3.线性神经网络----动手学深度学习
线性回归的从0开始实现
随机梯度下降
小批量随机梯度下降
在每次迭代中,我们首先随机抽样一个小批量
B
\mathcal{B}
B, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数
η
\eta
η,并从当前参数的值中减掉。

批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。 这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter).
调参(hyperparameter tuning)是选择超参数的过程。 超参数通常是我们根据训练迭代结果来调整的, 而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
用未包含在训练数据中的数据来测试模型的时候叫预测or推理
高斯分布
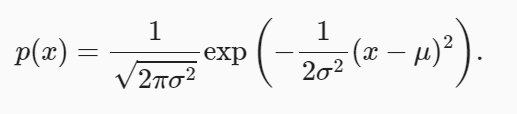
import math
import time
import numpy as np
import torch
from d2l import torch as d2l
def normal(x, mu, sigma):
p = 1/math.sqrt(2 * math.pi * sigma**2)
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)
# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01)
# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',
ylabel='p(x)', figsize=(4.5, 2.5),
legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])
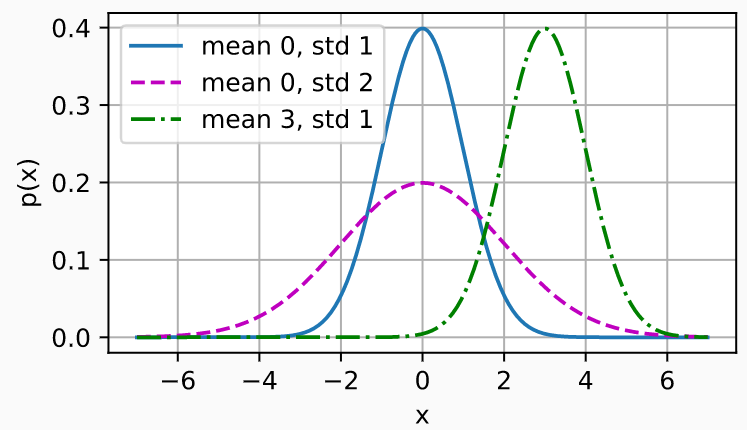


以上就是为了说从概率的角度来看最小二乘,当 σ \sigma σ为一个定值时,最小化 ( y − y ˆ ) 2 (y-\^{y})^2 (y−yˆ)2就是最小化 − l o g P ( y ∣ X ) -logP(\bf{y}|\bf{X}) −logP(y∣X)
torch.Tensor.detach()
detach():从计算图中脱离出来
参考博客