【408篇】C语言笔记-第十五章( 考研必会的查找算法考研真题实战)
文章目录
- 第一节:顺序查找原理及实战
- 1. 顺序查找原理解析
- 2. 顺序查找代码实战
- 第二节:折半查找原理及实战
- 1. 折半查找原理解析
- 2. 折半查找代码实战
- 第三节:二叉排序树原理及建树实战
- 1. 二叉排序树原理解析
- 2. 二叉排序树代码实战
- 第四节:二叉排序树删除实战
- 第五节:考研真题解析
第一节:顺序查找原理及实战
1. 顺序查找原理解析
顺序查找又称线性查找,它对于顺序表和链表都是适用的。对于顺序表,可通过数组下标递增来顺序扫描每个元素;对于链表,则通过指针来依次扫描每个元素。
2. 顺序查找代码实战
在之前的方法中,我们使用数组实现,这次我们使用指针来实现。也就是申请一个堆空间,使用方法和数组一致。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int ElemType;
typedef struct {
ElemType *elem; // 整型指针
int TableLen; // 存储动态数组里边元素的个数,相当于之前的len
}SSTable;
// 初始化链表
void ST_Init(SSTable &ST,int len){
// 多申请一个位置,为了存哨兵,不使用哨兵也可以
ST.TableLen=len+1;
ST.elem= (ElemType*)malloc(sizeof(ElemType)*ST.TableLen);
int i;
srand(time(NULL));// 生成随机数
for(i=1;i<ST.TableLen;i++){// 因为第0个位置时哨兵,所以从1开始随机
ST.elem[i]=rand()%100; // 为了让随机数在0-99之间
}
}
// 打印
void ST_print(SSTable ST){
for(int i=1;i<ST.TableLen;i++){
printf("%3d",ST.elem[i]);// 和获取数组方法一样
}
printf("\n");
}
// 查找元素
int Search_Seq(SSTable ST,int key){
ST.elem[0]=key; // 让零号元素作为哨兵。有了这个,在循环时,可以少写一个i>=0的判断
int i;
int j;
for(i=1;i<ST.TableLen;i++){ // 等价于注释中的一行
if(ST.elem[i]==key){
j=i;
}
}
// for(i=ST.TableLen-1;ST.elem[i]!=key;i--);// 从后往前找,找到了,i就是刚好的对应位置
return j;
}
int main() {
SSTable ST;
ST_Init(ST,10);
ST_print(ST);
ElemType key;
int pos;// 存储查找元素的位置
printf("please inter key:\n");
scanf("%d",&key);
pos=Search_Seq(ST,key);
if(pos){
printf("find success,%d\n",pos);
} else{
printf("not find");
}
return 0;
}
F:\Computer\Project\practice\15\15.3-order\cmake-build-debug\15_3_order.exe
31 55 95 72 75 17 29 5 87 52
please inter key:
52
find success,10
进程已结束,退出代码为 0
第二节:折半查找原理及实战
1. 折半查找原理解析
折半查找又称二分查找,它仅适用于有序的顺序表。
折半查找的基本思想:首先将给定值key与表中中间位置的元素比较,若相等,则查找成功,返回该元素的存储位置;若不等,则要查找的元素只能在中间元素以外的前半部分或后半部分。比如在查找表升序排列时,若给定值key大于中间元素,则所查找的元素只能在后半部分。然后再缩小的范围内继续进行同样的查找,如此重复,直到找到为止。或确定表中没有所需要查找的元素,则查找不成功,返回查找失败的信息。
针对顺序表排序,我们使用qsort来排序。使用方法如下:
#include <stdlib.h>
void qsort(void *buf,size_t num,size_t size,int(*compare)(const void *,const void*));
buf:要排序数组的起始地址,也可以是指针,申请了一块连续的堆空间。
num:数组中元素的个数。
size:数组中每个元素所占用的空间大小。
compare:比较规则,需要我们传递一个函数名,这个函数由我们自己编写,返回值必须是int类型,形参是两个void类型指针,这个函数我们编写,但是是qsort内部调用的,相当于我们传递一种行为给qsort。
动画演示:
https://www.cs.usfca.edu/~galles/visualization/Search.html

2. 折半查找代码实战
流程:
- 初始化顺序表,随机10个元素。
- 使用qsort进行排序,排序完毕后,打印确认。
- 输入要查找的元素值,存入变量key中。
- 通过二分法查找对应key值,找到则输出在顺序表中的位置,没找到则输出未找到。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int ElemType;
typedef struct {
ElemType *elem;
int TableLen;
