TreeBERT:基于树的编程语言预训练模型。
TreeBERT
https://arxiv.org/abs/2105.12485
Comments: Accepted by UAI2021
Subjects: Machine Learning (cs.LG); Programming Languages (cs.PL)
Cite as: arXiv:2105.12485 [cs.LG]
1 Introduction
现有挑战:
-
设计适当的机制来学习程序的语法结构
代码是强结构化的,代码的语义依赖于要表示的具有不同语法结构的程序语句和表达式的组合,不能仅仅采用类似于自然语言的处理方法(简单的将代码建模为单词序列)。
如何使用AST作为预训练模型的输入?
-
树形结构的预训练任务探索
面向序列的任务直接应用于非顺序结构化AST中存在一些不恰当的问题,因此,需要为树设计新的预训练任务,使预训练模型能够同时从AST中提取语法和语义信息。
主要贡献:
- 提出了TreeBERT,一个面向pl的基于树的预训练模型。
- 遵循Transformer编码器-解码器架构。为了使Transformer能够利用树形结构,将代码片段对应的AST表示为根节点到终端节点路径的集合,然后引入节点位置嵌入以获得节点在树中的位置。
- 提出了一种适用于AST的混合目标来学习语法和语义知识,即树掩码语言建模(TMLM)和节点顺序预测(NOP)。
- 在TMLM中,在编码器侧输入具有屏蔽节点的AST路径集,并在解码器侧使用AST中的上下文信息预测完整的代码片段。
- 由于路径中节点的顺序表达了程序结构信息,NOP通过预测节点是否无序来提高模型捕获语法结构信息的能力。
2 Model
2.1 Model Architecture
采用transformer的编码器-解码器结构。修改了Transformer的编码器端,只添加了一个完全连接的层来调整输入的维度。
2.2 Input Representation
AST Representation
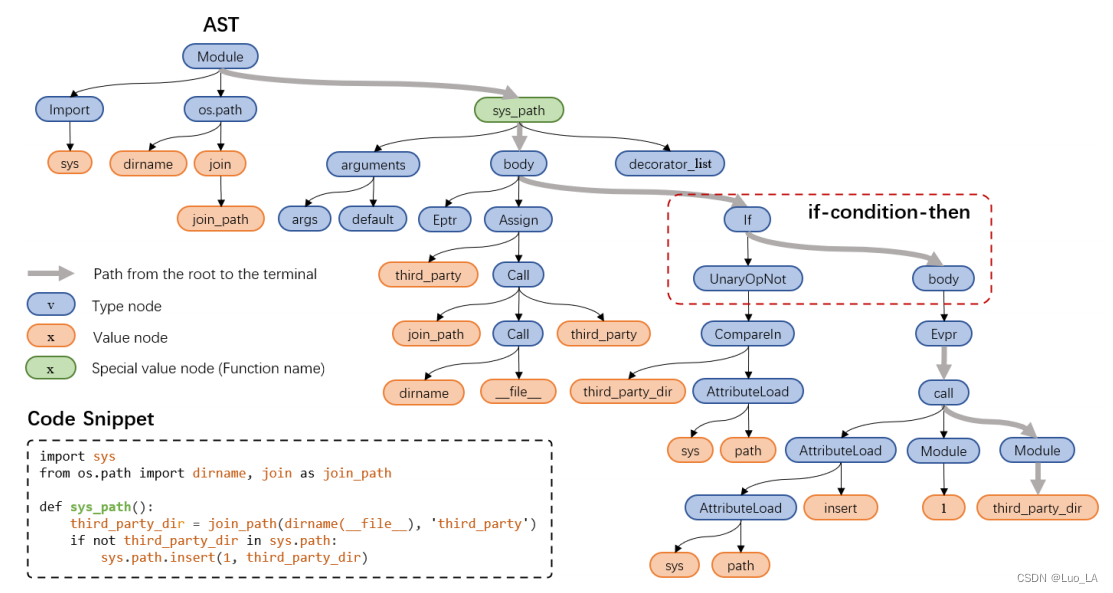
AST以树的形式展示了程序的语法结构。树中的每个节点表示代码中的一个结构。
AST节点分为两类:
- 类型节点(type node),用 v 表示。
- 值节点(value node),用 x 表示。值节点几乎都是叶节点(终端节点),除了函数名是非叶子节点但是使用了 value 属性。
