ChatGPT在数据处理中的应用
ChatGPT在数据处理中的应用
今天的这篇文章,让我不断体会AI的强大,愿人类社会在AI的助力下走向更加灿烂辉煌的明天。
扫描下面二维码注册

数据处理是贯穿整个数据分析过程的关键步骤,主要是对数据进行各种操作,以达到最终的分析目的。数据处理主要包括以下几部分。
1.1 概览数据
接下来的操作基于示例表的样例数据展开。这是一个简短的订单明细表,包含订单ID、用户ID、产品ID、订单日期、用户性别、用户年龄这几列。我们先对这份数据进行概览。
| 订单ID | 用户ID | 产品ID | 订单日期 | 用户性别 | 用户年龄 |
|---|---|---|---|---|---|
| 1001 | 101 | 10001 | 2023-04-01 | 男 | 28 |
| 1002 | 102 | 10002 | 2023-04-01 | 女 | |
| 1003 | 103 | 10003 | 2023-04-01 | 男 | 22 |
| 1004 | 104 | 10001 | 2023-04-01 | 女 | |
| 1005 | 105 | 10002 | 2023-04-01 | 男 | 45 |
| 1006 | 106 | 10003 | 2023-04-01 | 女 | 32 |
| 1007 | 101 | 10001 | 2023-04-02 | 男 | 28 |
| 1008 | 102 | 10002 | 2023-04-02 | 女 | 35 |
| 1009 | 103 | 10003 | 2023-04-02 | 男 | 22 |
| 1010 | 104 | 10001 | 2023-04-02 | 女 | 45 |
此表格由[小蜜蜂AI网站][https://zglg.work]生成。
1.1.1 ChatGPT帮我做
来看第一种实现方式。只需把数据传给ChatGPT,并发出明确的操作指令即可。源数据一般是CSV格式的,我们需要将其以文本格式传入ChatGPT。下面我们向ChatGPT输入具体操作和数据集。
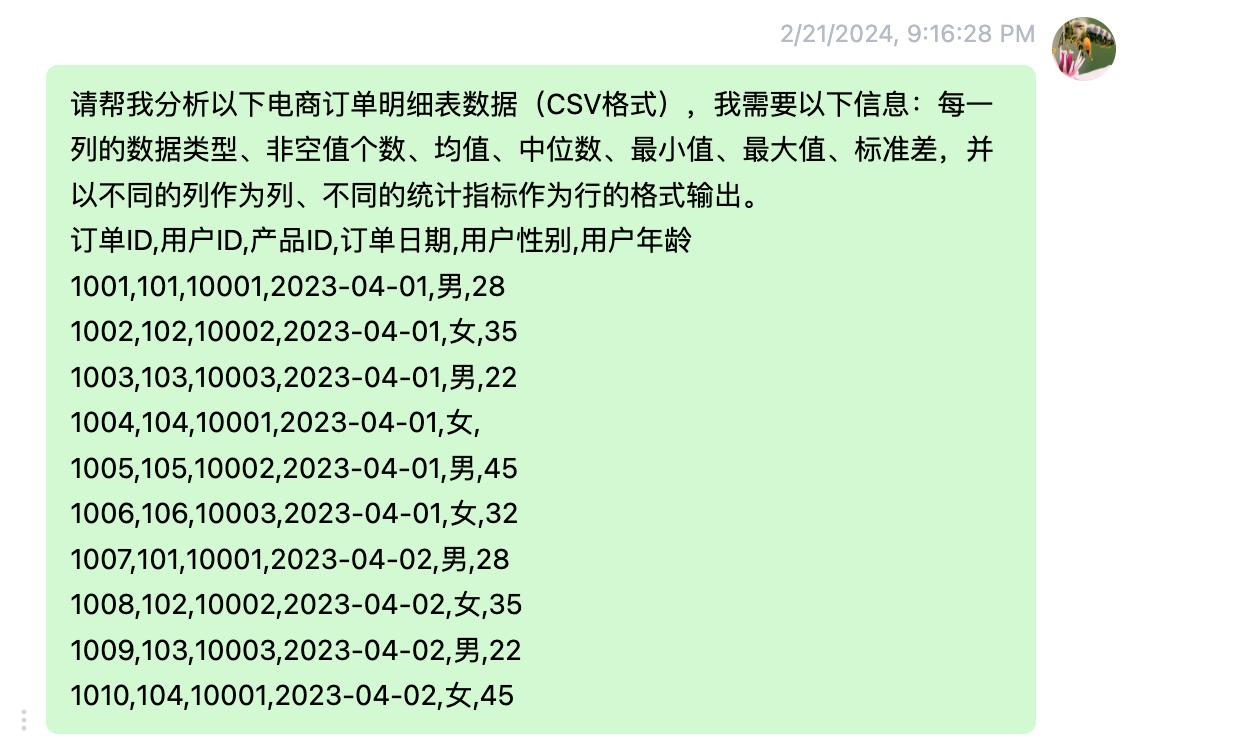
在输入数据时,我们要将CSV文件转换成可以直接输入ChatGPT中的格式。只需将CSV文件用记事本或文本编辑器打开,然后复制粘贴即可。
按照上面的指令,ChatGPT返回如下表所示的结果。
| 统计指标 | 订单ID | 用户ID | 产品ID | 用户年龄 |
|---|---|---|---|---|
| 数据类型 | 整数 | 整数 | 整数 | 整数 |
| 非空值个数 | 10 | 10 | 10 | 8 |
| 均值 | 1005.5 | 102.5 | 10002 | 34.25 |
| 中位数 | 1005.5 | 102.5 | 10002 | 33.5 |
| 最小值 | 1001 | 101 | 10001 | 22 |
| 最大值 | 1010 | 104 | 10003 | 45 |
| 标准差 | 2.87 | 1.29 | 0.82 | 7.79 |
注:订单日期和用户性别列属于文本型数据,无法进行数值统计。
1.1.2 ChatGPT告诉我
来看第二种实现方式,问ChatGPT用什么工具可以及如何实现某个需求。我们需要把数据结构以及具体需求描述清楚,然后发送给ChatGPT。在Excel中概览数据比较简单,这里不展开了,而主要展示在SQL和Python中如何实现。下面是我们向ChatGPT发送的具体内容。

ChatGPT收到上述内容以后,返回如下结果。
-- SQL结果
