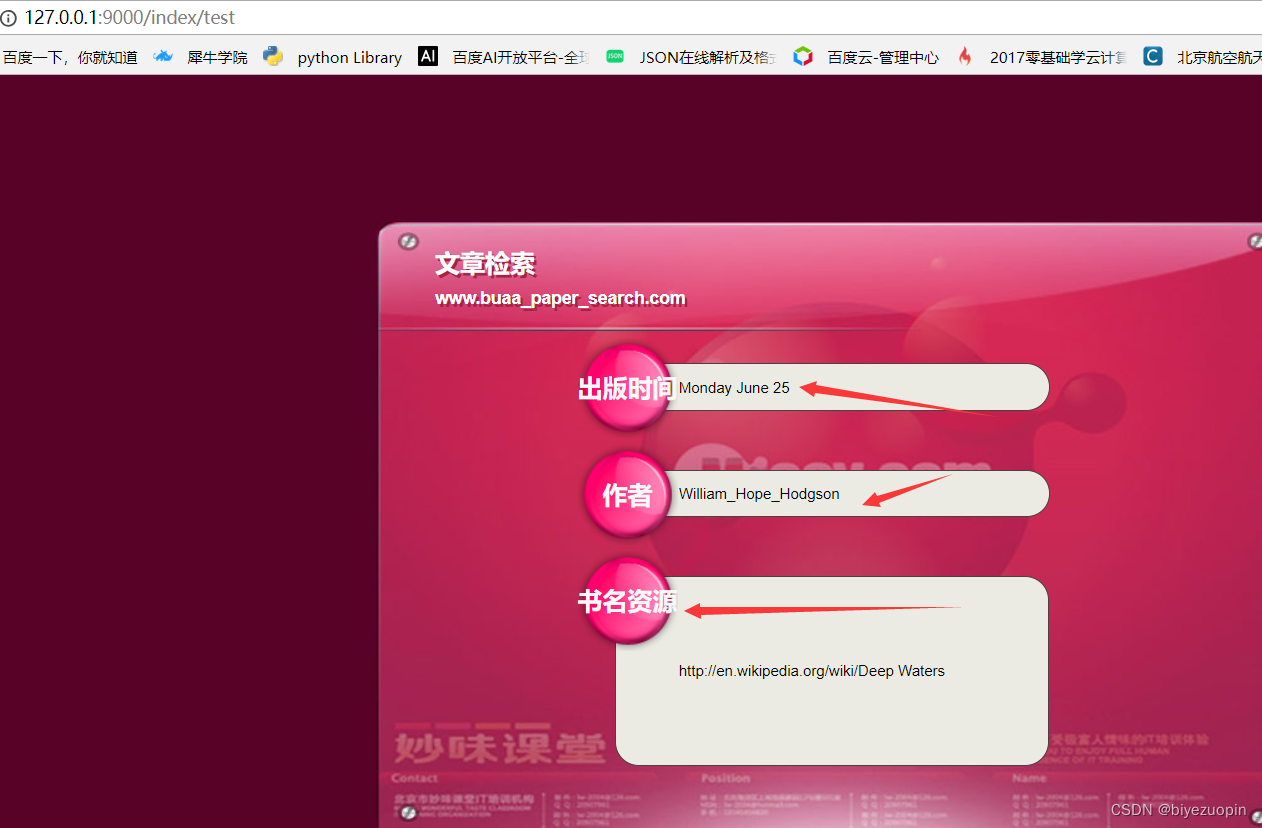
三. SPARQL语句分析 7
四. 经验与收获 8
五. 不足 8
六. 所需配置的环境与包 8
四.推荐功能服务 9
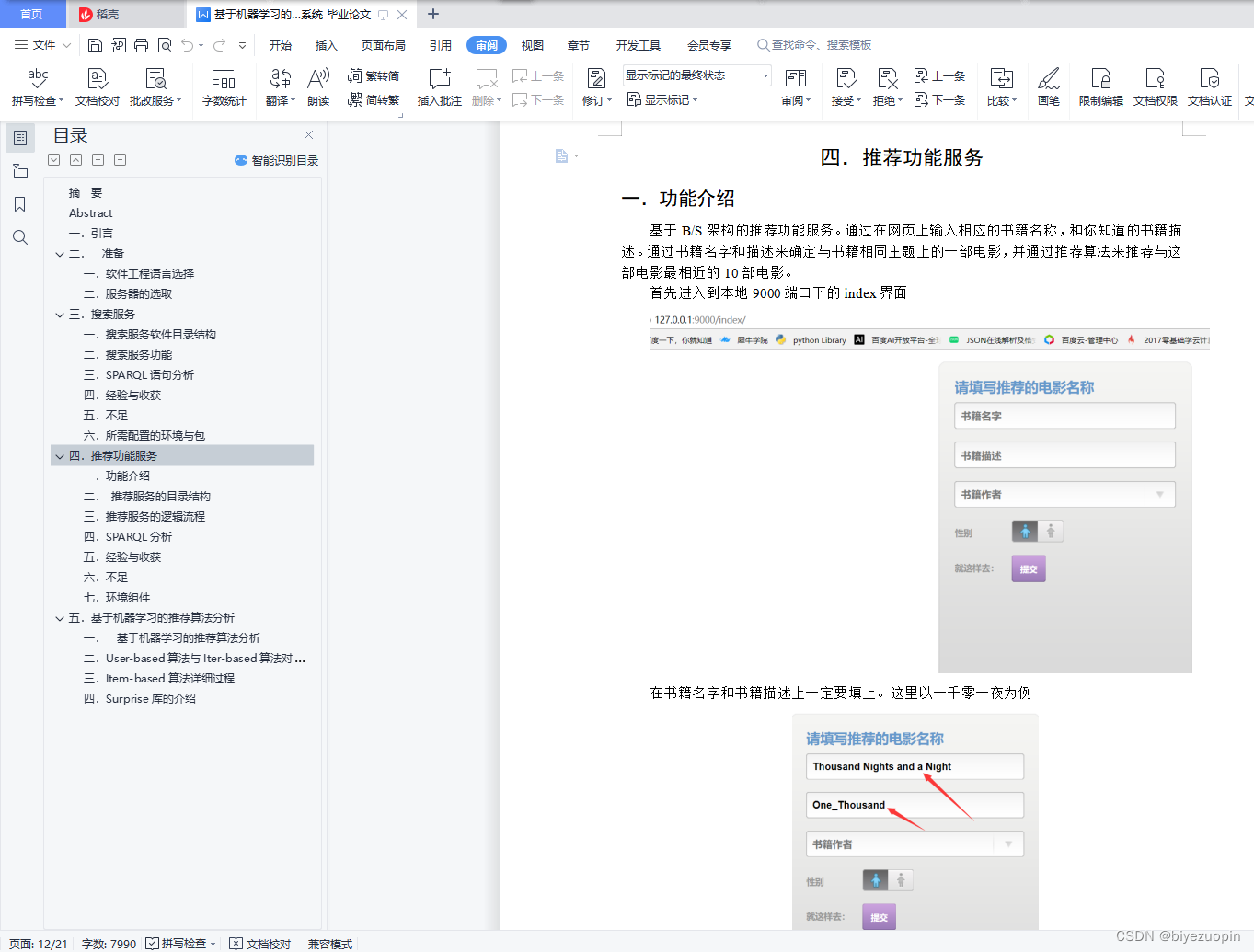
一.功能介绍 9
二. 推荐服务的目录结构 11
三. 推荐服务的逻辑流程 11
四. SPARQL分析 12
五. 经验与收获 13
六. 不足 14
七. 环境组件 14
五.基于机器学习的推荐算法分析 15
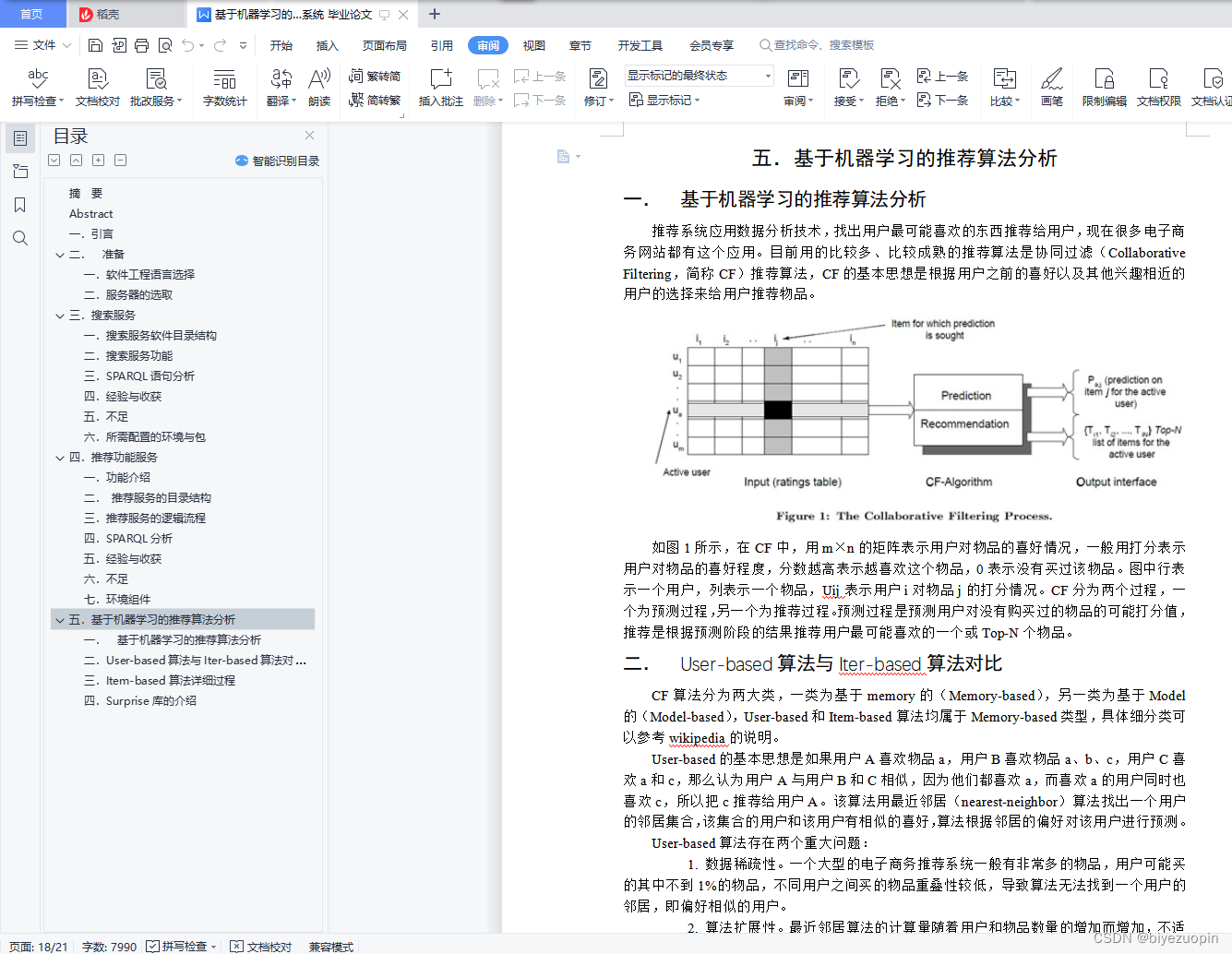
一. 基于机器学习的推荐算法分析 15
二. User-based算法与Iter-based算法对比 15
三. Item-based算法详细过程 16
四. Surprise库的介绍 17
二. 准备
一.软件工程语言选择
世界上有非常多的软件编译语言,主流的有C,C++,JAVA,PYTHON,C#等等。每一种编译语言都有他们自己的特点,每一种编译语言都有他们自己的库和相关的编译工具。用什么样的语言来实现我们搜索和推荐服务是首先要考虑的。
搜索和推荐服务是一个对互联网信息资源进行搜索整理、分类,并储存在网络数据库中供用户查询的系统,包括信息收集,信息分类,和目标查询三个部分组成。
从使用者的角度看,搜索和推荐服务提供一个包含搜索输入框的页面,在搜索框中输入词汇,通过浏览器提交给搜索后台服务引擎后,搜索后台服务引擎就会返回跟用户输入的内容相关的信息列表。其实这样的搜索后台服务引擎涉及到很多领域的理论和技术:数字图书馆,数据库,信息检索,信息提取,人工智能,机器学习,自然语言处理,计算机语言学,统计数据分析,数据挖掘,计算机网络,分布式处理等等,具有综合性和挑战性。