用从根节点到叶节点的路径集合表示AST,A = { p1,p2,…,pN },N表示AST中路径的个数。
Code Representation
与AST相应的代码片段被分割成一系列 tokens,[LT] 和 [CLS] 分别被添加在序列的开始和结尾处。
C = [LT],x1,x2,…,x3,[CLS] ,其中 [LT] 是 [LT] 的向量表示, [CLS] 是 [CLS] 的向量表示,M是代码片段的长度。
C 被使用在解码器的输入。[EOS] 是解码器端的句尾标识符。
[LT] 不仅作为解码器端的句子开头标识符,它的值还表示目标编程语言的类型。例如, [LT] = [PLT] 表示语言类型是 Python,[LT] = [JLT] 表示语言为Java,当 [LT] = [UNK] 时表示编码器生成的语言是在预训练阶段未见过的语言。这样定义是因为在将代码片段转换为AST时,隐藏了不同类型语言的实现细节,我们需要提示语言类型,以便模型了解不同编程语言之间的差异。
使用 [CLS] 作为NOP的聚合表示。
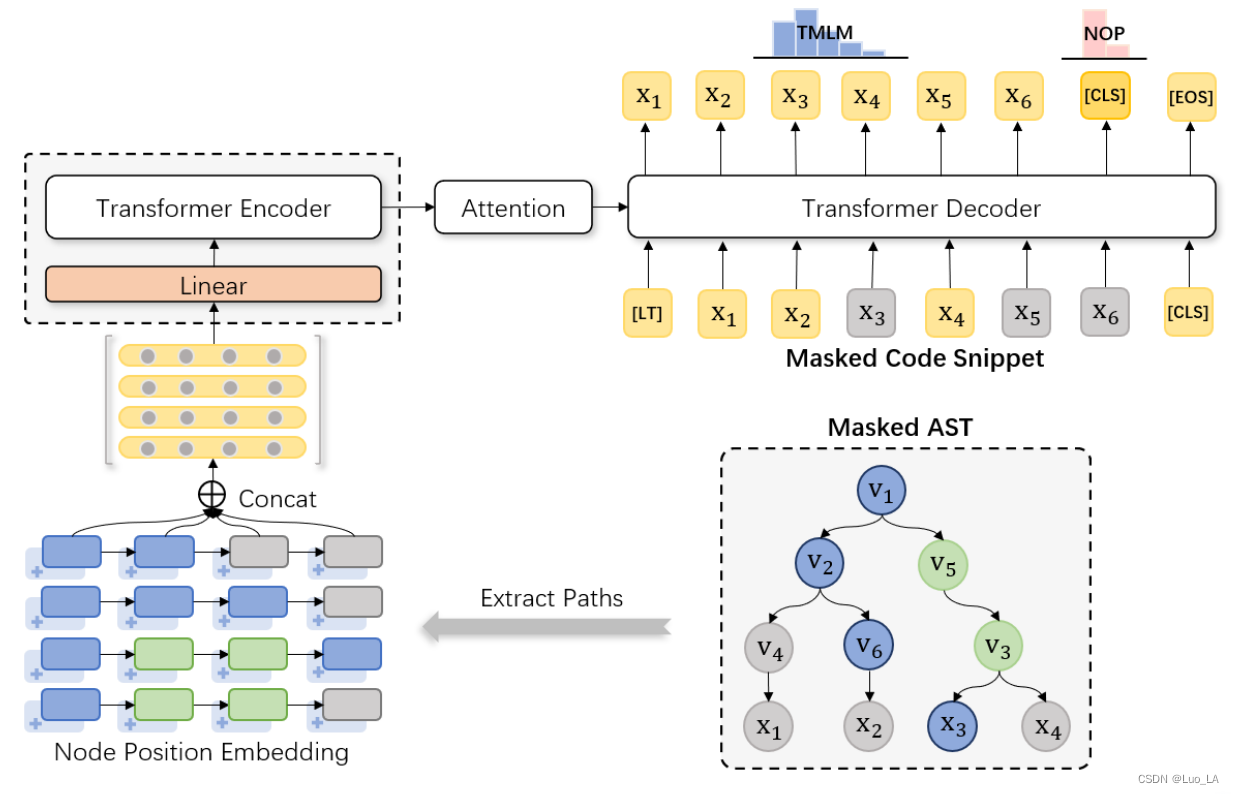
Path Representation
每一个 path 是一个 nodes 序列, p i = v 1 i v 2 i . . . v L − 1 i x t i p_i=v^i_1v^i_2...v^i_{L-1}x^i_t pi=v1iv2i...vL−1ixti,path 上的叶子节点 x t i x^i_t xti 是对应的代码片段的一个 token,L是 path 的长度。
我们将路径上的节点向量连接起来以表示路径:
p i = C o n c a t [ v 1 i ; v 2 i ; . . . ; v L − 1 i ; x t i ] ; p_i=Concat[v^i_1;v^i_2;...;v^i_{L-1};x^i_t]; pi=Concat[v1i;v2i;...;vL−1i;xti];
路径集合中的路径表示向量之间没有排序关系。因此,与标准Transformer不同,我们的模型编码器端不添加位置编码来为路径向量分配位置信息,而是在形成节点表示时使用节点位置嵌入来添加树中节点的位置信息。
Token Representation
