Hadoop RPC简介
数新网络-让每个人享受数据的价值![]() https://www.datacyber.com/
https://www.datacyber.com/
前 言
RPC(Remote Procedure Call)远程过程调用协议,一种通过网络从远程计算机上请求服务,而不需要了解底层网络技术的协议。RPC它假定某些协议的存在,例如TPC/UDP等,为通信程序之间携带信息数据。在OSI网络七层模型中,RPC跨越了传输层和应用层,RPC使得开发,包括网络分布式多程序在内的应用程序更加容易。
01 RPC调用流程
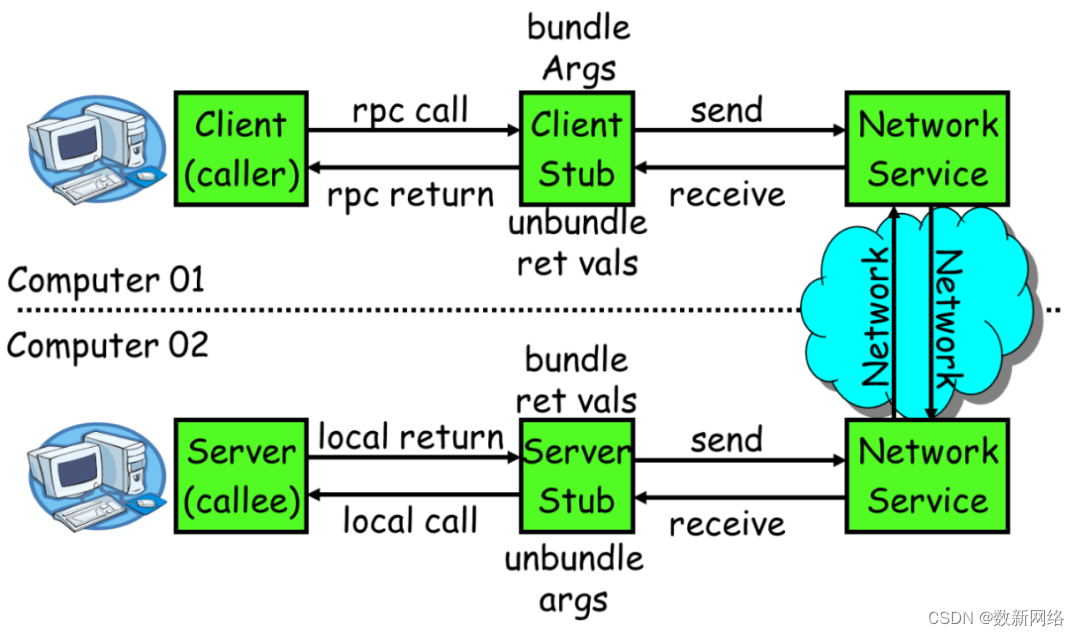
·服务消费方(client)调用,以本地调用方式调用服务
·client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体
·client stub找到服务地址,并将消息发送到服务端
·server stub收到消息后进行解码
·server stub根据解码结果调用本地的服务
·本地服务执行并将结果返回给server stub
·server stub将返回结果打包成消息并发送至消费方
·client stub接收到消息,并进行解码
·服务消费方得到最终结果
02 RPC的特点
2-1 透明性
远程调用其他机器上的程序,对用户来说就像是调用本地方法一样
2-2 高性能
RPC server能够并发处理多个来自Client的请求(请求队列)
2-3 可控性
jdk中已经提供了一个RPC框架-RMI,但是该RPC框架过于重量级并且可控之处比较少,因此Hadoop RPC实现了自定义的RPC框架
03 Hadoop RPC
与其他RPC框架一样,Hadoop RPC主要分为四个部分,分别是序列化层、函数调用层、 网络传输层和服务器端处理框架,具体实现机制如下:
