爬虫实战--人民网
文章目录
- 前言
- 发现宝藏
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
http://jhsjk.people.cn/testnew/result
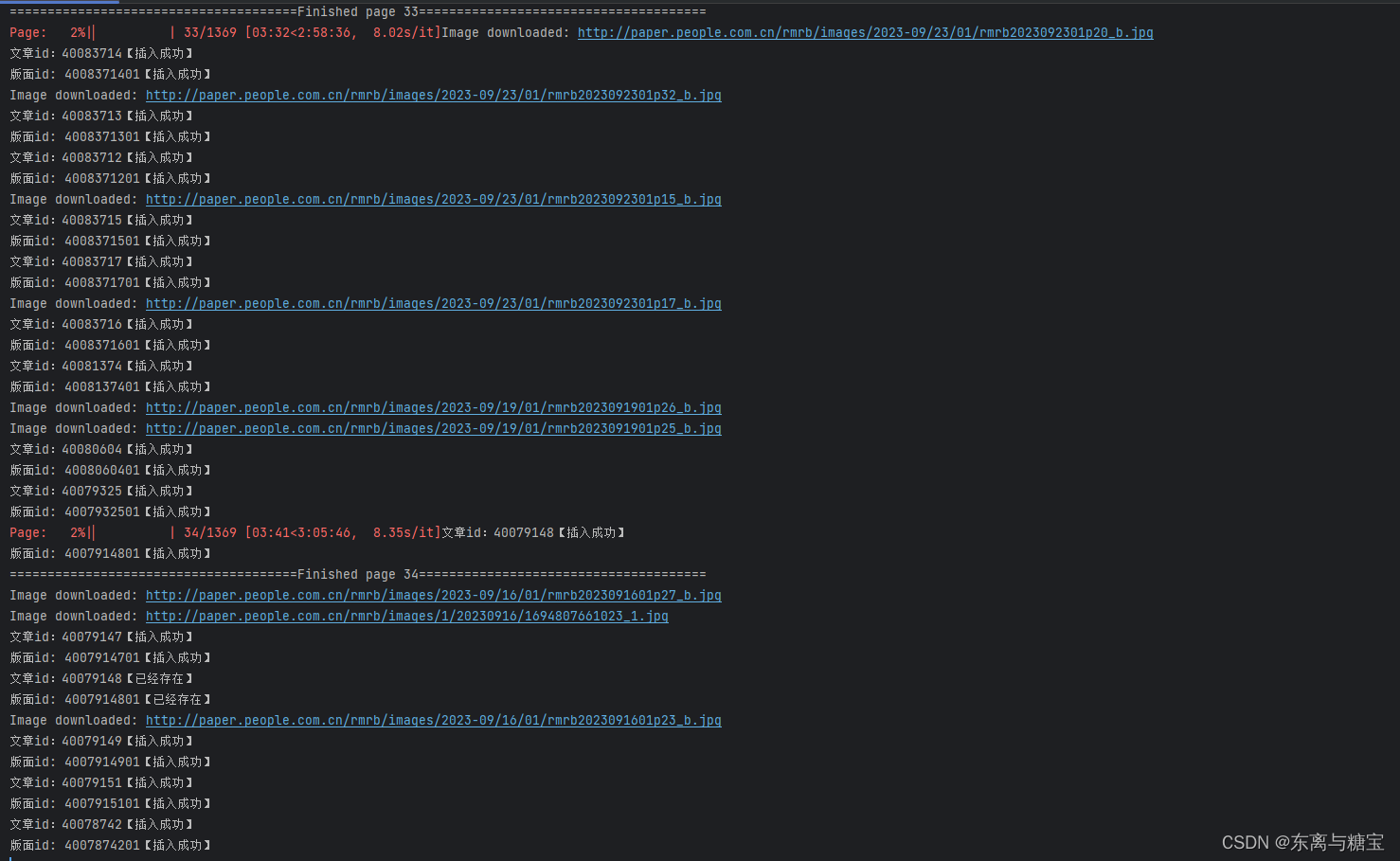
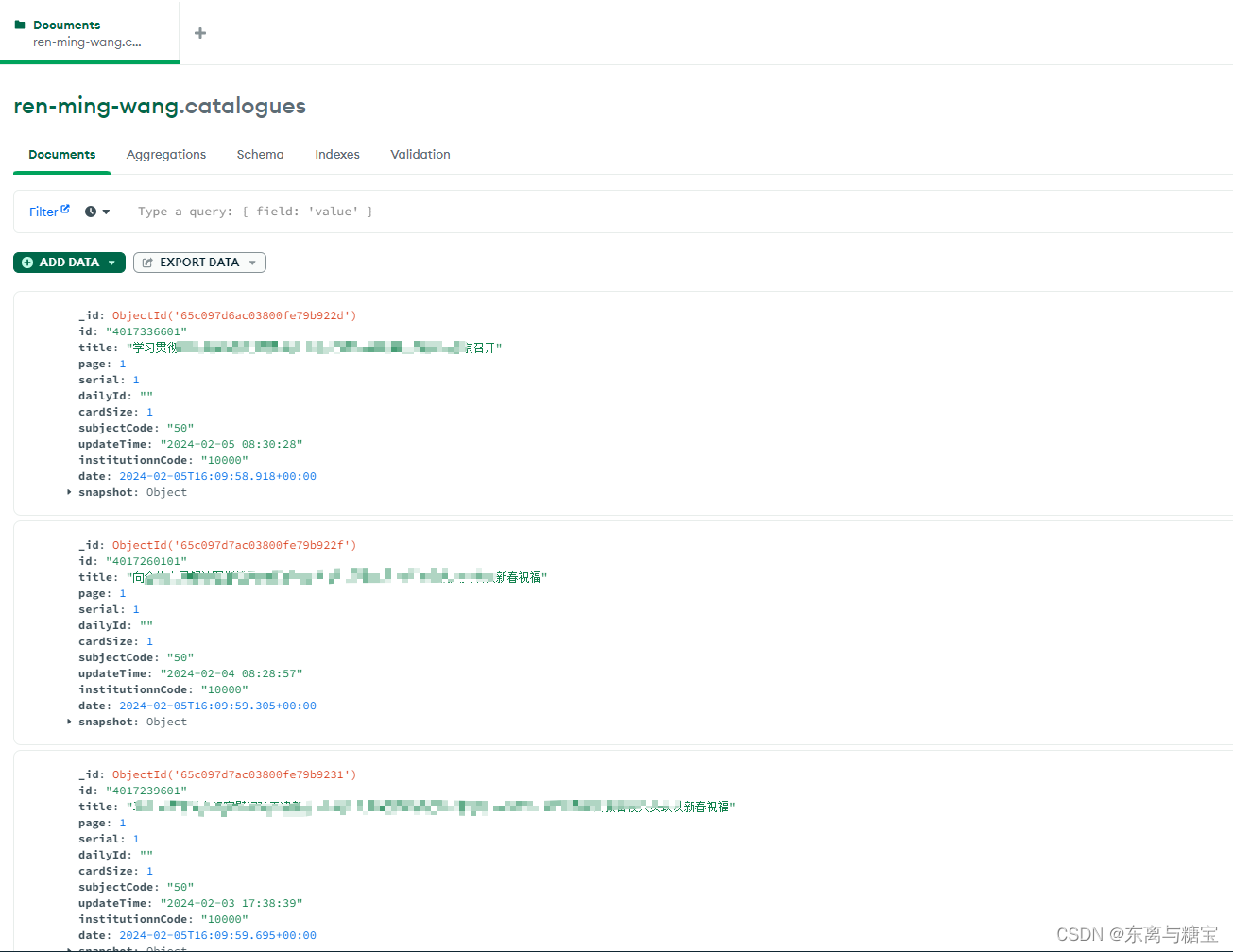
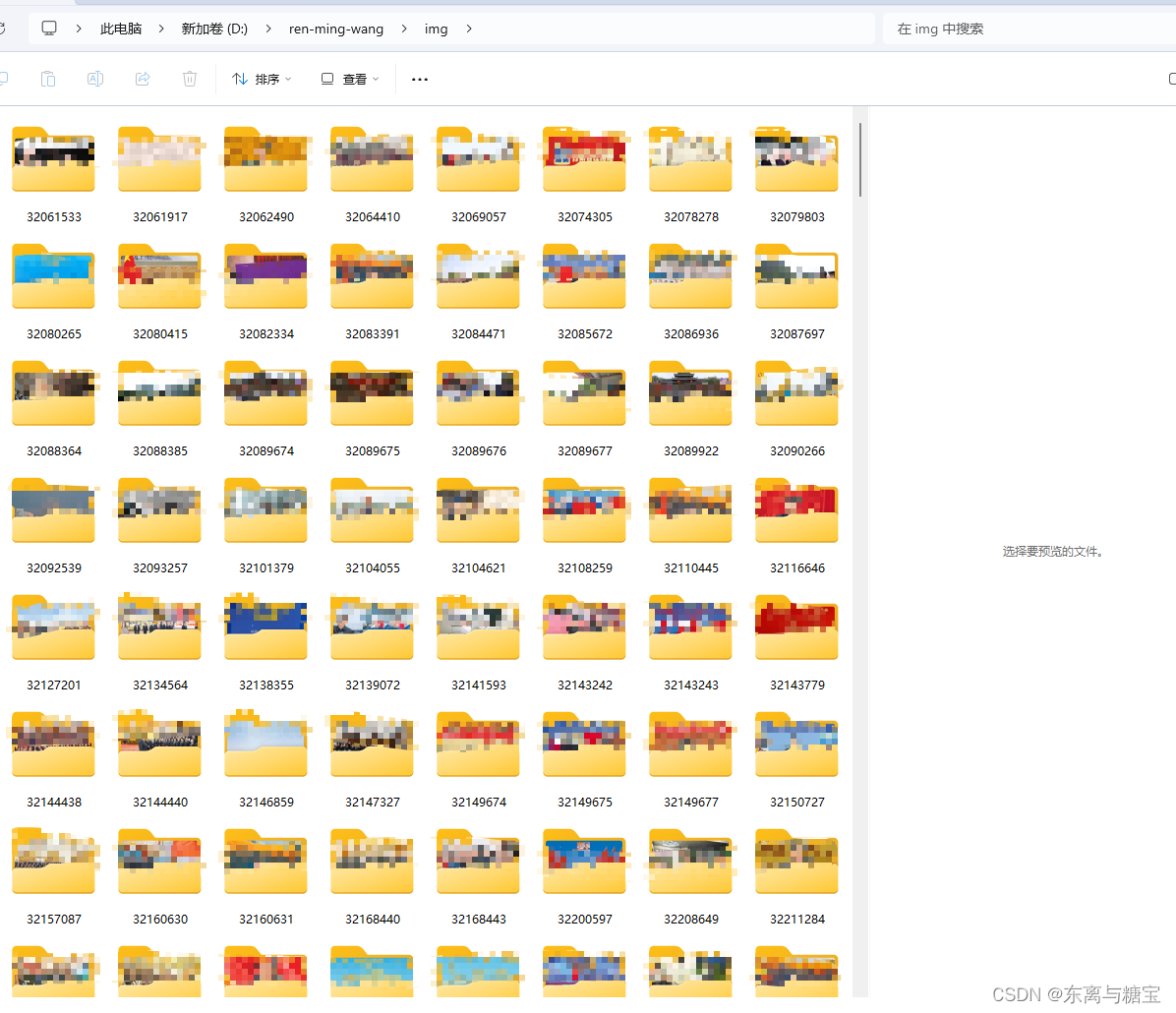
import os
import re
from datetime import datetime
import requests
import json
from bs4 import BeautifulSoup
from pymongo import MongoClient
from tqdm import tqdmclass ArticleCrawler:def __init__(self, catalogues_url, card_root_url, output_dir, db_name='ren-ming-wang'):self.catalogues_url = catalogues_urlself.card_root_url = card_root_urlself.output_dir = output_dirself.client = MongoClient('mongodb://localhost:27017/')self.db = self.client[db_name]self.catalogues = self.db['catalogues']self.cards = self.db['cards']self.headers = {'Referer': 'https://jhsjk.people.cn/result?','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/119.0.0.0 Safari/537.36','Cookie': '替换成你自己的',}# 发送带参数的get请求并获取页面内容def fetch_page(self, url, page):params = {'keywords': '','isFuzzy': '0','searchArea': '0','year': '0','form': '','type': '0','page': page,'origin': '全部','source': '2',}response = requests.get(url, params=params, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')return soup# 解析请求版面def parse_catalogues(self, json_catalogues):card_list = json_catalogues['list']for list in card_list:a_tag = 'article/'+list['article_id']card_url = self.card_root_url + a_tagcard_title = list['title']updateTime = list['input_date']self.parse_cards(card_url, updateTime)date = datetime.now()catalogues_id = list['article_id']+'01'# 检查重复标题existing_docs = self.catalogues.find_one({'id': catalogues_id})if existing_docs is not None:print(f'版面id: {catalogues_id}【已经存在】')continuecard_data = {'id': catalogues_id,'title': card_title,'page': 1,'serial': 1,# 一个版面一个文章'dailyId': '','cardSize': 1,'subjectCode': '50','updateTime': updateTime,'institutionnCode': '10000','date': date,'snapshot': {}}self.catalogues.insert_one(card_data)print(f'版面id: {catalogues_id}【插入成功】')# 解析请求文章def parse_cards(self, url, updateTime):response = requests.get(url, headers=self.headers)soup = BeautifulSoup(response.text, "html.parser")try:title = soup.find("div", "d2txt clearfix").find('h1').textexcept:try:title = soup.find('h1').textexcept:print(f'【无法解析该文章标题】{url}')html_content = soup.find('div', 'd2txt_con clearfix')text = html_content.get_text()imgs = [img.get('src') or img.get('data-src') for img in html_content.find_all('img')]cleaned_content = self.clean_content(text)# 假设我们有一个正则表达式匹配对象matchmatch = re.search(r'\d+', url)# 获取匹配的字符串card_id = match.group()date = datetime.now()if len(imgs) != 0:# 下载图片self.download_images(imgs, card_id)# 创建文档document = {'id': card_id,'serial': 1,'page': 1,'url' : url,'type': 'ren-ming-wang','catalogueId': card_id + '01','subjectCode': '50','institutionCode': '10000','updateTime': updateTime,'flag': 'true','date': date,'title': title,'illustrations': imgs,'html_content': str(html_content),'content': cleaned_content}# 检查重复标题existing_docs = self.cards.find_one({'id': card_id})if existing_docs is None:# 插入文档self.cards.insert_one(document)print(f"文章id:{card_id}【插入成功】")else:print(f"文章id:{card_id}【已经存在】")# 文章数据清洗def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)# content = re.sub(r'\n', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return content# 下载图片def download_images(self, img_urls, card_id):# 根据card_id创建一个新的子目录images_dir = os.path.join(self.output_dir, card_id)if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for img_url in img_urls:try:response = requests.get(img_url, stream=True)if response.status_code == 200:# 从URL中提取图片文件名image_name = os.path.join(images_dir, img_url.split('/')[-1])# 确保文件名不重复if os.path.exists(image_name):continuewith open(image_name, 'wb') as f:f.write(response.content)downloaded_images.append(image_name)print(f"Image downloaded: {img_url}")except