基于LLaMA-Factory的微调记录
文章目录
- 数据模型准备
- 基于网页的简单微调
- 基于网页的简单评测
- 基于网页的简单聊天
- 基于网页的模型合并
- 微调问题测试与解决
- 问题测试
- 模板修改
- 强化训练
LLaMA-Factory是一个非常好用的无代码微调框架,不管是在模型、微调方式还是参数设置上都提供了非常完备的支持,下面是对微调全过程的一个记录。
数据模型准备
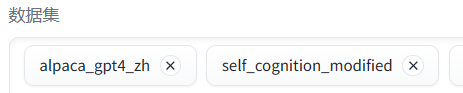
微调时一般需要准备三个数据集:一个是自我认知数据集(让大模型知道自己是谁),一个是特定任务数据集(微调时需要完成的目标任务),一个是通用任务数据集(保持大模型的通用能力,防止变傻)。前两个一般要自己定义,最后一个用现成的就行。
自定义数据集可采用alpaca和sharegpt格式,这里采用的是alpaca格式:
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
由于不需要考虑多轮对话,所以history可以不要,这里采用了两种数据集的组织方式,一种是只有instruction和output,把问题作为instruction,另外一种是把问题作为input,把回答问题这一要求作为instruction。这两种格式分别记为format2和format3。
在生成完自定义的问答json文件之后,根据以下代码计算其sha1值:
import hashlibdef calculate_sha1(file_path):sha1 = hashlib.sha1()try:with open(file_path, 'rb') as file:while True:data = file.read(8192) # Read in chunks to handle large filesif not data:breaksha1.update(data)return sha1.hexdigest()except FileNotFoundError:return "File not found."# 使用示例
file_path = './data/self_cognition_modified.json' # 替换为您的文件路径
sha1_hash = calculate_sha1(file_path)
print("SHA-1 Hash:", sha1_hash)
将json文件放入data文件夹下,同步修改dataset_info.json文件,输入新增的文件名称和对应的sha1值。
测试的大模型可以使用这些,注意要下载最新版,老版的模型结构不太匹配。
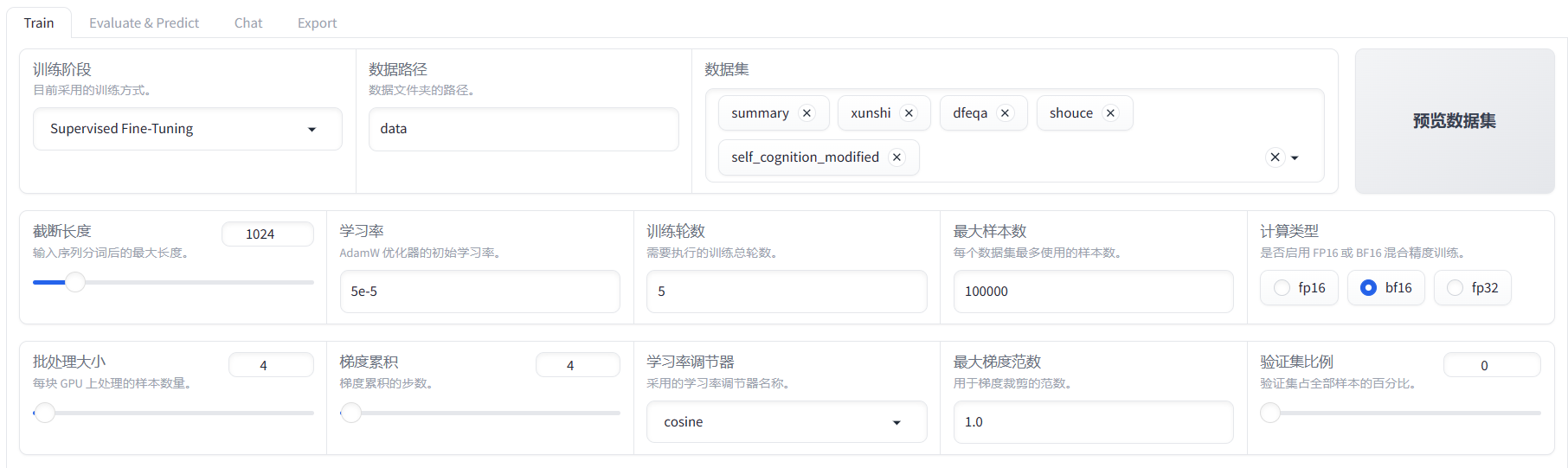
基于网页的简单微调
在后台执行CUDA_VISIBLE_DEVICES=0 python src/train_web.py命令,成功开启网页,设置如下,手动输入模型路径。