序列化层:序列化层的主要作用是将结构化对象转为字节流以便于通过网络进行传输或 写入持久存储。在RPC框架中,它主要用于将用户请求中的参数或者应答转化成字节流 以便跨机器传输。Hadoop自己实现了序列化框架,一个类只要实现Writable接口,即 可支持对象序列化与反序列化。
函数调用层:函数调用层的主要功能是定位要调用的函数并执行该函数。HadoopRPC采 用Java反射机制与动态代理实现了函数调用。
网络传输层:网络传输层描述了Client与Server之间消息传输的方式,Hadoop RPC 采用了基于TCP/IP的Socket机制。
服务器端处理框架:服务器端处理框架可被抽象为网络I/O模型。它描述了客户端与服 务器端间信息交互的方式。它的设计直接决定着服务器端的并发处理能力。常见的网络 I/O模型有阻塞式I/O、非阻塞式I/O、事件驱动I/O等,而Hadoop RPC采用了基于 Reactor设计模式的非阻塞式I/O模型。
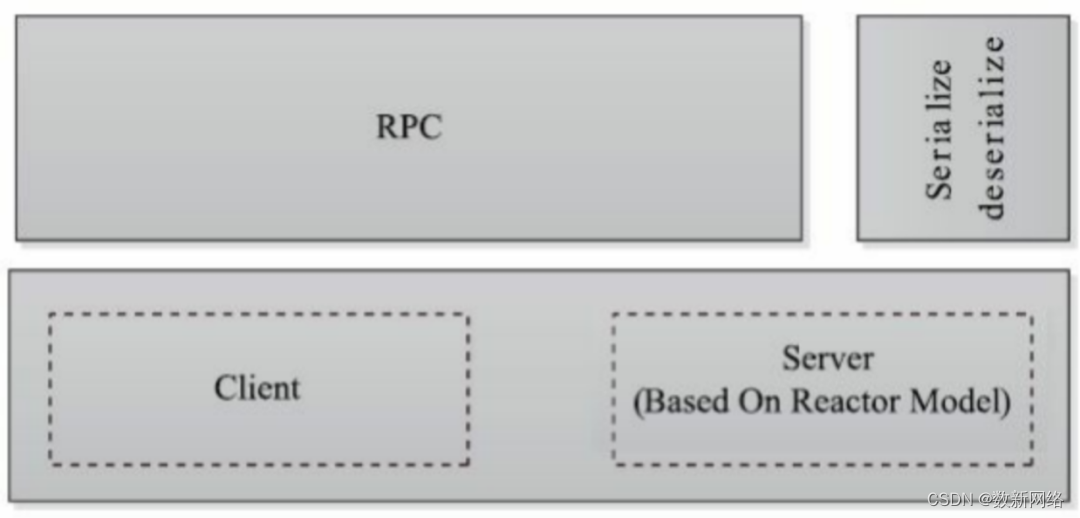
由上图可知Hadoop RPC实现主要包括三部分Client类、Server类、RPC类。
3-1 客户端代理的创建:
由RPC.getProxy获取客户端代理,一个代理处理用户到具体服务器的具体协议对应的连接,同时连接属于一个Client,而Client一般由SocketFactory决定,不同SocketFactory对应不同Client。
因此getProxy需指定包括SocketFactory,用户,服务器地址,协议这4个信息,另外还需指定连接读操作超时时间。对应getProxy重要的5个信息,最少需给定服务器地址和使用的协议,其他的都可以默认。
