软件测试常见笔试题总结
http://t.csdn.cn/2fKts
软件测试常见笔试题总结
- 01 mysql
- 1.1 数据库操作
- 1.2 表结构操作
- 1.2.1 创建表
- 1.2.2删除表
- 1. 删除单张表:
- 2. 删除多个表:
- 1.2.3 修改表
- 1. 添加列(属性)
- 2. 删除表(属性)
- 3. 修改属性:数据类型
- 4. 修改字段名
- 1. 3数据基本操作(增、删、改、查)
- 1.3.1 插入数据
- 1. 插入单条
- 2. 插入单条:省略列名
- 3. 插入多条
- 1.3.2 delete
- 1. 清空表内的数据(谨慎操作)
- 2. 有条件的进行删除:
- 1.3.3 更新数据
- 1. 更新单个字段值(整列更新)
- 2. 更新多个字段值
- 3. 根据条件更新
- 1.3.4 select
- 1. 单列查询
- 2. 多列查询
- 3. 使用关键字 distinct 查询
- 4. 使用别名查询
- 5. 条件查询
- 6. 范围搜索范围
- 7. 列表搜索条件
- 8. and 和or
- 9. 空或非空查询
- 10. 模糊查询
- 11. 分组(有点像去重)
- 12. 排序 order by
- 13. 分页查询 limit
- 14. 聚合函数
- 15. having和where区别
- 1.3.5 多表查询
- 1. 数据准备
- 2. 内连接
- 3. 左连接(包含左表所有数据)
- 4. 右连接(包含右表所有数据)
- 5. 自连接
- 5. 子查询
- 1.3.6 案例练习
- 02 linux
- 2.1 find
- 2.2cat
- 2.2 tail
- 2.3 head
- 2.4 grep
- 2.5 sed
- 2.6 awk
- 2.7 综合案例
- 2.8 其他常用命令
01 mysql
1.1 数据库操作
1. 查询所有数据库
show databases;

2. 创建数据库
- 语句:create database 数据库名;
- 实例:create database tests;

3. 查看数据库详情
- 语句:show create database 数据库名;
- 实例:show create database tests;

4. 创建数据库指定字符集
- 语句:create database 数据库名 character set gbk/utf8;
- 实例:create database tests_1005 character set utf8;

5. 删除数据库
- 语句:drop database 数据库名;
- 实例:drop database tests;

1.2 表结构操作
1.2.1 创建表
- 语法:
create table 表名( 属性名1 数据类型 [约束条件], 属性名2 数据类型 [约束条件], 属性名3 数据类型 [约束条件] ); - 实例1:学生表
create table t_student( `id` int(11) NOT NULL AUTO_INCREMENT, `num` int(11) NOT NULL COMMENT '学生编号', `name` varchar(128) NOT NULL COMMENT '学生姓名', `age` int(11) COMMENT '学生年龄', `class` int(11) NOT NULL COMMENT '学生班级', `created_time` datetime DEFAULT NULL COMMENT '创建时间', `modified_time` datetime DEFAULT NULL COMMENT '最后修改时间', `created_user` varchar(50) DEFAULT NULL COMMENT '创建人', `modified_user` varchar(50) DEFAULT NULL COMMENT '最后修改人', PRIMARY KEY (`id`) )ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;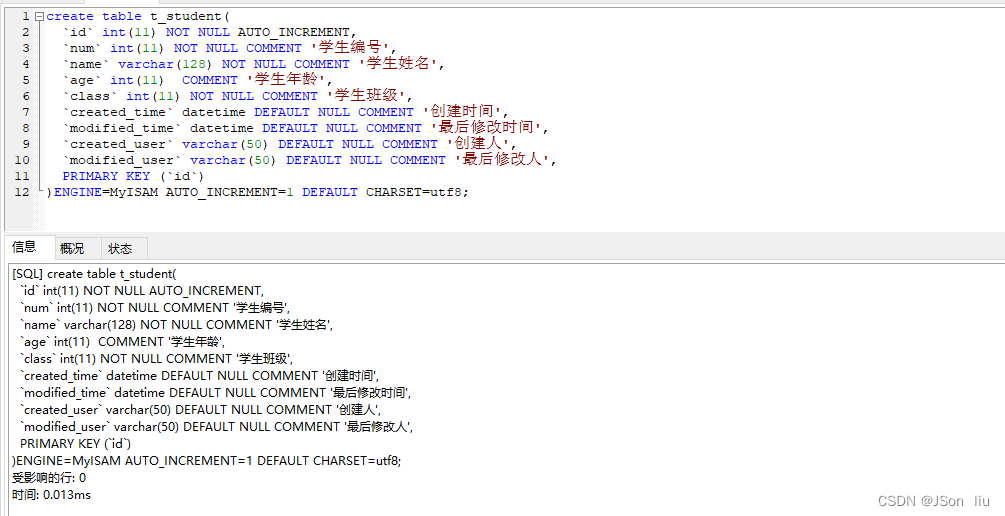
- 实例2:员工表
create table t_employee_info( `id` int(11) NOT NULL AUTO_INCREMENT, `num` int(11) NOT NULL COMMENT '员工编号', `name` varchar(128) NOT NULL COMMENT '员工姓名', `age` int(11) COMMENT '员工年龄', `department` varchar(128) NOT NULL COMMENT '员工部门', `position` varchar(128) NOT NULL COMMENT '员工职位', `working_yeas` int(11) NOT NULL COMMENT '工作年限', `salary` DECIMAL(2) NOT NULL COMMENT '薪资', `created_time` datetime DEFAULT NULL COMMENT '创建时间', `last_modified_date` datetime DEFAULT NULL COMMENT '更新时间', `created_user` varchar(50) DEFAULT NULL COMMENT '创建人', `last_modified_by` varchar(50) DEFAULT NULL COMMENT '更新人', PRIMARY KEY (`id`) )ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;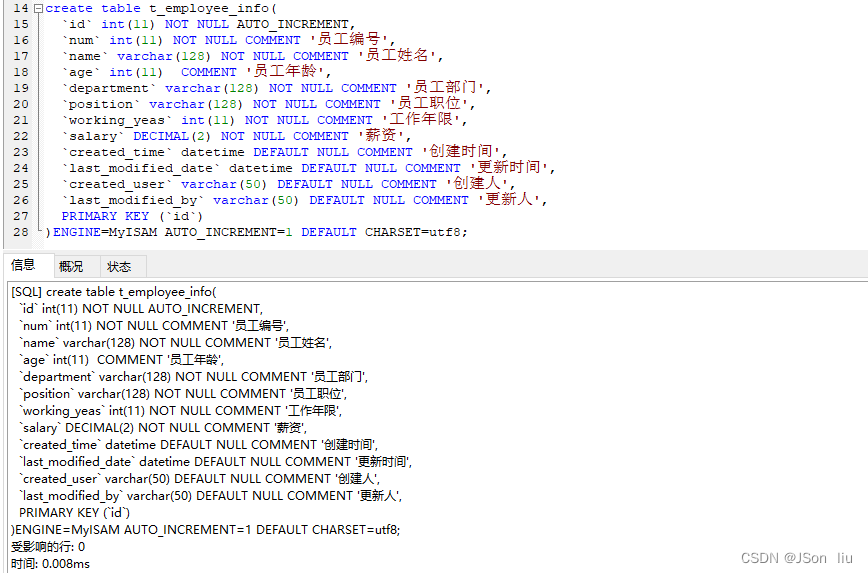
1.2.2删除表
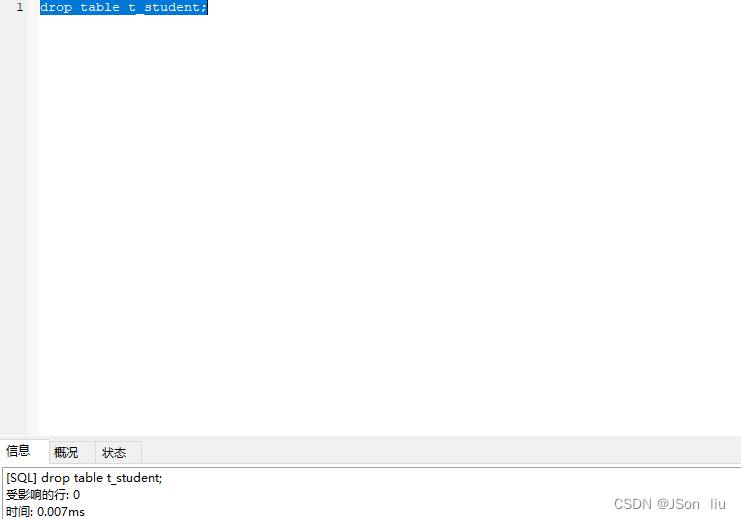
1. 删除单张表:
- 语法:drop table 表名;
- 实例:drop table t_student
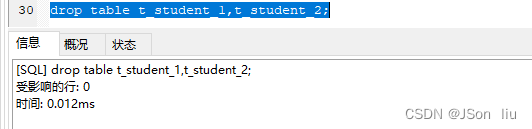
2. 删除多个表:
- 语法:drop table 表名 1,表名 2 …
- 实例:drop table t_student_1,t_student_2;
1.2.3 修改表
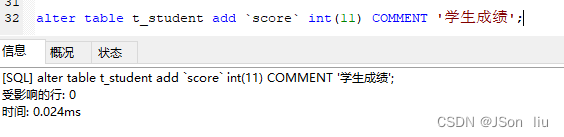
1. 添加列(属性)
- 语法:alter table 表名 add 属性名 数据类型;
- 实例:
alter table t_student add `score` int(11) COMMENT '学生成绩';
2. 删除表(属性)
- 语句:alter table 表名 drop 属性名;
- 实例:
alter table t_student drop `score`;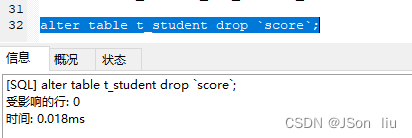
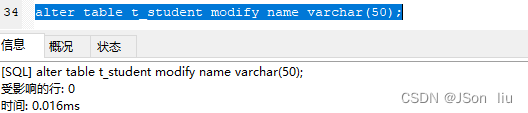
3. 修改属性:数据类型
- 语句:alter table 表名 modify 属性名 数据类型;
- 实例:alter table t_student modify name varchar(50);
4. 修改字段名
alter table 表名 change 旧字段名 新字段名 数据类型;

1. 3数据基本操作(增、删、改、查)
1.3.1 插入数据
1. 插入单条
- 语法: insert into 表名(列名 1,列名 2 …) values(值 1,值 2 …);
- 实例
INSERT into t_student(`id`,`num`,`s_name`,`age`,`class`,`created_time`,`modified_time`,`created_user`,`modified_user`) VALUES( 2,001,'lisi',18,'1201',SYSDATE(),SYSDATE(),'admin','admin')

