【Java并发】聊聊Disruptor背后高性能的原理
为什么需要Disruptor
对于单机生产者消费者来说,JUC本身提供了阻塞队列,ArrayBlockingQueue、LinkedBlockingQueue 等,但是为了保证数据安全,使用了reentrantLock进行加锁操作会影响性能,另一方面,本身如果生产者生产数据过快会导致,内存溢出问题。以及采用数据实现会有伪共享问题。
Disruptor 原理和应用场景
那么Disruptor是如何进行设计的?
- 环形数组结构
- 元素位置定位
- 无锁设计
- 利用缓存行填充解决伪共享问题
- 实现了基于事件驱动的生产者消费者模型(观察者模式)
RingBuffer数据结构
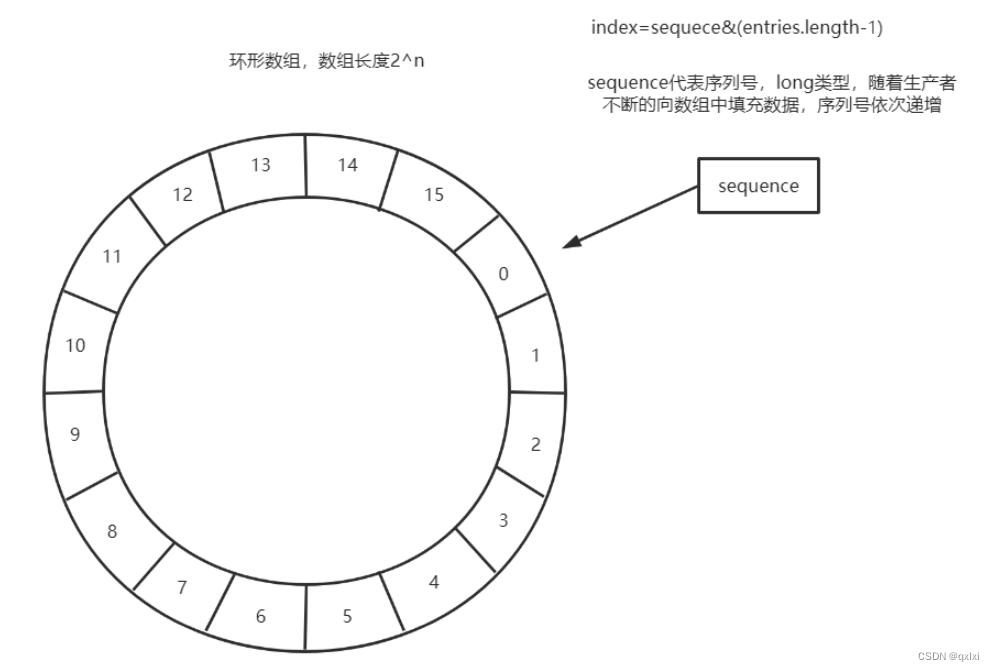
唤醒数组其实就是一个自定义大小的环形数组,有一个序列号 sequence 用以指向下一个可用的元素,需要保证数组的长度必须是2的N次幂,这样就可以通过sequence % length 或者 通过 sequence &(length -1) 可以直接获取到下标位置。其实hashmap也是同样的原理。
那么当环形数组数据满之后,就会覆盖0号位置,具体使用什么策略。提供了4种。
- BlockingWaitStrategy:不覆盖数据,等待
- SleepingWaitStrategy
- YieldingWaitStrategy
- BusySpinWaitStrategy
这里了解即可,用到的时候 在查
缓存行
abstract class RingBufferPad
{protected long p1, p2, p3, p4, p5, p6, p7;
}abstract class RingBufferFields<E> extends RingBufferPad
{......
}public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;protected long p1, p2, p3, p4, p5, p6, p7;......