SELECTCOUNT(order_id) AS non_null_order_id_count, COUNT(DISTINCT user_id) AS non_null_user_id_count,COUNT(DISTINCT product_id) AS non_null_product_id_count,AVG(order_date) AS avg_order_date,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY order_date) AS median_order_date,MIN(order_date) AS min_order_date,MAX(order_date) AS max_order_date,AVG(user_age) AS avg_user_age,STDDEV(user_age) AS stddev_user_age
FROMorders;import pandas as pdorder_df = pd.read_csv('order.csv')result = order_df.describe().transpose()result['non_null'] = order_df.count()
print(result[['non_null', 'mean', '50%','min', 'max', 'std']])# 运行结果如下:non_null mean 50% min max std
订单ID 10 1005.500000 1005.5 1001.0 1010.0 3.027650
用户ID 10 103.100000 103.0 101.0 106.0 1.663330
产品ID 10 10001.900000 10002.0 10001.0 10003.0 0.875595
用户年龄 9 32.444444 32.0 22.0 45.0 8.560244Process finished with exit code 0
在SQL结果中,我没有实际去验证。在Python结果中,使用了describe函数,还是很不错的。我们在Python中概览数据时,就是使用该函数。但是describe函数的结果中已经包含了非空值计数,而ChatGPT又单独计算了一次。
1.2 数据预处理
数据预处理主要包括缺失值填充、重复值删除、异常值删除或替换。接下来看看ChatGPT如何帮助我们完成这项工作。
1.2.1 ChatGPT帮我做
第一种实现方式。下面是我们向ChatGPT输入的具体操作和数据集。

ChatGPT收到上述内容后,给出如下的Python处理代码及结果。
import pandas as pd
import numpy as np# 创建数据集
data = {'订单ID': [1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010],'用户ID': [101, 102, 103, 104, 105, 106, 101, 102, 103, 104],'产品ID': [10001, 10002, 10003, 10001, 10002, 10003, 10001, 10002, 10003, 10001],'订单日期': ['2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-02', '2023-04-02', '2023-04-02', '2023-04-02'],'用户性别': ['男', '女', '男', '女', '男', '女', '男', '女', '男', '女'],'用户年龄': [28, 35, 22, np.nan, 45, 32, 28, 35, 22, 45]}df = pd.DataFrame(data)# 找出缺失值并用均值填充
mean_age = df['用户年龄'].mean()
df['用户年龄'] = df['用户年龄'].fillna(mean_age).astype(int)# 去重
df = df.drop_duplicates()# 将年龄大于40的值视作异常并替换为40