2. 插入单条:省略列名
- 语法: insert into 表名 values(值 1,值 2 …);
- 实例
INSERT into t_student VALUES( 3,003,'wangwu',18,'1201',SYSDATE(),SYSDATE(),'admin','admin')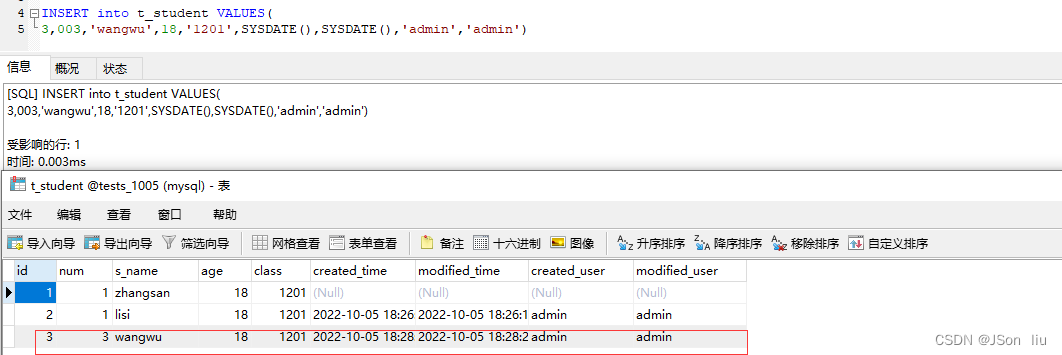
3. 插入多条
- 语法:insert into 表名 values(值 1,值 2,值 3 …),(值 1,值 2,值 3 …);
- 实例:
INSERT into t_student VALUES (4,004,'小红',19,'1203',SYSDATE(),SYSDATE(),'小王','admin'), (5,005,'小王',20,'1202',SYSDATE(),SYSDATE(),'小王','admin'), (6,006,'小菜鸡',21,'1204',SYSDATE(),SYSDATE(),'admin','admin');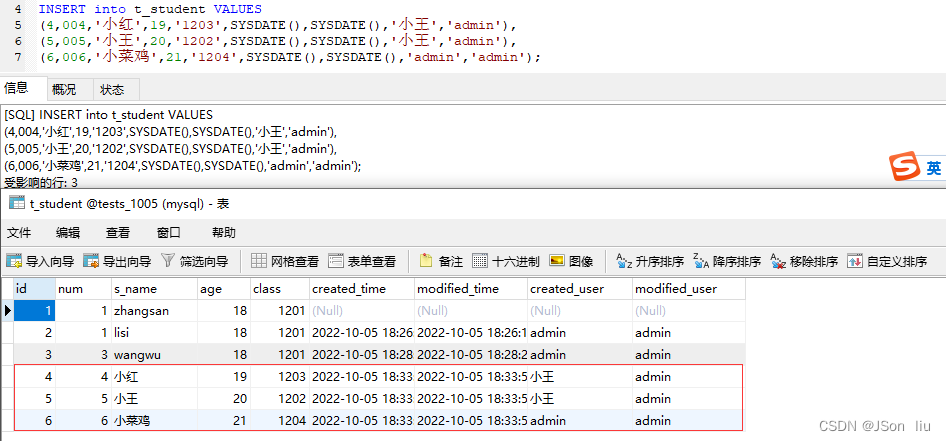
1.3.2 delete
1. 清空表内的数据(谨慎操作)
delete from 表名;
2. 有条件的进行删除:
- 语句:delete from 表名 where 条件;
- 实例:delete from t_student where s_name = ‘zhangsan’;
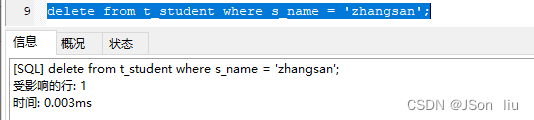
1.3.3 更新数据
1. 更新单个字段值(整列更新)
- 语句:update table_name set 字段=值;
- 案例:update t_student set age=30;
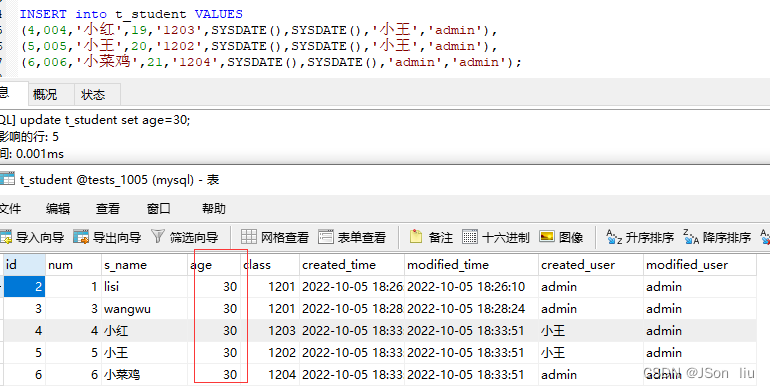
2. 更新多个字段值
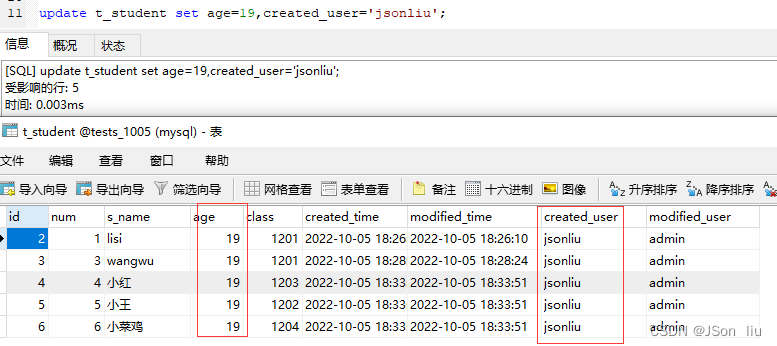
- 语法:update table_name set 字段=值,字段=值;
- 案例:update t_student set age=19,created_user=‘jsonliu’;
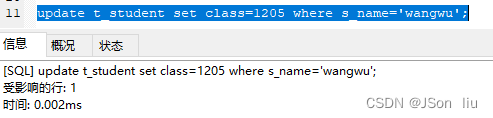
3. 根据条件更新
- 语法:update table_name set 字段=值,字段=值 where 条件;
- 实例:update t_student set class=1205 where s_name=‘wangwu’;
1.3.4 select
1. 单列查询
- 语法:select 列名 from 表名;
- 实例:select s_name from t_student;

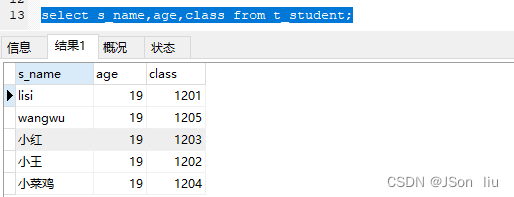
2. 多列查询
- 语法:select 列名 1,列名 2,列名 3 … form 表名;
- 实例:select s_name,age,class from t_student;
3. 使用关键字 distinct 查询
- 在查询返回结果中删除重复行
- 语法:select distinct 列名称 from 表名称;
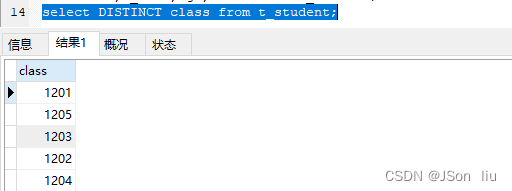
只针对一个列去重 - 实例:查询有多少个班级数
select class from t_student; # 获取所有班级 select DISTINCT class from t_student; # 班级去重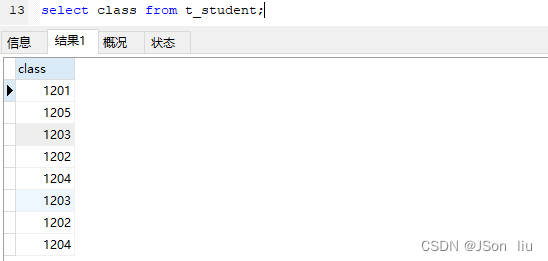
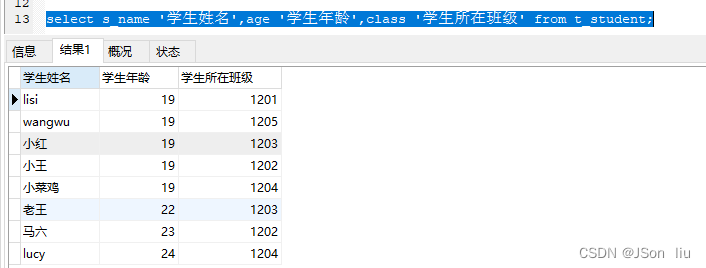
4. 使用别名查询
- 省略as关键字:
- select 列名1 ‘别名’,列名2 ‘别名’,… from 表名;
- 实例:select s_name ‘学生姓名’,age ‘学生年龄’,class ‘学生所在班级’ from t_student;
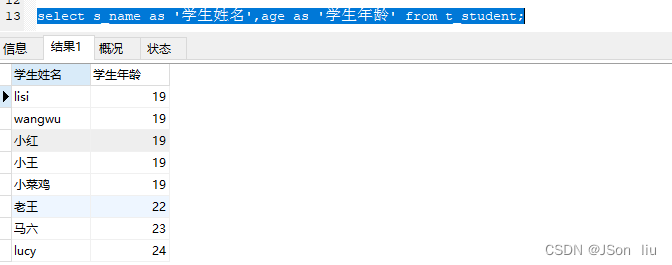
- as关键字:
- select 列名 as ‘别名’ from 表名;
- 实例: select s_name as ‘学生姓名’,age as ‘学生年龄’ from t_student;
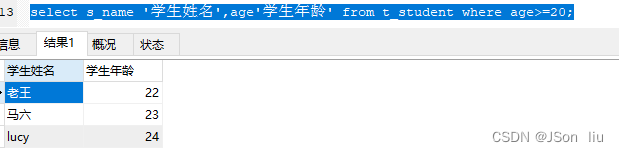
5. 条件查询
- 语法:select 列名 from 表名 where 条件;
- 实例:select s_name ‘学生姓名’,age’学生年龄’ from t_student where age>=20;
6. 范围搜索范围
- 在范围之内
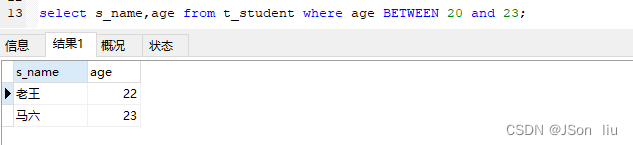
- 语法:select 列名 from where 列名 between 开始值 and 结束值
- 实例:select s_name,age from t_student where age BETWEEN 20 and 23;
- 不在范围之内
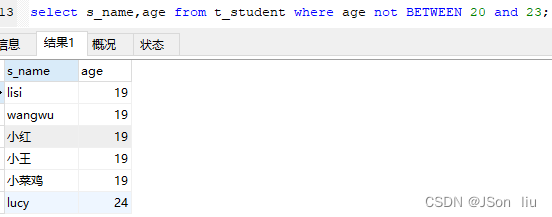
- 语法:select 列名 from 表名 where 列名 not between 开始值 and 结束值;
- 实例:select s_name,age from t_student where age not BETWEEN 20 and 23;
7. 列表搜索条件
in: 只要匹配到括号里任意一个值就会有查询结果;
- in:
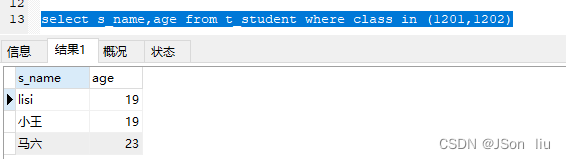
- 语法:select 列名 from 表名 where 列名 in (值 1,值 2,值 3 …)
- 实例: select s_name,age from t_student where class in (1201,1202)
- not in:
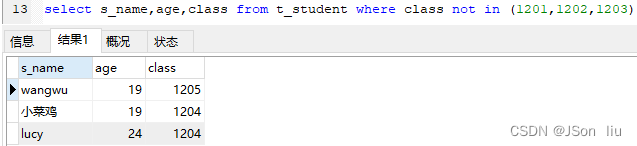
- 语法: select 列名 from 表名 where 列名 not in(值 1,值 2,值 3);
- 实例:select s_name,age,class from t_student where class not in (1201,1202,1203)
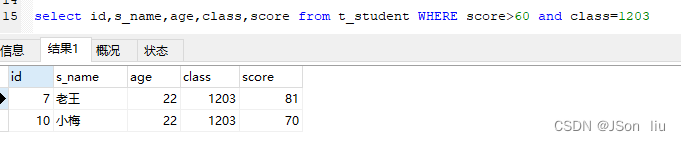
8. and 和or
- 语法:select 列名1,列名2 from 表名 where 条件1 and 条件2 …;
- 实例: select id,s_name,age,class,score from t_student WHERE score>60 and class=1203
9. 空或非空查询
- is null
- 语法:select 列名 from 表名 where 列名 is NULL
- 实例:select id,s_name,age,class,score from t_student WHERE modified_user is NULL