在世界范围内,百度,GOOGLE,搜狗就是非常好的搜索引擎。通过学习这些搜索服务,我们发现他们都是通过Web来进行搜索服务的。
因此我们确定我们的搜索和推荐服务也应当是通过TCP方式,HTTP协议,以Web的方式进行搜索和推荐服务,通过Web来实现搜索和推荐的交互功能。
在实现Web这样的B/S架构时,我们发现两种语言适用于开发这样的服务程序。一个是Java语言,一个是Python语言。
在Java语言中有Tomcat服务来实现网页与后台的相互传参,运算;在Python语言中有Callimachus和Django来实现网页与后台逻辑的通讯。
通过对比Java和Python开发我们发现:
·Java开发所需要的JDK版本一旦安装完成,在同一台PC机上是需要通过卸载重新安装来实现;在Python中对于Python2.7和Python3,我们通过virtualenv和anaconda等虚拟容易来盛放不同的python版本只需要通过cmd(windows下)命令就可以实现。
·Java中的库主要都是对于类型转换,和网页servlet方式的库;在python中不仅包含于网页的相关库,他更强大的是有很多算法库,由于python属于脚本语言,所有他所支持和库所涉及的功能范围比java库要更加多。
·在Java中进行相关的SPARQL查询,需要安装jena,并将安装好的jena文件进行相应的环境变量配置;但是在python中对于sparqlwrapper,只需要通过cmd命令(pip install xxx)就可以静待电脑自动安装相应文件,而不需要配置相应的环境变量。
因此基于以上分析,我们最终选用python来作为我们的软件开发语言。
二.服务器的选取