df.loc[df['用户年龄'] > 40,'用户年龄'] = 40
df.to_excel('order.xlsx',index=False) # 我个人添加的,其他部分均由ChatGPT生成
| 订单ID | 用户ID | 产品ID | 订单日期 | 用户性别 | 用户年龄 |
|---|---|---|---|---|---|
| 1001 | 101 | 10001 | 2023-04-01 | 男 | 28 |
| 1002 | 102 | 10002 | 2023-04-01 | 女 | 35 |
| 1003 | 103 | 10003 | 2023-04-01 | 男 | 22 |
| 1004 | 104 | 10001 | 2023-04-01 | 女 | 32 |
| 1005 | 105 | 10002 | 2023-04-01 | 男 | 40 |
| 1006 | 106 | 10003 | 2023-04-01 | 女 | 32 |
| 1007 | 101 | 10001 | 2023-04-02 | 男 | 28 |
| 1008 | 102 | 10002 | 2023-04-02 | 女 | 35 |
| 1009 | 103 | 10003 | 2023-04-02 | 男 | 22 |
| 1010 | 104 | 10001 | 2023-04-02 | 女 | 40 |
ChatGPT没有输出哪一列有缺失值,而是直接对缺失值进行了填充,并对年龄大于40的值进行了替换。总体而言结果符合要求。
1.2.2 ChatGPT告诉我
来看第二种实现方式,把数据结构以及具体要进行的操作描述清楚,然后发给ChatGPT。关于数据预处理,在Excel中实现起来比较简单,而主要展示在SQL和Python中如何实现。下面是我们向ChatGPT发送的具体内容。

ChatGPT收到上述内容后,返回如下结果。
Hive SQL 实现
1. 填充缺失值并返回数据集
-- 使用均值填充缺失值
SELECT 订单ID,用户ID,产品ID,订单日期,用户性别,COALESCE(用户年龄, AVG(用户年龄) OVER ()) AS 用户年龄
FROM your_table;2. 删除重复行后的数据集
-- 删除重复行
CREATE TABLE temp_table AS
SELECT DISTINCT *
FROM your_table;-- 可选步骤:删除原表,重命名临时表为原表名3. 替换异常值后的数据集
-- 替换年龄大于40的异常值为40
UPDATE your_table
SET 用户年龄 = 40
WHERE 用户年龄 > 40;
Python 实现
1. 填充缺失值并返回数据集import pandas as pd# 读取数据
df = pd.read_csv("your_data.csv")# 使用均值填充缺失值
df['用户年龄'] = df['用户年龄'].fillna(df['用户年龄'].mean())2. 删除重复行后的数据集
# 删除重复行
df = df.drop_duplicates()3. 替换异常值后的数据集
# 替换年龄大于40的异常值为40
df.loc[df['用户年龄'] > 40, '用户年龄'] = 40
在SQL结果中,一个语句就实现了填充功能,其他的功能也都轻松搞定。在Python结果中,准确给出了各个操作的函数代码,还是不错的。可以自行体验一下。
1.3 数据选择
数据选择主要是根据实际需求选择特定的行或列。接下来看看ChatGPT如何帮助我们完成这项工作。
1.3.1 ChatGPT帮我做
看看第一种方式,下面是我们向ChatGPT输入的具体操作和数据集。

按照上面的指令,ChatGPT给出如下的Python代码及返回如下所示结果。
import pandas as pd# 创建数据集
