【DjangoDRF+缓存 五万字总结】预计在2022.11月份会再次进行更新
百年沉浮困低谷,莫以今朝度兴衰, 人生终有高飞日,傲振才华过沧海.
目录
什么是Redis
Redis 由 Vmware 公司开发, (卧槽 虚拟机)! 因为考虑有没有学习Linux的同学 基础篇使用Windows的Redis入门 后期会进入Linux的Redis学习阶段
NoSql 的简介
有些数据用Mysql这种数据库存储很不nice!譬如一些图片 秒杀活动之类的数据 这个时候就可用用到Redis类似的NoSql来存储了
高速缓存技术
用内存存储数据的技术 从而提高curd(增删改查)速度
扯句题外话kodachi是一个存储在内存上的系统 黑客们很喜欢使用它 毕竟一个关机键就可以完全清除他们的犯罪历史 遇见危险 直接关机处理 有哪个小可爱会不喜欢呢
运存(内存)空间很小 如何去保存数据呢? 关机就清除数据的话 不就都没了吗?
- 我们先要明白 数据使用频率很高的时候我们称之为 热数据 ,举个栗子, 淘宝的商品 steam的热销 哔咔的推荐本 都算是一种热数据
- 如果我们每次都想看这些数据,我们就不用把他们放在Mysql这样存储大量数据的地方了(虽然Mysql有索引这样的机制 但还是麻烦!) 毕竟放在硬盘的数据怎么都比不过存在内存上的数据
- 反而呢 内存非常贵 (吃鸡火热的时候 一个内存买500了解一下) 为了节约成本 不经常使用叫做冷数据 存放在硬盘里这是很不错的选择
万一哪一天停电没有存储在硬盘的热数据岂不是直接GameOver, 所以我们需要了解一个点 热数据其实不但保存在内存 他也有机会在硬盘中被存储 这里存储在硬盘的热数据就是备份备份
所以加入高速缓存的存储机制是这样的:
- 去应用程序里找数据(变量, 列表之类的简单数据)
- 没在App找到,辨认这个数据是否为热数据,
- 是的话就去缓存中查找(redis),冷数据就去 数据库查找
- 实在找不到你在HDD里找找?
如果缓存数据发生变化记得及时 更新到数据库里哦!
使用案例
- 买的火爆的商品数据在redis中,买的一般的数据在数据库中
- 网红的言论在redis中,普通人的评论在数据库中
- 这不是流量的限流,只是为了让更多人加载网红的言论速度更快,普通人的评论似乎没那么多人去看加载快不快与我无关~
- 区别对待是吧 好家伙
- 超大量(上亿万)的数据请求提交的时候 先交给集群们
- 集群们先暂存数据拿到数据之后等到请求来到低谷期在上传到Mysql类数据库
- 高速缓存是并发的 买秒杀物品的时候 抢到之后下单支付明明到了支付界面,但是还是可能会支付失败是因为其他进程线程虽然晚入一步订单界面但是他提前执行了订单操作, 从而自己被挤了下去. 订单失败的人就想 这玩意儿有黑幕!一定是商家自导自演! 引入Redis后 只要提交了数据就是 一个一个执行不会出现插队或者加塞的情况 你可以慢慢下单 甚至插科打诨一段时间再去下单 只要道德允许 Redis就能允行。
集群
如果大量数据只靠一台服务器做告诉缓存似乎没那么靠谱 我们就可以搭建集群 类似HDFS叫做 LAZY_PERSIST 的玩意儿. 一般我们在Docker这种容器中搭建
Redis的介绍
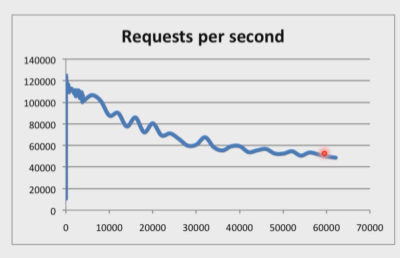
是一个NoSQL数据库产品之一 以键值对的形式进行存储 像JSON 像DICT 像Mapper 由C语言编写(源码开源) 理论可以达到10个w的QPS QPS指的是每秒查询的次数
X轴是链接数 Y轴是一秒查询的次数
安装与服务器的搭建
下载链接https://github.com/tporadowski/redis/releases,下载ZIP即可
现在之后不要打开任何程序 我们需要让redis-server.exe启动的时候redis.windows.conf, 但是 exe 默认不会加载任何文件 我们需要写一个Bat文件来实现这样的效果
新建记事本txt:
redis-server redis.windows.conf
写完之后 存储为.bat文件即可
打开bat弹出的cmd类似于下图

基础使用
启动客户端的话可以直接点击redis-cli.exe运行 界面简陋 见谅 服务器端口默认 6379
默认, Redis有16个逻辑库(0~15) 都是空的 可以存储数据 使用 select <id> 切换到指定id的逻辑库 如
select 0
切换到 0 号逻辑库
还有以下命令:
set <key> <value> 新增键值对
get <key> 获取指定key的value
del <key> 删除
clear 清空控制台
flushall 删除所有数据
虽然好用但是简陋!高端程序员的美工都差劲(暴论)
安装 RedisDesktopManager 优化你的眼睛查看更高级的界面

官网收费从别人那里借来的免费网盘链接
百度网盘:https://pan.baidu.com/s/15xVRpCT8mkP2uT8PoBHT3g 提取码:v727
Redis的持久化
为了不让突然断电的事故导致Redis数据丢失 Redis提供了俩不错的方案
- RDB方案
- 定期存储备份 只有触发一定条件 才会进行同步 比如一分钟读写1000次我就进行同步
- AOF方案
- 日志记录 你写一次我就记录一次 宕机后 使用日志重启就会把操作的记录复刻一次
参数配置
对Redis本身的配置
- port 端口 默认 6379
- bind 默认被注释 表示可以连接数据库的IP地址 推荐是0.0.0.0 表示全部
- 删除空格的时候记得删除空格!
- timeout 超时时间 默认是0 表示没有超时时间
- 长时间不用不关闭也不好 timeout最好设置个数字
- logfile 日志输出的文件名称
- 填写之后记得找到注释并删除注释: syslog-enabled
- 值设置为no就行
- databases 逻辑库的数量
- 默认16
- requirepass
- 密码 默认被注释 建议打开
rdb是内存数据同步到硬盘的数据库文件 有如下操作
- save 同步频率
- 写入包括增删改
- save 60 10000 指的是 在 60s 之内 写入了10000条数据就进行同步
- save 900 1 指的是900内写入了一条数据都可以进行同步
- rdbcompression
- 同步数据采用压缩
- rdbchecksum
- 同步数据校验
- rdbfilename
- rdb文件的名称
- dir
- redis所在的目录、
RDB 同步方案似乎会导致数据的丢失? 我们不妨了解一下AOF的备份方案吧
- maxclients 最大连接数
- 默认无限制 实际环境推荐设置一个大数字
- maxmemory 占用内存的大小
- 默认无限制 实际环境推荐设置一个70%的内存
- appendonly 开始AOF模式
- 默认关闭
- 开启AOF RDB就要关闭 我们只需要删除save命令存在的配置行即可
- appendfsync 同步频率
- no - 不可靠就是了
- everysec - 每秒都会把数据写入到硬盘 不可靠就是了
- always - 每次内存写入 都会写入硬盘
Redis的数据
前排提示:
这一章出现的指令很多! 当我们常用的数据指令了 太多了 记不住?
