Pytorch的加速和优化
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
PyTorch on a TPU
PyTorch on Multiple GPUs(单台计算机)
数据并行处理
使用 nn 的多线程方法。数据平行
使用 DDP 的多进程方法(首选)
模型并行处理
组合数据并行处理和模型并行处理
分布式训练(多台机器)
模型优化
超参数优化
量化
修剪
修剪模型示例
本地和全局修剪
修剪接口
自定义修剪方法
您学习了如何使用 PyTorch 的内置功能,并通过创建自己的用于深度学习的自定义组件来扩展这些功能。这样做使您能够快速设计新的模型和算法来训练它们。
但是,在处理非常大的数据集或更复杂的模型时,在单个 CPU 或 GPU 上训练模型可能需要很长时间,可能需要数天甚至数周才能获得初步结果。较长的训练时间可能会令人沮丧,尤其是当您想要使用不同的超参数配置进行许多实验时。
在本章中,我们将探讨使用 PyTorch 加速和优化模型开发的最新技术。首先,我们将研究使用张量处理单元 (TPU) 而不是 GPU 设备,并考虑使用 TPU 可以提高性能的实例。接下来,我将向您展示如何使用 PyTorch 的内置功能进行并行处理和分布式训练。这将为跨多个 GPU 和多台机器训练模型提供快速参考,以便在有更多硬件资源可用时快速扩展训练。在探索加速训练的方法之后,我们将了解如何使用超参数优化、量化和修剪等高级技术来优化模型。
本章还将提供参考代码,以便于入门,并参考我们使用过的关键包和库。创建模型和训练循环后,可以返回到本章,了解有关如何加速和优化训练过程的提示。
让我们首先探讨如何在 TPU 上运行模型。
PyTorch on a TPU
随着深度学习和人工智能的日益普及,公司正在开发定制硬件芯片或ASIC,旨在优化硬件中的模型性能。谷歌开发了自己的用于NN加速的ASIC,称为TPU。由于TPU是为NN设计的,因此它没有GPU的一些缺点,GPU是为图形处理而设计的。谷歌的TPU现在可供您作为谷歌云TPU的一部分使用。您也可以使用TPU运行谷歌实验室。
在前面的章节中,我向您展示了如何使用 GPU 测试和训练深度模型。如果以下条件适用于您的使用案例,则应继续使用 CPU 和 GPU 进行训练:
-
您有具有小批量大小的小型或中型模型。
-
您的模型不需要很长时间来训练。
-
将数据移入和移出是您的主要瓶颈。
-
您的计算经常是分支或主要按元素完成的,或者您使用稀疏内存访问。
-
您需要使用高精度。双打不适合 TPU。
另一方面,您可能希望使用TPU而不是GPU进行训练有几个原因。TPU在执行密集矢量和矩阵计算方面非常快。它们针对特定工作负载进行了优化。当以下情况适用于您的使用案例时,您应强烈建议您考虑使用 TPU:
-
您的模型以矩阵计算为主。
-
模型的训练时间很长。
-
您希望在 TPU 上运行整个训练循环的多次迭代。
在 TPU 上运行与在 CPU 或 GPU 上运行非常相似。让我们在下面的代码中重新讨论如何在 GPU 上训练模型:
device = torch.device("cuda" if
torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(n_epochs):
for data in trainloader:
input, labels = data
input = input.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(input)
loss = criterion(input, labels)
loss.backward()
optimizer.step()- 将设备配置为 GPU(如果可用)。
- 将模型发送到设备。
- 将输入和标签发送到 GPU。
也就是说,我们将模型,输入和标签移动到GPU,其余的为我们完成。在 TPU 上训练网络几乎与在 GPU 上训练网络相同,只是您需要使用 PyTorch/XLA(加速线性代数)软件包,因为 PPU 目前不受 PyTorch 的本机支持。
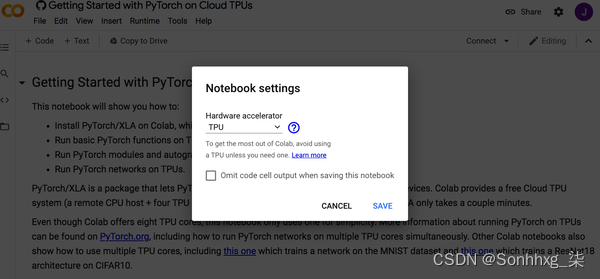
让我们使用谷歌协作实验室在云 TPU 上训练我们的模型。打开一个新的 Colab 笔记本,然后从运行时菜单中选择更改运行时类型。然后从“硬件加速器”下拉菜单中选择 TPU,如图 1-1 所示。谷歌Colab提供免费的云TPU系统,包括一个远程CPU主机和四个TPU芯片,每个芯片有两个内核。
