二叉树题目:二叉树最大宽度
文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 前言
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:二叉树最大宽度
出处:662. 二叉树最大宽度
难度
5 级
题目描述
要求
给定一个二叉树的根结点 root \texttt{root} root,返回给定的树的最大宽度。
树的最大宽度是所有层中的最大宽度。
每一层的宽度定义为两端结点(最左和最右的非空结点)之间的长度,两端结点之间的空结点也计入长度的计算。
题目保证答案在 32 \texttt{32} 32 为有符号整数范围内。
示例
示例 1:
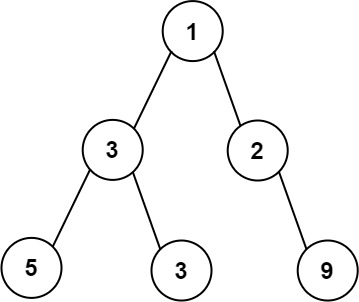
输入: root = [1,3,2,5,3,null,9] \texttt{root = [1,3,2,5,3,null,9]} root = [1,3,2,5,3,null,9]
输出: 4 \texttt{4} 4
解释:最大宽度出现在第 3 \texttt{3} 3 层,宽度为 4 \texttt{4} 4( 5,3,null,9 \texttt{5,3,null,9} 5,3,null,9)。
示例 2:
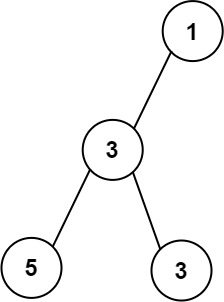
输入: root = [1,3,null,5,3] \texttt{root = [1,3,null,5,3]} root = [1,3,null,5,3]
输出: 2 \texttt{2} 2
解释:最大宽度出现在第 3 \texttt{3} 3 层,宽度为 2 \texttt{2} 2( 5,3 \texttt{5,3} 5,3)。
示例 3:
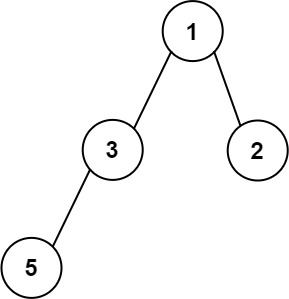
输入: [1,3,2,5] \texttt{[1,3,2,5]} [1,3,2,5]
输出: 2 \texttt{2} 2
解释:最大宽度出现在树的第 2 \texttt{2} 2 层,宽度为 2 \texttt{2} 2( 3,2 \texttt{3,2} 3,2)。
数据范围
- 树中结点数目在范围 [1, 3000] \texttt{[1, 3000]} [1, 3000] 内
- -100 ≤ Node.val ≤ 100 \texttt{-100} \le \texttt{Node.val} \le \texttt{100} -100≤Node.val≤100
前言
为了得到二叉树的最大宽度,需要得到二叉树每一层中的每个结点的位置。每一层的宽度取决于该层最左和最右的非空结点的位置,除了根结点以外的每个结点的位置由该结点的父结点和该结点是左子结点还是右子结点决定。
考虑满二叉树每一层中的每个结点的位置。定义根结点位于第 0 0 0 层,则满二叉树的第 k k k 层有 2 k 2^k 2k 个结点,从左到右的每个结点的位置依次是 0 0 0 到 2 k − 1 2^k - 1 2k−1,满二叉树的第 k + 1 k + 1 k+1 层有 2 k + 1 2^{k + 1} 2k+1 个结点,从左到右的每个结点的位置依次是 0 0 0 到 2 k + 1 − 1 2^{k + 1} - 1 2k+1−1。由于满二叉树的第 k + 1 k + 1 k+1 层的结点数目是第 k k k 层的结点数目的 2 2 2 倍,因此对于第 k k k 层中位置是 pos \textit{pos} pos 的结点,其左子结点和右子结点在第 k + 1 k + 1 k+1 层中的位置分别是 pos × 2 \textit{pos} \times 2 pos×2 和 pos × 2 + 1 \textit{pos} \times 2 + 1 pos×2+1。
上述关于结点位置的定义同样适用于不是满二叉树的情况。对于每个非空结点,只要知道该结点在当前层中的位置,即可知道该结点的每个子结点在下一层中的位置,因此可以知道每个结点在对应层中的位置。
解法一
思路和算法
由于需要计算二叉树每一层的宽度,然后得到最大宽度,因此可以使用层序遍历实现。
从根结点开始依次遍历每一层的结点,在层序遍历的过程中需要区分不同结点所在的层,确保每一轮访问的结点为同一层的全部结点。遍历每一层结点之前首先得到当前层的结点数,即可确保每一轮访问的结点为同一层的全部结点。对于每一层,记录该层的最左和最右非空结点的位置,然后计算该层的宽度。
