GAN Step By Step -- Step4 CGAN
GAN Step By Step

心血来潮
GSBS,顾名思义,我希望我自己能够一步一步的学习GAN。GAN 又名 生成对抗网络,是最近几年很热门的一种无监督算法,他能生成出非常逼真的照片,图像甚至视频。GAN是一个图像的全新的领域,从2014的GAN的发展现在,在计算机视觉中扮演这越来越重要的角色,并且到每年都能产出各色各样的东西,GAN的理论和发展都蛮多的。我感觉最近有很多人都在学习GAN,但是国内可能缺少比较多的GAN的理论及其实现,所以我也想着和大家一起学习,并且提供主流框架下 pytorch,tensorflow,keras 的一些实现教学。
在一个2016年的研讨会,杨立昆描述生成式对抗网络是“机器学习这二十年来最酷的想法”。
Step4 CGAN (Conditional GAN)
Conditional GAN
Conditional Generative Adversarial Nets
Authors
Mehdi Mirza, Simon Osindero
Abstract
Generative Adversarial Nets [8] were recently introduced as a novel way to train generative models. In this work we introduce the conditional version of generative adversarial nets, which can be constructed by simply feeding the data, y, we wish to condition on to both the generator and discriminator. We show that this model can generate MNIST digits conditioned on class labels. We also illustrate how this model could be used to learn a multi-modal model, and provide preliminary examples of an application to image tagging in which we demonstrate how this approach can generate descriptive tags which are not part of training labels.
[Paper] [[code]][]

CGAN的全称叫Conditional Generative Adversarial Nets,其实从这个名字来看,与正常的GAN比,多了一个Conditional,condition的意思就是条件,正常的GAN来说,就是通过随机噪声生成图片即可,但是对于CGAN来说,加了一些简单的条件约束,输入了标签,指定去生成特定标签的图片。
我们也可以看一下两者的结构,对于GAN来说,两者的区别就是多了一个c。
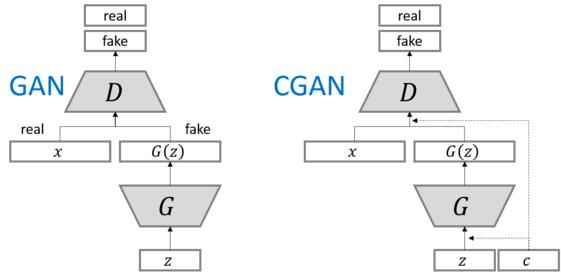
用一句话来总结CGAN,把标签一起送进生成器和判别器,让他们根据标签来生成/判别结果。
我们可以看一看,原始GAN的核心公式:

对于CGAN来说,如果我们已知输入的ground truth的label信息,那么我们便可以在这个基础上结合条件概率的公式得到CGAN的目标函数:

CGAN在生成模型G和判别模型D中同时加入条件约束y来引导数据的生成过程。条件可以是任何补充的信息,如类标签,其它模态的数据等,这样使得GAN能够更好地被应用于跨模态问题,例如图像自动标注。
参考了下【生成对抗网络】Conditional GAN (CGAN,条件GAN) 详细解读, 如下图所示,通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,先验输入噪声p(z)和条件信息y联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。类似地,条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):

MNIST数据集实验
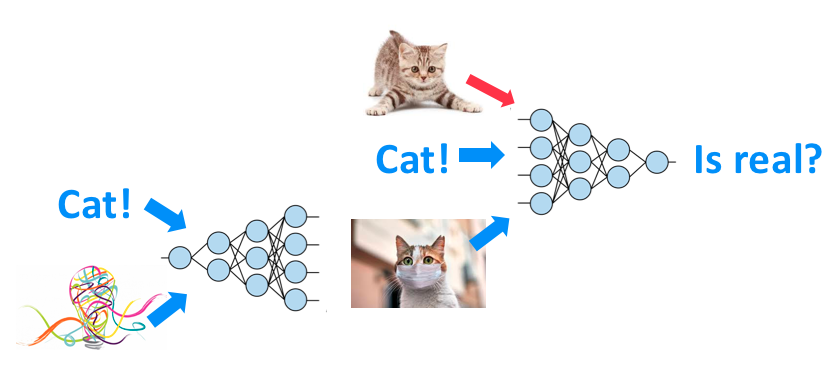
相较于原始的GAN,这个很简单,只需要在训练和预测的时候,在 Generator 和 Discriminator 的输入端多给一个 input,这个 input 作用就是提供一个标签。 让 Generator 知道这张照片该生成什么,让 Discriminator 知道这张照片我应该判别是:它是否是此标签类别。
举个例子,假设在下面这个情况中,条件 c 是 train,图片 x 也是一张清晰的火车照片,那么 D的输出就会是 1。