由于 Colab 默认情况下没有安装 PyTorch/XLA,我们需要先使用以下命令进行安装。这将安装最新的“夜间”版本,但如果需要,您可以选择其他版本:
!curl 'https://raw.githubusercontent.com/pytorch' \
'/xla/master/contrib/scripts/env-setup.py' \
-o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version "nightly" <1>这些命令是要在笔记本中运行的命令。省略 “!” 以在命令行上运行它们。
安装 PyTorch/XLA 后,我们可以导入软件包并将数据移动到 TPU:
import torch_xla.core.xla_model as xm
device = xm.xla_device()请注意,我们在此处不使用,因为它仅适用于 GPU。不幸的是,TPU没有方法。如果您的环境未针对 TPU 进行配置,则会出现错误。torch.cuda.is_available()is_available()
设置设备后,其余代码完全相同:
model.to(device)
for epoch in range(n_epochs):
for data in trainloader:
input, labels = data
input = input.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(input)
loss = criterion(input, labels)
loss.backward()
optimizer.step()
print(output.device)
# out: xla:1如果 Colab 是为 TPU 配置的,您应该会看到 。xla:1
PyTorch/XLA 是 XLA 操作的通用库,除了 TPU 之外,还可以支持其他专用 ASIC。有关熊猫/XLA 的更多信息,请访问熊猫/XLA GitHub 存储库。
在 TPU 上运行仍存在许多限制,并且 GPU 支持更为广泛。因此,大多数PyTorch开发人员首先会使用单个GPU对代码进行基准测试,然后探索使用单个TPU或多个GPU来加速其代码。
我们在本书前面已经介绍了如何使用单个 GPU。在下一节中,我将向您展示如何在具有多个 GPU 的计算机上训练模型。
PyTorch on Multiple GPUs(单台计算机)
在加速培训和开发时,充分利用可用的硬件资源非常重要。如果您有一台本地计算机或网络服务器可以访问多个 GPU,本节将向您展示如何充分利用系统上的 GPU。此外,您可能希望通过在单个实例上使用云 GPU 来扩展 GPU 资源。这通常是考虑分布式训练方法之前的第一级缩放。
跨多个 GPU 运行代码通常称为并行处理。并行处理有两种方法:数据并行处理和模型并行处理。在数据并行处理期间,数据批次在多个 GPU 之间拆分,而每个 GPU 运行模型的副本。在模型并行处理期间,模型在多个 GPU 之间拆分,数据批处理通过管道传送到每个部分。
数据并行处理在实践中更常用。模型并行处理通常用于模型不适合单个 GPU 的情况。在本节中,我将向您展示如何执行这两种类型的处理。
数据并行处理
图 1-2 说明了数据并行处理的工作原理。在此过程中,每个数据批处理被拆分为 N 个部分(N 是主机上可用的 GPU 数)。N 通常是 2 的幂。每个 GPU 都保存模型的副本,并计算批次每个部分的梯度和损失。梯度和损失在每次迭代结束时合并。此方法适用于较大的批大小和模型适合单个 GPU 的用例。
数据并行处理可以在PyTorch中使用单进程,多线程方法或使用多进程方法实现。单进程、多线程方法只需要一行额外的代码,但在许多情况下性能不佳。
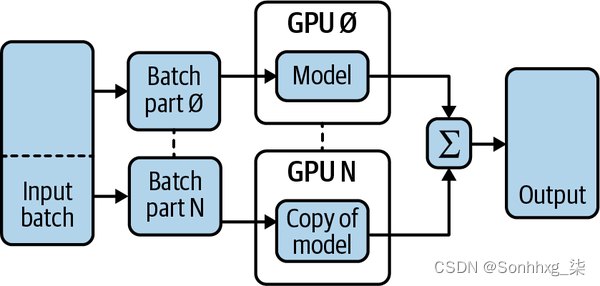
图 1-2。 数据并行处理
不幸的是,由于Python的全局解释器锁(GIL)跨线程的争用,模型的每次迭代复制以及分散输入和收集输出引入的额外开销,多线程性能不佳。您可能希望尝试此方法,因为它非常简单,但在大多数情况下,您可能会使用多进程方法。
使用 nn 的多线程方法。数据平行
PyTorch 的模块本身就支持多线程数据并行处理方法。您需要做的就是在将模型发送到 GPU 之前将其包装进去,如以下代码所示。在这里,我们假设您已经实例化了模型:nnnn.DataParallel
if torch.cuda.device_count() > 1:
print("This machine has",
torch.cuda.device_count(),
"GPUs available.")