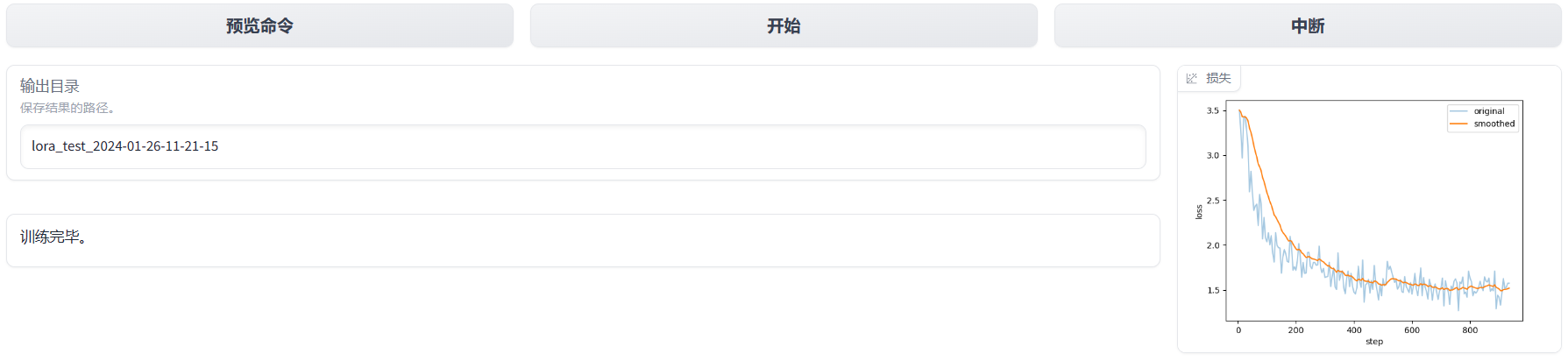
训练完成之后的界面,可以查看损失函数
基于网页的简单评测
- 原始模型评测
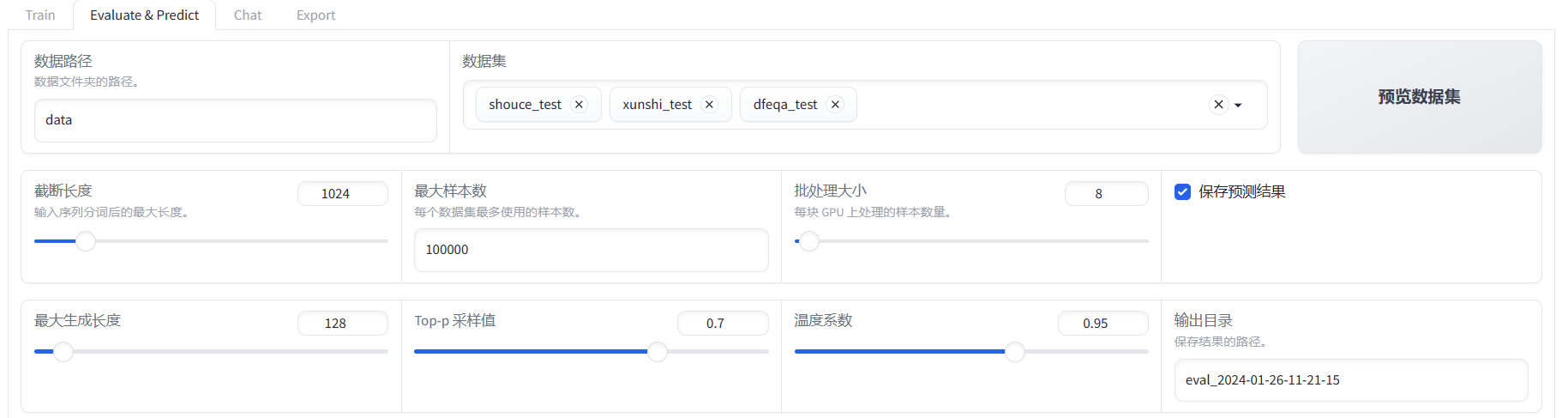
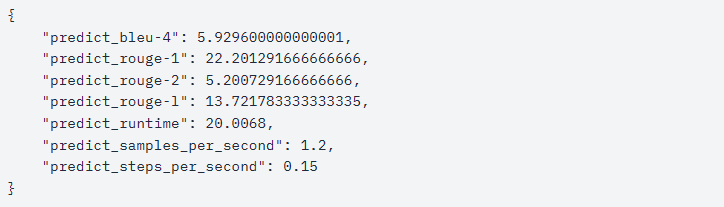
- 微调后模型评测
首先加载lora