为了记录每个结点的位置,需要使用两个队列,分别存储结点和结点的位置,这两个队列分别为结点队列和位置队列,初始时将根结点和位置 0 0 0 分别入两个队列。在遍历每一层之前,位置队列的队首元素即为该层的最左非空结点的位置,遍历该层的每个结点时,将每个结点的非空子结点和子结点对应的位置分别入两个队列,该层的最后一个结点即为该层的最右非空结点,计算两端结点之间的长度,得到该层的宽度,并用该层的宽度更新最大宽度。
遍历结束之后,即可得到二叉树的最大宽度。
代码
class Solution {public int widthOfBinaryTree(TreeNode root) {int maxWidth = 0;Queue<TreeNode> nodeQueue = new ArrayDeque<TreeNode>();Queue<Integer> posQueue = new ArrayDeque<Integer>();nodeQueue.offer(root);posQueue.offer(0);while (!nodeQueue.isEmpty()) {int leftmost = posQueue.peek();int size = nodeQueue.size();for (int i = 0; i < size; i++) {TreeNode node = nodeQueue.poll();int pos = posQueue.poll();if (i == size - 1) {int width = pos - leftmost + 1;maxWidth = Math.max(maxWidth, width);}TreeNode left = node.left, right = node.right;if (left != null) {nodeQueue.offer(left);posQueue.offer(pos * 2);}if (right != null) {nodeQueue.offer(right);posQueue.offer(pos * 2 + 1);}}}return maxWidth;}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度主要是队列空间,队列内元素个数不超过 n n n。
解法二
思路和算法
也可以使用深度优先搜索计算二叉树最大宽度。具体做法是使用前序遍历,依次访问二叉树的根结点、左子树和右子树,由于前序遍历满足同一层结点被访问的顺序为从左到右,因此同一层结点中第一个被访问的结点一定是该层最左的非空结点。使用哈希表存储每一层的最左的非空结点的位置(以下简称「最左位置」),当访问到某个结点时,如果哈希表中没有该结点所在层的最左位置,则在哈希表中将当前层对应的最左位置设为该结点的位置。
对于访问到的每个非空结点,可以得到当前层内该结点的位置和最左位置,计算当前层内该结点和最左的非空结点之间的宽度,并更新二叉树的最大宽度。遍历结束之后,即可得到二叉树的最大宽度。
代码
class Solution {Map<Integer, Integer> leftmostMap = new HashMap<Integer, Integer>();int maxWidth = 0;public int widthOfBinaryTree(TreeNode root) {dfs(root, 0, 0);return maxWidth;}public void dfs(TreeNode node, int depth, int pos) {leftmostMap.putIfAbsent(depth, pos);maxWidth = Math.max(maxWidth, pos - leftmostMap.get(depth) + 1);TreeNode left = node.left, right = node.right;if (left != null) {dfs(left, depth + 1, pos * 2);}if (right != null) {dfs(right, depth + 1, pos * 2 + 1);}}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度主要是哈希表和栈空间,取决于二叉树的高度,最坏情况下二叉树的高度是 O ( n ) O(n) O(n)。