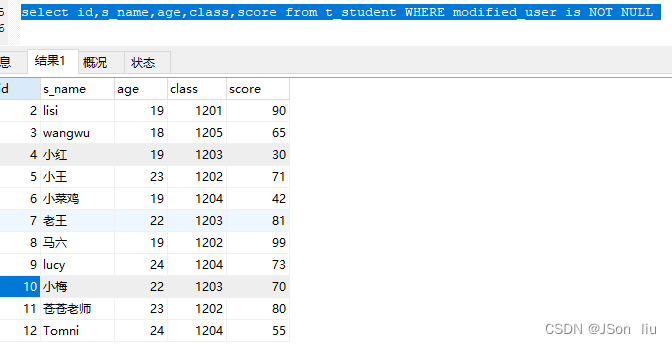
- is not null
- 语法:select 列名 from 表名 where 列名 is NOT NULL
- 实例:select id,s_name,age,class,score from t_student WHERE modified_user is NOT NULL
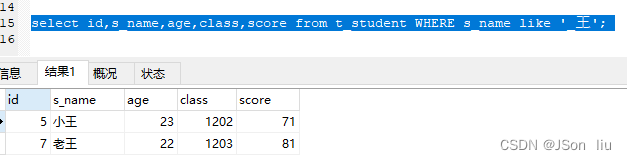
10. 模糊查询
- _:代表单个未知字符
- 实例:select id,s_name,age,class,score from t_student WHERE s_name like ‘_王’;
- 实例:select id,s_name,age,class,score from t_student WHERE s_name like ‘_王’;
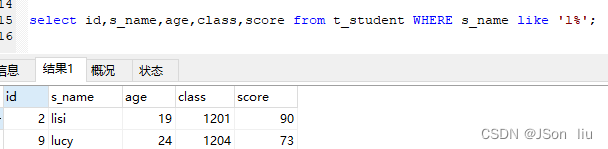
- %:代表0或多个未知字符
- 实例:
- 查询姓名是字母l开头的学生:select id,s_name,age,class,score from t_student WHERE s_name like ‘l%’;
- 查询姓名包含n字母的学生:select id,s_name,age,class,score from t_student WHERE s_name like ‘%n%’;
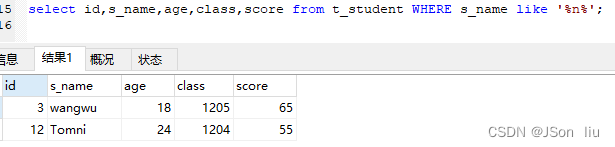
- 查询姓名是字母l开头的学生:select id,s_name,age,class,score from t_student WHERE s_name like ‘l%’;
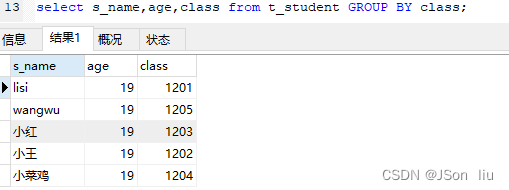
11. 分组(有点像去重)
- 语法:select 列名1,列名2,… from 表名 GROUP BY 列名;
- 实例:select s_name,age,class from t_student GROUP BY class;
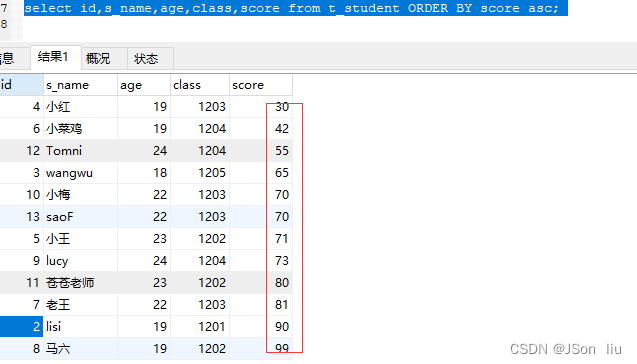
12. 排序 order by
- 升序(asc):
- 语法:select 列名1,列名2,… from 表名 ORDER BY 列名 asc;
- 实例:select id,s_name,age,class,score from t_student ORDER BY score asc;
- 降序(desc):
- 语法:select 列名1,列名2,… from 表名 ORDER BY 列名 desc;
- 实例 :select id,s_name,age,class,score from t_student ORDER BY score desc;
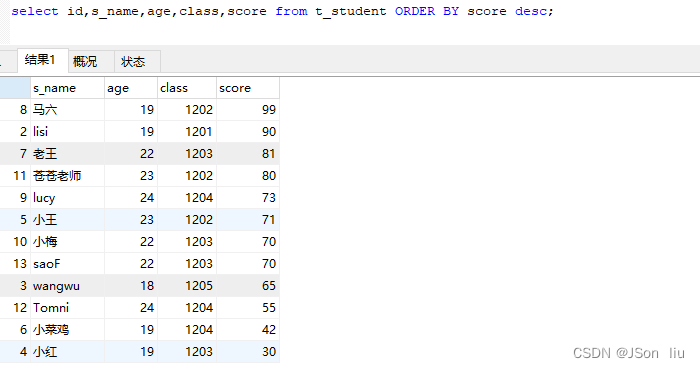
13. 分页查询 limit
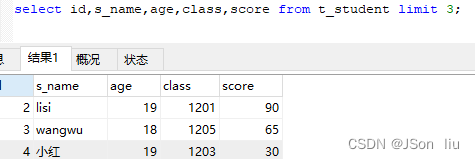
- 语法:select 列名1,列名2,… from 表名 limit 限制页数;
- 实例:select id,s_name,age,class,score from t_student limit 3;
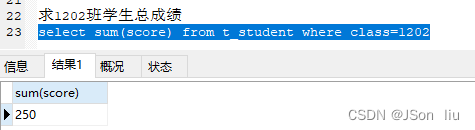
14. 聚合函数
- sum(字段名):
- 语法:select sum(字段名) from 表名 where 条件;
- 实例:select sum(score) from t_student where class=1202;
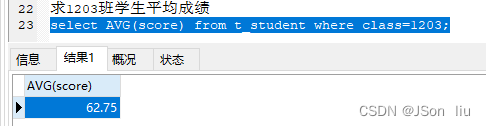
- avg(字段名):
- 语法:select avg(字段名) from 表名 where 条件;
- 实例:select AVG(score) from t_student where class=1203;
- max(字段名):
- 语法:select max(字段名) from 表名 where 条件;
- 实例:select max(score) from t_student where age BETWEEN 22 and 24;
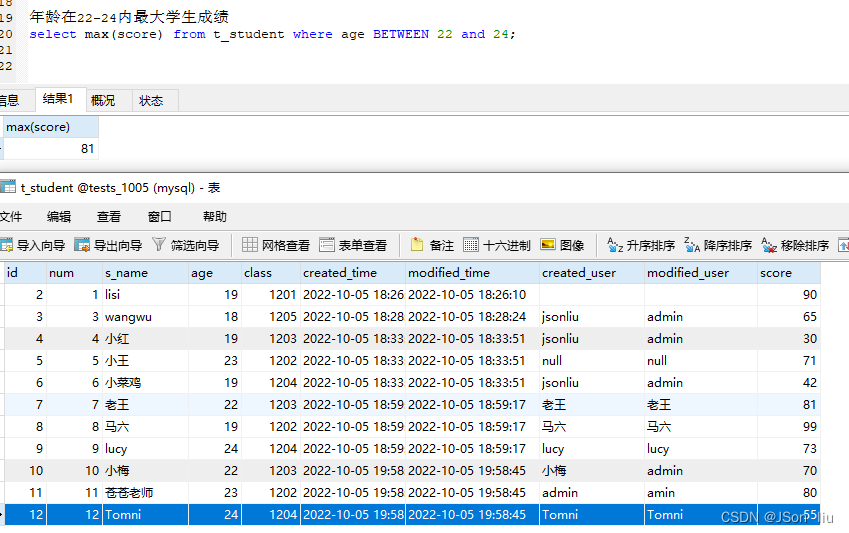
- min(字段名):
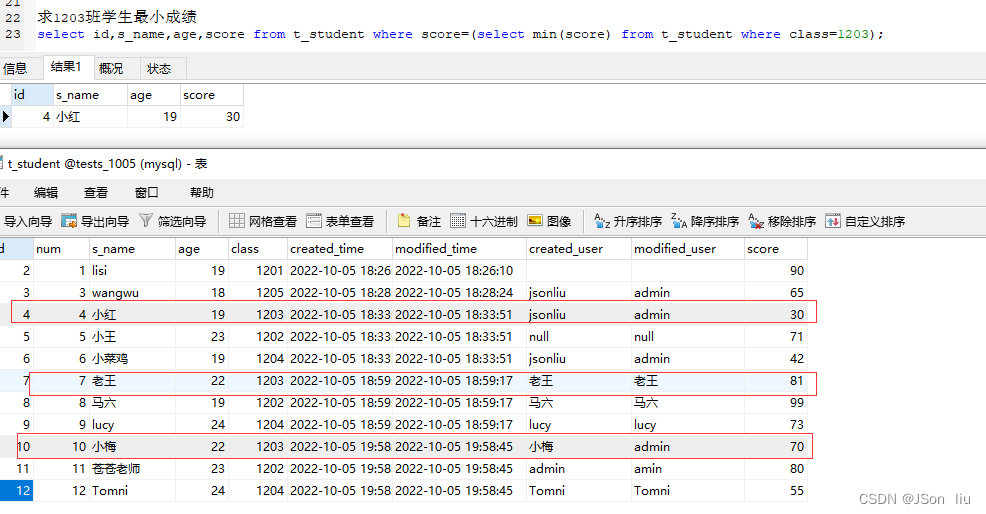
- 语法:select min(字段名) from 表名 where 条件;
- 实例:select id,s_name,age,score from t_student where score=(select min(score) from t_student where class=1203);
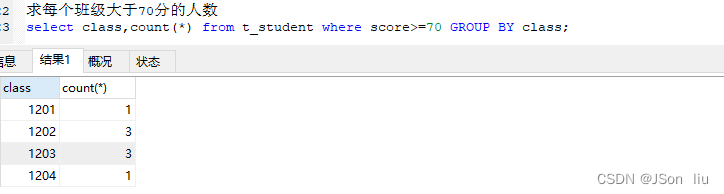
- count(*):
- 语法:select count(*) from 表名 where 条件;
- 实例:select class,count(*) from t_student where score>=70 GROUP BY class;
15. having和where区别
- where查询条件中不可以使用聚合函数,而 having查询条件中可以使用聚合函数
- where在数据分组前进行过滤,而 having在数据分组后进行过滤
- where针对数据库文件进行过滤,而 having针对查询结果进行过滤
- where查询条件中不可以使用字段别名,而 having查询条件中可以使用字段别名
1.3.5 多表查询
1. 数据准备
- 创建dept表,并插入数据
create table dept(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment '部门名称'
)comment '部门表';
INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'),
(5, '总经办'), (6, '人事部'),(7,'测试部'),('8','产品部'),('9','运维部'),('10','售后部');
- 创建emp表,并插入数据
create table emp(
id int auto_increment comment 'ID' primary key,
`name` varchar(50) not null comment '姓名',
age int comment '年龄',
job varchar(20) comment '职位',
salary int comment '薪资',
entrydate date comment '入职时间',
managerid int comment '直属领导ID',
dept_id int comment '部门ID'
)comment '员工表';
- 添加外键
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references
dept(id);
- emp表插入数据
INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id)
VALUES
(1, '张三', 66, '总裁',20000, '2000-01-01', null,5),
(2, '李四', 20, '项目经理',12500, '2005-12-05', 1,8),
(3, '王五', 33, '开发', 8400,'2000-11-03', 2,1),
(4, '马六', 48, '开发',11000, '2002-02-05', 2,1),
(5, '鬼脚七', 43, '运维',10500, '2010-09-07', 1,9),
(6, '马冬梅', 19, '程序员鼓励师',6600, '2004-10-12', 2,1),
(7, '吴老狗', 60, '财务总监',8500, '2002-09-12', 1,3),
(8, '胡八一', 19, '会计',48000, '2006-06-02', 7,3),
(9, '王胖子', 23, '出纳',5250, '2009-05-13', 7,3),
(10, '王凯', 20, '市场部总监',12500, '2004-10-12', 1,2),
(11, '张启山', 56, '测试',3780, '2011-10-03', 1,7),
(12, '二月红', 19, '职员',3750, '2007-05-09', 10,2),
(13, '霍仙姑', 33, '职员',5500, '2009-03-12', 10,2),
(14, '齐八爷', 88, '销售总监',14000, '2004-10-12', 1,4),
(15, '解九爷', 38, '销售',4600, '2004-10-12', 14,4),
(16, '陈皮阿四', 40, '销售',4600, '2004-10-12', 14,4),
(17, '虚竹', 41, '售后',4500, '2003-10-12', 14,10),
(18, '十三姨', 22, '职员',5500, '2012-03-12', 10,2),
(19, '常遇春', 42, null,2000, '2011-10-12', 1,null);
(20, '乔峰', 35, '职员',5500, '2008-03-12', 10,2),
(21, '段誉', 37, '职员',5500, '2002-03-12', 10,2);
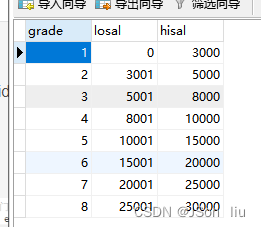
- 创建工资等级表
create table salgrade(
grade int,
losal int,
hisal int
) comment '薪资等级表';
- salgrade表插入数据
insert into salgrade values (1,0,3000);
insert into salgrade values (2,3001,5000);
insert into salgrade values (3,5001,8000);
insert into salgrade values (4,8001,10000);
insert into salgrade values (5,10001,15000);
insert into salgrade values (6,15001,20000);
insert into salgrade values (7,20001,25000);
insert into salgrade values (8,25001,30000);
2. 内连接
- 隐式内连接
- 语法:
from 表名1.列名1,表名1.列名2,表名2.列名1,表名2.列名2... form 表名1,表名2 where 表名1.列=表名2.列; //列为相同的列 - 实例:查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接)
select e.name , d.name from emp e, dept d where e.dept_id = d.id ;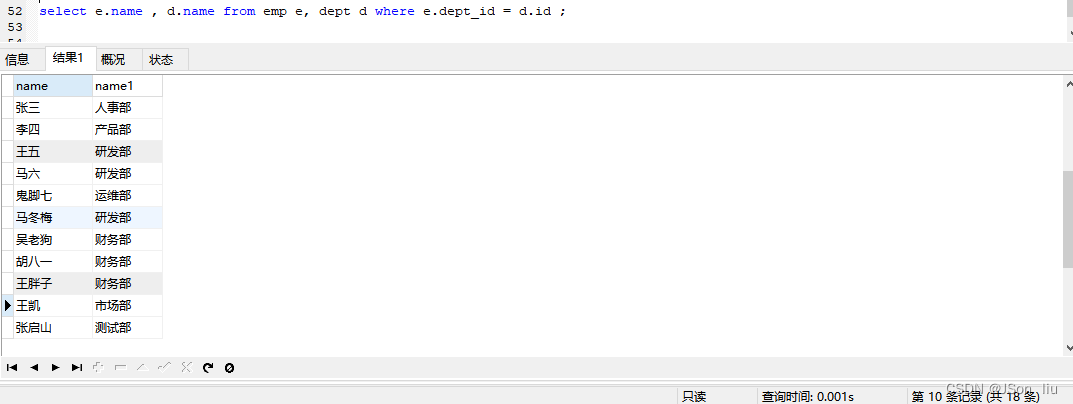
- 语法:
- 显示内连接
- 语法:
from 表名1.列名1,表名1.列名2,表名2.列名1,表名2.列名2... form 表名1 inner join 表名2 on 表名1.列=表名2.列; //列为相同的列- 实例:查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接)
select e.name , d.name from emp e INNER JOIN dept d on e.dept_id = d.id ;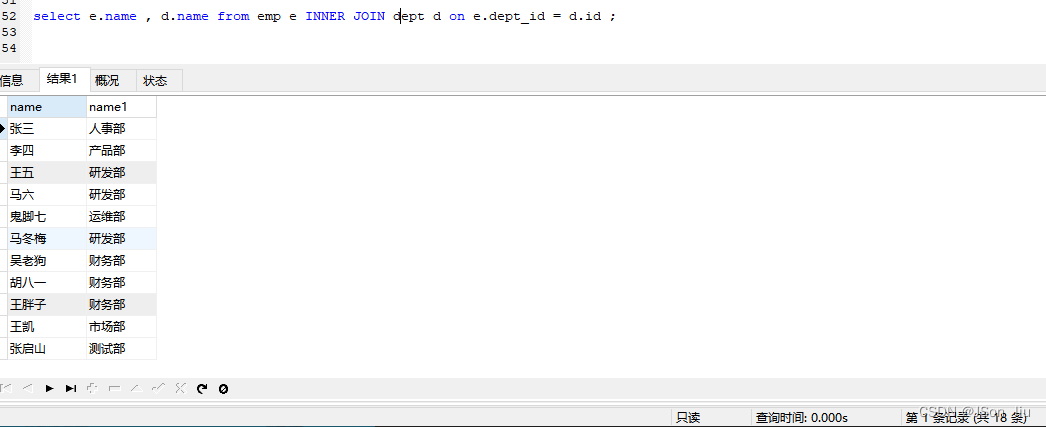
3. 左连接(包含左表所有数据)
- 语法:
select 表名1.列名1,表名1.列名2,表名2.列名2 from 表名1 left outer join 表名2 on 表名1.列=表名2.列; //列为大家共有的列 - 实例:查询emp表的所有数据, 和对应的部门信息
select e.* , d.name from emp e left join dept d on e.dept_id = d.id ;