}SSTable;
//初始化
void ST_Init(SSTable &ST,int len){
ST.TableLen=len;
ST.elem= (ElemType*)malloc(sizeof(ElemType)*ST.TableLen);
int i;
srand(time(NULL)); // 生成随机数
for(i=0;i<ST.TableLen;i++){
ST.elem[i]=rand()%100;
}
}
// 打印
void ST_print(SSTable ST){
for(int i=0;i<ST.TableLen;i++){
printf("%3d",ST.elem[i]);
}
printf("\n");
}
// 实现compare
// 函数名中存储的是函数的入口地址,也是一个指针,是函数指针类型
// qsort规定:如果left指向的值大于right指向的值,返回正值。相反返回负值,如果相等则返回0
// left指针和right指针指向数组中的任意两个元素
// qsort可以排不同类型的数组。所以参数那里是void,而这里我们需要的是int类型,所以需要强转。
int compare(const void *left,const void *right){
return *(ElemType*)left-*(ElemType*)right; // 从小到大排序
// return *(ElemType*)right-*(ElemType*)left; // 从大到小排序
}
// 实现二分法查找。时间复杂度logn
int BinarySearch(SSTable L,ElemType key){
int low=0;
int high=L.TableLen-1;
int mid;
while (low<=high){
mid=(low+high)/2;
if(L.elem[mid]==key){
return mid; // 等于就找到了
} else if(L.elem[mid]>key){
high=mid-1; // 从小到大使用
// low=mid+1; // 从大到小时使用
} else{
low=mid+1; // 从小到大使用
// high=mid-1; // 从大到小时使用
}
}
return -1; // 没有找到
}
int main() {
SSTable ST;
ElemType key;
ST_Init(ST,10);
ST_print(ST); // 打印排序前的结果
qsort(ST.elem,ST.TableLen, sizeof(ElemType),compare);
ST_print(ST); // 打印排序后的结果
printf("please inter key:\n");
scanf("%d",&key);
int pos=BinarySearch(ST,key); // 二分查找,也叫折半查找
if(pos!=-1){
printf("find success:%d\n",pos);// 找到的是下标,从0开始
} else{
printf("not find");
}
return 0;
}
F:\Computer\Project\practice\15\15.4-binary_Searching\cmake-build-debug\15_4_binary_Searching.exe
42 61 85 11 60 30 89 30 47 65
11 30 30 42 47 60 61 65 85 89
please inter key:
60
find success:5
进程已结束,退出代码为 0
第三节:二叉排序树原理及建树实战
1. 二叉排序树原理解析
二叉排序树(也称二叉查找树)或者是一棵空树,或者是具有下列特性的二叉树:
- 若左子树非空,则左子树上所有结点的值均小于根结点的值。
- 若右子树非空,则右子树上所有结点的值均大于根结点的值。
- 左、右子树也分别是一棵二叉排序树。
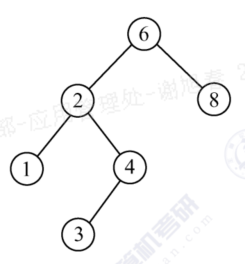
预览效果:
https://www.cs.usfca.edu/~galles/visualization/BST.html
2. 二叉排序树代码实战
流程:
- 新建一棵二叉排序树,使用递归或非递归的方法均可。
- 对建好的二叉排序树进行中序遍历输出。
- 对二叉排序树进行查找。
考研中二叉排序树一般选用中序遍历,原因是二叉排序树本身需要排序,而中序遍历的结果就是排序后的结果。两者能互相验证。
二叉排序树的最大查找次数就是树的高度。
#include <stdio.h>
#include <stdlib.h>
typedef int KeyType;
typedef struct BSTNode{
KeyType key;
struct BSTNode *lchild,*rchild;
}BSTNode,*BiTree;
int BST_Insert(BiTree &T,KeyType k){
if(NULL==T){
T= (BiTree)malloc(sizeof(BSTNode));
T->key=k;
T->lchild=T->rchild=NULL;
return 1;// 1代表插入成功
}
BiTree p=T,parent; // p用来遍历,parent用来存p的父亲
while (p){
parent=p;
if(k==p->key){
return 0;
} else if(k<p->key){
p=p->lchild;
} else{
p=p->rchild;
}
}
// 开始申请空间并插入