多用就是哈哈
刚开始用记不住,不妨下载一个 Utools 安装插件redis文档 在开发的时候使用Alt+空格输入redis可以快速查找你的指令
比如我要查询列表删除的数据 我就这样:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mWHjQeg5-1665327867949)(https://www.helloimg.com/images/2022/08/25/ZpQNEt.png)]
然后使用多了你就可以得心应手了!
不是广告!!!
redis的数据类型分为 5 种 - 字符串 哈希 列表 集合 有序集合
字符串String类型
可以保存文字数字 也可以保存图片等多媒体文件数据
如何保存多媒体文件?
将文件转化为二进制 序列化 即可存储
但是String并不是无穷大的 最大可以保存512MB数据
- 基本指令
set <key> <value>可以设置数据 也可以对已有key进行修改 不用给value引号 Redis不需要他get <key>获取字符串的数据del <key>删除数据
- 高级指令
getrange <key> <index_min> <index_max>- 截取字符串从index_min到index_max的子串
strlen <key>获取字符串的长度setex <key> <sec> <value>设置带有过期时间的kv对(单位秒)psetex <key> <sec> <value>设置带有过期时间的kv对(单位毫秒)mset <k1> <v1>...<kn> <vn>同时设置多个kv对mget <k1> <k2>获取多个k的valueappend <k> <v>向 k 对应的 value 追加内容 内容为v
- 加法运算
incr <key>数字+1incrby <key> <number>数字+number number∈intincrbyfloat <key> <number>数字+number number∈floatdecr <key>数字-1decrby <key> <number>数字-number number∈int- 没有
decrbyfloat
浮点计算不大准确 还是少用最好
哈希Hash类型
hash说白了就是字典这种结构化的数据 在Redis使用hash 有种字典套字典的感觉
使用hash 可以一次性存储多个数据 比如对象的全部属性
hset <key> <hash_key> <hash_value>
-- 在key里定义一个hash的value 并给这个hash的hash_key 设置一个hash_value
hmset -- 类似于mset 同时给一个hash设置多个key
hget <key> <hash_key> -- 获取hash的hash_key的value
hmget -- 类似于hmget
hgetall <key> -- 获取hash所有的kv
hkeys <key> -- 获取hash所有的key
hlen <key> -- 获取hash的key数量
hexists <key> <hkey> -- 是否存在key字段 (0False 1True)
hvals <key> -- 获取字段值
hdel <key> <hkey>...<hkeyn> -- 删除多个hash的kv对
其实我们发现了一个规律只要在String的指令前面加上h 在添加一个hash_key的参数基本可以复刻string的操作
猜猜hincrby 和 hincrbyfloat 是什么? 如何用?
列表list类型
列表可以存储多个重复的值 他和Java的数组(但是你不用定义长度) python的列表有些类似
- rpush key val1 [val2 …] 向某个列表的最右侧添加数据
- lpush key val1 [val2 …] 向某个列表的最左侧添加数据
- lset key index val 向某个列表的索引为index的地方设置数据(index从0开始)

猜猜 现在dname列表种存储的元素是哪些 顺序如何
你可以使用lrange查看列表数据
- llen key 获取长度
- lrange key start_index end_index 查看指定范围的list子串 end_index为负数的时候表示倒数第几个
- lindex key index 获取第几个元素值
- linsert key before|after value1 value2 将value2插入到列表元素value的前面|后面
- lpop key 删除第0个元素(最左的)
- rpop key 删除最后一个元素(最右的)
- lrem key number value 删除列表的指定元素值的值 如果有多个可以使用number指定删除多少个
集合set类型
类似于Python的集合 和列表一致 不过不能存储重复字段而且无序
- sadd key value [value2 vlaue3] 向集合添加元素 可以是多个元素
- smembers key 获取集合所有元素
- scard key 获取集合长度
- sismember key value value是否属于集合
- srem key value 删除元素值
- spop 随机删除一个元素并返回
- srandmember key number 从集合里随机返回number个元素
顺序集合Zset类型
顾名思义 可以排序的集合

- zadd 添加元素并加上权重值
- zincrby 添加元素的权重
- zrevrange 降序排序key


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-peHS8b84-1665327867952)(https://www.helloimg.com/images/2022/08/25/ZpQWbb.png)]
5 10 表示 5<= x <= 10
(10 表示 小于10
+inf 表示无穷大
-inf 表示负无穷大
同理, ZrevrangebyScore表示降序 参数和升序一致


Redis 的Key命令

Redis 事务
还记得Mysql的事务吗,记不得了? 没事 redis的事务机制和Mysql不同
但是还是推荐你去复习一下Mysql的事务…
mysql这一类 的数据库的事务是为了防止数据在进行操作的过程中发生了意外的宕机而出现的数据错乱问题所以引入的事务机制 undo redo
redis本身不需要对数据进行持久化,所以redis也不需要向mysql这样的事务机制,在redis中失败就是失败成功就是成功 没有原子性的说法。
redis的事务可以这么理解
- 有两个客户端对redis进行请求
- A-cli有两条指令 B-cli也有两个
- ac 向redis发送请求 执行的期间 bc可能也会来请求
- 但是ac值执行到了半途 没有事务的时候 bc可以从中进行插队执行
- 所以我们引入了事务 如果是a先来的 就需要等到a执行完毕之后 b再去执行
- 保证了客户端即使有多个命令也不会被插队的问题不再发生
- 而且redis的事务没有回滚 错误就是错误 正确就是正确
数据监视
Redis 不会给数据来个锁来保证数据被多个请求所修改的事情发生,而是使用一个数据监视来监视数据,如果事务在执行过程中,其他的客户端修改了监视的记录那么当前的事务会自动的关闭。只有监视的数据没有被其他客户端修改的时候,事务才会执行完成。
watch <key> <key2> ... 监视的数据可以是一条可以是多条
事务启动
使用 multi 启动事务 使用 exec 提交事务
开启事务后操作不会立即执行 而是在提交事务时候一同执行(类似批处理)
redis的事务没有回滚机制 所以不存在原子性 当事务提交之后不能进行回滚的操作,但是在事务提交之前我们随时可以使用discard取消事务。
既然学习了这么多的命令 不妨来做个小demo 假设设计一个网络购物平台 只有下单前10名的用户才可以拿到数据 记录他们的名字与购买序号!
创建一个Django项目
pip install django 之后 使用命令 django-admin startproject 项目名 创建项目 然后会出现类似的结构

- setting - 配置文件
- urls - 路由
- wsgi - web服务器 与 Django交互的入口
- manage - 项目的管理文件
使用命令: python manage.py runserver 启动服务器
Django开发中, 我们会对网站的功能进行不同模块的划分,一个模块一个Django的应用 ,使用 python manger.py startapp 【应用名】 开启一个应用。
输入命令
python manager.py startapp studentapp可以得到
这些应用的文件有什么作用呢?
