使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(一)
本篇文章聊聊更轻量的向量数据库方案:Redis。
以及基于 Redis 来快速实现一个高性能的本地图片搜索引擎,在本地环境中,使用最慢的稠密向量检索方式来在一张万图片中查找你想要的图片,总花费时间都不到十分之一秒。
写在前面

接着上一篇文章的话题,继续聊聊“图片搜索引擎”。给月底即将发生的一场分享中的“命题作文”补充一些详细的实践教程:《使用向量数据库快速构建本地轻量图片搜索引擎》。其实,在一年前,在做 Milvus 开源布道师的时候,我曾经写过一些 Milvus 相关的内容。这篇分享中提到的“图片搜索引擎”的话题,我在一年前就写过啦:《向量数据库入坑:使用 Docker 和 Milvus 快速构建本地轻量图片搜索引擎》。
不过,在这场分享活动中,有来自各种厂商的向量数据库“利益相关”的从业者,举办方站在中立立场上,希望大家的分享内容都更加中立客观的,尤其是厂商之外的分享者,不要表现太多的偏向性,话题百花齐放更好些,朋友的要求,自然是要尊重的。
此外,距离我发布上一篇“图片搜索引擎”后,不论是文章中使用的向量数据库 Milvus、还是用来快速做 Embedding 的 Towhee 不论是项目还是团队,都经历了比较多的迭代,面向的目标客户群体和场景也更明确,不太适合再做本地解决方案,更适合云端分布式场景。
正巧,在合作中的其中一家朋友的公司,前段时间也在折腾向量数据库,他更倾向先使用“更老牌”一些的技术方案,诸如:Elasticsearch、Mongo、Postgres、ClickHouse、Redis 这类加上向量数据库解决能力的成名久已的传统解决方案。
所以,这篇文章就来聊聊用户群体甚多,大家都很熟悉的老牌开源软件:Redis 的向量数据库场景实践。
准备材料
接下来聊聊本篇实践内容中需要的三个素材:Docker、HuggingFace 上下载的 OpenAI 的 Clip 模型(用于 Embedding)、以及适合我们自己或者业务实际使用的大量的图片数据集(文本、语音、视频、文件等同理)。
本文中使用的相关程序都已经开源在 soulteary/simple-image-search-engine/,欢迎一键三连,😄
Docker 运行环境

本文的所有内容都可以在标准的 Docker 容器环境中复现。
所以,想顺滑的完成实践,我推荐你安装 Docker,不论你的设备是否有显卡,都可以根据自己的操作系统喜好,参考这两篇来完成基础环境的配置《基于 Docker 的深度学习环境:Windows 篇》、《基于 Docker 的深度学习环境:入门篇》。当然,使用 Docker 之后,你还可以做很多事情,比如:之前几十篇有关 Docker 的实践,在此就不赘述啦。
如果你和我一样,使用 Docker 环境折腾、学习和用于生产。那么,我推荐你使用 Nvidia 家提供的深度学习环境 nvcr.io/nvidia/pytorch:23.10-py3 作为基础镜像,其中的 CUDA 版本经常效率比公开的开源社区版本要跑的更快一些:
FROM nvcr.io/nvidia/pytorch:23.10-py3
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple && \pip3 install --upgrade pip # enable PEP 660 support
WORKDIR /app
RUN pip3 install transformers==4.35.0 "redis[hiredis]==5.0.1"
我们将上面的内容保存为 Dockerfile,然后使用下面的命令来完成稍后使用的镜像的构建(项目中的相关文件保存在 soulteary/simple-image-search-engine/docker/Dockerfile):
docker build -t soulteary/image-search-engine:20231114 .