4. 右连接(包含右表所有数据)
- 语法:
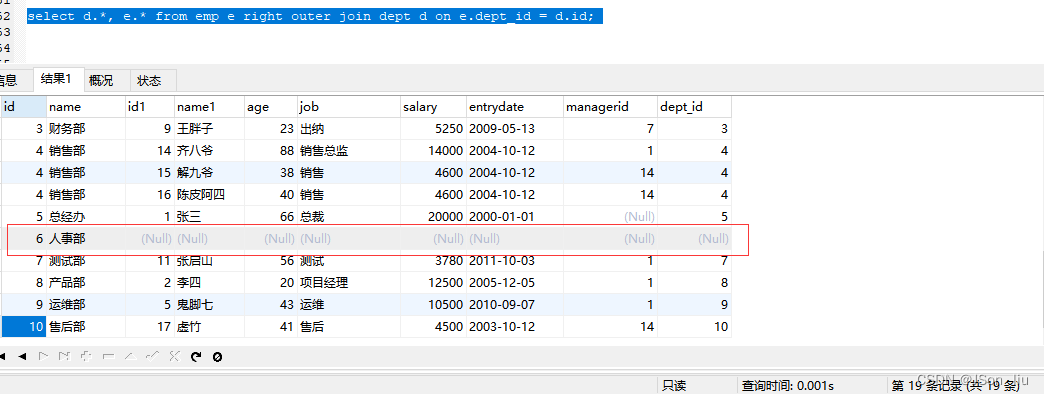
right outer join select 表名1.列名1,表名1.列名2,表名2.列名1,表名2.列名2 from 表名1 right outer join 表名2 on 表名1.列=表名2.列; - 实例:查询dept表的所有数据, 和对应的员工信息(右外连接)
select d.*, e.* from emp e right outer join dept d on e.dept_id = d.id;
5. 自连接
- 语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ; - 实例1:
select a.name , b.name from emp a , emp b where a.managerid = b.id;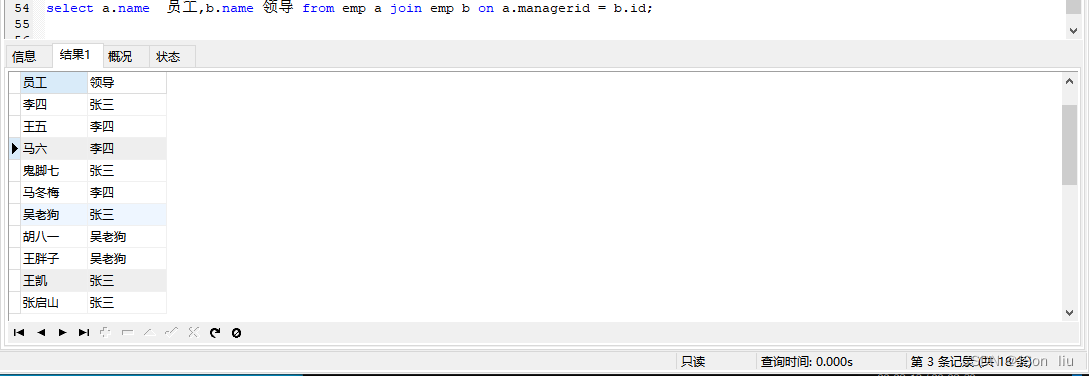
5. 子查询
- 基本语法:
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ); - 标量子查询:
- 子查询返回的结果是单个值(数字、字符串、日期等)
- 常用的操作符:= <> > >= < <=
- 实例1:查询 “市场部” 的所有员工信息
select e.* from emp e where e.dept_id = (select dept.id from dept WHERE name='市场部')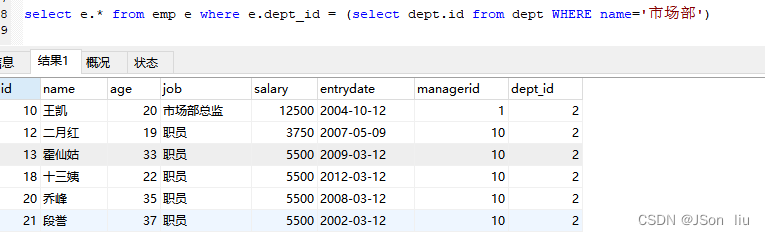
- 实例2:查询在 “霍仙姑” 入职之后的员工信息
select e.* from emp e where entrydate > (select e.entrydate from emp e where e.`name`='霍仙姑');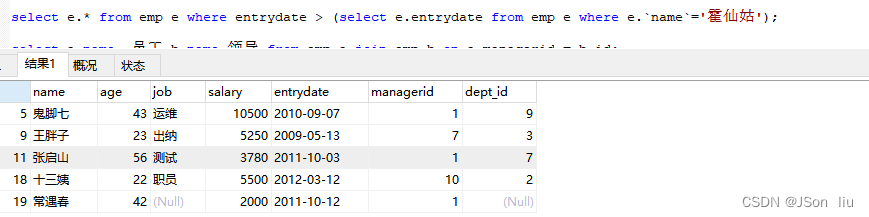
- 列子查询
- 返回的结果是一列(可以是多行)
- 常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
- 实例1:查询 “研发部” 和 “测试部” 的所有员工信息
select e.* from emp e where e.dept_id in (select id from dept where name = '研发部' or name='测试部')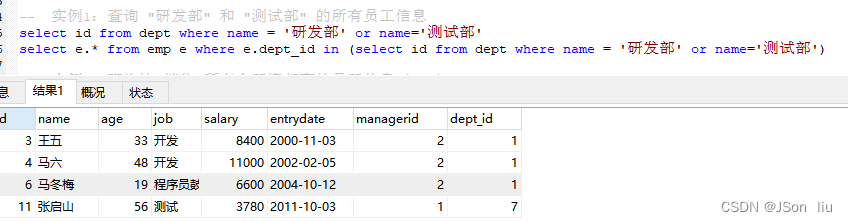
- 实例2:查询比 销售部 所有人工资都高的员工信息(all)
select e.* from emp e where e.salary > all (select salary from emp where dept_id= (select id from dept where name='销售部'))
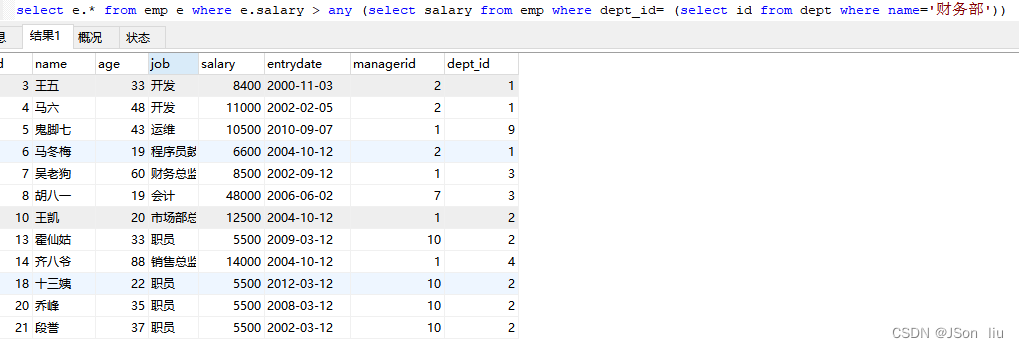
- 实例3: 查询比财务部其中任意一人工资高的员工信息
select e.* from emp e where e.salary > any (select salary from emp where dept_id= (select id from dept where name='财务部'))
- 行子查询(子查询结果为一行):
- 常用的操作符:= 、<> 、IN 、NOT IN
- 实例:查询与 “李四” 的薪资及直属领导相同的员工信息
select e.* from emp e where (e.salary,e.managerid)=(select salary,managerid from emp where name='李四');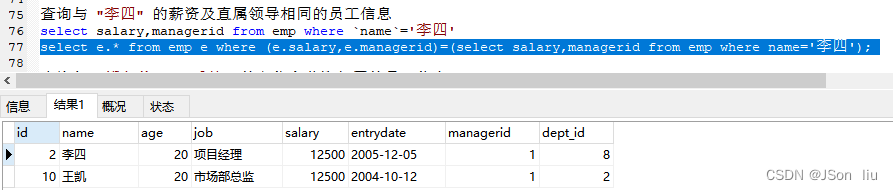
- 表子查询(子查询结果为多行多列):in
- 案例1:查询与 “解九爷” , “乔峰” 的职位和薪资相同的员工信息
select e.* from emp e where (job,salary) in (select job,salary from emp where name in ('解九爷','乔峰'))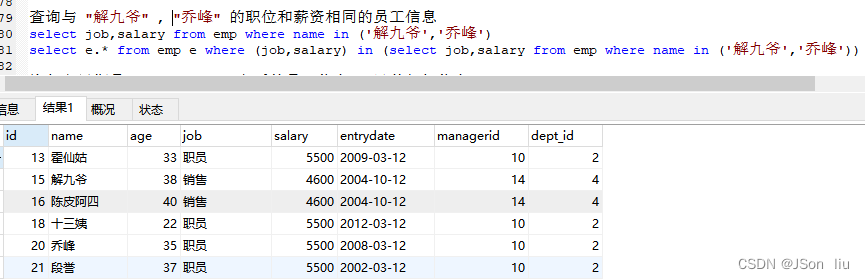
- 案例2:查询入职日期是 “2009-01-01” 之后的员工信息 , 及其部门信息
select e.*,d.* from (select * from emp where entrydate > '2009-01-01') e LEFT JOIN dept d on e.dept_id= d.id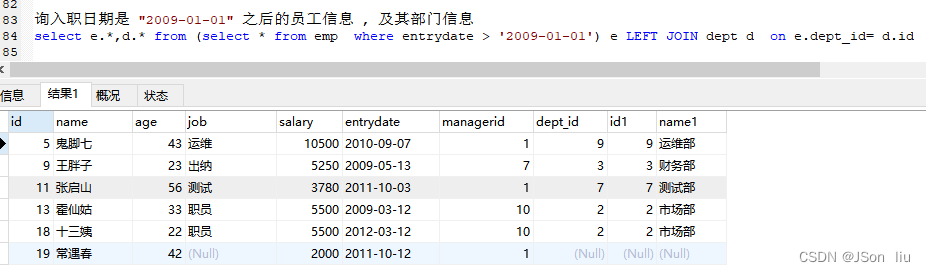
- 案例1:查询与 “解九爷” , “乔峰” 的职位和薪资相同的员工信息
1.3.6 案例练习
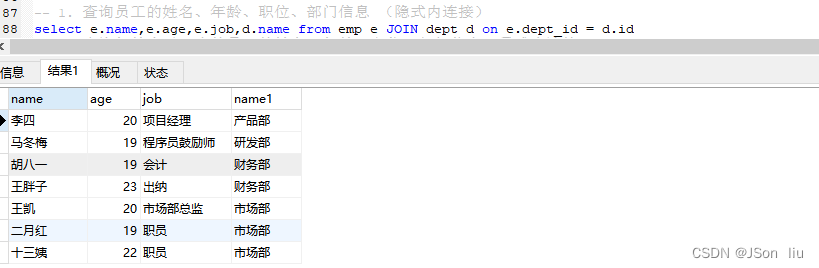
1. 查询员工的姓名、年龄、职位、部门信息 (隐式内连接)
select e.name,e.age,e.job,d.name from emp e JOIN dept d on e.dept_id = d.id
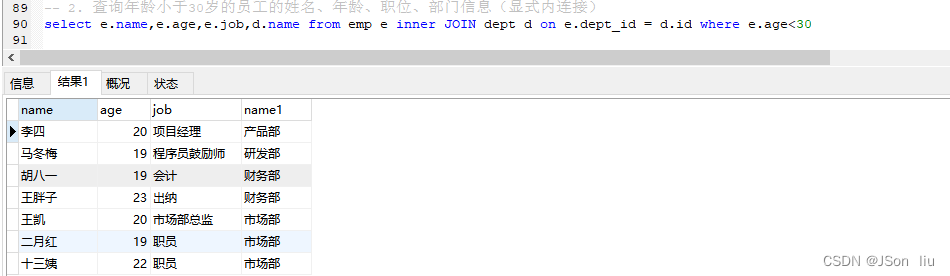
2. 查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接)
3. 查询拥有员工的部门ID、部门名称
select DISTINCT d.id,d.name from emp e LEFT JOIN dept d on e.dept_id=d.id