data = {'订单ID': [1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010],'用户ID': [101, 102, 103, 104, 105, 106, 101, 102, 103, 104],'产品ID': [10001, 10002, 10003, 10001, 10002, 10003, 10001, 10002, 10003, 10001],'订单日期': ['2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-02', '2023-04-02', '2023-04-02', '2023-04-02'],'用户性别': ['男', '女', '男', '女', '男', '女', '男', '女', '男', '女'],'用户年龄': [28, 35, 22, None, 45, 32, 28, 35, 22, 45]
}df = pd.DataFrame(data)# 找出订单日期为“2023-04-01”的女性用户全部订单
filtered_df = df[(df['订单日期'] == '2023-04-01') & (df['用户性别'] == '女')]
print(filtered_df)订单ID 用户ID 产品ID 订单日期 用户性别 用户年龄
1 1002 102 10002 2023-04-01 女 35.0
3 1004 104 10001 2023-04-01 女 NaN
5 1006 106 10003 2023-04-01 女 32.0
可以看到,ChatGPT按照我们的要求完成了任务。
1.3.2 ChatGPT告诉我
看看第二种实现方式。下面是我们向ChatGPT发送的具体内容。

按照上面的指令,ChatGPT返回如下结果。
SQL 结果:
-- 筛选订单日期为“2023-04-01”的女性用户的全部订单
SELECT *
FROM your_table
WHERE 订单日期 = '2023-04-01' AND 用户性别 = '女';
# Python结果
import pandas as pd
# 假设数据已经存储在名为data的pandas DataFrame中
# 如果需要从CSV文件中读取数据,可以使用如下代码:
# data = pd.read_csv('your_csv_file.csv')df = pd.DataFrame(data)# 筛选订单日期为“2023-04-01”的女性用户的全部订单
filtered_df = df[(df['订单日期'] == '2023-04-01') & (df['用户性别'] == '女')]
print(filtered_df) 因为数据选择相关的需求整体比较简单,所以ChatGPT给出的结果都没什么问题。
1.4 数值操作
数值操作主要是对数据进行替换、排序等操作。接下来看看ChatGPT如何帮助我们完成这项工作。
1.4.1 ChatGPT帮我做
看看第一种方式。下面是我们向ChatGPT输入的具体操作和数据集。

ChatGPT收到上述内容后,返回如下结果。
import pandas as pd# 创建数据集
data = {'订单ID': [1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010],'用户ID': [101, 102, 103, 104, 105, 106, 101, 102, 103, 104],'产品ID': [10001, 10002, 10003, 10001, 10002, 10003, 10001, 10002, 10003, 10001],'订单日期': ['2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-02', '2023-04-02', '2023-04-02', '2023-04-02'],'用户性别': ['男', '女', '男', '女', '男', '女', '男', '女', '男', '女'],'用户年龄': [28, 35, 22, None, 45, 32, 28, 35, 22, 45]