当然,如果你不使用 Docker 环境,也可以通过手动安装 pytorch 和执行下面的命令,完成 PyPi 相关依赖安装:
pip3 install transformers==4.35.0 "redis[hiredis]==5.0.1"
当然,为了折腾更简单一些,我还做了一个能够让我的读者一键拉起来的运行环境:
version: "2.4"services:embededing-server:ipc: hostulimits:memlock: -1stack: 67108864stdin_open: truetty: truevolumes:- ./make-embededing:/appimage: soulteary/image-search-engine:20231114command: tail -f /etc/hostscontainer_name: embededing-serverredis-server:image: redis/redis-stack-server:7.2.0-v6volumes:- ./redis-data:/data
将上面的文件保存为 docker-compose.yml。然后使用 docker compose up 启动服务,我们就能够分别使用下面的命令,来访问用来构建向量的容器 embededing-server 和 redis-server 啦。
# 使用命令行进入 Embededing Server 容器
docker exec -it embededing-server bash
# 使用命令行进入 Redis Server 容器
docker exec -it redis-server bash
HuggingFace 上的 OpenAI Clip 模型
本篇文章主要使用的模型是 OpenAI 在两年前开源的 Clip 模型,也是 HuggingFace 上的宝藏模型之一。关于 Clip 的介绍,OpenAI 公开的研究页面有非常详细的资料,如果你感兴趣,可以移步阅读。
在图片搜索这个场景下,我们可以根据自己的情况选择下面两个版本的模型,推荐选择 patch16 版本,相对新一些:
- openai/clip-vit-base-patch16(第二版发布的版本)
- openai/clip-vit-base-patch32(第一版发布的版本)
至于更新一些时候发布的两个标记为 large 的版本,好用是好用,但是需要更多的资源(模型尺寸接近之前的三倍):
- openai/clip-vit-large-patch14-336 (第四版发布版本)
- openai/clip-vit-large-patch14 (第三版发布版本)
开源项目中的代码,直接执行,会自动下载这两个模型。不过因为一些原因,Huggingface 的模型有时候会下载的特别慢,所以我们可以考虑用下面两个方案来加速模型下载,比如直接使用 Huggingface 新推出的命令行 HF Transfer 和好心网友搭建的 hf-mirror.com 加速器,来完成模型的快速下载:
HF_ENDPOINT=https://hf-mirror.com HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download --resume-download openai/clip-vit-base-patch16 --local-dir clip-vit-base-patch16 --local-dir-use-symlinks False
不过因为上面的加速网站的原理是依赖 CDN,有时候要“看天吃饭”,不甚稳定。所以,你也可以使用百度网盘下载我上传好的两个模型。
模型下载完毕后,将它放在 openai 目录后,我们开始处理图片数据集。
从视频文件中提取图片数据集
因为这篇命题是图片搜索,所以我们还需要一些有趣的、大量的图片数据。在上一篇“图搜实践”的文章里,我用的是从搜索引擎搜索出的第一页原神卡通壁纸,数量不多,只有 60 多张壁纸。
为了更直观的感受 Redis 作为向量数据库的性能优势,我们需要把图片数据整的更多一些。
通常情况下,获取合适的数据集自然是有难度的,但是在学习研究的情况下,或许你可以参考这篇文章《开源软件 FFmpeg 生成模型使用图片数据集》,使用造福了无数视频软件公司、在线直点播公司、无数 CDN 云服务厂商的 FFmpeg 和你喜爱的电影、视频,来手动构建适合你的测试数据集。

通过上面的方法,我把这部电影转换成了每秒 10393 张图片(其实也不多,数量级还是太小了),它们被命名为 ball-001.png、ball-002.png … 之所以使用视频中的关键帧作为数据集,主要的原因是:这类数据比较有代表性、画面质量相对较高,包含高质量的多种分类的图片。 目前互联网流量中绝大多数是视频,在“哔哩哔哩”或者各种 PT 爱好者网站、以及各种百度云、阿里云盘等资源站点,视频资源的获取难度相对较低,资源相对充分,比如这篇文章我们可以以科幻电影为例,也可以以纪录片为例、或者用连续剧也没啥问题。
如果你希望获得更大规模大数据集,你可以尝试比如把 “哈利波特系列”、“老友记”、“狂飙” 这种可以转换出图片数量更多的电影、电视剧作为目标,轻轻松松搞出十万级、百万级的图片数据集。
将图片放在名为 images 的目录中,我们要给搜索引擎建立“底库”的数据集准备工作就完毕啦。
一切都准备好之后,我们开始通过编写少量代码,完成这个曾经只有互联网大厂才提供服务的:图片搜索引擎。
设计程序
正常情况下,图片搜索引擎会有两套主要的工作流程。
第一套逻辑是:“制菜和备菜”。使用一些能够解析图片的模型程序,解析海量图片中的特征点,并进行向量化存储,建立合适的数据库索引,方便后续提供服务。
第二套逻辑是:“菜品的售卖”。制作一个用户看着顺眼的界面(网页、客户端)让用户能够通过一些交互方式,来实现用文本搜索图片(文本搜索图片内容或上下文的文本),或者用图片来搜索图片(以图搜图)。