model = nn.DataParallel(model)
model.to("cuda")
首先,我们检查以确保我们有多个GPU,然后我们使用设置数据并行处理,然后将模型发送到GPU。nn.DataParallel()to(device)
这种多线程方法是在多个GPU上运行的最简单方法。但是,多进程方法通常表现更好,即使在单台计算机上也是如此。此外,多进程方法还可用于跨多台计算机运行,我们将在本章后面看到。
使用 DDP 的多进程方法(首选)
跨多个 GPU 训练模型最好使用多进程方法完成。派托奇通过其模块支持这一点。分布式数据处理 (DDP) 可以与单台计算机上的多个进程一起使用,也可以与多台计算机上的多个进程一起使用。我们将从一台机器开始。nn.parallel.DistributedDataProcessing
修改代码需要执行四个步骤:
- 使用torch.distributed.初始化进程组。
- 使用 torch.nn.to()创建本地模型。
- 使用torch.nn.parallel使用 DDP 包裹模型。
- 使用torch.nn.parallel生成进程。
以下代码演示如何转换模型以进行 DDP 训练。我们将它分解为几个步骤。首先,导入必要的库:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel \
import DistributedDataParallel as DDP请注意,我们正在使用三个新库 : 火炬.分布式、火炬.多处理和火炬.nn.并行。以下代码说明如何创建分布式训练循环:
def dist_training_loop(rank,
world_size,
dataloader,
model,
loss_fn,
optimizer):
dist.init_process_group("gloo",
rank=rank,
world_size=world_size)
model = model.to(rank)
ddp_model = DDP(model,
device_ids=[rank])
optimizer = optimizer(
ddp_model.parameters(),
lr=0.001)
for epochs in range(n_epochs):
for input, labels in dataloader:
input = input.to(rank)
labels = labels.to(rank)
optimizer.zero_grad()
outputs = ddp_model(input)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
dist.destroy_process_group()- 设置包含流程的流程组。world_size
- 将模型移动到 ID 为 的 GPU。rank
- 将模型包装在 DDP 中。
- 将输入和标签移动到 ID 为 的 GPU。rank
- 为正向传递调用 DDP 模型。
DDP 将模型状态从进程广播到所有其他进程,因此我们不必担心不同进程具有不同初始化权重的模型。rank0
DDP 处理较低级别的进程间通信,这些通信允许您将模型视为本地模型。在向后传递期间,DDP 会自动同步渐变,并在返回时将同步的梯度张量放在 params.grad 中。loss.backward()
现在我们已经定义了进程,我们需要使用函数创建这些进程,如下面的代码所示:spawn()
if __name__=="__main__":
world_size = 2
mp.spawn(dist_training_loop,
args=(world_size,),
nprocs=world_size,
join=True)在这里,我们运行代码以生成两个进程,每个进程都有自己的GPU。这就是您在一台机器上的多个 GPU 上运行数据并行处理的方式。main
警告
GPU 设备不能跨进程共享。
如果您的模型不适合单个 GPU,或者您使用的是较小的批大小,则可以考虑使用模型并行处理而不是数据并行处理。我们接下来将对此进行研究。
模型并行处理
图 1-3 说明了模型并行处理的工作原理。在此过程中,模型将拆分为同一台计算机上的 N 个 GPU。如果我们按顺序处理数据批次,则下一个GPU将始终等待前一个GPU完成,这违背了并行处理的目的。因此,我们需要对数据处理进行管道化处理,以便每个GPU在任何给定时刻都在运行。当我们对数据进行管道处理时,仅按顺序运行前 N 个批次,然后每次后续运行都会激活所有 GPU。
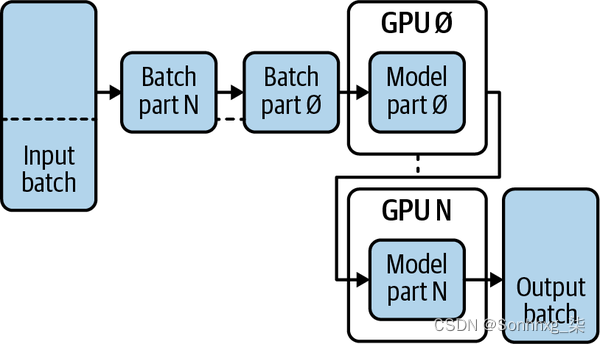
图 1-3。 模型并行处理
实现模型并行处理并不像数据并行处理那么简单,它需要您重写模型。您需要定义如何将模型拆分到多个 GPU 中,以及如何在正向通道中对数据进行管道传输。这通常是通过为模型编写子类来完成的,该子类具有针对特定数量的 GPU 的多 GPU 实现。
以下代码演示了AlexNet的双 GPU 实现:
class TwoGPUAlexNet(AlexNet):
def __init__(self):
super(ModelParallelAlexNet, self).__init__(
num_classes=num_classes,
*args,
**kwargs)
self.features.to('cuda:0')
self.avgpool.to('cuda:0')
self.classifier.to('cuda:1')
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size,
dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
s_prev = self.seq2(s_prev)
ret.append(self.fc(
s_prev.view(s_prev.size(0), -1)))
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(
s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
如您所见,训练循环需要更改一行代码以确保标签位于最后一个GPU上,因为在计算损失之前,这是输出的位置。
数据并行处理和模型并行处理是利用多个 GPU 加速训练的两种有效范例。如果我们能够将这两种方法结合起来并取得更好的结果,那不是很好吗?让我们看看如何实现组合方法。