SocketFactory默认为默认SocketFactory,用户默认为当前用户,读操作超时时间默认为0,此时会设置为pingInterval获取客户端代理的类为RPCEngine类,默认实现为ProtobufRpcEngine在ProtobufRpcEngine中对getProxy方法进行了重载。

最终调用的为参数最多的getProxy方法
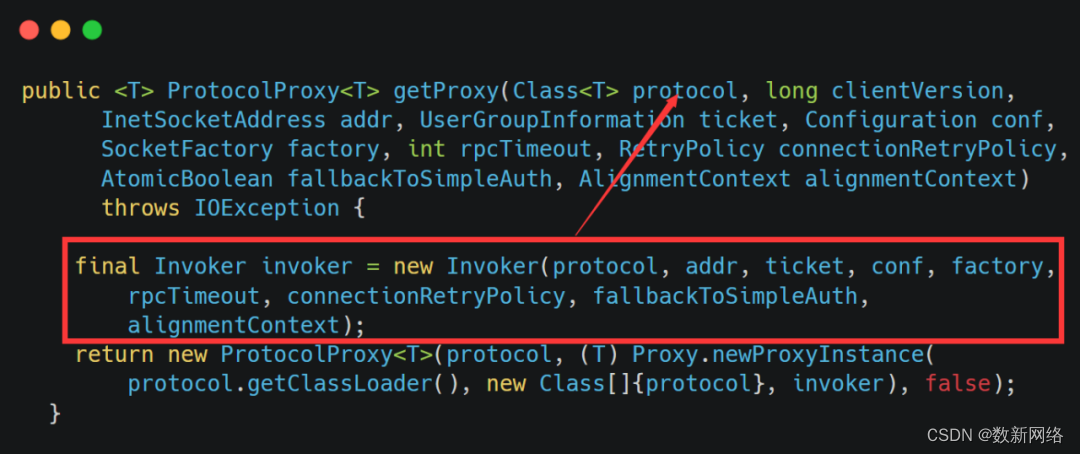
由方法实现可知创建代理最主要的就是通过getProxy方法传入的参数创建invoker对象,然后通过Java动态代理创建动态代理,因此创建的代理核心信息保存在调用处理器invoker中,下面是invoker的构造函数。

因此,就是通过传入的用户、服务器地址、协议、超时时间等信息构建Invoker。ConnectionId用来确定该invoker负责处理的链接,SocketFactory用来在缓存中查找所属客户端,若存在则使用该factory的客户端,否则构建一个Client对象。
获取client的方法:

这样,客户端的代理构建完成了,其实主要是构建了代理关联的调用处理器中的connectionId(对应一个Connection),以及client(将代理处理的连接注册到相应客户端)。
3-2 创建服务器对象
因为Server端涉及到多个客户端的调用,所以使用了Reactor的设计模式。Reactor 主要是基于多路复用的非阻塞IO实现的基于事件驱动的IO框架。Hadoop RPC 底 层使用的是Java NIO,而Java NIO正好就是一种多路复用的非阻塞IO,其中最重要的就是Selector选择器。
RPC Server处理流程:
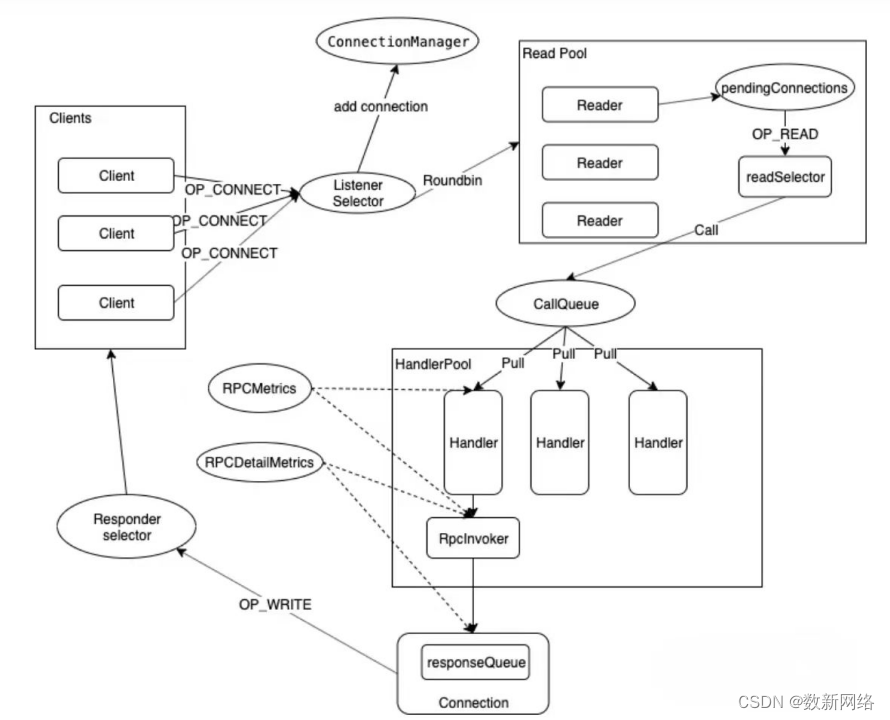
其中有几个比较重要的组件:
Client: 客户端