一个好的关联数据开发平台有助于提高开发效率。Callimachus和Django都是这样的一种平台。
2.1 Callimachus
尽管Callimachus的开发者们将其定义为关联数据管理系统,但是将其视为关联数据的应用服务器更加合适。Callichus主要具备以下特征:
·模板系统能自动为OWL类(OWL class)的所有成员生成网页。严格来说,OWL类与RDF schema类本身或其子类并无二致(取决于所用的OWL配置文件)。简单起见,我们认为OWL类与RDF Schema类是等价的。
·在运行时检索数据,并将其转换为RDF格式。
·将SPARQL查询与URL关联起来,对查询进行参数化,并使用带有图标库(charting library)的查询结果。
·PURL(持久化URL)实现
·基于DocBook的结构化书写系统(structured writing system)包括可视化编辑环境。
简而言之,Callimachus支持使用关联数据进行导航,可视化,构建应用程序等操作。数据既可以保存在本地,也可以从万维网上采集,甚至可以在载入Callimachus时被转换为RDF。
2.2 Django
而Django是一个开放源代码的Web应用框架,由Python写成。采用了MTV的框架模式,即模型M,模板T和视图V。
Django 项目是一个Python定制框架,它源自一个在线新闻 Web 站点,于 2005 年以开源的形式被释放出来。Django 框架的核心优势有:
·用于创建模型的对象关系映射
·为最终用户设计的完美管理界面
·一流的 URL 设计
·设计者友好的模板语言
·缓存系统。
