可变形注意力(Deformable Attention)及其拓展
文章目录
- 一、补充知识
- (一)可变形卷积(Deformable Convolution)
- (二)多头注意力机制
- 二、可变形注意力模块
- 三、可变形自注意力模块
- (一)偏移模块:
- (二)注意力模块
- 三、多尺度可变形注意力:
- 四、常规注意力模块与可变形注意力模块的不同
一、补充知识
(一)可变形卷积(Deformable Convolution)
可变形卷积将固定形状的卷积过程改造成了能适应物体形状的可变的卷积过程,从而使结构适应物体形变的能力更强。
实现方式: 对感受野上的每一个点加一个偏移量 ,偏移的大小是通过学习得到的 ,偏移后感受野不再是个正方形,而是和物体的实际形状相匹配。这么做的好处就是无论物体怎么形变,卷积的区域始终覆盖在物体形状的周围。如下图所示:
- a 为原始感受野范围
- b ~ d 是对感受野上的添加偏移量后的感受野范围,可以看到叠加偏移量的过程可以模拟出目标移动、尺寸缩放、旋转等各种形变


实验效果 : 左侧的传统卷积单个目标共覆盖了5 x 5=25个采样点,感受野始终是固定不变的方形;右侧的可变形卷积因为感受野的每一个点都有偏移量,造成卷积核在图片上滑动时对应的感受野的点不会重复选择,这意味着会采样9 x 9=81个采样点,比传统卷积更多。
传统卷积核在卷积过程中由于会存在重叠,最终输出后的感受野范围小,而可变性卷积中因为有偏移,不会有重叠,从而感受野范围更大

(二)多头注意力机制
多头注意力机制的基本步骤:
- 线性变换:对输入序列 X X X进行多次线性变换,得到多组查询 Q i Q_i Qi、键 K i K_i Ki和值 V i V_i Vi;
- 注意力计算:对每组查询、键和值分别进行注意力计算,得到多组注意力加权的输出表示;
- 将多组注意力加权的输出拼接在一起, 并通过另一个可以学习的线性投影进行变换,得到最终输出。
公式表示如下。其中, m m m代表多头注意力机制中的第m个注意力头, x x x为Key和Value输入特征, z z z为Query输入特征, W m ′ W'_m Wm′是输入特征到Value的转移矩阵,用于将 x k x_k xk变换成value, W m W_m Wm是对注意力施加在value后的结果进行线性变换从而得到不同头部的输出结果,标量 A m q k A_{mqk} Amqk是注意力权重。

二、可变形注意力模块
可变形注意力(Deformable Attention)是一种用于神经网络中的注意力机制。在传统的注意力机制中,权重是通过对位置固定的注意力模型进行计算得到的。而在可变形注意力中,可以动态地调整注意力模型的形状和大小,以更好地适应不同任务和输入数据的特点。
大体流程如下:
- 给定特征图 x ∈ R H × W × C x\in \mathbb{R}^{H\times W\times C} x∈RH×W×C,生成一个点 p ∈ R H G × W G × 2 p\in \mathbb{R}^{H_G \times W_G \times 2} p∈RHG×WG×2的统一网格作为参考;
- 将特征映射线性投影到query token q = x W q q=xW_q q=xWq,然后输入一个轻量子网络 θ o f f s e t \theta_{offset} θoffset,生成偏移量 Δ θ o f f s e t ( q ) \Delta \theta_{offset(q)} Δθoffset(q);
- 在变形点的位置采样,作为key和value,与query一同传入多头注意力机制中;
- 每个头部的特征连接在一起,通过 W 0 W_0 W0投影得到最终输出 z z z。