Listener: Server端只存在一个Listener,主要功能就是分发,在Selector中注册了ACCEPT事件,每当有新的Client连接,便会为Client指定一个Reader线程。创建服务器对象,通过RPC.getServer完成
Reader: Reader线程有多个,主要任务是读取请求,并将请求封装成一个Call,放入callQueue中
CallQueue: reader handler之间的缓冲队列,生产消费者模型
Responder:read request和write response采用不同的selector实现读写分离
connectionManager: 定时清理idle时间过长的Connection
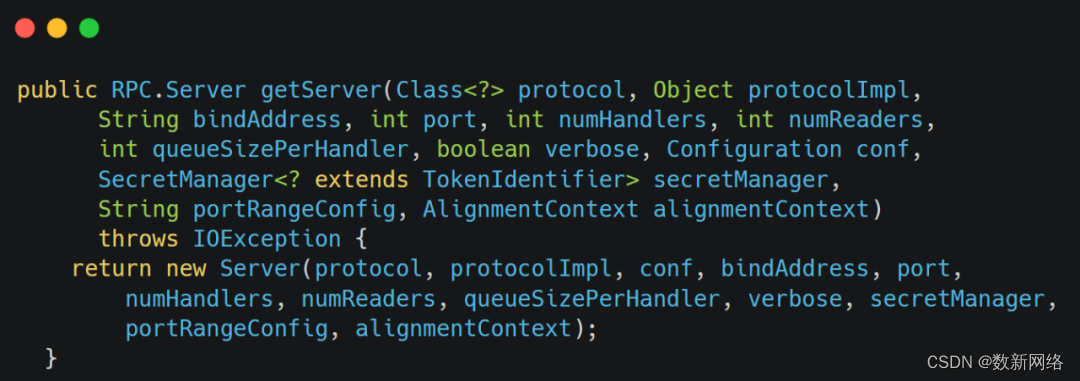
上图是RPCEngine获取Server服务器对象的方法,该方法最后会调用Server类中的构造方法创建Server对象。
在构造方法中除了对端口地址等属性初始化外,还构建了Listener和Responder,一般通过RPC.getServer创建服务器后,会调用服务器的start方法启动服务器。当服务端启动时同时会启动Listener,Responder及Handler。

Listener构造:
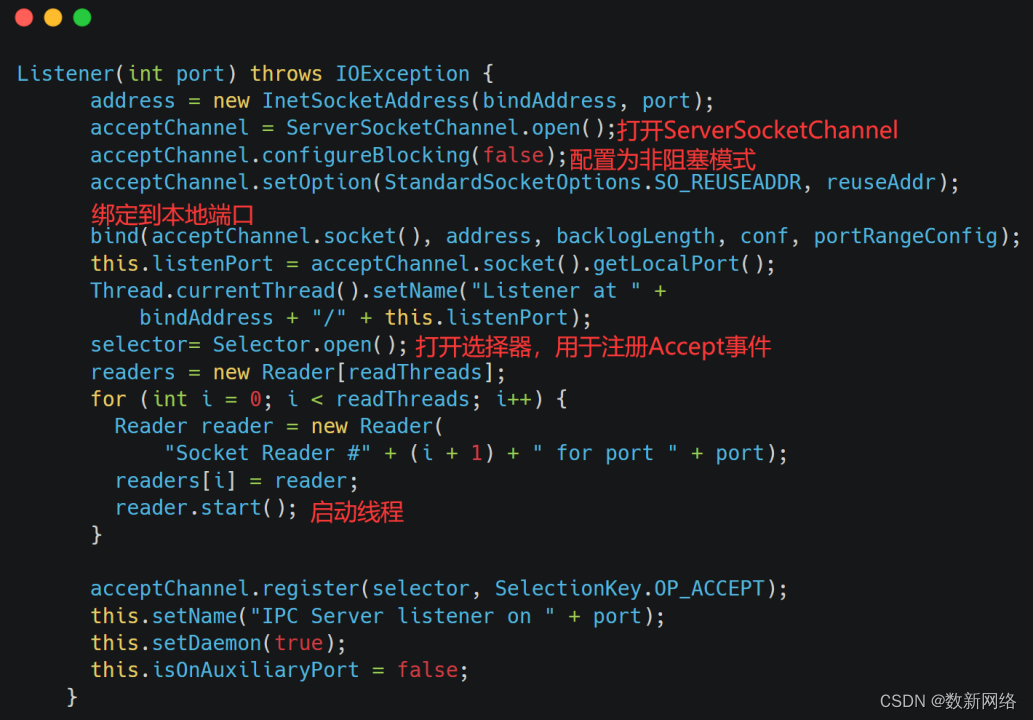
Listener类是一个线程类,主要任务就是为连入的Socket分配Reader。详细代码逻辑在启动线程后的run方法的doAccept方法中。
Reader:
将Request中的属性提取出来封装成一个RpcCall对象,并将Call对象放入CallQueue中。

Call:
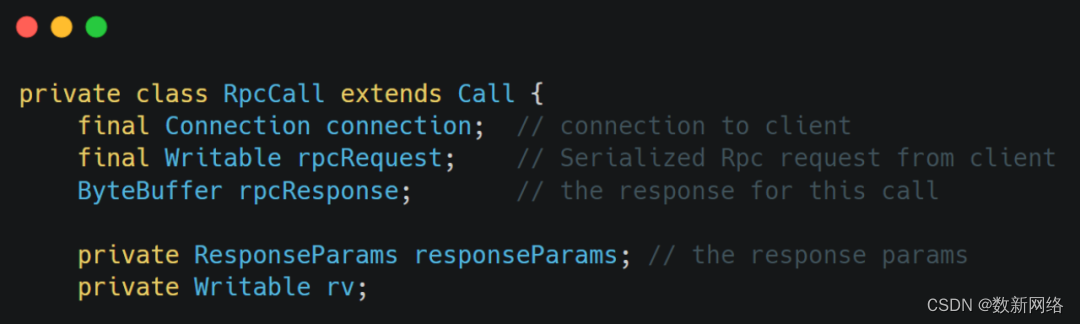
Call类中封装了Request对象和Response对象,Call类被Reader存放在CallQueue中,等待Handler的处理。