使用字节对编码(BPE),从AST的值节点和代码片段中学习最常见的 subtoken,并对其进行切片,例如 “third_party” 可能被切片成 “third” ,“-” 和 “party”,使用过程每个token 的所有 subtoken 的向量和来表示完整的 token。
AST中的类型节点数量固定且较少,直接通过embedding将其表示为 实值向量。
Node Posiotion Embedding
一个节点的 position embedding 是其父节点的 position embedding 与它相应的 level embedding 的线性组合。
由 H+1 个 level embedding 作为参数,即 W l e v e l W^{level} Wlevel,其中H为树的高度。我们使用 W 0 l e v e l W^{level}_0 W0level作为根节点的 parent position embedding。如果在 第 j 层有一个节点,它的 position embedding 是 W p a r e n t W^{parent} Wparent 并且它由 c 个子节点,那么它的第 i 个子节点的 position embedding 表示为:
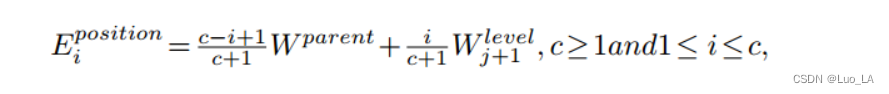
其中 W p a r e n t W^{parent} Wparent , W l e v e l W^{level} Wlevel 是可学习的线性矩阵。Node Posiotion Embedding 可以获得层次信息和节点的父节点和兄弟节点的相对位置信息。
2.3 Pre-training Tasks
Tree Masked Language Modeling (TMLM)
给定 AST-code 片段对,提出一种屏蔽AST中的节点和代码片段的tokens的策略。
在编码器端,首先根据概率 { q n i } n = 1... L \{q^i_n\}_{n=1...L} {qni}n=1...L的分布对路径 p i p_i pi 上的节点进行采样,并使用 TOPK() 操作去选择概率最大的k个节点 m i A m^A_i miA,然后用一个特殊 token [mask] 替换路径 p i p_i pi 中的这些节点,得到 p i m a s k e d p^{masked}_i pimasked
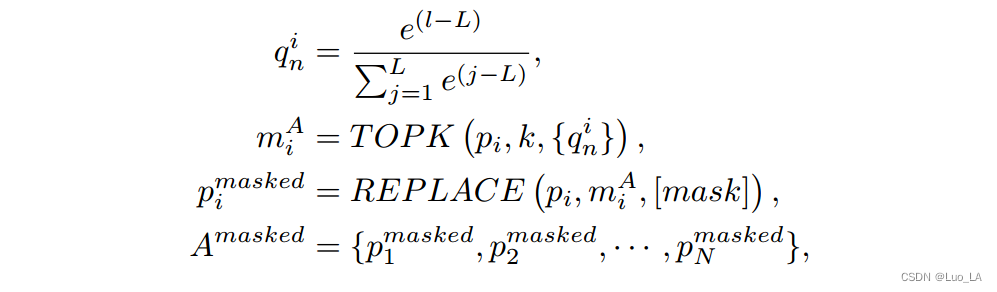
