python多页网站目录_2:url有规律的多页面爬取
举例网站:http://www.luoo.net/music/期刊号
e.g:http://www.luoo.net/music/760
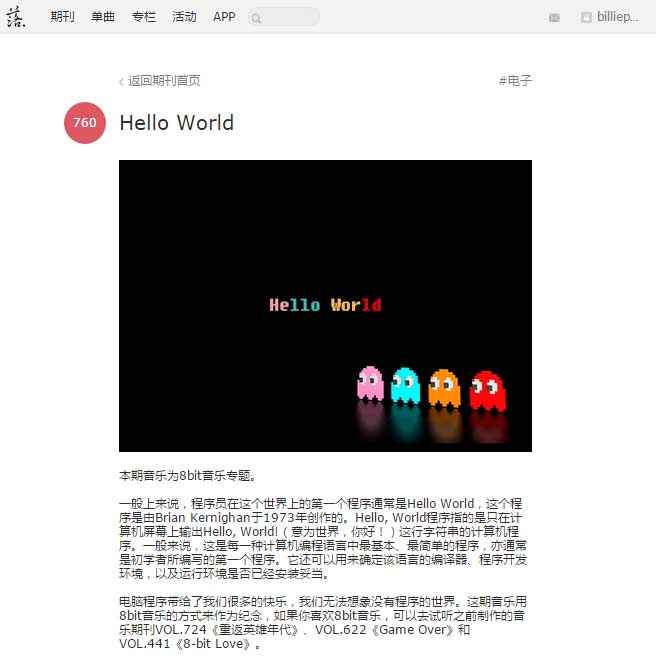
打算爬取其title:Hello World;pic;desc:本期音乐为......《8-bit Love》。
步骤:
1):建立项目
在shell中你对应的目录下:scrapy startproject luoo
在pycharm中打开luoo文件夹
2):编写items.py
1 importscrapy2 classLuooItem(scrapy.Item):3 url =scrapy.Field()4 title =scrapy.Field()5 pic =scrapy.Field()6 desc = scrapy.Field()
3):编写spider
在spiders文件夹下建立luoospider.py
1 importscrapy2 from luoo.items importLuooItem3
4 classLuooSpider(scrapy.Spider):5 name = "luoo"
6 allowed_domains = ["luoo.net"]7 start_urls =[]8 for i in range(750,763):9 url = 'http://www.luoo.net/music/%s'%(str(i))10 start_urls.append(url)11
12 defparse(self, response):13 item =LuooItem()14 item['url'] =response.url15 item['title'] = response.xpath('//span[@class="vol-title"]/text()').extract()16 item['pic'] = response.xpath('//img[@class="vol-cover"]/@src').extract()17 item['desc'] = response.xpath('//div[@class="vol-desc"]/text()').extract()18 return item
4)pipelines.py不动
5)在command中进入luoo目录
scrapy list 列出可用的爬虫(luoo)
scrapy crawl luoo -o result.csv(执行爬虫并且以result.csv保存到当前目录下)
6)用notepad++打开result.py并且更改格式为ANSI后保存,再用excel打开就不会有乱码了
*遗留to do:
1)数据考虑后期迁移到mysql数据库
2)单独把图片保存到图片格式的文件夹中
memory:顺便附上两个月前用urllib库实现的此功能代码(python3.4)
现在看看用scrapy真的是方便太多了,更别提其牛逼呼呼的可扩展性:
1 importurllib.request2 importre3 importtime4
5 defopenurl(urls):6 htmls=[]7 for url inurls:8 req=urllib.request.Request(url)9 req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.107 Safari/537.36')10 #Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0
11 response =urllib.request.urlopen(url)12 htmls.append(response.read())13 time.sleep(5)14 returnhtmls15
16 defjiexi(htmls):17 pics=[]18 titles=[]19 contents=[]20 for html inhtmls:21 html = html.decode('utf-8')22 pics.append(re.findall('
26 i =len(titles)27 with open('C:\\Users\\Administrator\\Desktop\\test.txt', 'w') as f:28 for x inrange(i):29 print("正在下载期刊:%d" %(746-x))30 f.write("期刊名:"+str(titles[x])[2:-2]+"\n")31 f.write("图片链接:"+str(pics[x])[2:-2]+".jpg\n")32 content = str(contents[x])[4:-2]33 content.strip()34 print(content.count("""
\n"""))35 content.replace("""
\n""","#")36 f.write("配诗:"+content+"\n\n\n")37
38
39 yur='http://www.luoo.net/music/'
40 urls =[]41 for i in range(657,659):42 urls.append(yur +str(i))43
44 htmls =openurl(urls)45 pics = jiexi(htmls)