单尺度可变形注意力用公式表达如下。其中, A m q k A_{mqk} Amqk不是由Query和Key矩阵做内积得到,而是由输入特征 z q z_q zq直接通过全连接层得到的; p q p_q pq代表 z q z_q zq的位置(理解成坐标即可),是2D向量,作者称其为参考点; Δ p m q k \Delta p_{mqk} Δpmqk表示第m个注意力头第k个采样点相对于参考点的位置偏移; K K K是采样的key总数。
可以看到,每个query在每个头部中采样K个位置,只需和这些位置的特征交互( x ( p q + Δ q m q k ) x(p_q+\Delta q_{mqk}) x(pq+Δqmqk))。
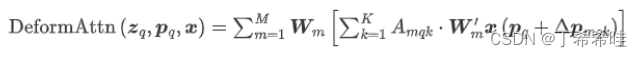
三、可变形自注意力模块
在groundingdino的模型框架中,对于图像特征的增强就采用了Deformable Self-Attention模块,具体可以参考Grounding DINO:开放集目标检测,将基于Transformer的检测器DINO与真值预训练相结合。
变形自注意力模块主要由两个组成部分构成:偏移模块和注意力模块。 大致流程如下图所示:
- 将输入向量转换成特征图,然后生成Query向量,同时考虑参考点的坐标;
- 将输入特征图在线性变换后与Query向量一同输入到偏移模块中
- 将偏移模块产出的结果与Query向量输入到注意力模块中得到最终结果。

(一)偏移模块:
偏移模块对Query向量应用线性变换,得到偏移 Δ p q \Delta p_q Δpq;然后根据参考点的偏移确定每个参考点的感兴趣点(采样点),并使用双线性插值实现每个点的输出 o f s e t v a l u e ofset_{value} ofsetvalue。
每个Query向量具有H个注意力头,每个注意力头与K个偏移点相关联。
(二)注意力模块
注意力模块的过程:
- 开始于对输入Query向量的线性变换,并且使用softmax函数生成每个偏移的权重向量。
- 将offset模块中确定的每个偏移的输出与相应的权重向量相乘并汇总,得到 S a m p l e v a l u e Sample_{value} Samplevalue。
- 之后,再将每个参考点对应的注意力头连接起来,得到最终的向量,称为 S a m p l e o u t p u t Sample_{output} Sampleoutput。
- 最后,对采用后的输出向量进行线性变换,得到最终的输出值。
三、多尺度可变形注意力:
多尺度可变形注意力与单尺度可变形注意力的计算公式相比,多出了 { x l } l = 1 l \{x^l\}^l_{l=1} {xl}l=1l和 ϕ l ( ) \phi _l() ϕl()。 { x l } l = 1 l \{x^l\}^l_{l=1} {xl}l=1l是输入的多尺度特征图集合, p ^ q \hat{p}_q p^q表示归一化, ϕ l ( ) \phi _l() ϕl()用于将归一化的坐标映射到各个特征层去
ϕ l ( ) \phi _l() ϕl()使得每个参考点在所有特征层都会有一个对应的归一化坐标,方便计算在不同特征层进行采样的点的位置

四、常规注意力模块与可变形注意力模块的不同
- 常规注意力模块中, k ∈ Ω k k\in \Omega _k k∈Ωk,即考虑所有的key;而可变形注意力模块中 k ∈ [ 1 , K ] k \in [1,K] k∈[1,K],即只需要考虑一部分的key。
- 常规注意力模块中,分别取 N k N_k Nk个 x k x_k xk,然后把结果作加权求和;而可变形注意力模块中 x ∈ C × H × W x\in C\times H \times W x∈C×H×W,设 p q p_q pq是2D空间上任意一点,先与一个2D实数值 Δ p m q k \Delta p_{mqk} Δpmqk相加,然后通过双线性插值得到新的feature map的一点。

- Deformable的Attention不是用Query和Key矩阵做内积得到的,而是由输入特征直接通过Lienear Transformation得到的。
参考:
Deformable DETR
CVPR 2022 | 清华开源DAT:具有可变形注意力的视觉Transformer
MFDS-DETR开源 | HS-FPN多级特征融合+Deformable Self-Attention,再续DETR传奇
详解可变形注意力模块(Deformable Attention Module)