数据挖掘-模型的评估(四)

目录
一、混淆矩阵与准确率指标
二、业务抽样评估
三、泛化能力评估
四、其他评估指标
五、评估数据的处理
总结
模型评估是对模型进行多种维度的评估,来确认模型是否可以放到线上去使用。
例子:
“识别图片是不是关于小狗”的分类模型:
有1000张图片用于测试该模型的效果
并且预先已经进行了人工的标注(这里假设人工标注的数据都是100%正确)
每张图都会标注是或者不是小狗的图片,假设有800张标注“是”,200张标注“否”

一、混淆矩阵与准确率指标
准确率相关指标:
可以直接反映一个模型对于样本数据的学习情况,是一种标准化的检验
矩阵中包含4种数值:
1.真阳性(True Positive,TP)∶小狗图被判定为小狗图
样本的真实类别是正例,并且模型预测的结果也是正例(在本案例中此数值为745)
2.真阴性(True Negative,TN)︰不是小狗图被判定为不是小狗图
样本的真实类别是负例,并且模型将其预测成为负例(在本案例中此数值为175)
3.假阳性(False Positive,FP)︰不是小狗图被判定为小狗图
样本的真实类别是负例,但是模型将其预测成为正例(在本案例中此数值为25)
4.假阴性(False Negative,FN) :小狗图被判定为不是小狗图
样本的真实类别是正例,但是模型将其预测成为负例(在本案例中此数值为55)
准确率(Accuracy):所有预测正确的占全部样本的概率。
在本案例中为(745+175)/(745+175+25+55)=0.92。
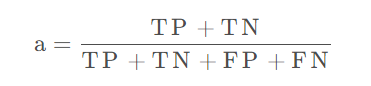
accuracy局限性:准确率是分类问题最简单也是最直接的评价标准,但存在明显的缺陷。如:当负样本数占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
精确率(Precision):预测正确的结果占所有预测成“是”的概率,即TP/(TP+FP)“是小狗图”类别的精确率是745/(745+25)~ 0.9675。
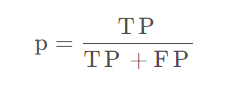
召回率(Recall):该类别下预测正确的结果占该类别所有数据的概率,即TP/(TP+FN)本案例中“是”类别召回率745/(745+55)~0.93。
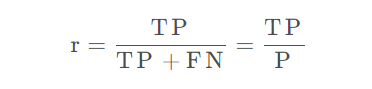
F值(F Score) :准确率和召回率的调和平均值。计算方法 2*(Accuracy*Recall)/ (Accuracy+Recall)如果一个模型的准确率为0,召回率为1,那么F值仍然为0。
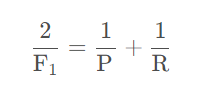