而在下面两个情况中,左边虽然输出图片清晰,但不符合条件 c;右边输出图片不真实。因此两种情况中 D 的输出都会是 0。

所以改动经典GAN的程度相对比较少,而我们在 mnist 数据加工的时候,还要额外做一道工序,除了拿出手写数字图片,还要将数字标签也拿出来。
生成网络
生成器的输入有两个,一个是高斯噪声noise,一个是由我希望生成的图片的label信息,通过embedding的方法把label调整到和类别相同的维度,再拼接这样便使得noise的输入是建立在label作为条件的基础上。 不懂embedding的同学可以进行学习一下,nn.Embedding层
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
#生成器的输入有两个
# 一个是高斯噪声noise
# 一个是由我希望生成的图片的label信息
# 通过embedding的方法把label调整到和噪声相同的维度,在乘起来这样便使得noise的输入是建立在label作为条件的基础上
# Concatenate label embedding and image to produce input
gen_input = torch.cat((self.label_emb(labels), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *img_shape)
return img
判别网络
对于我们的判别器来说,多层感知机的网络还是类似的,但是多了一个Embedding层,这样我们的判别器的输入包含了图片信息和起对应的标签,我们的判别器不但要判别是否真假,还需要判别是不是图片符合对应的类别信息
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
# Concatenate label embedding and image to produce input
# 判别器的输入包含了图片信息和起对应的标签,我们的判别器不但要判别是否真假,还需要判别是不是图片符合对应的类别信息
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels)), -1)
validity = self.model(d_in)
return validity
训练过程
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
epoch_step = len(dataloader)
with tqdm(total = epoch_step,desc = f'Epoch {epoch+1:3d}/{opt.n_epochs:3d}',postfix=dict,mininterval=0.3) as pbar:
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
# 得到对抗的ground truths,valid全为1, fake全为0
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input 转化数据格式
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# Sample noise and labels as generator input
# z为设置的噪声,用正态分布来随机生成,均值为0,方差为1
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))
# Generate a batch of images
# 生成一个batch的图片,并且CGAN加入生成的labels
gen_imgs = generator(z, gen_labels)
# ---------------------
# Train Discriminator 训练判别器
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
validity_real = discriminator(real_imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid) # 判别真实图片的损失
# Loss for fake images
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake) # 判别生成图片的损失
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
d_x = validity_real.mean() # 得到判别正确图片的准确率
d_g_z1 = validity_fake.mean() # 得到判别错误图片的准确率
d_loss.backward() # 进行反向传播
optimizer_D.step() # 更新参数
# -----------------
# Train Generator 训练生成器
# -----------------
optimizer_G.zero_grad()
# Loss measures generator's ability to fool the discriminator
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid) # 生成损失
d_g_z2 = validity.mean() # 对生成图片判别的概率
g_loss.backward() # 进行反向传播
optimizer_G.step() # 更新参数
# 每sample_interval个batchs后保存一次images,图片放在images文件夹下
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
# 利用tqdm实时的得到我们的损失的结果
pbar.set_postfix(**{'D Loss' : d_loss.item(),
'G Loss' : g_loss.item(),
'D(x)': '{:.4f}'.format(d_x.item()),
'D(G(z))': '{:.4f} /{:.4f} '.format(d_g_z1, d_g_z2)})
pbar.update(1)
# 进行tensorboard可视化, 得到真实的图片
# 以及记录各个值,这样有助于我们判断损失的变化
img_grid = make_grid(real_imgs)
tbwriter.add_image(tag='real_image',img_tensor=img_grid,global_step=epoch+1)
# img_grid = make_grid(gen_imgs)
tbwriter.add_scalar('D(x)',d_x.item(),global_step=epoch+1)
tbwriter.add_scalar('D(G(z))',d_g_z2.item(),global_step=epoch+1)
tbwriter.add_scalar('dist_loss', d_loss.item(),global_step=epoch+1)
tbwriter.add_scalar('gene_loss',g_loss.item(),global_step=epoch+1)
实验结果

从结果我们可以看的出来,我们的生成器能够很好的根据我们提供的label信息生成对应的图像,我们的CGAN使用非常简单的线性网络,多层感知机,但是依然可以得到所有label对应的分布的图像的,并且这也是一种监督学习,CGAN告诉我们condition是很重要的,并且能在多个领域都能取得比较好的结果,比如说图像自动标注等等。条件GAN思想确实比较简单,作者在paper里面也说了,这只是extremely preliminary,并且之后也延伸出了很多东西,之后也会一起学习。都看到这里了,如果感兴趣的小伙伴们,觉得还不错的话,可以三连支持一下,点赞+评论+收藏,你们的支持就是我最大的动力啦!😄