Django是一个基于MVC构造的框架。但是在Django中,控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),称为 MTV模式。它们各自的职责如下:
模型(Model),即数据存取层:
处理与数据相关的所有事务:如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等。
模板(Template),即业务逻辑层:
处理与表现相关的决定: 如何在页面或其他类型文档中进行显示。一般将网页html和js文件存放在此层中。
视图(View),即表现层
存取模型及调取恰当模板的相关逻辑。模型与模板的桥梁。在view里面进行python后台处理,他将网页的响应数据拿到,同时也为网页发送请求。
从以上表述可以看出Django 视图不处理用户输入,而仅仅决定要展现哪些数据给用户,而Django 模板 仅仅决定如何展现Django视图指定的数据。或者说, Django将MVC中的视图进一步分解为 Django视图 和 Django模板两个部分,分别决定 “展现哪些数据” 和 “如何展现”,使得Django的模板可以根据需要随时替换,而不仅仅限制于内置的模板。
2.3 对比
通过使用Callimachus和Django两种服务器我们发现:
1.Django在后台可以植入各种py文件来作为算法和逻辑基础;在Callimachus所有的sparql操作统一下xhtml上div块中进行书写,也就是Callimachus将业务逻辑基本集成在网页上面编写。
2.系统稳定性:Django早在2005年的时候就已经开始使用,网上对于Djano开发时所遇到的问题都有全面的回答,维护起来非常方便;Callimachus是在近几年才推出来的关联数据管理器,他虽然针对关联数据有很好的执行能力,但是在网上不止是关于他运行时的一些解决问题,就连关于他的介绍都微乎其微,在Callimachus运行的时候所遇到的维护问题只能靠自己解决,稳定性不确定,属于试验阶段。