组合数据并行处理和模型并行处理
您可以将数据并行处理与模型并行处理相结合,以进一步提高性能。在这种情况下,您将使用 DDP 包装模型,以便在多个进程之间分发数据批次。每个进程将使用多个 GPU,并且您的模型将在每个 GPU 之间进行分区。
我们只需要进行两项更改:
- 更改我们的多 GPU 模型类以接受设备作为输入。
- DDP将决定输入和输出数据的放置位置。
以下代码演示如何修改多 GPU 模型:
class Simple2GPUModel(nn.Module):
def __init__(self, dev0, dev1):
super(Simple2GPUModel,
self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(
10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(
10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
在构造函数中,我们传入 GPU 设备对象和 ,并描述模型的哪些部分驻留在哪些 GPU 中。这使我们能够在不同的进程上实例化新模型,每个进程都有两个GPU。该方法在模型中的适当点将数据从一个 GPU 移动到下一个 GPU。__init__()dev0dev1forward()
以下代码显示了训练循环更改:
def model_parallel_training(rank, world_size):
print(f"Running DDP with a model parallel")
setup(rank, world_size)
# set up mp_model and devices for this process
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = Simple2GPUModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(
ddp_mp_model.parameters(), lr=0.001)
for epochs in range(n_epochs):
for input, labels in dataloader:
input = input.to(dev0),
labels = labels,to(dev1)
optimizer.zero_grad()
outputs = ddp_mp_model(input)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
cleanup()- 将模型包装在 中。DDP
- 将输入和标签移动到相应的设备 ID。
- 输出位于 上。dev1
回顾一下,在多个GPU上使用PyTorch时,您有几个选择。您可以使用本节中的参考代码实现数据并行、模型并行或组合并行处理,以加速模型训练和推理。到目前为止,我们只讨论了一台机器或一个云实例上的多个GPU。
在许多情况下,在一台计算机上跨多个 GPU 进行并行处理可以将训练时间缩短一半或更多 ,您只需升级 GPU 卡或使用更大的云 GPU 实例即可。但是,如果您正在训练非常复杂的模型或使用非常大的数据集,则可能需要使用多台计算机或云实例来加快训练速度。
好消息是,多台计算机上的 DDP 与单台计算机上的 DDP 没有太大区别。下一节将介绍如何完成此操作。
分布式训练(多台机器)
如果在单台机器上训练您的 NN 模型不能满足您的需求,并且您有权访问服务器集群,则可以使用 PyTorch 的分布式处理功能在多台机器上扩展您的训练。PyTorch 的分布式子包 提供了一组丰富的功能,以适应各种训练架构和硬件平台。torch.distributed
该子包由三个组件组成:DDP、基于 RPC 的分布式训练 (RPC) 和集体通信 (c10d)。我们在上一节中使用 DDP 在一台计算机上运行多个进程,它最适合数据并行处理范例。创建 RPC 是为了支持更通用的训练体系结构,可用于数据并行处理范例以外的分布式体系结构。torch.distributed
c10d 组件是一个通信库,用于跨进程传输张量。c10d 被 DDP 和 RPC 组件用作后端,而 PyTorch 提供了一个 c10d API,因此您可以在自定义分布式应用程序中使用它。
在本书中,我们将重点介绍如何使用 DDP 进行分布式训练。但是,如果您有更高级的用例,则可能需要使用 RPC 或 c10d。您可以通过阅读 PyTorch 文档来了解有关这些内容的更多信息。
对于使用 DDP 的分布式训练,我们将遵循与对具有多个进程的单台计算机相同的 DDP 过程。但是,在这种情况下,我们将在单独的计算机或实例上运行每个进程。
若要在多台计算机上运行,我们使用指定配置的启动脚本运行 DDP。启动脚本包含在 中,可以执行,如以下代码所示。假设您有两个节点,即节点 0 和节点 1。节点 0 是主节点,IP 地址为 192.168.1.1,空闲端口为 1234。在节点 0 上,您将运行以下脚本:torch.distributed
>>> python -m torch.distributed.launch
--nproc_per_node=NUM_GPUS
--nnodes=2
--node_rank=0
--master_addr="192.168.1.1"
--master_port=1234
TRAINING_SCRIPT.py (--arg1 --arg2 --arg3)node_rank设置为节点 0。
在节点 1 上,您将运行下一个脚本。请注意,此节点的排名为:1
>>> python -m torch.distributed.launch
--nproc_per_node=NUM_GPUS
--nnodes=2
--node_rank=1
--master_addr="192.168.1.1"
--master_port=1234
TRAINING_SCRIPT.py (--arg1 --arg2 --arg3)node_rank设置为节点 1。
如果要浏览此脚本中的可选参数,请运行以下命令:
>>> python -m torch.distributed.launch --help请记住,如果您没有使用 DDP 范例,则应考虑为您的使用案例使用 RPC 或 c10d API。并行处理和分布式训练可以显著提高模型性能并缩短开发时间。在下一节中,我们将研究通过实现优化模型本身的技术来提高 NN 性能的其他方法。