这两套逻辑一般情况下分开处理,各自选择最合适的技术方案性能最好,资源消耗最少,也利于进行水平扩展。第一套逻辑因为数据量通常巨大,适合用“离线、批处理”的方式来做,可以节约大量的成本;而第二套逻辑,则是我们日常使用的搜索引擎,我们在搜索内容的时候,遇到在系统中搜索一个东西超过几秒其实不常见,对于性能要求还是很高的,不然就有极其差的体验或者口碑。
图片搜索引擎的不足之处
目前视频和图片都搜索产品,其实都还不是那么的完善。不论是国内还是海外的产品,目前提供公开的、能够满足大量用户使用的产品还做不到一些看起来很自然的事情:搜索 “连续剧里吃冰糕的小男孩” 就能够快速定位某个影视剧、以及从该影视剧中的小男孩开始吃冰糕的那一秒开始播放。或者搜索“某某电影中男一号第二天起床后,旁边桌面上的闹钟的购物链接”。
有非常多的搜索引擎,还在依赖着上一代的文本检索、或者基础的语义检索的方式,来针对和图片一起出现的网页文本来进行内容关联。 不少时候,靠的还是搜索到视频编辑运营或用户发布的带有对应描述的文本内容,捎带出来的图片。甚至还有靠文本完全匹配来进行图片推荐的,也是离谱,都 2023 年末啦!
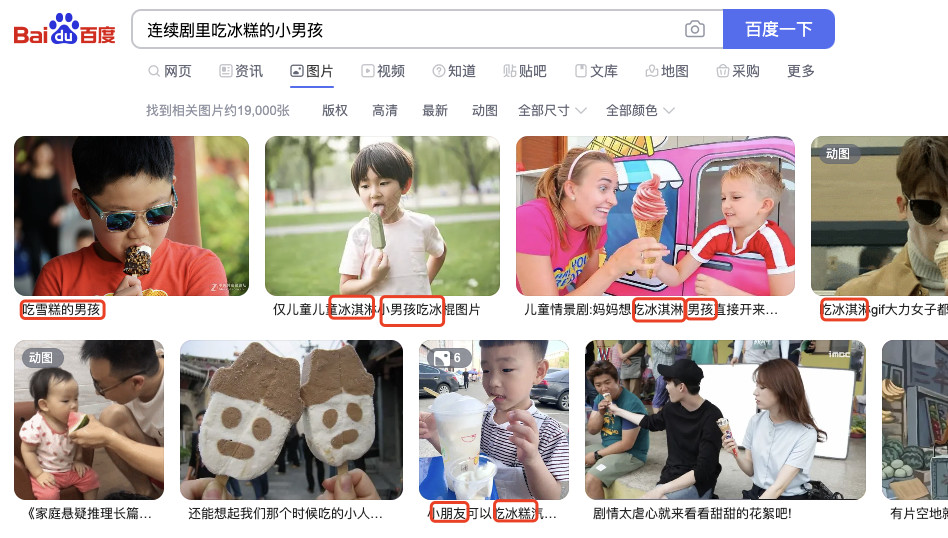
关于上面提到的“语义检索”,在之前的这篇文章中有提到过:《向量数据库入坑:传统文本检索方式的降维打击,使用 Faiss 实现向量语义检索》,感兴趣可以自行翻阅,自己实现一个试试看。
不过随着算力的发展、越来越多的软件都开始支持向量检索,用户可以被模型宠溺的越来越懒,相信这个状况一定会有所改善。
图片等数据的向量化处理
言归正传,我们先来实现第一套搜索引擎的处理逻辑,将图片进行向量化处理和存储到向量数据库中。
将图片进行向量化处理
为了方便我们测试代码功能,先选择流浪地球2剧作中的一帧画面(随便选就行):

下面这段代码,实现了从 HuggingFace 加载 OpenAI 的 Clip 模型,并对电影流浪地球2 中的我们选择的某一帧画面进行向量化处理,生成可以被存储在 Redis 中的数据的逻辑:
import torch
import numpy as np
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import time# 默认从 HuggingFace 加载模型,也可以从本地加载,需要提前下载完毕
model_name_or_local_path = "openai/clip-vit-base-patch16"model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)# 记录处理开始时间
start = time.time()
# 读取待处理图片
image = Image.open("ball-8576.png")
# 处理图片数量,这里每次只处理一张图片
batch_size = 1with torch.no_grad():# 将图片使用模型加载,转换为 PyTorch 的 Tensor 数据类型# 你也可以在这里对图片进行一些特殊处理,裁切、缩放、超分、重新取样等等inputs = processor(images=image, return_tensors="pt", padding=True)# 使用模型处理图片的 Tensor 数据,获取图片特征向量image_features = model.get_image_features(inputs.pixel_values)[batch_size-1]# 将图片特征向量转换为 Numpy 数组,未来可以存储到数据库中embeddings = image_features.numpy().astype(np.float32).tolist()print('image_features:', embeddings)# 打印向量维度,这里是 512 维vector_dimension = len(embeddings)print('vector_dimension:', vector_dimension)# 计算整个处理过程的时间end = time.time()print('%s Seconds'%(end-start))
将上面的代码保存为 app.py,执行 python app.py 后,不出意外,我们就能够得到这张图片的向量数据、向量数据的维度、以及处理时间啦:
image_features: [-0.4382634162902832, -0.3964928984642029, 0.23583322763442993, -0.31856775283813477, -0.2937283515930176, 0.13698264956474304, -0.32216179370880127, 0.2034275382757187, 0.11416329443454742, 0.08056379109621048,
...-0.2022382766008377, -0.3622089624404907, 0.14547640085220337, 0.20014266669750214, -0.08147376030683517, 0.24707356095314026, 0.1416967660188675, 0.305078387260437, 0.5607554316520691, -0.005001917481422424]vector_dimension: 5120.10873532295227051 Seconds
这部分的代码开源在了 GitHub 的 soulteary/simple-image-search-engine/steps/1.how-to-embededing,有需要可以自取,注释都写的比较详尽啦,就不赘述啦。
获取一万张图片的有序列表
