[ai笔记9] openAI Sora技术文档引用文献汇总
欢迎来到文思源想的ai空间,这是技术老兵重学ai以及成长思考的第9篇分享!
这篇笔记承接上一篇技术文档的学习,主要是为了做一个记录,记录下openai sora技术介绍文档提到的一些论文,再此特地记录一下!
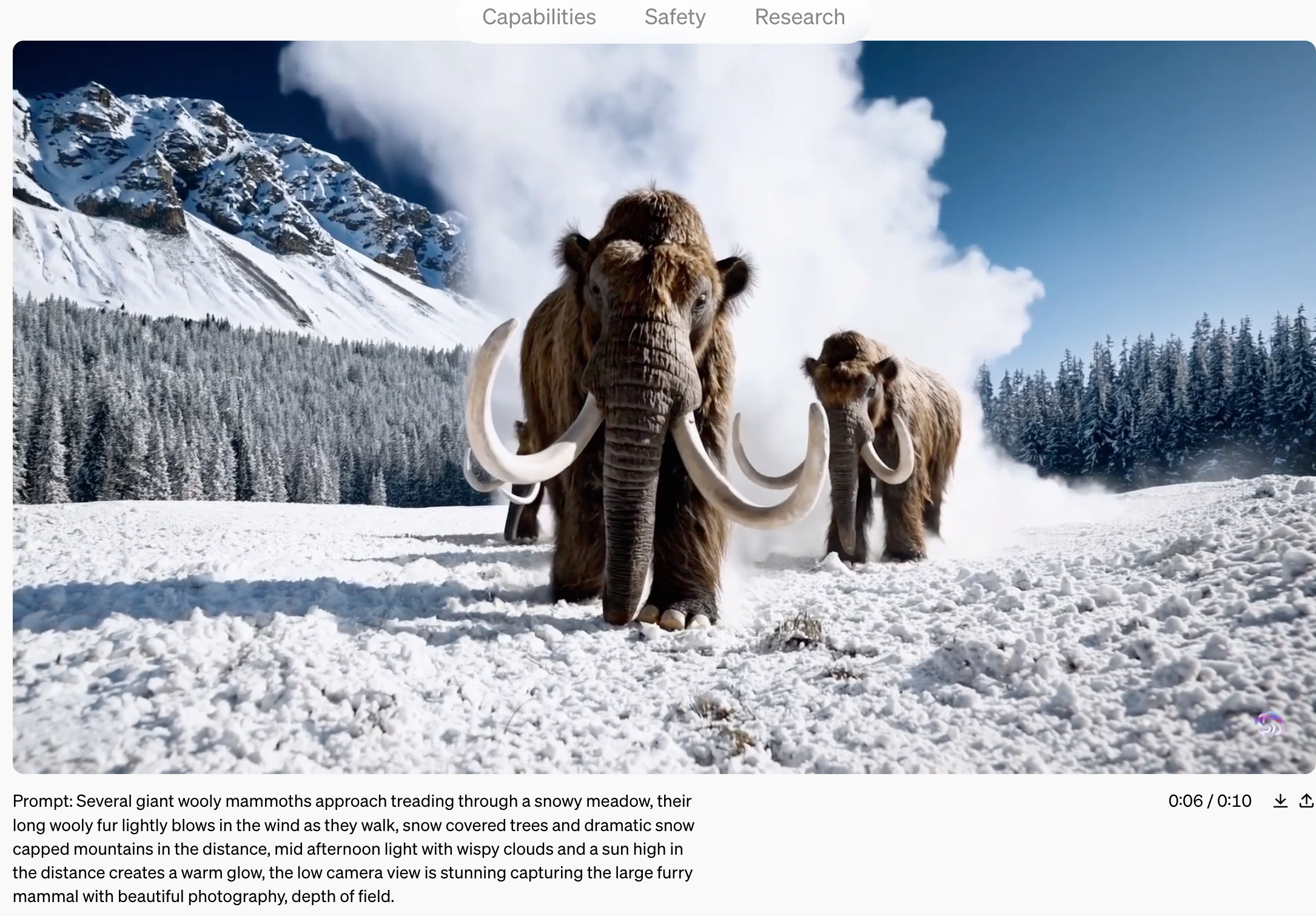
1 原文引用文献汇总
- Chiappa, Silvia, et al. "Recurrent environment simulators." arXiv preprint arXiv:1704.02254 (2017).↩︎
- Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).↩︎
- Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. "Generating videos with scene dynamics." Advances in neural information processing systems 29 (2016).↩︎
- Tulyakov, Sergey, et al. "Mocogan: Decomposing motion and content for video generation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.↩︎
- Clark, Aidan, Jeff Donahue, and Karen Simonyan. "Adversarial video generation on complex datasets." arXiv preprint arXiv:1907.06571 (2019).↩︎
- Brooks, Tim, et al. "Generating long videos of dynamic scenes." Advances in Neural Information Processing Systems 35 (2022): 31769-31781.↩︎
- Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).↩︎
- Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.↩︎
- Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).↩︎
- Blattmann, Andreas, et al. "Align your latents: High-resolution video synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.↩︎
- Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).↩︎
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).↩︎↩︎
- Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.↩︎↩︎
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).↩︎↩︎
- Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.↩︎↩︎
- He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎↩︎
- Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).↩︎↩︎
- Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎
- Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).↩︎
- Sohl-Dickstein, Jascha, et al. "Deep unsupervised learning using nonequilibrium thermodynamics." International conference on machine learning. PMLR, 2015.↩︎
- Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.↩︎
- Nichol, Alexander Quinn, and Prafulla Dhariwal. "Improved denoising diffusion probabilistic models." International Conference on Machine Learning. PMLR, 2021.↩︎
- Dhariwal, Prafulla, and Alexander Quinn Nichol. "Diffusion Models Beat GANs on Image Synthesis." Advances in Neural Information Processing Systems. 2021.↩︎
- Karras, Tero, et al. "Elucidating the design space of diffusion-based generative models." Advances in Neural Information Processing Systems 35 (2022): 26565-26577.↩︎
- Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.↩︎
- Chen, Mark, et al. "Generative pretraining from pixels." International conference on machine learning. PMLR, 2020.↩︎
- Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International Conference on Machine Learning. PMLR, 2021.↩︎
- Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022): 5.↩︎
- Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8↩︎↩︎
- Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.↩︎
- Meng, Chenlin, et al. "Sdedit: Guided image synthesis and editing with stochastic differential equations." arXiv preprint arXiv:2108.01073 (2021).↩︎
2 原文引用文献翻译
- Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. "Unsupervised learning of video representations using lstms." International conference on machine learning. PMLR, 2015.↩︎斯里瓦斯塔瓦、尼蒂什、埃尔曼·曼西莫夫和鲁斯兰·萨拉胡迪诺夫。 “使用 lstms 进行视频表示的无监督学习。”机器学习国际会议。 PMLR,2015。↩︎
- Chiappa, Silvia, et al. "Recurrent environment simulators." arXiv preprint arXiv:1704.02254 (2017).↩︎奇亚帕、西尔维娅等人。 “循环环境模拟器。” arXiv 预印本 arXiv:1704.02254 (2017).↩︎
- Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).↩︎哈,大卫和尤尔根·施米德胡贝尔。 “世界模特。” arXiv 预印本 arXiv:1803.10122 (2018).↩︎
- Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. "Generating videos with scene dynamics." Advances in neural information processing systems 29 (2016).↩︎冯德里克、卡尔、哈米德·皮尔西亚瓦什和安东尼奥·托拉尔巴。 “生成具有场景动态的视频。”神经信息处理系统的进展29 (2016).↩︎
- Tulyakov, Sergey, et al. "Mocogan: Decomposing motion and content for video generation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.↩︎图利亚科夫,谢尔盖,等人。 “Mocogan:分解运动和内容以生成视频。” IEEE 计算机视觉和模式识别会议论文集。 2018.↩︎
- Clark, Aidan, Jeff Donahue, and Karen Simonyan. "Adversarial video generation on complex datasets." arXiv preprint arXiv:1907.06571 (2019).↩︎克拉克、艾丹、杰夫·多纳休和凯伦·西蒙尼安。 “复杂数据集上的对抗性视频生成。” arXiv 预印本 arXiv:1907.06571 (2019).↩︎
- Brooks, Tim, et al. "Generating long videos of dynamic scenes." Advances in Neural Information Processing Systems 35 (2022): 31769-31781.↩︎布鲁克斯、蒂姆等人。 “生成动态场景的长视频。”神经信息处理系统进展 35 (2022): 31769-31781.↩︎
- Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).↩︎严,威尔逊,等人。 “Videogpt:使用 vq-vae 和 Transformer 生成视频。” arXiv 预印本 arXiv:2104.10157 (2021).↩︎
- Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.↩︎吴晨飞,等。 “女娲:神经视觉世界创建的视觉合成预训练。”欧洲计算机视觉会议。 Cham:施普林格自然瑞士,2022。↩︎
- Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).↩︎何乔纳森等人。 “Imagen 视频:使用扩散模型生成高清视频。” arXiv 预印本 arXiv:2210.02303 (2022).↩︎
- Blattmann, Andreas, et al. "Align your latents: High-resolution video synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.↩︎布拉特曼、安德烈亚斯等人。 “对齐你的潜在特征:高分辨率视频合成与潜在扩散模型。” IEEE/CVF 计算机视觉和模式识别会议论文集。 2023.↩︎
- Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).↩︎古普塔、阿格里姆等人。 “使用扩散模型生成逼真的视频。” arXiv 预印本 arXiv:2312.06662 (2023).↩︎
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).↩︎↩︎瓦斯瓦尼、阿什什等人。 “你所需要的就是注意力。”神经信息处理系统进展30 (2017).↩︎↩︎
- Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.↩︎↩︎布朗、汤姆等人。 “语言模型是小样本学习者。”神经信息处理系统的进展33(2020):1877-1901。↩︎↩︎
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).↩︎↩︎多索维茨基,阿列克谢,等人。 “一张图像相当于 16x16 个单词:用于大规模图像识别的 Transformer。” arXiv 预印本 arXiv:2010.11929 (2020).↩︎↩︎
- Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.↩︎↩︎阿纳布、阿努拉格等人。 “Vivit:视频视觉转换器。” IEEE/CVF 计算机视觉国际会议论文集。 2021.↩︎↩︎
- He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎↩︎他,凯明,等人。 “蒙面自动编码器是可扩展的视觉学习器。” IEEE/CVF 计算机视觉和模式识别会议论文集。 2022.↩︎↩︎
- Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).↩︎↩︎德加尼、穆斯塔法等人。 “Patch n'Pack:NaViT,适用于任何宽高比和分辨率的视觉转换器。” arXiv 预印本 arXiv:2307.06304 (2023).↩︎↩︎
- Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎罗姆巴赫、罗宾等人。 “利用潜在扩散模型进行高分辨率图像合成。” IEEE/CVF 计算机视觉和模式识别会议论文集。 2022.↩︎
- Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).↩︎Kingma、Diederik P. 和马克斯·威灵。 “自动编码变分贝叶斯。” arXiv 预印本 arXiv:1312.6114 (2013).↩︎
- Sohl-Dickstein, Jascha, et al. "Deep unsupervised learning using nonequilibrium thermodynamics." International conference on machine learning. PMLR, 2015.↩︎索尔-迪克斯坦、贾沙等人。 “利用非平衡热力学进行深度无监督学习。”机器学习国际会议。 PMLR,2015。↩︎
- Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.↩︎何乔纳森、阿杰·贾恩和彼得·阿贝尔。 “去噪扩散概率模型。”神经信息处理系统进展33(2020): 6840-6851.↩︎
- Nichol, Alexander Quinn, and Prafulla Dhariwal. "Improved denoising diffusion probabilistic models." International Conference on Machine Learning. PMLR, 2021.↩︎尼科尔、亚历山大·奎因和普拉富拉·达里瓦尔。 “改进的去噪扩散概率模型。”国际机器学习会议。 PMLR,2021。↩︎
- Dhariwal, Prafulla, and Alexander Quinn Nichol. "Diffusion Models Beat GANs on Image Synthesis." Advances in Neural Information Processing Systems. 2021.↩︎达里瓦尔、普拉富拉和亚历山大·奎因·尼科尔。 “扩散模型在图像合成方面击败了 GAN。”神经信息处理系统的进展。 2021.↩︎
- Karras, Tero, et al. "Elucidating the design space of diffusion-based generative models." Advances in Neural Information Processing Systems 35 (2022): 26565-26577.↩︎卡拉斯、泰罗等人。 “阐明基于扩散的生成模型的设计空间。”神经信息处理系统的进展 35 (2022): 26565-26577.↩︎
- Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.↩︎皮布尔斯、威廉和谢赛宁。 “带有变压器的可扩展扩散模型。” IEEE/CVF 国际计算机视觉会议论文集。 2023.↩︎
- Chen, Mark, et al. "Generative pretraining from pixels." International conference on machine learning. PMLR, 2020.↩︎陈、马克等人。 “从像素进行生成预训练。”机器学习国际会议。 PMLR,2020。↩︎
- Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International Conference on Machine Learning. PMLR, 2021.↩︎拉梅什、阿迪亚等人。 “零镜头文本到图像生成。”国际机器学习会议。 PMLR,2021。↩︎
- Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022): 5.↩︎于家辉,等。 “扩展自回归模型以生成内容丰富的文本到图像。” arXiv 预印本 arXiv:2206.10789 2.3 (2022): 5.↩︎
- Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8↩︎↩︎贝特克、詹姆斯等人。 “通过更好的字幕改进图像生成。”计算机科学。 https://cdn.openai.com/papers/dall-e-3。 pdf 2.3 (2023): 8↩︎↩︎
- Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.↩︎拉梅什、阿迪亚等人。 “具有剪辑潜在特征的分层文本条件图像生成。” arXiv 预印本 arXiv:2204.06125 1.2 (2022): 3.↩︎
- Meng, Chenlin, et al. "Sdedit: Guided image synthesis and editing with stochastic differential equations." arXiv preprint arXiv:2108.01073 (2021).↩︎孟陈林,等。 “Sdedit:使用随机微分方程引导图像合成和编辑。” arXiv 预印本 arXiv:2108.01073 (2021).↩︎