- admin
- apps
- models 写数据库相关的内容
- tests 测试类
- views 接受请求进行处理与MT交互 返回应答

HelloWorld
创建好应用之后就可以在视图中实现代码了
from django.http import HttpResponse
def index(res):
"""
index主页视图
:param res:
:return:
"""
return HttpResponse("HelloWorld")
默认的 views.py 有一个render的引用现阶段可以删除他
视图写完了 但是无法看见他真正的效果,我们需要将一个 URL 映射到它——这就是我们需要 URLconf 的原因了。
在 应用文件夹 里创建一个 url.py 并做好注册工作
from django.urls import path
from . import views
urlpatterns = [
path('', views.index , name='index')
]
# 这里面的列表名称必须是urlpatterns
这一步的操作是给我们的 APP 中的view(第二个参数) 指定路由(第一个参数 ) 并给他命名(name参数)
但是我们应用并没有注册到服务器上 所以我们需要在Django的项目urls中进行注册
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('student/',include('studentapp.urls')),
# 给 studentapp.urls 里面注册的视图一个路由组 student/
path("admin/", admin.site.urls),
]
运行网站 访问IP:http://127.0.0.1:8000/student/ 即可查看视图
数据库的配置
在项目的setting中有一个DATABASES列表我们可以轻松的找到里面字典ENGINE的值 默认是 SQLite 我们可以换成MySQL 或者是其他的DBMS.
ENGINE– 可选值有'django.db.backends.sqlite3','django.db.backends.postgresql','django.db.backends.mysql',或'django.db.backends.oracle'。其它 可用后端。
当我们使用的不是SQLite的时候我们可能会给连接的数据库获取他的密码或者是用户名称 可以这么做:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydatabase',
'USER': 'mydatabaseuser',
'PASSWORD': 'mypassword',
'HOST': '127.0.0.1',
'PORT': '5432',
}
}
Django的数据库配置
使用mysql的时候 直接启动程序会有问题:
Did you install mysqlclient?你可以在项目的__init__文件中输入下列代码import pymysql pymysql.install_as_MySQLdb()
中文设置
在setting中设置
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
可以设置中文
模型-基础
我们可以在应用下的 models 里编辑
from django.db import models
# Create your models here.
from django.db.models import CASCADE
class TeacherModel(models.Model):
name : str = models.CharField(max_length=255)
_teacher_id : int = models.IntegerField()
class StudentModel(models.Model):
_id: int = models.AutoField(primary_key=True, null=False)
name: str = models.CharField(max_length=255)
_teacher_id: int = models.ForeignKey(TeacherModel, on_delete=models.CASCADE, db_column='_teacher_id') # 外键
我们再把眼光跳到应用的 apps.py 这是我们应用的一个AppConfig 比如: studentapps的 AppConfig 就是StudentappConfig 这是应用的灵魂
Django 的应用是可以热插拔的 你可以在任何项目使用同一个应用 !
而我们的AppConfig相当于一个插头,可以使App插入Django项目 我们只需要在 项目的setting.py 中的 INSTALLED_APPS 进行注册即可
注册的方式如下:

在AppConfig 中 有两个属性 name 我们知道是 这个应用的名称 default_auto_field 是指如果模型没有指定主键 那么就会自创建一个主键 这个主键的类型是default_auto_field的值 一般是django.db.models.BigAutoField 指的是巨大数字
给一个Filed设置主键只需要设置参数:
primary_key=True主键默认自动递增
通过模型类 获取对应的建表SQL
迁移是对Django模型的定义变化的存储方式, 我们使用命令 python manage.py makemigrations 应用名称 执行之后我们可以在 应用/migrations/000x_initial.py 中找到迁移的数据,使用第二个命令: python manage.py sqlmigrate 应用名 000x 可以查看迁移的模型的建表SQL
使用命令:
python manager.py sqlmigrate
将模型在SQL语句中创建
模型的curd
使用 python manage.py shell 可以 快速操作模型哦
insert 部分
from StudentApp.models import StudentModel as sm
from TeacherApp.models import TeacherModel as tm
newdata = sm(
name='新增字段', # 普通字段
_teacher_id=tm(_teacher_id=1) # 外键
)
newdata.save()
# 插入成功
- save可以实现插入的操作 也可以实现Update操作
select 部分
使用filter函数进行查找 他的参数是拼接而成的 比如 name__endwith 表示name字段 以参数值结尾的数据的查询
name__endswith结尾__name__contains包含name__isnull为空id__in等于列表元组里的某个值id__lt小于 参数再加个eid__lte小于等于id__gt大于 参数再加个eid__gte大于等于id__year时间在某年id__gt时间在之后- 大小比较可以类比到时间中
id__iexact大小写不敏感
使用函数 exclude 进行反操作
还有很多… 更多查询
delete 部分
如果有查询出的结果 调用结果对象的delete方法就是删除
update 部分
a = sm.objects.all()
for i in a:
i.name= "23"
i.save()
或者是
Example.objects.filter(id=481).update(total_calories = 10)
总结
总而言之 使用Django的模型创建表格需要以下几步
- 编辑
models.py文件,改变模型。 - 运行
python manage.py makemigrations为模型的改变生成迁移文件。 - 运行
python manage.py migrate来应用数据库迁移。
在后期的模型更新的时候你可以不在两个命令后加上应用名
踩坑
有些时候指定了主键但是还是会出现 Django新建字段名称为:id列作为主键,这种情况在模型被其他模型做成了外键的时候会出现, 解决方式是在设置外键的模型字段添加参数db_column 指定列名。
from django.db import models
from teacherapp.models import TeacherModel
class StudentModel(models.Model):
_id: int = models.AutoField(primary_key=True, null=False)
name: str = models.CharField(max_length=255)
_teacher_id: int = models.ForeignKey(TeacherModel, on_delete=models.CASCADE, db_column='_teacher_id') # 外键
模型的其他参考文档:
- 模型字段参考
- 模型
管理页面
首先,我们得创建一个能登录管理页面的用户。请运行下面的命令:
python manage.py createsuperuser
边学记录
Ajax的请求处理
<input type="text" name="name" id="name">
$.ajax({
type: 'post',
url: '/withtag_ajax/',
data: {name: $("#name").val()}, // data直接是js对象
success: function (data) {
$('#info').text(data.msg)
}
}
)
from django.http import HttpRequest, JsonResponse
from django.views import View
from api_blog.models import BlogModels
class api_get_page_blogs(View):
def post(self, response: HttpRequest):
"""
Ajax 请求处理
DESCRIPT
返回指定页数的所有博客
CLient AJAX Format
{
page: xxx // 第几页
pre_page_count: xxx // 每页有X个博客需要展示 默认 5
order: READERCOUNTER | DEFAULT (READERCOUNTER可以缩写为1 表示阅读量 DEFAULT简写为0默认)
}
Server AJAX ForMat
{
data : [{ 'name' : ... , 'page': ... ,'author' : ...}...] // 博客数据
status: 1 | error | 3; 1 表示成功 2表示失败(页数不符合规范或者没有数据) 3表示请求不规范
}
:param response: 浏览器的请求体
:return:Server AJAX JSON
:author LiuBoyuan@qq.com
"""
json = {}
ajax_data: dict = response.POST
now_page = ajax_data.get('page')
pre_page_count = ajax_data.get("pre_page_count")
order = ajax_data.get("order")
if now_page is None or now_page < 0:
return JsonResponse({"status": 'error'})
pre_page_count = pre_page_count if pre_page_count is not None else 5
order_rule = order if order is not None else "DEFAULT"
if order_rule == "READERCOUNTER" or order_rule == 1:
BlogModels.objects.order("reader_count")
slice_index = slice((now_page - 1) * pre_page_count, now_page * pre_page_count)
all_das = BlogModels.objects.all()
ret_das = all_das[slice_index]
if ret_das == [] or not ret_das:
return JsonResponse({"status": 2})
json['data'] = ret_das
json['status'] = 1
return json
DEGUG不同模式下的 static 文件目录 的设置
见:https://zhuanlan.zhihu.com/p/151855280
STATIC_URL = '/static/'
if DEBUG == False:
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
else:
STATICFILES_DIRS = [
os.path.join(BASE_DIR,"static")
]
# setting.py
Session
一般情况下 Session是不会串联的(每个客户单的session单独存在 除非两个客户端的session被同时设值等问题)
def view(req):
req.session['key'] = value
req.seesion.get('key')
...