刚开始看 发现什么 写一堆这些px 有什么用,其实是充分利用计算机cpu core 的 cache。利用填充行填充。比如我们定义了一个10个长度的long数组,不同一个元素一个元素从内存加载搭配CPU cache的。而是一次性固定加载整个缓存行。
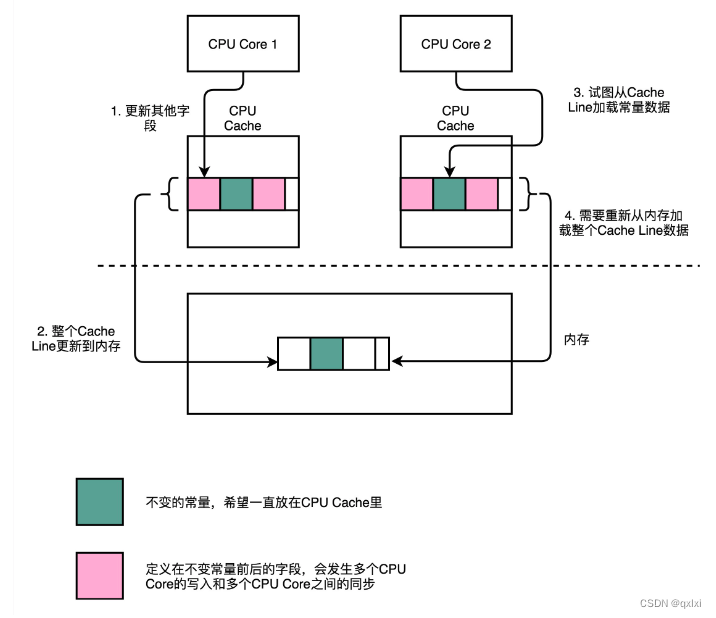
所以如果只是一个单独的long 变量,可能在多个线程操作下,前后的变量,可能来回的回写和加载,不断的导致INITIAL_CURSOR_VALUE 从内存到 CPU cache,为了防止,所以在前后 添加7个long 类型变量。就会一只在CPU cache中。
无锁的并发-生产者=消费者模型
其实我们可以通过一个数组模拟出一个生产者消费者模型,但是这种方式在单生产者单消费者的情况下,其实没有问题,在多线程情况下,其实没有办法解决,需要加锁的方式,但是加锁的话,其实从一定程度上降低了系统的整体性能,比如说 ArrayBlockingQueue 中 添加元素和获取元素 都是通过lock的方式加锁。
public boolean offer(E e) {checkNotNull(e);final ReentrantLock lock = this.lock;lock.lock();try {if (count == items.length)return false;else {enqueue(e);return true;}} finally {lock.unlock();}}public E peek() {final ReentrantLock lock = this.lock;lock.lock();try {return itemAt(takeIndex); // null when queue is empty} finally {lock.unlock();}}
那么Disruptor是如何实现的?
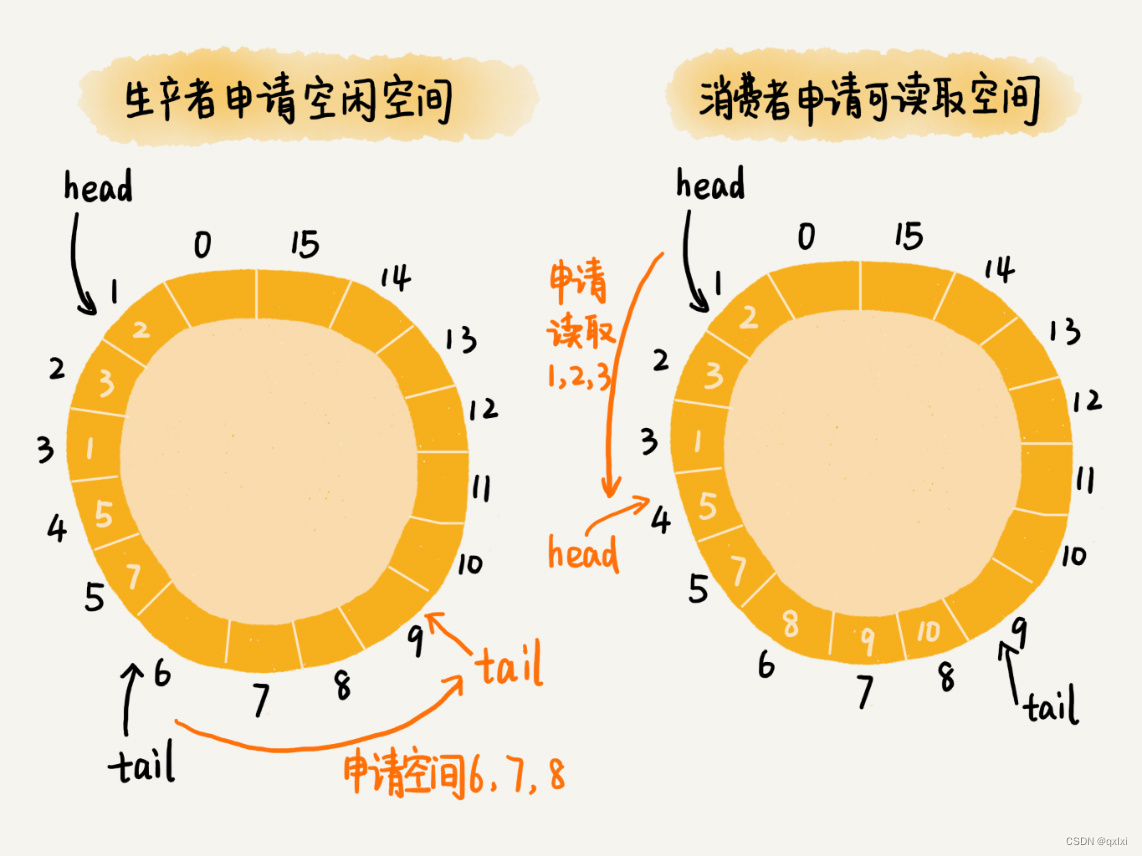
对生产者来说: 往队列中添加数据之前,可以先申请可用空闲存储单元,并且是批量申请连续N个单元,申请之后,后续就不用往队列中添加元素,不用加锁。并且申请的存储单元是这个线程独享的。不过申请存储单元的过程需要加锁。
对于消费者来说:也是一次获取多个可读的范围,申请一批连续可读的存储单元。
比如对于 生产者A申请到一组连续的存储单元,3到6,生产者B申请到7到9的存储单元。那么在3到6没有完全写入数据之前,7到9是没有办法读取。这是一个弊端。
Code
构建数据
/*** @author qxlx* @date 2024/1/29 22:39*/
public class Data {private String uid;public String getUid() {return uid;}public void setUid(String uid) {this.uid = uid;}
}
生产者