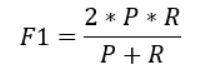
ROC曲线和AUC值:构建了很多组混淆矩阵
在有些模型的产出中
通常给出“是”和“否”的概率值(这两个概率值相加为1)根据概率值来判定最终的结果
指定“是”的概率为0.1及以上时,就判定结果为“是”
“是”的概率小于0.1时,判定结果为“否”
在每一组混淆矩阵中,获取两个值:
真正例率:TP/ (TP+FN)
假正例率:FP/(FP+TN)
横坐标为真正例率,纵坐标为假正例率。
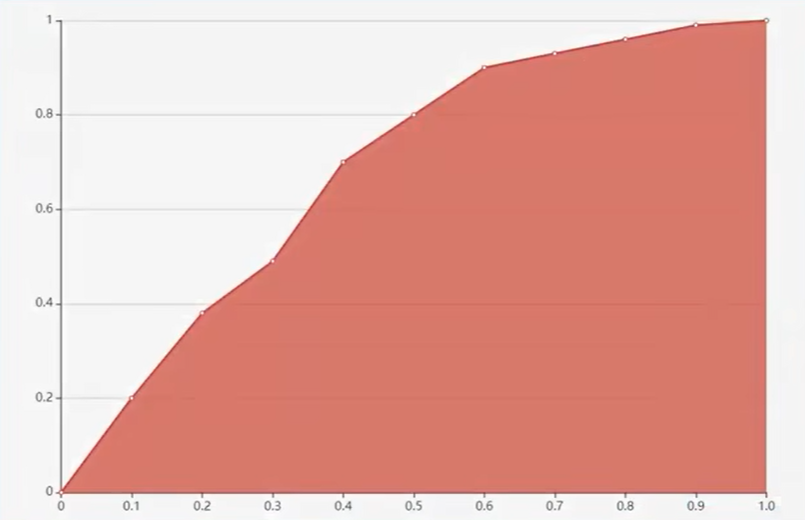
ROC和AUC值
二、业务抽样评估
在实际中存在一些问题,通常是由数据本身并不完美导致的。
对于标注数据,人工标注通常也存在一定的错误率,不是100%正确。
业务抽样评估可以减弱这种情况。
三、泛化能力评估
泛化能力反映的是模型对未知数据的判断能力。
在数据挖掘中,数据的维度通常有很多,数据也都是非标准值。
泛化能力好的模型在数据存在着波动的情况下,能够做出正确的判断。
过拟合(overfitting)与欠拟合(underfitting)
过拟合:模型在训练集上表现良好,而在测试集或者验证集上表现不佳。
欠拟合:在训练集和测试集上的表现都不好。
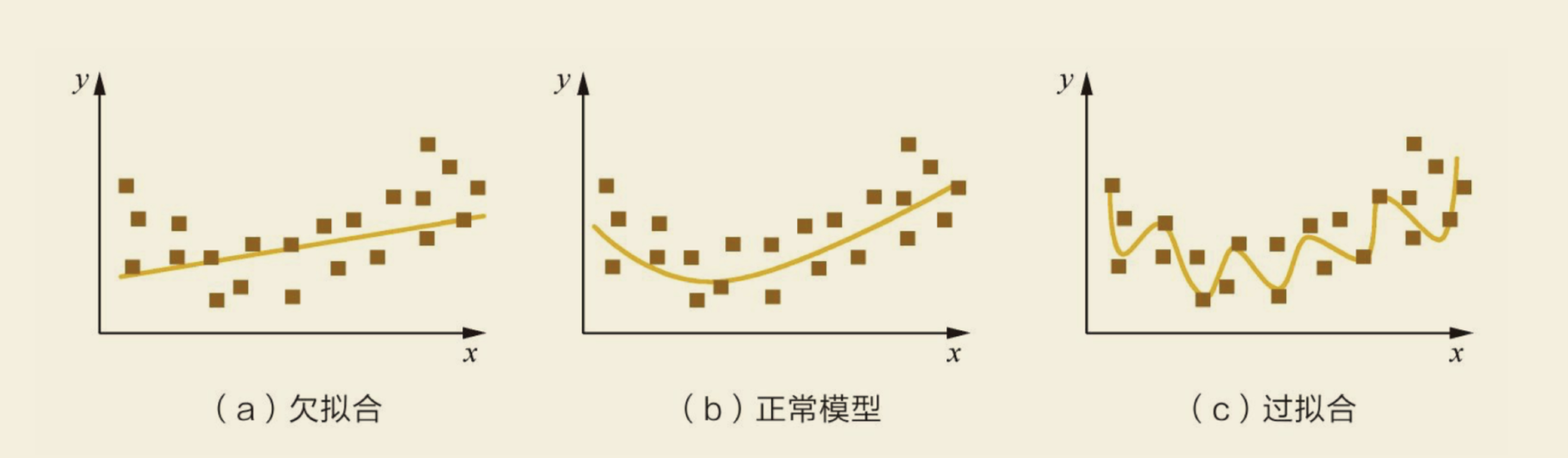
泛化性能的评估依赖于在不同的数据集上的准确结果之间的比较
处理过拟合和欠拟合的问题
需要对数据进行重新整理,总结出现过拟合和欠拟合的原因,然后调整数据重新进行训练
四、其他评估指标
- 模型速度:主要评估模型在处理数据上的开销和时间
- 鲁棒性:主要考虑在出现错误数据或者异常数据甚至是数据缺失时,模型是否可以给出正确的结果,甚至是否可以给出结果,会不会导致模型运算的崩溃
- 可解释性:在很多场景下(比如金融风控),需要给出一个让人信服的理由
五、评估数据的处理
随机抽样:把数据分成训练集与测试集,使用测试集对模型进行测试,得到各种准确率指标。
随机多次抽样:在随机抽样的基础上,进行n次随机抽样,得到n组测试集使用这n组的平均值作为最终结果。
交叉验证:需要训练多个模型。把原始数据分为k份,每次选取其中的一份作为测试集其他的作为训练集训练一个模型,计算这k个模型结果作为整体获得的准确率。
自助法:随机有放回地抽取样本,构建一个训练集,对比原始样本集和该训练集。
把训练集中未出现的内容整理成为测试集。重复这个过程k次、构建出k组数据、训练k个模型
计算这k个模型结果作为整体获得的准确率。
总结
模型的各种评估指标,从一个混淆矩阵出发,衍生出一系列的准确度评测。
对模型泛化能力进行评估。
介绍了如何在数据上进行一些优化从而减少评估时产生误差。