目录中的图片,虽然有序号,但是倘若直接用程序读取图片列表,我们很难保障获取的图片顺序。而有序的存储图片,有利于后续继续拓展这个图片搜索引擎的能力,比如:实现视频搜索引擎,或者实现自动分段视频剪辑工具,连续的内容,一般是连续序列存放。
import osimage_directory = "images"# 使用列表推导式获取目录中所有的 PNG 图片名称
png_files = [filename for filename in os.listdir(image_directory) if filename.endswith(".png")]# 根据文件名中的数字部分进行排序
sorted_png_files = sorted(png_files, key=lambda x: int(x.split('-')[-1].split('.')[0]))# 打印排序后的 PNG 图片名称列表
for idx, png_file in enumerate(sorted_png_files, start=1):print(f"{idx}: {png_file}")
将上面的内容保存为 app.py,然后再次使用 python app.py 执行代码,就能够获得有序的文件列表啦:
1: ball-001.png
2: ball-002.png
3: ball-003.png
4: ball-004.png
5: ball-005.png
6: ball-006.png
7: ball-007.png
8: ball-008.png
9: ball-009.png
...
10391: ball-10391.png
10392: ball-10392.png
10393: ball-10393.png
这部分的代码保存在 GitHub 的这个目录:soulteary/simple-image-search-engine/steps/2.get-all-sorted-images。
处理所有的图片数据
将上面的两个代码片段进行合理的组合,我们就能够得到一份依次处理所有图片 embedding 数据的程序啦:
import torch
import numpy as np
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import time
import osmodel_name_or_local_path = "openai/clip-vit-base-patch16"
model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)image_directory = "images"
png_files = [filename for filename in os.listdir(image_directory) if filename.endswith(".png")]
sorted_png_files = sorted(png_files, key=lambda x: int(x.split('-')[-1].split('.')[0]))batch_size = 1with torch.no_grad():for idx, png_file in enumerate(sorted_png_files, start=1):print(f"{idx}: {png_file}")start = time.time()image = Image.open(f"{image_directory}/{png_file}")inputs = processor(images=image, return_tensors="pt", padding=True)image_features = model.get_image_features(inputs.pixel_values)[batch_size-1]embeddings = image_features.numpy().astype(np.float32).tolist()print('image_features:', embeddings)vector_dimension = len(embeddings)print('vector_dimension:', vector_dimension)end = time.time()print('%s Seconds'%(end-start))
这部分的代码保存在:soulteary/simple-image-search-engine/steps/3.how-to-embededing-all-images。
使用 Redis 存储图片的向量数据
前面的文章中,我们聊过了如何使用 Clip 模型来对图片进行向量化处理,以及如何批量处理大量文件数据,接下来我们来看看如何操作,以上文中最简单的 Embededing 实现为例:
import torch
import numpy as np
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import time
import redis# 连接 Redis 数据库,地址换成你自己的 Redis 地址
client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)model_name_or_local_path = "openai/clip-vit-base-patch16"
model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)png_file = "ball-8576.png"start = time.time()
image = Image.open(png_file)
batch_size = 1# 初始化 Redis Pipeline
pipeline = client.pipeline()