DRF 前后端分离模式
api 接口与 restful
api 就是一个接口 一个url
restful 中文叫做 资源状态转移(表征状态转义)
实质上 restful 是面对资源进行开发的
我们理解的 Book/add Book/delete 这些路由是不符合restful 规范的
面向资源开发指的是指
针对资源本身 不加入任何动作的规范 add delete属于资源的动作 所以不符合我们的要求。
restful规范是通过请求的类型来规定制定的动作不同
- post 添加数据
- get 获取数据
- get 获取id为pk的数据
- delete id为pk数据的删除
- put 修改一个学生的全部数据
- patch 修改一个学生部分的信息
FBV 和 CBV
实质上 FBV 就是函数视图 CBV 就是类视图
def student(req):
if req.method == 'GET':
return HttpResponse("Get")
elif req.method == 'POST':
return HttpResponse("Post")
以上就是使用 FBV 实现的RESTFUL的函数视图
CBV的实现就是
def StudentView(django.views.View):
def get(self, request):
return HttpResponse("Get")
def post(self, request):
return HttpResponse("Post")
在urls中的注册
urlpatterns = [
path("student/", StudentView.as_view(), name='...')
]
问题:
我写的 CBV 写好了 student 路由的 post 方法 为什么postman的时候获取不到呢?
127.0.0.1:8000/api/student
因为 student后面没有 / 也就是不是 127.0.0.1:8000/api/student/这么结束的时候 Django默认会补全一个/ 从而重定向一个get请求。
源码解析
我们在Path中首先走了as_view() 方法:
@classonlymethod
def as_view(cls, **initkwargs):
"""Main entry point for a request-response process."""
....
$ def view(request, *args, **kwargs):
...
...
$ return view
as_view的大致结构是这样的 前后做了些操作 关键的是: 定义了一个inner函数view 然后将其返回
所以我们在 StudentView.as_view()的部分就是as_view 返回的函数的调用
细看下as_view返回的函数
def view(request, *args, **kwargs):
self = cls(**initkwargs) # 将类进行实例化 谁调用的as_view谁是cls
...
return self.dispatch(request, *args, **kwargs)
view 函数将类进行实例化 然后使用实例化对象的dispatch方法 dispatch方法返回什么 view返回什么
我们细说下dispatch:
def dispatch(self, request, *args, **kwargs):
if request.method.lower() in self.http_method_names:
$ 如果请求在cls的请求列表里(请求类型存在)
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
$ 设置对象的指定请求名称的方法
else:
handler = self.http_method_not_allowed
$ 请求不存在 设置请求不存在方法
return handler(request, *args, **kwargs)
$ 调用设置好的方法 并将结果返回
DRF 与 APIView
pip install djangorestframework
我们将CBA视图的父类修改为APIView如:
from rest_framework.views import APIView
class BookView(APIView):
def get(self, request):
return HttpResponse("Get")
def post(self, request):
return HttpResponse("Post")
我们使用postman测试的时候,发现她返回的数据与功能和View大差不差 是一致的.
源码剖析
前往ApiView类之后我们可以看到该类重写了View的 as_view 类
def as_view(cls, **initkwargs):
if isinstance... $ 滤过
view = super().as_view(**initkwargs) # 调用了View原生的as_view 并接受她的返回值
$ ... 滤过
return csrf_exempt(view) $ 相当与返回view 而且这个API不受csrf保护
我们已经知道了APIView 无非是将View的返回值进行一层csrf_exempt的包装 其余似乎什么也没有 但是我们知道在View中的as_view 他调用了self.dispatch() 这个方法有没有被重写呢 —— 重写了 这是dispatch
def dispatch(self, request, *args, **kwargs):
...
request = self.initialize_request(request, *args, **kwargs)
$ 构建了一个新的request对象
...
return self.response
封装前的request 和 封装后的request
封装之前的request只支持处理UrlEncoded的数据 封装之后便开始支持 Json格式的数据了
当然在此后它还做了认证 权限 限流等组件的初始化
在BookView具体的请求处理函数中 post 可以使用 request.data 来获取请求体 get 就是query_params
class ClassBook(APIView):
def get(req):
data = req.query_params
...
def post(req):
data = req.data
...
序列化
在网络中的序列化就是把模型对象转化为字典 经过response之后 变成Json对象就是序列化 反序列化就是将JSON转化为字典 列表之类的模型的
from django.http import HttpRequest, HttpResponse
from rest_framework import serializers
from rest_framework.response import Response
# Create your views here.
from rest_framework.views import APIView
from sers.models import Book
class BookSerializer(serializers.Serializer):
"""
书籍模型的序列化器
"""
title: str = serializers.CharField(max_length=32)
price: int = serializers.IntegerField()
date: str = serializers.DateField(source='pub_date')
class SersView(APIView):
def get(self, request: HttpRequest):
"""
获取 全部的书籍 数据
:param request:
:return:
"""
book_list = Book.objects.all()
# 使用序列化对象进行序列化
bookSerializer = BookSerializer(
instance=book_list, # 序列化的对象
many=True # 是否同时序列化多个对象
)
ret = bookSerializer.data # 获取序列化的结果
print(ret)
return Response(ret)
def post(self, request: HttpResponse):
"""
添加数据
:param request:
:return:
"""
datas = request.data
bookSerializer = BookSerializer(data=datas) # 反序列化
print(bookSerializer.is_valid()) # 传过来的字段合法吗
"""
合法生成一个 validated_data 对象 里面存储着可以直接被数据库存储的对象数据
不合法生成一个 errors 对象 里面生成了 键值对 键是字段 值是错误的原因
"""
if bookSerializer.is_valid():
print(bookSerializer.validated_data)
Book.objects.create(**bookSerializer.validated_data)
return Response(datas)
else:
return Response(bookSerializer.errors)
我们在对模型数据返回到前台的时候 或者是 需要将前台传来的数据进行模块话的时候 我们可以使用 rest_framework 进行序列化和反序列化的操作:
- 首先我们要将数据进行序列化和反序列化的时候我们需要一个序列模板 他继承了
serializers.Serializer类 serializers.Serializer放着我们想要对模型进行序列化的字段 以及它的数据类型- 创建一个
serializers.Serializer的派生类 传入不同的参数有不同的效果 从而进行序列数据的处理初始化- data - 反序列化
- instance - 序列化
- 序列化的数据可以直接交给Response进行转化为JSON 交给前台
- 反序列化的数据首先要获取数据的合法性 也就是 调用
is_valid()函数 如果True生成一个validated_data对象 里面存储着可以直接被数据库存储的对象 如果Flase 生成一个error对象 里面生成了 键值对 键是字段 值是错误的原因 你可以直接使用Response返回
save和create
为了实现松耦合,我们可以不再添加数据的时候加入代码
Book.objects.create(**bookSerializer.validated_data)
而是使用序列器继承下来的save()函数 也就是
bookSerializer.save()
但是这样会报错 因为在源码中save调用类Serializer的基类的create,但是这个create可以理解成 抽象 的 需要去实现 而且create需要有返回值 这个返回值将会作为这个序列器对象的instance的值 也就默认帮我们将结果的数据进行了序列化 所以我们在Response传给前端的时候 可以直接使用 序列器对象的.data 获得 其 instance 的值。
也就是这样的:
...