Exception as e:print(f"Failed to download image {img_url}. Error: {e}")return downloaded_images# 如果文件夹存在则跳过else:print(f'文章id为{card_id}的图片文件夹已经存在')# 查找共有多少页def find_page_all(self, soup):# 查找<em>标签em_tag = soup.find('em', onclick=True)# 从onclick属性中提取页码if em_tag and 'onclick' in em_tag.attrs:onclick_value = em_tag['onclick']page_number = int(onclick_value.split('(')[1].split(')')[0])return page_numberelse:print('找不到总共有多少页数据')# 关闭与MongoDB的连接def close_connection(self):self.client.close()# 执行爬虫,循环获取多页版面及文章并存储def run(self):soup_catalogue = self.fetch_page(self.catalogues_url, 1)page_all = self.find_page_all(soup_catalogue)if page_all:for index in tqdm(range(1, page_all), desc='Page'):# for index in tqdm(range(1, 50), desc='Page'):soup_catalogues = self.fetch_page(self.catalogues_url, index).text# 解析JSON数据soup_catalogues_json = json.loads(soup_catalogues)self.parse_catalogues(soup_catalogues_json)print(f'======================================Finished page {index}======================================')self.close_connection()if __name__ == "__main__":crawler = ArticleCrawler(catalogues_url='http://jhsjk.people.cn/testnew/result',card_root_url='http://jhsjk.people.cn/',output_dir='D:\\ren-ming-wang\\img')crawler.run() # 运行爬虫,搜索所有内容crawler.close_connection() # 关闭数据库连接