大数据面试重点之mysql篇
目录
一、B树和B+树的区别,为什么Mysql使用B+树作为索引?
二、索引有哪些?
三、索引设计有哪些注意事项(原则)?
四、mysql有哪些锁?
五、查询有哪几种等级?
六、mysql有哪些优化方式?
七、事务的四种隔离级别?
八、mysql聚簇和非聚簇索引的区别?
九、sql的慢查询的优化?
十、数据库存储引擎有哪些?
十一、mysql中在建表的时候可以创建自增列,hive中可以这样创建吗?
十二、select…for update是什么锁?
一、B树和B+树的区别,为什么Mysql使用B+树作为索引?
1.B树结点上存储的是数据,而B+树上非叶子结点上存储的是键值(也可以说是索引),它的数据都存储在叶子结点上。如果要实现整棵树的遍历,B+树只需要去遍历叶子节点,而B树则需要通过从根节点从上往下的遍历。范围查找也同理只需要遍历叶子结点中它的那部分,所以B+树范围查找的效率更高。
2.B树指针少的情况下要保存大量数据, 只能增加树的高度, 导致 IO 操作变多,查询性能变低;所以B+树的读写磁盘代价更低(相对更加“矮胖”)。
3.B+树的叶子结点之间有指针。(比如遍历叶子结点时查找时候发现大于这个叶子结点所有数据中最大的那个,那就可以通过指针直接去查找下一个叶子结点的数据)

二、索引有哪些?
1.普通索引:普通索引是最基本的索引,它没有任何限制,值可以为空;仅加速查询。
2.唯一索引:唯一索引与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
3.主键索引:主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
4.组合索引:
5.全文索引:
三、索引设计有哪些注意事项(原则)?
1.频繁更新的列不适合建立索引
2.适合索引的列是出现在where、order by、group by、distinct,或者连接子句中指定的列,或者经常需要搜索的列。
3.不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引例越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
4.一个列重复率高的,不易区分的或者一个列的值很少的,建索引都不合理。
5.数据量小的表不适合设置索引。
四、mysql有哪些锁?
1.基于锁的属性分类:共享锁(读锁)、排他锁(写锁)。
2.基于锁的粒度分类:行级锁((innodb )、表级锁( innodb、myisam)、页级锁( innodb引擎)、记录锁、间隙锁等。
3.还分为乐观锁和悲观锁。
行锁:行锁是指上锁的时候锁住的是表的某一行或多行记录,其他事务访问同一张表时,只有被锁住的记录不能访问,其他的记录可正常访问,特点:粒度小,加锁比表锁麻烦,不容易冲突,相比表锁支持的并发要高。
表锁:表锁是指上锁的时候锁住的是整个表,当下一个事务访问该表的时候,必须等前一个事务释放了锁才能进行对表进行访问;特点:粒度大,加锁简单,容易冲突;
间隙锁:是一个在索引记录之间的间隙上的锁,可以是两个索引记录之间,也可能是第一个索引记录之前或最后一个索引之后的空间。
五、查询有哪几种等级?

详解:

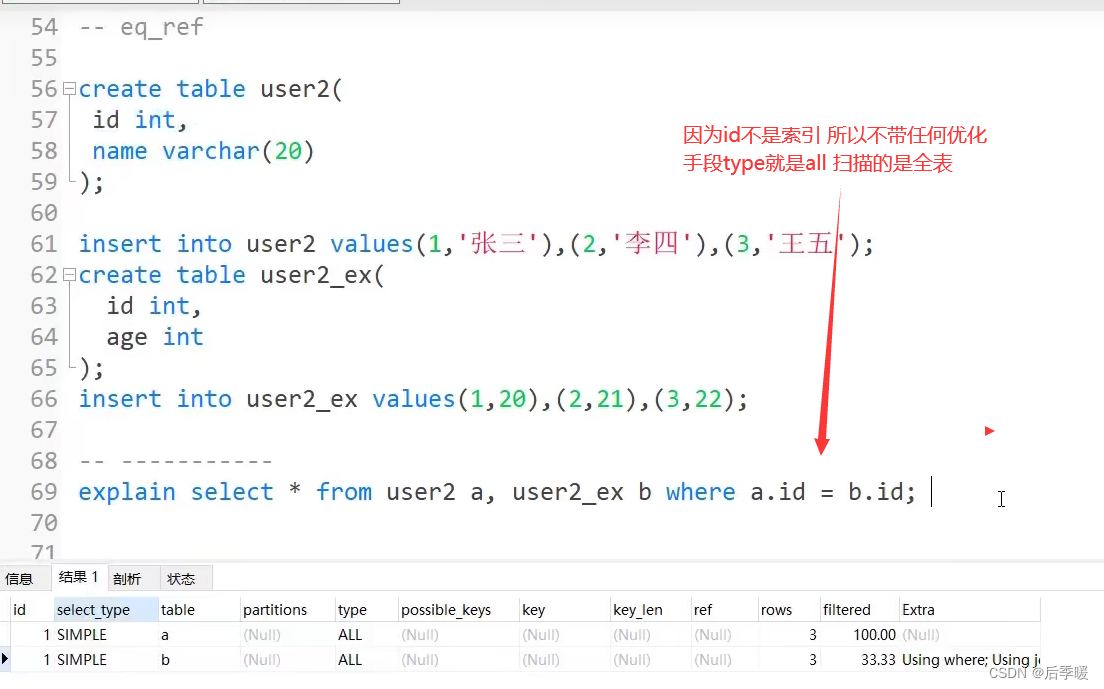
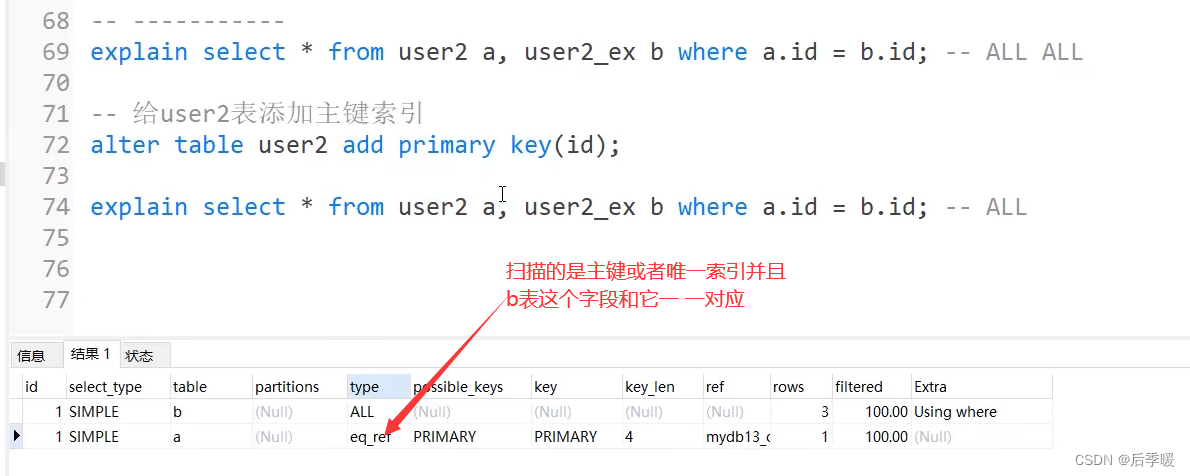

六、mysql有哪些优化方式?
1、explain
2、in中的内容尽量少 between能替代in的用between
能用exists替代in则用exists
3、SELECT语句务必指明字段名称,尽量避免select*
4、尽量用union all代替union
5、最佳左前缀法则
6、尽量少用or、<>等...
七、事务的四种隔离级别?
可以参考我的另一篇文章:
事务的四种隔离级别(超详细!!!)_后季暖的博客-CSDN博客
八、mysql聚簇和非聚簇索引的区别?
都是B+树的数据结构
聚簇索引∶将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数据。数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。
非聚簇索引:叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再取磁盘查找数据,这个就有点类似一本书的目录,比如我们要找第三章第一节,那我们先在这个目录里面找,找到对应的页码后再去对应的页码看文章。
九、sql的慢查询的优化?
在业务系统中,除了使用主键进行的查询,其他的都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的:
·首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
·分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
·如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
十、数据库存储引擎有哪些?
1、InnoDB引擎 mysql5.5以后默认引擎,支持事务, 最小的锁粒度是行锁
2、ISAM引擎
3、MYISAM引擎 mysql5.1前,不支持事务,MyISAM 最小的锁粒度是表锁
4、MEMORY存储引擎
5、HEAP引擎
6、ARCHIVE引擎
十一、mysql中在建表的时候可以创建自增列,hive中可以这样创建吗?
hive本身不支持表自增列的实现,但是可以通过其它手段来实现。row_number()
十二、select…for update是什么锁?
select for update 即排他锁,排他锁又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。