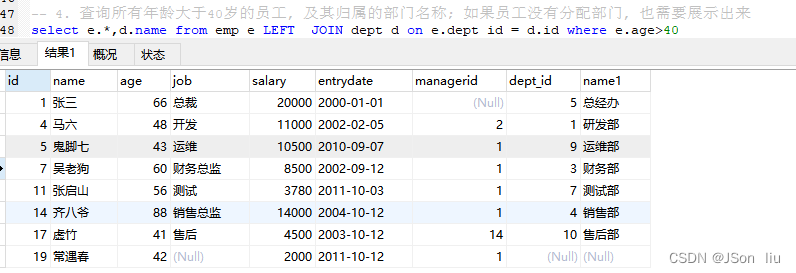
4. 查询所有年龄大于40岁的员工, 及其归属的部门名称; 如果员工没有分配部门, 也需要展示出来
select e.*,d.name from emp e LEFT JOIN dept d on e.dept_id = d.id where e.age>40
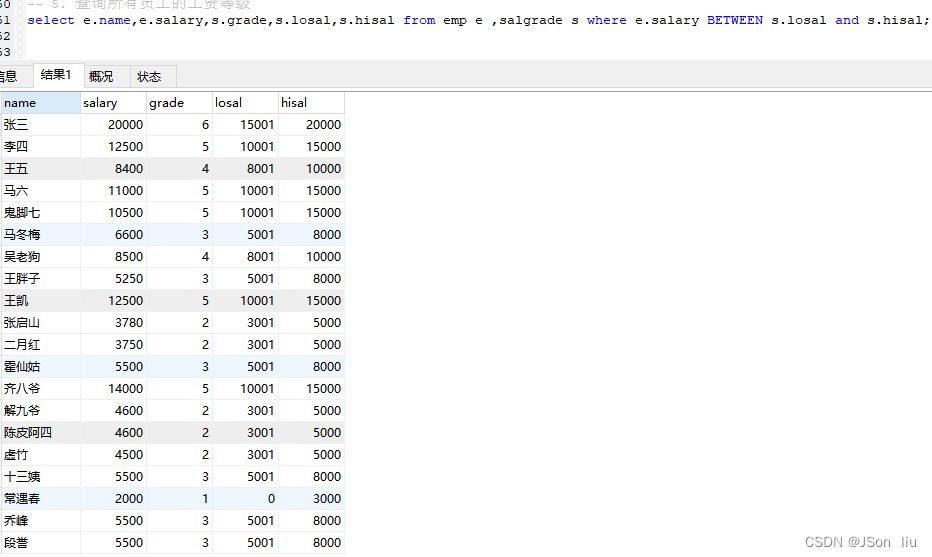
5. 查询所有员工的工资等级
select e.name,e.salary,s.grade,s.losal,s.hisal from emp e ,salgrade s where e.salary BETWEEN s.losal and s.hisal;
6. 查询 “研发部” 所有员工的信息及 工资等级
select e.*,s.grade FROM
emp e, dept d, salgrade s
where e.dept_id=d.id AND
e.salary BETWEEN s.losal and s.hisal AND
d.name='研发部'

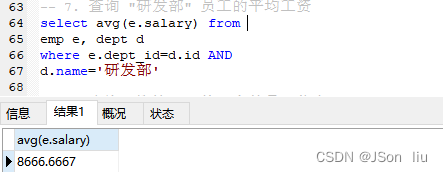
7. 查询 “研发部” 员工的平均工资
select avg(e.salary) from
emp e, dept d
where e.dept_id=d.id AND
d.name='研发部'
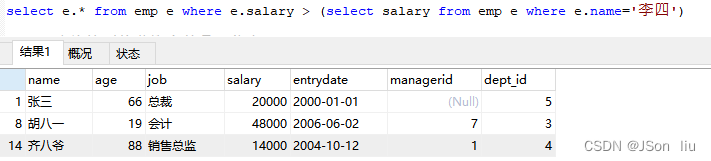
8. 查询工资比 “李四” 高的员工信息
select e.* from emp e where e.salary > (select salary from emp e where e.name='李四')
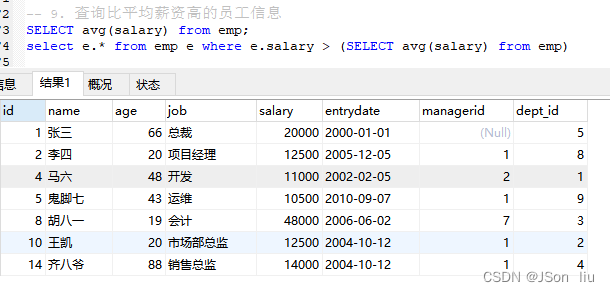
9. 查询比平均薪资高的员工信息
SELECT avg(salary) from emp;
select e.* from emp e where e.salary > (SELECT avg(salary) from emp)
10. 查询所有的部门信息, 并统计部门的员工人数
select d.id,d.name,(select COUNT(*) from emp e where e.dept_id = d.id) from dept d;

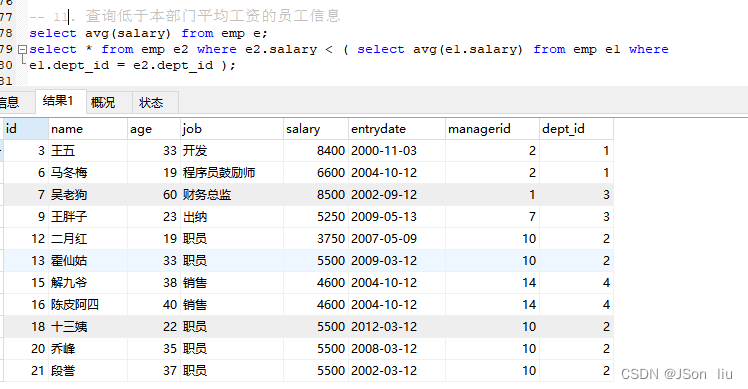
11. 查询低于本部门平均工资的员工信息
select avg(e1.salary) from emp e1 where e1.dept_id = 1
select avg(e1.salary) from emp e1 where e1.dept_id = 2
select * from emp e2 where e2.salary < ( select avg(e1.salary) from emp e1 where
e1.dept_id = e2.dept_id );
02 linux
2.1 find
1. 语法
- 格式:
find [路径] [参数] [关键字] [动作] - 参数
-name 按照文件名查找文件 -type 查找某一类型文件 -mtime 查找某天修改的文件 -path "子目录" 在指定目录的的子目录下查找,一般与-prune使用 -prune 在查找文件时,忽略指定的内容,不能和-depth - 动作:
-print 默认属性,打印信息 -ls 列出文件详细属性 -exec 命令 {} \; 对过滤的文件进行下一步操作,注意:{} 就相当于过滤出来的文件操作类似于 | xargs 命令
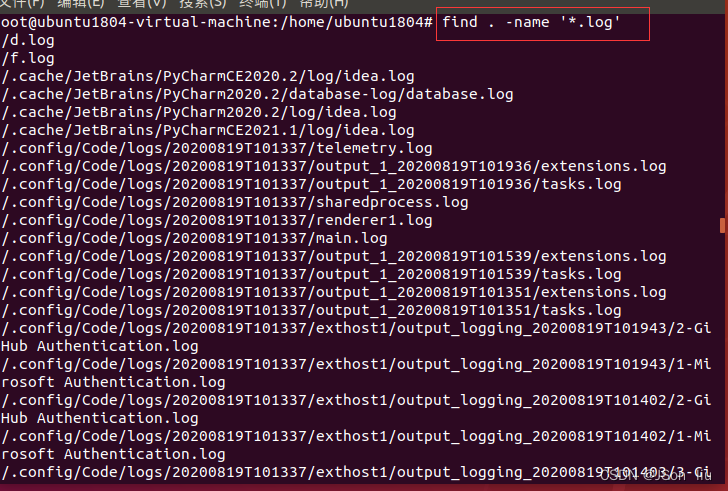
2. 查找log结尾的文件
find . -name ‘*.log’
3. 按时间查找文件
atime 最后一次访问时间
ctime 最后一次状态修改时间
mtime 最后一次内容修改时间
+n 多少天前
-n 多少天内
n 当天一天
- 10天以前所有,不包括第10天当天的文件
$ find ./ -type -f -mtime +10 ; - 10天前,当天一天的文件
$ find ./ -type -f -mtime 10; - 10天内,包括今天的文件,但不包括第10当天的文件
$ find ./ -type -f -mtime -10;