模型优化
模型优化是一个高级主题,重点介绍 NN 模型的基础实现以及如何训练它们。随着该领域的研究不断发展,PyTorch增加了各种模型优化功能。在本节中,我们将探讨优化的三个领域 — 超参数优化、量化和修剪 — 并提供参考代码供您在自己的设计中使用。
超参数优化
深度学习模型开发通常涉及选择许多用于设计模型的变量以及如何训练模型。这些变量称为超参数,可以包括层数、层深度和内核大小等体系结构变体,以及池化或批量规范化等可选阶段。超参数还可以包括损失函数或优化参数的变化,例如LR或权重衰减率。
在本节中,我将向您展示如何使用名为 Ray Tune 的包来管理超参数优化。研究人员经常手动测试一小组超参数。但是,Ray Tune 允许您配置超参数并确定哪些设置最适合性能。
Ray Tune 支持最先进的超参数搜索算法和分布式训练。它不断更新新功能。让我们看看如何使用 Ray Tune 来执行超参数优化。
还记得我们在第3章中训练用于图像分类的LeNet5模型吗?让我们试验不同的模型配置和训练参数,看看我们是否可以使用超参数优化来改进我们的模型。
为了使用雷调谐,我们需要对模型进行以下更改:
- 定义我们的超参数及其搜索空间。
- 编写一个函数来包装我们的训练循环。
- 运行雷调谐超参数调优。
让我们重新定义我们的模型,以便我们可以配置完全连接的层中的节点数,如下面的代码所示:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, nodes_1=120, nodes_2=84):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, nodes_1)
self.fc2 = nn.Linear(nodes_1, nodes_2)
self.fc3 = nn.Linear(nodes_2, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x- 在 中配置节点。fc1
- 在 中配置节点。fc2
到目前为止,我们有两个超参数,和 。让我们再定义两个超参数和 ,以便我们可以改变训练中使用的学习速率和批大小。nodes_1nodes_2lrbatch_size
在下面的代码中,我们导入包并定义超参数配置:ray
from ray import tune
import numpy as np
config = {
"nodes_1": tune.sample_from(
lambda _: 2 ** np.random.randint(2, 9)),
"nodes_2": tune.sample_from(
lambda _: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}在每次运行期间,将从指定的搜索空间中选择这些参数的值。可以使用该方法和函数来定义搜索空间,也可以使用内置的采样函数。在本例中,并且每个都设置为从 到 使用的随机值。tune.sample_from()lambdalayer_1layer_229sample_from()
和 使用内置函数,其中随机选择为从 1e-4 到 1e-1 的双精度函数,具有均匀分布,并随机选择为 、 、 或 。lrbatch_sizelrbatch_size24816
接下来,我们需要使用一个将配置字典作为输入的函数来包装训练循环。此训练循环函数将由雷调谐调用。
在编写训练循环之前,让我们定义一个加载 CIFAR-10 数据的函数,以便在训练期间重用来自同一目录的数据。下面的代码类似于我们在第 3 章中使用的数据加载代码:
import torch
import torchvision
from torchvision import transforms
def load_data(data_dir="./data"):
train_transforms = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
(0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
(0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(
root=data_dir, train=True,
download=True, transform=train_transforms)
testset = torchvision.datasets.CIFAR10(
root=data_dir, train=False,
download=True, transform=test_transforms)
return trainset, testset
现在,我们可以将训练循环包装到函数 train_model()中,如以下代码所示。这是一大段代码;但是,您应该熟悉它:
from torch import optim
from torch import nn
from torch.utils.data import random_split
def train_model(config):
device = torch.device("cuda" if
torch.cuda.is_available() else "cpu")
model = Net(config['nodes_1'],
config['nodes_2']).to(device=device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),
lr=config['lr'],
momentum=0.9)
trainset, testset = load_data()
test_abs = int(len(trainset) * 0.8)
train_subset, val_subset = random_split(
trainset,
[test_abs, len(trainset) - test_abs])
trainloader = torch.utils.data.DataLoader(
train_subset,
batch_size=int(config["batch_size"]),
shuffle=True)
valloader = torch.utils.data.DataLoader(
val_subset,