class BookSerializer(serializers.Serializer):
...
def create(self, validated_data):
"""
实现create方法从而默许调用 save
:param validated_data:
:return:
"""
return Book.objects.create(**validated_data)# 返回之后默认序列化
class SersView(APIView):
def post(self, request: HttpResponse):
"""
添加数据
:param request:
:return:
"""
...
if bookSerializer.is_valid():
bookSerializer.save()
return Response(datas)
else:
return Response(bookSerializer.errors)
当然除了create save还隐式调用了update 我们可以实现update再序列器中 然后进行调用
序列化器实现增改查查
from django.http import HttpRequest, HttpResponse
from rest_framework import serializers
from rest_framework.response import Response
# Create your views here.
from rest_framework.views import APIView
from sers.models import Book
class BookSerializer(serializers.Serializer):
"""
书籍模型的序列化器
"""
title: str = serializers.CharField(max_length=32)
price: int = serializers.IntegerField()
date: str = serializers.DateField(source='pub_date')
def create(self, validated_data):
"""
实现create方法从而默许调用 save
:param validated_data:
:return:
"""
return Book.objects.create(**validated_data)
def update(self, instance, validated_data):
"""
实现 update 方法从而默许调用save
:param instance:
:param validated_data:
:return:
"""
Book.objects.filter(id=instance.id).update(**validated_data)
return Book.objects.get(id=instance.id)
class SersView(APIView):
def get(self, request: HttpRequest, id:int = None):
"""
获取 全部的书籍 数据
:param request:
:return:
"""
if id is None:
book_list = Book.objects.all()
else:
book_list = Book.objects.get(id=int(id))
# 使用序列化对象进行序列化
bookSerializer = BookSerializer(
instance=book_list, # 序列化的对象
many=True if id is None else False # 是否同时序列化多个对象
)
ret = bookSerializer.data # 获取序列化的结果
print(ret)
return Response(ret)
def post(self, request: HttpResponse):
"""
添加数据
:param request:
:return:
"""
datas = request.data
bookSerializer = BookSerializer(data=datas) # 反序列化
print(bookSerializer.is_valid()) # 传过来的字段合法吗
if bookSerializer.is_valid():
print(bookSerializer.validated_data)
bookSerializer.save()
return Response(datas)
else:
return Response(bookSerializer.errors)
class BookDetailView(APIView):
def get(self, request, _id:str):
if _id.isnumeric():
_id = int(_id)
try:
book = Book.objects.get(id=_id)
except :
return Response("NO Exist")
bookSerializer = BookSerializer(instance=book, many=False)
return Response(bookSerializer.data)
else:
return Response("error")
def put(self, request, _id:str):
"""
设置
:param request:
:param _id:
:return:
"""
request_json = request.data
print(request_json)
if _id.isnumeric():
_id = int(_id)
try:
book = Book.objects.get(id=_id)
bookSerializer = BookSerializer(data=request_json, instance=book)
if bookSerializer.is_valid():
bookSerializer.save()
else:
return Response(bookSerializer.errors)
return Response(bookSerializer.validated_data)
except Exception as e:
return Response(f"error1{e}")
return Response("error2")
ModelSerializer
顾名思义 ModelSerializer 是通过model自动实现序列器对象 不需要手动创建序列器的神器(甚至 create和update 都已经做好了)
class BookSerializer(serializers.Serializer):
title: str = serializers.CharField(max_length=32)
price: int = serializers.IntegerField()
date: str = serializers.DateField(source='pub_date')
def create(self, validated_data):
return Book.objects.create(**validated_data)
def update(self, instance, validated_data):
Book.objects.filter(id=instance.id).update(**validated_data)
return Book.objects.get(id=instance.id)
$ 可以直接这么写:
class BookSerializerAuto(serializers.ModelSerializer):
date = serializers.DateField(source="pub_date")
class Meta:
model = Book
# fiedle = ['title', "price"] # 对指定的字段进行序列化
# fiedle = "__all__" # 对所有字段进行序列化
exclude = ['pub_date'] # 哪些字段不用序列化 因为我们自定义了一个date 所以pub_date可以不要
GenericApiView 视图
其实还是基础的CBV开发模式 只不过在APIView上提供了新的方法而已 依旧采用的dispatch分发的流程,一个简单的增删改查查代码太多了! 我们需要使用一种方式来简化我们的代码 这个时候GenericApiView的好处就来了
常用属性与方法
- get_serializer_class(self)
- 获取序列化器的类
- get_serializer
- 获取序列化器
- get_queryset
- 获取查询结果
- get_object
- 获取模型类数据对象
以上四个方法的作用为调度
- queryset 属性
- 确认数据的全部查询结果
- serializer_class 属性
- 需要使用的序列器
简单的使用
以我们的get请求为例
class SerailizerStudent(ModelSerializer):
class Meta:
model = Student
fields = '__all__'
class StudntView(GenericAPIView):
queryset = Student.objects.all() # 设置查询集
serializer_class = SerailizerStudent # 设置序列器
def get(self, req):
mydatas = self.get_queryset() # 获取自身的查询集
ret = self.get_serializer(instance=mydatas, many=True).data
# 序列器的创建
return response.Response(ret) # 返回
针对主键的查询
我们有些时候并不会获取全部的数据而是获取指定id的数据 那么如何实现呢?
