Argoverse2数据集的导入
AV2数据集介绍:
一个用于自动驾驶域中感知和预测研究的三个数据集的集合。带标注的传感器数据集包含1000个多模态数据序列,包括来自七个环视摄像机和两个双目摄像机的高分辨率图像,以及激光雷达点云和6自由度地图配准位姿。序列包含26个目标类别的三维长方体标注,所有这些标注都是充分采样的,以支持训练和三维感知模型的评估。激光雷达数据集包含20,000个未标记的激光雷达点云序列和地图配准位姿。该数据集是有史以来最大的激光雷达传感器数据集合,支持自监督学习和新兴的点云预测任务。最后,运动预测数据集包含250,000个场景,挖掘每个场景中自车与其他参与者之间有趣和具有挑战性的交互。模型的任务是预测每个场景中scored actors的未来运动,并提供跟踪历史,捕捉目标的位置、航向、速度和类别。在所有三个数据集中,每个场景都包含自己的高精地图,带有3D车道和人行横道几何形状--来自六个不同城市的数据。
数据集下载地址:
argoverse/argoverse-api: Official GitHub repository for Argoverse dataset
下载后解压:
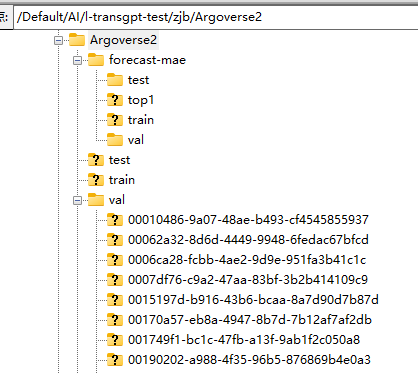
其中forecast-mae文件夹是通过forecast中的preprocess.py进行预处理得到的数据。
forecast-mae的地址是https://github.com/jchengai/forecast-mae.git
from argparse import ArgumentParser
from pathlib import Path
from typing import Listimport ray
from tqdm import tqdmfrom src.datamodule.av2_extractor import Av2Extractor
from src.utils.ray_utils import ActorHandle, ProgressBar#不要超过CPU核心数
ray.init(num_cpus=16)def glob_files(data_root: Path, mode: str):file_root = data_root / modescenario_files = list(file_root.rglob("*.parquet")) #使用rglob方法遍历指定文件夹及其子文件夹下的所有文件,寻找扩展名为.parquet的文件,并将它们的路径存储在scenario_files列表中。return scenario_files@ray.remote
def preprocess_batch(extractor: Av2Extractor, file_list: List[Path], pb: ActorHandle):for file in file_list:extractor.save(file)pb.update.remote(1)def preprocess(args):batch = args.batchdata_root = Path(args.data_root)for mode in ["train", "val", "test"]:save_dir = data_root / "forecast-mae" / modesave_dir.mkdir(exist_ok=True, parents=True)extractor = Av2Extractor(save_path=save_dir, mode=mode)scenario_files = glob_files(data_root, mode)if args.parallel:pb = ProgressBar(len(scenario_files), f"preprocess {mode}-set")pb_actor = pb.actorfor i in range(0, len(scenario_files), batch):preprocess_batch.remote(extractor, scenario_files[i : i + batch], pb_actor)pb.print_until_done()else:for file in tqdm(scenario_files):extractor.save(file) #把轨迹文件*.parquet存储为.pt文件if __name__ == "__main__":parser = ArgumentParser()parser.add_argument("--data_root", "-d", type=str, required=True)parser.add_argument("--batch", "-b", type=int, default=50)parser.add_argument("--parallel", "-p", action="store_true")args = parser.parse_args()preprocess(args)
下载AV2数据集的相关包,请文后本文绑定的资源下载。

然后如何读取数据呢,请看
from datetime import datetime
import os
import hydra
import random
import math
from hydra.utils import instantiateimport numpy as np
import torch
from src.datamodule.av2_datamodule import Av2DataModule
from arguments import get_argsdef main(conf):av2datamoudle=Av2DataModule(data_root="/home/user/Argoverse2",data_folder="forecast-mae",train_batch_size=32,val_batch_size=32,test_batch_size=32,shuffle=True,num_workers=8,pin_memory=True,)av2datamoudle.setup()train_sdata_loader = av2datamoudle.train_dataloader()passfor i, data in enumerate(train_sdata_loader):passif __name__ == "__main__":main()这样即可