可以看到,微调之后的模型在各个指标上有了显著提升
基于网页的简单聊天
切换到Chat并点击加载模型后,可以进入聊天
基于网页的模型合并
把lora的权重合并到原始模型中
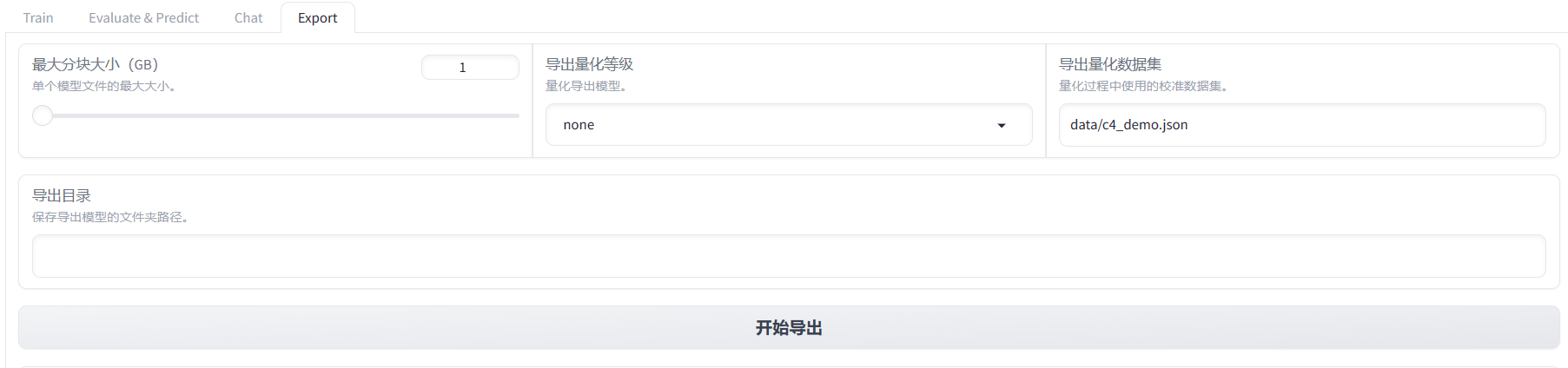
微调问题测试与解决
问题测试
虽然在评估时看着分数挺高,但实际使用起来,问题还是挺大的:
- 自我认知无法更新

- 专业问题答不上来
这是训练集中的一条数据

这是无lora的情况:
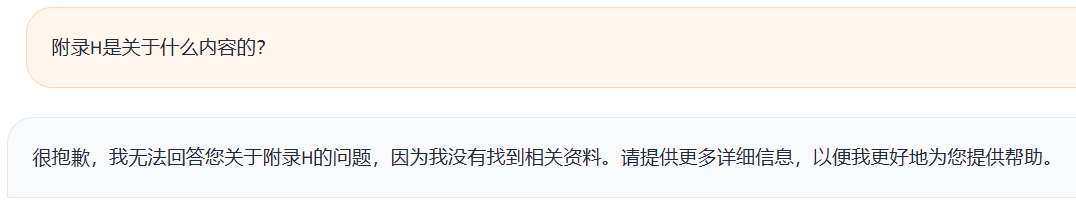
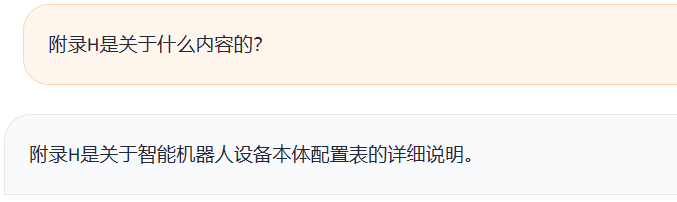
这是带lora的情况:
模板修改
ChatGLM之所以一口咬定自己是智谱开发的,主要原因是有个系统提示词,打开src/llmtuner/data/template.py文件,将以下部分删除

强化训练
为了让大模型学习更深入,补充通用数据集,增加学习率和epoch,再来一次微调