在GenericApiView中我们有一个叫做 lookup_field 的属性 通过 get_object 我们可以获取指定的
mixin
mixin类为 GenericApiView 进行了再一步的封装
- ListModelMixin
- 实现了get的功能在自己的list方法中
- CreateModelMixin
- 实现了post的功能在自己的create方法中
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import *
from rest_framework.serializers import ModelSerializer
from Study.models import Student
class SerailizerStudent(ModelSerializer):
class Meta:
model = Student
fields = '__all__'
class StudntView(GenericAPIView, ListModelMixin, CreateModelMixin):
queryset = Student.objects.all()
serializer_class = SerailizerStudent
def get(self, req):
return self.list(req)
def post(self, req):
return self.create(req)
class StudentDetailView(GenericAPIView, RetrieveModelMixin, DestroyModelMixin, UpdateModelMixin):
queryset = Student.objects.all()
serializer_class = SerailizerStudent
def get(self, req, pk):
return self.retrieve(req)
def put(self, req, pk):
return self.update(req)
def delete(self, req, pk):
return self.destroy(req)
再封装
class StudntView(ListCreateAPIView):
queryset = Student.objects.all()
serializer_class = SerailizerStudent
class StudentDetailView(RetrieveUpdateDestroyAPIView):
queryset = Student.objects.all()
serializer_class = SerailizerStudent
高封装视图
ViewSet
viewset改变了原有的apiview分发机制的逻辑,将单一资源和多资源的查询结合在一起从而简化代码
class StudentView(ViewSet):
def get_object(self, req, pk):
return Response("单一查询")
def get_all(self, req):
return Response("多个查询")
def add_object(self, req, pk):
return Response("添加数据")
def update_object(self, req, pk):
return Response("单一添加")
def delete_object(self, req, pk):
return Response("单一删除")
如上 我们可以自定义方法的名称来区分 单一资源的面向和多资源的面向
对于他的分发点 我们可以在as_view中创建映射
urlpatterns = [
path("student/", StudentView.as_view(
{
"get": "get_all",
"post": "add_object",
}
)),
re_path(r"student/(?P<pk>\d+)", StudentView.as_view(
{
"get": "get_object",
"delete": "delete_object",
"put": "update_object"
}
))
]
ModelViewSet
因为原生的ViewSet继承的是APIView没有GenericApiView的功能自然也用不了Mixin这些好玩意儿, 功能可以说是非常的鸡肋,所以我们推荐使用 GenericViewSet 进行开发 这样我们可以直接映射到Mixin方法里面
path("student/", StudentView.as_view(
{
"get": "list",
"post": "create",
}
))
通过这种方式我们可以实现这样的玩意儿
class StudentView(
ViewSet,
GenericAPIView,
ListModelMixin,
UpdateModelMixin,
CreateModelMixin,
RetrieveModelMixin,
DestroyModelMixin
):
queryset = Student.objects.all()
serializer_class = SerailizerStudent
urlpatterns = [
path("student/", StudentView.as_view(
{
"get": "list",
"post": "create",
}
), name='...'),
re_path(r"student/(?P<pk>\d+)", StudentView.as_view(
{
"delete": "destroy",
"update": "update",
"get": "retrieve"
}
))
]
继承的东西太多了! 直接
class StudentView(ModelViewSet):
queryset = Student.objects.all()
serializer_class = SerailizerStudent
路由
针对Mixin和ViewSet django 有一套路由
from rest_framework.routers import DefaultRouter
from .views import StudentView
route = DefaultRouter()
route.register('student', StudentView)
urlpatterns = []
urlpatterns += route.urls
认证 权限 限流 过滤
在drf的view的源码中,认证权限和限流是在执行dispatch前执行的三件套(在方法initial中执行)
def initial(self, request, *args, **kwargs):
...
self.perform_authentication(request)# 认证
self.check_permissions(request)# 权限武松和
self.check_throttles(request)# 限流
认证权限的开发场景
认证
完成用户信息的判断 确定是否为用户表中的注册用户
权限
判断用户的视图操作权限
用户
普通账号
from django.contrib.auth.models import User
user = User.objects.create_user('john', 'lennon@thebeatles.com', 'johnpassword')
# 可以进行修改
u = User.objects.get(username='john')
u.set_password('new password')
u.save()
超级账号
我们需要用户来进行操作 所有的用户信息都在auth_user里面存放着
admin用户的创建:python manage.py createsuperuser 然后会让你输入Password Email 和Username信息

字段
username
必须。150 个字符或更少。用户名可能包含字母数字,_,@,+,。和 - 字符。如果您使用的 MySQL,请指定 max_length=191,因为默认情况下,MySQL 只能创建 191 个字符的唯一索引。
first_name
可选 (blank=True)。 30 个字符或更少。
last_name
可选 (blank=True)。 150 个字符或更少
email
可选 (blank=True)。邮箱地址。
password
必须。密码的散列和元数据。(Django 不存储原始密码。)原始密码可以是任意长的,并且可以包含任何字符。
groups
多对多关系 Group
user_permissions
多对多关系 Permission
is_staff
Bollean 类型。指定此用户是否可以访问 admin 站点。
is_active
Bollean 类型。指定是否应将此用户帐户视为活动用户。我们建议您将此标志设置为 False 而不是删除帐户;这样,如果您的应用程序对用户有任何外键,外键不会中断。
is_superuser
Bollean 类型。指定该用户具有所有权限而不明确分配它们。
last_login
用户上次登录的日期时间。
date_joined
指定帐户何时创建的日期时间。在创建帐户时默认设置为当前日期/时间
操作
class UserView(APIView):
def get(self, request: Request):
"""
登录
:param request:
:return:
"""
user_info = request.data
username, password = user_info.get("username"), \
user_info.get("password")
print(username, password)
ret = authenticate(
username=username,
password=password
)
print(ret)
return Response({"status": False if ret is None else True})
def post(self, request):
"""
注册
:param request:
:return:
"""
user_info = request.data
username, password = user_info.get("username"), \
user_info.get("password")
try:
User.objects.get(username=username)
return Response({"status": False})
except User.DoesNotExist:
ret = User.objects.create_user(
username=username,
password=password,
email="??@qq.com"
)
return Response({"status": True})
踩坑记录:
创建用户使用的是create_user函数 而不是create
其他操作
from django.contrib.auth import login, logout
user = User.objects.get(username="xxx")
user.set_password("2323") # 设置密码
user.save()
def lv(req):
user = authenticate(username=urn, password=pwd)# 首先校验
a = login(req, user) if user else user is None # 保持登录状态 存放在session中
@login_required # 判断当前有用户登录
def user_center(req):
login_user = req.user # 获取用户
logout(req) # 登出
扩展字段
我们可以内建抽象user模型类
前提 我们需要在一个没有进行migrate的情况下使用该方法
步骤:
- 新建一个应用
python manage.py startapp myNewUser - 定义模型类 继承
AbstractUser - 在Setting中进行设置
AUTH_USER_MODEL = "应用名.类名"
EG:
模型:
from django.contrib.auth.models import AbstractUser
from django.db import models
class MyNewUser(AbstractUser):
phone = models.CharField(max_length=11, default="")
# 在这里添加新的字段
设置:
AUTH_USER_MODEL = "myNewUser.MyNewUser"
认证
def perform_authentication(self, request):
request.user
源码中就做了一件事调用了request的user属性方法
@property
def user(self):
if not hasattr(self, '_user'):
with wrap_attributeerrors():
self._authenticate()
return self._user
没有_user的时候我们就去_authenticate里面一探究竟。
def _authenticate(self):
for authenticator in self.authenticators:
try:
user_auth_tuple = authenticator.authenticate(self)
except exceptions.APIException:
self._not_authenticated()
raise
if user_auth_tuple is not None:
self._authenticator = authenticator
self.user, self.auth = user_auth_tuple
return
self._not_authenticated()
至于这个authenticators是什么我们还得回去看看我们dispatch创建request对象的地方:
file:view.py
...
def initialize_request(self, request, *args, **kwargs):
"""
Returns the initial request object.