3.开发周期:Django因为有越来越多的人在使用,而且出来较早,对于Django的查询和学习资料较为广泛,开发时间短;Callimachus因为网上资料确实太少,仅有的介绍只是Callimachus的官网说明,本文转载自http://www.biyezuopin.vip/onews.asp?id=14698因此开发难度较大,学习周期长。
基于以上分析,我们最终选用Django服务器来实现我们的搜索和推荐服务。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>文章检索</title>
<link href="/static/Paper_search.css" rel="stylesheet" type="text/css" />
<script type="text/javascript" src="/static/Paper_search.js">
</script>
</head>
<body>
<dl>
<form action="test" method="post">
{%csrf_token%}
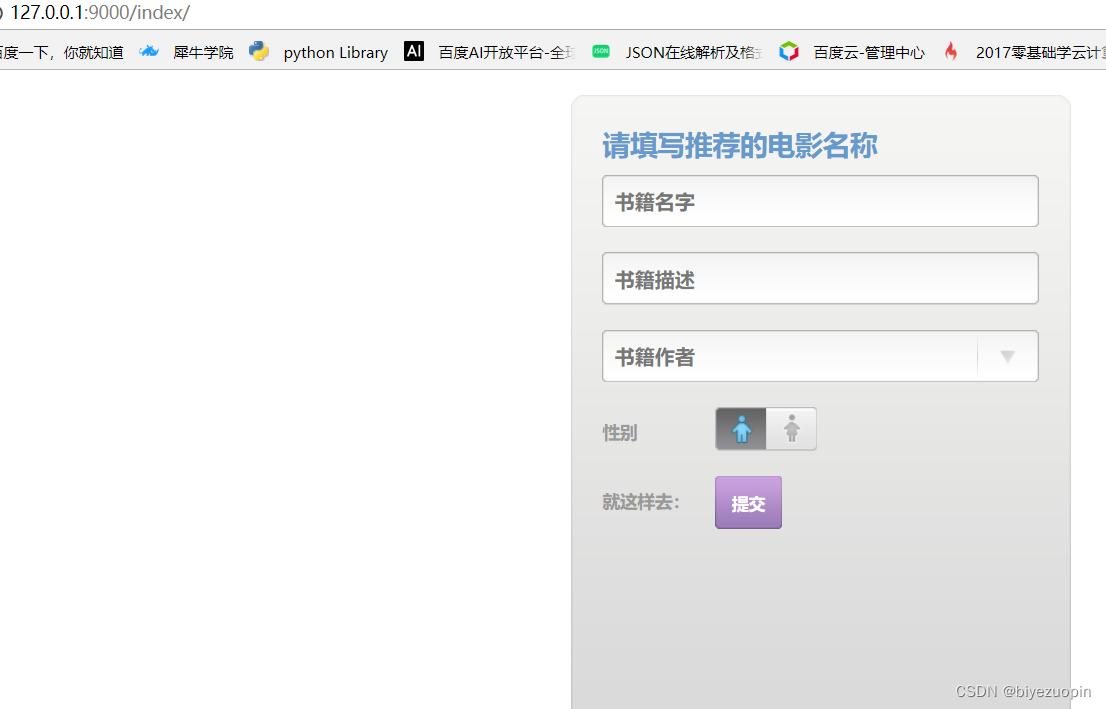
<dt>请填写搜索的相关信息</dt>
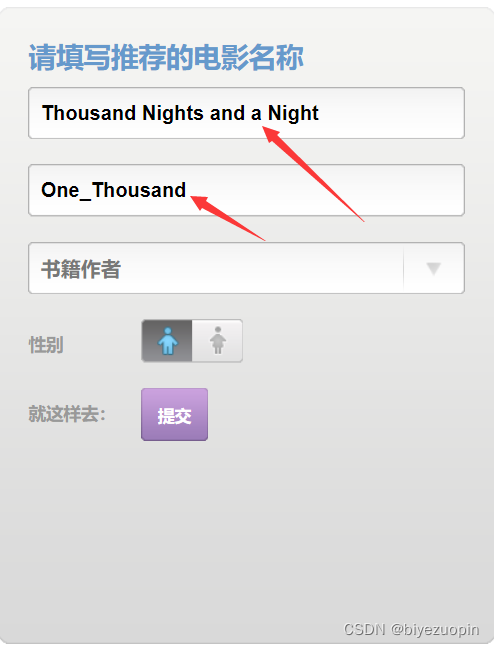
<dd><input id="name" name="paper_name" type="text" class="text" value="文章名字" /></dd>
<dd><input id="contact" name="paper_author" type="text" class="text" value="文章作者" /></dd>
<dd style="z-index: 2;">
<div id="btn_come_from_drop_down" class="select_normal"></div>
<input id="come_from" name="come_from" type="text" class="text" value="作者籍贯" />
<ul id="come_from_drop_down" class="area">
<li class="active">北京</li>
<li>Maine</li>
<li>Prince_Edward_Island</li>
<li>Brooklyn</li>
<li>Thomas Leo Clancy</li>
</ul>
</dd>
<dd class="clear">
<input id="gender" name="gender" type="hidden" />
<h2>性别</h2>
<ul class="sex">
<li id="gender_man" title="男" class="men_active"></li>
<li id="gender_woman" title="女" class="woman_normal"></li>
</ul>
</dd>
<dd>
<h2>就这样去:</h2>
<div class="btn"><input type="submit" value="提交" /></div>
</dd>
</form>
</dl>
</body>
</html>