2.2cat
1. 语法:
cat file_name 显示文件全部内容
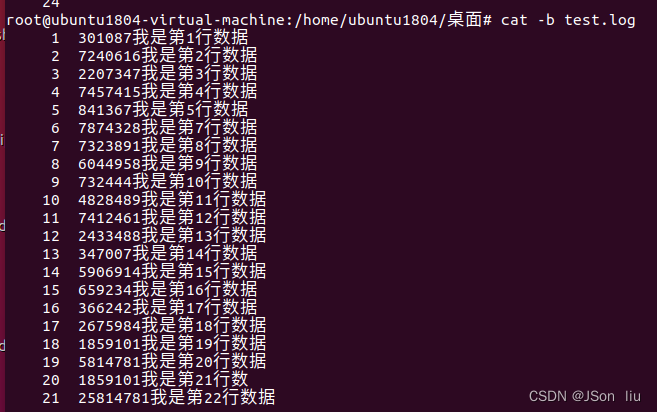
cat -b file_name 显示文件非空行内容
cat -E file_name 在文件每行末尾显示$,常用于管道功能
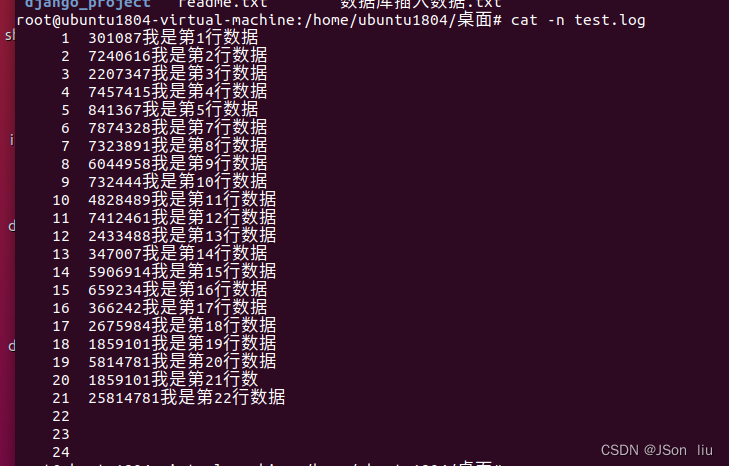
cat -n file_name 显示内容和行号
2.2 tail
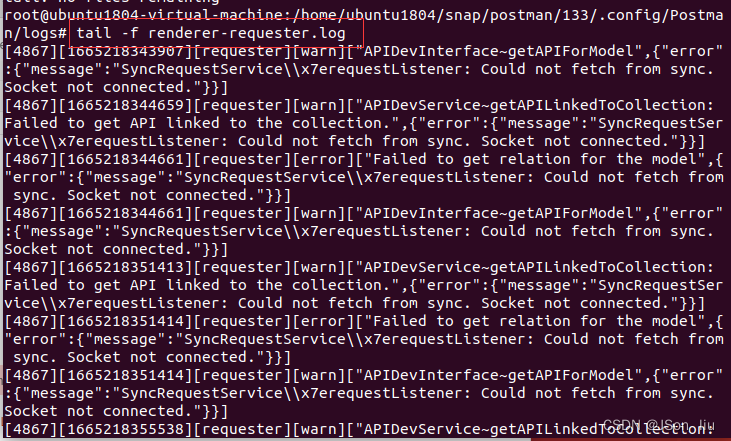
1. 实时查看动态日志:
tail -f 日志名称.log
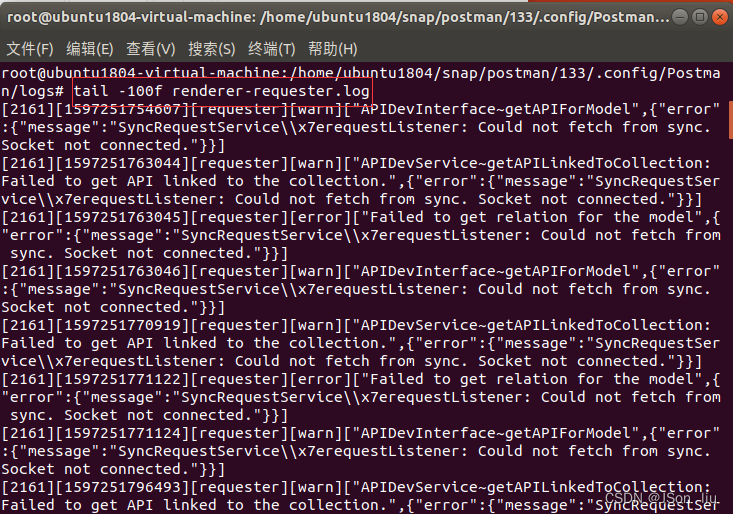
2. 实时监控100行日志
tail -100f test.log
3. 查询日志尾部最后10行的日志;
tail -n 10 test.log
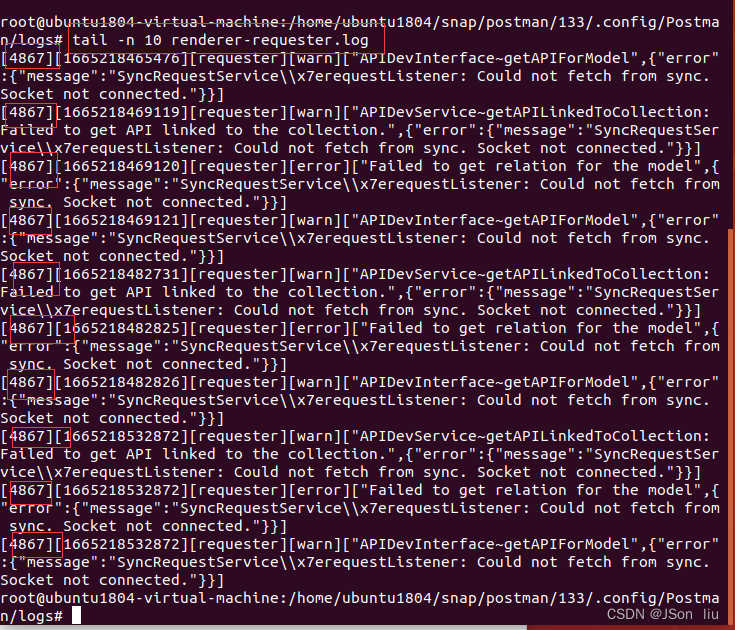
4. 查询10行之后的所有日志;
tail -n +10 test.log
2.3 head
1. 查询日志文件中的头10行日志;
head -n 10 test.log
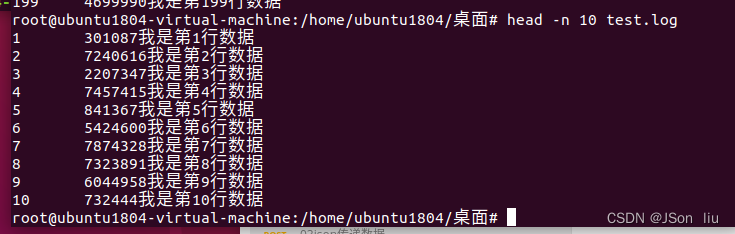
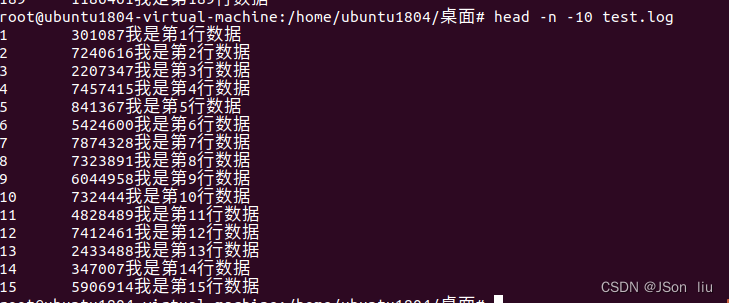
2. 查询日志文件除了最后10行的其他所有日志
head -n -10 test.log
2.4 grep
根据用户指定的模式(pattern)对目标文本进行过滤,显示被模式匹配到的行
1. 数据准备
he hello helloworld hender HelloWorld
hehe helloo helloworld hender HELLO
google goolerer goolerchrome GOolerChrome
HEHE HELLO GOOGLE HELLOWORLD HE
NETMASK=255.0.0.0
INET=192.168.32.152
broadCast=192.168.32.255
cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
2. 语法
- 两种形式:
grep [option] [pattern] [file1,file2,...] some command | grep [option] [pattern] - 选项
-i 忽略大小写 -c 只输出匹配行的数量 -n 显示行号 -r 递归搜索 -E 支持扩展正则表达式 -l 只列出匹配的文件名 -F 不支持正则,按字符串字母意思匹配 -v 取反 -o : 只显示被模式匹配到的字符串,而不是整个行 -A5 : 显示匹配到的行时,显示后面的 5 行 -B5 : 显示匹配到的行时,前面的 5 行 -C5 : 显示匹配到的行时,前后的 5 行
3. 案例
- 忽略大小写:grep -i -n ‘Hello’ grep_test.log

- 显示匹配的行数: grep -c ‘go’ grep_test.log

- 递归搜索:grep -r -n ‘hello’ .
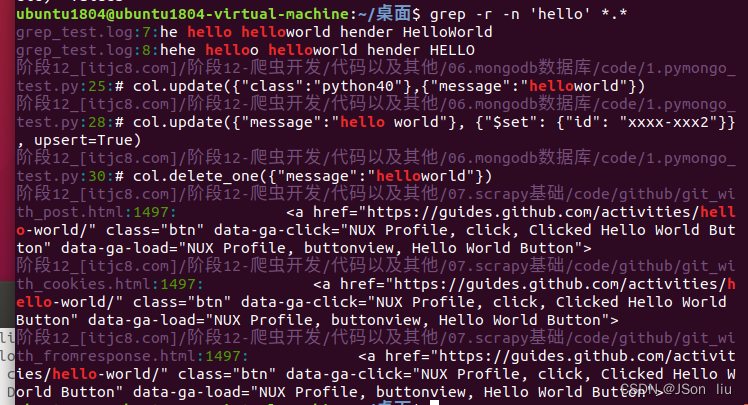
- 查找‘he’开头的行:grep -n -E ‘^he’ .

- 查找’login’结尾的行:grep ‘login’ grep_test.log

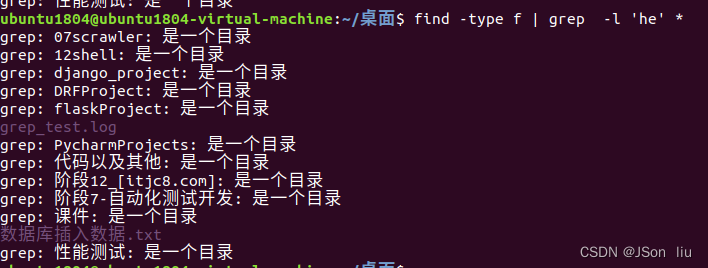
- 列出匹配的文件名:find -type f | grep -l ‘he’ *
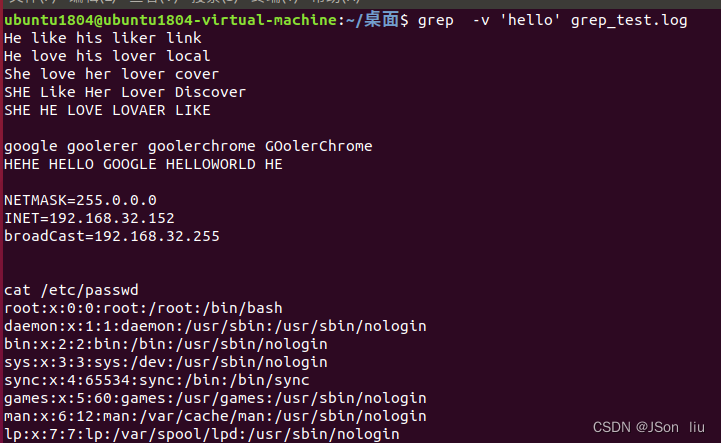
- 排除包含hello的行:grep -v ‘hello’ grep_test.log
- 只显示匹配的字符串:grep -o -n ‘hello’ grep_test.log

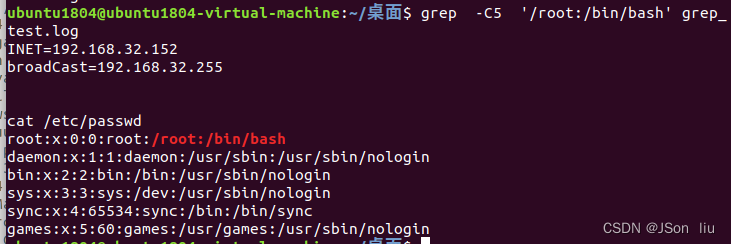
- 显示匹配到的行是前后的 5 行:grep -C5 ‘/root:/bin/bash’
2.5 sed
流编辑器,对文本逐行处理
1. 数据准备
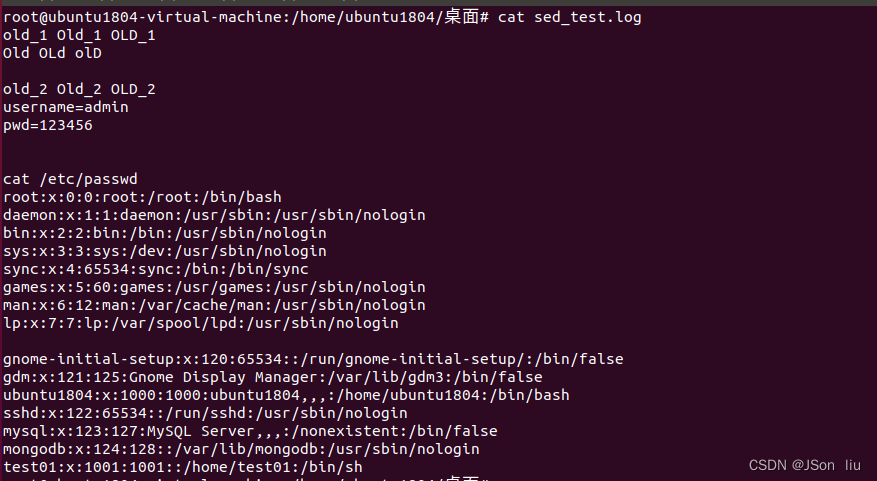
2. 语法
- 两种形式
sed [option] "pattern command" file
some command | sed [option] "pattern command"
- option
-n 只打印模式匹配的行
-f 加载存放动作的文件(使用命令文件)
-r 支持扩展正则
-i 直接修改文件
-e 执行一个sed命令
- pattern command
n 只处理第n行
m,n 只处理第m行到第n行
/pattern1/ 只处理能匹配pattern1的行
/pattern1/,/pattern2/ 只处理从匹配pattern1的行到匹配pattern2的行
- cmmand命令
- 查询:p打印
- 新增
- a 在匹配行后新增
- i 在匹配行前新增
- r 外部文件读入,行后新增
- w 匹配行写入外部文件(写入一个新文件)
- 删除
- d
- 取代
- s/old/new/ 只修改匹配行中第一个old
- s/old/new/g 修改匹配行中所有的old
- s/old/new/ig 忽略大小写
3. 打印匹配hello的行:sed -n ‘/hello/p’ grep_test.log