batch_size=int(config["batch_size"]),
shuffle=True)
for epoch in range(10):
train_loss = 0.0
epoch_steps = 0
for data in trainloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
val_loss = 0.0
total = 0
correct = 0
for data in valloader:
with torch.no_grad():
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(
outputs.data, 1)
total += labels.size(0)
correct += \
(predicted == labels).sum().item()
loss = criterion(outputs, labels)
val_loss += loss.cpu().numpy()
print(f'epoch: {epoch} ',
f'train_loss: ',
f'{train_loss/len(trainloader)}',
f'val_loss: ',
f'{val_loss/len(valloader)}',
f'val_acc: {correct/total}')
tune.report(loss=(val_loss / len(valloader)),
accuracy=correct / total)- 使模型层可配置。
- 使学习速率可配置。
- 使批大小可配置。
接下来,我们要运行 Ray Tune,但首先需要确定要使用的调度程序和报告程序。计划程序确定 Ray Tune 如何搜索和选择超参数,而报告器则指定我们希望如何查看结果。让我们在下面的代码中设置它们:
from ray.tune import CLIReporter
from ray.tune.schedulers import ASHAScheduler
scheduler = ASHAScheduler(
metric="loss",
mode="min",
max_t=10,
grace_period=1,
reduction_factor=2)
reporter = CLIReporter(
metric_columns=["loss",
"accuracy",
"training_iteration"])
对于调度程序,我们将使用异步连续减半算法 (ASHA) 进行超参数搜索,并指示它最小化损失。对于报告器,我们将配置一个 CLI 报告程序,以报告每次运行 CLI 上的丢失、准确性、训练迭代和所选超参数。
最后,我们可以使用以下代码中所示的方法运行 Ray Tune:run()
from functools import partial
result = tune.run(
partial(train_model),
resources_per_trial={"cpu": 2, "gpu": 1},
config=config,
num_samples=10,
scheduler=scheduler,
progress_reporter=reporter)
我们预配资源并指定配置。我们传入配置字典,指定样本或运行的数量,然后传入我们的 and 函数。schedulerreporter
雷调谐将报告结果。该方法返回一个对象,其中包含有关最佳试验的信息。我们可以打印出产生最佳结果的超参数设置,如以下代码所示:get_best_trial()
best_trial = result.get_best_trial(
"loss", "min", "last")
print("Best trial config: {}".format(
best_trial.config))
print("Best trial final validation loss:",
"{}".format(
best_trial.last_result["loss"]))
print("Best trial final validation accuracy:",
"{}".format(
best_trial.last_result["accuracy"]))有关详细信息,请参阅雷调谐文档。如您所见,Ray Tune具有一组丰富的功能,但还有其他超参数包也支持PyTorch。其中包括快板列车和奥普图纳。
超参数优化可以通过查找效果最佳的设置来显著提高 NN 模型的性能。接下来,我们将探索另一种优化模型的技术:量化。
量化
NN 作为计算图实现,它们的计算通常使用 32 位(或在某些情况下为 64 位)浮点数。但是,我们可以使我们的计算使用较低精度的数字,并且仍然通过应用量化来获得可比较的结果。
量化是指用于计算和访问具有较低精度数据的内存的技术。这些技术可以减小模型大小,减少内存带宽,并通过int8算术更快地执行推理。
快速量化方法是将所有计算精度降低一半。让我们再次考虑我们的 LeNet5 模型示例,如下面的代码所示:
import torch
from torch import nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(
F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(
F.relu(self.conv2(x)), 2)
x = x.view(-1,
int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet5()
默认情况下,所有计算和内存都实现为 float32。我们可以使用以下代码检查模型参数的数据类型:
for n, p in model.named_parameters():
print(n, ": ", p.dtype)
# out:
# conv1.weight : torch.float32
# conv1.bias : torch.float32
# conv2.weight : torch.float32
# conv2.bias : torch.float32
# fc1.weight : torch.float32
# fc1.bias : torch.float32
# fc2.weight : torch.float32
# fc2.bias : torch.float32
# fc3.weight : torch.float32
# fc3.bias : torch.float32正如预期的那样,我们的数据类型是 float32。但是,我们可以使用以下方法在一行代码中将模型减少到一半精度:half()
model = model.half()