# 初始化 Redis,先使用 PNG 文件名作为 Key 和 Value,后续再更新为图片特征向量
pipeline.json().set(png_file, "$", png_file)
res = pipeline.execute()
print('redis set keys:', res)with torch.no_grad():inputs = processor(images=image, return_tensors="pt", padding=True)image_features = model.get_image_features(inputs.pixel_values)[batch_size-1]embeddings = image_features.numpy().astype(np.float32).tolist()vector_dimension = len(embeddings)print('vector_dimension:', vector_dimension)end = time.time()print('%s Seconds'%(end-start))# 将计算出的 Embeddings 更新到 Redis 数据库中pipeline.json().set(png_file, "$", embeddings)res = pipeline.execute()print('redis set:', res)
Redis 的操作方式和我们之前使用并没有太大的区别,还是走“初始化连接”、“初始化键值”、“合适时机塞数据”的路子。
这部分代码保存在 soulteary/simple-image-search-engine/steps/4.save-embededing-to-redis。
处理并保存所有的向量数据
继续调整和优化上面的程序,我们就可以将所有的图片都进行 embedding 处理和存入 Redis 中啦:
import torch
import numpy as np
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import time
import os
import redis# 连接 Redis 数据库,地址换成你自己的 Redis 地址
client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)model_name_or_local_path = "openai/clip-vit-base-patch16"
model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)image_directory = "images"
png_files = [filename for filename in os.listdir(image_directory) if filename.endswith(".png")]
sorted_png_files = sorted(png_files, key=lambda x: int(x.split('-')[-1].split('.')[0]))# 初始化 Redis Pipeline
pipeline = client.pipeline()
for i, png_file in enumerate(sorted_png_files, start=1):# 初始化 Redis,先使用 PNG 文件名作为 Key 和 Value,后续再更新为图片特征向量pipeline.json().set(png_file, "$", png_file)batch_size = 1with torch.no_grad():for idx, png_file in enumerate(sorted_png_files, start=1):print(f"{idx}: {png_file}")start = time.time()image = Image.open(f"{image_directory}/{png_file}")inputs = processor(images=image, return_tensors="pt", padding=True)image_features = model.get_image_features(inputs.pixel_values)[batch_size-1]embeddings = image_features.numpy().astype(np.float32).tolist()print('image_features:', embeddings)vector_dimension = len(embeddings)print('vector_dimension:', vector_dimension)end = time.time()print('%s Seconds'%(end-start))# 更新 Redis 数据库中的文件向量pipeline.json().set(png_file, "$", embeddings)res = pipeline.execute()print('redis set:', res)
将程序保存后执行,等待所有数据处理完毕,我们再进行构建索引操作,这里我的电脑大概运行了 10 分钟。
这部分代码保存在 soulteary/simple-image-search-engine/steps/5.save-all-embededing-to-redis。
当一切都执行完毕之后,我们观察 Redis 的容器进程,能够看到类似下面的内容:
8:M 14 Nov 2023 11:39:20.525 * Background saving terminated with success
8:M 14 Nov 2023 11:44:21.093 * 100 changes in 300 seconds. Saving...