4. 增加
- 第二行后增加一行:sed -e ‘2 a newuser’ sed_test.log
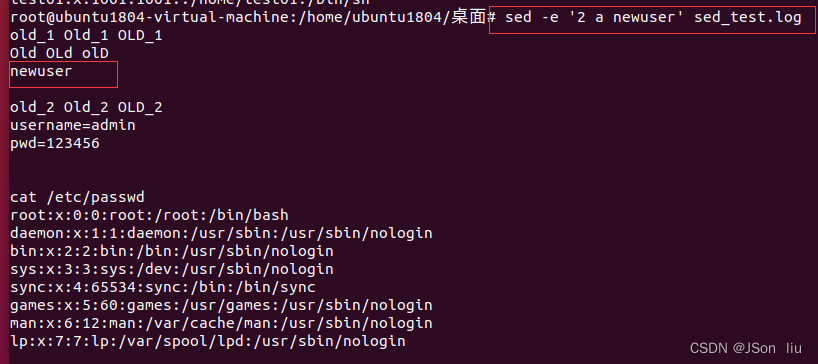
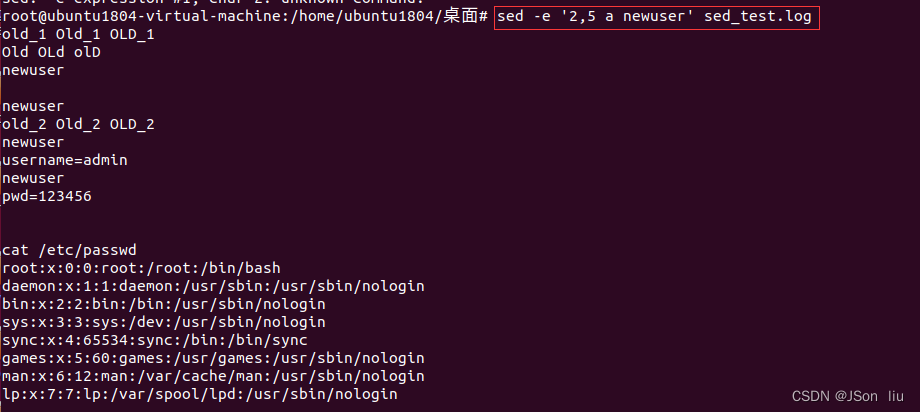
- 第二行、第五行添加一行:sed -e ‘2,5 a newuser’ sed_test.log
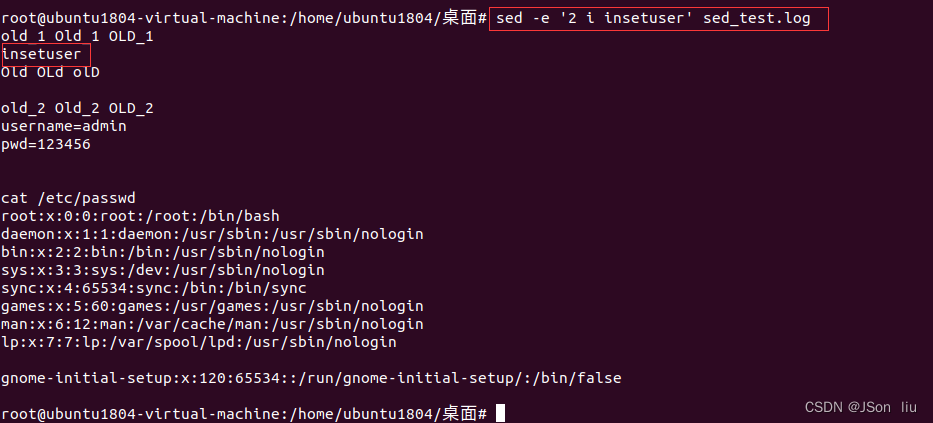
- 第二行前插入一行:sed -e ‘2 i insertuser’ sed_test.log
- 第二行到第五行前都插入一行:sed -e ‘2,5 i insertuser’ sed_test.log
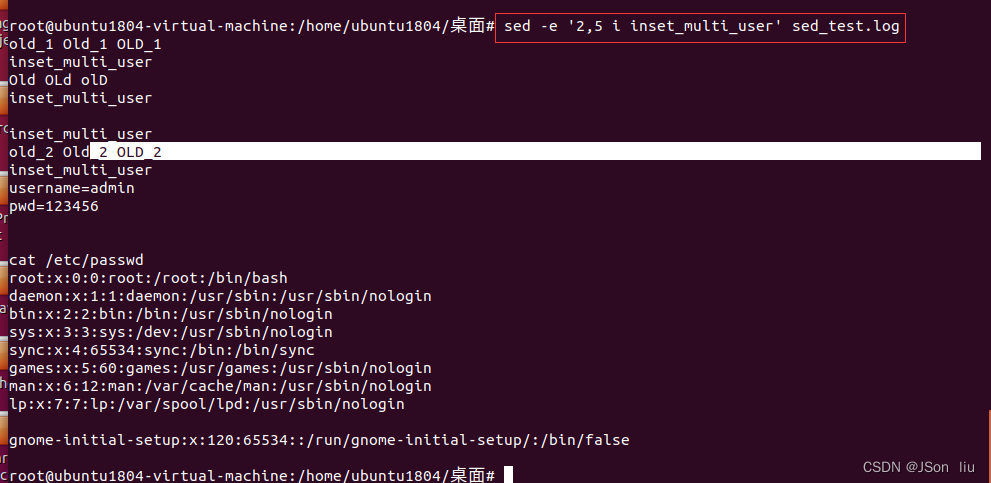
5. 取代
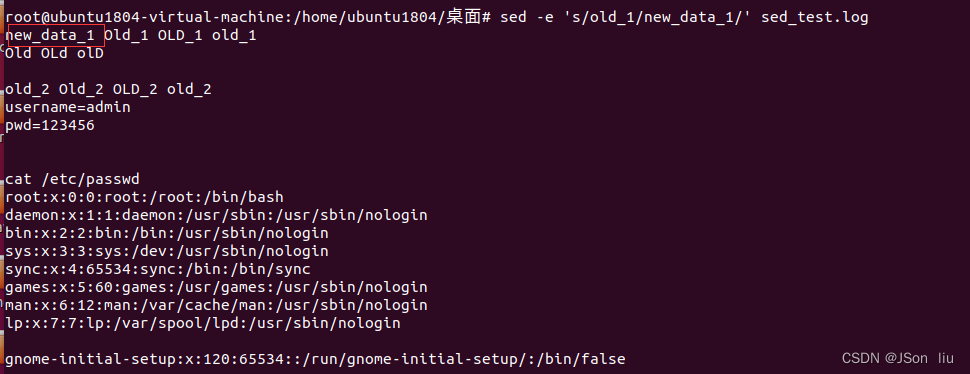
- 只修改匹配行中的第一个值:sed -e ‘s/old_1/new_data_1/’ sed_test.log
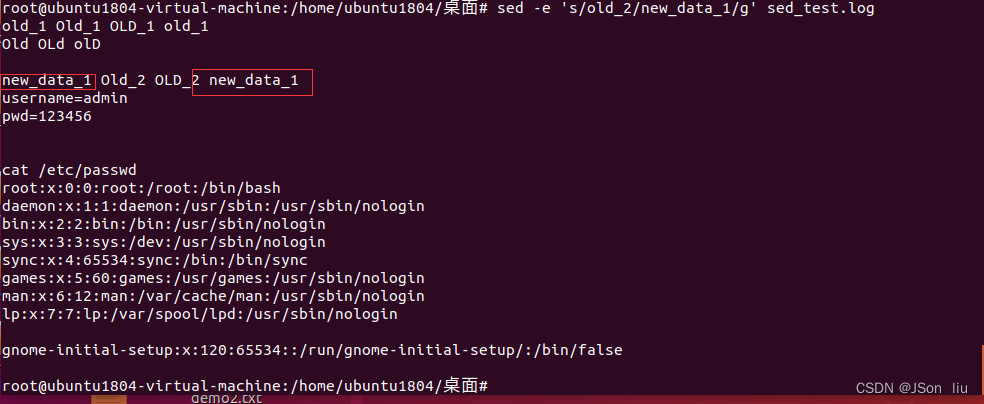
- 取代匹配行中所有的值:sed -e ‘s/old_2/new_data_2/g’ sed_test.log
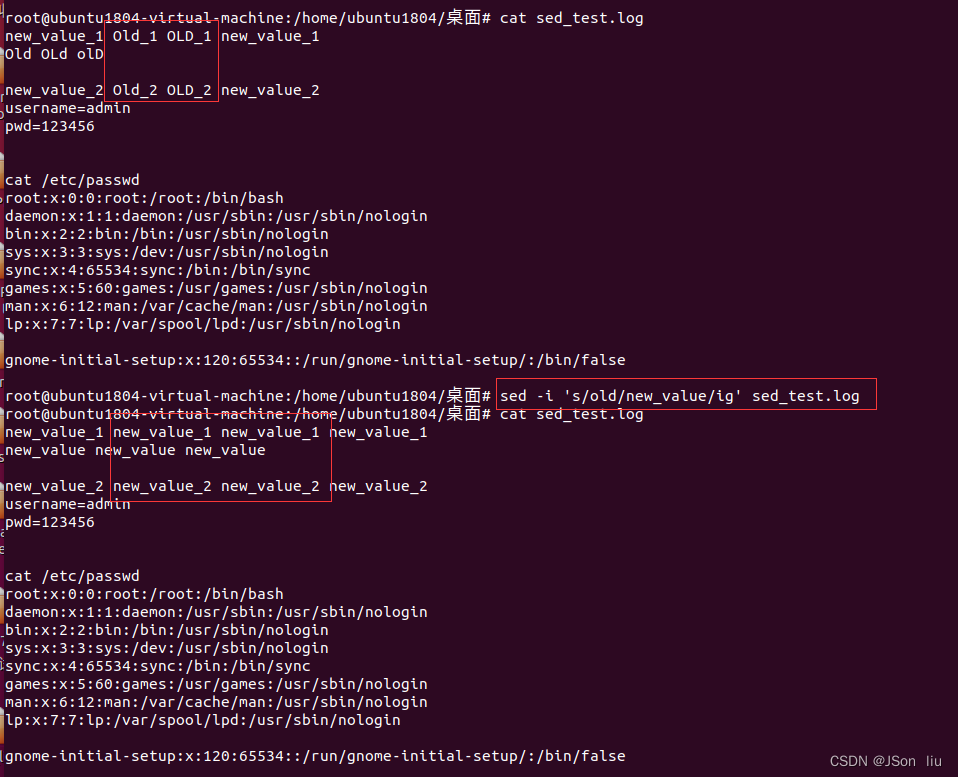
- 直接修改文件:sed -i ‘s/old/new_value/g’ sed_test.log
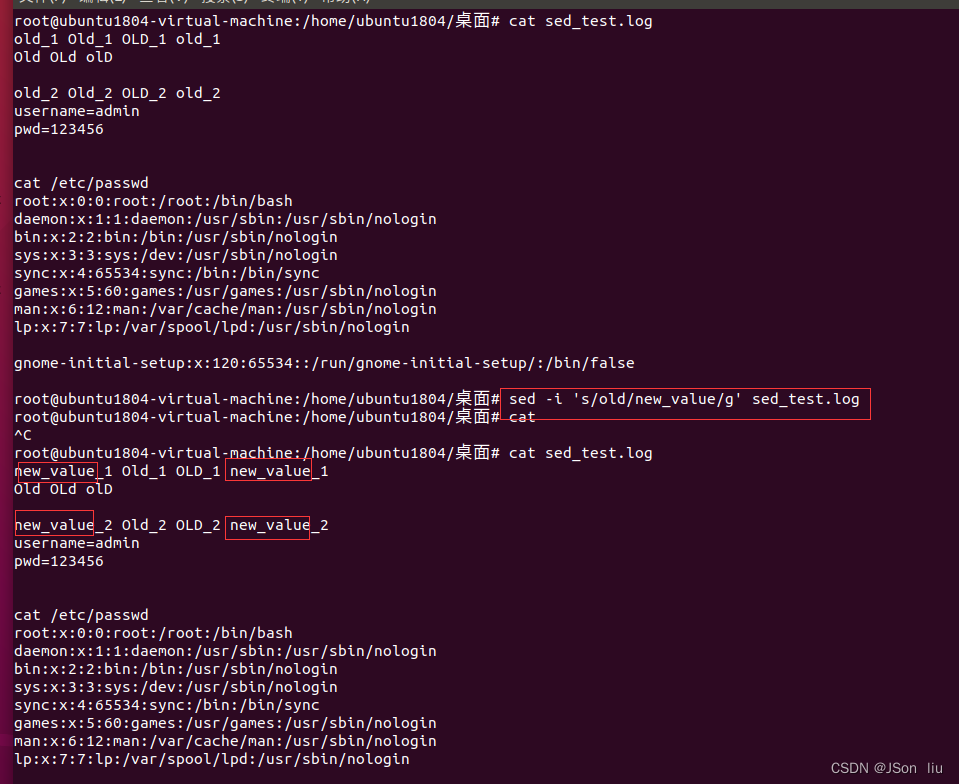
- 忽略大小写: sed -i ‘s/old/new_value/ig’ sed_test.log
6. 删除
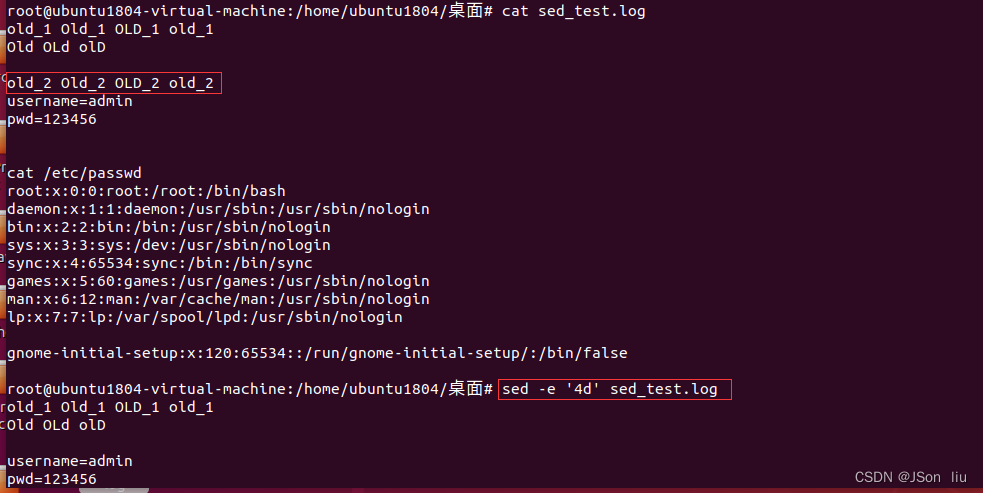
- 删除第四行:sed -e ‘4d’ sed_test.log
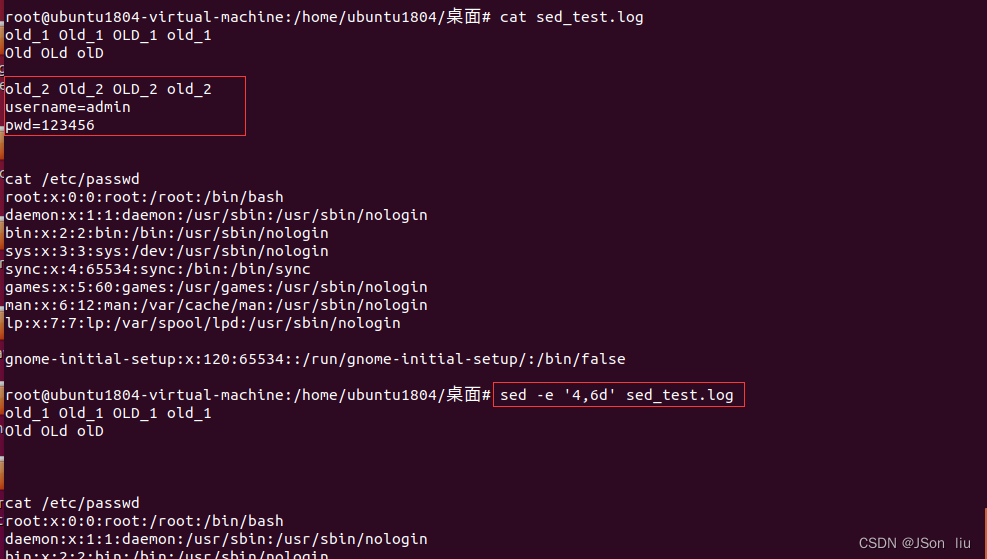
- 删除4-6行: sed -e ‘4,6d’ sed_test.log
2.6 awk
把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行后续处理
1. 语法
awk 'BEGIN{}pattern{commands}END{}' file
- 参数
模式 含义
BEGIN{} 处理数据之前执行
pattern 匹配模式
{commands} 处理的命令
END{} 处理数据之后执行
- 内置变量
$0 整行内容
$1~$n 当前行的第1~n个字段
NF(Number Field) 当前行字段数(a aa aaa 表示有3个字段数)
NR(Number Row) 当前行行号,从1开始
FS(Field Separator) 输入字段分隔符,默认为空格或tab键,等价于命令行-F选项
RS(Row Separator) 输入行分隔符,默认为回车符
OFS (Output Field Separator) 输出字段分隔符,默认为空格
ORS(Output Row Separator) 输出行分隔符,默认为回车符
- pattern匹配模式
/pattern1/ 只处理能匹配pattern1的行
/pattern1/,/pattern2/ 只处理从匹配pattern1的行到匹配pattern2的行
2. 搜索sed_test.log有root关键字的所有行,并显示对应的shell
awk -F : ‘/root/{print $7}’ sed_test.log