Handler:
Handler的主要任务就是从callQueue拿出Call,并通过Request找到真实的实现方法,并通过方法名和参数进行执行。
3-3 建立连接
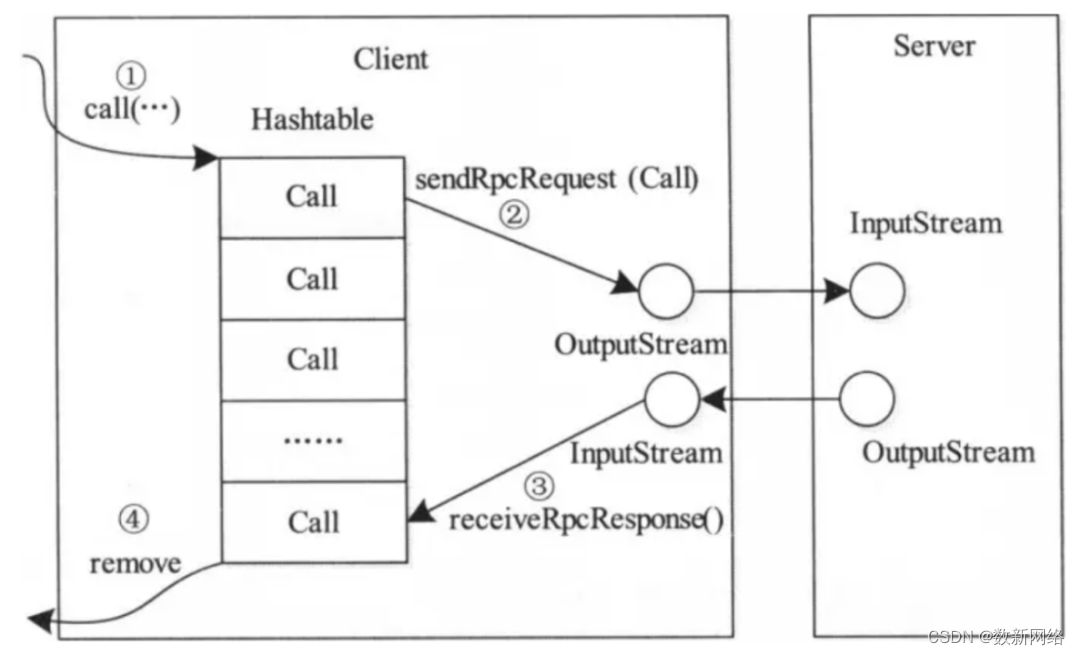
Client与每个Server之间维护一个通信连接。该连接相关的基本信息及操作被封装到Connection类中。其中,基本信息主要包括:通信连接唯一标识(remoteId),与Server端通信的Socket(socket),网络输入数据流(in),网络输出数据流(out),保存RPC请求的哈希表(calls)等。
当调用call函数执行某个远程方法时,Client端需要进行如下几个步骤:
步骤1
创建一个Connection对象,并将远程方法调用信息封装成Call对象,放到 Connection对象中的哈希表calls中;
步骤2
调用Connetion类中的sendParam()方法将当前Call对象发送给Server端;
步骤3
Server端处理完RPC请求后,将结果通过网络返回给Client端,Client端通过receiveResponse()函数获取结果;
步骤4
Client端检查结果处理状态(成功还是失败),并将对应的Call对象从哈希表中删除。
在建立连接完成后就可以处理客户端的请求了,主要任务是从共享队列中获取call对象,执行对应的函数调用,并将结果返回给客户端,这全部由Handler线程完成。
Server端可同时存在多个Handler线程,它们并行从共享队列中读取Call对象,经执行对应的函数调用后,将尝试着直接将结果返回给对应的客户端。
但考虑到某些函数调用返回结果很大或者网络速度很慢,可能难以将结果一次性发送给客户端,此时Handler将尝试着将后续发送任务交给Responder线程。