BiTree pnew= (BiTree)malloc(sizeof(BSTNode));
pnew->key=k;
pnew->lchild=pnew->rchild=NULL;
if(k>parent->key){
parent->rchild=pnew; // 把新结点存在父亲的右边
} else{
parent->lchild=pnew; // 把新结点存在父亲的左边
}
return 1;
}
// 创建二叉排序树
void Creat_BST(BiTree &T,KeyType str[],int n){
T= NULL;// T是树根
int i=0;
while (i<n){
BST_Insert(T,str[i]);// 把某一个结点放入二叉查找树
i++;
}
};
// 中序遍历
void InOrder(BiTree T){
if(T!=NULL){
InOrder(T->lchild);
printf("%3d",T->key);
InOrder(T->rchild);
}
}
// 查找
BSTNode *BST_Search(BiTree T,KeyType key,BiTree &p){
p=NULL;
while (T!=NULL && key!=T->key){
p=T;
if(key < T->key){ // 比当前结点小,去左边找
T=T->lchild;
} else{
T=T->rchild; // 比当前结点大,去右边找
}
}
return T;
}
int main() {
BiTree T=NULL; // 树根
BiTree parent; // 存储父亲结点的地址值
BiTree search;
KeyType str[7]={54,20,66,40,28,79,58};
Creat_BST(T,str,7);
InOrder(T); // 中序遍历
printf("\n");
search=BST_Search(T,40,parent);
if(search){
printf("find success,%d\n",search->key);
} else{
printf("not find\n");
}
return 0;
}
"F:\Computer\Project\practice\15\15.5-Binary sort\cmake-build-debug\15_5_Binary_sort.exe"
20 28 40 54 58 66 79
find success,40
进程已结束,退出代码为 0
第四节:二叉排序树删除实战
在第三节建树的基础上新增删除。
二叉排序树的删除我们使用递归来实现。
预览效果:
https://www.cs.usfca.edu/~galles/visualization/BST.html
#include <stdio.h>
#include <stdlib.h>
typedef int KeyType;
typedef struct BSTNode{
KeyType key;
struct BSTNode *lchild,*rchild;
}BSTNode,*BiTree;
int BST_Insert(BiTree &T,KeyType k){
if(NULL==T){
T= (BiTree)malloc(sizeof(BSTNode));
T->key=k;
T->lchild=T->rchild=NULL;
return 1;// 1代表插入成功
}
BiTree p=T,parent; // p用来遍历,parent用来存p的父亲
while (p){
parent=p;
if(k==p->key){
return 0;
} else if(k<p->key){
p=p->lchild;
} else{
p=p->rchild;
}
}
// 开始申请空间并插入
BiTree pnew= (BiTree)malloc(sizeof(BSTNode));
pnew->key=k;
pnew->lchild=pnew->rchild=NULL;
if(k>parent->key){
parent->rchild=pnew; // 把新结点存在父亲的右边
} else{
parent->lchild=pnew; // 把新结点存在父亲的左边
}
return 1;
}
// 创建二叉排序树
void Creat_BST(BiTree &T,KeyType str[],int n){
T= NULL;// T是树根
int i=0;
while (i<n){
BST_Insert(T,str[i]);// 把某一个结点放入二叉查找树
i++;
}
};
// 中序遍历
void InOrder(BiTree T){
if(T!=NULL){
InOrder(T->lchild);
printf("%3d",T->key);
InOrder(T->rchild);
}
}
// 查找
BSTNode *BST_Search(BiTree T,KeyType key,BiTree &p){
p=NULL;
while (T!=NULL && key!=T->key){
p=T;
if(key < T->key){ // 比当前结点
T=T->lchild;
} else{
T=T->rchild;
}
}
return T;
}
// 删除某个结点
void DeleteNode(BiTree &root,KeyType x){
if(root==NULL){
return;
}
if(root->key>x){
DeleteNode(root->lchild,x); // 往左子树找要删除的点
} else if(root->key<x){