"""
parser_context = self.get_parser_context(request)
return Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
.....
def get_authenticators(self):
return [auth() for auth in self.authentication_classes]
至于这个authentication_classes是什么我们可以前往rest_framework的Setting(不是项目的Setting!)里面的 DEFAULTS 里面进行查看。
'DEFAULT_AUTHENTICATION_CLASSES': [
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication'
],
我们可以看到这里面是一个默认存储了Session的验证机制(Session验证机制是基于Basic的所以需要加入)
因为在perform_authentication中我们调用了了Request的user 也就是获取属性方法 - user的返回值 其属性方法主要的内容就是self._authenticate, 而 self._authenticate 做的主要的事情就是做的主要的事情就拿到authenticators 里面的对象的authenticate方法的返回值 默认返回一个元组 格式: (user, token)。
然后将返回值返回给 request 的 user和auth
所以我们可以在自己的StudentView(自定义的视图里面进行 重写authentication_classes)
class StudentView(ModelViewSet):
authentication_classes = [
]
queryset = Student.objects.all()
serializer_class = SerailizerStudent
这是局部的配置 如果要做全局的配置那么就再Setting里面进行设置
REST_FRAMEWORK = {
"DEFAULT_AUTHENTICATION_CLASSES":[]
}
自定义认证器
我们可以先看看默认的用户是什么, 通过request.user获取
class StudentView(ModelViewSet):
authentication_classes = [
]
queryset = Student.objects.all()
serializer_class = SerailizerStudent
def retrieve(self, reqest, *args, **kwargs):
print(reqest.user)
return super().retrieve(reqest, *args, **kwargs)
通过 http://127.0.0.1:8000/student/1 获得到了: AnonymousUser 也就是匿名用户 好的我们给这个Views一个局部的认证器罢:
class Authen(BaseAuthentication):
def authenticate(self, request):
return ("NoAdmin", None)
class StudentView(ModelViewSet):
authentication_classes = [
Authen
]
...
当列表存在多个认证器 遍历 如果认证器返回值不为空 其后面的认证器不在执行
简单DEMO
class Authen2(BaseAuthentication):
def authenticate(self, request:Request):
user = request.META.get('HTTP_X_USERNAME')
# 获取请求头需要 在请求头前面加上HTTP_
print(user)
if user:
try:
user_obj = User.objects.get(username=user)
return (user_obj, None)
except User.DoesNotExist:
return None
return None
class Permissions(BasePermission):
def has_permission(self, request, view):
print(request.user.username)
if request.user.is_superuser == 1:
print("超级用户来啦")
return True
return False
class StudentView(ModelViewSet):
authentication_classes = [
Authen2
]
permission_classes = [
Permissions
]
queryset = Student.objects.all()
serializer_class = SerailizerStudent
def retrieve(self, reqest, *args, **kwargs):
print(reqest.user)
print(reqest.auth)
return super().retrieve(reqest, *args, **kwargs)
权限
权限同理 到get_permissions 中获取由 self.permission_classes 构成的对象列表 默认是在DEFAULTS里的PERMISSION_CLASSES里面
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.AllowAny',
],
这个表示的是允许任何权限
class AllowAny(BasePermission):
def has_permission(self, request, view):
return True
AllowAny 就是无脑返回True
k def check_permissions(self, request):
for permission in self.get_permissions():
if not permission.has_permission(request, self):
# 在权限列表中,只要有一个权限对象返回的是 False 那么就是无权限
self.permission_denied(
request,
message=getattr(permission, 'message', None),
code=getattr(permission, 'code', None)
)
Django 缓存优化
Django缓存优化
目的
每次对于热数据的访问,都需要使用Mysql等数据库进行增删改查,为了减小数据库的压力我们通常将热数据放在缓存中进行操作
- 减小过载
- 避免重复计算
- 提高技能
流程
- 给定一个服务请求
- 查询页面
- 如果缓存命中: 返回缓存的页面
- 如果缓存不命中: 生成页面,将页面进行缓存(可以采用
lru等算法) 并返回页面
缓存类型
- Memcached
- 内存缓存 最快最有效
- Database caching
- 数据库存储
- 比如有两个表 表A的数据很麻烦 非常麻烦每次查询都十分的消耗时间 这个时候我们可以将查询的结果放在表B中进行存储,下一次就可以直接在表B中进行简单的查询。
- FileSystem caching 不推荐
- 将缓存存成某个文件
- Local-memory caching 不推荐
- 本地缓存 存储在服务器的内存之中
- LOCATION可以指定成
unique-snowflake雪花缓存算法进行内存地址寻址而不是指定地址
- Dummy caching 不推荐
- 仿缓存 假的
- Using a custom cache backend
- 自开发
缓存粒度
- per-site cache
- 网站全局缓存 整个站点进行缓存
- per-view cache
- 对某个指定的视图进行缓存
- 模板缓存 Template fragment caching
- Low-level cache API
- 低级缓存对某一个部分进行缓存
Django的配置
先pip一个库: pip install python-memcached
CACHES = {
'default':{
"BACKEND": # 引擎策略
"django.core.cache.backends.memcached.MemcachedCache",
"LOCATION": "127.0.0.1:11211", # IP地址 可以是列表 代表一个集群
"TIMEOUT": 300, # 保存的过期时间,
"OPTIONS":{
"MAX_ENTRIES": 300, # 缓存最大的数据量
"CULL_FREQUENCY": 2 # 缓存条数达到最大值的时候 删除 1/2(2是字面量) 条数据
}
}
}
其中LOACTION可以是一个IP的列表 代表一个缓存的集群
DatabaseCache
配置:
CACHES = {
'default':{
"BACKEND":"django.core.cache.backends.db.DatabaseCache",
"LOCATION": "my_cache_table", # 表名称
"TIMEOUT": 300
}
}
使用命令 python manage.py createcachetable 在数据库中创建指定名称的缓存表 并且使用 mirate 进行数据表的迁移
创建好的数据表有三个字段: cache_key value expires 键 值 过期时间
per-view cache
将某个视图函数直接进行缓存
@cache_page(30)
def retrieve(self, reqest, *args, **kwargs):
if reqest.user.is_staff == 1:
cache1 = cache.get("adminUser")
print(cache1)
if cache1 is None:
print("缓存未命中")
cache.set('adminUser', reqest.user.username, 30)
cache1 = cache.get("adminUser")
print("cache", cache1)
return super().retrieve(reqest, *args, **kwargs)
@cache_page(30)
def get_html(req, username):
s = time.time()
user = User.objects.get(username=username)
return HttpResponse(f"<h1>HelloWorld, 你是员工吗:{user.is_staff} <hr> 消耗时间:{time.time() - s}</h1>")
如果我们开启了缓存会发现 所显示的消耗的时间是不会被改变的 因为他已经将固定的返回内容进行了缓存 导致界面无法进行更新
Low-level cache API
我们观察上面的代码 其实慢就满载对User模型的查询部分我们能不能对其进行单独的提取从而进行缓存呢? 答案是可以的
我们在Setting里面的配置项可以是多个 其中默认是default那个表示默认的default. 我们使用from django.core.cache import cache 可以直接使用 default配置项里面的数据,但是你也可以使用from django.core.cache import caches 然后 caches['default'] 也可以
from django.core.cache import cache
...