8:M 14 Nov 2023 11:44:21.097 * Background saving started by pid 21
21:C 14 Nov 2023 11:44:21.707 * DB saved on disk
21:C 14 Nov 2023 11:44:21.708 * Fork CoW for RDB: current 1 MB, peak 1 MB, average 1 MB
8:M 14 Nov 2023 11:44:21.799 * Background saving terminated with success
我们可以手动执行一个命令,确保 Redis 将所有数据都正确存储了下来。
docker exec -it reids bash -c "echo BGREWRITEAOF | redis-cli"
执行完毕,当看到下面的带有“Background AOF rewrite finished successfully”的提示,数据就都被安全的存储下来啦:
8:M 14 Nov 2023 12:01:58.364 * Background append only file rewriting started by pid 69
69:C 14 Nov 2023 12:01:58.962 * Successfully created the temporary AOF base file temp-rewriteaof-bg-69.aof
69:C 14 Nov 2023 12:01:58.963 * Fork CoW for AOF rewrite: current 1 MB, peak 1 MB, average 1 MB
8:M 14 Nov 2023 12:01:59.022 * Background AOF rewrite terminated with success
8:M 14 Nov 2023 12:01:59.022 * Successfully renamed the temporary AOF base file temp-rewriteaof-bg-69.aof into appendonly.aof.5.base.rdb
8:M 14 Nov 2023 12:01:59.036 * Removing the history file appendonly.aof.4.base.rdb in the background
8:M 14 Nov 2023 12:01:59.050 * Background AOF rewrite finished successfully
查看数据目录,这 135M 的数据里,就包含了上万个图片的特征向量啦。
# du -hs redis-data135M redis-data
我们可以编写一段简单的程序,来验证存储的数据是否正确:
import redis# 连接 Redis 数据库,地址换成你自己的 Redis 地址
client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)res = client.json().get("ball-1234.png")
print(res)
执行完毕,正常的情况下,我们将得到文件的 embedding 数据。不过,目前这些数据都是以 KEY-VALUE 模式存储在数据库里。想要真正使用上向量化数据查询方式,我们还需要进行最后一步操作:建议向量索引。
构建向量索引
关于向量数据库实现的相似性检索,以及不同向量类型的差异,我在这篇《向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss》文章中提到过,感兴趣可以自行翻阅。
这里我们使用最简单的平面索引,这种索引方式的内存使用量最低,因为会采取遍历式搜索,所以别名被称为“暴力搜索”。
import redis
from redis.commands.search.field import VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType# 连接 Redis 数据库,地址换成你自己的 Redis 地址
client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)# 之前模型处理的向量维度是 512
vector_dimension = 512
# 给索引起个与众不同的名字
vector_indexes_name = "idx:ball_indexes"# 定义向量数据库的 Schema
schema = (VectorField("$","FLAT",{"TYPE": "FLOAT32","DIM": vector_dimension,"DISTANCE_METRIC": "COSINE",},as_name="vector",),
)
# 设置一个前缀,方便后续查询,也作为命名空间和可能的普通数据进行隔离
# 这里设置为 ball-,未来可以通过 ball-* 来查询所有数据
definition = IndexDefinition(prefix=["ball-"], index_type=IndexType.JSON)
# 使用 Redis 客户端实例根据上面的 Schema 和定义创建索引
res = client.ft(vector_indexes_name).create_index(fields=schema, definition=definition
)
print("create_index:", res)
当程序执行完毕之后,我们将得到 create_index: OK 的结果。这个过程可能会需要几秒钟,当我们看到 Redis 后台日志出现下面的内容时,索引就构建完毕啦:
8:M 14 Nov 2023 13:04:24.834 * <module> Scanning index idx:ball_indexes in background: done (scanned=10393)
如果你不放心,还可以手动查询下向量索引的数量,看看和你的原始图片数量对不对的上。
import redis# 连接 Redis 数据库,地址换成你自己的 Redis 地址
client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)vector_indexes_name = "idx:ball_vss"# 从 Redis 数据库中读取索引状态
info = client.ft(vector_indexes_name).info()
# 获取索引状态中的 num_docs 和 hash_indexing_failures
num_docs = info["num_docs"]
indexing_failures = info["hash_indexing_failures"]
print(f"{num_docs} documents indexed with {indexing_failures} failures")
当我们执行完上面的代码后,将得到下面的日志输出:
10393 documents indexed with 0 failures
嗯,和我们的图片素材一致。引构建完毕后,我们就能够使用程序来进行向量查询检索啦。
实现以图搜图功能
图片搜索引擎,可以有很多能力,我们先来实现相对技术含量最高的一种:以图搜图。