for n, p in model.named_parameters():
print(n, ": ", p.dtype)
# out:
# conv1.weight : torch.float16
# conv1.bias : torch.float16
# conv2.weight : torch.float16
# conv2.bias : torch.float16
# fc1.weight : torch.float16
# fc1.bias : torch.float16
# fc2.weight : torch.float16
# fc2.bias : torch.float16
# fc3.weight : torch.float16
# fc3.bias : torch.float16现在我们的计算和内存值是浮点数16 。使用通常是量化模型的快速简便方法。值得一试的是,看看性能是否足以满足您的使用案例。half()
但是,在许多情况下,我们不希望以相同的方式量化每个计算,并且我们可能需要量化 float16 值之外的计数。对于这些其他情况,PyTorch 提供了三种额外的量化模式:动态量化、训练后静态量化和量化感知训练 (QAT)。
当吞吐量受到权重的计算或内存带宽限制时,将使用动态量化。这通常适用于 LSTM、RNN、来自变压器 (BERT) 的双向编码器表示或变压器网络。静态量化用于当吞吐量受到激活的内存带宽限制时,通常适用于CNN. QAT用于静态量化无法实现精度要求的情况。
让我们为每种类型的类型提供一些参考代码。所有类型都将权重转换为 int8。它们在句柄激活和内存访问方面有所不同。
动态量化是最简单的类型。它会动态地将激活转换为 int8。计算使用有效的 int8 值,但激活以浮点格式读取和写入内存。
以下代码演示如何使用动态量化来量化模型:
import torch.quantization
quantized_model = \
torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8)我们需要做的就是传入模型并指定量化层和量化水平。
警告
量化取决于用于运行量化模型的后端。目前,仅在以下后端支持量化运算符进行 CPU 推理:x86 (fbgemm) 和 ARM ()。但是,量化感知训练以完全浮点形式进行,可以在 GPU 或 CPU 上运行。qnnpack
训练后静态量化可用于通过观察训练期间不同激活的分布以及决定在推理时如何量化这些激活来进一步减少延迟。这种类型的量化允许我们在操作之间传递量化的值,而无需在内存中的浮点数和整数之间来回转换:
static_quant_model = LeNet5()
static_quant_model.qconfig = \
torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(
static_quant_model, inplace=True)
torch.quantization.convert(
static_quant_model, inplace=True)训练后静态量化需要配置和培训,以便在使用之前做好准备。我们将后端配置为使用 x86 (fbgemmtorch.quantization.prepare),并调用以插入观察器来校准模型并收集统计信息。然后,我们将模型转换为量化版本。
量化感知训练通常可以获得最佳准确性。在这种情况下,所有权重和激活在训练的前进和后退过程中都是“假量化”的。浮点值将舍入为 int8 等效值,但计算仍以浮点数形式完成。也就是说,重量调整“知道”它们将在训练期间被量化。以下代码演示如何使用 QAT 量化模型:
qat_model = LeNet5()
qat_mode.qconfig = \
torch.quantization.get_default_qat_qconfig('fbgemm')
torch.quantization.prepare_qat(
qat_model, inplace=True)
torch.quantization.convert(
qat_model, inplace=True)同样,我们需要配置后端并准备模型,然后调用来量化模型。convert()
PyTorch的量化能力正在不断发展,目前处于测试阶段。有关如何使用量化软件包的最新信息,请参阅 PyTorch 文档。
修剪
现代深度学习模型可能具有数百万个参数,并且可能难以部署。但是,模型被过度参数化,并且通常可以减少参数而不会对准确性或模型性能产生太大影响。修剪是一种减少模型参数数量的技术,对性能的影响最小。这允许您部署具有更少内存、更低功耗和更少硬件资源的模型。
修剪模型示例
修剪可以应用于 .由于 可以由单个层、多个层或整个模型组成,因此修剪可以应用于单个层、多个层或整个模型本身。让我们考虑一下我们的 LeNet5 模型示例:nn.modulenn.module
from torch import nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(
F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(
F.relu(self.conv2(x)), 2)
x = x.view(-1,
int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
我们的 LeNet5 模型有五个子模块—, , , , 和 。模型参数由其权重和偏差组成,可以使用该方法显示。我们来看看图层的参数:conv1conv2fc1fc2fc3named_parameters()conv1
device = torch.device("cuda" if
torch.cuda.is_available() else "cpu")
model = LeNet5().to(device)
print(list(model.conv1.named_parameters()))