}df = pd.DataFrame(data)# 替换年龄大于40的值为40
df.loc[df['用户年龄'] > 40, '用户年龄'] = 40# 按订单日期升序排列
df = df.sort_values(by='订单日期')# 新增一列,内容为该用户的上一笔订单日期
df['上一笔订单日期'] = df.groupby('用户ID')['订单日期'].shift(1)df.to_excel('帮我做.xlsx', index=False)
# 返回最终结果
print(df)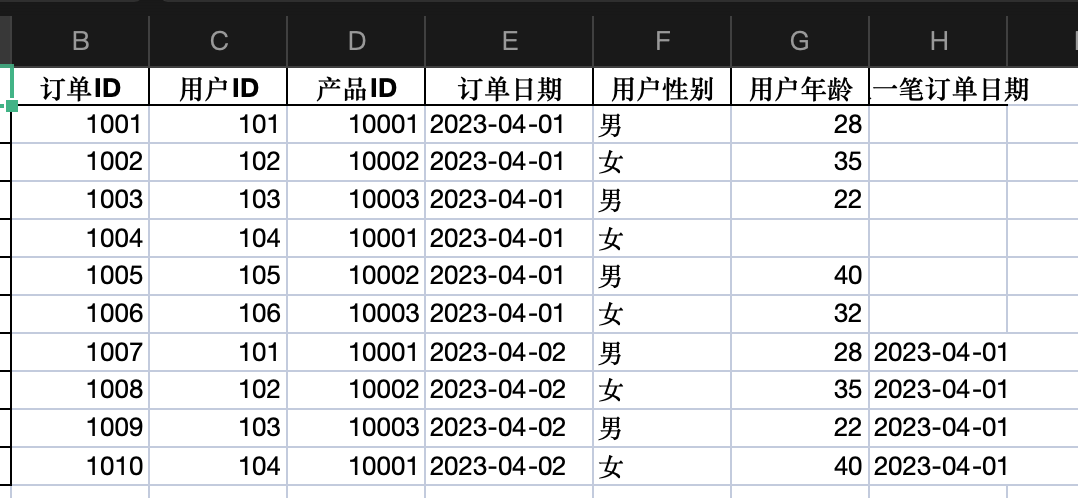
可以看到,ChatGPT给出的结果中,年龄已经按要求替换了,订单日期也升序排列了,新的一列也添加成了,而按订单日期升序排列的操作导致新增的这一列看起来有点乱,但结果是正确的。👍👍👍
1.4.2 ChatGPT告诉我
看看第二种方式。下面是我们向ChatGPT发送的具体内容。

ChatGPT收到上述内容后,返回如下结果。
SQL 结果:
-- 1. 将年龄大于40的值替换成40
UPDATE your_table
SET 用户年龄 = 40
WHERE 用户年龄 > 40;-- 2. 将数据按照订单日期进行升序排列
SELECT *
FROM your_table
ORDER BY 订单日期 ASC;-- 3. 新增一列数据,内容为该用户的上一笔订单日期
SELECT *,LAG(订单日期) OVER (PARTITION BY 用户ID ORDER BY 订单日期) AS 上一笔订单日期
FROM your_table;# Python 结果import pandas as pddata = pd.read_csv('order.csv')
df = pd.DataFrame(data)# 1. 将年龄大于40的值替换成40
df['用户年龄'] = df['用户年龄'].apply(lambda x: min(x, 40))# 2. 将数据按照订单日期进行升序排列
df.sort_values(by='订单日期',inplace=True)# 3. 新增一列数据,内容为该用户的上一笔订单日期
df['上一笔订单日期'] = df.groupby('用户ID')['订单日期'].shift(1)
df.to_excel('帮我做1.xlsx')
print(df)订单ID 用户ID 产品ID 订单日期 用户性别 用户年龄 上一笔订单日期
0 1001 101 10001 2023-04-01 男 28.0 NaN
1 1002 102 10002 2023-04-01 女 35.0 NaN
2 1003 103 10003 2023-04-01 男 22.0 NaN
3 1004 104 10001 2023-04-01 女 NaN NaN
4 1005 105 10002 2023-04-01 男 40.0 NaN
5 1006 106 10003 2023-04-01 女 32.0 NaN
6 1007 101 10001 2023-04-02 男 28.0 2023-04-01
7 1008 102 10002 2023-04-02 女 35.0 2023-04-01
8 1009 103 10003 2023-04-02 男 22.0 2023-04-01
9 1010 104 10001 2023-04-02 女 40.0 2023-04-01
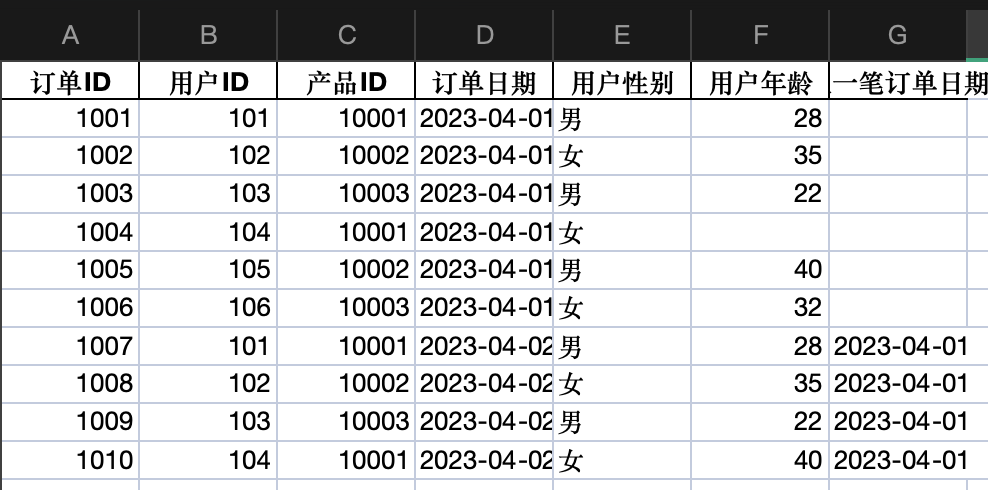