import torch
import numpy as np
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import time
import redis
from redis.commands.search.query import Querymodel_name_or_local_path = "openai/clip-vit-base-patch16"
model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)vector_indexes_name = "idx:ball_indexes"client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)start = time.time()
image = Image.open("ball-8576.png")
batch_size = 1with torch.no_grad():inputs = processor(images=image, return_tensors="pt", padding=True)image_features = model.get_image_features(inputs.pixel_values)[batch_size-1]embeddings = image_features.numpy().astype(np.float32).tobytes()print('image_features:', embeddings)# 构建请求命令,查找和我们提供图片最相近的 30 张图片
query_vector = embeddings
query = (Query("(*)=>[KNN 30 @vector $query_vector AS vector_score]").sort_by("vector_score").return_fields("$").dialect(2)
)# 定义一个查询函数,将我们查找的结果的 ID 打印出来(图片名称)
def create_query_table(query, query_vector, extra_params={}):result_docs = (client.ft(vector_indexes_name).search(query,{"query_vector": query_vector}| extra_params,).docs)print(result_docs)for doc in result_docs:print(doc['id'])create_query_table(query, query_vector, {})end = time.time()
print('%s Seconds'%(end-start))
在上面的代码里,其实最关键的有三个细节。
第一个是,在之前的对图片进行向量化的过程中,我们是将向量数据从 Tensor 类型数据使用 tolist 转换为 list 数据。
在这里,因为要进行 Redis 查询,我们需要将数据使用 tobytes 进行转换,如果我们将数据打印出来,大概是这样样子:
image_features: b'\xc7\n\x80>\xec\xd4+\xbfK\xee:\xbe\xd3\r\x10>\x8d\xe1\x80\xbeI\xed\xdd\xbef\xc5\xaf\xbd@*\x8f\xbd\xd8\x04\x8e>\x8e\xf32?V&\x04?\xf4P\xc0=O\xac\x07\xbe\xbc\xa5$>\xa9\xf6\xf0\xbe\xc9\xb7i>
...
...
...
>HG\xf4\xbc\xbfA\x8d>\x06\xfcL\xbdh\xe4\r\xbd\xc6\x9a\xaa\xbc\x99&E>\xe2Sn?w\xf6\xa0>M\x8d\x88?oa\x1d\xbeXO\xc6>\xa2\x10\x0c\xbe\xff\xd7\xfb='
第二个细节是我们需要在 query 中实现,关于 Redis 能够支持的搜索方式,在官方文档里有非常详细的记录,可以移步:
from redis.commands.search.query import Query...# 构建请求命令,查找和我们提供图片最相近的 30 张图片
query_vector = embeddings
query = (Query("(*)=>[KNN 30 @vector $query_vector AS vector_score]").sort_by("vector_score").return_fields("$").dialect(2)
)
最后,我们需要使用这个封装的函数,来获取我们找到的最接近的图片的名称(字段 ID),这主要借助了 Redis 的 commands/ft.search/:
# 定义一个查询函数,将我们查找的结果的 ID 打印出来(图片名称)
def dump_query(query, query_vector, extra_params={}):result_docs = (client.ft(vector_indexes_name).search(query,{"query_vector": query_vector}| extra_params,).docs)print(result_docs)for doc in result_docs:print(doc['id'])dump_query(query, query_vector, {})
当我们执行代码之后,将能够得到一串结果,包含了和我们提交查询图片最接近的图片:
...ball-8576.png
ball-8595.png
ball-8596.png
ball-8591.png
ball-8592.png
ball-8305.png
ball-8579.png
ball-8310.png
ball-8161.png
ball-2818.png>>>
>>> end = time.time()
>>> print('%s Seconds'%(end-start))
0.08090639114379883 Seconds
目前,我们还在设计第一阶段的程序,还没有方便用户使用的界面。所以,我们手动找到这些图片,来进行对比,看看程序通过模型找的图片像不像?

似乎还挺靠谱的嘛。
当然,这只是图片搜索引擎的一部分能力,下一篇文章,我们来探索更多的内容,包括实现图片搜索引擎中的第二个部分,用户交互流程部分。
最后
原本以为,我把上一篇文章单独拆出来之后,这篇文章一整篇就能把图片搜索引擎架构中,常见的两个主要部分都讲完,没想到还需要再拆一篇。
那么,下一篇文章见。
—EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
致新朋友:为生活投票,不断寻找更好的朋友
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年11月15日
统计字数: 20431字
阅读时间: 41分钟阅读
本文链接: https://soulteary.com/2023/11/15/use-redis-to-build-a-lightweight-vector-database-application-image-search-engine-part-1.html