# out:
# [('weight', Parameter containing:
# tensor([[[[0.0560, 0.0066, ..., 0.0183, 0.0783]]]],
# device='cuda:0',
# requires_grad=True)),
# ('bias', Parameter containing:
# tensor([0.0754, -0.0356, ..., -0.0111, 0.0984],
# device='cuda:0',
# requires_grad=True))]本地和全局修剪
局部修剪是指我们只修剪模型的特定部分。通过这种技术,我们可以将局部修剪应用于单个层或模块。只需调用修剪方法,传入图层,然后设置其选项,如以下代码所示:
import torch.nn.utils.prune as prune
prune.random_unstructured(model.conv1,
name="weight",
amount=0.25)此示例将随机非结构化修剪应用于模型中层中指定的参数。这只会修剪权重参数。我们也可以使用以下代码修剪偏差参数:weightconv1
prune.random_unstructured(model.conv1,
name="bias",
amount=0.25)修剪可以迭代应用,因此您可以跨不同维度使用其他修剪方法进一步修剪相同的参数。
您可以以不同的方式修剪模块和参数。例如,您可能希望按模块或层类型进行修剪,并以不同于线性层的方式对卷积层应用修剪。以下代码说明了执行此操作的一种方法:
model = LeNet5().to(device)
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
prune.random_unstructured(module,
name='weight',
amount=0.3) 1
elif isinstance(module, torch.nn.Linear):
prune.random_unstructured(module,
name='weight',
amount=0.5) 2- 将所有 2D 卷积层修剪 30%。
- 将所有线性层修剪 50%。
修剪 API 的另一个用途是应用全局修剪,其中我们将修剪方法应用于整个模型。例如,我们可以全局修剪 25% 的模型参数,这可能会导致每层的修剪率不同。下面的代码演示了应用全局修剪的一种方法:
model = LeNet5().to(device)
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.25)在这里,我们修剪整个模型中所有参数的25%。
修剪接口
PyTorch 在其模块中为修剪提供了内置支持。表 6-2 列出了修剪 API 中的可用函数。torch.nn.utils.pruneTable 6-2. Pruning functions
| 功能 | 描述: __________ |
| is_pruned(module) | 检查模块是否修剪 |
| remove(module, name) | 从模块中删除修剪重新参数化,并从正向挂钩中删除修剪方法 |
| custom_from_mask(module, name, mask) | 修剪与调用的参数相对应的张量,方法是在 中应用预先计算的掩码namemodulemask |
| global_unstructured(params, pruning_method) | 通过应用指定的paramspruning_method |
| ln_structured(module, name, amount, n, dim) | 通过沿具有最低 L 范数的指定通道删除指定的(当前未修剪的)通道来修剪与调用的参数相对应的张量namemoduleamountdimn |
| random_structured(module, name, amount, dim) | 通过沿随机选择的指定通道删除指定的(当前未修剪的)通道来修剪与调用的参数相对应的张量namemoduleamountdim |
| l1_unstructured(module, name, amount) | 通过删除具有最低 L1 范数的指定(当前未修剪)单位来修剪与调用的参数相对应的张量namemoduleamount |
| random_unstructured(module, name, amount) | 通过删除随机选择的指定(当前未修剪)单位来修剪与调用的参数相对应的张量namemoduleamount |
自定义修剪方法
如果找不到适合您需求的修剪方法,可以创建自己的修剪方法。为此,请从 中提供的类创建一个子类。在大多数情况下,可以将BasePruningMethodtorch.nn.utils.prunecall() 、apply_mask() 、apply() 、prune() 和 remove()方法保留原样。
但是,您需要编写自己的构造函数和方法来描述修剪方法如何计算掩码。此外,还需要指定修剪类型(、__init__()、compute_mask() 或structuredunstructuredglobal )。以下代码显示了一个示例:
class MyPruningMethod(prune.BasePruningMethod):
PRUNING_TYPE = 'unstructured'
def compute_mask(self, t, default_mask):
mask = default_mask.clone()
mask.view(-1)[::2] = 0
return mask
def my_unstructured(module, name):
MyPruningMethod.apply(module, name)
return module首先,我们定义类。此示例修剪每隔一个参数,如 中的代码所定义。PRUNING_TYPE用于将修剪类型配置为非结构化。然后,我们包含并应用一个实例化该方法的函数。您可以通过以下方式将此修剪应用于模型:compute_mask()
model = LeNet5().to(device)
my_unstructured(model.fc1, name='bias')现在,您已经创建了自己的自定义修剪方法,并且可以在本地或全局范围内应用它。
本章向您展示了如何使用 PyTorch 加速训练和优化模型。下一步是将您的模型和创新部署到世界各地。在下一章中,你将学习如何将模型部署到云以及移动和边缘设备,我将提供一些参考代码来构建快速应用程序来展示你的设计。