public class EventProducer {private RingBuffer<Data> ringBuffer;public EventProducer(RingBuffer<Data> ringBuffer) {this.ringBuffer = ringBuffer;}public void send(long value,String name) {long next = ringBuffer.next();Data data = ringBuffer.get(next);// 写入消息数据data.setUid(name);//发布事件ringBuffer.publish(next);}}
数据工厂
public class OrderEventFactory implements EventFactory<Data> {@Overridepublic Data newInstance() {return new Data();}
}
消费者
public class EventHanderConsumer implements EventHandler<Data> {@Overridepublic void onEvent(Data data, long l, boolean b) throws Exception {System.out.println("消费者获取数据"+data.getUid());}
}
public static void main(String[] args) {// 构建disruptor对象 Disruptor<Data> disruptor = new Disruptor<Data>(new OrderEventFactory(),1024 * 1024,Executors.defaultThreadFactory(),ProducerType.SINGLE,new YieldingWaitStrategy() //等待策略);// 消费者disruptor.handleEventsWith((EventHandler<? super Data>) new EventHanderConsumer());// 启动disruptor.start();// 生产数据RingBuffer<Data> ringBuffer = disruptor.getRingBuffer();EventProducer eventProducer = new EventProducer(ringBuffer);for (int i = 0; i < 100; i++) {eventProducer.send(1,"fix"+i);}}
应用场景
在实际的应用场景中,比如我们分库分表,user表有8个子表。那么如何保证每个子表生产的uid是固定增长的。一种方式是使用分布式id 雪花算法,另一种方式则可以通过将每个子表的id 每次都+8。比如表1的id是从1 9。表二 从2 10 这样就可以通过固定的步长确定。
好了本篇其实主要简单介绍了其核心原理,具体的大家可以看源代码。
推荐阅读:https://tech.meituan.com/2016/11/18/disruptor.html