SQL结果的逻辑基本是准确的。这里主要看第三个操作,刚开始的实现逻辑是借助ROW_NUMBER 函数,比较复杂,经过提示可以直接使用LAG函数以后(过程省略),ChatGPT马上给出了正确的答案。
Python结果的实现方式和代码完全正确。
1.5 数值运算
数值运算主要是对数据进行算术运算、比较运算、汇总运算等操作。接下来看看ChatGPT如何帮助我们完成这项工作的。
1.5.1 ChatGPT帮我做
看看第一种实现方式。下面是我们向ChatGPT输入的具体操作和数据集。

ChatGPT收到上述内容后,Python实现代码及返回结果。
import pandas as pd# 创建数据集
data = {'订单ID': [1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010],'用户ID': [101, 102, 103, 104, 105, 106, 101, 102, 103, 104],'产品ID': [10001, 10002, 10003, 10001, 10002, 10003, 10001, 10002, 10003, 10001],'订单日期': ['2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-01', '2023-04-02', '2023-04-02', '2023-04-02', '2023-04-02'],'用户性别': ['男', '女', '男', '女', '男', '女', '男', '女', '男', '女'],'用户年龄': [28, 35, 22, None, 45, 32, 28, 35, 22, 45]
}df = pd.DataFrame(data)# 1. 将订单ID列和产品ID列进行相加,生成新的一列
df['相加结果'] = df['订单ID'] + df['产品ID']# 2. 对用户ID进行非重复值计数
non_duplicate_count = df['用户ID'].nunique()# 返回结果
print("添加相加结果的数据集:")
print(df)
print("\n用户ID的非重复值计数结果:", non_duplicate_count)# 运行结果
添加相加结果的数据集:订单ID 用户ID 产品ID 订单日期 用户性别 用户年龄 相加结果
0 1001 101 10001 2023-04-01 男 28.0 11002
1 1002 102 10002 2023-04-01 女 35.0 11004
2 1003 103 10003 2023-04-01 男 22.0 11006
3 1004 104 10001 2023-04-01 女 NaN 11005
4 1005 105 10002 2023-04-01 男 45.0 11007
5 1006 106 10003 2023-04-01 女 32.0 11009
6 1007 101 10001 2023-04-02 男 28.0 11008
7 1008 102 10002 2023-04-02 女 35.0 11010
8 1009 103 10003 2023-04-02 男 22.0 11012
9 1010 104 10001 2023-04-02 女 45.0 11011用户ID的非重复值计数结果: 6
可以看到,ChatGPT按照我们的要求完成了任务。
1.5.2 ChatGPT告诉我
看看第二种方式。下面是我们向ChatGPT发送的具体内容。

ChatGPT收到上述内容以后,返回如下结果。
# SQL结果
-- 1. 将订单ID列和产品ID列进行相加,生成新的一列
ALTER TABLE your_table ADD COLUMN 相加结果 INT;
UPDATE your_table SET 相加结果 = 订单ID + 产品ID;-- 2. 对用户ID进行非重复值计数,返回计数结果