3. 打印sed_test.log的第5行信息
awk ‘NR==5{print $0}’ sed_test.log

4. 用=进行内容换行
awk ‘{RS=“=”}{print $0}’ sed_test.log

2.7 综合案例
1. 按关键字查询
cat meiduo.log |grep “ 404 ”

2. 不知道日志文件名称,只记得关键字,如何获取日志文件
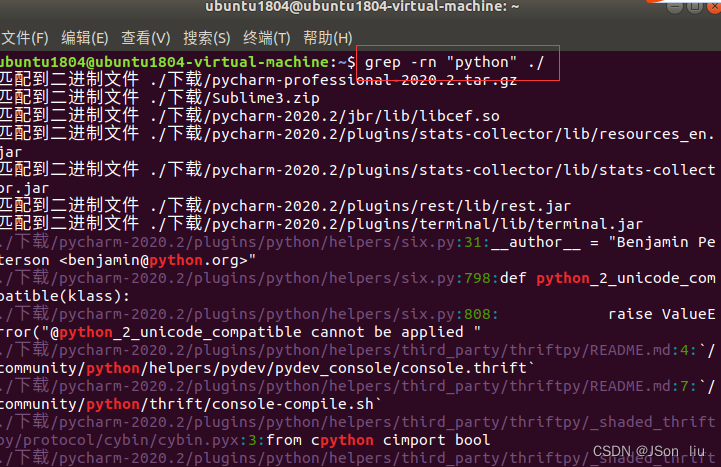
grep -rn "python" ./ (其中,r 表示递归, n 表示查询结果显示行号)
find ./ -name "*.*" | xargs grep "关键字"
find ./ | xargs grep -ri "关键字" -l(-l 表示只显示文件名)
find ./ -type f -name "*.txt" | xargs grep "关键字"


3. 统计报日志报500或404的条数
- grep -E ‘\s500\s|\s404\s’ meiduo.log | wc -l
- awk ‘$9~/404|500/’ meiduo.log | wc -l
- awk ‘/ 404 | 500 /’ meiduo.log | wc -l

4. 访问量最高的ip
- awk方式
awk '{print $1}' ip.log | sort | uniq -c | sort -nr | head -3
uniq 重复ip合并;-c显示条数; n数字排序; r取反:从大到小

- grep 方式
cat ip.log | grep -Eo '^([0-9]*\.){3}[0-9]*' | sort| uniq -c | sort - rn| head -3

2.8 其他常用命令
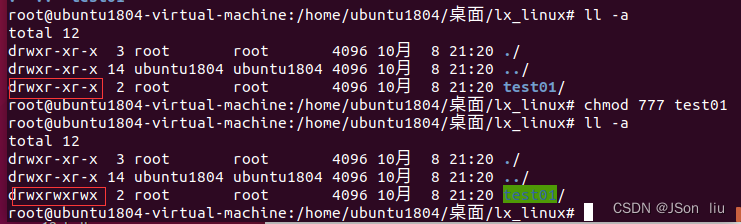
1. 修改文件属性

r读权限read 4
w写权限write 2
操作权限execute 1
chmod 777 test01,修改test文件属性
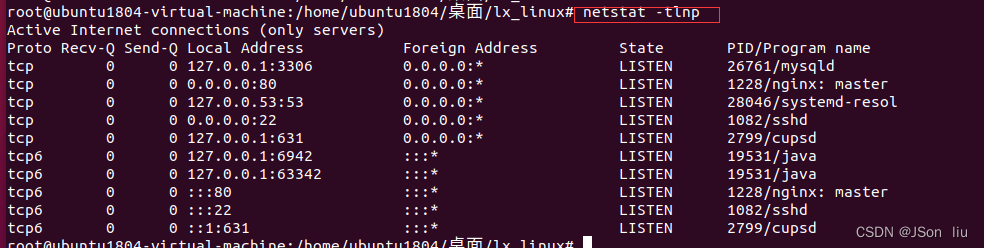
2. 网络系统状态信息
-t:列出所有tcp
-u:列出所有udp
-l:只显示监听端口
-n:数字形式显示地址和端口
-p:显示进程pid和名称
- 显示tcp 监控端口和pid:netstat -tlnp
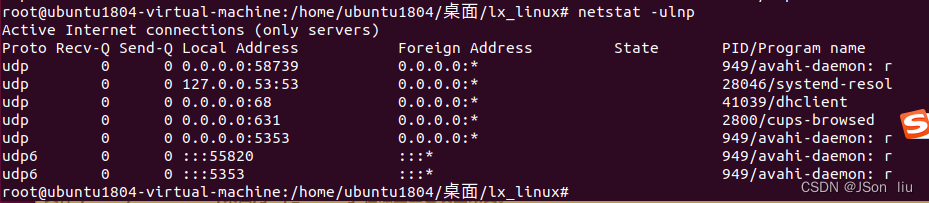
- 显示tcp 监控端口和pid:netstat -ulnp
- 查看ngnix或redis 启动服务端口
netstat -antp | grep ‘nginx|redis’

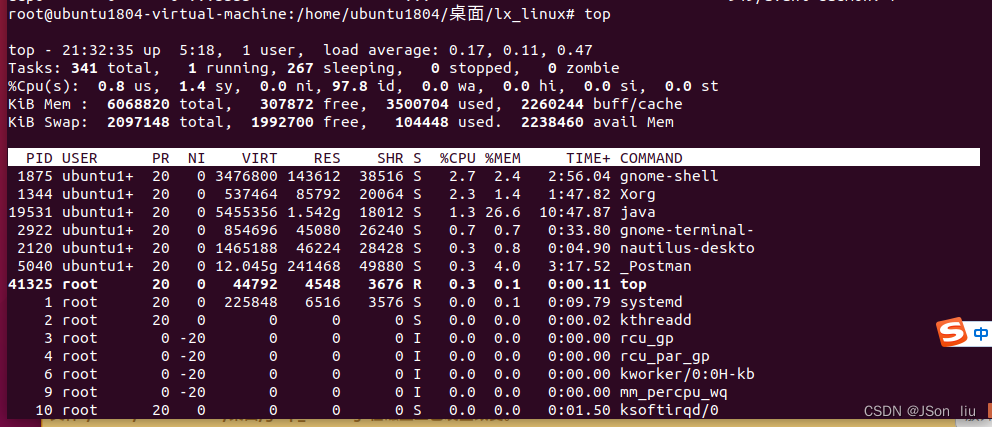
3. 监听系统性能:top
4. 显示所有进程:ps -aux
5. 查找指定服务进程并杀死进程
- ps -ef | grep -i ngnix
- kill -9 进程id