DeleteNode(root->rchild,x); // 往右子树找要删除的点
}else{ // 查找到要删除的点
if(root->lchild==NULL){ // 如果左子树为空,则右子树顶上
BiTree tempNode=root; // 临时指针
root=root->rchild;
free(tempNode);
} else if (root->rchild==NULL){ // 如果右子树为空,则左子树顶上
BiTree tempNode=root;
root=root->lchild;
free(tempNode);
} else{ // 左右子树都不为空,针对删除跟结点的情况,效果见图15.6
// 一般的删除策略是:1.左子树的最大数据 或者 2.右子树的最小数据,代替要删除的节点。这里采用第1种
BiTree tempNode=root->lchild;
while (tempNode->rchild!=NULL){
tempNode=tempNode->rchild;
}
root->key=tempNode->key; // 把tempNode对应的值替换到要删除的位置上
DeleteNode(root->lchild,tempNode->key);
}
}
}
int main() {
BiTree T=NULL; // 树根
BiTree parent; // 存储父亲结点的地址值
BiTree search;
KeyType str[7]={54,20,66,40,28,79,58};
Creat_BST(T,str,7);
InOrder(T); // 中序遍历
printf("\n");
search=BST_Search(T,40,parent);
if(search){
printf("find success,%d\n",search->key);
} else{
printf("not find\n");
}
DeleteNode(T,66); // 删除某个结点
InOrder(T);
printf("\n");
return 0;
}
"F:\Computer\Project\practice\15\15.6-Binary sort\cmake-build-debug\15_5_Binary_sort.exe"
20 28 40 54 58 66 79
find success,40
20 28 40 54 58 79
进程已结束,退出代码为 0
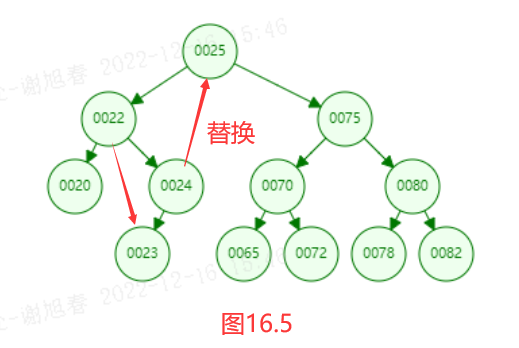
如果删除了根结点25,那么就会找左侧最右端的值24替换成根结点。或者找右侧最左端的65替换成根结点。这里是24替换了根结点,然后22指向了23。
第五节:考研真题解析

解析:
这道题目所考察的内容是二分查找。但是有两个数组,是双数组的二分查找。因为空间尽可能高效,因此我们不能在去搞一个大数组,把两个数组合并到一起,得分会比较低。
解答:
1)算法的基本设计思想:
分别求出序列A和B的中位数,设为a和b,求序列A和B的中位数的过程如下:
a.若a=b,则a或b的中位数即为所求的中位数,算法结束。
b.若a<b,则舍弃序列A中较小的一半,同时舍弃序列B中较大的一半,要求舍弃的长度相等。
c.若a>b,则舍弃序列A中较大的一半,同时舍弃序列B中较小的一半,要求舍弃的长度相等。
在保留的两个升序序列中,重复过程a,b,c,知道两个序列中均只有一个元素为止,较小者即为所求的中位数。
2)代码实现
#include <stdio.h>
int MidSearch(int A[],int B[],int n){
// 分别表示序列A和B的首位数,末尾数和中位数,s是start简写,d是end简写
int s1=0,d1=n-1,m1,s2=0,d2=n-1,m2;
// 循环判断结束条件是,两个数组均不断删除,最后君只能剩余一个元素
while (s1!=d1 || s2!=d2){
m1=(s1+d1)/2;
m2=(s2+d2)/2;
if(A[m1]==B[m2]){
return A[m1]; // 满足条件1
}
if(A[m1]<B[m2]){ // 满足条件2
if((s1+d1)%2==0){ // 若元素个数为奇数,这里注意数组下标是从0开始
s1=m1; // 舍弃A中间点以前的部分且保留中间点
d2=m2; // 舍弃B中间点以前的部分且保留中间点
} else{
s1=m1+1; // 舍弃A中间点及中间点以前的部分
d2=m2; // 舍弃B中间点以后部分且保留中间点
}
} else{ // 满足条件3
if((s1+d1)%2==0){ // 若元素个数为奇数
d1=m1; // 舍弃A中间点以后的部分且保留中间点
s2=m2; // 舍弃B中间点以前的部分且保留中间点
} else{ // 元素个数为偶数
d1=m1; // 舍弃A中间点以后及中间点以前的部分
s2=m2+1; // 舍弃B中间点以前部分且保留中间点
}
}
}
return A[s1]<B[s2]?A[s1]:B[s2]; // 因为题目要的是11,因此我们取小的那个
}
int main() {
int A[]={11,13,15,17,19};
int B[]={2,4,6,8,20};
int mid=MidSearch(A,B,5);
printf("mid=%d\n",mid);
return 0;
}
F:\Computer\Project\practice\15\15.7-2014-42\cmake-build-debug\15_7_2014_42.exe
mid=11
进程已结束,退出代码为 0