SELECT COUNT(DISTINCT 用户ID) AS 非重复用户数
FROM your_table;# Python结果
import pandas as pddata = pd.read_csv('order.csv')
df = pd.DataFrame(data)# 1. 将订单ID列和产品ID列进行相加,生成新的一列
df['相加结果'] = df['订单ID'] + df['产品ID']# 2. 对用户ID进行非重复值计数,返回计数结果
non_duplicate_count = df['用户ID'].nunique()# 返回结果
print("添加相加结果的数据集:")
print(df)
print("\n用户ID的非重复值计数结果:", non_duplicate_count) 上述SQL和Python的实现逻辑都是正确的。因为数值运算整体比较简单,所以这里就不举更多例子了,大家可以根据实际的业务需求进行调整。
1.6 数据分组
数据分组是按照某些维度先对数据进行分组,再对分组后的数据进行汇总运算。接下来看看ChatGPT如何帮助我们完成这项工作。
1.6.1 ChatGPT帮我做
看看第一种方式。下面是我们向ChatGPT输入的具体操作和数据集。
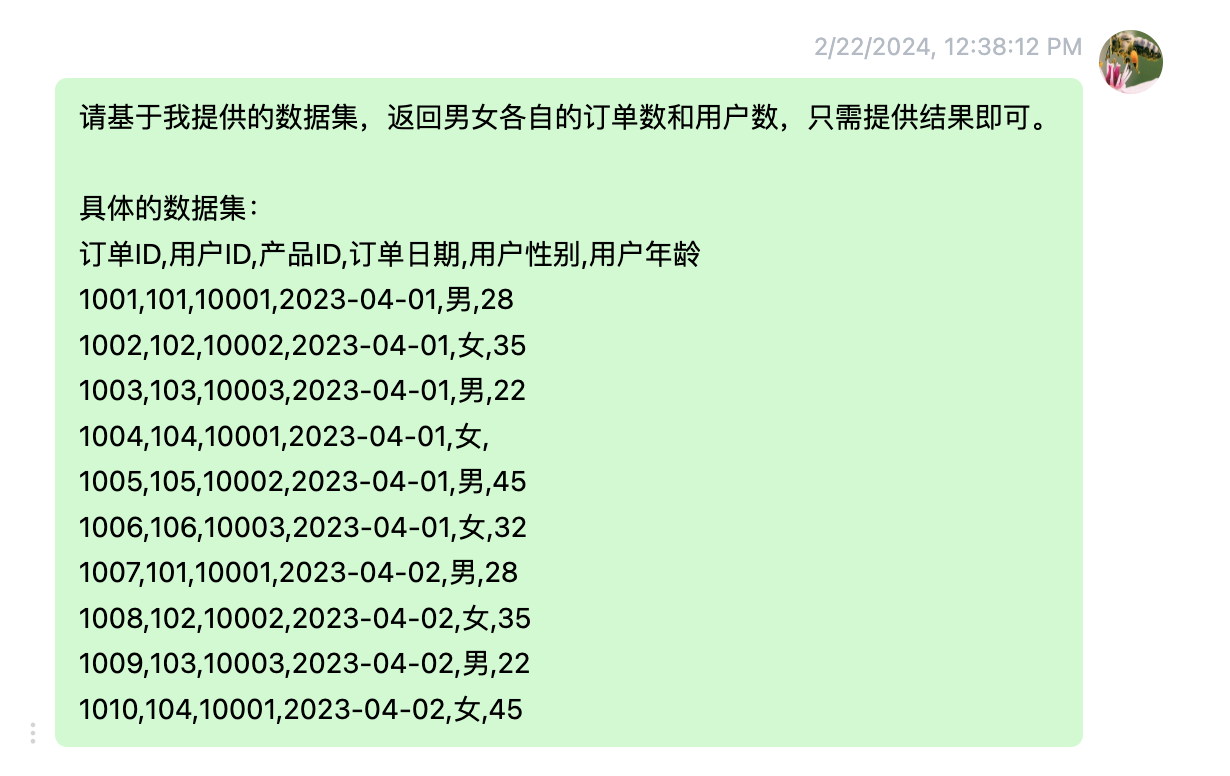
ChatGPT收到上述内容后,返回如下结果。
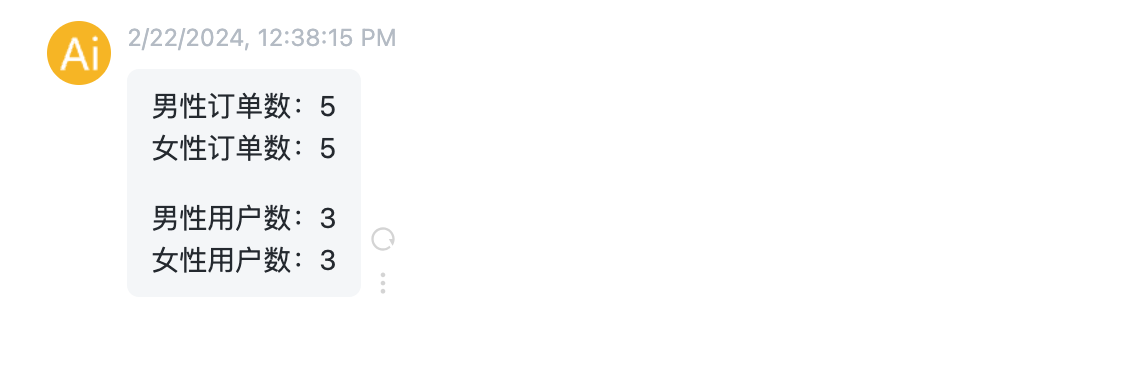
可以看到,ChatGPT按照我们的要求完成了任务。
1.6.2 ChatGPT告诉我
看看第二种实现方式。下面是我们向ChatGPT发送的具体内容。

ChatGPT收到上述内容后,返回如下结果。
SQL 结果
-- 计算男性和女性的订单数
SELECT 用户性别, COUNT(订单ID) AS 订单数
FROM your_table
GROUP BY 用户性别;-- 计算男性和女性的用户数
SELECT 用户性别, COUNT(DISTINCT 用户ID) AS 用户数
FROM your_table
GROUP BY 用户性别;
# Python结果
import pandas as pddata = pd.read_csv('order.csv')
df = pd.DataFrame(data)# 计算男性和女性的订单数
order_counts = df['用户性别'].value_counts()# 计算男性和女性的用户数
user_counts = df.groupby('用户性别')['用户ID'].nunique()# 返回结果
print("男性和女性各自的订单数:")
print(order_counts)
print("\n男性和女性各自的用户数:")
print(user_counts)# 运行结果如下:
男性和女性各自的订单数:
男 5
女 5
Name: 用户性别, dtype: int64男性和女性各自的用户数:
用户性别
女 3
男 3
Name: 用户ID, dtype: int64 上述SQL和Python的实现逻辑都是正确的
1.7 时间序列分析
时间序列分析的操作主要时间格式互换、时间索引、时间运算等。接下来看看ChatGPT如何帮助我们完成这项工作。
1.7.1 ChatGPT帮我做
看看第一种方式。下面是我们向ChatGPT输入的具体操作和数据集。
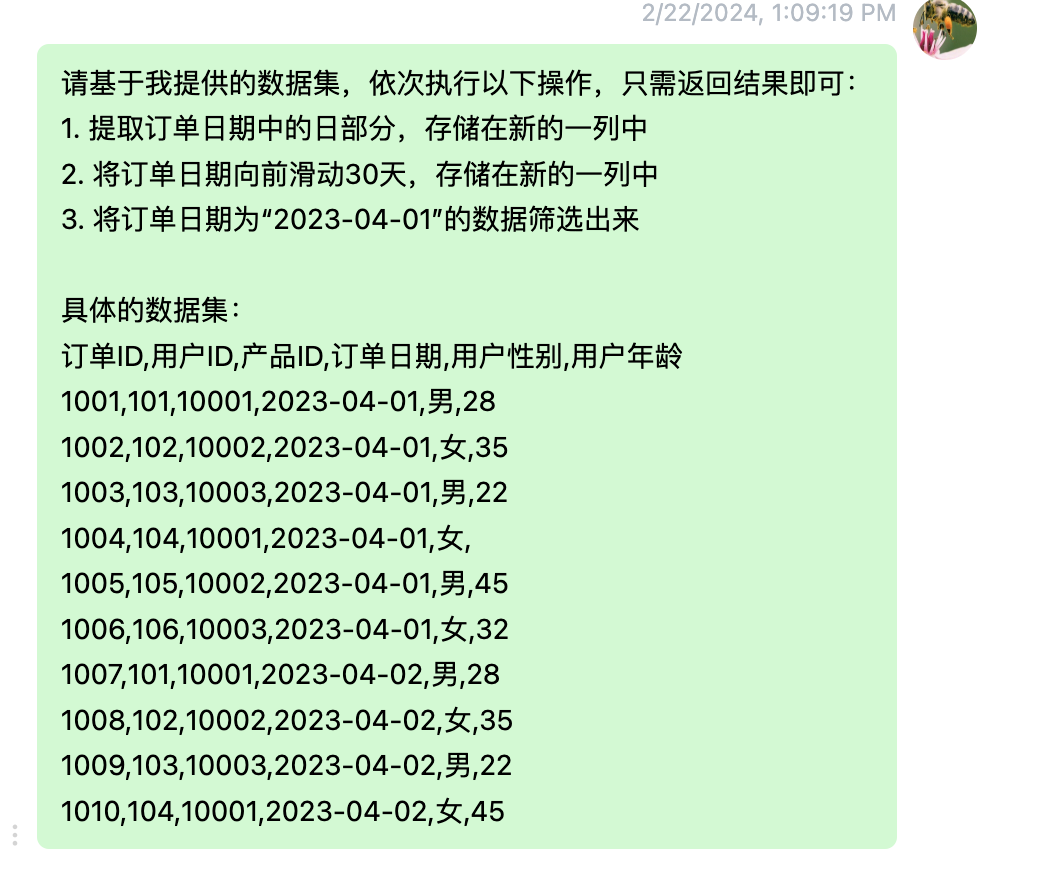
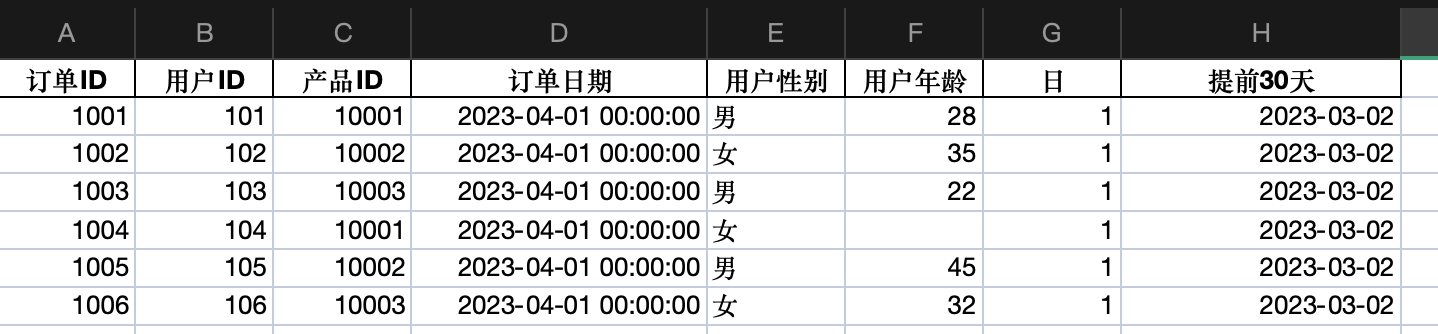
ChatGPT收到上述内容后,返回如下所示结果。
1.7.2 ChatGPT帮我做
看看第二种方式,下面我们向ChatGPT发送的具体内容。

ChatGPT收到上述内容后,返回如下结果。
SQL 结果