其中 A m a s k e d A^{masked} Amasked 代表 masked 路径的结合, l l l 是当前的节点层次, L L L 是路径中最大的节点层数, N N N 为AST中包含的路径个数, i = 1... N i=1...N i=1...N。注意, L L L 被减去是为了防止数值溢出,这确保了路径中在较大层次的节点被屏蔽的概率更高。
TMLM以更高的概率屏蔽路径中靠近终端的节点。主要原因是:
- 由于每条路径都是从根节点到终端节点,所以节点离根节点越近,在路径集中重复的次数就越多。如果我们使用标准的MLM屏蔽策略,许多相同类型的节点被屏蔽。重复学习这些节点的表示会损害模型的性能。
- AST的终端节点通常是指用户自定义的值,这些值代表代码中具有丰富含义的标识符和名称。因此,更频繁地屏蔽这些节点可以迫使我们的模型学习它们的表示。
在解码器端,解码器的输入 C m a s k e d C^{masked} Cmasked是通过屏蔽代码片段中的 tokens 获得的,屏蔽公式如下:
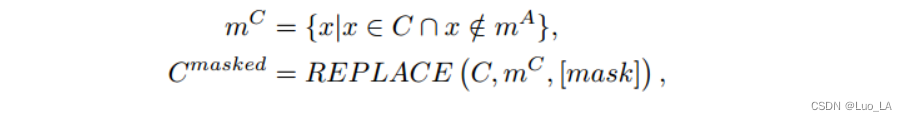
其中 m A = m 1 A ∪ m 2 A ∪ . . . ∪ m N A m^A=m^A_1∪m^A_2∪...∪ m^A_N mA=m1A∪m2A∪...∪mNA, x x x 是集合 m C m^C mC 中需要被 mask 的元素。
我们保留与 m A m^A mA 中的值节点对应的 tokens,屏蔽代码片段 C 中的其他节点。这样,通过下一个 token 的预测,TMLM可以强制解码器依赖于 AST 的特征表示,而不是代码片段中的 previous token。
下图显示了一个示例,灰色节点意味着节点被 masked。根据前面的策略,在AST 中,四条路经被 masked 的节点集合为: m 1 A = { v 4 , x 1 } , m 2 A = { x 2 } , m 3 A = { } , m 4 A = { x 4 } m^A_1=\{v_4,x_1\},m^A_2=\{x_2\},m^A_3=\{\},m^A_4=\{x_4\} m1A={v4,x1},m2A={x2},m3A={},m4A={x4},在代码片段中,值节点 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3 是被给出的,其它节点是被 masked 的,即 m C = { x 3 , x 5 } m_C=\{x_3,x_5\} mC={x3,x5}。解码器需要做的是预测完整的代码片段 x 1 , x 2 , x 3 , x 4 , x 5 , x 6 x_1,x_2,x_3,x_4,x_5,x_6 x1,x2,x3,x4,x5,x6。