cache.set("hot_data_blog", "【热门】", 20) # 设置热点数据到缓存服务器上
cache.get("hot_data_blog") # 获取
cache.add("hot_data", "Value")# 添加数据 只有key值不存在才生效
例如代码:
class StudentView(ModelViewSet):
authentication_classes = [
Authen2
]
permission_classes = [
IsAuthenticated
]
queryset = Student.objects.all()
serializer_class = SerailizerStudent
def retrieve(self, reqest, *args, **kwargs):
if reqest.user.is_staff == 1:
cache1 = cache.get("adminUser")
print(cache1)
if cache1 is None:
print("缓存未命中")
cache.set('adminUser', reqest.user.username, 30)
cache1 = cache.get("adminUser")
print("cache", cache1)
return super().retrieve(reqest, *args, **kwargs)
浏览器缓存策略
浏览器请求某个路由的时候
- 发送请求到缓存中 如果缓存有该路由的缓存 直接渲染浏览器(缓存命中)
- 没有的话才会想服务器请求
- 请求好了 浏览器将服务器返回的数据交给缓存进行存储
中间件
中间件是一个请求/响应处理的钩子框架 轻量 低级的插件 用于全局改变输入和输出
当请求发送给服务器的时候 中间件可以在主路由前 视图前做一定的处理(或者是拦截) 或者是服务器发送响应给浏览器的时候也需要通过中间件 当然中间件的类型还有很多 不一一举例
中间件以类定义 需要继承类 django.utils.deprecation.MiddlewareMixin 类
定义
from django.utils.deprecation import MiddlewareMixin
class RouterMiddleWare(MiddlewareMixin):
"""
一个合格的中间件 需要有以下的函数 可以是多个!
以下函数都需要返回数据:
None: 继续王下周
HttpResponse: 结束了 不用继续了 我把数据返回给你就是
"""
def process_request(self, request, callback=None, callback_args=None, callback_kwargs=None):
"""
执行路由之前被调用 在每个请求上调用
"""
print("-process_request-")
def process_view(self, request,callback=None, callback_args=None, callback_kwargs=None):
"""
调用视图之前被调用
"""
print("-process_view-")
def process_response(self, request, response,callback=None, callback_args=None, callback_kwargs=None):
"""
所有响应返回给浏览器被调用 只能返回 HttpResponse
"""
print("-process_response-")
return response
注册
我们可以在setting里面进的MiddleWare进行注册
执行的顺序
在视图返回数据之前 按照注册顺序执行 在视图函数之后 注册顺序的逆序执行
例子
让浏览器每次指定访问次数
from django.http import HttpResponse
from django.utils.deprecation import MiddlewareMixin
from collections import defaultdict
import schedule
class LimitRequestRoute(MiddlewareMixin):
visit_log = defaultdict(lambda :0)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
schedule.every(10).seconds.do(self.clear)
print("[中间件/LimitRequestRoute]: 开始执行数据")
def clear(self):
self.visit_log.clear()
print("[中间件/LimitRequestRoute]: 缓存被清空")
def process_request(self, request, **kwargs):
value = request.META.get("REMOTE_ADDR")
schedule.run_pending()
if self.visit_log[value] <= 4:
self.visit_log[value] += 1
print(self.visit_log)
else:
return HttpResponse("你的访问次数超过正常值 请在10秒后重试")
分页
有一个叫做Paginator的类 很nice
实例化
page = Paginator(object_list, pre_pages)
- object_list 数据列表
- pre_pages 每页的数据量
使用
它有这些
、数据
- count 数据的长度
- num_pages 分页后的总数
- page_range: 当前所有的页数
- page(number)
- 返回number页码的信息(从1开始而不是0)
- 如果不存在 抛出
InvalidPage的异常 - 返回的信息数据有这些属性
- object_list 当前页上所有数据的对象列表
- number 当前页的序号
- paginator 当前page的Paginator对象
- has_next() 下一页有吗
- has_previous() 上一页有吗
- has_other_pages() 有上一页和下一页吗
- next_page_number() 下一页的页码 如果不存在抛出InvalidPage异常
- previous_page_number() 上一页的页码 如果不存在抛出InvalidPage异常
文件上传
我们先做个前端:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.staticfile.org/jquery/3.6.1/jquery.min.js"></script>
</head>
<body>
<style>
#form {
width: 60%;
margin: auto;
}
input {
display: block;
width: 100%;
margin-bottom: 20px;
height: 50px;
font-size: 2rem;
}
</style>
<form id="form" method="post" enctype="multipart/form-data" action="/file/upload/">
<input type="file" id="ac">
<input type="submit" value="登录" id="dl">
</form>
</body>
</html>
后端:
def file_update(req: Request):
if req.method == 'POST':
file: InMemoryUploadedFile = req.FILES.get('user_file')
print(type(file))
if file is None: return HttpResponse("上传失败 - 文件为空")
filename = file.name
return HttpResponse(f"你的文件是{filename}, 大小 {file.size} KB")
else:
return HttpResponse("不支持的类型")
在Django中 我们将客户端上传的资源称之为: media 资源 区别于 static 资源
这是对 media 资源的配置
MEDIA_URL = "/media/" # 加载资源的时候 路由需要以MEDIA_URL开头
MEDIA_ROOT = os.path.join(BASE_DIR, "media")
我们还需要在主路由里面配置MEDIA_URL设置的路由
from django.conf import settings
from django.conf.urls import static
urlpatterns += static(
settings.MEDIA_URL,
document_root=settings.MEDIA_ROOT
)
文件存储
方案一: open() 传统法则
file_path = os.path.join(settings.MEDIA_ROOT,file.name)
with open(file_path, 'wb') as f:
f.write(file.file.read())
缺点:容易重复名称
方案二:文件ORM
1: 创建一个模型
from django.db import models
class Content(models.Model):
title = models.CharField("name", max_length=11)
path = models.FileField(upload_to="picture") # upload_to 表示的是子目录
- 使用
def file_update(req: Request):
if req.method == 'POST':
file: InMemoryUploadedFile = req.FILES.get('user_file')
print(type(file))
if file is None: return HttpResponse("上传失败 - 文件为空")
filename = file.name
Content.objects.create(title=filename, path=file)
return HttpResponse(f"你的文件是{filename}, 大小 {file.size} KB")
else:
return HttpResponse("不支持的类型")
项目部署
部署机器: Centos
runserver 的能力很差 我们一般使用 uwsgi 进行
uWSGI
定义
是一个新的web网关接口 是将Python应用放在web服务器之间的一种接口 被广泛的使用 我们平时使用的runserver 是一种很拉的测试环境使用的接口(但是如果没有runserver django根本和http无关).
通俗的说 wsgi就是一种http和django之间的翻译而且实现了uwsgi的协议功能完善协议众多。
我们可以使用 pip install uwsgi进行安装
报错解决:
yum install -y gcc* pcre-devel openssl-devel
yum install -y python-devel
# 或者是yum install -y python3-devel
pip3 install uwsgi
我们要在于主应用目录中设置一个ini配置文件
[uwsgi]
#socket=0.0.0.0:9876
http=0.0.0.0:9876 ;让uwsgi 默认在9876端口开启http服务
chdir=/xxx/xxx/xxx/ ; 项目的路径 必须是绝对路径
wsgi-file=blog/wsgi.py ; 告诉uwsgi: wsgi的路径 相对路径
process=1
thread=2
pidfile=us.pid ; 服务的pid
daemonize=x.log ; 日志
master=true ; 主进程的管理
然后我们直接运行:
uwsgi --ini uwsgi.ini