-- 1. 提取订单日期中的日部分,存储在新的一列中
ALTER TABLE your_table ADD COLUMN 日部分 STRING;
UPDATE your_table SET 日部分 = SUBSTR(订单日期, 9, 2);-- 2. 将订单日期向前滑动30天,存储在新的一列中
ALTER TABLE your_table ADD COLUMN 减去30天日期 STRING;
UPDATE your_table SET 减去30天日期 = FROM_UNIXTIME(UNIX_TIMESTAMP(订单日期) - 30*24*60*60, 'yyyy-MM-dd');-- 3. 将订单日期为“2023-04-01”的数据筛选出来
SELECT *
FROM your_table
WHERE 订单日期 = '2023-04-01';# Python结果
'''import pandas as pd
from datetime import timedelta# 读取数据集
data = pd.read_csv("order.csv")# 提取订单日期中的日部分
data['日'] = pd.to_datetime(data['订单日期']).dt.day
# 将订单日期转换为日期类型
data['订单日期'] = pd.to_datetime(data['订单日期'])# 向前滑动30天
data['提前30天'] = data['订单日期'] - timedelta(days=30)# 筛选订单日期为“2023-04-01”的数据
filtered_data = data[data['订单日期'] == '2023-04-01']
# 打印结果
filtered_data.to_excel('筛选完.xlsx')'''
import pandas as pddata = pd.read_csv('order.csv')
df = pd.DataFrame(data)# 1. 提取订单日期中的日部分,存储在新的一列中
df['日部分'] = df['订单日期'].str[-2:]# 2. 将订单日期向前滑动30天,存储在新的一列中
df['减去30天日期'] = pd.to_datetime(df['订单日期']) - pd.DateOffset(days=30)# 3. 将订单日期为“2023-04-01”的数据筛选出来
filtered_data = df[df['订单日期'] == '2023-04-01']# 返回结果
print("提取订单日期中的日部分和减去30天日期后的数据集:")
print(df[['订单ID', '用户ID', '产品ID', '订单日期', '用户性别', '用户年龄', '日部分', '提前30天']])
print("\n订单日期为'2023-04-01'的数据:")
print(filtered_data)# 运行结果
订单日期为'2023-04-01'的数据:订单ID 用户ID 产品ID 订单日期 用户性别 用户年龄 日部分 提前30天
0 1001 101 10001 2023-04-01 男 28.0 1 2023-03-02
1 1002 102 10002 2023-04-01 女 35.0 1 2023-03-02
2 1003 103 10003 2023-04-01 男 22.0 1 2023-03-02
3 1004 104 10001 2023-04-01 女 NaN 1 2023-03-02
4 1005 105 10002 2023-04-01 男 45.0 1 2023-03-02
5 1006 106 10003 2023-04-01 女 32.0 1 2023-03-02
上述SQL和Python的实现逻辑都是正确的。
所有示例均可在小蜜蜂AI网站实现,网址:https://zglg.work
扫描下面二维码注册