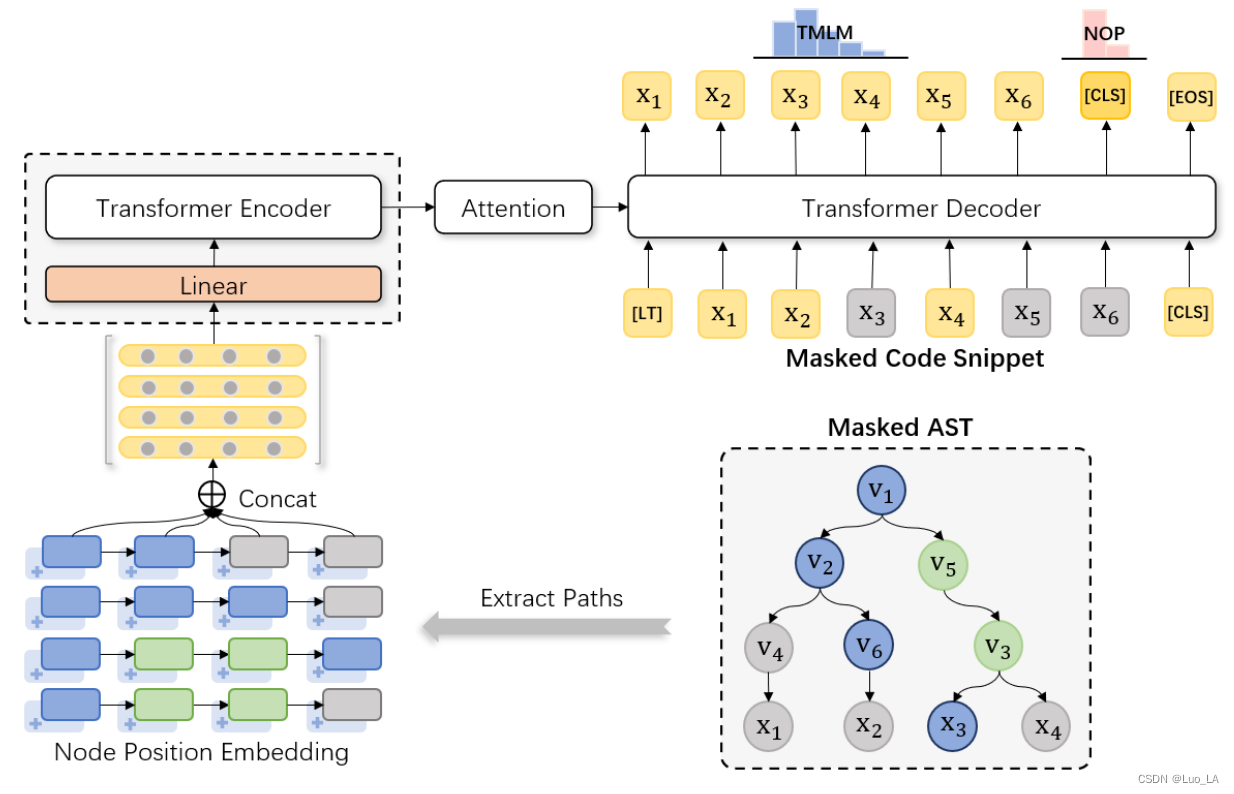
在TMLM中,**编码器读取被屏蔽的AST路径集合,然后解码器推断出与AST对应的代码片段。**当代码转换为AST时,隐藏了一些语义信息,如“+”,“>”,“<=”等二进制操作符在AST中使用“BinOpSub”节点表示。在这种情况下,如果解码器被设计为预测AST,则上述语义信息将被忽略。因此,我们设计解码器来预测代码片段,以鼓励模型推断这些语义信息,从而增强其在下游任务中的泛化能力。
总之,TMLM可以强制编码器理解AST并推断隐藏在AST中的语义信息。
Node Order Prediction(NOP)
为了进一步提高从程序中提取语法结构信息的能力,我们设计了二值化预训练任务NOP。
AST中节点的顺序有一些隐式约束。以上图中的AST结构为例,“if”节点下必须有一个“body”节点,“body”节点下必须有一个“Expr”节点。为了获取这种语法结构信息,我们以一定的概率决定是否随机交换路径中某些节点的位置,然后训练模型来区分AST中节点的顺序是否正确。如图2所示,我们交换节点v3和v5的位置(图中绿色的节点代表交换位置)。
[CLS] 的隐向量通过一个全连接层压缩到一维,然后通过sigmoid函数得到AST路径中无需节点存在的概率 y’
3 Experiment
为了验证TreeBERT的有效性,TreeBERT对两个生成任务进行了微调,并与基线进行了比较。生成任务是代码总结和代码文档。我们还评估了TreeBERT在c#数据集上的性能,并通过实验证明TreeBERT可以很好地推广到预训练阶段未见的编程语言。
4 Conclusion
改进策略:
- TreeBert不仅可以用于代码摘要和代码文档之类的任务,还可以用于源语言能够进行AST构造的任何任务。继续探索将TreeBERT应用于更多 PL 任务的可能性。
- 进一步改进TreeBERT,例如在AST中添加更多的程序信息,或者同时使用AST、graph和sequence等多模态形式,从而从不同的角度提取程序信息,使TreeBERT能够更好地解决PL下游任务。